the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 28 May 2026
| 28 May 2026
Boosting ensembles for statistics of tails at conditionally optimal advance split times
Justin Finkel
Paul A. O'Gorman
Climate science needs more efficient ways to study high-impact, low-probability extreme events, which are rare by definition and costly to simulate in large numbers. Rare event sampling (RES), including ensemble boosting, offers a novel strategy to extract more information from those occasional simulated events, by applying small perturbations to turn a moderate event into a severe one which otherwise might not come for many more simulation-years. But how severe the events can become, and their estimated probabilities, depend sensitively on the details of the perturbation. In particular, for sudden and transient events like precipitation, performance of boosting depends sensitively on the choice of advance split time (AST) of the perturbation. Heuristically, the perturbation must come early enough before the event to let the ensemble of simulations diversify, but not so early that they forget the special initial conditions that led to the extreme. In pursuit of guidelines for choosing the AST, we study the effect of AST in the task of sampling extreme fluctuations of a passive tracer in a quasigeostrophic turbulent channel flow. This model system is idealized, but captures key elements of midlatitude storm track dynamics while exposing similar algorithmic challenges. We formulate AST selection as a concrete optimization problem for statistical accuracy against a ground truth. Given that such a ground truth would not generally be available, we propose a proxy objective function to optimize in practice: thresholded entropy, which rewards ensembles with both a high mean and a large spread. We show that ensemble boosting, when given a well-chosen AST and equipped with methods to estimate probabilities, can accurately sample extremes at long return periods. We furthermore find evidence that thresholded entropy successfully identifies an optimal AST, which is roughly 1–3 ddy turnover timescales in the quasigeostrophic system. Moreover, this proxy captures the variation of AST with the target location of the tracer within the flow field, suggesting it can generalize to more general chaotic systems including realistic climate models. Applying our boosting methodology at scale will require further development in adaptive optimization strategies, but our work here is an essential first step for establishing what must be optimized.
- Article
(17134 KB) - Full-text XML
- BibTeX
- EndNote




1.1 Background and motivation
The outsize impact of extreme weather events, and the need to understand the physical processes that cause them, have driven substantial research interest in the tails of climatological probability distributions. The fundamental challenge is scarcity of data: the historical record is too short to enable robust estimation of extremes rarer than a few times per century, even if the climate were stationary. Different modeling paradigms have developed to confront the issue. The most straightforward is direct numerical simulation (DNS), whereby a climate model is integrated extensively and the extreme events tallied, either as a single long run with stationary forcing (e.g., Huang et al., 2016; O'Gorman and Schneider, 2009) or as an ensemble with non-stationary forcing (e.g., Thompson et al., 2017; John et al., 2022). This increases the sample size of extreme events, and reduces the relative error (mean/standard deviation) of an empirical estimate , but at a slow rate of for p≪1 (Zuev, 2015). For example, estimating the probability of a once-per-century storm (p=0.01 yr−1) to within 10 % relative error would take roughly model years. Most of that simulation time is wasted, just waiting for the next event.
Rare event sampling (RES) takes a shortcut by repurposing that time to generate more extremes instead, perturbing simulations in a targeted way to favor extreme behavior – with the tradeoff of having to account for bias properly. The need to track probabilities makes rare event sampling distinct from optimization, i.e., finding the most extreme event possible (or plausible) given physical constraints. That problem has been attacked successfully with constrained optimization algorithms by Farazmand and Sapsis (2017) and Blonigan et al. (2019) for extreme dissipation events in turbulence, and in AI-based weather forecasting by Whittaker and Luca (2025) for extreme heat waves. RES can benefit from these techniques, but aims to represent the entire tail distribution of extremes with statistical fidelity and not just the maximum.
RES was first developed for nuclear safety assessment (Kahn and Harris, 1951), and has since been generalized for diverse applications including structural reliability engineering (Au and Beck, 2001), molecular dynamics (Zuckerman and Chong, 2017), and more recently climate and weather (e.g., Ragone et al., 2018; Webber et al., 2019; Baars et al., 2021). RES stands in contrast to many other strategies which, in one way or another, replace the expensive physical model with a cheaper approximation. Extreme value theory gives principles for parametrically estimating distributions tails (Coles, 2001), but its asymptotic assumptions are not always justified by the finite datasets available, and it is best suited to model univariate distributions (e.g., average temperature over a region) rather than full spatiotemporal processes like storms, although spatial extreme value modeling is steadily progressing (Huser and Wadsworth, 2022; Huser et al., 2025). Hybrid statistical/physical models aim to parameterize physical processes rather than the final output statistics, and include linear inverse models (Penland and Magorian, 1993); stochastic weather generators based on analogues or Markov state models (van den Dool, 1989; Ghil et al., 2011; Yiou and Jézéquel, 2020; Finkel et al., 2023; Pons et al., 2024); empirical downscaling (Vandal et al., 2017; Saha and Ravela, 2024; Rampal et al., 2025); statistical (including machine-learned) emulation (Tebaldi et al., 2020; Boulaguiem et al., 2022; Mahesh et al., 2024a, b); and generative modeling (Watt and Mansfield, 2024; Sundar et al., 2024; Giorgini et al., 2024). Machine learning models in particular are proliferating at a dizzying pace, and they can indeed generate new samples at low cost, but their ability to represent physics outside their training data – perhaps the most essential requirement for extreme event modeling – is rightly regarded with suspicion.
In light of these options, modelers have several tools to help deal with the tradeoff between bias (incorrect physics or limited resolution) and variance (erratic statistical estimates due to limited sample size). The methods are not mutually exclusive, with many interesting synergies possible (e.g., as conceptualized in Lucente et al., 2022), but RES in particular is our focus here as an under-utilized and under-developed strategy to reduce variance without incurring extra bias.
1.2 Rare event sampling: promise and pitfalls
The generic RES procedure can be summarized as follows. We denote the full state vector by x(t)∈ℝd, and the measure of severity by R*: some functional of a trajectory x that is user-defined, e.g., rainfall averaged over any time interval and spatial region of interest.
-
Generate an ensemble of initial conditions to serve as candidate extreme events. Call these “ancestors”.
-
Select a subset of ancestors with high propensity to produce extreme events (large R*), discarding the others. Apply small perturbations to this subset to generate “descendants”: new simulations likely to generate large R* like their parents, but to do so in diverse ways.
-
Adjust the probability weights downward on these selected ancestors, spreading their weight across their descendants to correct for the over-sampling.
-
Repeat steps 2–3 multiple times on the new, extreme-skewed population, until hitting a termination criterion.
-
Estimate any climatological statistics of interest by taking weighted averages of all the simulations.
This template must be specialized for the kind of target event. Diffusion Monte Carlo (DMC), as applied to season-long hot extremes (with a variant called “GKTL” after its inventors; Ragone et al., 2018) and tropical cyclones (with a variant called “QDMC” that applies quantile mapping to intensity values; Webber et al., 2019), performs the split/kill operation at a chronological sequence of time points, extending the timespan of surviving members while aborting discarded members before they can run to completion—thus, before their R* values can even be measured. This is appropriate when the propensity for a future extreme R* is well-approximated by some property R(x(t)) measurable at the present: for example, if R* is the mean temperature from June to August, R(x(t)) = (running average temperature from 1 June to t) is a good splitting criterion (Ragone et al., 2018). If R* is peak wind speed over a tropical cyclone's lifetime, R(x(t))= (minimum sea-level pressure in the eye) is a good splitting criterion (Webber et al., 2019).
But suppose that no good predictor exists. In particular, assume that the severity function R* of a simulation is the maximum over the event's timespan of a user-defined observable R(x(t)), such as the accumulated rainfall over a small region between t−1 day and t, which we generically call the intensity function. Assume further that no better predictor for R* is known besides R itself at the present time. In this case, a better choice of RES algorithm might be adaptive multilevel splitting (AMS; Cérou and Guyader, 2007), or more general versions such as “anticipated AMS” (Rolland, 2022) and “trying-early” AMS (TEAMS), which we previously introduced in Finkel and O'Gorman (2024) – itself a special case of subset simulation (Au and Beck, 2001) from engineering – in which every ensemble member runs to completion and produces an actual value of R*, not some proxy for it. Descendants are then spawned from the ancestor at some advance split time (AST) A before R* is achieved, to give them enough time to diversify and perhaps exceed their ancestor's severity, but not so much time to forget their ancestor's special initial conditions. Figure 1 illustrates this tradeoff when selecting AST in the context of a simple stochastic system, namely Langevin dynamics (Pavliotis, 2014) with a logarithmic potential which is specified in Appendix A, but the picture alone conveys the essential phenomenon of an optimal AST. The existence of a nontrivial (i.e., strictly positive) optimum is obvious when looking at isolated events, but its precise value is subtle to quantify when our purpose relates to climatological statistics, i.e., averages over many events.
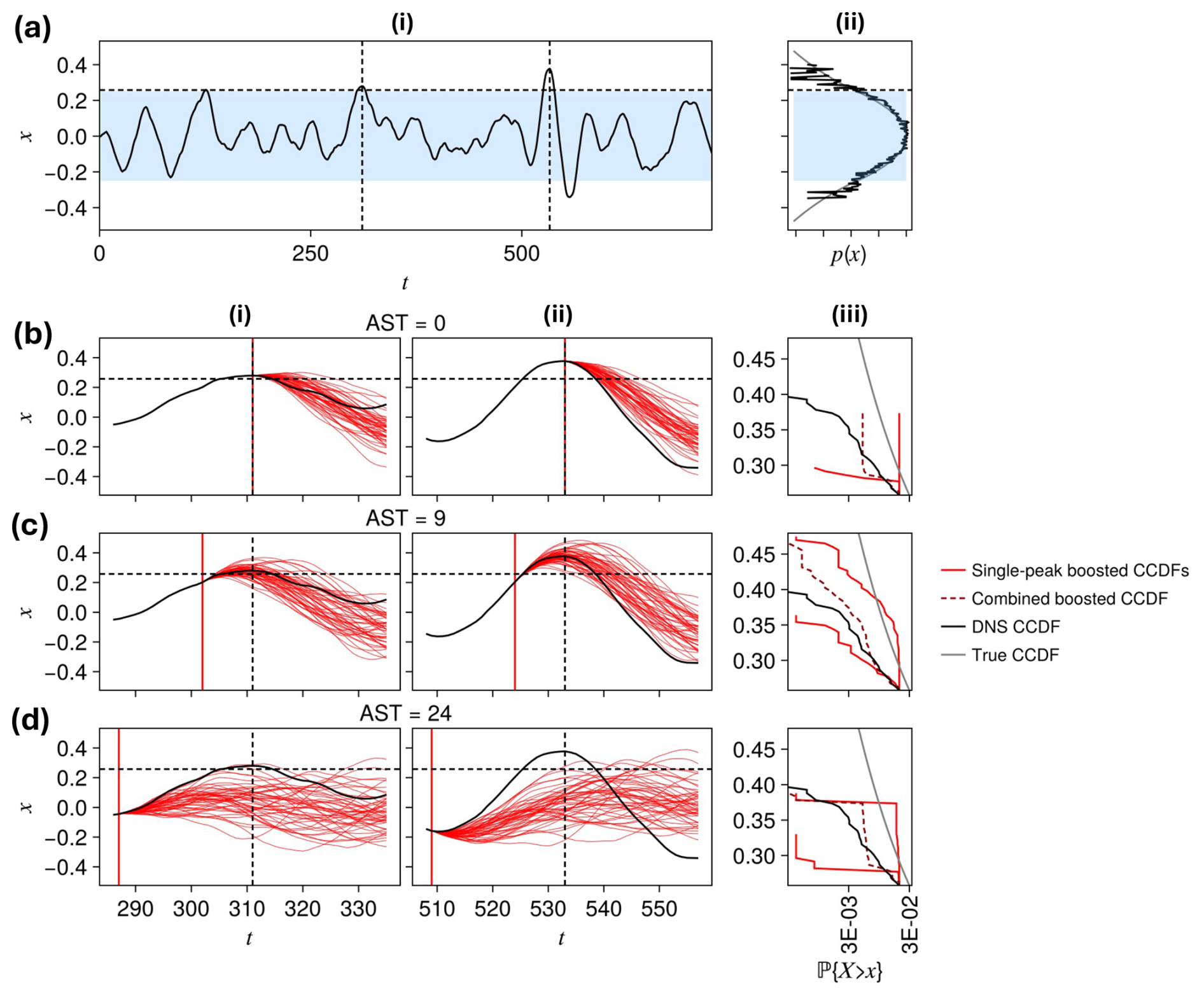
Figure 1Schematic summarizing the ensemble boosting and tail estimation procedure, using a simple Langevin dynamics with a potential that is quadratic for – the blue-shaded region in (a)- – and logarithmic outside this range. Appendix A specifies the system completely. The position variable X(t) exhibits intermittent, transient extremes (a.i) and power law tails (a.ii). We set a threshold for severity (horizontal black dashed line) at roughly the minimum probability estimable from a relatively short (duration 1600) timeseries (see the black empirical PDF in a.ii and the black empirical complementary CDFs (CCDFs) in (b, c, d).iii, as compared with the true PDF and CCDF in gray). We then identify the peaks over the threshold (marked by vertical black dashed lines in a.i), and perturb the simulation in advance of these peaks. Three choices of advance split time (AST) are shown in rows (b)–(d) marked by vertical red lines, each resulting in “boosted” peak ensembles, shown as red curves in (b–d).(i,ii) and summarized by CCDFs shown in light red in (b–d).(iii). Combining these conditional CCDFs together using the “MoCTail” estimator introduced later in Eq. (17) gives the dark red dashed line, which is meant to approximate the ground truth (gray line) better than the short DNS alone can do, including by going to higher values of x. The intermediate AST (c) is best among the three for this task, and our goal is to formulate and characterize this optimal AST more generally.
There is no general procedure for selecting AST and other hyperparameters, which impedes the application of RES methods to arbitrary target events and models. We have shown empirically in Finkel and O'Gorman (2024) the existence of an optimal AST – in the sense of accuracy of long return period estimates – that is roughly approximated by the time until of error saturation. But this result might be specific to the Lorenz-96 system and a number of choices made in Finkel and O'Gorman (2024), in particular relating to
-
The target variable defining intensity (energy density, , with site index k=0, though for Lorenz-96 all sites are statistically equivalent).
-
The spatial and temporal scale for averaging the target variable (we simply studied the instantaneous maximum at a single site, k=0).
-
The stochastic parameterization (smooth in space, white in time).
-
The metric in which to measure distances between ensemble members (Euclidean distance, ).
Practitioners working with models more complicated than Lorenz-96 face a vast menu of choices in all four domains, the first two falling under the purview of domain science and the last two falling under algorithm design. If the physical model or the choice of target variable changes, it stands to reason that the choice of metric should also change, and any single prescription of AST is unlikely to work for all cases. Indeed, in our recent application of TEAMS to extremes of temperature and daily precipitation in a general circulation model, we found that the rule provided some guidance but underestimated the optimal AST for both temperature and precipitation (Finkel and O'Gorman, 2026). Error norms incorporating global information will be less relevant than local norms around the target region, which tend to saturate more slowly (Finkel and O'Gorman, 2026).
Our primary goal in this study is to establish a general principle for optimizing AST for intermittent extreme events in meteorologically relevant dynamical systems. To balance computational economy with physical realism, we select a system of intermediate complexity between Lorenz-96 and a moist GCM: a 2-layer quasigeostrophic (QG) flow with a passive tracer. Since its original formulation in Phillips (1956), the 2-layer QG model has served as a useful paradigmatic minimal model for baroclinic instability and associated jets, waves, and vortices in the atmosphere and ocean. It has been augmented in many ways to study specific processes, for example by Lapeyre and Held (2004), who coupled in a moisture component and found the resulting precipitation and latent heating to strongly affect the balance between waves and vortices in the underlying flow. However, even the simpler addition of a passive tracer – one without feedback through latent heating – is enough to advance the algorithmic questions we pursue here. Passive tracer dynamics is physically interesting in its own right, as seen by many studies of intermittency and heavy-tailed tracer statistics in turbulent flows (Castaing et al., 1989; Gollub et al., 1991; Pumir et al., 1991). In climate science too, extremes of pollution concentration and temperature can be captured partially through passive tracer advection (Bourlioux and Majda, 2002; Neelin et al., 2010; Linz et al., 2020).
Our choice of the 2-layer QG model as a test system is thus a major upgrade in physical relevance as well as algorithmic difficulty from Lorenz-96, which resembles QG dynamics only loosely via its Hopf bifurcation structure (van Kekem and Sterk, 2018). This path up the model hierarchy has been trodden before by Qi and Majda (2016, 2018), who added passive tracers to Lorenz-96 and a QG model respectively and studied extreme fluctuations in the tracer's Fourier modes. Also, Gálfi et al. (2017) quantified extreme value statistics – including local and global statistics – of QG wind fields themselves. All these works have inspired and guided this one, but we focus distinctly on the link between short-time perturbation dynamics and long-term climate statistics.
The QG model has enough “space” to explore the effects of all four decision axes listed above on optimal AST. In principle, one can do this with an exhaustive suite of experiments: for every target region (location, size) and every version of stochastic input (e.g., perturbation magnitude and spatial scale) of interest, run TEAMS with a wide range of AST parameters, measure the skill of each AST in matching a reference ground truth distribution, and select the optimal AST. In practice, this exhaustive procedure is not feasible, in part because of the huge number of potential targets, but more fundamentally because TEAMS' performance is highly subject to randomness. Measuring the effect of any parameter change on the algorithm's performance requires many repetitions – several dozen at least – to average out the variability inherent in Monte Carlo. Moreover, other hyperparameters related to “population management” exist within TEAMS and other rare event algorithms: the number of initial ensemble members, how many of them to kill and clone at every iteration, and the termination criterion, to name a few. Randomness appears not only as physical forcing, but also in selecting which members to clone, thus interacting tightly with the population hyperparameters. One can think of this as confounding due to sampling bias, which further blurs the imprint of AST itself on performance.
So instead of using TEAMS for our investigation, we turn to a related method of ensemble boosting (Gessner et al., 2021; Fischer et al., 2023). The idea of ensemble boosting is simple: identify some extremes from an initial climatic timeseries, and re-simulate them with perturbed antecedent conditions to generate unrealized but physically plausible (and possibly more extreme) scenarios. By focusing on a limited set of ancestor events to boost, we avoid the additional randomness that occurs in TEAMS as the level is raised and additional ensemble members are stochastically added, which simplifies our investigation. In addition, Bloin-Wibe et al. (2025) has developed an approach to estimate probabilities based on the boosted ensembles, and we have also been developing such an estimator that is introduced below. With the addition of an ability to estimate probabilities, ensemble boosting may now be viewed as an RES algorithm.
We suspect that the optimal AST is closely related to a physically intrinsic quantity that is not particular to a given algorithm. Analogously to Lyapunov exponents, which encode the timescale for small perturbations to double, the optimal AST should encode the timescale for extreme values of some target variable to maximize in variability. This statement is heuristic, and a primary goal here is to propose some quantities that are very close to the optimal AST and that, like Lyapunov exponents, are intrinsic to the system and do not depend on arbitrary algorithmic choices. We propose and evaluate several candidates, including entropy and expected improvement: two functionals of ensemble distributions which are drawn from reinforcement learning.
We have three major contributions. First, we develop a new estimator for low probabilities of extreme fluctuations from boosted ensembles, similar to the estimator of Bloin-Wibe et al. (2025) but distinct in the aggregation step. Our approach includes an optional parametric fit of the response function to perturbations (applicable to both estimators), a simple quadratic regression model that imposes regularity on the resulting severity distribution. Second, we use the two estimators to measure the quality of a range of ASTs across a range of target events (tracer concentration at different target locations), finding evidence for an entropy-based optimality principle. Third, and most importantly from a practical perspective, we demonstrate that both estimators successfully approximate low probabilities when the ensembles are launched from a good AST, which the optimality principle can help to select efficiently. Our goal here is not to demonstrate a performant rare event algorithm – only to elucidate a necessary ingredient (AST) to be optimized in future algorithms – but even when comparing statistical errors at equal cost, we find (and report at the end of the analysis, in Fig. 13) that our boosted ensembles are already competitive with an equal-cost DNS.
The rest of the paper is organized as follows. Section 2 details the procedure of generating samples and estimating tail statistics, at a model-agnostic level, and proposes several candidate indicators of measuring ensemble dispersion that may help select an optimal AST. Section 3 specifies the QG system, its numerical simulation, and its extreme value statistics. Section 4 specifies the perturbed-ensemble design at a model-specific level. Section 5 visualizes some examples of perturbed events, and how the AST selection criteria behave on these examples. Section 6 reports the performance of different AST choices, and visualizes the overall “optimization landscape”. Section 7 concludes with an outlook and proposed roadmap for subsequent research – theoretical, algorithmic, and applied.
Our methodology can be separated into three parts, summarized here and expounded in three subsections. For a given target variable and location defining the extreme event, we
-
run a relatively short direct numerical simulation (“short DNS”), identify the extreme events within it, and generate a dataset of boosted ensembles for each event at a range of ASTs;
-
estimate tail distributions, conditional on the event and the AST;
-
combine the conditional tails into an unconditional (“climatological”) tail, using the estimators specified below, for a range of ASTs, and select the optimal AST based on the skill of the corresponding tail estimate in reproducing the tail of a “long DNS”.
We then display the results of applying this procedure to a range of target locations in the model flow domain.
2.1 Generating the dataset of boosted ensembles
There are many design choices in ensemble boosting (Gessner et al., 2021): how to select extreme events to boost, how many boosts to generate, when to launch them, etc. This subsection details the choices used here.
We run a direct numerical simulation (“short DNS”) , long enough to generate some extremes but not enough to estimate probabilities smaller than for a relative error tolerance of ϵ=0.1. The premise of RES, and ensemble boosting, is that the extremes it does generate might have been even worse, perhaps just a butterfly flap away from the more intense extremes one would see with a “long DNS” of duration Tlong≫Tshort. We generate such a long DNS as well to serve as a ground-truth for validation. Following the ensemble boosting methodology laid out in Gessner et al. (2021); Gessner (2022) Fischer et al. (2023) and Noyelle (2024), we first identify a threshold μ with exceedance probability q(μ) that is moderate enough to estimate precisely with the short DNS. In other words, μ is the [1−q(μ)]th quantile, or “q(μ)th complementary quantile”. Equivalently, q(μ) is the complementary cumulative density function (CCDF) of the random variable R, evaluated at μ. In line with the peaks-over-threshold procedure (Coles, 2001), we take cluster maxima of exceedances above μ as the “ancestral” extreme events. Concretely, a cluster maximum is a state from the DNS, , such that
where Amax and B are buffer times longer than the mixing timescale of the dynamics (i.e., how long two perturbed simulations need to become independent), ensuring that two consecutive events are genuinely independent from each other. Amax is an upper bound on the ASTs used for boosting.
