the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Jul 2021
| 30 Jul 2021
Producing realistic climate data with generative adversarial networks
Olivier Pannekoucke
Corentin Lapeyre
Olivier Thual
This paper investigates the potential of a Wasserstein generative adversarial network to produce realistic weather situations when trained from the climate of a general circulation model (GCM). To do so, a convolutional neural network architecture is proposed for the generator and trained on a synthetic climate database, computed using a simple three dimensional climate model: PLASIM.
The generator transforms a “latent space”, defined by a 64-dimensional Gaussian distribution, into spatially defined anomalies on the same output grid as PLASIM. The analysis of the statistics in the leading empirical orthogonal functions shows that the generator is able to reproduce many aspects of the multivariate distribution of the synthetic climate. Moreover, generated states reproduce the leading geostrophic balance present in the atmosphere.
The ability to represent the climate state in a compact, dense and potentially nonlinear latent space opens new perspectives in the analysis and handling of the climate. This contribution discusses the exploration of the extremes close to a given state and how to connect two realistic weather situations with this approach.
- Article
(33811 KB) - Full-text XML
- BibTeX
- EndNote





The ability to generate realistic weather situations has numerous potential applications. Weather generators can be used to characterize the spatio-temporal complexity of phenomena in order, for example, to assess the socio-economical impact of the weather (Wilks and Wilby, 1999; Peleg et al., 2018). However, in numerical weather prediction the dimension of a simulation can be very large: an order of 109 is often encountered (Houtekamer and Zhang, 2016). The small size of ensembles used in data assimilation, due to computational limitations, leads to a misrepresentation of the balance present in the atmosphere such as an increment in the geopotential height, resulting in an unbalanced incremented wind because of localization (Lorenc, 2003). Issues of small finite samples of weather forecast ensembles could be addressed by considering larger synthetic ensembles of generated situations. With current methods it is difficult to generate a realistic climate state at a low computational cost. This is usually done by using analogs or by running a global climate model for a given time (Beusch et al., 2020) but remains costly. Generators can also be used for super resolution so as to increase the resolution of a forecast leading to better results than interpolations (Li and Heap, 2014; Zhang et al., 2012).
The last decade has seen new kinds of generative methods from the machine-learning field using artificial neural networks (ANNs). Among these, generative adversarial networks (GANs) (Goodfellow et al., 2020), and more precisely Wasserstein GANs (WGANs) (Arjovsky et al., 2017), are effective data-driven approaches to parameterizing complex distributions. GANs have proven their power in unsupervised learning by generating high-quality images from complex distributions. Gulrajani et al. (2017) trained a WGAN on the ImageNet database (Russakovsky et al., 2015), which contains over 14 million images with 1000 classes, and successfully learned to produce new realistic images. Several techniques developed for computer vision with GANs seem promising for domains in the geosciences. Notable examples of usage to date include Yeh et al. (2017) to do inpainting, where the objective is to recover a full image from an incomplete one, Ledig et al. (2017) to do super resolution, or Isola et al. (2017) to do image-to-image translation, where an image is generated from another one, e.g., translate an image that contains a horse into one with a zebra.
Data-driven approaches and numerical weather prediction are two domains that share important similarities. Watson-Parris (2021) explains that both domains use the same methods to answer different questions. This study and Boukabara et al. (2019) also show that numerical weather prediction contains lots of interesting challenges that could be tackled by machine-learning methods. It clarifies the growing literature about data-driven techniques applied to weather prediction. Scher (2018) used variational autoencoders to generate the dynamics of a simple general circulation model conditioned on a weather state. Weyn et al. (2019) trained a convolutional neural network (CNN) on gridded reanalysis data in order to generate 500 hPa geopotential height fields at forecast lead times up to 3 d. Lagerquist et al. (2019) developed a CNN to identify cold and warm fronts and a post-processing method to convert probability grids into objects. Weyn et al. (2020) built a CNN able to forecast some basic atmospheric variables using a cubed-sphere remapping in order to alleviate the task of the CNN and impose simple boundary conditions.
While there is a growing interest in using deep-learning methods in weather impact or weather prediction (Reichstein et al., 2019; Dramsch, 2020), few applications have been described using GANs applied to physical fields in recent years (Wu et al., 2020). Notable examples include application to subgrid processes (Leinonen et al., 2019), to simplified models such as the Lorenz '96 model (Gagne et al., 2020) or to data processing like satellite images (Requena-Mesa et al., 2018). In particular, little is known about the feasibility of designing and training a generator that would be able to produce multivariate states of a global atmosphere. A first difficulty is to propose an architecture for the generator, with the specific challenge of handling the spherical geometry. Most of the neural network architectures in computer vision handle regular two-dimensional images instead of images representing projected spherical images. Boundary conditions of these projections are not simple, as the spherical geometry also influences the spread of the meteorological object as a function of its latitude. These effects have to be considered in the neural network architecture. Another difficulty is to validate the climate resulting from the generator compared with the true climate.
In this study, in order to evaluate the potential of GANs applied to the global atmosphere, a synthetic climate is computed using the PLASIM global circulation simulator (Fraedrich et al., 2005a), a simplified but realistic implementation of the primitive equations on the sphere. An architecture is proposed for the generator and trained using an approach based on the Wasserstein distance. A multivariate state is obtained by the transformation of a sample from a Gaussian random distribution in 64 dimensions by the generator. Thanks to this sampling strategy, it is possible to compute a climate as represented by the generator. Different metrics are considered to compare the climate of the generator with the true climate and to assess the realism of the generated states. Because the distribution is known, the generator provides a new way to explore the climate, e.g., simulating the intensification of a weather situation or interpolating two weather situations in a physically plausible manner.
The article is organized as follows. The formalism of WGAN is first introduced in Sect. 2 with the details of the proposed architecture. Then, Sect. 3 evaluates the ability of the generator to reproduce the climate of PLASIM with assessment of the climate states that are produced by the generator. The conclusions and perspectives are given in Sect. 4.
2.1 Parameterizing the climate of the Earth system
The Earth system is considered to be the solution of an evolution equation
where χ denotes the state of the system at a given time and ℳ characterizes the dynamics including the forcing terms, e.g., the solar annual cycle. While χ should stand for continuous multivariate fields, we consider its discretization in a finite grid so that χ∈X with X=ℝn, where n denotes the dimension. Equation (1) describes a chaotic system. The climate is the set of states of the system along its time evolution. It is characterized by a distribution or a probability measure, denoted pclim.
Obtaining a complete description of pclim is intractable due to the complexity of natural weather dynamics and because a climate database, pdata, is limited by numerical resources and is only a proxy for this distribution.
For instance, in the present study, the true weather dynamics ℳ are replaced by the PLASIM model that has been time-integrated over 100 years of 6 h forecasts. Accounting for the spinup, the first 10 years of simulation are ignored. Thus, the climate pclim is approximated from the resulting climate database of 90 years, pdata. The synthetic dataset is presented in detail in Sect. 3.1.
Thus, pdata lives in the n-dimensional space X, but it is non-zero only on an m-manifold 𝕄 (where m≪n) that can be fractal. The objective is to learn a mapping
from Z=ℝm, the so-called latent space, to X. Moreover, g must transform a Gaussian 𝒩(0,Im) to pdata⊂𝕄.
The main advantage of such a formulation is to have a function g that maps a low-dimensional continuous space Z to 𝕄. This property could be useful in the domain of the geosciences, notably in the climate sciences, where a high-dimensional space is ruled by important physical constraints and parameters.
Here the generator is a good candidate for learning the physical constraints that make a climate state realistic without the need to run a complete simulation. The construction of the generator is now detailed.
2.2 Background on Wasserstein generative adversarial networks
To characterize the climate, we first introduce a simple Gaussian distribution of zero mean and covariance the identity matrix Im, defined on the space Z=ℝm, called the latent space. The objective of an adversarial network is to find a nonlinear transformation of this space Z to X as written in Eq. (2) so that the Gaussian distribution maps to the climate distribution, i.e., g#(pz)=pclim, where g# denotes the push forward of a measure by the map g, defined here as follows: for any measurable set E of X, , where g−1(E) denotes the measurable set of Z that is the pre-image of E by g. The latent space, Z, can be seen as an encoded climate space where each point drawn from pz corresponds to a realistic climate state and where the generator is the decoder. Looking for such a transformation is non-trivial.
The search is limited to a family of transformations {gθ} characterized by a set of parameters θ. Thus, for each θ, the nonlinear transform of the Gaussian pz by gθ is a distribution pθ. The goal is then to find the best set of parameters θ* such that , where di is a measure of the discrepancy between the two distributions, so that approximates pclim. This method is known as generative learning, where gθ is implemented as a neural network of trainable parameters θ. Note that, being a neural network, the resulting gθ is then a differentiable function.
Even with this simplified framework, the search for an optimal θ is not easy. One of the difficulties is that the differentiability of gθ requires the comparison of continuous distribution pθ with pclim, which is not necessarily a density on a continuous set. To alleviate this issue, Arjovsky et al. (2017) introduced an optimization process based on the Wasserstein distance defined for the two distributions pclim and pθ by
where Π(pθ,pclim) denotes the set of all joint distributions γ(x,y) whose marginals are, respectively, and . The Wasserstein distance, also called the Earth mover distance (EMD), comes from optimal transport theory and can be seen as the minimum work required (in the sense of mass×transport) to transform the distribution pθ into the distribution pclim. Thus, the set Π(pθ,pclim) can be seen as all the possible mappings, also called couplings, to transport the mass from pθ to pclim. The Wasserstein distance is a weak distance: it is based on the expectation, which can be estimated whatever the kind of distribution. Hence, the optimization problem is stated as
which leads to the WGAN approach.
One of the major advantages of the Wasserstein distance is that it is real-valued for non-overlapping distributions. Indeed, the Kullback–Leibler (KL) divergence is infinite for disjoint distributions, and using it as a loss function leads to a vanishing gradient (Arjovsky et al., 2017). The Wasserstein distance does not exhibit vanishing gradients when distributions do not overlap, as did the KL divergence in the original GAN formulation.
Unfortunately, the formulation in Eq. (3) is intractable. A reformulation is necessary using the dual form discovered by Kantorovich (Kantorovich and Rubinshtein, 1958). Reframing the problem as a linear programming problem yields
where 1−Lipshitzian denotes the set of Lipshitzian functions of coefficient 1, i.e., for any , , being the Euclidian norm of ℝn. For any 1−Lipshitzian function f the computation of Eq. (5) is simple: the first expectation can be approximated by
where the right-hand side is computed as the empirical mean over the climate database pdata that approximates pclim in the weak sense Eq. (6). The second expectation can be computed from the equality
where the expectation of the right-hand side can be approximated by the empirical mean computed from an ensemble of samples of z which are easy to sample due to the Gaussianity.
However, there is no simple way to characterize the set of 1−Lipshitzian functions, which limits the search for an optimal function in Eq. (5). Instead of looking at all 1−Lipshitzian functions, a family of functions {fw} parameterized by a set of parameters w is introduced. In practice, it is engendered by a neural network with trainable parameters w, called the critic.
Finally, if the weights of the network are constrained to a compact space 𝒲, which can be done by the weight-clipping method described in Arjovsky et al. (2017), then {fw}w∈𝒲 will be K-Lipschitzian with K depending only on 𝒲 and not on individual weights of the network. This yields
which tells us that the critic tends to the Wasserstein distance when trained optimally, i.e., if we find the max in Eq. (8) and if f is in (or close to) {fw}w∈𝒲. The weight-clipping method was replaced by the gradient penalty method in Gulrajani et al. (2017) because it diminished the training quality as mentioned in Arjovsky et al. (2017). Because it results from a neural network, any function fw is differentiable, so that the 1−Lipshitzian condition remains to ensure a gradient norm bounded by 1, i.e., for any x∈X, . To do so, Gulrajani et al. (2017) have proposed computing the optimal parameter as the solution of the optimization problem
where L is the cost function
with λ the magnitude of the gradient penalty and where is uniformly sampled from the straight line between a sample from pdata to a sample from pθ (line 8) of Algorithm 1. The optimal solution is obtained from a sequential method where each step is written as
where βk is the magnitude of the step. In an adversarial way, Eq. (10) could be solved sequentially, e.g., by the steepest descent algorithm with an update given by
where αq is the magnitude of the step. We chose to use the two-sided penalty for the gradient penalty method, as it was shown to work well in Gulrajani et al. (2017). At convergence, the Wasserstein distance is approximated by
Hence, the solution of the optimization problem Eq. (4) is obtained from a sequential process composed of two steps, summarized in Algorithm 1. In the first step, the weights of the generator are frozen with a given set of parameters θq and the critic neural network is trained in order to find the optimal parameter solution Eq. (9) (lines 3–11 in Algorithm 1). In the second step, the critic is frozen and the generator is set as trainable in order to compute θq+1 from Eq. (12) (lines 12–17 in Algorithm 1). Note that in Algorithm 1, the steepest descent is replaced by an Adam optimizer (Kingma and Ba, 2014), a particular implementation of stochastic gradient descent which has been shown to be efficient in deep learning.
The following sections will aim to create a climate data generator from the WGAN method. The next section will describe the architecture of the network adapted to the complexity of the dataset used.

2.3 Neural network implementation
WGANs are known to be time-consuming to train, usually needing a high number of iterations due to the alternating aspect of the training algorithm between the critic and the generator. Our initial architecture used a simple convolutional network for both, with a high number of parameters, but it proved difficult to train a fitting multimodal distribution such as green distributions in the left panels in Fig. 15. That is why for this study a ResNet-inspired architecture (He et al., 2016) was chosen. The goal of the residual network is to reduce the number of parameters of the network and avoid gradient vanishing, which is a recurrent problem for deep networks that results in an even slower training.
A network is composed of a stack of layers; when a specific succession of layers is used several times, we can refer to it as a block. The link between two layers is named a connection; a shortcut connection refers to a link between two layers that are not successive in the architecture. A residual block (Figs. 2 and 3) is composed with stacked convolution and a parallel identity shortcut connection. The idea is that it is easier to learn the residual mapping than all of it, so residual blocks can be stacked without observing a vanishing gradient. Moreover, a residual block can be added to an N-layer network without reducing its accuracy because it is easier to learn F(x)=0 by setting all the weights to 0 than it is to learn the identity function. Residual blocks allow building of deeper networks without loss of accuracy.
