the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 17 Sep 2020
| 17 Sep 2020
Applications of matrix factorization methods to climate data
Terence J. O'Kane
An initial dimension reduction forms an integral part of many analyses in climate science. Different methods yield low-dimensional representations that are based on differing aspects of the data. Depending on the features of the data that are relevant for a given study, certain methods may be more suitable than others, for instance yielding bases that can be more easily identified with physically meaningful modes. To illustrate the distinction between particular methods and identify circumstances in which a given method might be preferred, in this paper we present a set of case studies comparing the results obtained using the traditional approaches of empirical orthogonal function analysis and k-means clustering with the more recently introduced methods such as archetypal analysis and convex coding. For data such as global sea surface temperature anomalies, in which there is a clear, dominant mode of variability, all of the methods considered yield rather similar bases with which to represent the data while differing in reconstruction accuracy for a given basis size. However, in the absence of such a clear scale separation, as in the case of daily geopotential height anomalies, the extracted bases differ much more significantly between the methods. We highlight the importance in such cases of carefully considering the relevant features of interest and of choosing the method that best targets precisely those features so as to obtain more easily interpretable results.
- Article
(11466 KB) - Full-text XML
- BibTeX
- EndNote





A ubiquitous step in climate analyses is the application of an initial dimension reduction method to obtain a low-dimensional representation of the data under study. This is, in part, driven by the purely practical fact that large, high-dimensional datasets are common, and to make analysis feasible, some initial reduction in dimension is required. Often, however, we would like to associate some degree of physical significance with the elements of the reduced basis, for instance by identifying separate modes of variability. Given the wide variety of possible dimension reduction methods to choose from, it is important to understand the strengths and limitations associated with each for the purposes of a given analysis.
Perhaps the most familiar example in climate science is provided by an empirical orthogonal function (EOF; Lorenz, 1956; Hannachi et al., 2007) or principal component analysis (PCA; Jolliffe, 1986), which identifies directions of maximum variance in the data, or, more generally, the directions maximizing a chosen norm. The difficulties inherent in interpreting EOF modes physically have been thoroughly documented (Dommenget and Latif, 2002; Monahan et al., 2009) and partly motivate various modifications of the basic EOF analysis (Kaiser, 1958; Richman, 1986; Jolliffe et al., 2003; Lee et al., 2007; Mairal et al., 2009; Witten et al., 2009; Jenatton et al., 2010).
Another approach to constructing interpretable representations is based on cluster analysis, which, in its simplest variants, identifies regions of phase space that are repeatedly visited (MacQueen, 1967; Ruspini, 1969; Dunn, 1973; Bezdek et al., 1984). The utility of clustering-based methods is founded on the apparent existence of recurrent flow patterns over a range of timescales (Michelangeli et al., 1995). As estimating the multidimensional probability density function (PDF) associated with the distribution of states is generally difficult, clustering methods attempt to detect groupings or regions of higher point density, which may in some cases be approximations to peaks in the underlying distribution, and otherwise detect preferred weather patterns or types (Legras et al., 1987; Mo and Ghil, 1988). Extensions to standard clustering algorithms may take into account the fact that such patterns usually exhibit some degree of persistence or quasi-stationarity (Dole and Gordon, 1983; Renwick, 2005). Hierarchical or partitioning-based clustering techniques, of which k-means is a popular example, have been widely used to identify spatial patterns associated with regimes or to classify circulation types (see, e.g., Mo and Ghil, 1988; Stone, 1989; Molteni et al., 1990; Cheng and Wallace, 1993; Hannachi and Legras, 1995; Kidson, 2000; Straus et al., 2007; Fereday et al., 2008; Huth et al., 2008; Pohl and Fauchereau, 2012; Neal et al., 2016). Despite their widespread use, there can be difficulties in interpreting the resulting patterns (Kidson, 1997), while ambiguities in selecting the number of clusters can lead to conflicting characterizations of regimes (Christiansen, 2007). In particular, while k-means is widely used due to its simplicity, if the data do not fall into well-defined, approximately spherical clusters, the method need not provide a particularly useful classification of each sample, in which case an alternative clustering algorithm may be more appropriate.