We collect all such peaks occurring in the short DNS,
and for a sequence of increasing ASTs , …, J} bounded between 0 and Amax, launch an ensemble of descendants , …, Mn,j} by applying Mn,j different perturbations to the DNS at time , and running each simulation to time . Note that Mn,j could in principle vary between ancestors n and lead times j, which is not needed for our exhaustive sweeps in this paper, but certainly would be needed in an “online” rare event sampling procedure that iteratively homes in on a subset of the most extreme-ogenic ancestors {n} and ASTs {j} to draw more samples from.
A bit more notation helps clarify how the perturbing is done, abstractly at first and concretely in Sect. 3 when we specialize to the QG system. For each (n, j, m), we draw a random sample from some sample space Ω. Denoting by the flow map that integrates the perturbed dynamics forward by a time interval Δt, the (n, j, m)th descendant's trajectory through state space ℝd can be written
In words, the descendant shares its ancestor's past up until the time of perturbation , after which it diverges.
There are two main forms of commonly used perturbation. An impulsive perturbation is a kick applied at a single time (which is used in ensemble boosting), in which case Ω=ℝk or ℂk, typically with k≪d, and a sample ω is transformed to spate space via a function (e.g., a low-rank matrix multiplication). Then, the perturbed dynamics can be written , where ΦΔt with only one argument is the unperturbed dynamics. We also use the convention that G(0)=0, i.e., ω=0 corresponds to no perturbation.
The other common case is where x(t) is a stochastic process, e.g., an Itô diffusion forced by white noise, as we used in Finkel and O'Gorman (2024) as well as the schematic in Fig. 1. In that case, ω is a white noise process sampled at discrete times, whose dimensionality scales with the number of timesteps. In the QG experiments, we adhere to impulsive perturbations for three reasons: it introduces fewer arbitrary parameters, it is less disruptive to the system's intrinsic dynamics, and it keeps the dimensionality of the random space low. If, as we conjecture, even low-dimensional butterfly flaps are sufficient to excite the more extreme fluctuations, it would make deterministic search methods – which should always be preferred over Monte Carlo – more viable.
Following the perturbation, the descendant drifts away from the parent and achieves its own severity R* (peak of its intensity function R) at some time possibly different from its ancestor's peak time :
where the latter notation emphasizes dependence on ω, while recognizing that each (n, j) induces a different severity function R* because perturbations may be felt differently depending on the initial condition.
If the perturbation is small, the descendant's peak time will be close to the ancestor's peak time . However, if the intensity function R(x(t)) tends to oscillate, e.g., with each passing Rossby wave crest, a large-enough perturbation might cause the next wave crest after to outgrow the original peak, misappropriating the imposed perturbation to fuel a different event than the original target. Tersely, might be a discontinuous function of ω, and R*(ω) a non-differentiable function of ω, which is a nuisance for our goal to optimize over ω and, more importantly, complicates the causal chain between perturbation and response. We explicitly prohibit this behavior by restricting the range of as follows.
-
Set an “argmax drift” parameter δt* based on physical timescales, e.g., half an oscillation period. Initially set .
-
If is a local maximum in R, then do not change it.
-
Otherwise, shift backward (if at the beginning of the interval) or forward (if at the end of the interval) until it is at a local maximum.
Although it is ad-hoc, this adjustment aims to uphold the core idea of ensemble boosting to augment existing events, while preserving their basic identity, rather than discover totally new events – which may as well be done by extending the DNS. In general this is a nontrivial condition to impose, as multiple spikes in a sequence may be dynamically correlated to each other, but we use only this simple strategy as demonstration.
2.2 Estimating conditional and climatological probabilities from boosted ensembles
Assume now there is a probability measure ℙΩ on Ω with associated density function pΩ(ω), which might for example place higher weight on smaller kicks. The Ω superscript will generally relate to statistics over this conditional probability measure, to distinguish it from long-term climatological statistics. A major aim of this paper is to show how they relate to each other. Each ensemble of descendants at each lead time gives rise to its own conditional severity distribution:
which can be estimated from the samples , …, Mn,j}. Here conditional means starting with a perturbation of the nth ancestor's particular initial condition at time and running forward until time . By contrast, we refer to the climatological severity distribution as that resulting from a long DNS.
Integrals of the form (Eq. 5) arise in many diverse risk analysis tasks, such as reliability engineering, where Ω often represents wind, waves, or tremors buffeting a built structure (Au and Beck, 2001; Mohamad and Sapsis, 2018), and is therefore high-dimensional. The default strategy for high-dimensional sampling is vanilla Monte Carlo, whose infamously slow convergence has motivated more efficient workarounds. A particular class of “variational” (Dematteis et al., 2019; Tong et al., 2021) and “first- and second-order reliability” methods (Breitung, 2021) approximate the sampling by constrained optimization, relying on the large-deviation principle that increasingly rare events have a shrinking space of possible pathways, concentrating around a single point of Ω. We could certainly make use of those methods here, but there is a crucial distinction: in our setting, the perturbation space is an arbitrary design choice aiming at an indirect goal (climate estimation), rather than some externally imposed distribution (e.g., a Gaussian process model for ocean bathymetry in Dematteis et al., 2019 and Tong et al., 2021). Therefore, nothing stops us here from deliberately choosing low-dimensional perturbations instead of high-dimensional ones as in Ragone et al. (2018) and Bloin-Wibe et al. (2025). This enables numerical quadrature instead of Monte Carlo or elaborate large-deviation approaches, and saves on cost by allowing sample re-use across different input distributions.
It is possible that higher-dimensional spaces are more effective for exciting extreme fluctuations, which would make the above-cited methodologies very useful for our purpose in future research. They can also be useful when conditional risk estimation (for near-term weather forecasting) is the end goal, as well as the previously-mentioned optimization methods demonstrated in Farazmand and Sapsis (2017), Blonigan et al. (2019), and Whittaker and Luca (2025). But our first goal is to determine whether our chosen low-dimensional kicks can suffice for climatological estimation.
Based on the samples drawn from Ω, we fit a regression model with parameters θ, in our case coefficients for linear and quadratic polynomials. In general could be a more elaborate parametric model, e.g., a Gaussian process or neural network with learned weights θ, as often used in modern uncertainty quantification (Kabir et al., 2018; Sapsis, 2020; Pickering et al., 2022). Then the integral over Ω can be estimated, either analytically (if p and take simple enough forms) or numerically by densely filling Ω with a grid of points, evaluating and p at each point, and taking the inner product of with p for any r. The result is an estimate for the conditional CCDF, , obtained by replacing the with in Eq. (5). The final step is to estimate the tail of the conditional CCDF,
which we could do just by putting hats on the Qs on the right-hand side. However, this risks dividing by zero, because the fitted function may imply zero probability of exceeding the threshold, particularly at long ASTs when descendants have enough time to decorrelate totally with their ancestor. This loss of ancestral “wisdom” is a more fundamental problem than the numerical issue of zero denominator, and we address it by implementing a continuous version of the “accept-reject” step of the TEAMS procedure in Finkel and O'Gorman (2024). Wherever the descendant severity falls below μ, we replace it with the ancestor severity, denoted (with no second subscript):
( when since is decreasing, hence the two terms in the last expression correspond to the two cases).
This estimator can be extended to other expectations of interest conditional on the target variable being extreme. Denote by a generic function of the trajectory Xn,j launched at AST Aj ahead of ancestor n, such as time-averaged wind speed or air temperature. It is actually a random variable (a function of ω, Φn,j(ω)) and its mean can be estimated by replacing each with Φ(ω) to obtain
The first term collects statistics of the part of the W-disc that contributes to the tail , and the second term just moves the remaining (“rejected”) probability mass back onto the ancestor at ω=0. We do not explore the properties of this estimator for different Φs, but note it could be important to an applied study with RES.
Another heuristic way to justify the accept-reject expression for in Eq. (10) is to stipulate that we care about approximating only the extreme part of the boosting distribution, i.e., those ωs near enough to 0 that , excluding the descendants bound to fall below μ. We re-allocate the probability mass in the “non-extreme” region of the disc (where ) to the very center of the disc (the ancestor, where by construction). This rearrangement ensures that is close to 1, justifying a Taylor series expansion in
The crux of our hypothesis is that these conditional distributions from boosting can be aggregated across ancestors to approximate the climatological distribution , where Θ is used to denote the ground truth that would be obtained from a long DNS. We specifically propose to aggregate the conditional CCDFs as a uniform mixture over ancestors, selecting one representative AST from each ancestor n to best represent its alternate realities according to some selection rule (different rules will be evaluated thoroughly for the QG system in Sect. 6). We write the mixture as
and call it the “MoCTail” estimator of QΘ(r,μ), for “Mixture of Conditional Tails”.
The recent works Noyelle (2024) and Bloin-Wibe et al. (2025) formulate a different estimator, which makes for an interesting comparison. Rather than summing Nshort tail CCDFs, each approximating a ratio of the form (Eq. 6), they construct a single ratio by summing Nshort numerators and Nshort denominators. Translated into our own notation, this becomes
We call this the “PoPTail” estimator of QΘ(r,μ), for “Pool of Perturbed Tails”. Bloin-Wibe et al. (2025) do not model R*(ω) parametrically, but instead use a standard Monte Carlo estimate (fraction of descendants exceeding r), which is probably necessary for their high-dimensional perturbations. However, we can convert the PoPTail estimator to our parametric version just by thinking in terms of CCDFs, hence the formulation in Eq. (18). The more important difference is that PoPTail avoids the potential degeneracy by “pooling” non-extreme descendants together with extreme ones in the denominator.
One could argue for either estimator based on the validity of its underlying assumptions which are challenging to rigorously verify. Here we adopt a more openly empirical perspective in testing the skill of both.
An important advantage of both estimators is extensibility with respect to the dataset: if the variance is too high, one can always either generate new ancestors by extending the short DNS, or extend the range of ASTs sampled, or enlarge the ensemble at any ASTs deemed promising, without discarding the laborious samples already generated. This is unfortunately not the case with an algorithm like AMS, TEAMS, GKTL, or QDMC: because of the random rules by which ancestors are selected and new members generated, a completed run cannot be enlarged while retaining its estimation properties unless we are willing to do an entirely new additional run and combine estimates from multiple runs as was done in Ragone et al. (2018), Webber et al. (2019) and Finkel and O'Gorman (2024). This results in waste during the fine-tuning process of calibrating TEAMS. For example, one might decide in retrospect that a TEAMS run was too aggressive in killing non-extreme simulations and raising the threshold and we cannot easily extend the run with a new set of hyperparameters. With boosting, we can simply go back, perturb those less-extreme simulations, and incorporate them into the dataset, without needing to re-generate everything. To make boosting competitive at sampling the highest levels of severity, we suspect it will be necessary to augment our current scheme with an iterative level-raising schedule, like TEAMS, but with less restriction on the sampling procedure.
2.3 Evaluating performance: statistical accuracy and computational cost
We evaluate the MoCTail and PoPTail estimators and by comparing to the ground truth QΘ as estimated from a long DNS. DNS is in fact a trivial special case of ensemble boosting with M=0 (no descendants), reducing each summand of Eq. (17) and the numerator of Eq. (18) to and the denominator of Eq. (18) to Nshort. Both estimators reduce to the same vanilla empirical CCDF in this case, and this is what we use to estimate QΘ.
We use χ2-divergence to measure the disparity of and from QΘ. This is estimated from a discrete histogram with a sequence of thresholds , and define the probability mass function as the probability contained in the kth bin (note that and so ). As described further in Sect. 3.3, we select the rks as quantiles with consecutively halving exceedance probabilities, i.e., for . These quantiles change with latitude, as the tail is different for each. Note the same set of rk's based on the climatological distribution is used also for evaluating estimated distributions. The χ2-divergence of either estimator is then defined as
We will compute both the MoCTail and PoPTail estimates on the same dataset, and find them numerically quite similar, both in terms of skill and in terms of individual bin estimates. It would be interesting to develop test cases where they differ more systematically, to clarify which (if either) is generally superior.
Computational efficiency is another important consideration besides accuracy, as the entire goal of rare event algorithms is to improve efficiency or accuracy (or both) relative to DNS. For a boosting-like rare event algorithm to be useful, its error should decrease faster by perturbing existing ancestors (increasing M) than by extending DNS by generating new ancestors (increasing N and not M), at least in some range of N that samples the attractor broadly but not exhaustively. However, this paper does not present a complete rare event algorithm per se, in the sense we do not yet stake our claim on a speedup. Rather, we ask a pre-requisite question: does increasing M decrease the error at all? Clearly boosting can increase the maximum severity, but that could happen in ways that do not respect the tail CCDF's shape, e.g., if perturbations tend to maximize the event's severity while bypassing moderate severities that carry significant statistical weight.
We will thus make two comparisons between boosting and DNS: accuracy at fixed N, and accuracy at fixed cost (where DNS runs an additional length equal to the cost of simulating descendants, allocating its full budget to “exploration” rather than “exploitation”). Specifically, we approximate the cost of the boosting approach for a given AST A as
where δt*, the “argmax drift” parameter, accounts for the extra time needed to run after the ancestor's peak to account for changes in peak timing. “Mean return period” is the average time between consecutive independent peaks over the threshold μ, which will be longer than because of de-clustering. The dependence on A is a complication, as each AST tried would merit a different-length DNS for cost comparison, and we do not want to penalize boosting too severely by summing over all ASTs because in practice we would not bother simulating the obviously sub-optimal ASTs. Rather, we optimistically estimate the cost if A is already known. On the other hand, our chosen M(=21) is likely more samples than necessary to fit a satisfactory parametric model, as we have deliberately sampled the perturbation space more generously than we would if chasing a speedup. We simplify the comparison by fixing A to in Eq. (20), which is close to or slightly greater than the optimal values that we found empirically.
We will show (Fig. 13b) that boosting is unambiguously more accurate than DNS when fixing the number of ancestors N, and similarly accurate with marginal improvements when fixing cost, though with variation across latitudes and AST criteria. Thus, we do achieve some speedup, even though it is not (yet) our main objective. Any fixed-cost performance gains we achieve here (not our main objective) should be viewed as a lower bound for future algorithms, which will benefit from the conceptual insights into AST that we glean presently.
To emphasize the conditional nature of the AST – its possible dependence on the ancestor n due to initial condition-dependent predictability – we refer to as the “conditional advance split time” (CAST), and its optimal value (by χ2 or other criteria) as the “conditionally optimal advance split time” (COAST). Our goal is to define the COAST, calculate it given extensive sampling from boosted ensembles, and finally to suggest useful criteria to estimate it when sample size is limited, as in a real rare event algorithm deployment.
2.4 AST selection criteria
With a data-generating plan and an estimator in place, we return to our central question of interest: how to select the CASTs ? There are three natural kinds of criteria.
-
Choose a single uniform AST for all ancestors (“U” for “uniform”). In this case, the CAST is not really “conditional” at all. In Finkel and O'Gorman (2024), we found the COAST for TEAMS by systematic grid search through candidate ASTs, and found post-hoc an empirical relationship for the COAST: , where tϵ(x0) is the time until an ensemble dispersing from initial condition x0 (each member forced by a different noise realization) reaches a fraction ϵ of its asymptotic root-mean-squared-error (RMSE), and is the average of tϵ(x0) over different initial conditions x0. In Finkel and O'Gorman (2024), we sampled x0 from the stationary distribution; here, for computational expediency, we will repurpose the boosting ensembles for estimating , i.e., sampling x0 from pre-peak antecedent conditions.
-
Choose the CAST An separately for each ancestor n such that that an ensemble launched at disperses to a pre-defined threshold at time . One could measure dispersal in different ways like RMSE, but here we opt instead for a pattern correlation, defined with respect to spatiotemporal fields F0 (from the ancestor) and Fm (from the mth ensemble member) as
Unless noted otherwise, ρ will refer to the average of ρ[F0,Fm] over all members m=1, …, M. The reason for subtracting time-averages is to fairly weight spatial regions with smaller background 〈F〉, e.g., poles if F is temperature. Dividing by spatial standard deviations is simply a useful normalization that restricts ρ to the range [−1, 1] by the Cauchy-Schwarz inequality. ρ ends to decrease over time from 1 to 0 except for occasional negative values when F0 and F1 are similar up to translation (but this effect usually disappears when averaging large-enough ensembles). We then choose some threshold , and select the corresponding CAST – a function of the threshold—as the smallest sampled AST An for which ρ creases from 1 to ρPC between the split time and the peak time . (PC stands for “pattern correlation”.) Note that the CAST varies with n, but the correlation threshold, denoted ρU, is uniform. Finding the COASTs then boils down to finding the optimal value of ρU.
The rule from Finkel and O'Gorman (2024), which used Euclidean distance as the dispersion indicator, can be approximately restated in terms of pattern correlation:
(The approximation invoked in the second-to-last step, , will hold when the spatial region is large enough that global fluctuations in the same direction are unlikely.) This calculation shows that the time until RMSE reaches of its saturation value is roughly equivalent to the time at which pattern correlation drops to . We do not assume this threshold is optimal, but include it as a reference for comparison. And we stress that the rule implemented in Finkel and O'Gorman (2024) determines a uniform AU, not a conditional APC, because their averaging was performed over the attractor, whereas here we will use ρ as an initial condition-specific diagnostic.
-
Define the CAST as the solution to an optimization problem, where we seek to maximize a functional on the boosted severity distribution that favors both a high mean and high variability of the severity. This would implicitly favor intermediate ASTs, as short-AST ensembles have high mean but low variability while long-AST ensembles will have high variability but low mean (approaching the climatological distribution). We propose and evaluate two such functionals in this paper:
- a.
Expected improvement (EI):
where and we recall that ω=0 means no perturbation (i.e., the ancestor)
- b.
Thresholded entropy (TE):
where the bin boundaries rk start at μ, and so only the tail part of the conditional CCDF contributes. The thresholded entropy is thus defined based on probability over discrete bins (with the bin boundaries rk set based on quantiles of the ground-truth distribution) and would change if the bins were changed.
Where it does not cause confusion, we will also call the CASTs AEI and ATE themselves COASTs because they optimize something, although it is something different than χ2. We conjecture that that these two notions of optimality coincide: if each ancestor separately optimizes I or TE, the resulting aggregate of distributions (via MoCTail or PoPTail estimators) will minimize χ2-divergence from the true climatological tail. Our results will approximately confirm the conjecture in the case of TE.
- a.
These criteria are each in turn more complex, but also more theoretically appealing. The correlation-based CASTs , unlike the synchronized AST AU, can vary with n to respect differences in predictability between different initial conditions, a well-recognized phenomenon in chaotic systems (Maiocchi et al., 2024), including the atmosphere (Lucarini and Gritsun, 2020). Still, both AU and require the user to set some arbitrary global threshold. The open question is whether optimizing or individually for each n will also optimize the accuracy of the unconditional (MoCTail) climatological CCDF estimator against the ground truth climatological CCDF from a long DNS.
Main result: climatological tails are estimated more accurately with perturbed ensembles than with un-perturbed ancestors alone (fixed-N comparison between DNS and boosting). This holds with few exceptions for both MoCTail and PoPTail estimators, for all COAST selection rules, and for all target spatial locations. At fixed cost, boosting and DNS are tied overall, but with some variation across latitudes and the value that cost is fixed to, suggesting that substantial speedups are possible with more highly optimized boosting-like algorithms. No single selection rule is superior across the board. The EI and TE criteria, however, have a distinct advantage of needing no arbitrary threshold choices. TE-based estimates strike a reasonable compromise between statistical error and arbitrariness, which is strong enough support that we recommend TE as a generic AST selection rule.
The remainder of the paper demonstrates the theoretical framework above on the QG system. Section 3 specifies the dynamical model and its numerical simulation, displays some representative output, defines the target intensity functions of interest, and reports on their basic tail statistics. Section 4 specifies the perturbation protocol (i.e., the space Ω and probability densities pΩ(ω)) and visualizes representative examples of the system's response, providing motivation for our choices of AST selection criteria. Section 6 compares the performances of all proposed AST selection criteria criteria in matching the climatological tail CCDF. Section 7 concludes with a summary and outlook on important future lines of work.
Throughout, we present more in-depth results for one select target latitudes just south of the domain center, and only summarize for the wider range of target latitudes, which reveals large-scale variations in extreme event predictability and representability across space.
The model setup aims to distill some challenges we have encountered with rare event algorithms. We first recognized the need for advance splitting (or “trying early”) to sample extreme precipitation in an aquaplanet GCM (Finkel and O'Gorman, 2026). A minimal surrogate model replicating this challenge was found in Lorenz-96 (Lorenz and Emanuel, 1998), which provided a testbed for the first working version of TEAMS and a recognition of an “optimal advance split time” (Finkel and O'Gorman, 2024). There is a huge gap in model complexity between Lorenz-96 and the GCM (see Table 1), and we wish to test our idea in this middle ground where the target spatial location can have an effect. Lorenz-96, with a one-dimensional domain and homogeneous forcing, is too simple. For this reason, and to make closer contact with physics, we selected the two-layer QG model as a suitable intermediate between Lorenz-96 and the GCM.
Table 1Three rungs on the model hierarchy. Left: the Lorenz-96 system used in Finkel and O'Gorman (2024) has a one-dimensional spatial domain (“longitude”) divided into discrete sites k=0, …, 39, on which generic meteorological variables {xk} evolve in time. Its state space dimension is 40. Right: the aquaplanet model used in Finkel and O'Gorman (2026) has a three-dimensional spatial domain: latitude λ, longitude ϕ, and pressure normalized by its surface value, . It has six prognostic fields: zonal wind u, meridioal wind v, temperature T, and humidity q vary in all three dimensions, whereas surface pressure ps and precipitation rate R vary only in the horizontal. Center: the 2-layer quasigeostrophic model used in this study has two layers () of two dimensions each (longitude x, latitude y), and two dynamical fields: streamfunction ψ which is discretized spectrally, and tracer concentration c which is discretized on a grid.