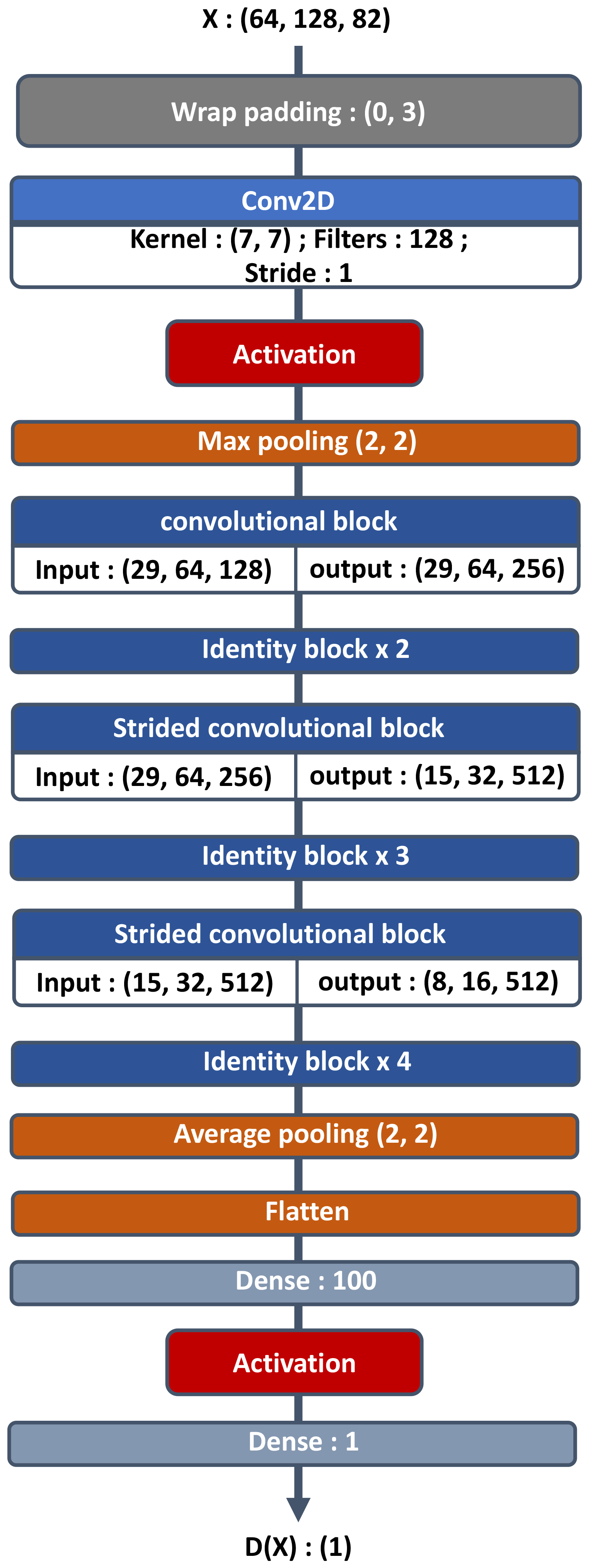
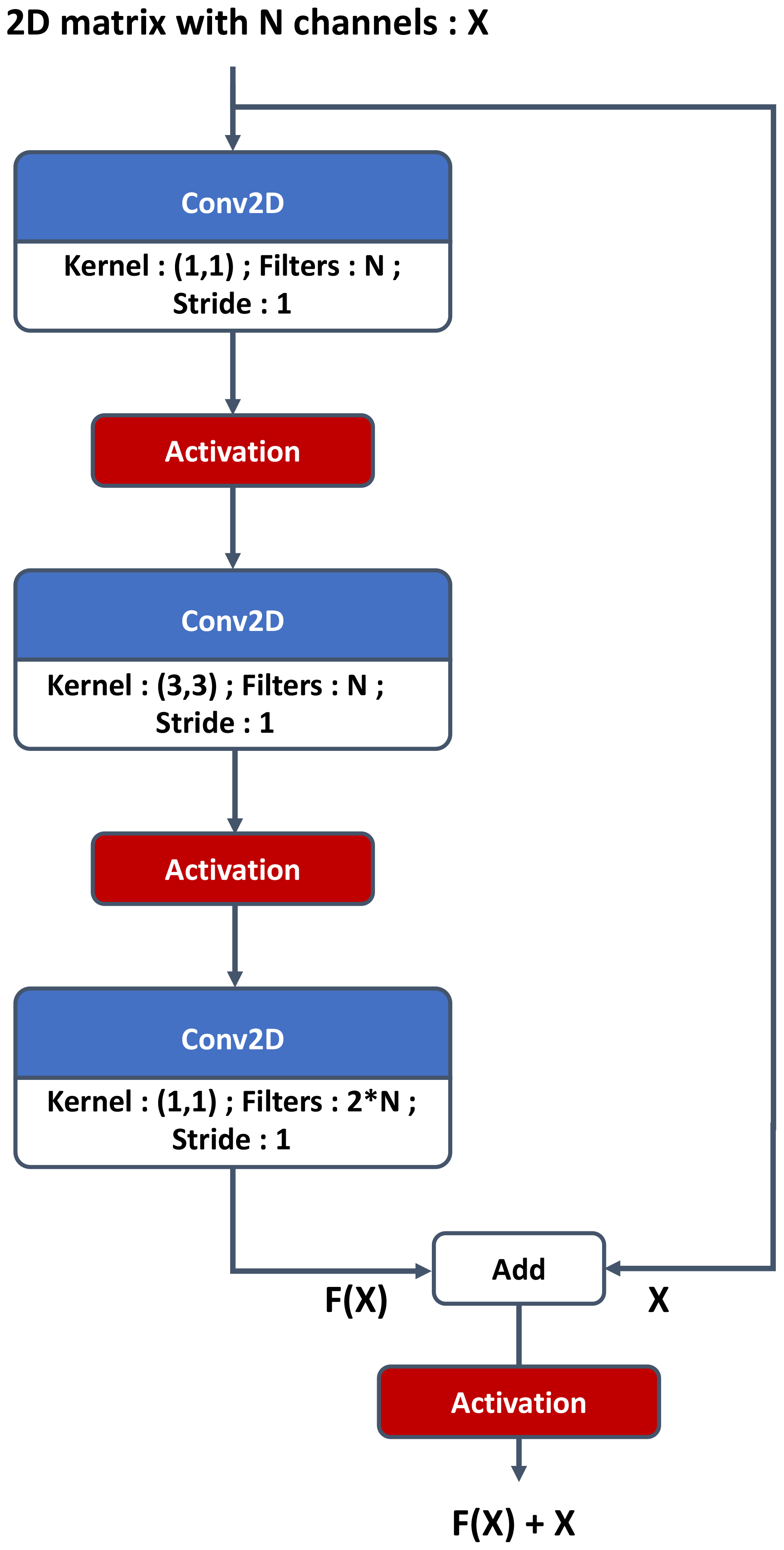
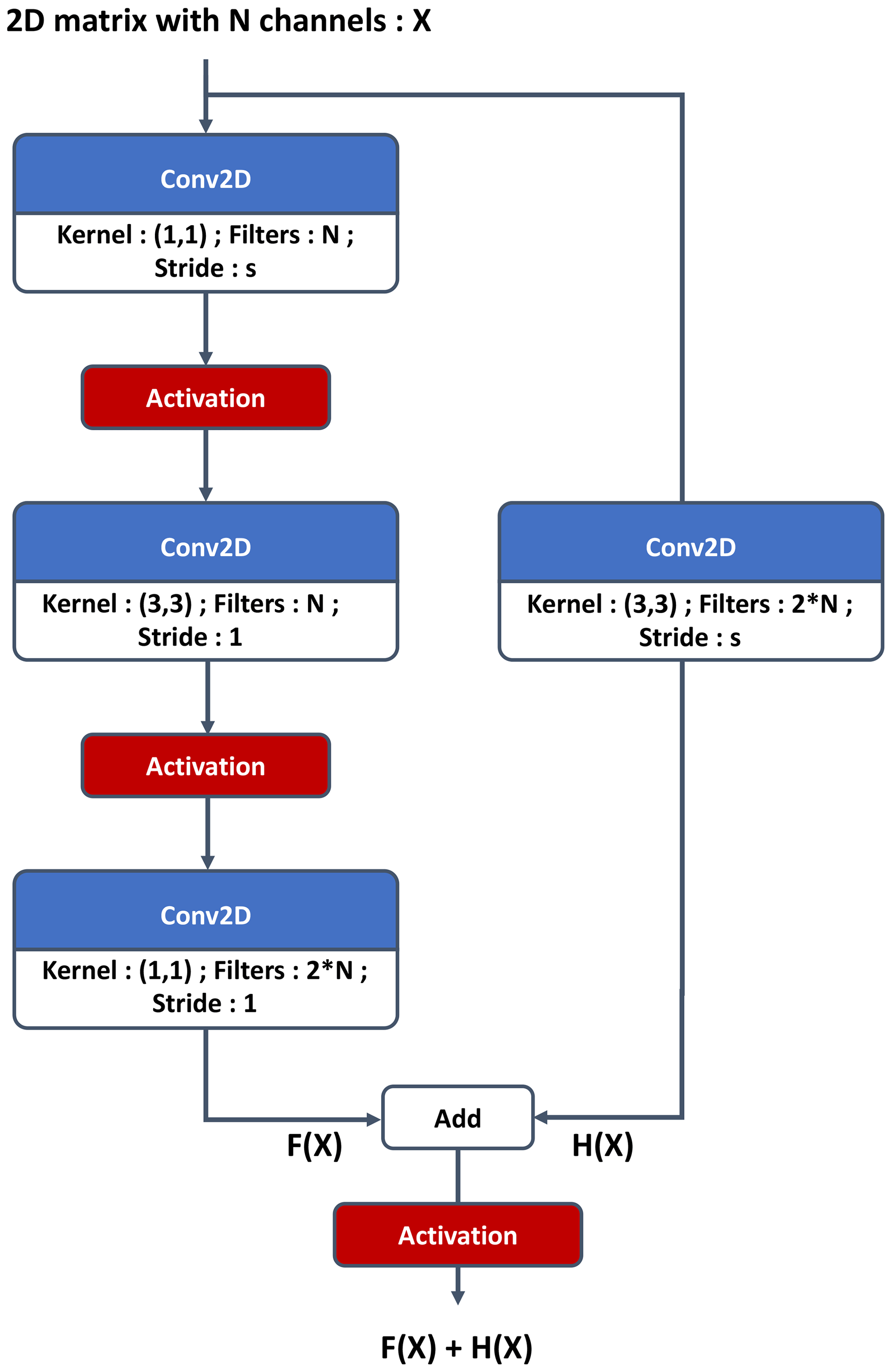
Figure 3Residual convolutional block for the critic. If s is different from 1, it is referenced as a strided convolutional block in Fig. 1.
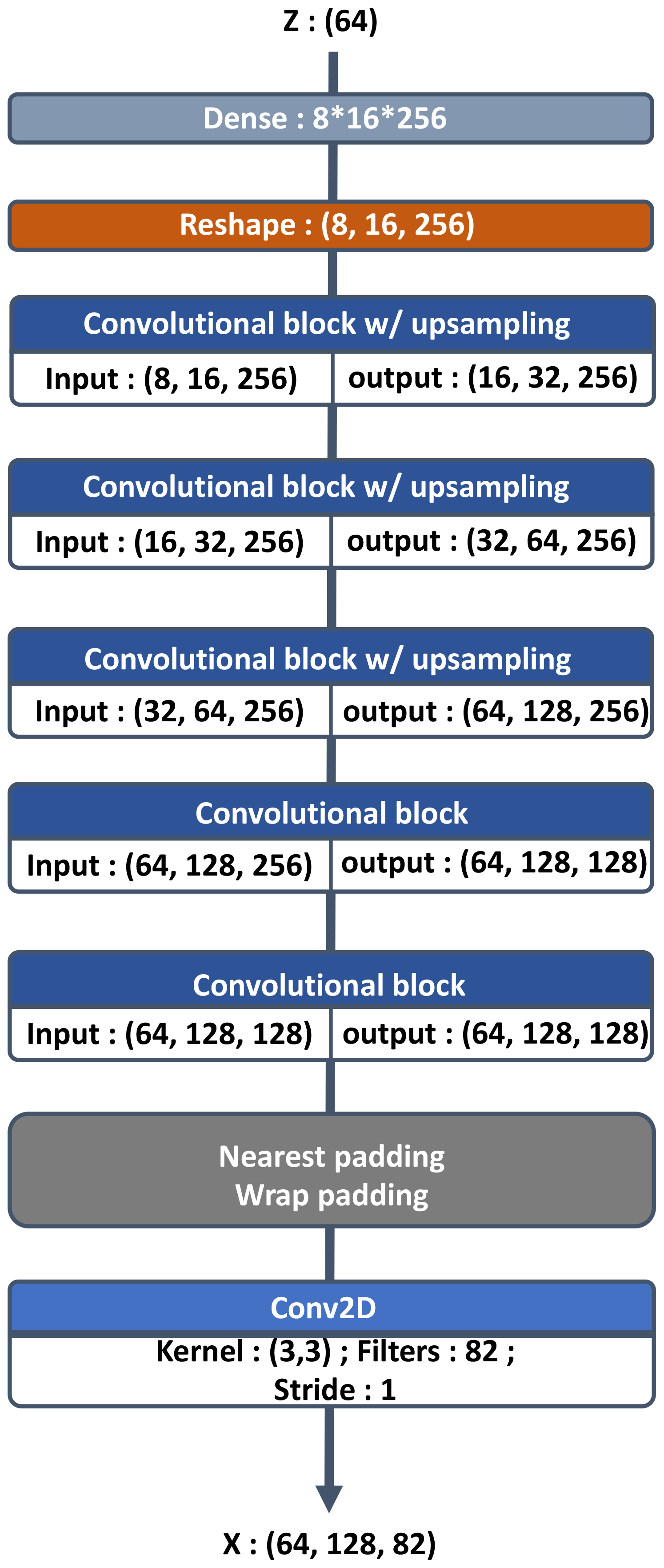
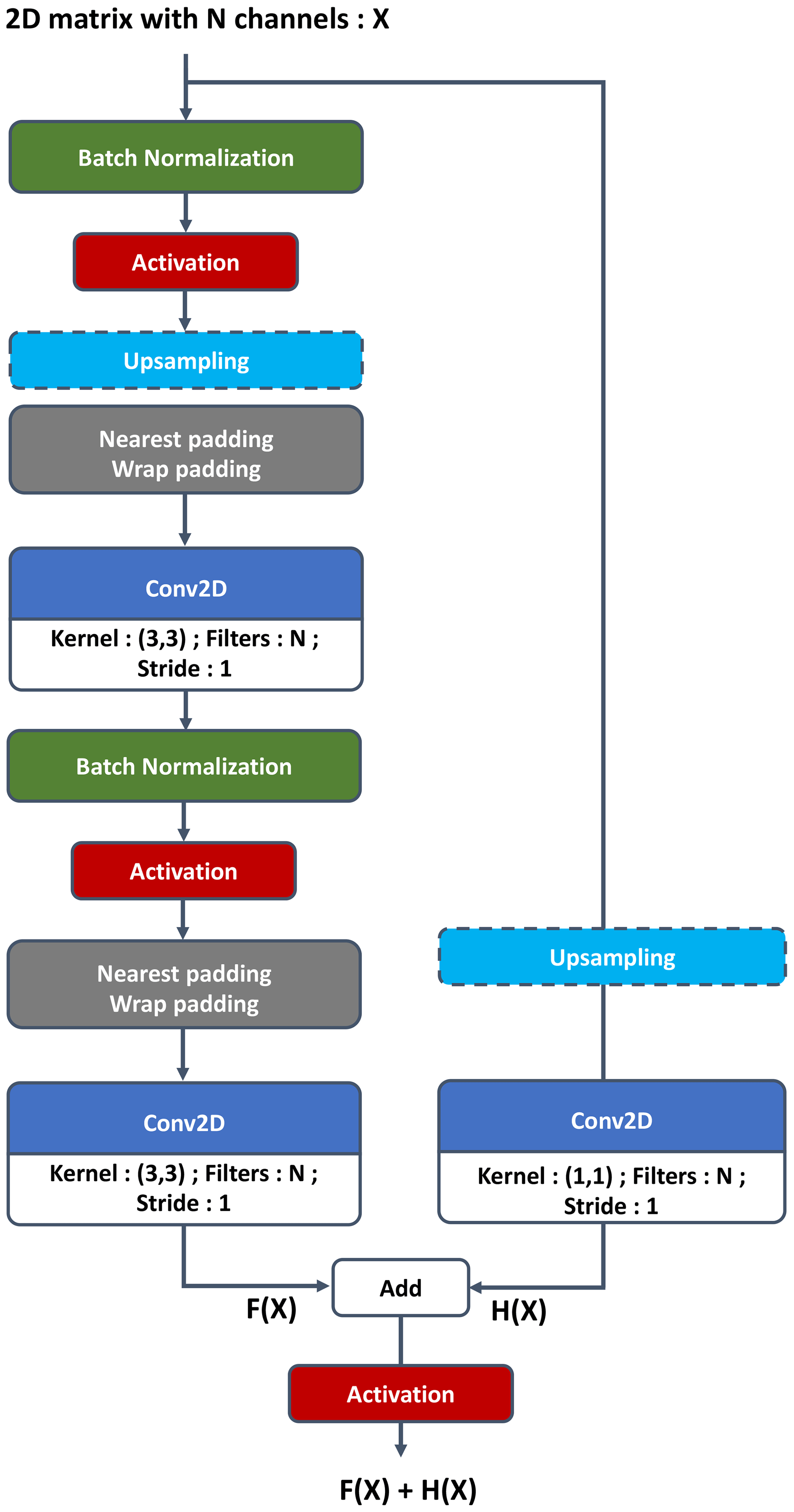
Figure 5Residual convolutional block for the generator. The upsampling layer can be removed if not necessary and is mentioned when used in Fig. 4.
One should note that the PLASIM simulator is a spectral model run on a Gaussian grid that consequently enforces the periodic boundary condition. In order to impose the periodic boundary condition in the generated samples, it was necessary to create a wrap padding layer, which takes multiple columns at the eastern side and concatenates them to the western side and vice versa. In the critic, the wrap padding is only after the input, since the critic will discriminate the images from the generator that are not continuous in the west–east direction. In the generator, the wrap padding layer is in every residual block; it is necessary because the reduced size of the convolution kernel compared to the image size makes it more difficult for the network to extract features from both sides of the image simultaneously. The north–south boundary is padded by repeating the nearest line, called the nearest padding layer. In Figs. 1–5 padding layer arguments have to be understood as (longitude direction, latitude direction), where the integer means the number of columns or rows to be taken from each side and placed next to the other one; e.g., Wrappadding (0,3) means the output image is six columns larger than the input. If the argument is not mentioned, then the arguments for wrap and nearest padding are (0,1) and (1,0), respectively.
2.3.1 Critic network
The critic network input has the shape of a sample from the dataset .
Its output must be a real number because it is an approximation of the Wasserstein distance between the distribution of the batch of images from the dataset and the one from the generator that is being processed. The architecture ends with a dense layer of one neuron with linear activation. The core of the structure is taken from the residual network and can be seen in Fig. 1. After the custom padding layers mentioned previously, the critic architecture is a classical residual network, starting with a convolution with 7 × 7 kernels, followed by a maximum pooling layer to reduce the image size and a succession of convolutional and identity blocks (Figs. 2 and 3). At each strided convolutional block, s=2 in Fig. 3, the image size is divided by a factor 2. It is equivalent to a learnable pooling layer that can increase the result (Springenberg et al., 2014). Finally, an average pooling is done, and the output is fed to a fully connected layer of 100 neurons and then to the output neuron. Batch normalization is not present in the critic architecture following Gulrajani et al. (2017); the batch normalization changes the discriminator's problem by considering all of the batch in the training objective, whereas we are already penalizing the norm of the critic's gradient with respect to each sample in the batch.
2.3.2 Generator architecture
The input of the generator network (see Fig. 4) is an m-dimensional vector containing noise drawn from the normal distribution 𝒩m(0,Im) for the numerical experiment m=64. The output of the generator has the shape of a sample of the dataset . The input is passed through a fully connected layer of output shape and fed to residual blocks. The rest of its architecture is also a residual network with a succession of modified convolutional blocks (relative to the one in the critic network). Modifications of the convolutional block are the following.
-
An upsampling layer is added to increase the image size for some convolutional blocks.
-
Wrap and nearest padding layers are added in, respectively, the west–east and north–south directions.
-
A batch normalization layer is present after convolutional layers.
One could argue that the ReLU activation function is not differentiable in 0, but this is managed by taking the left derivative in the software implementation. The study does not claim that the network architectures used are optimal: the computational burden was too high to run a parameter sensitivity study. Guidelines from Gulrajani et al. (2017) were followed, and the hyperparameters were adapted to the current problem. It showcases an example of hyperparameters producing interesting results, and inspired readers are encouraged to modify and improve this architecture.