The output of clustering algorithms such as k-means is an assignment of each data point to a cluster and a collection of cluster centroids corresponding to the mean within each cluster. The result is a partition of the phase space in which the elements of each partition are taken to be well represented by the cluster mean, as in vector quantization applications (Lloyd, 1982; Forgey, 1965). While this can yield a useful decomposition of the data, the ideal case occurring when the data do indeed form well-defined clusters, a representation in terms of cluster means is not always effective or suitable for all applications. For instance, the k-means centroids need not be realized as observed points within the dataset1, and, by virtue of their definition, will generally not afford a good representation of edges or extrema of the observed data. When such features are relevant, a possible alternative is to employ methods that construct a basis from points lying on (or outside of) the convex hull of the data. An example of this approach is given by archetypal analysis (AA; Cutler and Breiman, 1994; Stone and Cutler, 1996; Seth and Eugster, 2016), in which the basis vectors are required to be convex linear combinations of the data points that minimize a suitable measure of the reconstruction error. This has the effect of identifying points corresponding to extrema of features within the data. Unlike partitioning-based cluster algorithms such as k-means, AA does not yield a partition of the data into a set of clusters, so that it is not so straightforward to assign observations to a set of regimes. Instead, each observation is represented as a linear combination of the reduced basis of archetypes with appropriate convex weights and is in this sense similar to PCA. Compared to PCA, however, the archetype basis may (in some cases) be more easily interpreted, as the basis vectors correspond to extreme points of the observed data, or convex combinations thereof, rather than abstract directions in the data space.
Unlike PCA and standard clustering methods, AA has only relatively recently found use in climate studies (Steinschneider and Lall, 2015; Hannachi and Trendafilov, 2017). As a result, there has been little comparison of the results of using AA for dimension reduction versus more traditional approaches. Dimension reduction methods such as PCA, k-means, and AA can all be expressed generically as approximately representing the data in terms of some set of basis vectors (Mørup and Hansen, 2012), possibly with an additional stochastic error term2,
where x(t) is the d-dimensional observation at time t, the corresponding reduced representation, and {wi} the set of k basis vectors. Each method differs in the definition or criteria used to obtain the basis {wi} and weights zi(t), and hence the choice of method necessarily plays a key role in the nature of the retained features in the data and the interpretation of subsequent results (Lau et al., 1994). Understanding how the methods differ is important for assessing the appropriateness of each for a given task and for comparing results between methods. For instance, AA is a natural choice when the salient features are in close correspondence to extremal points but might be less informative in representing data with a regime-like or clustered structure in which a single cluster must be represented by multiple archetypes. When the data exhibit an elliptical distribution in phase space, modes extracted by PCA are easily interpreted, and k-means clustering can also be expected to perform well, but this need not be the case for more complicated distributions. Thus, naïvely we might expect that a clustering-based approach might be more useful for the purpose of identifying recurrent regimes, whereas AA may be a better choice for locating extremes of the dynamics.
Ultimately though, a fuller understanding might be best obtained by using generalizations of the above methods or combinations of multiple methods. AA can be regarded as a constrained convex encoding (Lee and Seung, 1997) of the dataset, where the basis vectors are restricted to being linear combinations of observed data points. Relaxing this constraint allows for a more flexible reduction in which the archetypes may not be representable as convex combinations of the data (Mørup and Hansen, 2012), although the effectiveness of doing so will depend somewhat on the underlying data-generating process. The problem of finding a convex coding of a given dataset can be unified with PCA and k-means clustering by phrasing each as a generic matrix factorization problem (Singh and Gordon, 2008); we review the basic formulation in Sect. 2. In addition to providing a consistent framework for defining each method, it is straightforward to incorporate additional constraints or penalties, e.g., for the purposes of feature selection or to induce sparsity (Jolliffe et al., 2003; Lee et al., 2007; Mairal et al., 2009; Witten et al., 2009; Jenatton et al., 2010; Gerber et al., 2020). Solving the resulting (usually constrained) optimization problem amounts to learning a dictionary with which to represent the data, with different methods producing different dictionaries. By carefully defining the optimization problem, the learned dictionary can be tuned to target particular features in the data. Below, we demonstrate this process by utilizing a recently introduced regularized convex coding (Gerber et al., 2020), which allows for feature selection to be performed by varying a regularization parameter. By tuning the imposed regularization to optimize the reconstruction or prediction error, the relative performance of selecting a basis lying on or outside the convex hull can be compared to one that preferentially extracts cluster means.