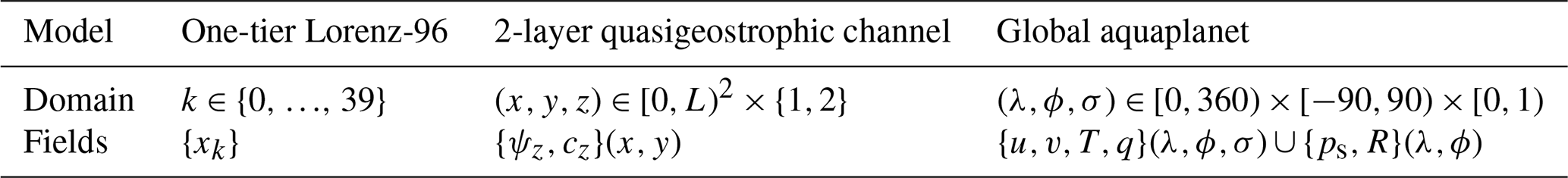
3.1 Equations of motion and numerical simulation
We implement a version of the QG model combining elements of several classic studies. Our numerical method and friction form follow Haidvogel and Held (1980), but on a smaller domain with weaker friction magnitude as in Panetta (1993) to contain only 1–2 more energetic zonal jets. We furthermore add bottom topography in the lower layer as in Thompson (2010) to fix preferred latitudes for jets while still allowing them to temporarily split, merge, and meander. Thus climate statistics, and hence the COAST itself, can vary with latitude. Further, we augment the system with a passive tracer to represent a key component of precipitation dynamics, following the spirit of Bourlioux and Majda (2002) and Qi and Majda (2016, 2018) who used turbulent advection-diffusion as a paradigm for intermittency.
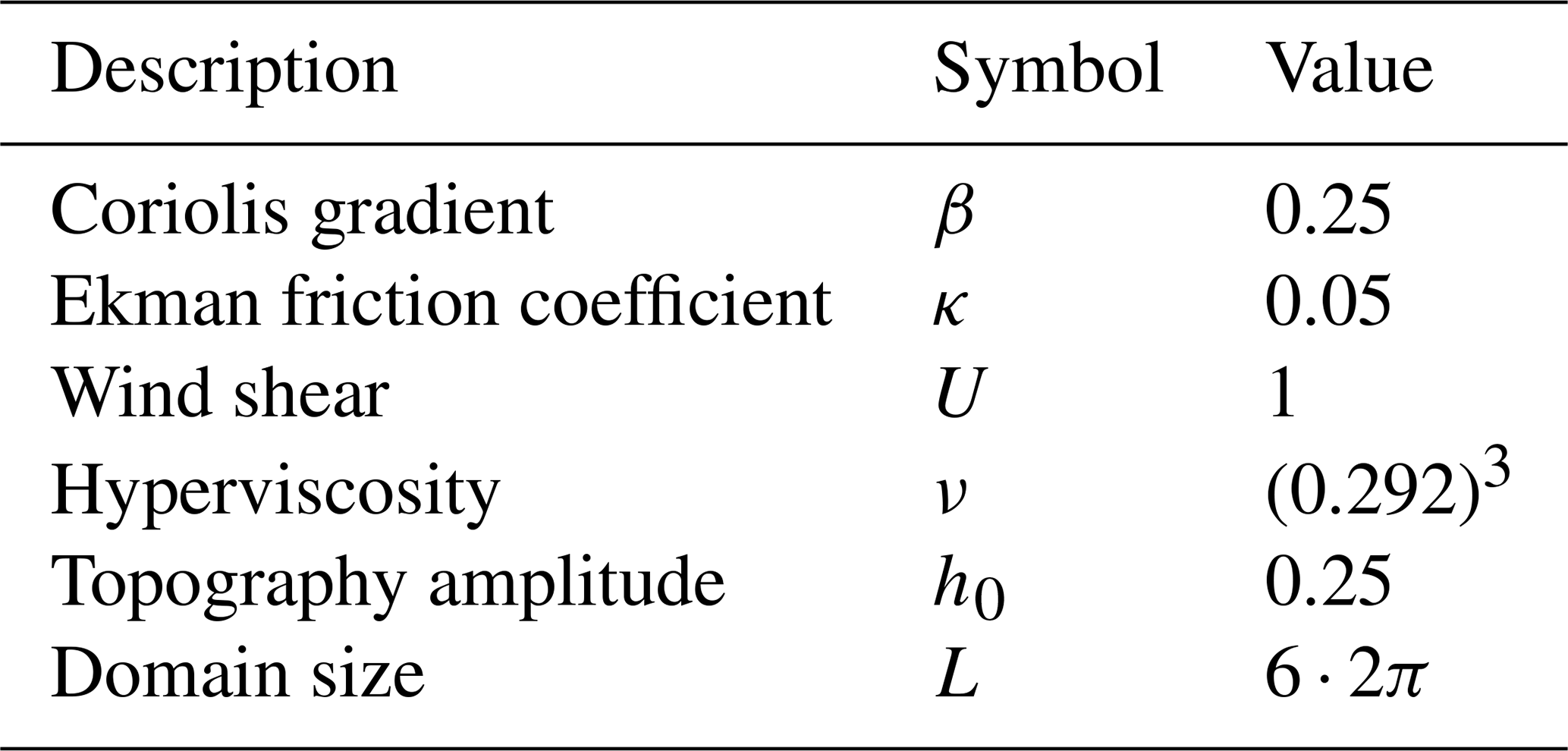
The model equations are as follows, in non-dimensionalized form using the deformation radius λ as the length scale and a velocity scale 𝒰. To make plain the role of the background shear, we define a non-dimensional wind U as the ratio between the imposed upper-level zonal wind and 𝒰. All non-dimensional parameter values are listed in Table 2. The horizontal coordinates (x, y) each run from 0 to L. The integer-valued vertical coordinate z is an index for the layer (1 for the top and 2 for the bottom, appearing as a subscript). ψ represents the streamfunction minus a background of . h is the bottom topography which is specified to vary sinusoidally with wavenumber 2 in latitude. q represents potential vorticity minus a background of , due to planetary vorticity gradient and topography. c represents the passive tracer field.
For ψ, we impose doubly periodic boundary conditions and timestep with a pseudo-spectral method with 64 Fourier modes in each dimension and standard -dealiasing (hence, an effective maximum wavenumber of 20). We time-step linear terms with the trapezoid rule (Crank–Nicolson) and nonlinear and topographic terms with a predictor-corrector (Heun's) method. Meanwhile, boundary conditions on c are periodic in x and Dirichlet in y, with values (0, 1) at . Together with a first-order upwind monotone finite-volume scheme, this setup guarantees that everywhere, making clear that its probability distribution has compact support. Note there is no explicit dissipation for c, but the low-order discretization creates some effective diffusivity.
Table 2Non-dimensional physical parameters used for the numerical simulation, similar to those chosen in Panetta (1993).
The number of degrees of freedom, or state space dimension, is
and we will sometimes refer to the full state vector as – not to be confused with the spatial coordinate x. For simplicity, we refer to one time unit as a day, which is of an eddy turnover timescale (see Fig. 3). The common timestep for ψ and c is 0.025 d, and the output frequency is once per day. The spatiotemporal resolution is coarse by modern standards, but we are not seeking to calculate any real-world physical quantity: we are seeking a general rule that will help make the COAST clear for a wide class of models.
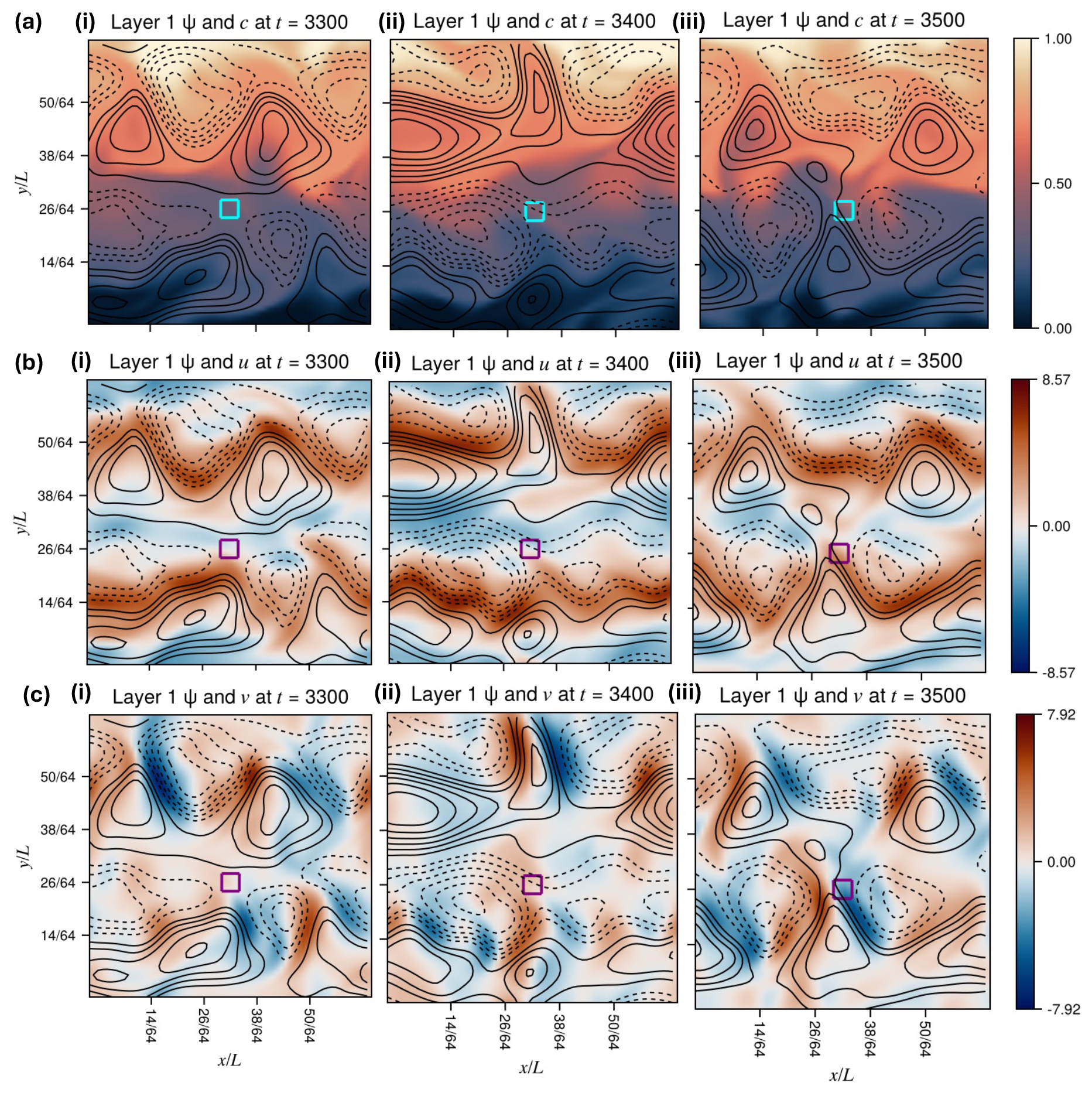
Figure 2Snapshots of the QG system configuration in the upper layer. Contours indicate the anomaly streamfunction ψ, which varies over a non-dimensional range of approximately ±18, dashed contours indicating negative anomalies. Colors indicate (a) tracer concentration c, (b) zonal wind velocity , where U=1 is the basic background shear, and (c) meridional velocity . The timestamps increase from left to right, and come from the long DNS. The small square represents an example target region in which to sample extremes of the local tracer concentration, in this case centered at and extending in both meridional and zonal directions. This same region is the target used in the following results, and we consistently refer to the domain coordinates in fractions of 64 across all figures.
3.2 Baseline simulation and statistics
We run a “short DNS” of length d ≈11 years (after a 500 d spinup) to supply the pool of initially un-perturbed (“ancestral”) events. Then, to provide “ground truth” statistics, we run a control simulation, or “long DNS”, of duration years, which is O(1600) eddy turnover times and O(160) jet meandering times (see Fig. 3 caption for timescale definitions). However, in estimating climatological statistics from the long DNS, we take advantage of statistical zonal symmetry by concatenating the timeseries of all 64 longitudes, increasing the effective sample size by a factor of (some typical correlation length). Conceptually, the short and long DNS are analogous to “training” and “validation” datasets in standard machine learning procedures, in the sense that we want to infer properties of the validation set using only information extracted from the training set (for example, by perturbing and re-simulating events seen in training). As we show below, simply counting events from the short DNS gives probability estimates that deterioriate at high levels of severity, which we aim to rectify with boosting.
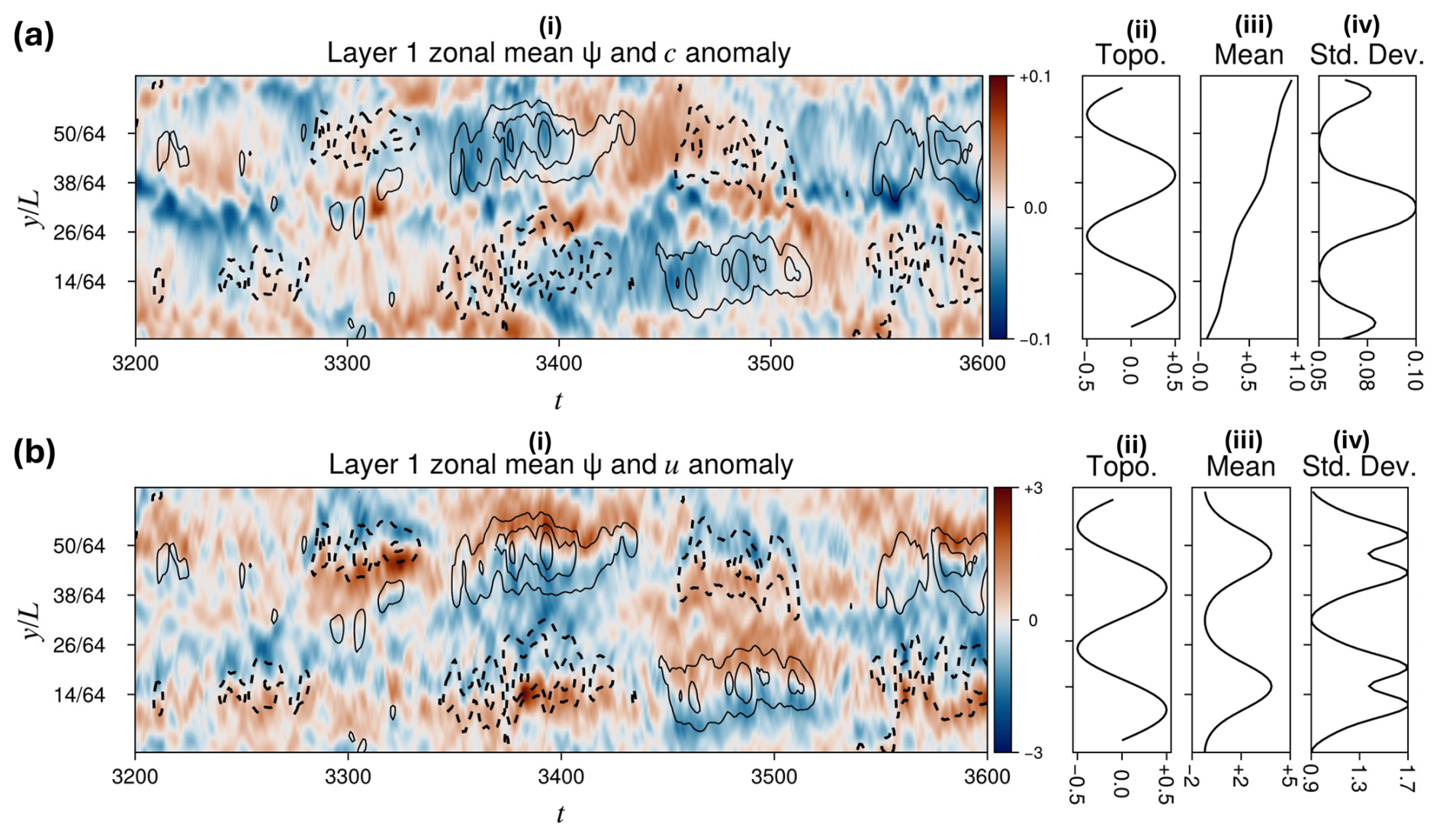
Figure 3Hovmöller diagrams of anomalies (departures from time-means) of zonal-mean concentration (a.i) and zonal-mean zonal wind (b.i). Contours indicate zonal-mean streamfunction anomaly (range ±10, negatives values dashed). Column (ii) shows bottom topography, which directly affects the lower layer only, but indirectly sets the preferred jet positions in the upper layer as well. For the same quantities, column (iii) shows the zonal and time mean and column (iv) shows the zonal mean of the temporal standard deviation. The Hovmöller diagrams give context to the snapshots of u from Fig. 2b, which come from times (i) 3300, when the upper and lower jets are both shifted south; (ii) 3400, when the jets are unusually far apart; and (iii) 3500, when the jets are unusually close together. These intermittent, discrete shifts in jet location happen every ∼100 d, which we call the “jet meandering timescale”. During a typical 100 d timespan of stationary jet, the fields oscillate roughly 10 times (not shown here; see Fig. 7); hence we assign the eddy turnover timescale a nominal value of 10 d.
Figure 2 shows representative snapshots of three dynamical fields in the upper layer from the long DNS: tracer concentration c, zonal velocity , and meridional velocity . Figure 3 shows Hovmöller diagrams of zonal-mean anomalies of c and u (not v, since zonal-mean meridional velocity is zero), as well as their climatological means and standard deviations plotted alongside the topography. These are statistics of the grid-cell values, not zonal means, but depend only on latitude because so does topography. Two eastward jets are prominent in the snapshots Fig. 2b and in the zonal mean profile Fig. 3b.iii, with preferred latitudes of and . The Hovmöller diagram gives a sense of characteristic timescales: jets tend to remain roughly stationary for stretches of ∼100 d at a time before shifting, as seen by the group of closed contours of ψ and associated dipole of u centered at time t=3400. and persisting ±50 d to either side. Within these stretches of quasi-stationarity, there are shorter undulations of duration ∼10, which we identify as the eddy turnover timescale.
The tracer statistics (Fig. 3a.iii and iv) have some easily explainable large-scale patterns and some subtler small-scale patterns. The tracer time-mean 〈c〉(y) increases linearly overall as , in keeping with its Dirichlet boundary conditions. However, in the central region of the domain (inside the weak westward jet) the tracer mean varies more rapidly with latitude and has a larger standard deviation (see also dashed curves in Fig. 4b and c).
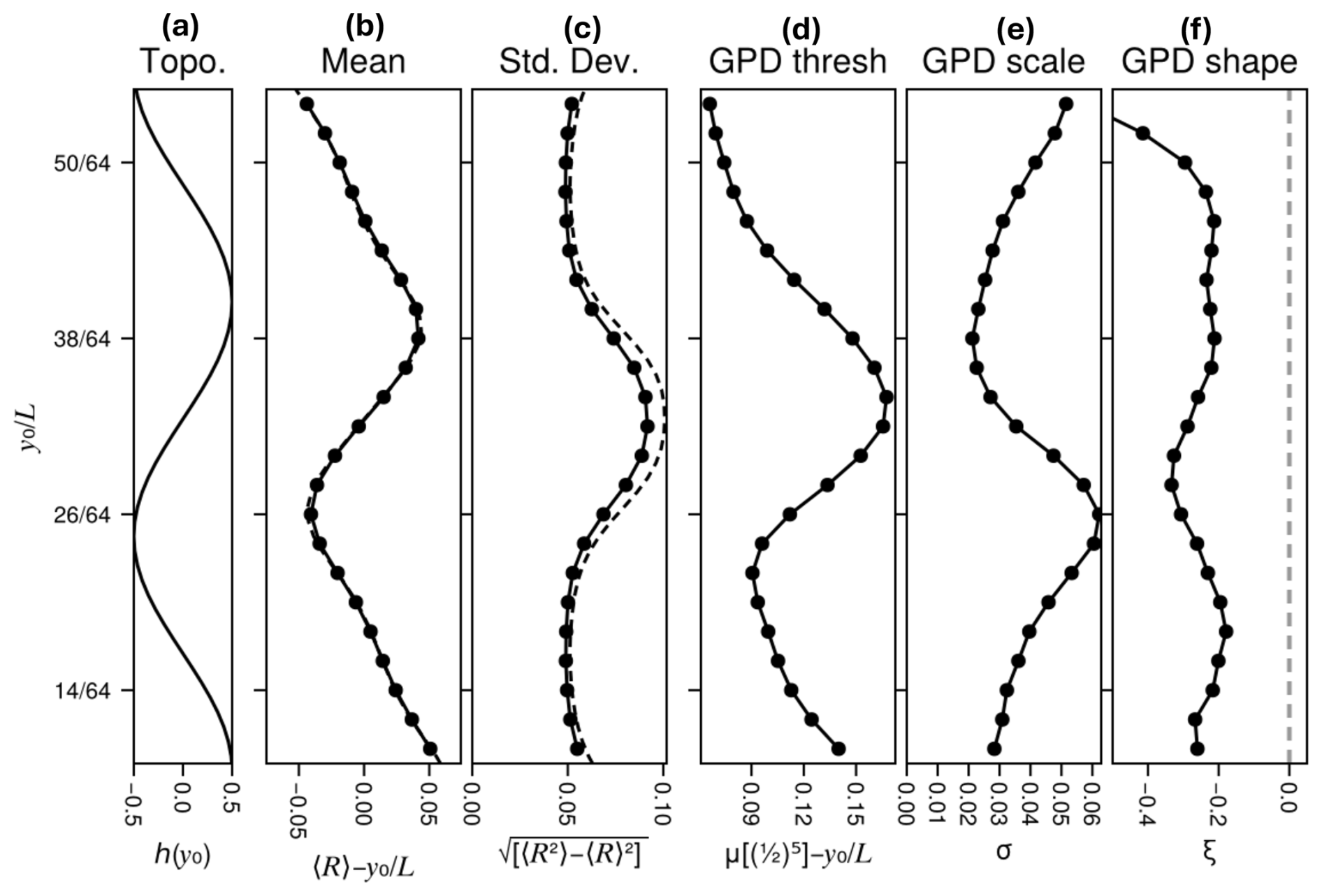
Figure 4Summary statistics of latitude-dependent climatological tail distributions of local tracer concentrations, also called “intensities”, which are denoted R and defined as the average concentration c over a box . and are fixed, while y0 varies across the midlatitudes from to . Panel (a) shows the lower-layer topography in this same range of middle latitudes, (b) shows the mean intensity 〈R〉(y0), after subtracting a nominal trend of to reveal a finer-scale structure that resembles the underlying topography, and (c) shows the standard deviation of intensity . Dashed curves in (b) and (c) indicate the mean and standard deviation, respectively, of the concentration field c without box-averaging. Panels (d)–(f) summarize the distribution of intensities R* via the parameters of the generalized Pareto distributions (GPD), inferred by the peaks-over-threshold fitting procedure (see Sect. 3.3 for details). The threshold is set to the -complementary quantile, denoted and shown in (d) with linear trend removed. Panels (e) and (f) display the estimated (scale, shape) parameters (σ, ξ).