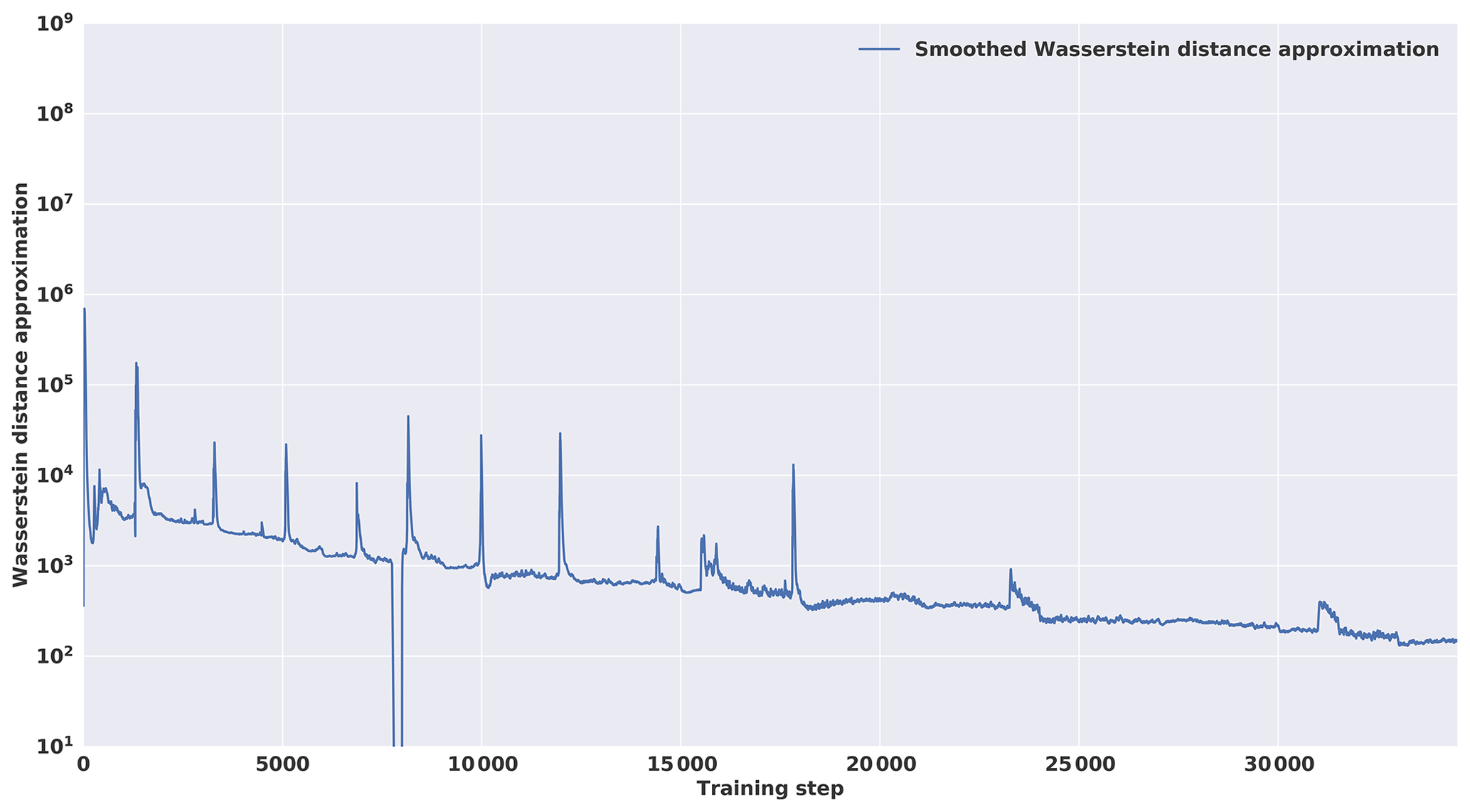
Figure 6Smoothed version of the Wasserstein distance computed during the training. The vertical axis is in log scale.
2.3.3 Training parameters
For the training phase, the neural network's hyperparameters are summarized in Table 1. The training was performed on an Nvidia Tesla V100-SXM2 with 32 GB of memory over 2 d. The choice of the optimizer, initial learning rate, weight of gradient penalty (λ in Eq. 10) and ratio between critic and generator iteration was directly taken from Gulrajani et al. (2017). The iterations mentioned in Table 1 are the number of batches seen by each neural network.
The training loss in Fig. 6 was smoothed using exponential smoothing:
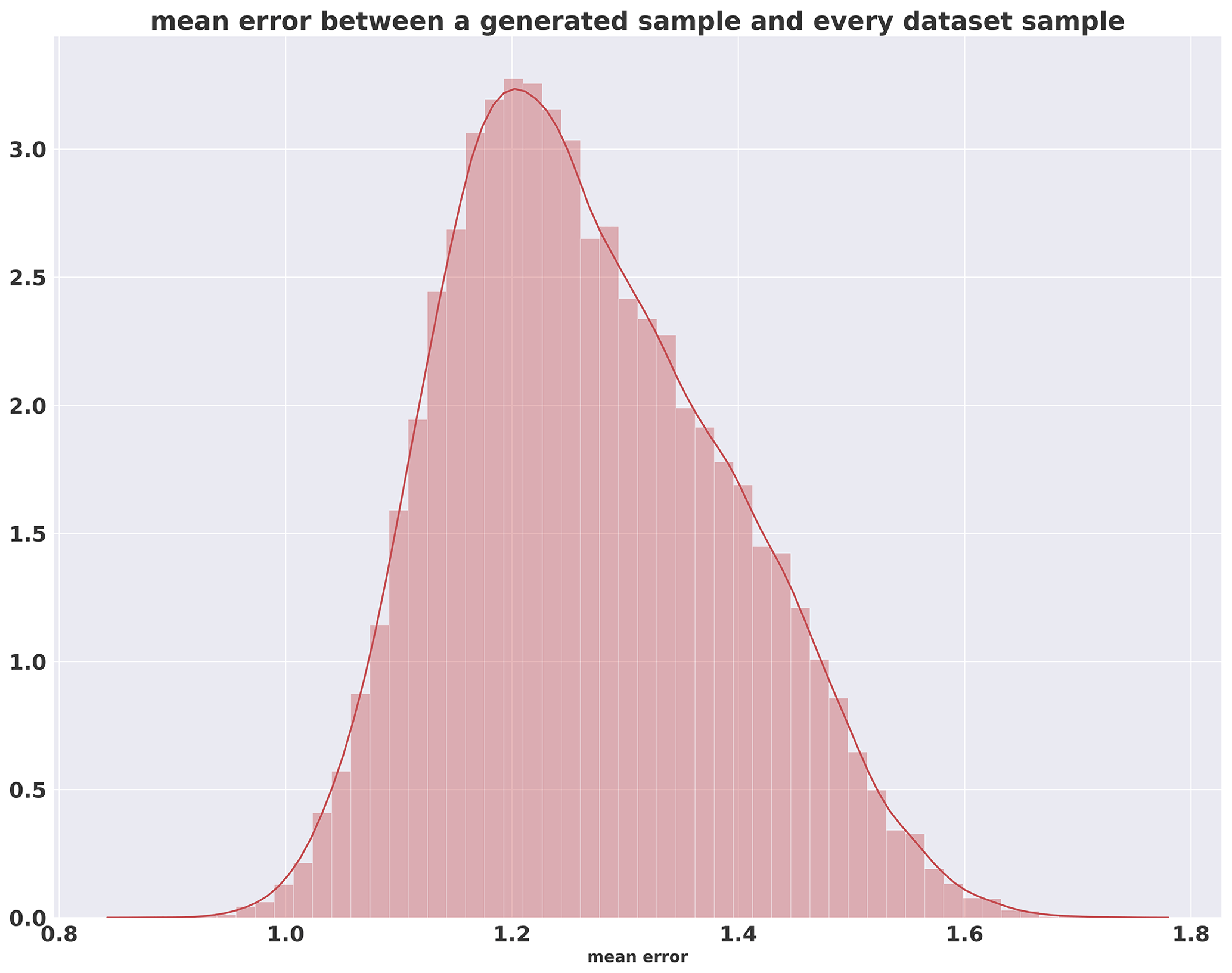
where yt is the value of the original curve at index t, st is the smoothed value at index t and α is the smoothing factor (equal to 0.9 here). An initial spinup of the optimization process tends to exhibit an increase in the loss of the first steps of the training phase before decreasing. This can be explained by the lack of useful information in the gradient due to the initial random weights in the network. A decrease in the Wasserstein distance can be seen in Fig. 6, which indicates a convergence during the training phase, although it is possible to use the loss of the critic as a convergence criterion because the Wasserstein loss is used and has a mathematical meaning such as the distance between synthetic and real data distributions and should converge to 0. However, WGAN-GP is not yet proven to be locally convergent under proper conditions (Nagarajan and Kolter, 2017); the consequence is that it can cycle around equilibrium points and never reach a local equilibrium. Condition on loss derivative is also difficult because of the instability of the GAN training procedure. Consequently, a quality check using metrics adapted to the domain on which the GAN is applied is still necessary. Moreover, at the end of the training, a first experiment was conducted to see whether the generations are present in the dataset. The histogram of the Euclidian distance divided by the number of pixels in one sample between one generation and all of the dataset can be seen in Fig. 7. Here, one can see that the minimum is around 0.8, which shows that the generated image is not inside the dataset. This experiment shows that the generator is able to generate samples without reproducing the dataset. It should be noted that in the WGAN framework, the generator never directly sees a sample from the dataset.
There are no stopping criteria for the training, and it was stopped after 35 000 iterations in the interest of computational cost. It should be highlighted that the performance of generative networks and especially GANs is difficult to evaluate. In the deep-learning literature, the quality of the images generated is assessed using a reference image dataset such as ImageNet (Russakovsky et al., 2015) and computing the inception score (IS) or the Fréchet inception distance (FID). Both use the inception network trained on ImageNet: the IS measures the quality and diversity of the images by classifying them and measuring the entropy of the classification, while the FID computes a distance between the features extracted by the inception network and is more robust to GAN-mode collapse.
Because our study does not apply to the ImageNet dataset, it is necessary to compute our own metrics. Section 3 proposes an approach for this kind of method in the domain of geosciences and more precisely the study of atmospheric fields. Our main objective is to assess the fitting quality of the dataset climate distribution.
The metrics by which the results will be analyzed are visual aspects, capacity to generate atmospheric balances and statistics of the generations compared to climate distribution. For the latter, the chosen metric is the Wasserstein distance. Because it is the same metric the generator has to minimize during the training step, it seems a good candidate to assess the training quality. One could argue that the network is overly trained on this metric; that is why we use other metrics such as mean and standard deviation differences and singular value decomposition to complete our analysis. Finally, because no trivial stop criteria are available, it is interesting to see where the magnitude of the Wasserstein distance is large so as to diagnose some limitations of the trained generator that would provide some ideas of improvements.
3.1 Description of the synthetic dataset
To create synthetic data, a climate model known as PLASIM (Fraedrich et al., 2005a) was used, which is a general circulation model (GCM) of medium complexity based on a simplified general circulation model PUMA (Portable University Model of the Atmosphere) (Fraedrich et al., 2005b). This model based on primitive equations is a simplified analog for operational numerical weather prediction (NWP) models. This choice facilitates the generation of synthetic data thanks to its low resolution and reasonable computational cost. Different components can be added to the model in order to improve the circulation simulation such as the effect of ocean with sea ice, orography with the biosphere or annual cycle.
A 100-year daily simulation was run at a T42 resolution (an approximate resolution of 2.8∘). We used orography and annual cycle parameterization; ocean and biosphere modelization were turned off in order to keep the dataset simple enough for our exploratory study. We removed the first 10 years in order to keep only the stationary part of the simulation. These resulting 90 years of simulation constitute the sampling of the climate distribution that we aim to reproduce. As preprocessing, each of the channels was normalized.
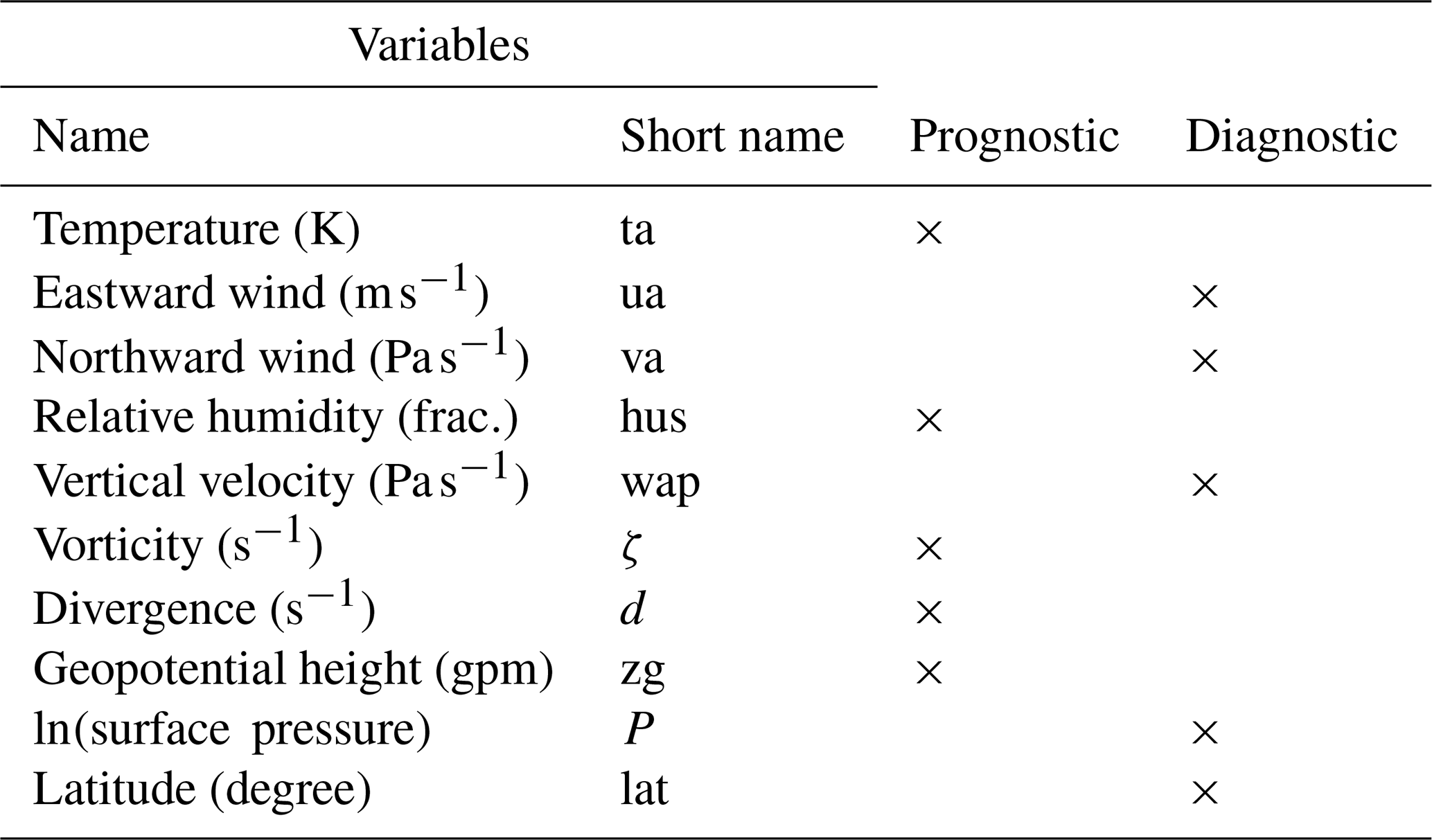
Each database sample is an 82-channel (nfield) two-dimensional matrix of size 64 (nlat) by 128 (nlon) pixels. The channels represent seven physical three-dimensional variables: the temperature (ta), the eastward (ua) and northward (va) wind, relative humidity (hus), vertical velocity (wap), the relative vorticity (ζ), divergence (d) and geopotential height (zg) at 10 pressure levels from 1000 to 100 hPa, plus the surface pressure (ps). Another channel was added to represent the latitude: it is an image going from −1 at the top of the image (North Pole) to 1 at the bottom (South Pole) in every column. It was found that hard coding the latitude in the data improved the learning of physical constraints, allowing the network to be sensitive to the fact that the data are represented by the equirectangular projection of the atmospheric physical fields, and, for example, the size of meteorological objects increases closer to the poles. Finally, the choice of having diagnostic variables in the dataset was to help the post-processing, and assessment of their necessity requires further research.
3.2 Comparison between climate dataset and generated climate
Our study aims to have a generator able to reproduce the climate distribution present in the dataset made from the low-resolution GCM PLASIM. This section proposes a way to assess the quality of the distribution learned by the WGAN.
The first required property for a weather generator is a low computational cost compared to the GCM that produced the data. Here the simulation with the GCM PLASIM took 50 min for a 100-year simulation in parallel on 16 processors, whereas the generator took 3 min to generate 36 500 samples equivalent to a 100-year simulation on an NVIDIA Tesla V-100.
Each generated sample is compared with dataset samples. Figures 8 and 9 show a sample where only the pressure levels 1000, 500 and 100 hPa are represented for readability. It should be noted that the generated fields seem to be spatially noisy compared to the dataset. The periodic boundary is respected knowing that in the dataset the borders are located at the longitude 0∘ where no discontinuities can be observed. In the figures, the image is translated in order to have Europe at the center of the image and to see whether some discontinuities remain.