The purpose of this paper is to explore some of the above issues in the context of climate applications, in the hope that this may provide a useful aid for researchers in constructing their own analyses. In particular, we aim to illustrate some of the strengths and weaknesses of PCA and other dimension reduction methods, using as examples k-means, AA, and general convex coding, by applying each method in a set of case studies. We first apply the methods to an analysis of global sea surface temperature (SST) anomalies, as in Hannachi and Trendafilov (2017). Interannual SST variability is in this case dominated by El Niño–Southern Oscillation (ENSO) activity (Wang et al., 2004), for which there is a large-scale separation between this mode and the sub-leading modes of variability, and consequently all methods are effective in detecting this feature of the data. Differences between the methods do arise at smaller scales, however. We then consider a similar analysis of daily 500 hPa geopotential height anomalies. Unlike SST, the time series of height anomalies generally does not exhibit noticeably large excursions corresponding to weather extremes; in this case, extremes in the data are characterized not by the amplitude of the anomalies, but by their temporal persistence. This demonstrates a limitation of all of the considered methods, namely, that (at least in their basic formulation) persistence or quasi-stationarity is not taken into account. Thus, a direct application of AA or convex codings may not be effective in detecting extremes, while clustering methods may be more informative in detecting recurrent weather patterns (to the extent that any such regimes are present in the analyzed fields).
The remainder of this paper is structured as follows. In Sect. 2 we review the dimension reduction methods used. In Sect. 3, we compare the results obtained using each method in a set of case studies to illustrate the distinctions between the methods. Finally, in Sect. 4 we summarize our observations and discuss possible future extensions.
In this section, we first describe the dimension reduction methods that we use in our case studies. As noted above, PCA, k-means, and convex coding applied to multidimensional data can all be phrased as matrix factorization problems. Given a collection3 of d-dimensional data points x(t)∈ℝd, , we may conveniently arrange the data into a T×d design matrix X with rows formed by the data samples. In this notation, the reduced representation Eq. (1) becomes
where is a T×k-dimensional matrix with rows giving the weights zi(t), and contains the basis vectors wi as columns. Note that here and below we assume that the columns of X have zero mean; if not, this can always be arranged by first centering the data,
where denotes the original data, IT×T the T×T identity matrix, and 1T the T-dimensional vector of ones.
The factors W and Z are calculated as the minimizers of a suitably chosen cost function , measuring (in some application-dependent sense) the quality of the reconstruction , subject to the constraint that they are within certain feasible regions ΩZ and ΩW,
A typical cost function takes the form of a decomposable loss function, measuring the reconstruction error, together with a set of penalty terms imposing any desired regularization, i.e.,
In Eq. (4) we have, for simplicity, supposed that W and Z are independently regularized, with the tunable parameters λW and λZ governing the amount of regularization. Common choices for the loss function include the ℓ2-norm4,
in which case the unregularized cost is proportional to the residual sum of squared errors (RSS), the Kullback–Leibler divergence for non-negative data,
or the wider class of Bregman divergences (Bregman, 1967; Banerjee et al., 2005; Singh and Gordon, 2008). In addition to the soft constraints imposed by the penalty terms ΦW(W) and ΦZ(Z), the feasible regions and define a set of hard constraints that must be obeyed by the optimal solutions. The definition of a given method thus comes down to a small number of modeling choices regarding the cost function and feasible regions.
PCA, in its synthesis formulation, is equivalent to minimizing an ℓ2-loss function with , i.e.,
where ∥A∥F denotes the Frobenius norm of a matrix, subject to the constraint that the reconstruction has rank at most k. The problem in this case has a global minimum (Eckart and Young, 1936) given by the singular value decomposition (SVD), and the retained basis vectors wi correspond to the directions of maximum variance. In our numerical case studies, we adopt the convention , W=V for the PCA factors W and Z, with the SVD of X=UΣVT for real X. While the existence of a direct numerical solution for the optimal factorization makes PCA very flexible and easy to apply, the basis vectors may be difficult to interpret, for instance if they have many non-zero components. Sparse variants of PCA that attempt to improve on this may be arrived at by introducing a sparsity-inducing regularization ΦW(W), of which a common choice is the ℓ1-penalty
The partitioning that results from k-means clustering may also be written in terms of a factorization . Whereas PCA by construction yields an orthonormal basis with which to represent the data, the k-means decomposition is in terms of the cluster centroids and iteratively attempts to minimize the within-cluster variance (Hastie et al., 2005). This is equivalent to minimizing an ℓ2-cost function, as in Eq. (7), subject to the constraint that the weights matrix Z has binary elements, , and rows with unit ℓ1-norm, ∥z(t)∥1=1. In other words, the optimization is performed within the feasible region
The corresponding basis matrix W then contains the cluster centroids wi as columns. Although both PCA and k-means can be seen to minimize the same objective function5, the additional constraints in k-means clustering mean that finding the exact clustering is NP-hard (Aloise et al., 2009; Mahajan et al., 2012), and heuristic methods must be used instead (e.g., Lloyd, 1982; Hartigan and Wong, 1979). These iterative methods are not guaranteed to find a globally optimal clustering and must be either run multiple times with different initial guesses or combined with more sophisticated global optimization strategies to reduce the chance of finding only a local minimum.