In the eastward jets, the tracer mean varies more slowly with latitude and has a smaller standard deviation. Comparison with the Hovmöller diagram (Fig. 3a.i) suggests that the central region owes its high variance to short-lived anomalous pulses, both positive and negative, which are more intense than in surrounding regions. We won't try to explain these patterns from first principles, but simply state that the setup accomplishes our intention to provide a variety of statistical behaviors as a suite of test cases for our approach.
3.3 Target variable
We define the intensity function of interest R(x) as the upper-level concentration, c1 (henceforth, simply c), averaged over a small square box of half-width . This function is designed to capture the real-world considerations and algorithmic difficulties that originally motivated the AST: it describes localized conditions, similar to concentrated pollution, high heat, or heavy rainfall over a region on Earth, and it is mediated by traveling baroclinic waves, and as a result it displays intermittency, with extreme spikes that come and go quickly. The choice of upper- instead of lower-level concentration is simply to weaken the impact of arbitrary aspects of the model setup like the surface topography. Real-world applications would of course refine this choice in many ways, but our choice is suitable for the QG level of model idealization.
To investigate the effects of location-dependent flow regimes, we vary y0 across 23 evenly spaced latitudes , restricted to the central region to avoid boundary effects. The central longitude x0 is fixed to , but by zonal homogeneity any longitude would be statistically equivalent. We also repeated the analysis with double the box length, and found results to be qualitatively similar, so we only show results for the smaller box size. The effect of spatial scale is worth considering in its own right with a wider range, which we postpone to future work.
Figure 4 displays some summary statistics of R(x(t)) as functions of the target latitude y0: alongside (a) the topography for reference, we show (b) the meridionally de-trended time-mean and (c) the standard deviation . Note the restricted latitude range. In Fig. 4a and b, dashed lines show the corresponding mean and standard deviation of c itself, as in Fig. 3c and d, of which R is a regional average: note that R has the same mean as c but a smaller standard deviation, and larger box sizes would reduce it even further.
While the low-order moments capture ordinary behavior of intensities R, the intensity peaks – i.e., severities R*, defined in Sect. 2 – are better viewed from an extreme value theory perspective, and summarized with the peaks-over-threshold procedure (Coles, 2001). We set a threshold μ as the th complementary quantile of R, also denoted , i.e., the level whose exceedance probability is . Severities R* are extracted as cluster maxima above μ, with buffer times Amax=40 d and B=20 d. All cluster maxima from the long DNS are used as input data points to infer the parameters (scale σ, shape ξ) of a generalized Pareto distribution (GPD), using the maximum-likelihood routine of the Extremes.jl package (Jalbert et al., 2024):
where . Figure 4d–f displays the threshold (detrended by ), scale parameter σ, and shape parameter ξ. Several characteristics are noteworthy.
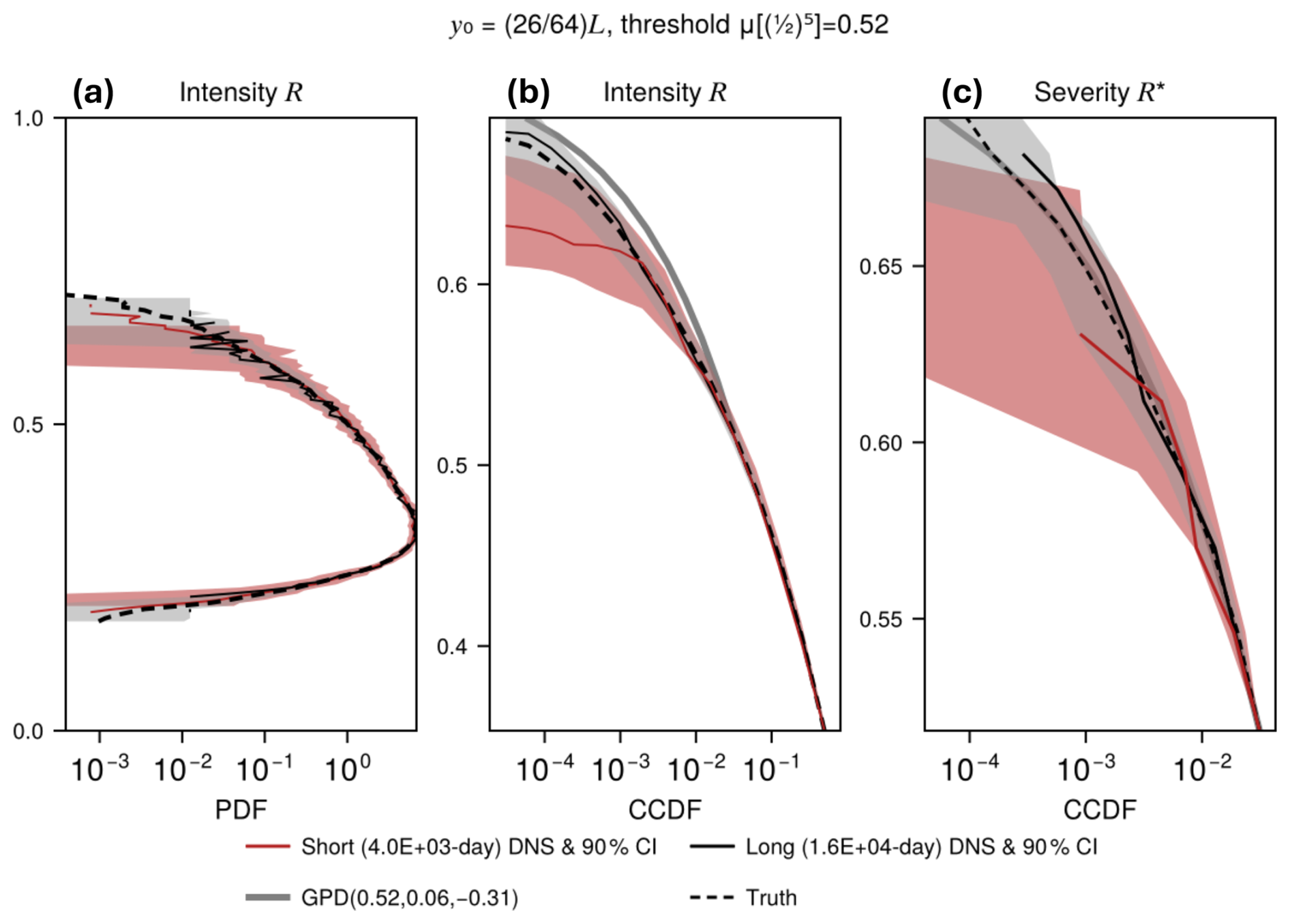
Figure 5Probability distributions of local tracer concentrations at latitude and averaged over a box of half-width . (a) The full PDF of intensity R. (b) The CCDF (tail integral) of intensity R, restricted to . (c) Further zoomed-in CCDF of the severity . In all three panels, solid black and red lines represent estimates from long and short DNS, respectively, with shaded 90 % confidence intervals obtained by repeating the inference 64 times, once for each possible longitudinal rotation of the dataset. Error bars become degenerate at levels experienced by <5 % of longitudes. Black dashed lines show the mean over all longitudinal rotations, our best estimate of ground truth. The gray line in (b, c) represents the GPD fit to R* with μ=0.52, σ=0.06, and , and this is a much better fit to the severities in (c) which makes sense given they are defined in terms of peaks.
-
The detrended threshold has a maximum-over-minimum profile similar to the the detrended mean intensity , but shifted southward. The maximum of is close to the mid-channel maximum in the standard deviation of R, perhaps because extremes depend more on variability than on average behavior.
-
As expected for an upper bounded tail, we find ξ<0 at all latitudes (Fig. 4f).
-
The GPD scale parameter, σ, is anti-correlated with the (detrended) mean. The constraint can explain this, as a higher distribution center leaves less room for an expansive tail. In addition, the threshold μ tracks approximately with the mean, and we can understand the anticorrelation mathematically through the non-uniqueness of GPD parameters: the same tail can be adequately described by two different choices of threshold (μ1,μ2), and the two corresponding scale parameters will be related by . Only the shape parameter, ξ, is invariant with respect to μ. Seeing that ξ is negative and varies only slightly with latitude, σ and μ would vary inversely even if the tail itself were not changing.
-
The mean appears odd-symmetric and the standard deviation appears even-symmetric about the midline (Fig. 4b and c), which is not surprising given the tracer boundary conditions which transform as when , negating the sign of fluctuations but leaving their absolute value constant (or perhaps disrupted slightly by topography). However, the GPD parameters are not symmetric (Fig. 4d–f), because they describe the upper tail of the local R* distribution, and the transformation swaps the lower and upper tails. The subsequent figures (Figs. 5 and 7) demonstrate pronounced skewness, so the upper and lower tails are markedly different. These partial symmetries will imprint upon the COAST's latitudinal variation seen later in Figs. 14 and 15.
We implemented the boosting and estimation procedures for every latitude separately, but for illustration focus the in-depth analysis on (the small boxes in Fig. 2), an interesting location where the (detrended) mean and threshold are both low, the GPD scale σ is large, and the GPD shape slightly more negative than in surrounding regions. Figure 5 displays the underlying probability distributions at to show the nature of the tails of the distributions and also to help clarify the relationship between intensities, severities, and GPD parameters. The full PDF of intensity, in Fig. 5a, has a positive skew and sub-Gaussian tail. Black and red solid curves are estimates obtained from the long and short DNS, respectively, and 90% confidence intervals are obtained by longitudinal translation. Specifically, the shaded intervals are the 5th–95th percentile ranges of intensities at the same y0, but with x0 shifted from its base location of by , , , …, . The dashed black curve is the mean of all 64 curves, our best available estimate of ground truth. The discrepancy between short and long DNS is most pronounced in the upper tail, which in Fig. 5b is magnified and integrated from the top, giving the CCDF. Gray lines mark the threshold, μ=0.52, and its CCDF value . Above this level, the short DNS becomes rapidly more uncertain (error bar widens), and severely underestimates probabilities smaller than ∼0.005.
Both short and long DNS estimates diverge markedly from the GPD fit shown in gray in Fig. 5b. This is where the distinction between intensity and severity comes into play: the GPD is fitted to peaks over the threshold μ – i.e., severities – whose distribution differs (most notably in the upward direction) from that of all exceedances over μ, which would include the clusters surrounding the peaks. Figure 5c confirms that the GPD fit is much more appropriate for severities R* than for intensities R, and thereby clarifies the distinction. If the threshold were raised, the clusters would shrink, the sequence of peaks would form a Poisson process, and the CCDFs of R and R* would converge. For computational economy and because non-asymptotic extremes are of interest for climate risk, we keep the threshold at and formally define our goal with boosting as correcting the distribution of severities – not intensities. Hence, our measure of success will be whether the short-DNS severity CCDF in Fig. 5c, when augmented by boosting, will become closer to the long-DNS severity CCDF.
4.1 Stochastic inputs
We perturb the QG model with impulsive forcing, which we now specify as a concrete version of the generic form in Sect. 2. The stochastic input ω lives in the complex plane ℂ(=Ω, the “input space”), and the state-space perturbation G(ω) consists of a single Fourier mode to be added to ψ. We stress that our focus here is on optimizing AST, not the perturbation space Ω, so the choice of mode is arbitrary so long as Ω remains low-dimensional. The optimal AST would probably change if Ω changes, e.g., if we perturbed a different mode or multiple modes at once; but the rule for choosing it based on entropy may well generalize, which will have to be tested in follow-up research.
Bearing these caveats in mind, we select a mode that is likely to grow fast, according to linear stability analysis, which is more easily explained as a procedure than as a closed formula:
-
Decompose ψ into a Fourier basis , and write the linearized dynamics (about the baroclinically unstable background state with vertical zonal wind shear and ψ=0, and neglecting topography) into the abstract form
where represents the conversion from streamfunction to potential vorticity, and represents the advection and linear dissipation terms (excluding topography).
-
Calculate the eigenvalues and eigenvectors of the Jacobian matrix , ordered by stability: Re{λ(1)}≥Re{λ(2)}, and select , i.e., the linearly most unstable mode from the background state. Restrict the optimization to (k,ℓ) both nonnegative, and not both zero.
-
For , increment by , and to maintain the solution's reality add the complex conjugate (c.c.) to . The perturbation can be written as a function of space,
which can have pointwise magnitudes up to . In the QG model, the mode we identify is , and G(ω) is plotted in Fig. 6c for three different example ωs, which correspond to the points labeled 1, 2, 3 in Fig. 6a. All share the same inter-layer relative phase and magnitude, as these are properties of , and , but differ in absolute phase and magnitude. Note that points 2 and 3 are approximately diametrically opposed, and hence spatially ∼180° out of phase, whereas point 1 is approximately one-quarter revolution away and spatially ∼90° out of phase with both 2 and 3. Points (2, 3) are (closest to, farthest from) the center of the circle, and hence have the (smallest, largest)-magnitude spatial perturbations. of the three examples shown.
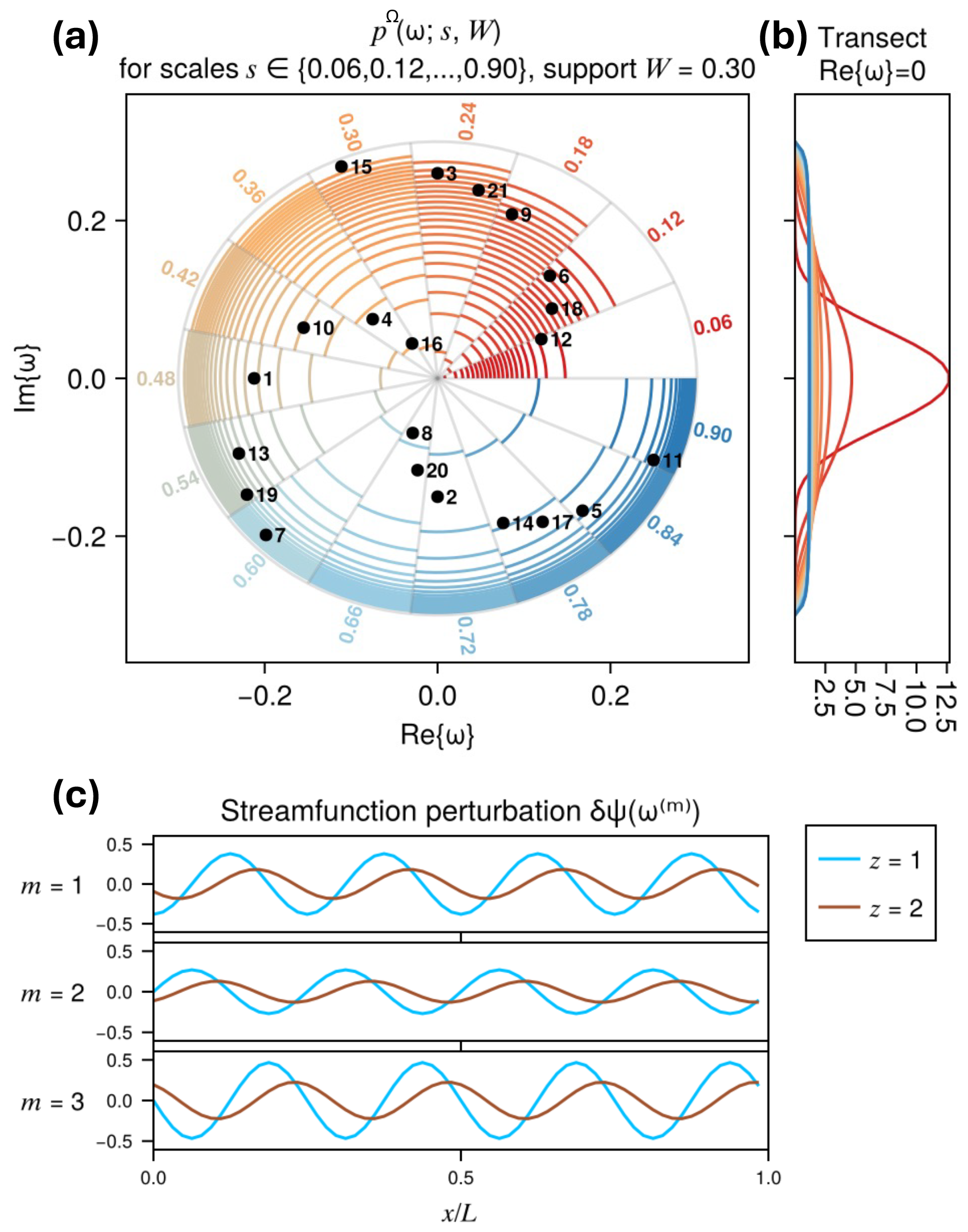
Figure 6Structure of perturbations and their probability distribution. (a) Level sets of each considered input distribution from scales s=0.06 (red) to s=0.9 (blue), each scale restricted to of the circle each so that all scales may be seen. Labels on the outer edge of the circle indicate the corresponding scale. Dots show the 21 impulses used at each AST before each ancestor, sampled by quasi-Monte Carlo. (b) One-dimensional transects of at each scale. (c) The shape of perturbations to the streamfunction corresponding to ω1, ω2, ω3. Note that the absolute amplitudes and phases vary, sampling the two degrees of freedom in the disc, but the relative amplitudes and phases of the upper and lower layers are fixed.
The steps above completely specify G(ω), a linear map from ℂ to functions of (x, y, z), which can be easily computed offline before running any ensembles. One could argue for two obvious refinements of this choice: (1) specializing the linearization to the actual initial state, not just the background state, by linearizing the quadratic form J(q,ψ) and including that in the calculation of D(k,ℓ); and (2) accounting for finite time horizons by using the leading singular vector of the linear propagator, i.e., the initial infinitesimal error whose magnitude amplifies the most over a given time horizon (Farrell and Ioannou, 1996a, b) and which could be estimated by a bred vector approach (Norwood et al., 2013).
For this study, we stick to the simpler choice of the most unstable modes of the background shear, choosing to focus attention on the less-studied optimization of the advance split time given a fixed perturbation shape. There are several reasons that singular vectors may not be suitable for our goals. First, it is easier to compare different initial conditions, different advance split times, and even different topographies (which we do not do here) when they are all subject to precisely the same perturbation. Second, as our results will demonstrate, the COAST tends to lie beyond the time range where linearized error dynamics are appropriate, which is natural because we aim for finite-amplitude boosts in extreme events. Third, singular vectors are typically designed to optimize global errors, which might not be as relevant for local extremes. Fourth, such highly specialized perturbation shapes might not be accessible in a generic GCM. Nonetheless, sensitivity analysis with respect to perturbation shape leads the agenda for follow-up work.
Having fixed a subspace Ω=ℂ for perturbations ω, we need to specify an input distribution pΩ(ω) over that space. We design the PDF for ω as a radially symmetric, smooth, “bump function” which has compact support in order to prevent perturbations so large as to induce oscillatory transients. The PDF is parameterized by two scales: W which is the maximum permissible magnitude of ω, and s which sets the typical perturbation strength:
When s≪W, p is approximately a bivariate Gaussian density with diagonal covariance s2I. When s≳W, p is approximately uniform over the W-disc , with rapid (but mathematically smooth) transition to 0 on the boundary. We fix W=0.3, limiting the maximum possible perturbation amplitude to (see text after Eq. 38), which is small compared to the characteristic streamfunction amplitude of . We include s as a parameter to vary because there is no established principle to set the magnitude of impulses for the purpose of rare event sampling. In contrast, numerical weather prediction has an established (if heuristic) practice of tuning noise amplitude to match ensemble spread with model error (e.g., Berner et al., 2015). Optimizing for climatological accuracy is a different, murkier goal calling for less prejudice with regard to perturbation magnitude. We therefore vary s widely from 0.06 to 0.9 in increments of 0.06 for 15 total values. s is the impulsive-forcing analogue to the continuous-forcing amplitude that we called F4 in Finkel and O'Gorman (2024), which strongly influenced the perturbation growth rate and therefore the optimal advance split time.
Figure 6a and b depicts in two ways: (a) two-dimensional level sets of the unnormalized density (Eq. 39) logarithmically spaced from e−4 to e−0.01, each value of s occupying one of 15 sectors of the circle; and (b) one-dimensional transects across fixing Re{ω}=0. To save the labor of drawing Monte Carlo samples from separately and simulating the perturbed children for each value of s, we compute the MoCTail and PoPTail estimators using numerical quadrature over the W-disc using a single set of samples drawn by quasi-Monte Carlo (QMC), and displayed as black dots in Fig. 6a. QMC is a general strategy which places samples deterministically across the input space in a way that mimics properties of randomness, but with lower discrepancy (fewer clumps and patches), thereby aiming to reduce variance in estimated statistics (Leobacher and Pillichshammer, 2014). We specifically use the LatticeRuleSampler from the QuasiMonteCarlo.jl Julia library (Rackauckas, 2023) to distribute points quasi-uniformly on the unit square [0, 1]2, and transform them to the W-disc with the formula
Since Um is a “quasi-random sample” of the uniformly distributed random variable , we have
which is the fraction of the W-disc between the radii r1 and r2. The phase 2πV is clearly 𝒰([0,2π]). If U and V were independent random variables, we would immediately conclude ω is uniformly distributed over the W-disc; in QMC they are not independent, but the conclusion still holds true (Leobacher and Pillichshammer, 2014). In all experiments to follow, M=21, corresponding to the 21 points plotted in Fig. 6a. While other sampling rules are possible, the LatticeRuleSampler enjoys a distinct advantage of being extensible: sampling 12 points at first and later deciding to add 9 more gives the same result as sampling 21 in one batch.
4.2 Sweeping over ancestors and advance split times
Following the procedure laid out in Sect. 2, we apply each perturbation to a collection of ancestor events at a range of ASTs . We set the number of ancestors, N to whichever is smaller: the total number of cluster maxima (see Sect. 3) in the short DNS, or 32. Considering all latitudes, the minimum N was 14, the median was 22, and the maximum 32 was found at four latitudes including which we consider in more depth. In the equal-cost comparisons to be shown later, we restrict N to smaller values. The ASTs sampled are , with a two-day spacing chosen as roughly half the period of small fluctuations in R(x(t)) (see Fig. 7).