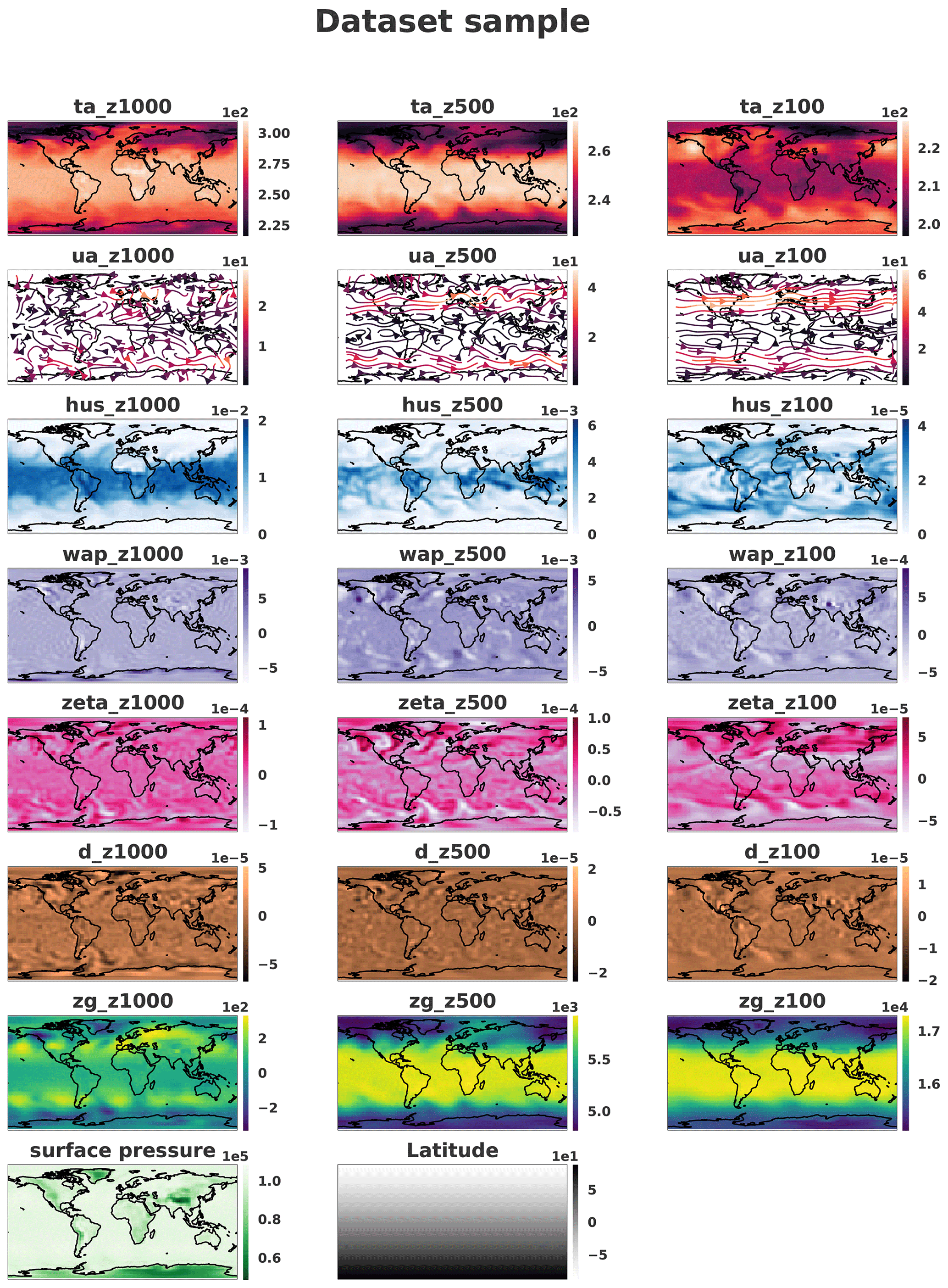
Figure 8Sample on three different pressure levels (1000, 500 and 100 hPa) taken from the dataset. The samples were horizontally transposed in order to have Europe at the center of the images. Coastlines were added a posteriori for readability. Units available in Table 2.
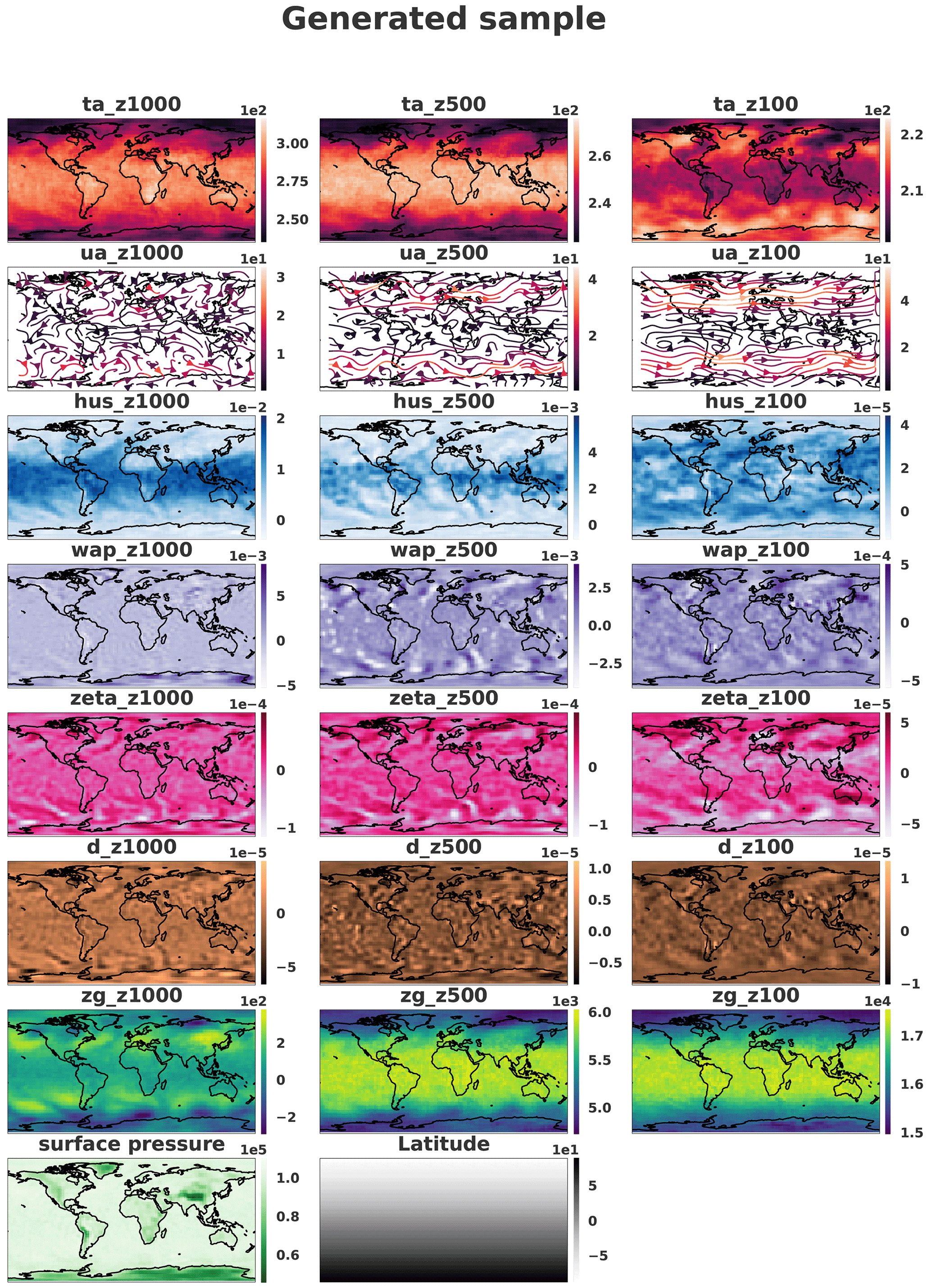
Figure 9Sample on three different pressure levels (1000, 500 and 100 hPa) generated by the network. The samples were horizontally transposed in order to have Europe at the center of the images to verify the quality of the periodic boundary. Coastlines were added a posteriori for readability.
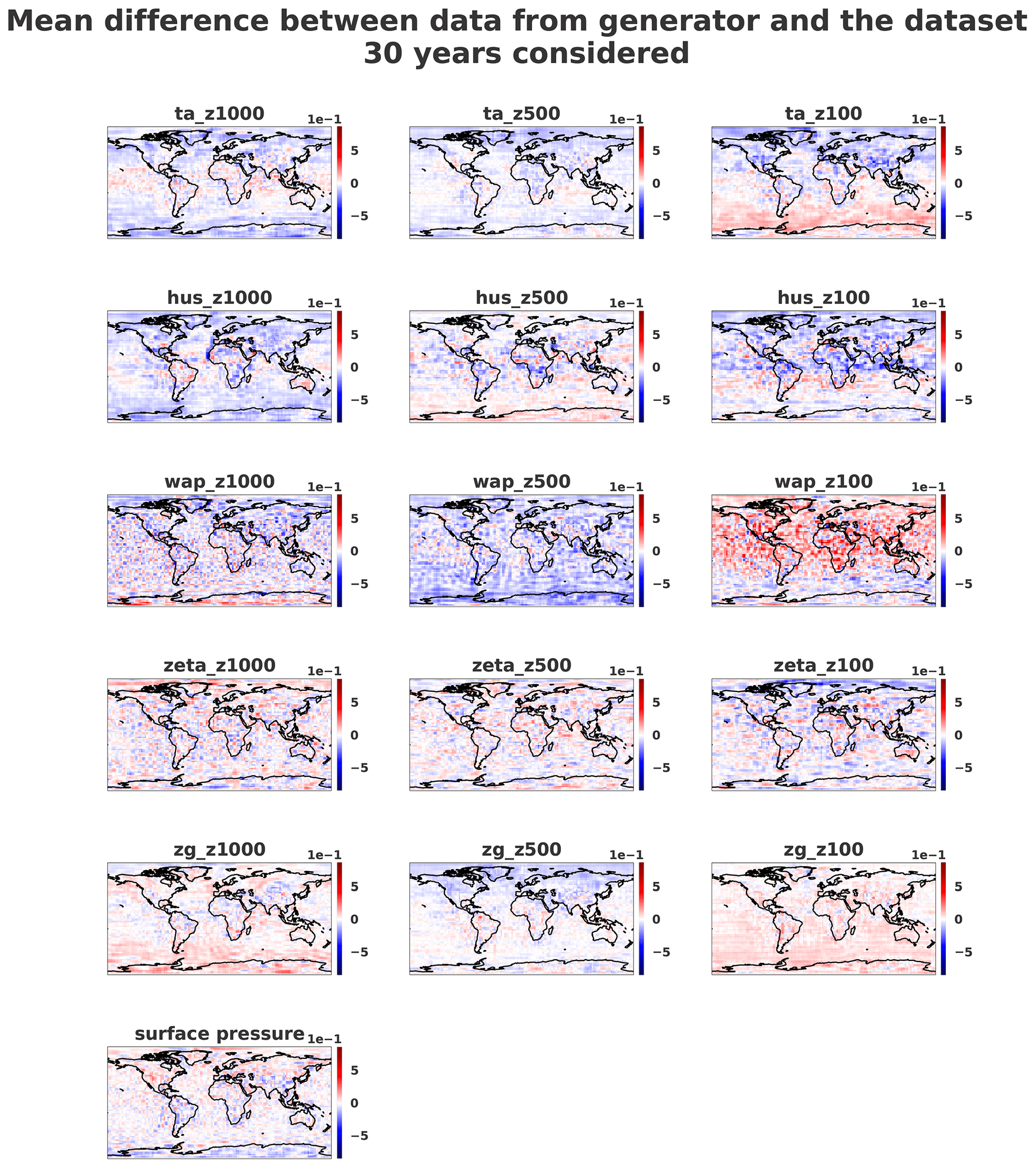
Figure 10Mean error over 30 years of the normalized dataset and the same number of normalized generated samples on three different pressure levels (1000, 500 and 100 hPa). The samples were horizontally transposed in order to have Europe at the center of the images. Coastlines were added a posteriori for readability.

Figure 11Standard deviation error over 30 years of the normalized dataset and the same number of normalized generated samples on three different pressure levels (1000, 500 and 100 hPa). The samples were horizontally transposed in order to have Europe at the center of the images. Coastlines were added a posteriori for readability.
In order to quantitatively assess the generator quality, Figs. 10 and 11 show the mean and standard deviation pixel-wise differences over 10 800 samples (equivalent to 30 years of data) between normalized dataset and generations. It appears that fields where small-scale patterns are present are the most difficult to fit for the generator.
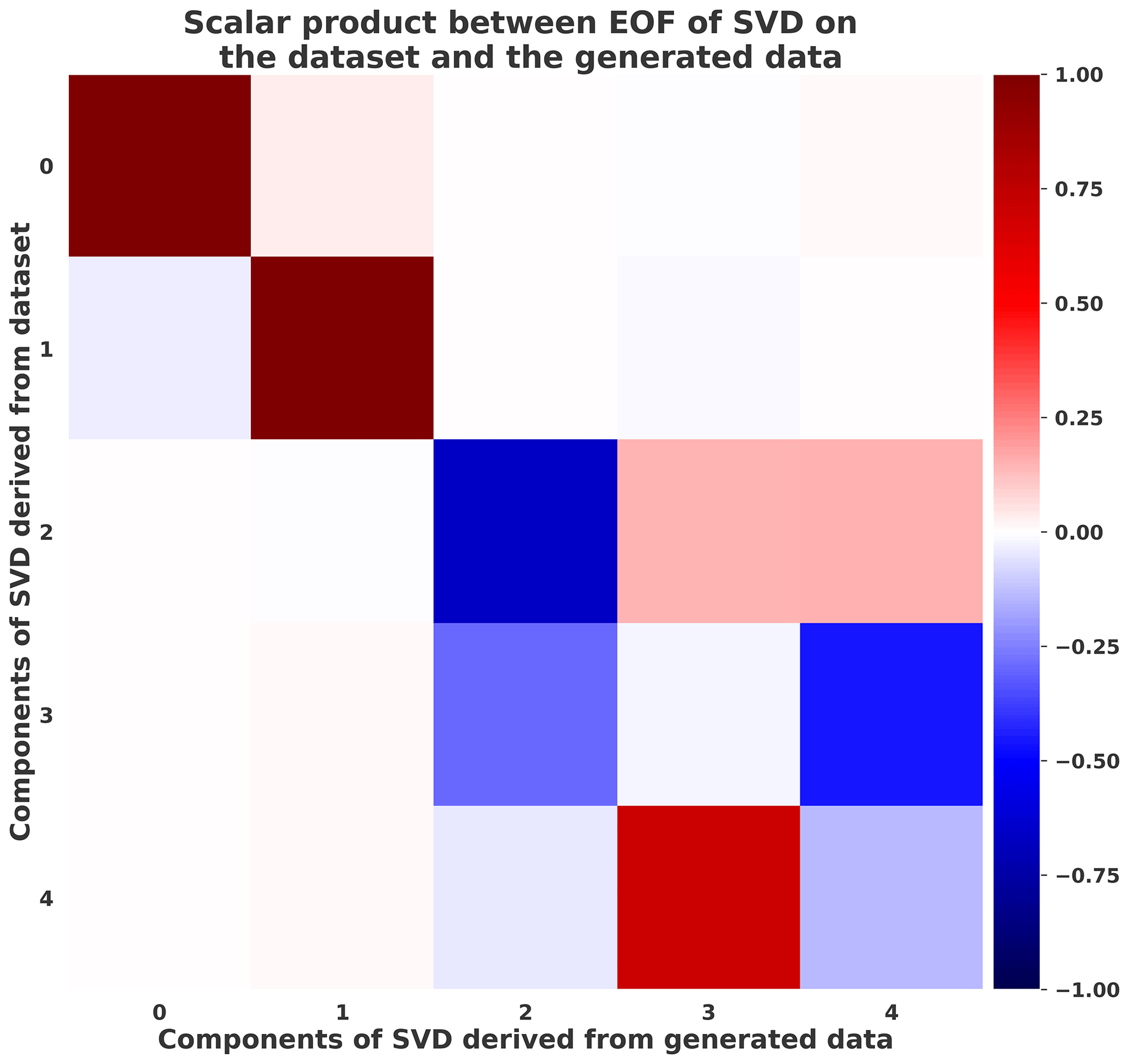

Figure 13Spatial components corresponding to principal components of SVDs applied to the dataset and the generated samples.
In order to go further in the analysis of the generated climate states, a singular value decomposition (SVD) was performed over 30 years of the dataset (renormalized over the 30 years). Then the same number of generated data was considered and projected onto the five first principal components of the SVD that represent 75 % of explained variance of the dataset. In Fig. 12 the dot product is represented between SVD components derived from the dataset and another one derived from the generated data . Figure 12 represents the cross-covariance matrix defined by . Values close to 1 or −1 show that the eigenvectors for both datasets (original and generated) are similar. This is another way of assessing whether the covariance structure of the original data is being preserved, and Fig. 12 shows that the five eigenvectors are similar. One should note that the SVD algorithm used from Pedregosa et al. (2011) suffers from sign indeterminacy, meaning that the signs of SVD components depend on the random state and the algorithm. For this reason, we consider the dot product close to both 1 and −1. One should note that an inversion remains between the components with indexes 3 and 4, which could be explained by a difference of eigenvalue order (sorted in decreasing order) in each dataset that determines the order of eigenvectors. The fourth principal direction (index 3 in the figure) of the generated data represents more variation of the generated dataset than the same direction explains variation in the original dataset. Figure 13 shows clearly the inversion of the last principal components between the dataset and generations. This suggests a way of improving our method in future work.

Figure 14Location from where the temperature distributions are plotted in Fig. 15. The Wasserstein distance value associated for each plot was computed on normalized data.