The convex codings that we employ below, like PCA and k-means, are based on minimizing the least squares loss Eq. (7). The least restricted version (Lee and Seung, 1997; Gerber et al., 2020) requires only that the reconstruction lies in the convex hull of the basis, or, in other words, that the weights Z satisfy the constraints
where the condition A⪰0 indicates an element-wise inequality. In the absence of any hard constraints on the basis W, the optimization problem to be solved reads
with ΩZ as in Eq. (10); note that, if these constraints are further tightened to require that the columns of Z be non-negative and orthonormal, , solving this optimization problem (in general, for λW=0) would yield the hard k-means clustering of the data (Li and Ding, 2006). In the absence of any regularization (λW=0), it follows from the Eckart–Young theorem that for a given basis size k the reconstruction error achieved by PCA is always no larger than that achieved by this convex coding, which in turn achieves a residual error that is smaller than that for k-means. Thus, were the goal to simply achieve the optimal least squares reconstruction error for a given basis size, PCA remains the preferred choice. The more constrained decomposition implied by performing a convex coding may yield advantages in terms of interpretability or feature selection. The choice of regularization ΦW provides further flexibility in this respect; for instance, an ℓ1-penalty as in Eq. (8) can be used to induce sparsity, while Gerber et al. (2020) suggest a penalty term of the form
observing that this places an upper bound on the sensitivity of the reconstruction to changes in the data. It is worth noting that, when combined with an ℓ2-loss function, as the regularization λW→∞ all of the basis vectors wi reduce to the global mean of the dataset.
For λW=0, the optimal basis vectors wi produced by solving Eq. (11) will tend to lie on or outside of the convex hull of the data. Standard AA adds a further more conservative constraint to force the wi to only lie on the convex hull, thus requiring that the archetypes are realizable in terms of convex combinations of the observed data. Under the more relaxed constraints, while the overall residual error might be reduced, one may extract basis vectors that, in reality, never occur and so are difficult to make sense of. In AA, the additional constraint amounts to requiring that W=XTCT for some non-negative with unit ℓ1-norm rows, i.e., C∈ΩC with
The corresponding optimization problem reads
with ΩZ as in Eq. (10). As for k-means, the optimization problem to be solved in performing either a convex coding or archetypal analysis cannot be solved exactly, and numerical methods must be employed to find the corresponding factorization. We describe one such algorithm for doing so in Appendix A.
Table 1Summary of the definitions of each of the four methods compared in this study. Each method is defined by a choice of cost function to be minimized together with a set of constraints placed on the factors Z and W (or Z and C for AA). The choices for each impact that nature of the features that each method extracts from a particular dataset.

The various choices of cost function and constraints defining the above methods are summarized in Table 1. While all of the methods fit within the broader class of matrix factorizations, the different choices of cost functions and constraints lead to important differences in the low-dimensional representation of the data produced by each method. For instance, in contrast to PCA, the basis vectors produced by k-means, convex coding, or AA are in general not orthogonal. In some circumstances, this non-orthogonality may be advantageous when the structure necessary to ensure orthogonal basis vectors (e.g., via appropriate cancellations) obscures important features or makes interpretation of the full PCA basis vectors difficult. A k-means clustering may, for example, provide a much more natural reduction of the data when multiple distinct, well-defined clusters are present. The cost function and choice of constraints that define convex coding and archetypal analysis imply that the optimal basis vectors produced by these methods are such that their convex hull (i.e., the set of all linear combinations of the basis vectors with weights summing to one) best fits the data. Consequently, both are well suited for describing data where points can be usefully characterized in terms of their relationship with a set of extreme values, be they spatial patterns of large positive or negative anomalies in a geophysical field or particular combinations of spectral components in a frequency domain representation of a signal. PCA and k-means may be less useful in such cases, as neither yields a decomposition of the data in terms of points at or outside of the boundaries of the observations. AA differs from more general convex encodings in imposing the stricter requirement that the dictionary elements, i.e., the archetypes, lie on the boundary of the data. It is, in this sense, conservative, in that the features extracted by AA lie on the convex hull of the data and so correspond to a set of extremes that are nevertheless consistent with the observed data. In the absence of any regularization (λW→0), the general convex codings that we consider admit basis vectors that lie well outside of the observed data. By doing so, the method finds a set of basis vectors whose convex hull better reconstructs the data than in AA, at the cost of representing it in terms of points that may not be physically realistic. This behavior and the impact of the different choices of cost function and constraints are sketched in Fig. 1.