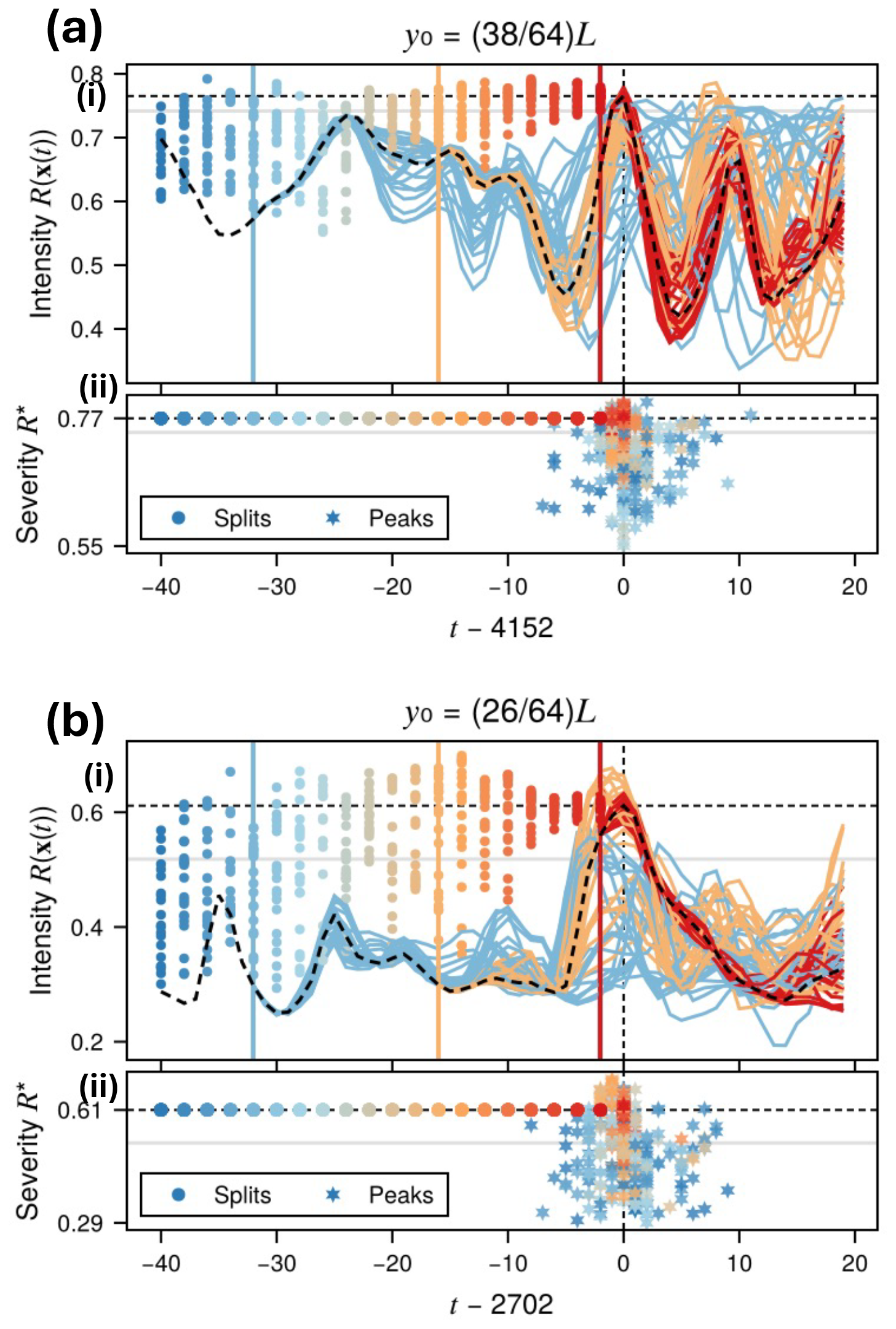
Figure 7Boosted ensembles of two selected events: (a) time at latitude , and (b) time at latitude . These are times when the intensity function R(x(t)) from the short DNS (dashed black curves) achieved a peak value (horizontal dashed black lines) above the threshold (horizontal gray lines). For each AST , an ensemble of perturbed events (descendants) is launched at , indexed by m=1, …, 21. For three selected ASTs , the full timeseries are shown in (a, b).i. The red-to-blue color scale indicates short-to-long ASTs. Each descendant achieves a different severity (peak intensity), indicated by circles in (a, b).i at () for all values of A. The peaks also occur at different times , indicated in (a, b).ii by stars at (), again for all A and colored accordingly.
In this section we present some case studies of conditional perturbed ensembles (from individual ancestors) and corresponding dispersion measures to be subsequently used in the MoCTail and PoPTail estimation. The results will add context and motivation to the protocols laid out above, and set the stage for the aggregation of results across ancestors.
5.1 Perturbed ensembles: case studies
Figure 7 displays a small but representative sample of boosted ensembles at two target latitudes at the inner edges of the two eastward jets: (a) and (b) . The ancestors' intensity (black dashed curves) reach their respective peaks at times for (a) and 2702 for (b). Note the differences in peak value and peak shape: the upper latitude has long-lasting, flat maxima and the lower latitude has brief, spiky maxima. The statistical properties at these two locations, both in Figs. 7 and 3, are approximately equivalent after reflection about (), meaning the upper tail of one resembles the lower tail of the other. This can be understood by the approximate north-south symmetry of the tracer's dynamics imposed by Dirichlet boundary conditions.
We show the perturbed intensities launched from three ASTs , colored (red, orange, blue) respectively. Following the split time, the ensemble members spread apart from the parent and from each other, achieving their own peak values (severities) that differ in both amplitude and timing from the ancestor, the discrepancies increasing with A. The red curves (A=2) replicate the ancestral peak very closely; the orange curves (A=16) peak at substantially higher or lower levels, and up to ∼2 d earlier or later. Still, the orange peaks are clearly dynamically related to the ancestral peaks. This is no longer true for the blue curves (A=32), whose intensity peaks are widely scattered in time and systematically lower than the ancestors' peaks.
Besides these three selected ASTs, each descendant is charted in Fig. 7a and b.i as a circle color-coded by AST, positioned vertically at its severity value and horizontally at its launch time. A corresponding star is plotted in Fig. 7a and b.ii, positioned vertically at its severity value (on a zoomed-in scale) and horizontally at its peak timing (constrained by the “argmax drift” parameter d ≈ half of an eddy turnover timescale, as explained in Sect. 2.1). We can see the transition of the R* ensemble from tightly clustered (for short AST) to roughly independent and climatologically distributed (for long AST), and in between there is a golden window of opportunity where severities can be both large and diverse. The optimal AST must balance these two objectives, a task akin to the exploitation-exploration tradeoff in Bayesian optimization and reinforcement learning (e.g., Yang et al., 2022). In this light, the two functionals defined in Eqs. (27) and (28) are candidate acquisition functions.
5.2 Relating severities to impulses: case studies
We now construct “severity response functions” mapping impulses ω∈ℂ to severities R*, approximating the action of the flow map using some empirical parameters θ. This will be needed to estimate conditional and unconditional probabilities through the MoCTail and PoPTail estimators (see Eq. 5), and will also help to understand the joint dependence between impulses ω∈ℂ and the times at which they are applied.
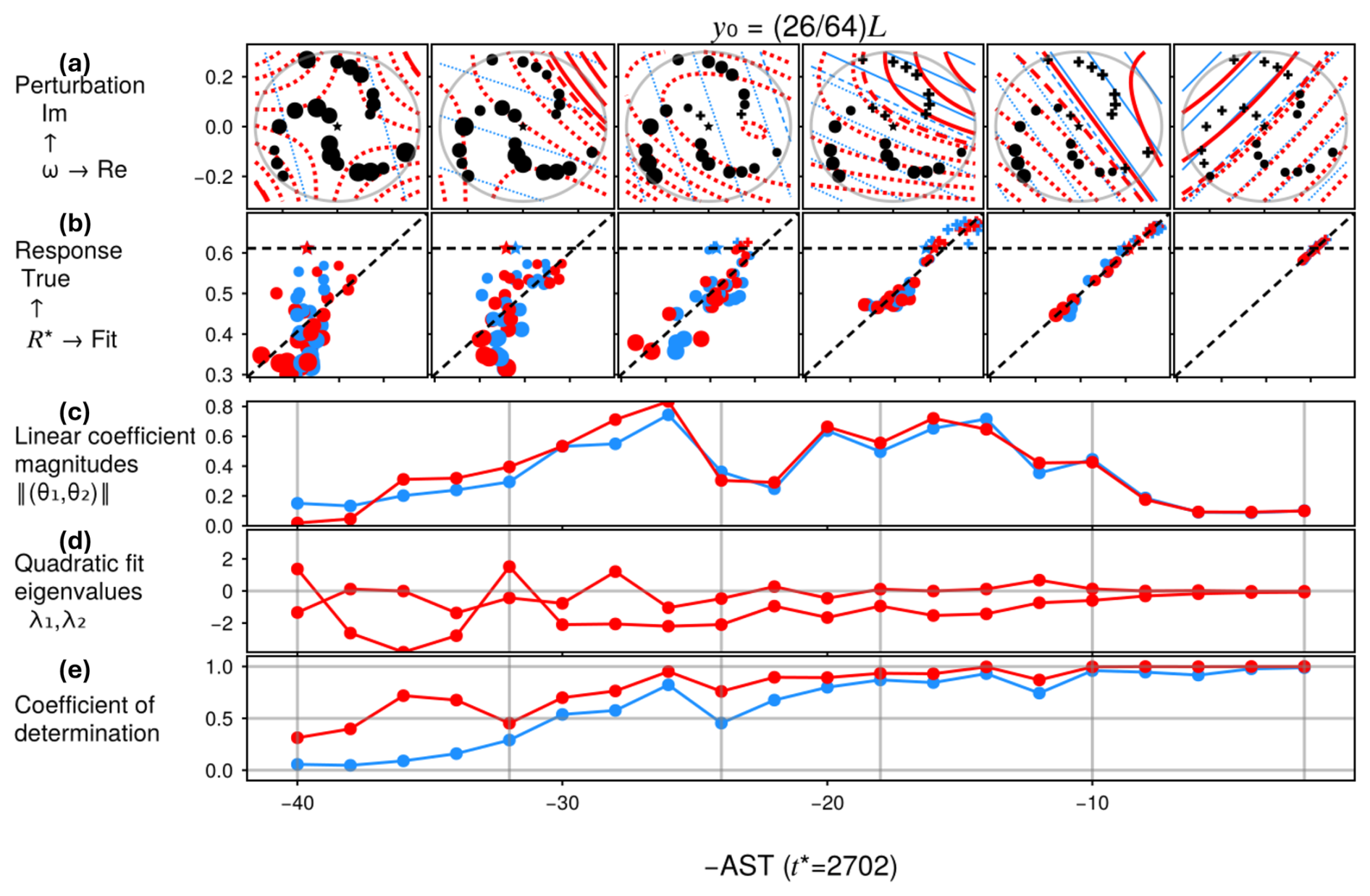
Figure 8The response of an extreme event to perturbations: magnitude, phase, and timing. The event is the same as in Fig. 7b. Row (a) represents impulses as in Fig. 6, but additionally shows the responses to them separately at six sampled ASTs (2, 10, 18, 24, 32, and 40 d marked with vertical gray lines in c–e), which increase from right to left (launch time increases left to right). Horizontal and vertical scales are equal. At the shortest AST shown, A=2, the response function is clearly linear: the impulses above and left of center are marked by +, representing an increased severity, and those below and right of center are marked by •, representing decreased severity, with marker sizes representing the magnitude of the change. Colored curves represent level sets of the fitted linear (blue) and quadratic (red) models, with (solid, dashed, dotted) contours to differentiate (positive, zero, negative) changes to R*. Row (b) displays the quality of these models by plotting true vs. fit responses (again, horizontal and vertical scales are equal). As AST increases, the impulses causing higher and lower severities become more intertwined and less linearly separable, as the red contours progressively bend and separate from the blue contours. Accordingly, the modeled linear response ceases to correlate with the true response. The modeled quadratic response has a slightly longer range of good quality, but also fails for AST ≳26 d. Row (c) shows that the linear components θ1, θ2 are estimated similarly (at least in magnitude) regardless of whether quadratic terms are also included. Row (d) shows that the quadratic model implies a local maximum (both eigenvalues nonpositive) for most of the range A<26, beyond which the landscape starts looking less like a hilltop and more like a saddle. Row (e) displays the coefficients of determination, conventionally denoted R2 but not here so as to avoid confusion with intensity R.
How should the response functions be parameterized? The simplest choice would be a linear model, often used in numerical weather prediction to optimize ensemble spread by perturbing in the most-effective directions, so-called singular vectors (Diaconescu and Laprise, 2012). However, linear models are strictly valid only for infinitesimal perturbations, hence short lead times. Similar logic should apply when optimizing for severity instead of ensemble spread, and indeed we demonstrate below that the COAST tends to lie beyond the range where a linear model is valid. We therefore construct a quadratic model as well, and it turns out that this minor upgrade is sufficient. Future work with more complex dynamics and objectives may call for more elaborate response functions (orthogonal polynomials, Gaussian processes, and neural networks for example), but we adhere to quadratic models in this study as a proof of concept that is easy to construct and interpret, which we do in the following two figures.
The linear and quadratic response functions take the form
We use ordinary least squares regression on the M=21 sampled impulses and associated severities , in addition to the non-perturbed ancestor (ω0:=0) with severity . A different set of coefficients is calculated separately for each ancestor n and AST Aj. The response functions for the same ancestor event as in Fig. 7b are visualized in Fig. 8, using (a) the two-dimensional response surfaces, (b) the true vs. fitted response values, (c) the overall slope, measured by the linear coefficient magnitudes, (d) the overall curvature, measured by the eigenvalues of the Hessian of the quadratic fit, and (e) the overall linear and quadratic skills, measured by the coefficient of determination. The response surface gradually transforms from a linear plane, to a curved hilltop, to a saddle, to a jagged landscape, as AST increases. Accordingly, the linear and then the quadratic model lose their skill. The quadratic model is slightly better than the linear model for this particular event, but substantially better when averaged across all events (see the forthcoming Fig. 9c.i), and so we will use quadratic models only as in the tail estimators.
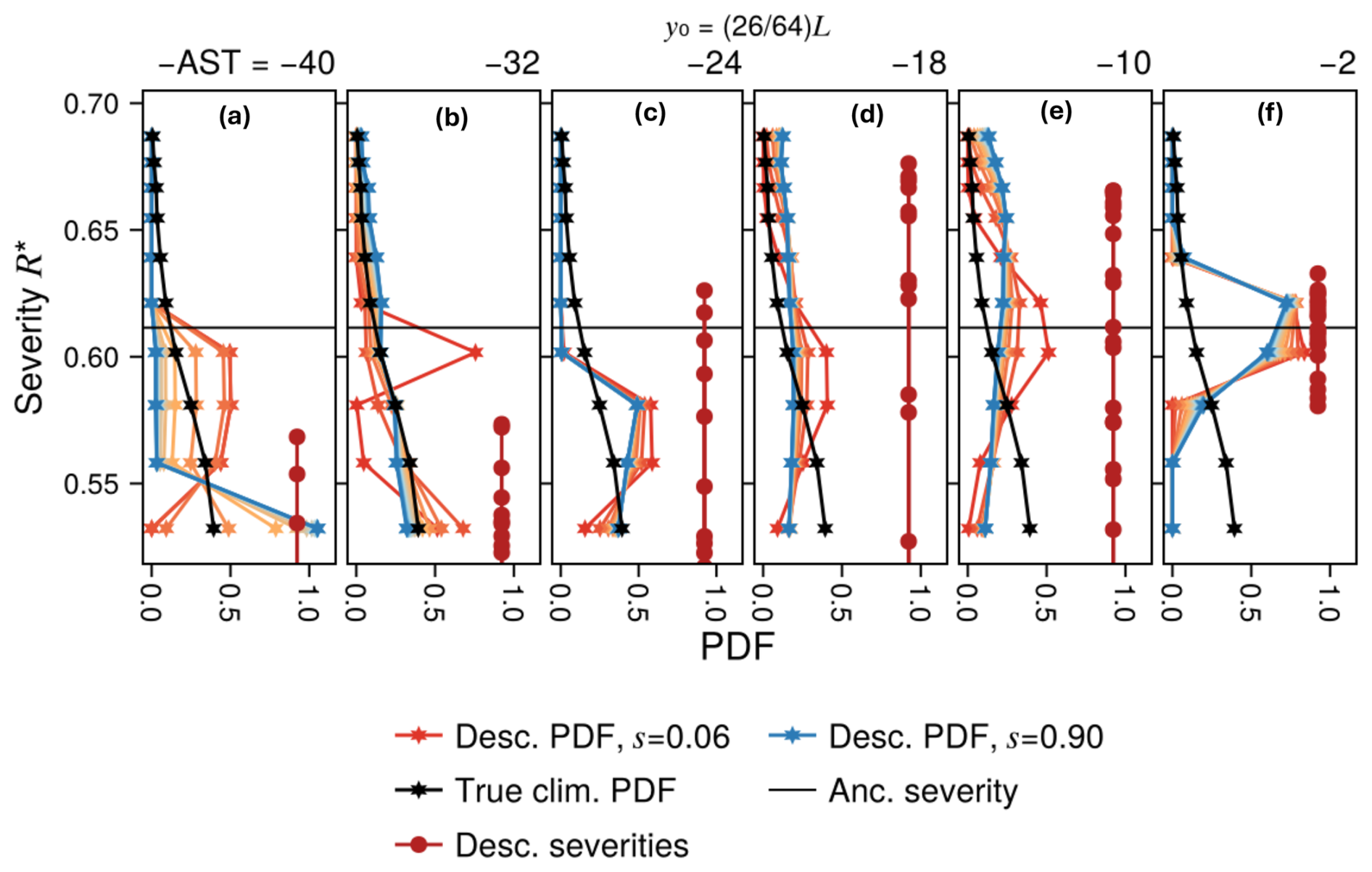
Figure 9Severities and their conditional distributions for the same case study as Fig. 7b. For six ASTs (same as Fig. 8, decreasing from left to right), perturbed severities are displayed as dark red circles along a vertical line, and the unperturbed (ancestral) severity is marked with a horizontal black line. Colored curves and stars show the severity PDFs above μ=0.52 as inferred from the quadratic regression, for a range of scales s from 0.06 (red) to 0.9 (blue). Note that the longest ASTs (40 and 32 d) show a substantial probability mass beyond the most-extreme sample. This is a sign of poor quadratic fit, which is consistent with Fig. 8e, and fortunately does not affect the later analysis since optimal ASTs are well short of 32 d. Black curves with stars represent the climatological tail PDF, as inferred from the long DNS, which we will seek to estimate by combining conditional distributions over many ancestors (not just the single ancestor considered here).
5.3 Conditional severity PDFs: case studies
Equipped with response functions approximated by quadratic models, we can now construct conditional severity PDFs using Eq. (10), which are displayed in Fig. 9. For the same ancestor as in Fig. 8 and the same six ASTs, we can see the relationship between actually sampled perturbed severities (red circles and lines), fitted severity PDFs (colored curves, one color for each input scale s) evaluated at the bins with lower boundaries , and the climatological PDF (black curves). As AST increases from right to left, the severity PDFs morph from narrow spikes centered at the ancestor severity to long, extended lumps reaching far beyond the ancestor severity, and then recede below the threshold . The PDF's motion resembles a wave crashing onto a shallow beach, blanketing the sand, and then retreating, hitting the true COAST somewhere in the middle stages. But this general behavior is strongly modulated by the choice of scale s: red PDFs, representing the smallest scale s=0.06, are narrower and located closer to the ancestral severity (horizontal black line) for all ASTs, whereas blue PDFs, representing the largest scale s=0.9, spread out further as a result of giving more weight to bigger impulses. This underscores our claim that the input distribution, an arbitrary choice, merits sensitivity analysis, and so we carry it through the remaining steps.
5.4 AST selection criteria: case studies
Figure 10 display the criteria proposed in Sect. 2.4 that might help determine in which stage of “wave breaking” the severity PDF finds the COAST. The EI and TE criteria shown in Fig. 10a and b both exhibit non-monotonic behavior by design, maximizing at COASTs denoted AEI and ATE (see Sect. 2.4). The AST dependence can be heuristically understood in light of the PDFs in Fig. 9:
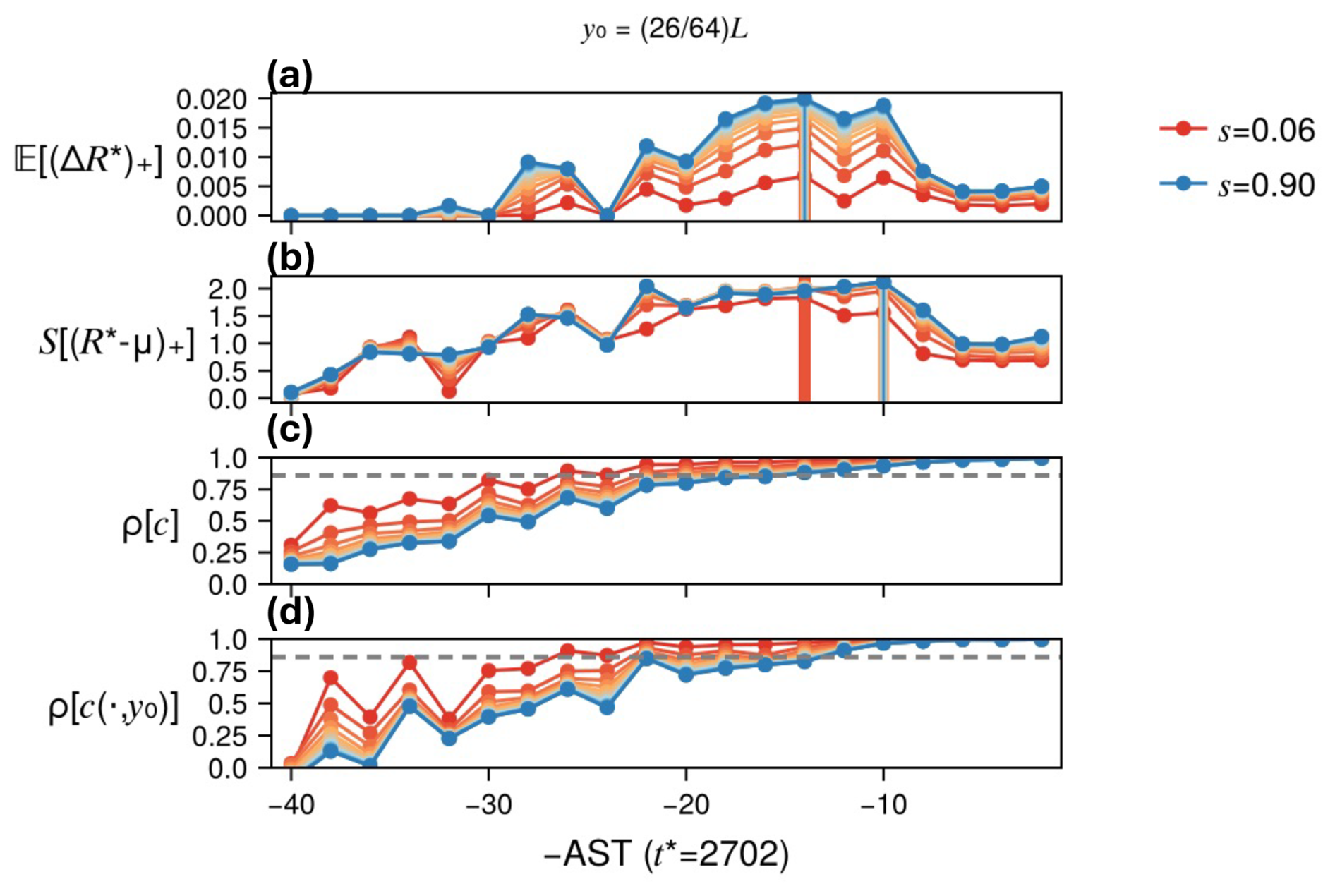
Figure 10Ensemble dispersion indicators as a function of AST, again for the same case study as Fig. 7b: (a) expected improvement EI, (b) thresholded entropy TE, (c) local and (d) global correlations. Colors indicate input scales s, from small (red: s=0.06) to large (blue: s=0.9). In (a, b), vertical bars mark the respective optimal ASTs, which may depend on the scale. In (c, d), horizontal dashed lines are positioned at , corresponding to the rule of thumb from Finkel and O'Gorman (2024).