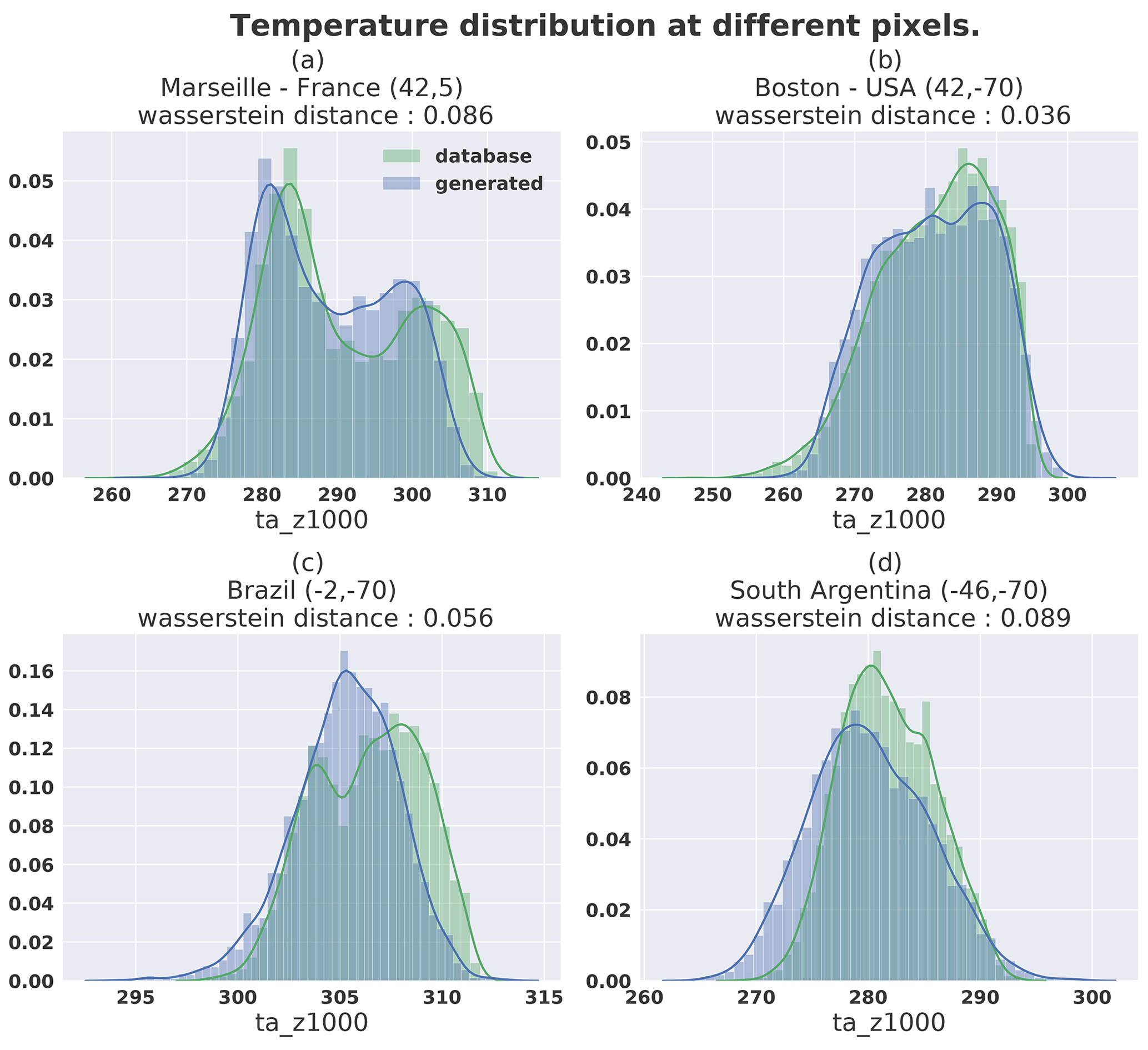
Figure 15Temperature distribution at different locations for 5000 samples from dataset (green) and generated (blue).
Figure 15 shows the temperature (at the pressure level 1000 hPa) distribution at different pixel locations corresponding to the red dots in Fig. 14. Different latitudes (42, −2 and −70∘) were chosen to represent diverse distributions. A value of Wasserstein distance is associated with each plot, representing the distance between the two normalized distributions. It is notable that the Wasserstein distance in the context of GAN training was introduced by Arjovsky et al. (2017) in order to avoid the mode collapse phenomenon where the generated samples produced by the GAN are representing only one mode of the distribution. In Fig. 15, even if the figure shows that some bimodal distributions remain approximated by a unimodal distribution, the span of these distributions covers the multiple modes of the targeted distribution. This explains why the higher Wasserstein distance in the figure is in the top-left panel, since despite the bimodal-generated distribution the high temperature values do not seem to be represented by the generated samples.
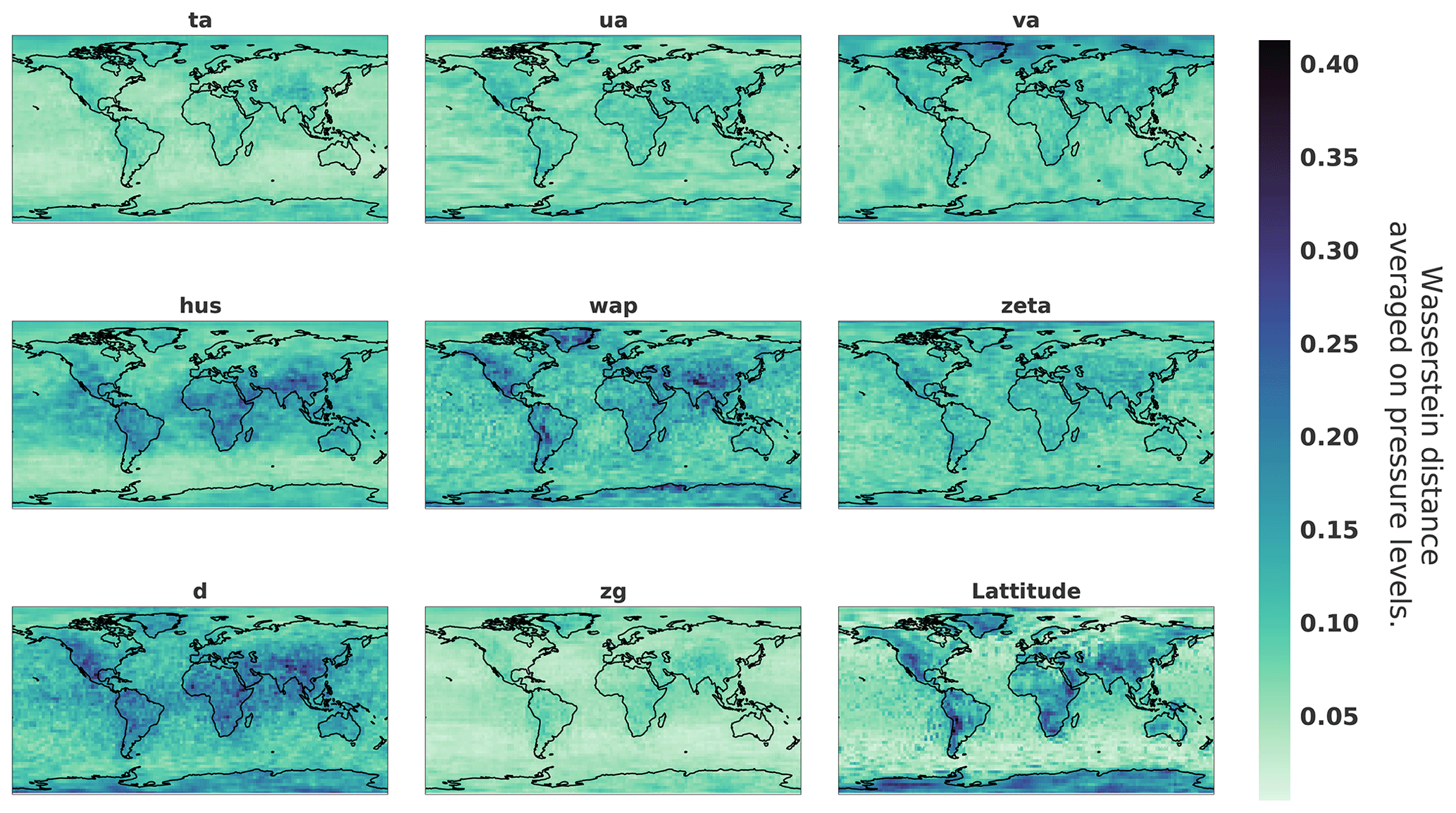
Figure 16Wasserstein distance between 5000 datasets and generated samples on each pixel and each channel.

Figure 17Distributions with the higher (a) and lower (b) Wasserstein distances computed on normalized data. The coordinates of corresponding pixels are, respectively, in latitude and longitude.

Figure 18Wasserstein distance between 5000 datasets and generated samples on each pixel grouped by pressure height (a) or variables (b).
It follows that a good way to see the general statistics learned by the generator is to plot the Wasserstein distance for every pixel and for every variable. This result can be visualized spatially in Fig. 16, where we observe that certain variables are better fitted by the generator than others. The figure also shows that areas with more variability such as land areas and more precisely mountainous areas are the most difficult to fit. As a way to better interpret this metric, Fig. 17 represents the distributions corresponding to the minimum and maximum values of the metric. The distribution of the Wasserstein distance can also be visualized grouped by pressure level and type of variable in Fig. 18. The wap variable that represents the vertical velocity seems to be the one with the higher Wasserstein distance value.
3.3 Analysis of the atmospheric balances
The previous subsection has shown the ability of the generator to engender weather situations and climate similar to those of the simulated weather. However, geophysical fluids are featured by multivariate fields that present known balance relations. Among these balances, the simplest ones are the geostrophic and thermal wind balances (see, e.g., Vallis, 2006). The next two sections assess the ability of the generator to reproduce the geostrophic and thermal wind balances.
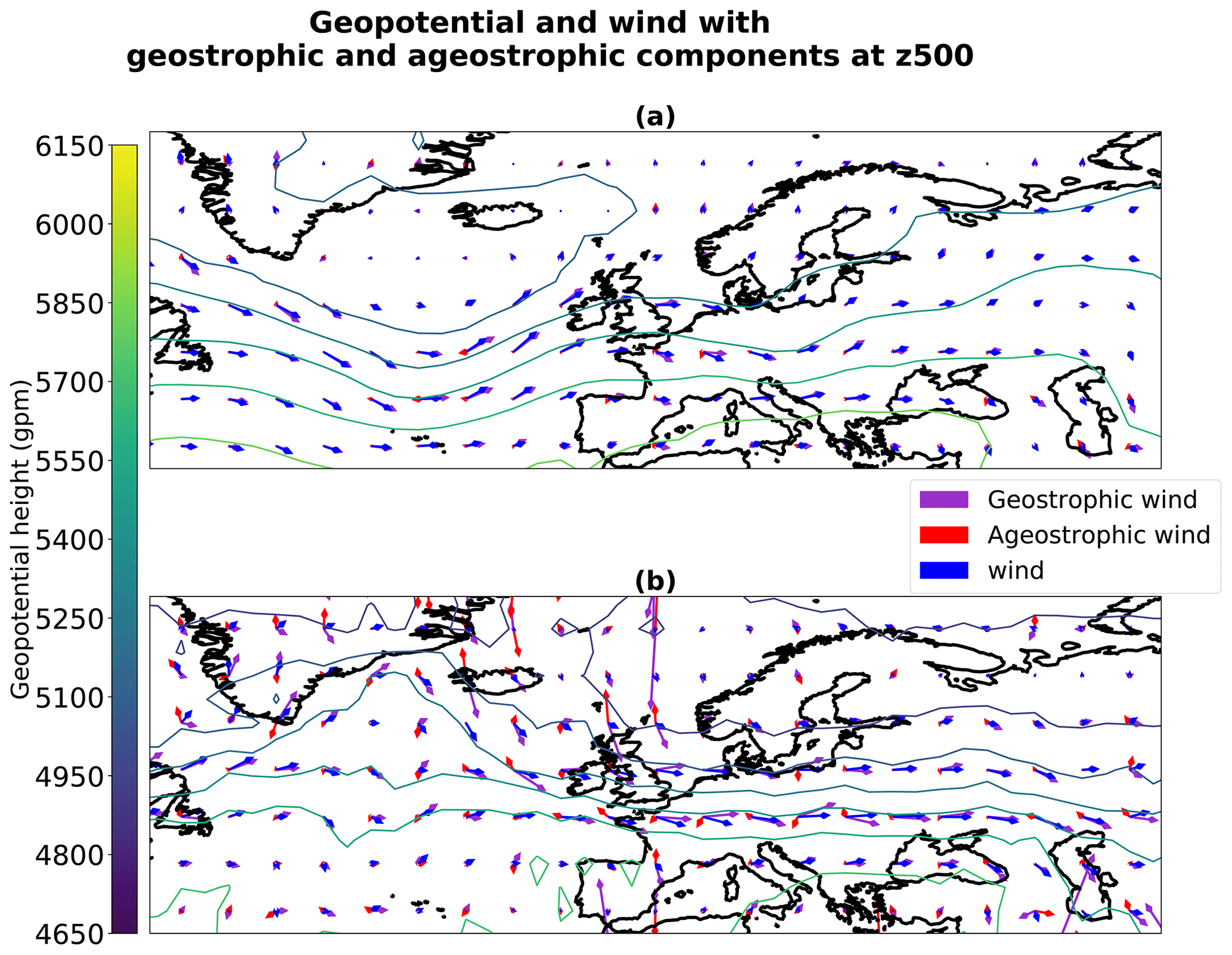
Figure 19Geostrophic and ageostrophic wind derived from geopotential at 500 hPa. Situation taken from dataset (a) and generated (b).
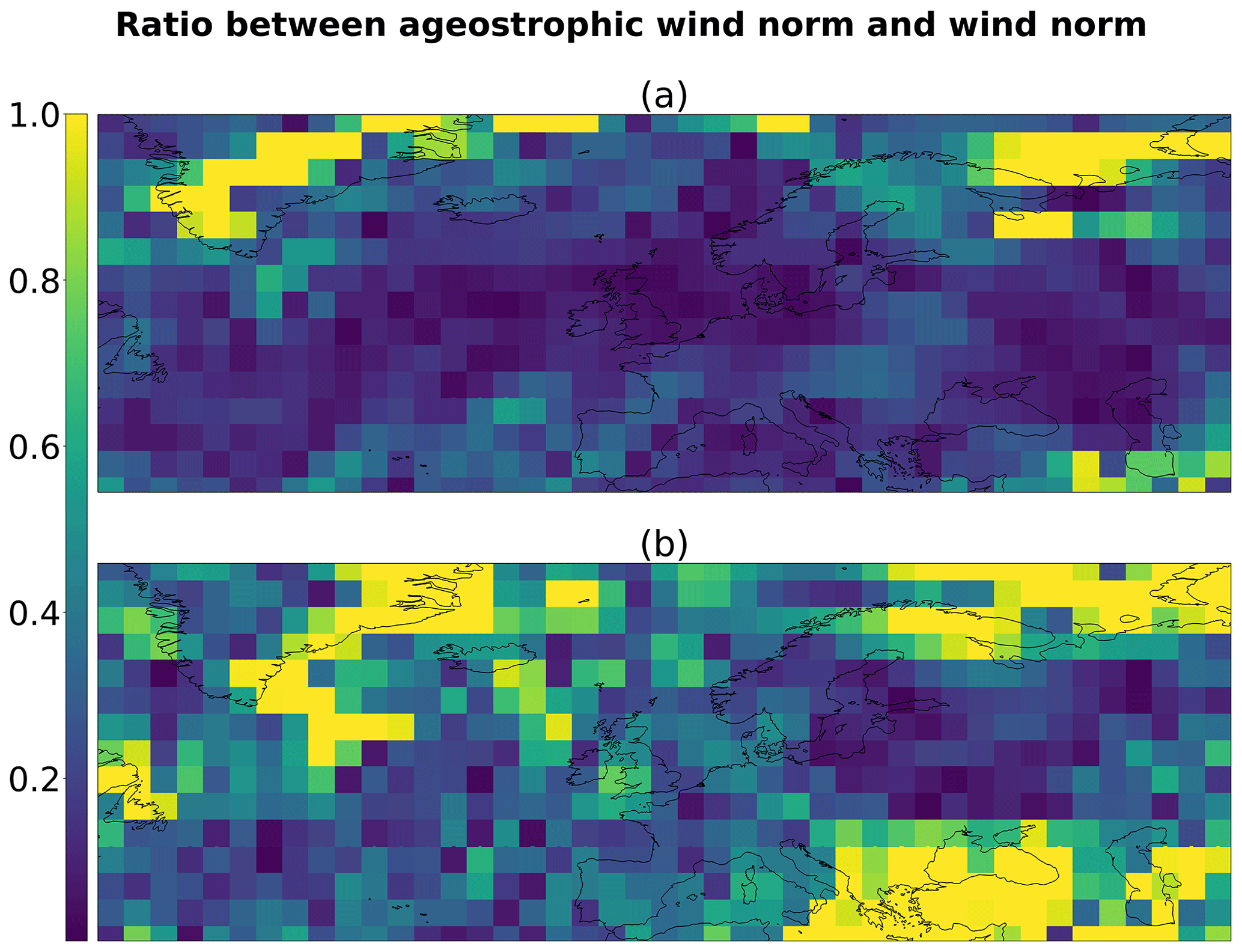
Figure 20Relative error in the norm between geostrophic wind and normal wind shown in Fig. 19 for the situation taken from dataset (a) and generated (b).
3.3.1 Geostrophic balance
The geostrophic balance occurs at a low Rossby number when the rotation dominates the nonlinear advection term. Two forces are in competition: the Coriolis force, fk×u, where k denotes the unit vector normal to the horizontal (f is the Coriolis parameter and u is the wind) and the pressure term −∇pΦ, where Φ is the geopotential and where ∇p denotes the horizontal gradient in the pressure coordinate. Asymptotically, the Coriolis force is then balanced by the pressure term which leads to the geostrophic wind:
The geostrophic flow is parallel to the line of constant geopotential, and it is counterclockwise (clockwise) around a region of low (high) geopotential. The magnitude of the geostrophic wind scales with the strength of the horizontal gradient of geopotential Vallis (2006, Sect. 2.8.2, p. 92).
This asymptotic balance Eq. (15) is verified to within 10 % of error at mid latitude, that is, , where the magnitude of the ageostrophic wind, uag, is less than 0.1 of the magnitude of the real wind u.
Figure 19a illustrates a particular boreal winter situation from the PLASIM dataset, focusing on the mid latitude and presenting a low area of geopotential in the southwest of Iceland. It appears that the wind is well approximated by the geostrophic wind, which is quantitatively verified in Fig. 20a that shows the norm of the ageostrophic wind normalized by the norm of the wind (that is, the relative error when approximating the wind by the geostrophic wind): the order of magnitude of the error is around 20 %. Properties of the geostrophic flow are visible, with a counterclockwise flow around the low geopotential. The wind is maximum where the horizontal gradient of geopotential is maximum, while its change in direction follows the trough.
A similar behavior can be observed in Fig. 19b, which illustrates a weather situation selected from the render by the generator of some samples in the latent space, so as to represent a boreal winter situation. This time, a low geopotential is found in the north of Europe. While the geopotential field is noisy (it is less smooth than in Fig. 19a), the wind is again found to be nearly geostrophic, verifying the geostrophic flow properties to within an error of 35 % (see Fig. 20b). The geopotential and wind fields were projected onto the solved dynamic truncation in order to remove the subgrid component due to the noise in the output of the generator. Despite the truncation, the geostrophic approximation seems to not be respected everywhere and could be a quantitative metric to monitor in order to improve our method.
We find that weather situations generated from samples in the latent space reproduce the geostrophic balance at an order of approximation that is similar to the one of the real dataset. This means that the generator is able to produce the realistic multivariate link between the wind and the geopotential. This property is essential in operational weather forecasting, e.g., in producing balanced fields in the ensemble Kalman filter.
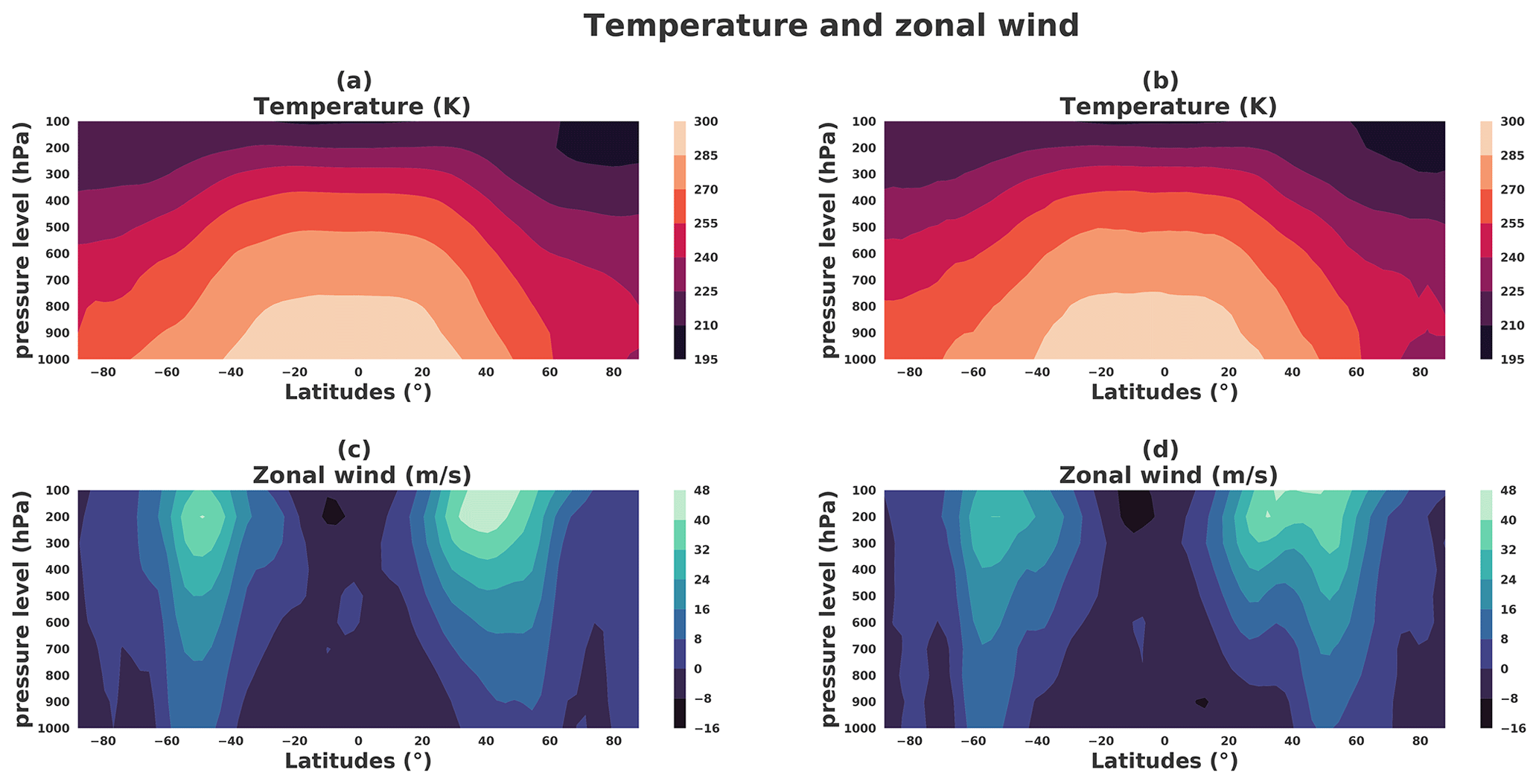
Figure 21Temperature (K) and zonal wind (m s−1) latitude zonals from a boreal winter situation: the thermal wind balance. Left panels correspond to a situation taken from the dataset. (a) Zonal temperature and (c) zonal wind. Right panels correspond to a situation taken from the generator. (b) Zonal temperature and (d) zonal wind.
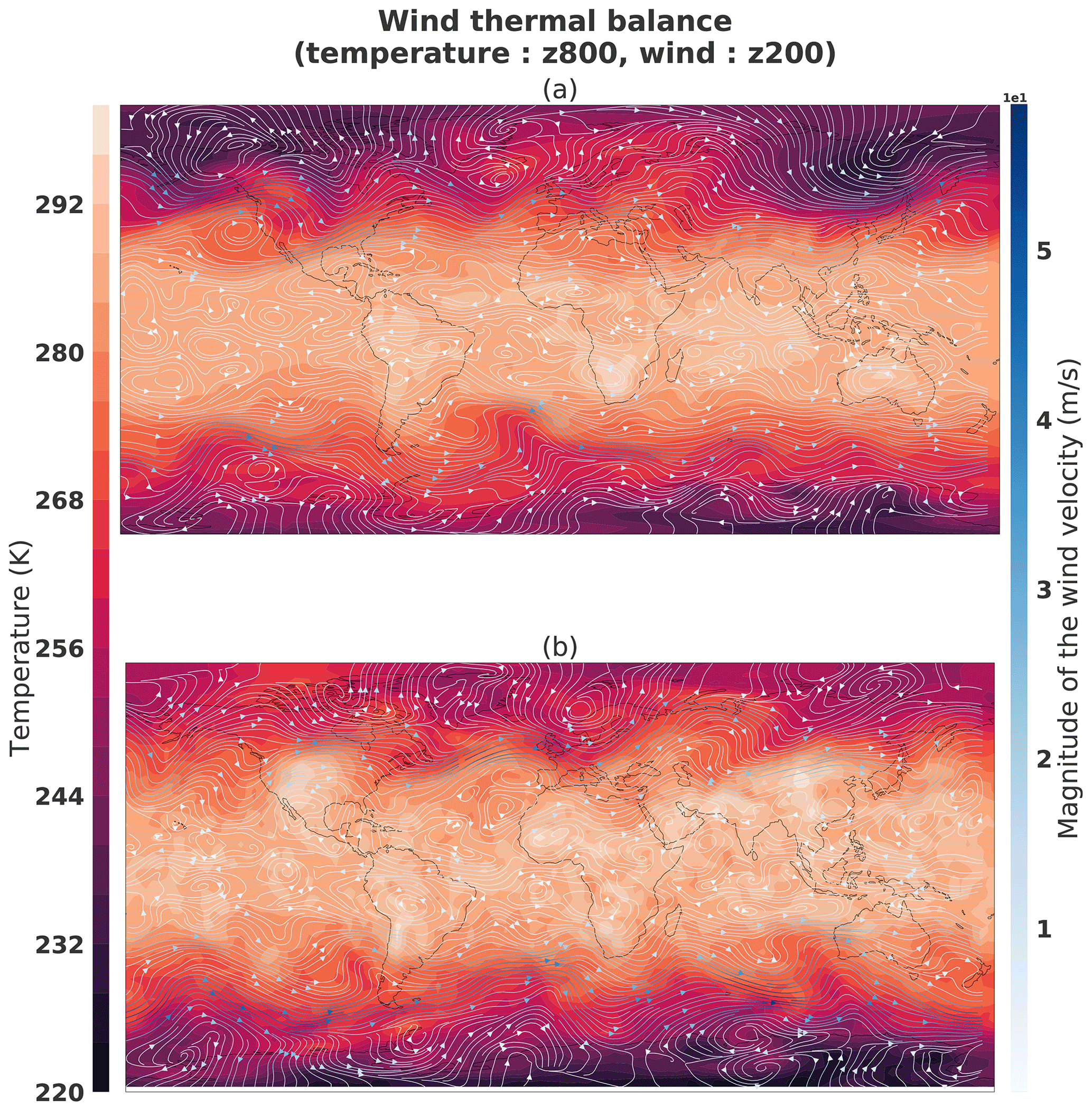
Figure 22Thermal wind balance from the boreal winter situation shown in Fig. 21: (a) sample from the dataset; (b) sample generated by the generator. The temperature (K) is from pressure level 800 hPa and the wind (m s−1) from 200 hPa.
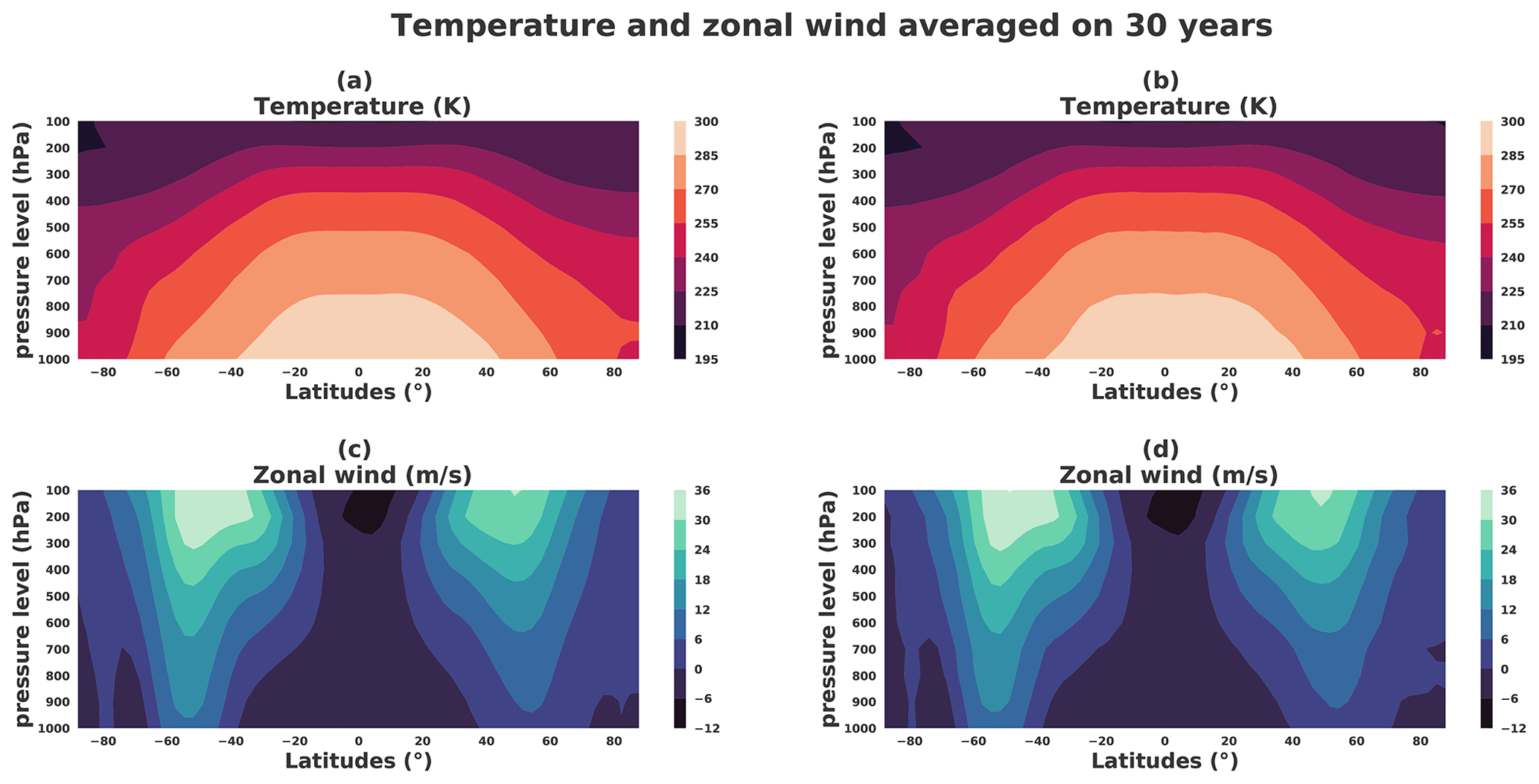
Figure 23Temperature (K) and zonal wind (m s−1) latitude zonals averaged on the 30-year subsample. Left panels correspond to a situation taken from the dataset: (a) zonal temperature and (c) zonal wind. Right panels correspond to a situation taken from the generator: (b) zonal temperature and (d) zonal wind.
3.3.2 Thermal wind balance
The thermal wind balance arises by combining the geostrophic wind Eq. (15) and the hydrostatic approximations, , where ρ is the density (Vallis, 2006, Sect. 2.8.4, p. 95): taking the derivative of Eq. (15) with respect to the pressure p makes the hydrostatic approximation appear, so that the vertical derivative of the geostrophic wind can be written as
where the ideal gas equation, p=ρRT, has been used. Equation (16) is the thermal wind balance that relates the vertical shear of the horizontal wind to the horizontal gradient of temperature. In particular, when the temperature falls in the poleward direction, the thermal wind balance predicts an eastward wind that increases with height.
Figure 21a and b show the vertical cross section of the zonal average of temperature and of the zonal wind for a particular weather situation in the dataset, corresponding to a boreal winter situation of the same weather situation represented in Fig. 21: the temperature is higher in the Southern Hemisphere than in the Northern Hemisphere, with a strong horizontal gradient of temperature in latitude ranges and . At the vertical of the horizontal gradient of temperature, the wind is eastward and increases with the height: this illustrates the thermal wind balance which produces a strong curled jet at the vertical of the strong horizontal gradient of temperature as shown in Fig. 22a that illustrates, for the same weather situation, the temperature at the bottom (800 hPa) with the horizontal wind at the top (200 hPa) of the troposphere.
The same illustrations are shown in Fig. 21c and d when considering a generated situation, selected to correspond to a boreal winter situation: the characteristics related to the thermal wind balance as observed before are found again. This results in the generator being able to render a weather situation that reproduces the thermal wind balance. Moreover, Fig. 23 shows the thermal wind balance averaged on 30 years for the dataset (Fig. 23a) and generations (Fig. 23b); both are very similar.
This section has shown the ability of the generator to reproduce some important balances present in the atmosphere. In particular, the generator is able to produce mid-latitude cyclones whose velocity field is in accordance with the geostrophic balance. The authors emphasize that it is necessary to conduct more analysis of the weather situations outputted by the generator, which is beyond the scope of this study. For example, it would be interesting to assess whether other inter-variable balances are present, such as the ω equation or vertical structures. Note that adding advanced diagnostic fields in the output of the generator could be investigated to improve the realism.
3.4 Exploration of the latent space structure and its connection to the climate
An exploratory study was done on the property of the latent space and its consequence in the climate space in regard to climate domain problematics. If the generator is perfectly trained, then each sample generated with it should represent a typical weather situation. It is hard to figure out what the attractor of the climate is. However, the geometry of the Gaussian in high dimension being known, it is easy to characterize the climate in the latent space.
3.4.1 Geometry of the normal distribution
For a normal law in the high dimension space Z=ℝm, i.e., with m larger than 10, the distributions of the samples are all located in a spherical shell of radius and of thickness on order (see, e.g., Pannekoucke et al., 2016). Because the covariance matrix Im is a diagonal of constant variance, no direction of ℝm is privileged, leading to an isotropic distribution of the direction of the sampled vectors: their unit directions uniformly cover the unit sphere. Another property is that the angle formed by two sampled vectors is approximately of magnitude : two random samples are orthogonal. These are simple consequences of the central limit theorem which predict, for instance, that the distance of a sample to the center of the sphere is asymptotically the Gaussian .
Considering these properties, one can introduce a two dimensional pseudo-representation which preserves the isotropy of the distribution as well as the distribution to the origin: a random sample vector in ℝm is represented by the projection , where stands for the Euclidian norm in ℝm.
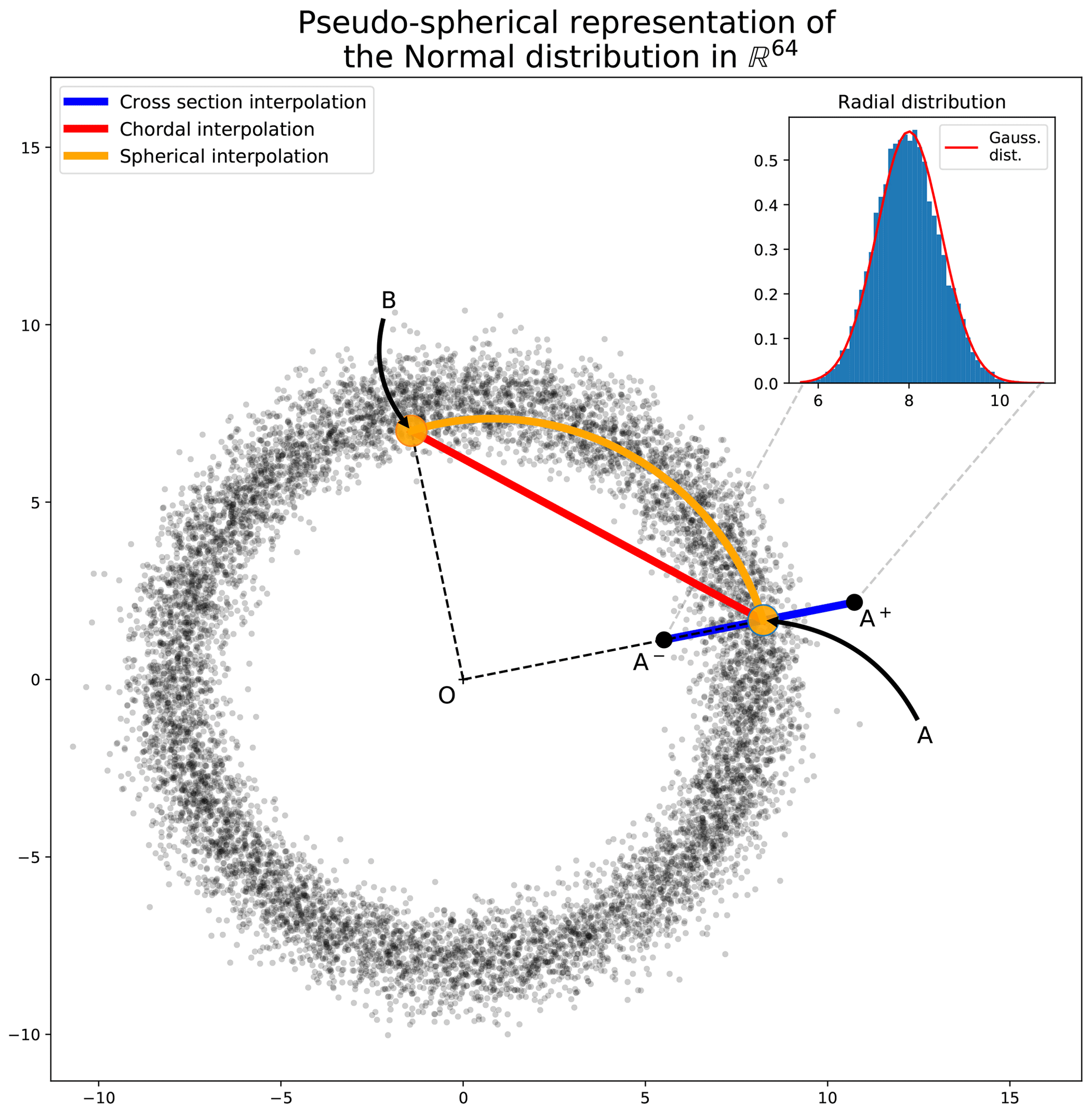
Figure 24Pseudo-spherical metaphorical representation of 10 000 samples of the normal distribution in ℝm with m=64 and the distribution of the distance of samples to the center of the spherical shell. For a sample A, A± denotes two extreme situations along the direction of A. Any second sample B, typical of the distribution, appears orthogonal to A. The inset figure represents the radial distribution compared with the asymptotic central limit theorem (CLT) Gaussian distribution (thin red curve).