-
At small AST, the narrow PDFs have a relatively high probability of improvement over the ancestor , but only by small amounts, hence a small EI. By a similar token, the TE terms in Eq. (28) are almost all positive because the PDF is situated well above μ, but being concentrated in a small number of bins makes its information content low.
-
At intermediate ASTs of 10–20 d, the PDFs remain roughly centered at the ancestor's severity, meaning that improvements remain highly probable, but are larger when they happen thanks to the long upper tails, contributing to a large EI. Meanwhile, both upper and lower tails contribute to a large TE, which does not directly favor exceptionally high severities but rather diverse severities that are high enough to exceed μ.
-
At large AST past ∼25 d, the PDFs have diminishing mass above μ, let alone above the ancestor severity , which zeros out most of the contributions to both EI and TE.
The COAST can change with the scale s: even though the overall shapes of TE and EI do not change very much, the location of their maxima might. Fortunately, we will find changes in scale for s≳0.24 to have negligible impact.
Figure 10c and d displays two versions of pattern correlation ρ, defined in Sect. 2.4 for an arbitrary field F: the “global correlation” ρ[c] uses the whole two-dimensional upper-layer concentration field , and the “local correlation” uses only the single-latitude transect at the target latitude y0. Both drop off steadily with AST, although local correlation fluctuates more due to averaging a smaller spatial region. The influence of perturbation scale s enters at the ensemble-averaging step, where the mth member's pattern correlation ρ[F0,Fm] is weighted by . Since smaller perturbations take longer to grow, smaller input scales lead to slower dropoff of ρ with A – but only at short lead times, where errors are still tiny. Beyond A≈6 and 10 d for global and local correlations respectively, decorrelation proceeds at a similar rate with respect to increasing AST for all scales. The nominal threshold is marked in both, and gives a similar AST for local and global correlations but generally longer than implied by EI or TE.
5.5 AST selection criteria: aggregate results
Figure 11 goes beyond the case study to show dispersion indicators averaged across all ancestors. The coefficients of determination for linear and quadratic models (Fig. 11a) are farther apart on average than they are for the case study (see Fig. 8e), the quadratic model enjoying much higher skill especially during the pivotal 10–20 d range when EI and TE tend to maximize (Fig. 11b and c). This validates our choice to use the quadratic model. Overall, the EI, TE, global and local correlations (Fig. 11b–e) are similar on average to the case study, but smoother.
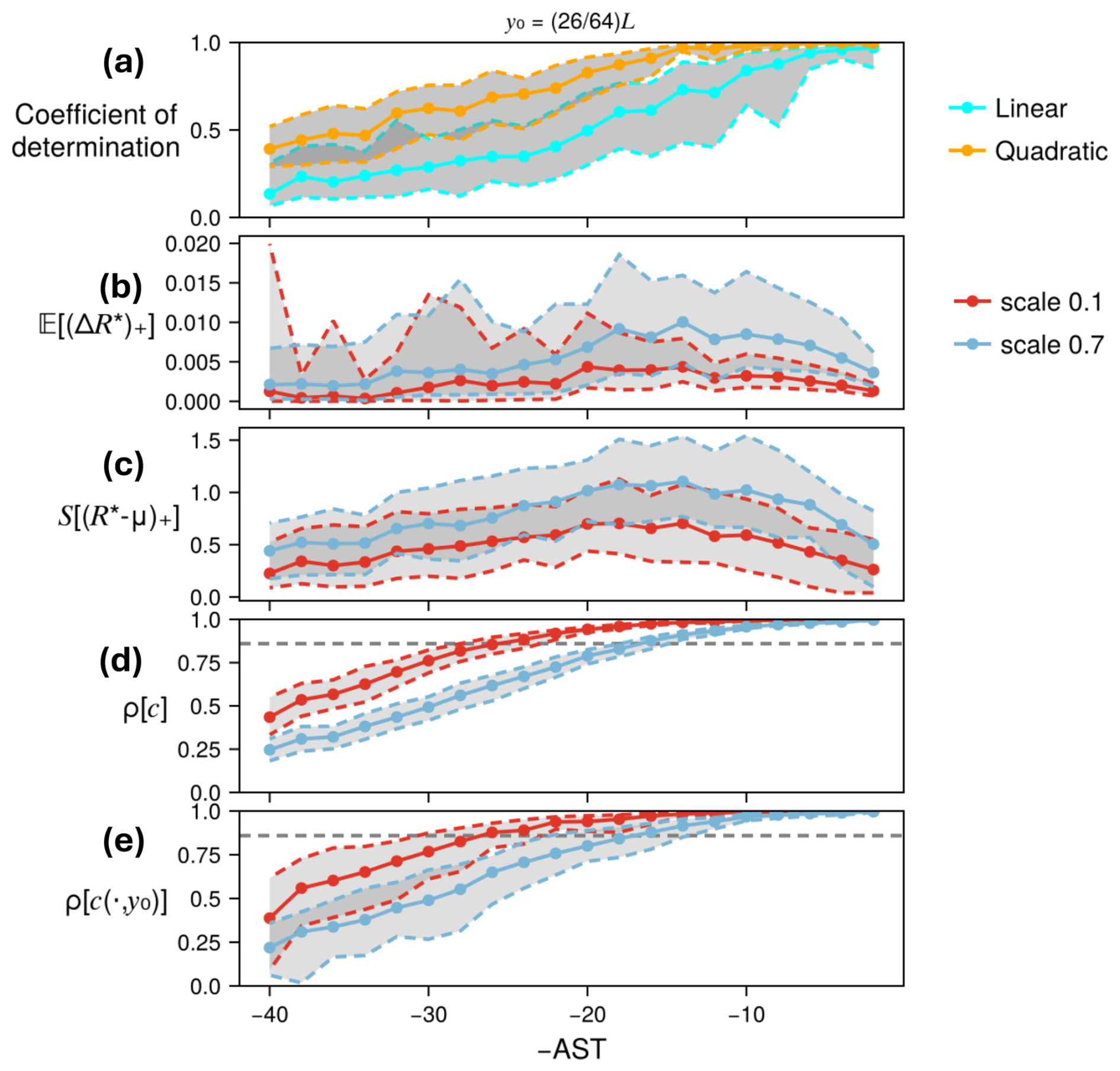
Figure 11Ensemble dispersion metrics averaged across ancestors at . (a) Coefficients of determination for linear (cyan) and quadratic (orange) regressions, averaged across ancestors. (b–e) Same quantities as in Fig. 10a–d but averaged across ancestors, with only the largest and smallest scales shown (red: s=0.06, blue: s=0.9). Shaded regions indicate variation across ancestors, which we quantify using truncated upper- and lower-means. For example, the upper truncated mean for correlation ρ is the mean of ρ across ancestors with above-average ρ: , separately at each AST. We choose truncated means to avoid the awkward properties of more standard measures of spread: interquartile ranges would be erratic for the relatively small sample size of ancestors, whereas standard deviation envelopes can misleadingly fall outside the bounds [0, ] to which ρ is constrained.
Note, however, that these averaged dispersion indicators are never used directly in AST selection: the COASTs are chosen separately for each ancestor as the maximizer of its own EI or TE, or at the longest AST such that global or local correlation is above ρU. This nuance is further illustrated in Fig. 12a and b, where (EI, TE) are plotted as joint functions of AST and input scale. Whereas the heatmaps are averages over ancestors of EI and TE just like Fig. 9c.ii and iii, the red circles indicate the fraction of ancestors whose EI or TE is maximized at a particular AST for each particular scale. We call the red circle sizes “COAST frequencies”. For example, at s=0.24, the mean EI maximizes at A=14 d, and that same AST is the most frequent COAST. However, the second-largest circle indicates that A=20 d is a close second-most frequent COAST according to EI. At the same scale, the most frequent COASTs according to TE are A=18 and 20. In general, we gather two patterns from Fig. 12a and b: the average EI and TE values (i) are well-correlated with their corresponding COAST frequencies, and (ii) both change rapidly at small scales but stabilize above s≈0.24, at which point the input distributions are close enough to uniform over the W-disc. This relative stability is reassuring, but we generally prefer smaller noise which disturbs the model dynamics less. To balance these considerations, we select s=0.24 as the nominal scale to examine more closely going forward.
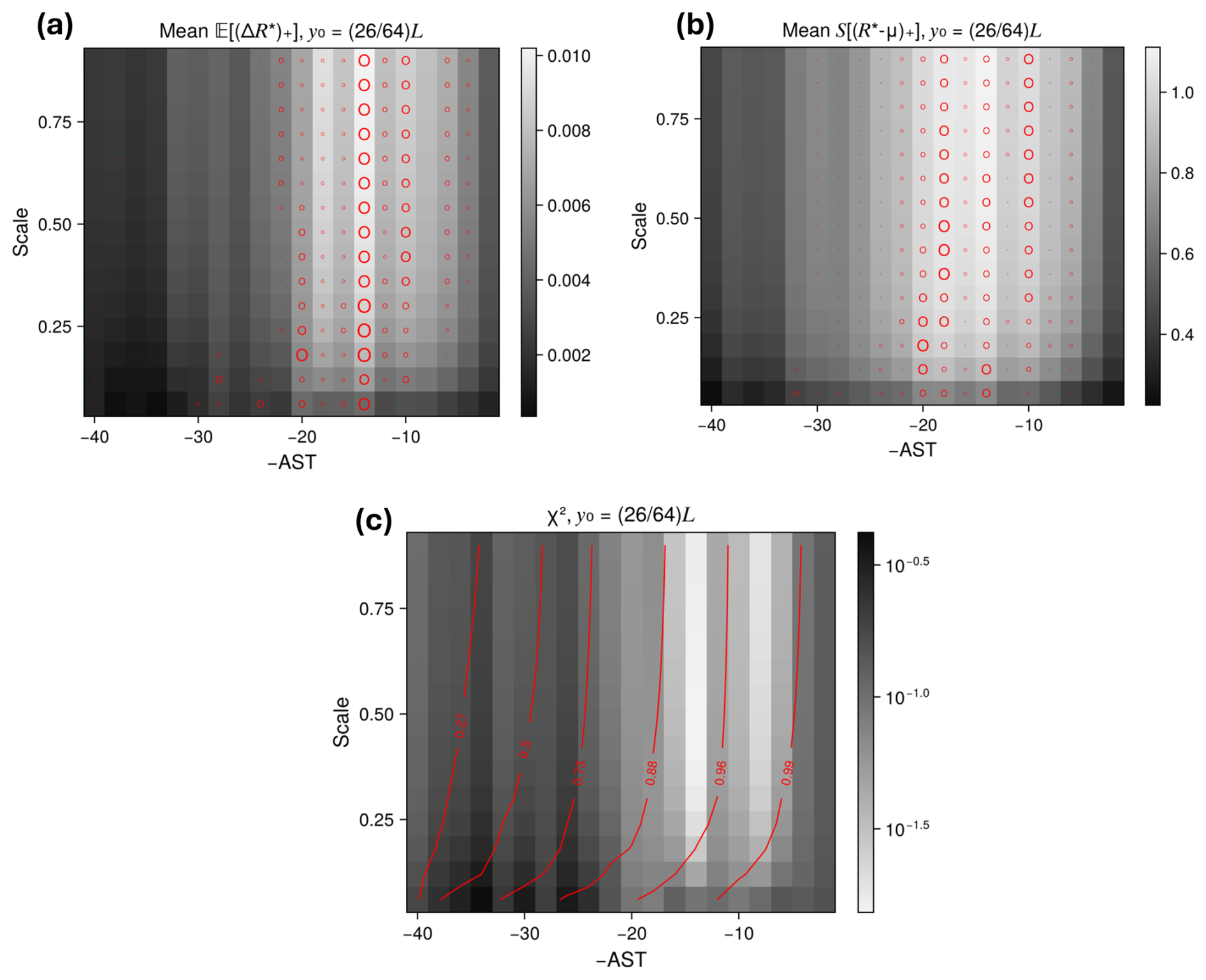
Figure 12Three optimization landscapes as joint functions of AST and input scale for : (a) expected improvement (EI), (b) thresholded entropy (TE), and (c) χ2 divergence between the MoCTail and ground truth. Lighter gray indicates better performance – smaller χ2 divergence or larger EI and TE – and the corresponding “best” ASTs consistently fall in the interior of the domain, across all scales. Contours of local correlation are overlaid in (c), giving a rough map of correspondence between correlation levels and AST. The size of red circles in (a, b) indicate the “COAST frequency”: the fraction of ancestors whose (EI, TE) is maximized at the corresponding AST while holding the scale fixed. Note the multiple local maxima in mean EI and TE (as indicated by the lightness of the gray color in a, b), each of which is the global maximum for some significant set of ancestors.
Having explained the construction of conditional distributions, we now aggregate across ancestors using MoCTail and PoPTail estimators to obtain our estimates of the climatological severity distribution from the boosted ensembles. We evaluate the skill of each AST selection rule by the χ2 divergence of the resulting climatological distribution from ground truth as obtained from the long DNS. We first restrict attention to extremes at and then assess a broader swath of latitudes.
First, consider the simplest AST selection rule A=AU, a uniform AST over all ancestors. We have no a priori principle for AU, so we search through all possible values from 2 to 40 d. Figure 12c displays the resulting χ2 divergence between the MoCTail and ground truth, as a function of AU and input scale. A clear optimum emerges at AU=14 d and persists for all scales s≳0.24, after rapid changes across smaller scales. Red contours also indicate the local correlation, averaged across ancestors to give a smooth and monotonic function of AST. In terms of correlation, the COAST AU=14 d corresponds to ρU≈0.92 depending on the scale, which is slightly above the nominal value , meaning one should split a little bit closer to the event than the rule of thumb implies.
Overall, the χ2 landscape (inverted) roughly aligns with the EI and TE landscapes, as do their respective optima. This is remarkable and encouraging: allowing each ancestor to determine its own COAST independently, with no knowledge of the ground truth or even other ancestors' COASTs, leads to a similar solution as the policy of synchronizing them all. Boosting based on EI and TE, therefore, is more parallelizable (optimizations are decoupled across ancestors), extensible (new ancestors can be added without changing the optimal split times for pre-existing ancestors), and interpretable (one can see the optimum clearly based on a case study, without complicated averaging procedures across initial conditions).
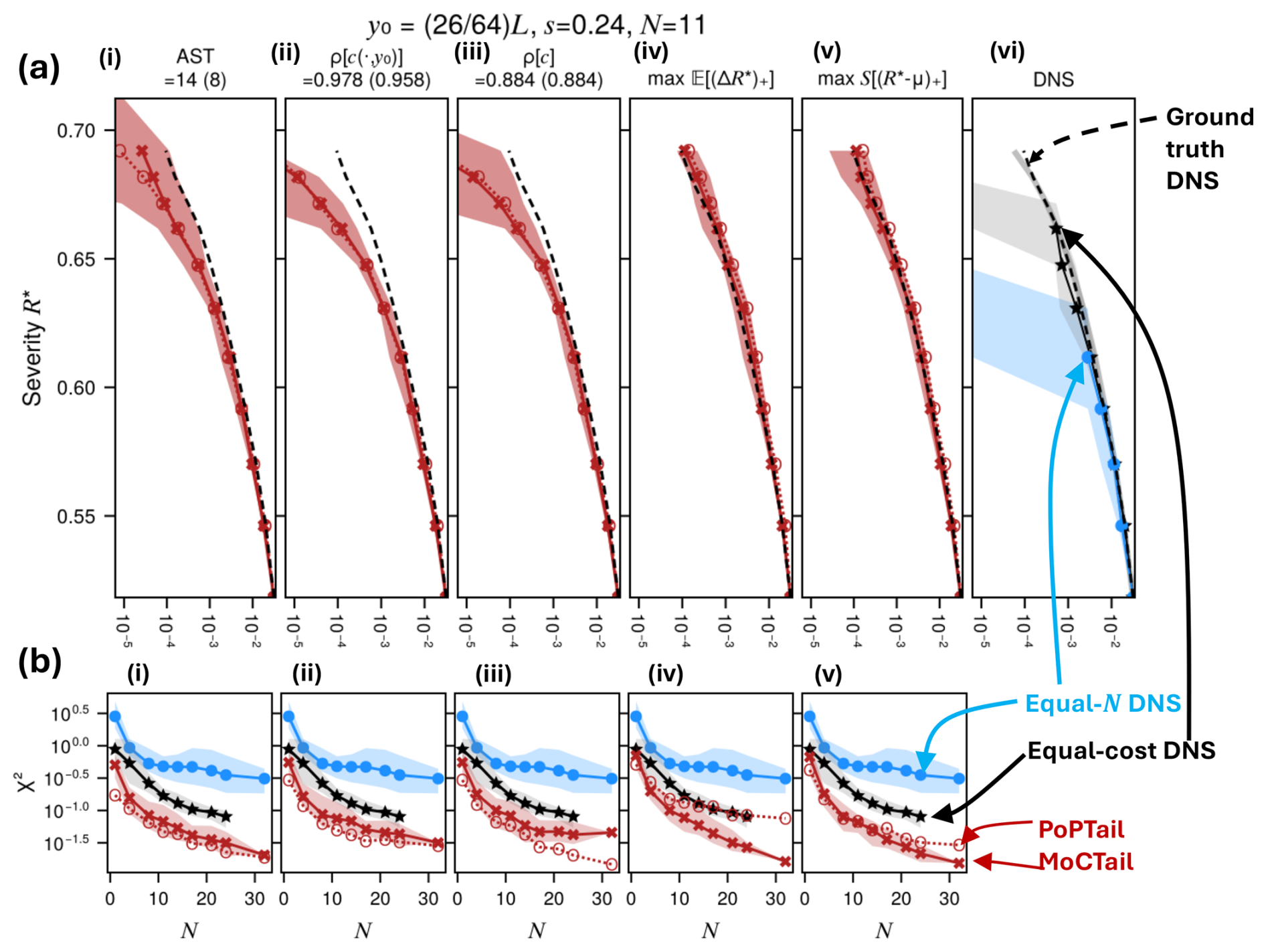
Figure 13CCDF approximations by various mixing criteria and associated errors, at the latitude and input scale choice s=0.24. (a.i–v) Tail CCDFs by various estimates using only N=11 ancestors, with lines showing medians and bands showing interquartile ranges across many size-11 subsamples of the total set of 32 ancestors. Dotted lines with open circles are PoPTails, while solid lines with crosses are MoCTails. Dashed black lines show the ground truth estimate. Panel (a.i) shows the tail approximation using a single uniform AST indicated at the top: 14 d for MoCTail and 8 d (parenthesized) for PoPTail. Panels (a.ii, iii) show the tail approximations using thresholds of (local, global) correlations as AST selection criteria. Panels (a.iv,v) show the tail approximations obtained by maximizing (EI, TE), which unlike the other criteria do not rely on knowing the ground truth to select ancestor-wise ASTs, either directly or through threshold choice. (a.vi) also shows estimates from DNS with equal cost to boosting on 11 ancestors (black stars, gray envelope) and DNS from only N=11 peaks (brown circles and envelope), in both cases estimating uncertainty by longitudinal rotation. The GPD fit to ground truth is shown as a gray curve. In (a.i–iii), the thresholds shown at the top (PoPTail thresholds parenthesized) are obtained by using all 32 ancestors, but the CCDFs displayed each choose an AST to minimize χ2 divergence from ground truth, separately for each subsample. Because this requires ground truth knowledge, the χ2 divergences must be interpreted as practical lower bounds. The 90 % error bar applies to the MoCTail estimator only, and comes from bootstrapping on entire “families” or in other words mixture components (not individual descendants) and choosing the best AST (by χ2 divergence) for each particular subsample. The error bar widths, too, must then represent lower bounds. (b) χ2 values for the estimator directly above in each case as a function of N, and compared with DNS at equal cost and equal N. DNS does not run long enough to equal the total cost accrued by boosting 32 ancestors, so the black curve stops before the others.
Figure 13 makes a tail-to-tail comparison between all the AST selection rules (a.i–v: AU, APC local and global, AEI, ATE), fixing the scale to s=0.24 and (in the case of AU and APC) selecting post-hoc the best-performing threshold to set the COASTs. We used subsets of only 11 of the 32 ancestors, resampling such subsets 64 times to obtain medians (solid) and interquartile ranges (shading) on CCDFs. The numerical values of optimal AST and ρ reported above a.i–iii, with PoPTail optima parenthesized, are the optima obtained from N=32, i.e., the best estimates of the true optima; they do not necessarily correspond to the values used for plotting with N=11, which are optimized separately for each resampling. The brown CCDF in panel a.vi is the estimate from the unboosted acestors alone (“equal-N”), and the black is the estimate from a larger number of ancestors to equal the cost of boosting. The curves underneath in panel (b) show the rate of improvement of χ2 with N.