Figure 24 illustrates this low-dimensional representation of an ensemble of 10 000 samples of the normal law in dimension m=64. For instance, points A and B represent two independent samples: their distance to the origin is closed to , and their angle is closed to . While m=64 can be considered a very small dimension, it appears that the distribution of the point's distance to the origin is well fit by the Gaussian (see inset figure in Fig. 24). Hence, it results that for this dimension, the interpretation of a Gaussian distribution as a spherical shell applies, with interesting consequences for extremes or typical states. A typical sample of this normal law is a point near the sphere of radius , while an extreme sample has a norm lying in the tails of the distribution .
This suggests evaluating whether the extremes of the latent space correspond to those of the meteorological space.
3.4.2 Connection between extremes in the latent and physical spaces
Knowing what are the extremes in the latent space might be helpful to determine what are the extremes of the climate, at least to determine what are extreme situations closed to a given state.
For any sample in the latent space, say point A, we can construct the point on the sphere along the same direction of A, , which can be considered the most likely typical state near A. Along the same direction of A, we can also construct the extreme situations A± whose distances to the origin, , lay, respectively, in the left and right tails of the Gaussian distribution .
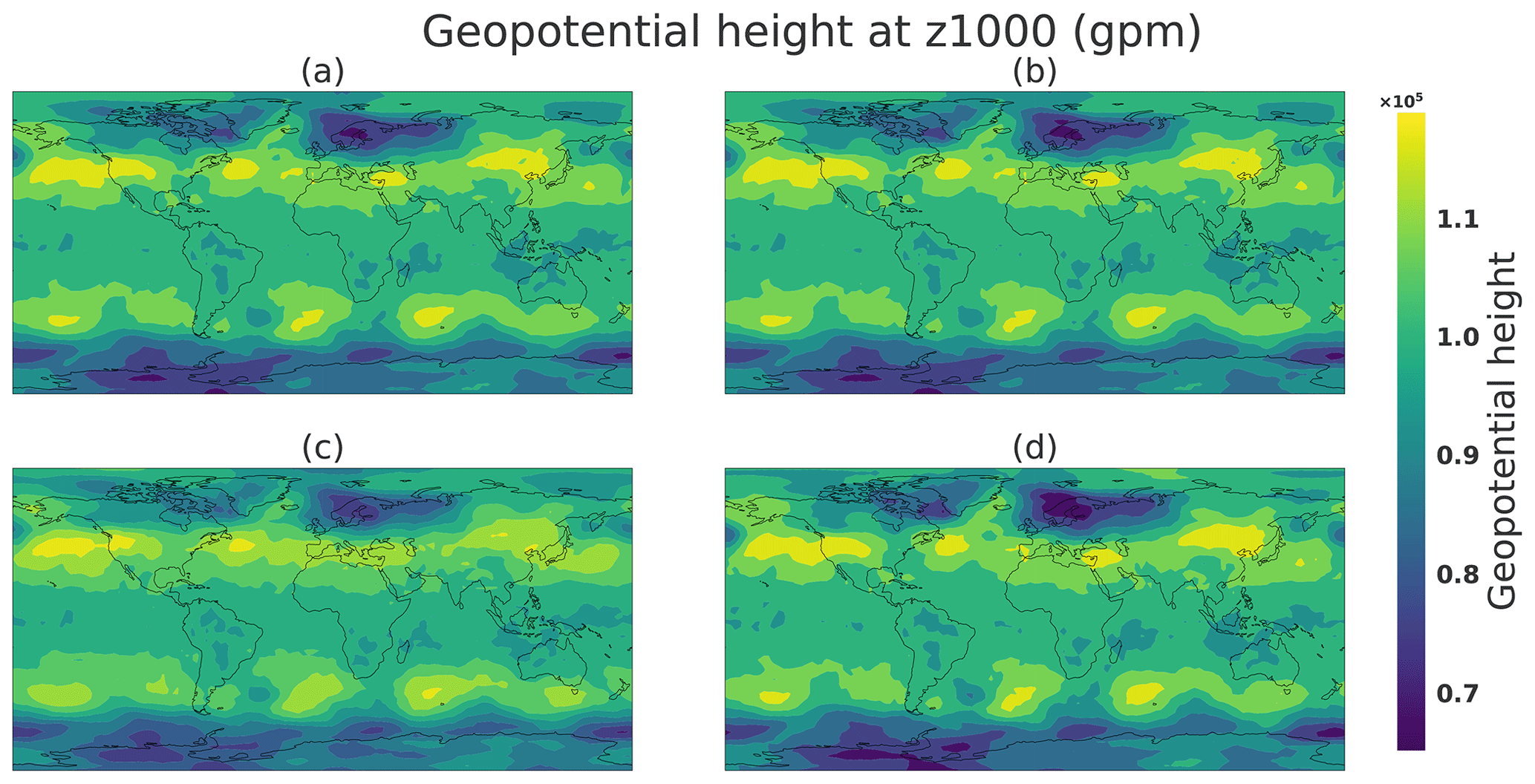
Figure 25Generations obtained by radial interpolation in the latent space. Panel (a) is the image corresponding to a randomly drawn latent vector A (two-norm: 7.69), (b) is its projection onto the mean of the same direction (two-norm: 8.0), and (c) and (d) are the projection onto, respectively, inferior A− (two-norm: 5.87) and superior A+ (two-norm: 10.12) 1 % quantile (see Fig. 24).
Figure 25 represents the weather situation generated from a randomly drawn latent vector from a 64-dimensional Gaussian 𝒩(0,1) sample A (Fig. 25a). Panel (a) represents a latent vector with a Euclidian norm equal to 7.69, close to the mean of the radial distribution of the hypersphere mentioned in Sect. 3.4.1. In the climate space this sample shows a meteorological object above northern Europe in the shape of a geopotential minimum which can be interpreted as a storm. This sample is the same as the one represented in Figs. 19b, 21b, and 22b.
The most likely typical state (Fig. 25b) is the radial projection of the latent vector A onto the mean of the radial distribution; thus, its Euclidian norm is equal to 8. Because sample A has a norm close to sample B, the weather situations are very similar at the geopotential height at z1000. This is an expected effect because by construction of the generator the input space is continuous, so two points in the latent space must be similar. Extreme situation A± along the direction of A is represented in Fig. 25c and d. Both panels shows clear differences in the geopotential height. First the panel (Fig. 25c) shows a decrease in the storm located above northern Europe; the same effect is visible in the south of South America. However, the weather situation is very similar to Fig. 25a. By contrast, Fig. 25d represents a deeper geopotential height minimum at the pre-existing storm of sample A. Thus, Fig. 25 seems to show a certain structure of the latent space generator where the radial direction could represent the strength of the meteorological objects such as storms above Europe, for example. It could be explained by the fact that the generator aims to map a distribution (64-dimensional Gaussian in the latent space) to another (weather distribution in the PLASIM physical space). Rare events exist in the latent space on the tails of the Gaussian distribution's potentially extreme weather situations. One of the ways to do a such mapping is to use the radial direction to represent high- or low-probability states of the climate. An important conclusion is that, for a given situation, the most likely state and the extremes are interesting physical states. This could open new possibilities to study an extreme situation close to a given one, which is an important topic, e.g., for insurance or to improve the study of high weather impact in ensemble forecasting.
The link of the animation of such interpolation is available on GitHub1 of the project.
3.4.3 Interpolation in the latent space
Even if there are no dynamics in the latent space, which makes it impossible to construct a prediction from this space, we can consider how to interpolate two latent states. A naive answer is to compute the linear interpolation between two samples of the latent space A and B,
which results in the red chordal illustrated in Fig. 24. The chordal interpretation highlights a major drawback of the linear interpolation: middle points of the chordal are extremes; these intermediate points should not correspond to typical (or even physically realizable) weather situations.
So as to preserve the likelihood of the interpolated weather situations, it is better to introduce a spherical interpolation. This kind of interpolation has also been used in image processing, where, e.g., White (2016) uses the formula
where θ is the angle and for such as M0=G(A) and M1=G(B).
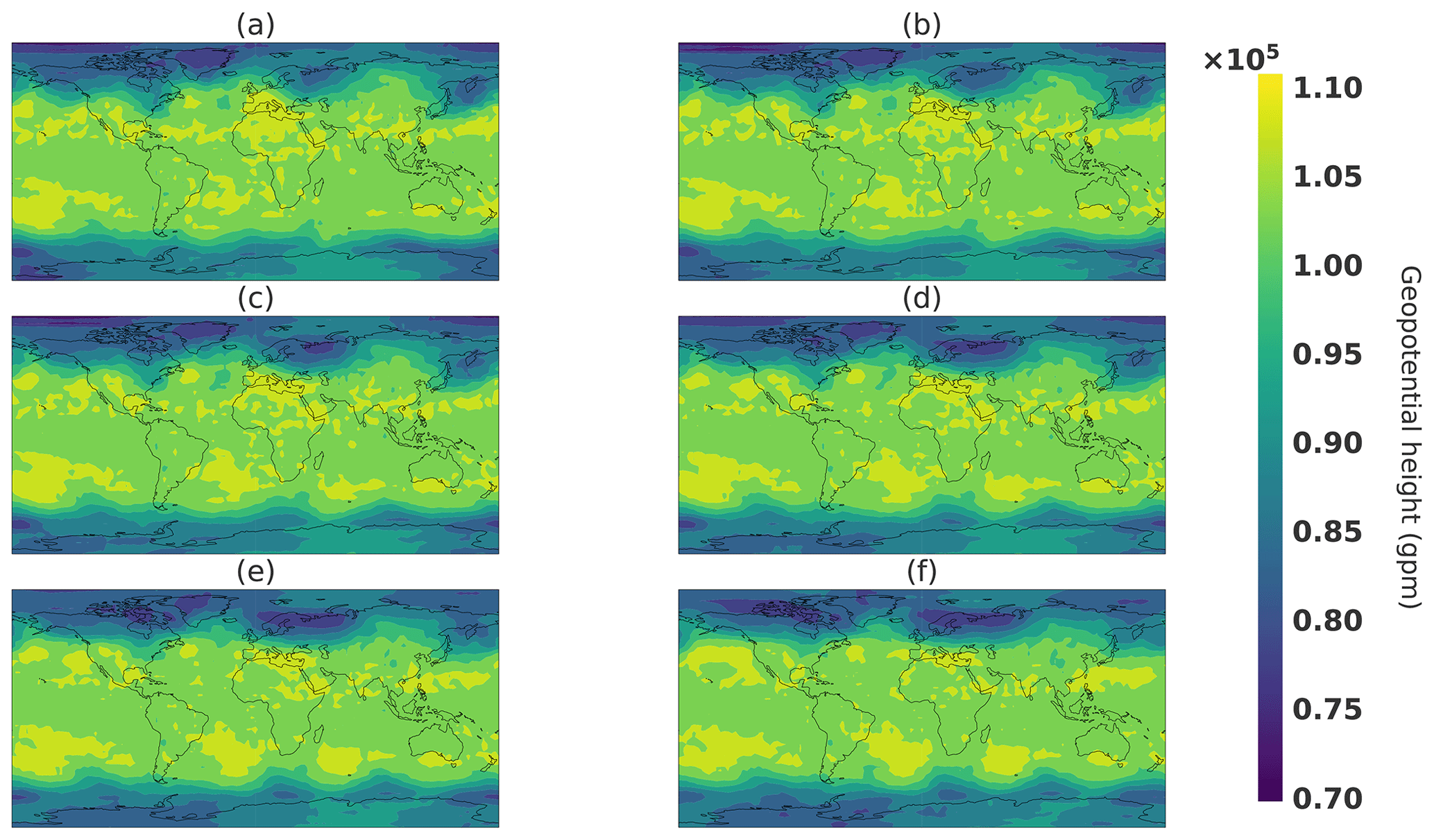
Figure 26Spherical interpolation snapshots. Respectively, panels (a–f) correspond to values of t in Eq. (18) of 0, 0.2, 0.4, 0.6, 0.8, and 1.
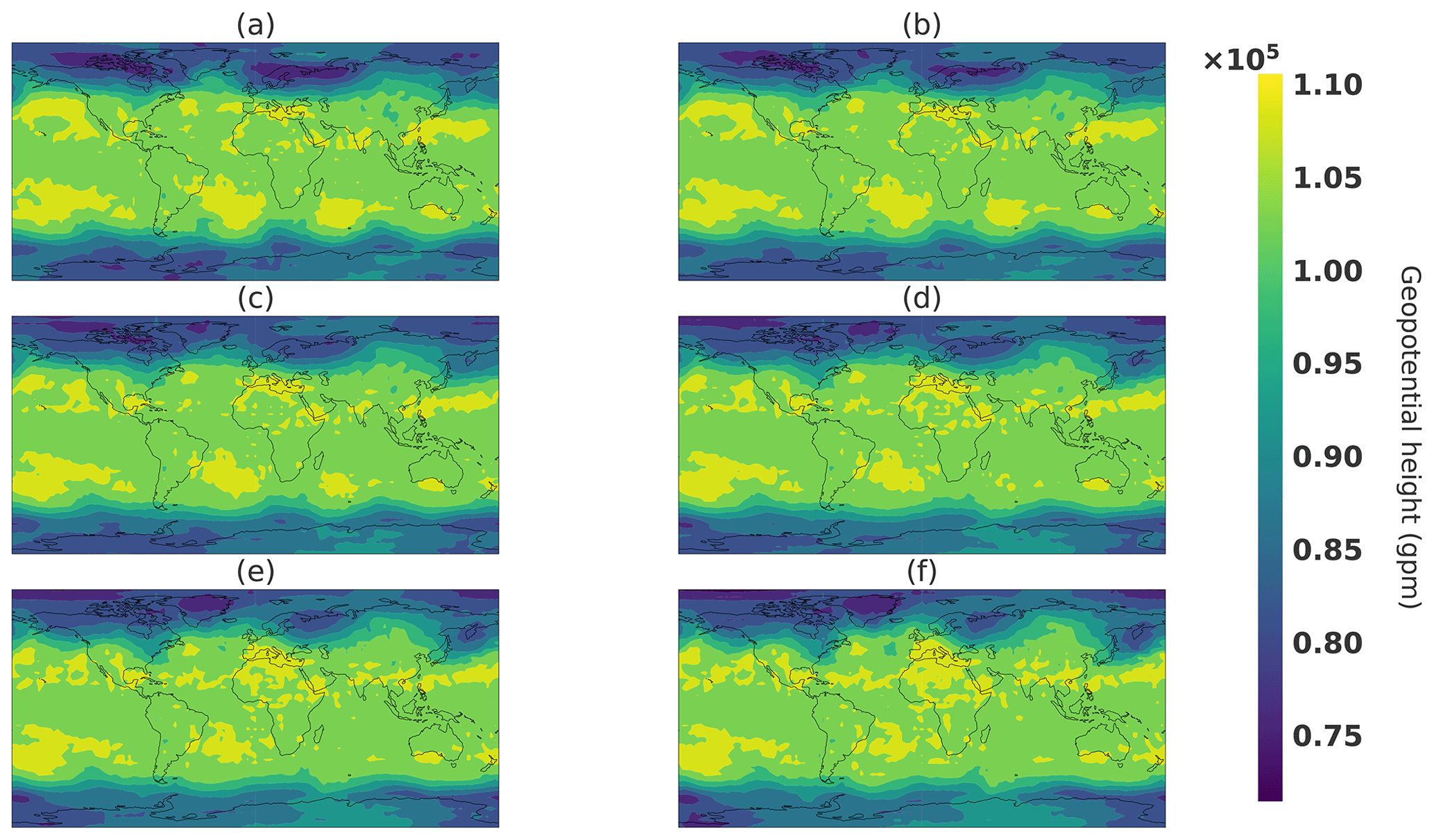
Figure 27Linear interpolation in the latent space interpolation snapshots. Respectively, panels (a–f) correspond to values of t in Eq. (17) of 0, 0.2, 0.4, 0.6, 0.8, and 1.

Figure 28Linear interpolation in the image space. Respectively, panels (a–f) correspond to values of t in Eq. (19) of 0, 0.2, 0.4, 0.6, 0.8, and 1.
This interpolation will connect point A to point B within the spherical shell of typical states, as illustrated by the orange curve line in Fig. 24. Figure 26 shows snapshots of the climate generated from a spherical interpolation in the latent space between sample A and another random sample B. For the sake of comparison, Figs. 27 and 28 are, respectively, snapshots of a linear interpolation in the latent space described in Eq. (17) and in the image space using the following equation:
The objective of this experience is to be able to produce realistic intermediate states. This can be visible in Fig. 26, where the storm above Europe emerges by first a smaller minimum in geopotential height that increases in size, whereas in both linear interpolations, in the latent and image spaces, the storm appears first as a long and thin geopotential minimum and then broadens in the latitude direction. Such a property can be helpful in the context of fluid dynamics for initial and boundary conditions of a local area model to avoid error correlated with user-defined parameters such as in lateral boundary conditions (Davies, 2014). An interesting generator property would be able to choose some characteristics of the generated climate such as meteorological objects at certain locations. In the next section, an experiment is conducted to see whether it is possible to change the location of such meteorological objects.
3.4.4 Coherent structure perturbation from the latent space
In this section, the goal is to study the difference between two climate states coming from close latent points. In this experiment, sample G(A) will be the reference climate state, and we added noise to A such as with ϵi taken from 𝒩(0,0.1).
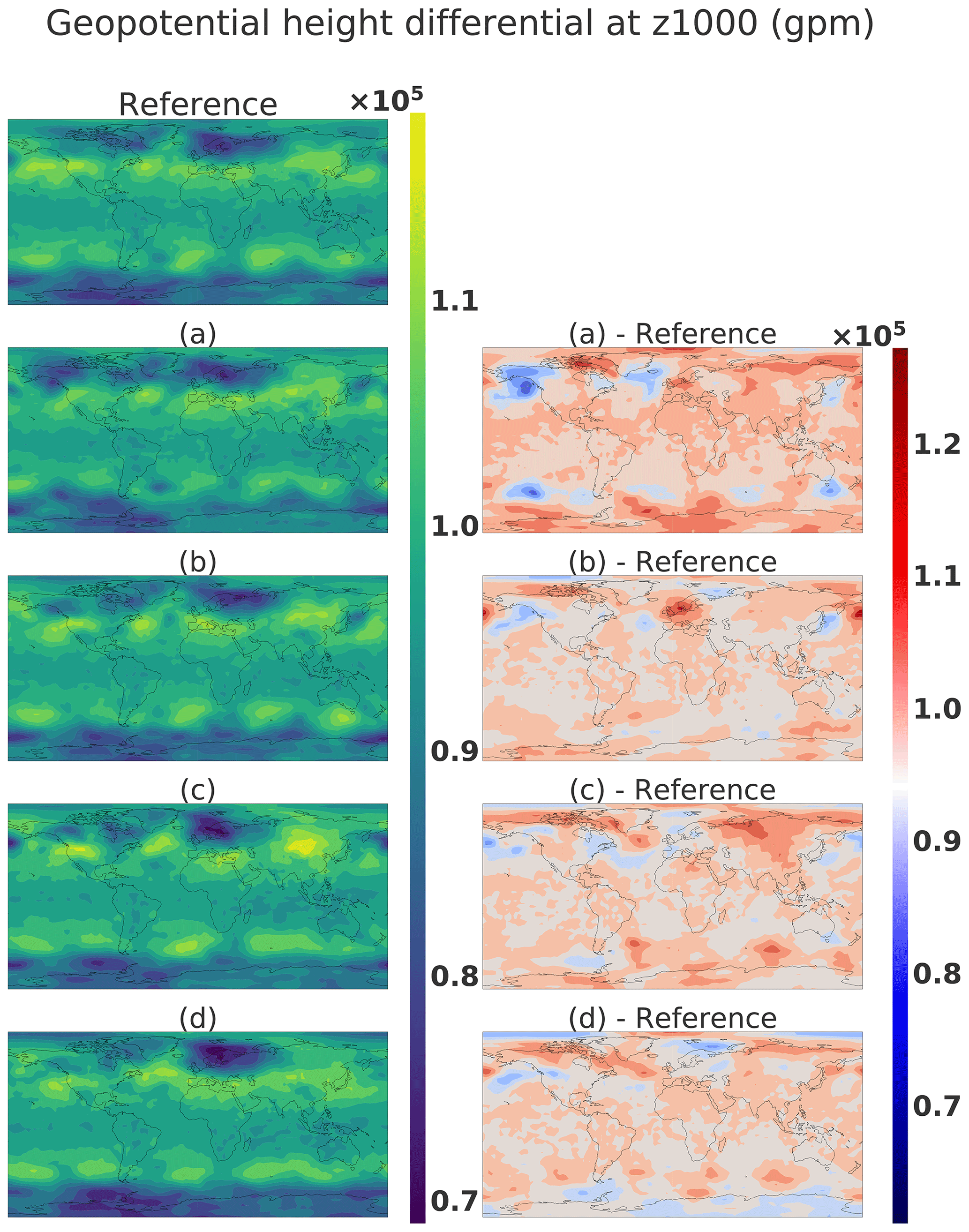
Figure 29Geopotential height: the first column reference corresponds to G(A), and panels (a–d) correspond to G(A+ϵi) and the second column .
Figure 29 shows the different climate states corresponding to G(A) and G(A+ϵi) in the first column and the difference with the reference in the climate states in the second column. The second column shows dipoles that represent the movement of meteorological structures, for example, in the South American area of panel d. We remarked that the perturbation of one latent vector is translated in the climate state by a dipole creation when the difference is done between the reference and perturbed versions. This shows the possibility of moving the meteorological object by remaining on the manifold of the realistic climate state. This is an interesting asset for the climate domain, where it is complicated to interpolate between two states where a storm is at two different locations as mentioned in Hergenrother et al. (2002). The WGAN could be a way to propose realistic intermediate states.
Our study shows that it is possible to map the climate distribution output of a GCM to a much simpler low-dimensional distribution using a highly nonlinear neural-network-based generator. It also proposes ways to assess the quality of the generator by evaluating statistical quantities as well as with respect to physical balance properties.
In this article, a weather generator based on the WGAN method able to produce realistic states of the atmosphere was created. Metrics such as SVD principal component comparison, Wasserstein distance on pixel value distribution and mean and standard deviation comparison were used in order to be compared to other future proposed methods.
A comparison of the atmospheric balance was realized between samples and averaged over 30 years of data, showing promising results. Coherence between variables as well as spatial coherence were also shown to be promising.
Interesting properties of such a generator were discussed with regard to possible applications in insurance, weather simulation and data assimilation. The generator is able to generate intermediate realistic climate states with coherent structures, interpolate between two defined states with other plausible states, and create realistic perturbations around a climate state, all at a low computational cost compared to a GCM.
A study was also done on the interpretability of the latent space and the connections between the extreme events in the data space and the latent space. It highlighted the radial direction as the direction of the intensity of climate events.
Our results highlight the ability of the method to handle the mapping of a high-dimensional distribution onto a multivariate Gaussian. We believe this is an important step that opens many opportunities for climate data exploration. Some extensions of this work as well as potential application are highlighted in the following.
First, the WGAN could be conditioned by the season or by the day in the year. Such conditioning would give access to other quantitative methods to assess the quality of the weather generator. It would be also an important step towards application in the risk assessment area, for example.
Optimization can be done to find specific states in the latent space by defining an objective function such as Euclidian distance in the climate space. The network gradient with respect to its inputs being accessible, direct minimization can be used to find climate states that fit observations in data assimilation problems. More advanced strategies, such as training a separate inference network (Chan and Elsheikh, 2019), are also possible to apply Bayes' rule without using a particle filter. It is also possible to condition the generations to a specific date in the annual cycle with slight modifications in the network architecture. One could think to condition the output of the generator by a forcing field in input such as forcing fields like SST fields for data assimilation application, which should be possible but with more important modifications of the network architecture and a possible impact on the speed of the training procedure.
A more sophisticated dataset could be used, such as a true climate reanalysis, to see the effect of the dataset complexity on the method's performance. The optimization of the network's architecture and a sensitivity study on the hyperparameters such as the dimension of the latent space, for example, would be useful. Moreover, it would be interesting to see whether it is possible to take advantage of the GAN trained in PLASIM to facilitate the training of a GAN on the reanalysis.
The structure of the latent space and its interpretability is also a critical way to exploit the specificities of the method. The opportunity to find similar climate states with extreme events is also something not possible with other weather generators and could have lots of application for risk assessment applications.
The definition of additional metrics to assess the quality of the generator should be the main focus following this study to identify improvement of the method and facilitate the participation from diverse researcher communities.
Finally, we could consider restarting the GCM from a generated state to assess how well balanced the generated fields are, which could have important implications in data assimilation methods.
The study is a first step towards deep-learning weather generation; while many challenges remain to be solved, it shows several potential applications of GANs to improve the effectiveness of current approaches.
The code and the weights of the trained neural network are available at the following GitHub repository in v0.1: https://github.com/Cam-B04/Producing-realistic-climate-data-with-GANs.git (last access: January 2021). The repository is associated with the following DOI: https://doi.org/10.5281/zenodo.4442450 (Besombes, 2021).
The dataset used is available on demand. The GitHub repository explains how to recreate it from a PLASIM simulation.
The authors contribute to the design of the neural network architecture and the experiments. CB implemented the neural network architecture, performed the PLASIM simulation and trained the WGAN. The analysis of the results has been made by the authors.
The authors declare that they have no conflict of interest.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research paper was written during a thesis in partnership with Total. We would like to thank Philippe Berthet, Anahita Abadpour, Daniel Busby and Tatiana Chugunova for their support in the application of our method in different fields of the geosciences. We would like to thank Rabeb Selmi for her help and for sharing her expertise.
This paper was edited by Takemasa Miyoshi and reviewed by two anonymous referees.
Arjovsky, M., Chintala, S., and Bottou, L.: Wasserstein gan, arXiv [preprint], arXiv:1701.07875, 26 January 2017. a, b, c, d, e, f
Besombes, C.: Producing realistic climate data with GANs, Zenodo [data set], https://doi.org/10.5281/zenodo.4442450, 2021 (data available at: https://github.com/Cam-B04/Producing-realistic-climate-data-with-GANs.git, last access: January 2021). a
Beusch, L., Gudmundsson, L., and Seneviratne, S. I.: Emulating Earth system model temperatures with MESMER: from global mean temperature trajectories to grid-point-level realizations on land, Earth Syst. Dynam., 11, 139–159, https://doi.org/10.5194/esd-11-139-2020, 2020. a
Boukabara, S.-A., Krasnopolsky, V., Stewart, J. Q., Maddy, E. S., Shahroudi, N., and Hoffman, R. N.: Leveraging modern artificial intelligence for remote sensing and NWP: Benefits and challenges, B. Am. Meteorol. Soc., 100, ES473–ES491, 2019. a
Chan, S. and Elsheikh, A. H.: Parametric generation of conditional geological realizations using generative neural networks, Computat. Geosci., 23, 925–952, https://doi.org/10.1007/s10596-019-09850-7, 2019. a
Davies, T.: Lateral boundary conditions for limited area models, Q. J. Roy. Meteor. Soc., 140, 185–196, 2014. a
Dramsch, J. S.: 70 years of machine learning in geoscience in review, Adv. Geophys., 61, 1–55, 2020. a
Fraedrich, K., Jansen, H., Kirk, E., Luksch, U., and Lunkeit, F.: The Planet Simulator: Towards a user friendly model, Meteorol. Z., 14, 299–304, 2005a. a, b
Fraedrich, K., Kirk, E., Lunkeit, F., Luksch, U., and Lunkeit, F.: The portable university model of the atmosphere (PUMA): Storm track dynamics and low-frequency variability, Meteorol. Z, 14, 735–746, 2005b. a
Gagne, D. J., Christensen, H. M., Subramanian, A. C., and Monahan, A. H.: Machine learning for stochastic parameterization: Generative adversarial networks in the Lorenz'96 model, J. Adv. Model. Earth Sy., 12, e2019MS001896, https://doi.org/10.1029/2019MS001896, 2020. a
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y.: Generative adversarial networks, Communications of the ACM, 63, 139–144, 2020. a
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville, A. C.: Improved training of wasserstein gans, in: Advances in neural information processing systems, arXiv [preprint], 5767–5777, arXiv:1704.00028v3, 2017. a, b, c, d, e, f, g
He, K., Zhang, X., Ren, S., and Sun, J.: Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, CVPR 2016, 770–778, 2016. a
Hergenrother, E., Bleile, A., Middleton, D., and Trembilski, A.: The abalone interpolation: A visual interpolation procedure for the calculation of cloud movement, in: Proceedings. XV Brazilian Symposium on Computer Graphics and Image Processing, Fortaleza, Brazil, 10 October 2002, 381–387, IEEE, 2002. a
Houtekamer, P. L. and Zhang, F.: Review of the ensemble Kalman filter for atmospheric data assimilation, Mon. Weather Rev., 144, 4489–4532, 2016. a
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A.: Image-to-image translation with conditional adversarial networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017, 1125–1134, 2017. a
Kantorovich, L. V. and Rubinshtein, S.: On a space of totally additive functions, Vestnik of the St. Petersburg University: Mathematics, 13, 52–59, 1958. a
Kingma, D. P. and Ba, J.: Adam: A Method for Stochastic Optimization, arXiv [preprint], arXiv:1412.6980, 22 December 2014. a
Lagerquist, R., McGovern, A., and Gagne II, D. J.: Deep learning for spatially explicit prediction of synoptic-scale fronts, Weather Forecast., 34, 1137–1160, 2019. a
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., and Shi, W.: Photo-realistic single image super-resolution using a generative adversarial network, in: Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017, 4681–4690, 2017. a
Leinonen, J., Guillaume, A., and Yuan, T.: Reconstruction of cloud vertical structure with a generative adversarial network, Geophys. Res. Lett., 46, 7035–7044, 2019. a
Li, J. and Heap, A. D.: Spatial interpolation methods applied in the environmental sciences: A review, Environ. Modell. Softw., 53, 173–189, 2014. a
Lorenc, A. C.: The potential of the ensemble Kalman filter for NWP–a comparison with 4D-Var, Q. J. Roy. Meteor. Soc., 129, 3183–3203, 2003. a
Nagarajan, V. and Kolter, J. Z.: Gradient descent GAN optimization is locally stable, arXiv [preprint], arXiv:1706.04156, 13 June 2017. a
Pannekoucke, O., Cebron, P., Oger, N., and Arbogast, P.: From the Kalman Filter to the Particle Filter: A geometrical perspective of the curse of dimensionality, Adv. Meteorol., 2016, 9372786, https://doi.org/10.1155/2016/9372786, 2016. a
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E.: Scikit-learn: Machine Learning in Python, J. Mach. Learn. Res., 12, 2825–2830, 2011. a
Peleg, N., Fatichi, S., Paschalis, A., Molnar, P., and Burlando, P.: An advanced stochastic weather generator for simulating 2-D high-resolution climate variables, J. Adv. Model. Earth Sy., 9, 1595–1627, 2017. a
Reichstein, M., Camps-Valls, G., Stevens, B., Jung, M., Denzler, J., Carvalhais, N., and Prabhat: Deep learning and process understanding for data-driven Earth system science, Nature, 566, 195–204, 2019. a
Requena-Mesa, C., Reichstein, M., Mahecha, M., Kraft, B., and Denzler, J.: Predicting landscapes as seen from space from environmental conditions, in: IGARSS 2018 – 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018, 1768–1771, IEEE, 2018. a
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Li, F.-F.: Imagenet large scale visual recognition challenge, Int. J. Comput. Vision, 115, 211–252, 2015. a, b
Scher, S.: Toward data-driven weather and climate forecasting: Approximating a simple general circulation model with deep learning, Geophys. Res. Lett., 45, 12616–12622, 2018. a
Springenberg, J. T., Dosovitskiy, A., Brox, T., and Riedmiller, M.: Striving for simplicity: The all convolutional net, arXiv [preprint], arXiv:1412.6806, 21 December 2014. a
Vallis, G. K.: Atmospheric and Oceanic Fluid Dynamics, Cambridge University Press, Cambridge, UK, https://doi.org/10.2277/0521849691, 2006. a, b, c
Watson-Parris, D.: Machine learning for weather and climate are worlds apart, Philos. T. R. Soc. A, 379, 20200098, https://doi.org/10.1098/rsta.2020.0098, 2021. a
Weyn, J. A., Durran, D. R., and Caruana, R.: Can machines learn to predict weather? Using deep learning to predict gridded 500-hPa geopotential height from historical weather data, J. Adv. Model. Earth Sy., 11, 2680–2693, 2019. a
Weyn, J. A., Durran, D. R., and Caruana, R.: Improving Data-Driven Global Weather Prediction Using Deep Convolutional Neural Networks on a Cubed Sphere, J. Adv. Model. Earth Sy., 12, e2020MS002109, https://doi.org/10.1029/2020MS002109, 2020. a
White, T.: Sampling Generative Networks, arXiv [preprint], arXiv:1609.04468, 14 September 2016. a
Wilks, D. S. and Wilby, R. L.: The weather generation game: a review of stochastic weather models, Prog. Phys. Geog., 23, 329–357, 1999. a
Wu, J.-L., Kashinath, K., Albert, A., Chirila, D., Prabhat, and Xiao, H.: Enforcing statistical constraints in generative adversarial networks for modeling chaotic dynamical systems, J. Comput. Phys., 406, 109209, https://doi.org/10.1016/j.jcp.2019.109209, 2020. a
Yeh, R. A., Chen, C., Yian Lim, T., Schwing, A. G., Hasegawa-Johnson, M., and Do, M. N.: Semantic image inpainting with deep generative models, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017, 5485–5493, 2017. a
Zhang, X.-C., Chen, J., Garbrecht, J., and Brissette, F.: Evaluation of a weather generator-based method for statistically downscaling non-stationary climate scenarios for impact assessment at a point scale, T. ASABE, 55, 1745–1756, 2012. a
https://github.com/Cam-B04/Producing-realistic-climate-data-with-GANs (last access: 15 January 2021)