In terms of quantitative improvements in χ2 for a fixed cost (vertical differences between curves), all the rules considered (AU, APC, AEI, ATE) improve substantially upon an equal-N DNS and modestly upon an equal-cost DNS. The size of the advantage varies with N in the way that we expect from boosting: substantial improvements in χ2 with moderate N, (∼5–10) when the DNS has sampled the attractor broadly but sparsely and extremes are within reach by perturbation. The advantage might diminish if N increases enough for DNS to see those extremes without perturbation, but we haven't reached that regime yet. MoCTail and PoPTail performances are similar, but not identical: PoPTail seems more suited for threshold-based rules (AU, APC local and global in b.i–iii), whereas MoCTail seems more suited for optimization-based rules (AEI, ATE in b.iv and v). Another way to measure boosting advantage is by “speedup”: given a prescribed χ2 error, how much extra simulation is needed with DNS relative to boosting to achieve it. These are the horizontal distances between curves. Across all AST criteria, speedup varies from 1.5× to 3×, and accelerates sharply as the DNS curve flattens around while the boosting curves continue to decrease linearly. These are modest speedups compared to other published rare event algorithms, which report between one and four orders of magnitude speedup depending on the event definition and the algorithm (e.g., Ragone and Bouchet, 2021; Finkel and O'Gorman, 2026), but again, we stress that the computational savings here are only incidental to our main goal of characterizing the COAST. Substantial improvements should be possible by targeted optimization and, potentially, repeated rounds of boosting.
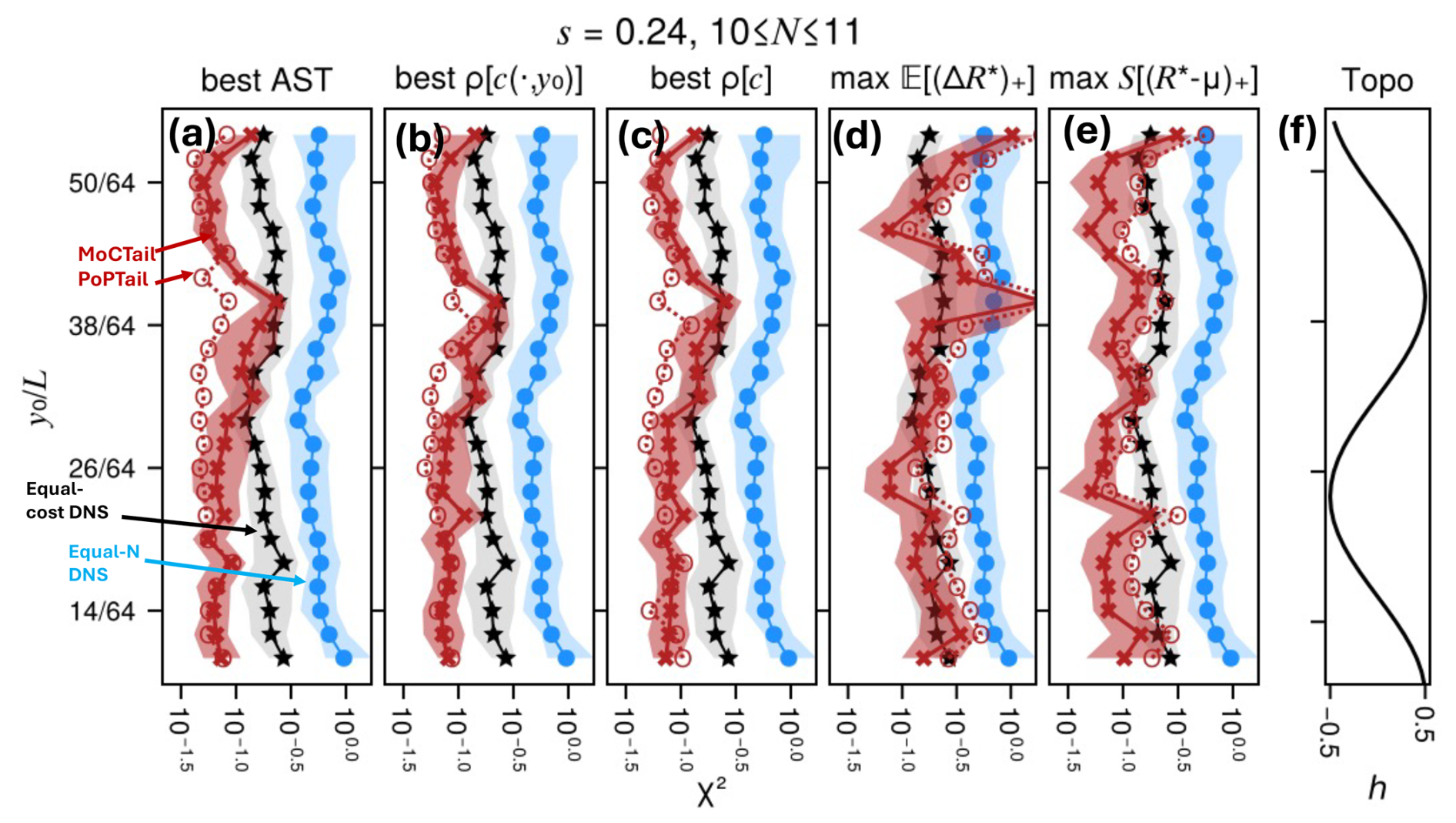
Figure 14Performance of all AST selection criteria, measured by χ2 divergence, across all latitudes for s=0.24 and N=10 or 11, whichever is nearest to 1/3 the number of ancestors found for the latitude in question (sometimes less than 32). Black line and gray envelope represent the error from the short DNS and its 90 % error bar according to quantiles across longitudes. Panels (a)–(e) parallel Fig. 13a.ii–vi. Solid lines and crosses represent the MoCTail estimator, while dotted lines with open circles represent the PoPTail estimator.
We selected N=11 to display the full CCDFs in Fig. 13a as the middle range of values tried, and where enough equal-size ancestor subsets are available for uncertainty quantification by bootstrapping. When comparing with DNS CCDFs, all five rules successfully extend the short, equal-N DNS tail into a longer tail that tracks closer to the ground truth farther into the extreme severity range. They also all find a larger maximum than even the equal-cost DNS found. However, the threshold-based rules exhibit apparent bias, systematically underestimating probabilities for , whereas the optimization-based rules are both more accurate and more confident. Our hypothesis for this behavior is that each ancestor has its own predictability timescale, physically linked to the frequency of the wave responsible for that particular event, and that these ancestor-varying timescales cannot all be respected at once by a single, globally imposed time like AU, or even a globally imposed correlation threshold to dictate APC. The optimization-based criteria AEI and ATE are tailored to the ancestor, and might in fact be choosing those predictability timescales implicitly. This is only speculation, however, and must be validated with more detailed analysis than fits in our present scope.
The COASTs identified by all rules lie strictly between the shortest and longest ASTs considered. For example, AU=14 according to the MoCTail estimator (using all N=32 ancestors). By comparing with Fig. 12c, we recognize 14 as the minimum of the χ2 landscape for s=0.24 (and larger scales), with an approximate local-correlation equivalent of 0.98.
Similar patterns hold across target latitudes, but with some notable caveats. The χ2 divergences of each selection rule are plotted in Fig. 14, of which Fig. 13c is one slice. The most obvious and important point holds: perturbed ensembles improve upon the DNS equal-N estimate, for almost all latitudes and AST selection rules, and they also improve on the equal cost estimate in many cases. But AEI is less reliable; its favorable performance noted above in Fig. 13 is peculiar to the latitude . At some other latitudes, it is similar or worse in skill than equal-N and even equal-cost DNS. Even so, it tends to fail by overestimating severities, which we have confirmed by examining the corresponding CCDFs (not shown), and thus it may serve as a useful upper bound. The MoCTail and PoPTail estimators are similar in quality across latitudes, but as observed in Fig. 13, PoPTail has an advantage with threshold-based rules (AU, APC local and global) whereas MoCTail performs better with optimization-based rules (AEI, ATE).
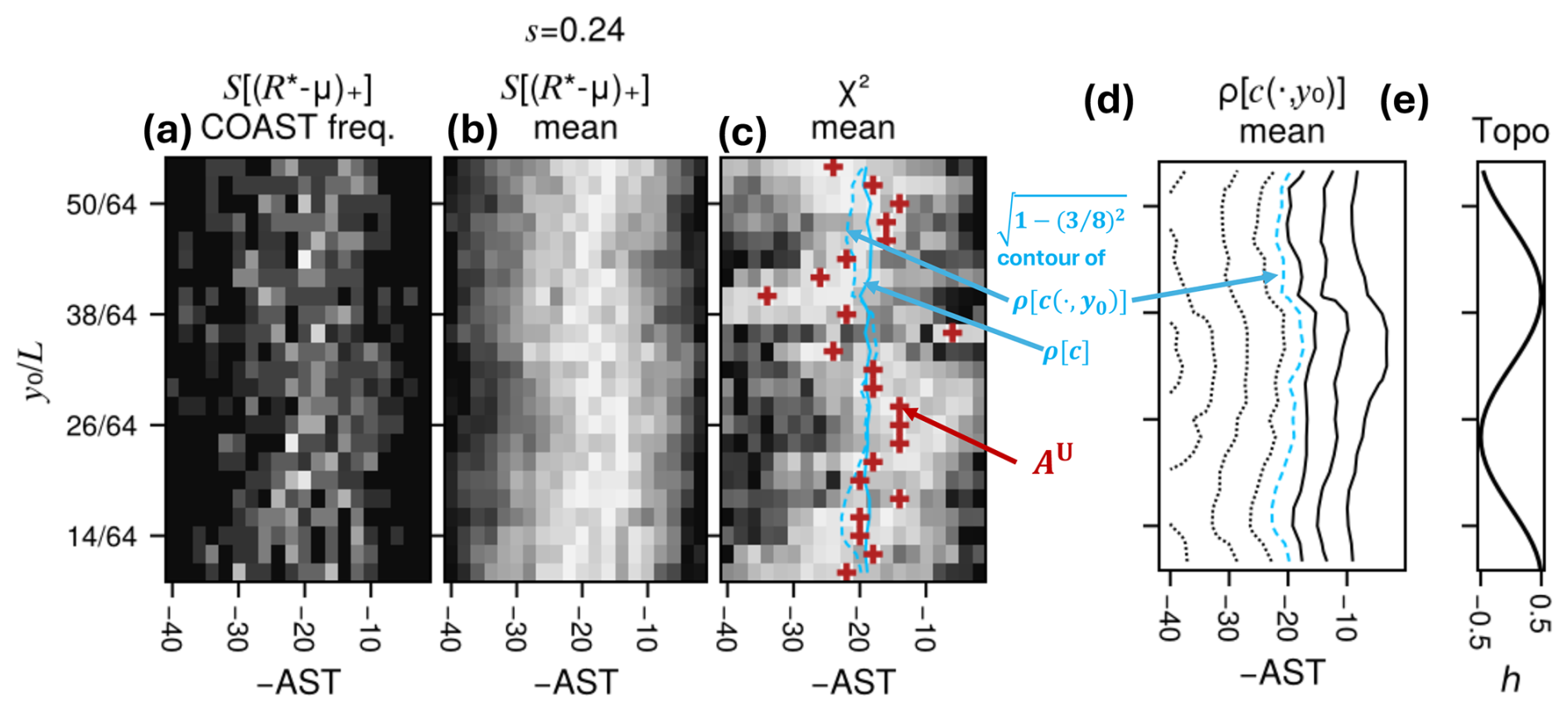
Figure 15Optimization landscapes and optimal ASTs across latitudes, again fixing the input scale to s=0.24. (a) Frequencies of conditionally optimal ASTs (COASTs), in the maximum-thresholded entropy sense, at each latitude, with whiter shading indicating higher frequency. E.g., at , the two adjacent bright pixels at AST =18, 20 indicate that for a large fraction of ancestors, the highest-entropy descendant ensemble is the one launched 18 or 20 d in advance of the peak. (b) Thresholded entropy as a function of AST, normalized to the range 0–1 (black-white, so brighter is better) separately at each latitude. This landscape is smoother than χ2 and varies less dramatically with latitude, but exhibits directionally similar trends. (c) χ2 divergence as a function of AST and latitude, normalized to the range 0–1 (white-black, so brighter is better) separately at each latitude so that different latitudes are visually comparable. Red crosses mark the optimal AST at each latitude. Cyan (solid, dashed) curves mark the AST at which the (global, local) correlations, averaged across ancestors, reach . This nominal choice is based on Finkel and O'Gorman (2024), and falls squarely in the middle of the latitude-dependent ASTs. (d) Contour map of local correlation, averaged over ancestors, as a function of AST and latitude. The levels range from 0.22 (left-most dotted black curve, fragmented by boundary) to 0.99 (rightmost solid black curve), evenly spaced in a stretched sigmoid scale (levels are shown only for qualitative purposes). The reference level appears dashed in cyan. (e) Bottom topography for reference.
The various estimators and AST selection rules have differences in skill, but a more important commonality: all of them indicate that an optimal advance split time exists that is strictly positive, which is not a foregone conclusion in light of standard rare event algorithms like adaptive multilevel splitting (AMS; Lestang et al., 2018) without “trying early”. Figure 12 shows clear intermediate optima when targeting the single latitude , and Fig. 15 extends this result to all latitudes by stacking together cross-sections of the per-latitude counterparts of Fig. 12 at s=0.24. The COAST frequency and mean-TE landscapes have broad ridges that meander slowly in AST space with latitude, approximately in phase with topography: smaller ASTs are favored at , where topography is minimized and meridional wind shear is negative, and larger ASTs are favored at , where topography is maximized and meridional wind shear is positive. A similar pattern, but with bigger swings, is seen in the χ2 landscape. All these patterns are a bit noisy, especially for the COAST frequencies and χ2-COAST locations, since both come from an inherently unstable “argmax” function. Nonetheless, the detailed latitude dependence is only a secondary effect on top of the main point, which is clearly demonstrated: splitting is most effective at intermediate ASTs rather than very short or long ASTs.
We can also now evaluate the rule from Finkel and O'Gorman (2024) in this broader multi-latitude context, though here we simplify the procedure by first averaging ρ across ancestors and then calculating AU as a threshold-crossing time of that average, which we call , rather than averaging times across ancestors. The same conclusion holds either way. The AST values are overlaid on the χ2 heatmap (Fig. 15d) as blue curves. The solid curve, representing a level set of ancestor-averaged global correlation, should be constant with latitude and varies only due to sampling errors. Likewise, the dashed curve, representing a level set of ancestor-averaged local correlation, should be approximately symmetric with respect to latitude because of the symmetric tracer boundary conditions and approximate mirror symmetry in velocities, as should all the level sets in panel c. Since the AU varies differently with latitude, exhibiting roughly odd symmetry about the midline, the rule cannot possibly be optimal for all latitudes simultaneously. More fundamentally, the COAST depends on more than just a generic metric for ensemble dispersion: it must also depend on the features of the tail being sampled, which in this case is the only possible source of meridional variation (see Fig. 4).
However, both versions of run right through the mean position of the meandering χ2 valley and associated COASTs, performing about as well as any such highly-constrained synchronized AU could do. Thus, the rule retains its relevance as a starting point for more refined optimization more tailored to the event, at least for this QG system. Whether the rule generalizes to more heterogeneous systems as the “optimal synchronized AST” requires further investigation. We found it provides some guidance for temperature and precipitation extremes in an idealized general circulation model, but overestimated the optimal AST in both cases (Finkel and O'Gorman, 2026).
Rare event sampling is a promising strategy to study extreme weather more efficiently with computer models by repeatedly cloning, perturbing, and re-simulating the most extreme events in an ensemble while tracking statistical weights. However, sudden and transient events such as mid-latitude precipitation present a particular challenge for rare event algorithms, leaving ensembles little time to diversify before the event passes by. Ensemble boosting (Gessner et al., 2021; Gessner, 2022; Fischer et al., 2023; Bloin-Wibe et al., 2025) and “trying-early adaptive multilevel splitting” (TEAMS; Finkel and O'Gorman, 2024, 2026) get around this problem by perturbing events farther in advance by some advance split time (AST) to allow ensembles to spread, but this opens a pivotal question: how should we choose the AST for maximal accuracy and efficiency? If AST is too short, perturbations cannot grow enough to give useful samples, and if it is too long, they regress to climatology. To deploy advance-splitting methods at scale, we need more reliable ways to set the AST as well as other hyperparameters. The AST itself may be a property of the physical system, not of algorithmic parameters like ensemble size, which would simplify its optimization while also yielding physical insight into causal mechanisms of the event.
In this paper, we have pursued this hypothesis and established the conditionally optimal advance split time (COAST) as a quantity more intrinsic to the dynamical system than to the idiosyncrasies of a particular rare event algorithm by removing the confounding effect of randomly selecting ensemble members to split. The COAST also depends on the target observable of interest, the imposed distribution over perturbations, and the initial conditions which may vary in their predictability. We formulate COAST mathematically as the solution to an optimization problem, and through a systematic boosting-based sampling and estimation procedure we discern the optimization landscape in the context of an idealized physical model: a baroclinically unstable quasi-geostrophic (QG) flow, with local passive tracer fluctuations as our extreme event of interest. To facilitate more efficient rare event sampling applications, we have further proposed various parsimonious rules for finding the COAST, and evaluated these rules empirically in the QG model.
We have four conclusions to report:
-
A boosting procedure, generated with a suitable AST, can well-approximate a probability distribution's tail using either of two estimators: “MoCTail”, which we formulate here, and “PoPTail”, due to Bloin-Wibe et al. (2025).
-
The optimal AST is strictly greater than zero and varies slowly with latitude, appearing smaller in regions of negative meridional wind shear (e.g., the northern edges of westerly jets) and larger in regions of positive meridional wind shear (e.g., the southern edges of westerly jets).
-
Several different rules for selecting the COAST are equally effective. Beyond the simplest option of setting a single fixed AST (called AU), one can set a conditional AST (called APC) by thresholding on ensemble dispersion. Both AU and APC perform similarly at tail reconstruction, but both unfortunately require a threshold choice, which there is no established method for selecting. Here we selected thresholds post hoc with knowledge of the ground truth. The rule proposed in Finkel and O'Gorman (2024)- – that AU≈ the time until ensembles disperse to their saturation value – appears to be a good single choice, but further improvement is possible by tailoring AST to the target location and the initial condition.
-
An attractive alternative to thresholding is optimizing some functional of the ensemble severity distribution designed to favor both high extremes and wide spread. We have found a suitable functional in thresholded entropy (TE), the expected information contained in that part of the ensemble's severity distribution exceeding the pre-selected threshold. Optimization-based AST rules open the door to using Bayesian optimization strategies to home in on the COASTs adaptively during an actual rare event sampling algorithm, avoiding the exhaustive grid searches we have performed here.
There are many important avenues of research indicated by the present study, both methodology-oriented and science-oriented. On the algorithmic front, it remains to be seen whether thresholded entropy succeeds at matching tail statistics in general systems, but the consistency across different targets within the QG model is encouraging. We suspect that some similar objective function over distributions is broadly applicable. Furthermore, the shape of perturbations is a possibly very important lever on the potency of perturbations, acting in concert with their timing. While we limited our present study to a two-dimensional perturbation space based on linearized dynamics about a baroclinically unstable background flow, a natural extension would be to use flow-dependent singular vectors as in operational weather forecasting. By design, they effect faster ensemble spread in the small-perturbation regime; however, it must be checked if their advantages carry into the finite-amplitude regime needed for effective rare event sampling. Computational tools such as adjoints, especially in novel machine learning models, invite the use of gradient-based optimization (Wang et al., 2020; Vonich and Hakim, 2024; Whittaker and Luca, 2025). Since exhaustive grid search over ASTs and perturbation spaces is not an option when deploying rare event algorithms in practice, we are actively pursuing efficient optimization strategies, which are important to make use of this research.
Intriguing dynamical questions also arise from the latitude dependence of the COAST, which can be seen as a predictability index tailored to extremes: how do the physical parameters such as topography, rotation rate, and the spatial domain affect COAST? Is the effect entirely explainable through the extreme value statistics, as we have speculated, or can two similarly shaped tails belie extremely different COAST behavior? These questions merit further parameter exploration, both within and beyond the quasigeostrophic framework. We expect to draw insight from recent theoretical advances relating extreme value theory to the geometry of chaotic attractors (Lucarini et al., 2016).
In summary, our work makes empirical progress on important theoretical and algorithmic questions regarding the probabilities of the most extreme weather events. Perturbed ensemble forecasts of individual weather events are distinct from the climatological distribution, but here we have given quantitative evidence for a relationship between the two – so long as the perturbations are well-timed – that can be exploited for efficient risk analysis via judicious perturbed simulations. Our work has elucidated what it means to be “well-timed”, and furthermore provided quantitative optimization criteria for perturbation timing. Only with this basic pre-requisite information on what to optimize, should we proceed to invest effort into optimizing efficiently.
The schematic in Fig. 1 comes from Langevin dynamics, consisting of a single particle moving in one dimension with position X(t) and momentum Y(t) subject to a potential gradient force, friction, and stochastic Gaussian white-noise forcing W(t):
where the potential function V(x) has a quadratic core and logarithmic wings,
which leads to a heavy-tailed (in x) steady-state probability density for large . Constant parameters are γ=0.05 for friction, m=1.2 for mass, σ=0.005 for stochastic forcing strength, ϵ=0.25 for the extent of the quadratic core of the potential, α=3.1 which sets the tail weight, and which is the inverse temperature.
The code to generate all results, including simulation, statistical analysis, and plotting, is available at the Zenodo repository COAST (https://doi.org/10.5281/zenodo.17355215, justinfocus12, 2025). Justin Finkel is happy to provide guidance on use and extension of the code upon request.
All data used here was generated using the code we have available in the Zenodo repository, COAST, accessible at https://doi.org/10.5281/zenodo.17355215 (justinfocus12, 2025).
JF formulated the initial study, carried out numerical computations, and wrote the initial draft. PO and JF both contributed to refining the methodology and substantially revising the manuscript.
The contact author has declared that neither of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
We thank Glenn Flierl, Andre Souza, and Talia Tamarin-Brodsky for helpful discussions and advice on theoretical and computational aspects of this work. This research is part of the MIT Climate Grand Challenge on Weather and Climate Extremes. Computations were performed on the MIT Engaging cluster.
This research was supported by Schmidt Sciences.
This paper was edited by Stéphane Vannitsem and reviewed by two anonymous referees.
Au, S.-K. and Beck, J. L.: Estimation of small failure probabilities in high dimensions by subset simulation, Probab. Eng. Mech., 16, 263–277, https://doi.org/10.1016/S0266-8920(01)00019-4, 2001. a, b, c
Baars, S., Castellana, D., Wubs, F., and Dijkstra, H.: Application of adaptive multilevel splitting to high-dimensional dynamical systems, J. Comput. Phys., 424, 109876, https://doi.org/10.1016/j.jcp.2020.109876, 2021. a
Berner, J., Fossell, K. R., Ha, S.-Y., Hacker, J. P., and Snyder, C.: Increasing the Skill of Probabilistic Forecasts: Understanding Performance Improvements from Model-Error Representations, Mon. Weather Rev., 143, 1295–1320, https://doi.org/10.1175/MWR-D-14-00091.1, 2015. a
Bloin-Wibe, L., Noyelle, R., Humphrey, V., Beyerle, U., Knutti, R., and Fischer, E.: Estimating return periods for extreme events in climate models through Ensemble Boosting, Weather Clim. Dynam., 6, 1147–1177, https://doi.org/10.5194/wcd-6-1147-2025, 2025. a, b, c, d, e, f, g
Blonigan, P. J., Farazmand, M., and Sapsis, T. P.: Are extreme dissipation events predictable in turbulent fluid flows?, Phys. Rev. Fluids, 4, 044606, https://doi.org/10.1103/PhysRevFluids.4.044606, 2019. a, b
Boulaguiem, Y., Zscheischler, J., Vignotto, E., van der Wiel, K., and Engelke, S.: Modeling and simulating spatial extremes by combining extreme value theory with generative adversarial networks, Environ. Data Sci., 1, e5, https://doi.org/10.1017/eds.2022.4, 2022. a
Bourlioux, A. and Majda, A. J.: Elementary models with probability distribution function intermittency for passive scalars with a mean gradient, Phys. Fluids, 14, 881–897, https://doi.org/10.1063/1.1430736, 2002. a, b
Breitung, K.: SORM, Design Points, Subset Simulation, and Markov Chain Monte Carlo, ASCE-ASME J. Risk Uncertain. Eng. Syst. A, 7, 04021052, https://doi.org/10.1061/AJRUA6.0001166, 2021. a
Castaing, B., Gunaratne, G., Heslot, F., Kadanoff, L., Libchaber, A., Thomae, S., Wu, X.-Z., Zaleski, S., and Zanetti, G.: Scaling of hard thermal turbulence in Rayleigh-Bénard convection, J. Fluid Mech., 204, 1–30, https://doi.org/10.1017/S0022112089001643, 1989. a
Coles, S.: An introduction to statistical modeling of extreme values, in: Springer Series in Statistics, 1st Edn., Springer, ISBN 978-1-85233-459-8, https://doi.org/10.1007/978-1-4471-3675-0, 2001. a, b, c
Cérou, F. and Guyader, A.: Adaptive Multilevel Splitting for Rare Event Analysis, Stoch. Anal. Appl., 25, 417–443, https://doi.org/10.1080/07362990601139628, 2007. a
Dematteis, G., Grafke, T., and Vanden-Eijnden, E.: Extreme Event Quantification in Dynamical Systems with Random Components, SIAM/ASA J. Uncertain. Quant., 7, 1029–1059, https://doi.org/10.1137/18M1211003, 2019. a, b
Diaconescu, E. P. and Laprise, R.: Singular vectors in atmospheric sciences: A review, Earth-Sci. Rev., 113, 161–175, https://doi.org/10.1016/j.earscirev.2012.05.005, 2012. a
Farazmand, M. and Sapsis, T. P.: A variational approach to probing extreme events in turbulent dynamical systems, Sci. Adv., 3, e1701533, https://doi.org/10.1126/sciadv.1701533, 2017. a, b
Farrell, B. F. and Ioannou, P. J.: Generalized Stability Theory. Part I: Autonomous Operators, J. Atmos. Sci., 53, 2025–2040, https://doi.org/10.1175/1520-0469(1996)053<2025:GSTPIA>2.0.CO;2, 1996a. a
Farrell, B. F. and Ioannou, P. J.: Generalized Stability Theory. Part II: Nonautonomous Operators, J. Atmos. Sci., 53, 2041–2053, https://doi.org/10.1175/1520-0469(1996)053<2041:GSTPIN>2.0.CO;2, 1996b. a
Finkel, J. and O'Gorman, P. A.: Bringing Statistics to Storylines: Rare Event Sampling for Sudden, Transient Extreme Events, J. Adv. Model. Earth Syst., 16, e2024MS004264, https://doi.org/10.1029/2024MS004264, 2024. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r
Finkel, J. and O'Gorman, P. A.: Rare Event Sampling for Moving Targets: Extremes of Temperature and Daily Precipitation in a General Circulation Model, J. Adv. Model. Earth Syst., 18, e2025MS005456, https://doi.org/10.1029/2025MS005456, 2026. a, b, c, d, e, f, g
Finkel, J., Gerber, E. P., Abbot, D. S., and Weare, J.: Revealing the Statistics of Extreme Events Hidden in Short Weather Forecast Data, AGU Adv., 4, e2023AV000881, https://doi.org/10.1029/2023AV000881, 2023. a
Fischer, E. M., Beyerle, U., Bloin-Wibe, L., Gessner, C., Humphrey, V., Lehner, F., Pendergrass, A. G., Sippel, S., Zeder, J., and Knutti, R.: Storylines for unprecedented heatwaves based on ensemble boosting, Nat. Commun., 14, 4643, https://doi.org/10.1038/s41467-023-40112-4, 2023. a, b, c
Gálfi, V. M., Bódai, T., and Lucarini, V.: Convergence of Extreme Value Statistics in a Two-Layer Quasi-Geostrophic Atmospheric Model, Complexity, 2017, 5340858, https://doi.org/10.1155/2017/5340858, 2017. a
Gessner, C.: Physical storylines for very rare climate extremes, PhD thesis, ETH Zurich, https://www.research-collection.ethz.ch/entities/publication/2405b8fb-a51d-41df-b4e5-e7afa0a93719 (last access: 17 May 2026), 2022. a, b
Gessner, C., Fischer, E. M., Beyerle, U., and Knutti, R.: Very Rare Heat Extremes: Quantifying and Understanding Using Ensemble Reinitialization, J. Climate, 34, 6619–6634, https://doi.org/10.1175/JCLI-D-20-0916.1, 2021. a, b, c, d
Ghil, M., Yiou, P., Hallegatte, S., Malamud, B. D., Naveau, P., Soloviev, A., Friederichs, P., Keilis-Borok, V., Kondrashov, D., Kossobokov, V., Mestre, O., Nicolis, C., Rust, H. W., Shebalin, P., Vrac, M., Witt, A., and Zaliapin, I.: Extreme events: dynamics, statistics and prediction, Nonlin. Processes Geophys., 18, 295–350, https://doi.org/10.5194/npg-18-295-2011, 2011. a
Giorgini, L. T., Deck, K., Bischoff, T., and Souza, A.: Response Theory via Generative Score Modeling, Phys. Rev. Lett., 133, 267302, https://doi.org/10.1103/PhysRevLett.133.267302, 2024. a
Gollub, J. P., Clarke, J., Gharib, M., Lane, B., and Mesquita, O. N.: Fluctuations and transport in a stirred fluid with a mean gradient, Phys. Rev. Lett., 67, 3507–3510, https://doi.org/10.1103/PhysRevLett.67.3507, 1991. a
Haidvogel, D. B. and Held, I. M.: Homogeneous Quasi-Geostrophic Turbulence Driven by a Uniform Temperature Gradient, J. Atmos. Sci., 37, 2644–2660, https://doi.org/10.1175/1520-0469(1980)037<2644:HQGTDB>2.0.CO;2, 1980. a
Huang, W. K., Stein, M. L., McInerney, D. J., Sun, S., and Moyer, E. J.: Estimating changes in temperature extremes from millennial-scale climate simulations using generalized extreme value (GEV) distributions, Adv. Stat. Climatol. Meteorol. Oceanogr., 2, 79–103, https://doi.org/10.5194/ascmo-2-79-2016, 2016. a
Huser, R. and Wadsworth, J. L.: Advances in statistical modeling of spatial extremes, WIREs Comput. Stat. 14, e1537, https://doi.org/10.1002/wics.1537, 2022. a
Huser, R., Opitz, T., and Wadsworth, J. L.: Modeling of spatial extremes in environmental data science: time to move away from max-stable processes, Environ. Data Sci., 4, e3, https://doi.org/10.1017/eds.2024.54, 2025. a
Jalbert, J., Farmer, M., Gobeil, G., and Roy, P.: Extremes.jl: Extreme Value Analysis in Julia, J. Statist. Softw., 109, 1–35, https://doi.org/10.18637/jss.v109.i06, 2024. a
John, A., Douville, H., Ribes, A., and Yiou, P.: Quantifying CMIP6 model uncertainties in extreme precipitation projections, Weather Clim. Ext., 36, 100435, https://doi.org/10.1016/j.wace.2022.100435, 2022. a
justinfocus12: justinfocus12/COAST: Initial release for submission of BEST COAST paper to NPG, Zenodo [code and data set], https://doi.org/10.5281/zenodo.17355215, 2025. a, b
Kabir, H. M. D., Khosravi, A., Hosen, M. A., and Nahavandi, S.: Neural Network-Based Uncertainty Quantification: A Survey of Methodologies and Applications, IEEE Access, 6, 36218–36234, https://doi.org/10.1109/ACCESS.2018.2836917, 2018. a
Kahn, H. and Harris, T. E.: Estimation of particle transmission by random sampling, series 12, National Bureau of Standards applied mathematics 27–30, https://people.bordeaux.inria.fr/pierre.delmoral/kahn-harris.pdf (last access: 17 May 2026), 1951. a
Lapeyre, G. and Held, I. M.: The Role of Moisture in the Dynamics and Energetics of Turbulent Baroclinic Eddies, J. Atmos. Sci., 61, 1693–1710, https://doi.org/10.1175/1520-0469(2004)061<1693:TROMIT>2.0.CO;2, 2004. a
Leobacher, G. and Pillichshammer, F.: Introduction to quasi-Monte Carlo integration and applications, Springer, ISBN 978-3-032-05446-3, https://doi.org/10.1007/978-3-032-05446-3, 2014. a, b
Lestang, T., Ragone, F., Bréhier, C.-E., Herbert, C., and Bouchet, F.: Computing return times or return periods with rare event algorithms, J. Stat. Mech.: Theory Exp., 2018, 043213, https://doi.org/10.1088/1742-5468/aab856, 2018. a
Linz, M., Chen, G., Zhang, B., and Zhang, P.: A Framework for Understanding How Dynamics Shape Temperature Distributions, Geophys. Res. Lett., 47, e2019GL085684, https://doi.org/10.1029/2019GL085684, 2020. a
Lorenz, E. N. and Emanuel, K. A.: Optimal Sites for Supplementary Weather Observations: Simulation with a Small Model, J. Atmos. Sci., 55, 399–414, https://doi.org/10.1175/1520-0469(1998)055<0399:OSFSWO>2.0.CO;2, 1998. a
Lucarini, V. and Gritsun, A.: A new mathematical framework for atmospheric blocking events, Clim. Dynam., 54, 575–598, https://doi.org/10.1007/s00382-019-05018-2, 2020. a
Lucarini, V., Faranda, D., Moreira Freitas, A. C., Freitas, J. M., Kuna, T., Holland, M., Nicol, M., Todd, M., and Vaienti, S.: Extremes and recurrence in dynamical systems, John Wiley & Sons, https://doi.org/10.1002/9781118632321, 2016. a
Lucente, D., Rolland, J., Herbert, C., and Bouchet, F.: Coupling rare event algorithms with data-based learned committor functions using the analogue Markov chain, J. Stat. Mech.: Theory Exp., 2022, 083201, https://doi.org/10.1088/1742-5468/ac7aa7, 2022. a
Mahesh, A., Collins, W., Bonev, B., Brenowitz, N., Cohen, Y., Elms, J., Harrington, P., Kashinath, K., Kurth, T., North, J., OBrien, T., Pritchard, M., Pruitt, D., Risser, M., Subramanian, S., and Willard, J.: Huge Ensembles Part I: Design of Ensemble Weather Forecasts using Spherical Fourier Neural Operators, arXiv [preprint], https://doi.org/10.48550/arXiv.2408.03100, 2024a. a
Mahesh, A., Collins, W., Bonev, B., Brenowitz, N., Cohen, Y., Harrington, P., Kashinath, K., Kurth, T., North, J., OBrien, T., Pritchard, M., Pruitt, D., Risser, M., Subramanian, S., and Willard, J.: Huge Ensembles Part II: Properties of a Huge Ensemble of Hindcasts Generated with Spherical Fourier Neural Operators, arXiv [preprint], https://doi.org/10.48550/arXiv.2408.01581, 2024b. a
Maiocchi, C. C., Lucarini, V., Gritsun, A., and Sato, Y.: Heterogeneity of the attractor of the Lorenz'96 model: Lyapunov analysis, unstable periodic orbits, and shadowing properties, Physica D, 457, 133970, https://doi.org/10.1016/j.physd.2023.133970, 2024. a
Mohamad, M. A. and Sapsis, T. P.: Sequential sampling strategy for extreme event statistics in nonlinear dynamical systems, P. Natl. Acad. Sci. USA, 115, 11138–11143, https://doi.org/10.1073/pnas.1813263115, 2018. a
Neelin, J. D., Lintner, B. R., Tian, B., Li, Q., Zhang, L., Patra, P. K., Chahine, M. T., and Stechmann, S. N.: Long tails in deep columns of natural and anthropogenic tropospheric tracers, Geophys. Res. Lett., 37, https://doi.org/10.1029/2009GL041726, 2010. a
Norwood, A., Kalnay, E., Ide, K., Yang, S.-C., and Wolfe, C.: Lyapunov, singular and bred vectors in a multi-scale system: an empirical exploration of vectors related to instabilities, J. Phys. A, 46, 254021, https://doi.org/10.1088/1751-8113/46/25/254021, 2013. a
Noyelle, R.: Statistical and dynamical aspects of extreme heatwaves in the mid-latitudes, Theses, Université Paris-Saclay, https://hal.science/tel-04632646 (last access: 17 May 2026), 2024. a, b
O'Gorman, P. A. and Schneider, T.: Scaling of Precipitation Extremes over a Wide Range of Climates Simulated with an Idealized GCM, J. Climate, 22, 5676–5685, https://doi.org/10.1175/2009JCLI2701.1, 2009. a
Panetta, R. L.: Zonal Jets in Wide Baroclinically Unstable Regions: Persistence and Scale Selection, J. Atmos. Sci., 50, 2073–2106, https://doi.org/10.1175/1520-0469(1993)050<2073:ZJIWBU>2.0.CO;2, 1993. a, b
Pavliotis, G. A.: Stochastic processes and applications: diffusion processes, the Fokker-Planck and Langevin equations, in: vol. 60, Springer, https://doi.org/10.1007/978-1-4939-1323-7, 2014. a
Penland, C. and Magorian, T.: Prediction of Niño 3 Sea Surface Temperatures Using Linear Inverse Modeling, J. Climate, 6, 1067–1076, https://doi.org/10.1175/1520-0442(1993)006<1067:PONSST>2.0.CO;2, 1993. a
Phillips, N. A.: The general circulation of the atmosphere: A numerical experiment, Q. J. Roy. Meteorol. Soc., 82, 123–164, https://doi.org/10.1002/qj.49708235202, 1956. a
Pickering, E., Guth, S., Karniadakis, G. E., and Sapsis, T. P.: Discovering and forecasting extreme events via active learning in neural operators, Na. Comput. Sci., 2, 823–833, https://doi.org/10.1038/s43588-022-00376-0, 2022. a
Pons, F. M. E., Yiou, P., Jézéquel, A., and Messori, G.: Simulating the Western North America heatwave of 2021 with analogue importance sampling, Weather Clim. Ext., 43, 100651, https://doi.org/10.1016/j.wace.2024.100651, 2024. a
Pumir, A., Shraiman, B. I., and Siggia, E. D.: Exponential tails and random advection, Phys. Rev. Lett., 66, 2984–2987, https://doi.org/10.1103/PhysRevLett.66.2984, 1991. a
Qi, D. and Majda, A. J.: Predicting fat-tailed intermittent probability distributions in passive scalar turbulence with imperfect models through empirical information theory, Commun. Math. Sci., 14, 1687–1722, 2016. a, b
Qi, D. and Majda, A. J.: Predicting extreme events for passive scalar turbulence in two-layer baroclinic flows through reduced-order stochastic models, Commun. Math. Sci., 16, 17–51, 2018. a, b
Rackauckas, C.: QuasiMonteCarlo.jl, GitHub [code], https://github.com/SciML/QuasiMonteCarlo.jl (last access: 9 May 2025), 2023. a
Ragone, F. and Bouchet, F.: Rare Event Algorithm Study of Extreme Warm Summers and Heatwaves Over Europe, Geophys. Res. Lett., 48, e2020GL091197, https://doi.org/10.1029/2020GL091197, 2021. a
Ragone, F., Wouters, J., and Bouchet, F.: Computation of extreme heat waves in climate models using a large deviation algorithm, P. Natl. Acad. Sci. USA, 115, 24–29, https://doi.org/10.1073/pnas.1712645115, 2018. a, b, c, d, e
Rampal, N., Gibson, P. B., Sherwood, S., Abramowitz, G., and Hobeichi, S.: A Reliable Generative Adversarial Network Approach for Climate Downscaling and Weather Generation, J. Adv. Model. Earth Syst., 17, e2024MS004668, https://doi.org/10.1029/2024MS004668, 2025. a
Rolland, J.: Collapse of transitional wall turbulence captured using a rare events algorithm, J. Fluid Mech., 931, A22, https://doi.org/10.1017/jfm.2021.957, 2022. a
Saha, A. and Ravela, S.: Statistical-Physical Adversarial Learning From Data and Models for Downscaling Rainfall Extremes, J. Adv. Model. Earth Syst., 16, e2023MS003860, https://doi.org/10.1029/2023MS003860, 2024. a
Sapsis, T. P.: Output-weighted optimal sampling for Bayesian regression and rare event statistics using few samples, P. Roy. Soc. A:, 476, 20190834, https://doi.org/10.1098/rspa.2019.0834, 2020. a
Sundar, R., Parashar, N., Blanchard, A., and Dodov, B.: TAUDiff: Improving statistical downscaling for extreme weather events using generative diffusion models, arXiv [preprint], https://doi.org/10.48550/arXiv.2412.13627, 2024. a
Tebaldi, C., Armbruster, A., Engler, H. P., and Link, R.: Emulating climate extreme indices, Environ. Res. Lett., 15, 074006, https://doi.org/10.1088/1748-9326/ab8332, 2020. a
Thompson, A. F.: Jet Formation and Evolution in Baroclinic Turbulence with Simple Topography, J. Phys. Oceanogr., 40, 257–278, https://doi.org/10.1175/2009JPO4218.1, 2010. a
Thompson, V., Dunstone, N. J., Scaife, A. A., Smith, D. M., Slingo, J. M., Brown, S., and Belcher, S. E.: High risk of unprecedented UK rainfall in the current climate, Nat. Commun., 8, 107, https://doi.org/10.1038/s41467-017-00275-3, 2017. a
Tong, S., Vanden-Eijnden, E., and Stadler, G.: Extreme event probability estimation using PDE-constrained optimization and large deviation theory, with application to tsunamis, Commun. Appl. Math. Comput. Sci., 16, 181–225, 2021. a, b
Vandal, T., Kodra, E., Ganguly, S., Michaelis, A., Nemani, R., and Ganguly, A. R.: DeepSD: Generating High Resolution Climate Change Projections through Single Image Super-Resolution, in: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '17, Association for Computing Machinery, New York, NY, USA, 1663–1672, ISBN 9781450348874, https://doi.org/10.1145/3097983.3098004, 2017. a
van den Dool, H. M.: A New Look at Weather Forecasting through Analogues, Mon. Weather Rev., 117, 2230–2247, https://doi.org/10.1175/1520-0493(1989)117<2230:ANLAWF>2.0.CO;2, 1989. a
van Kekem, D. L. and Sterk, A. E.: Wave propagation in the Lorenz-96 model, Nonlin. Processes Geophys., 25, 301–314, https://doi.org/10.5194/npg-25-301-2018, 2018. a
Vonich, P. T. and Hakim, G. J.: Predictability Limit of the 2021 Pacific Northwest Heatwave From Deep-Learning Sensitivity Analysis, Geophys. Res. Lett., 51, e2024GL110651, https://doi.org/10.1029/2024GL110651, 2024. a
Wang, Q., Mu, M., and Sun, G.: A useful approach to sensitivity and predictability studies in geophysical fluid dynamics: conditional non-linear optimal perturbation, Natl. Sci. Rev., 7, 214–223, https://doi.org/10.1093/nsr/nwz039, 2020. a
Watt, R. A. and Mansfield, L. A.: Generative Diffusion-based Downscaling for Climate, arXiv [preprint], https://doi.org/10.48550/arXiv.2404.17752, 2024. a
Webber, R. J., Plotkin, D. A., O'Neill, M. E., Abbot, D. S., and Weare, J.: Practical rare event sampling for extreme mesoscale weather, Chaos, 29, 053109, https://doi.org/10.1063/1.5081461, 2019. a, b, c, d
Whittaker, T. and Luca, A. D.: Constructing Extreme Heatwave Storylines with Differentiable Climate Models, arXiv [preprint], https://doi.org/10.48550/arXiv.2506.10660, 2025. a, b, c
Yang, Y., Blanchard, A., Sapsis, T., and Perdikaris, P.: Output-weighted sampling for multi-armed bandits with extreme payoffs, P. Roy. Soc. A, 478, 20210781, https://doi.org/10.1098/rspa.2021.0781, 2022. a
Yiou, P. and Jézéquel, A.: Simulation of extreme heat waves with empirical importance sampling, Geosci. Model Dev., 13, 763–781, https://doi.org/10.5194/gmd-13-763-2020, 2020. a
Zuckerman, D. M. and Chong, L. T.: Weighted Ensemble Simulation: Review of Methodology, Applications, and Software, Annu. Rev. Biophys., 46, 43–57, https://doi.org/10.1146/annurev-biophys-070816-033834, 2017. a
Zuev, K.: Subset Simulation Method for Rare Event Estimation: An Introduction, arXiv [preprint], https://doi.org/10.48550/arXiv.1505.03506, 2015. a
- Abstract
- Introduction
- Sampling and estimation methodology
- The quasigeostrophic model
- Ensemble design
- Results: conditional severity distributions
- Results: climatological severity distributions
- Conclusion
- Appendix A: Langevin model
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
rare event samplingand
ensemble boosting: lightly perturbing simulated moderate events into more extreme ones. We formulate a new, flexible sampling strategy and characterizes a critical parameter – the
advance split time, dictating when to perturb – in a simple atmospheric turbulence model, with generalizable entropy-based criteria.
- Abstract
- Introduction
- Sampling and estimation methodology
- The quasigeostrophic model
- Ensemble design
- Results: conditional severity distributions
- Results: climatological severity distributions
- Conclusion
- Appendix A: Langevin model
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References