Figure 1Illustration of the different decompositions obtained using k-means, regularized convex coding (denoted GPNH), and AA, and of the impact of the regularization parameter λW when using the penalty term Eq. (12). For increasing (from a to c) λW=0, 100, 1000, the number of selected features progressively decreases and the basis varies from lying outside the convex hull of the data to the global mean.
We now turn to a set of case studies that demonstrate some of the implications of the various differences noted above in realistic applications. We consider two particular examples that highlight the importance of considering the particular physical features of interest when choosing among possible dimension reduction methods. The first example that we consider, an analysis of SST anomalies, is characterized by a large separation of scales between modes of variability together with key physical modes, particularly ENSO, that can be directly related to extreme values of SST anomalies. This means that the basis vectors or spatial patterns extracted by PCA, k-means, and convex coding are for the most part rather similar in structure, and so the choice of method may be guided by other considerations, such as the level of reconstruction error. We then contrast this scenario with the example of an analysis of mid-latitude geopotential height anomalies, where there is neither scale separation nor coincidence of the physical modes solely with extreme anomaly values. As a result, methods that are based on constructing a convex coding of the data, without targeting features that capture the dynamical characteristics of the relevant modes, produce representations that are, arguably, more difficult to interpret and hence may be less suitable than clustering-based methods.
3.1 Sea surface temperature data
Following Hannachi and Trendafilov (2017), we first apply the methods described in Sect. 2 to monthly SST data. The source of the data is the Hadley Centre Sea Surface Temperature dataset (HadISST), version 1.1 (Rayner et al., 2003), consisting of monthly SST values on a global grid spanning the time period from January 1870 to December 2018. Monthly anomalies are calculated by removing from the full time series a linear warming trend and additive seasonal component, where the annual cycle is estimated based on the 1981 to 2010 base period. The analysis region is restricted to the region between 45.5∘ N and 45.5∘ S.
As the standard and most familiar method, we first perform PCA on the SST anomalies over the time period January 1870 to December 2018 to establish a baseline set of modes. The anomalies at each grid cell are area weighted by the square root of the cosine of the point's latitude. To provide a rough measure of the out-of-sample reconstruction error6, the EOFs and PCs are evaluated on the first 90 % of the anomaly time series (i.e., January 1870 to February 2004), and the root mean-square error (RMSE) defined by
is computed for the training set and for the test set consisting of the remaining 10 % of the data. In Eq. (15), is the ith dimension of the reconstruction from k EOFs, and T refers to the size of the training or test set, as appropriate. We consider the results of retaining the first k modes for ; for reference, the first 40 modes account for approximately 85 % of the total variance. The fraction of the total variance in the training set associated with the leading 10 modes is shown in Fig. 2. The most obvious feature of this variance spectrum is the well-known separation between the first and subsequent modes, with the first mode associated with ENSO variability on interannual timescales and large spatial scales. This is evident in the spatial patterns of the EOFs shown in Fig. 3, in which the first mode shows the canonical ENSO pattern of SST anomalies, while the higher-order modes correspond to spatially smaller-scale variability.

Figure 2Fraction of variance explained by the first 10 modes obtained from PCA of SST anomalies.
With the above EOF patterns as a point of reference, we now turn to comparing the representation of the dataset produced by each of k-means, archetypal analysis, and convex coding. In each case, the same dataset (i.e., latitude weighted, detrended anomalies) is used as input to the dimension reduction method. The individual data points consist of anomaly maps at each time step; in other words, the dimension reduction is performed in the state space rather than the sample space (Efimov et al., 1995), such that each dictionary vector corresponds to a particular spatial pattern of SST anomalies. We fit each method using dictionaries of size on the first 90 % of the dataset, using the last 10 % of samples to provide a simple picture of out-of-sample performance.
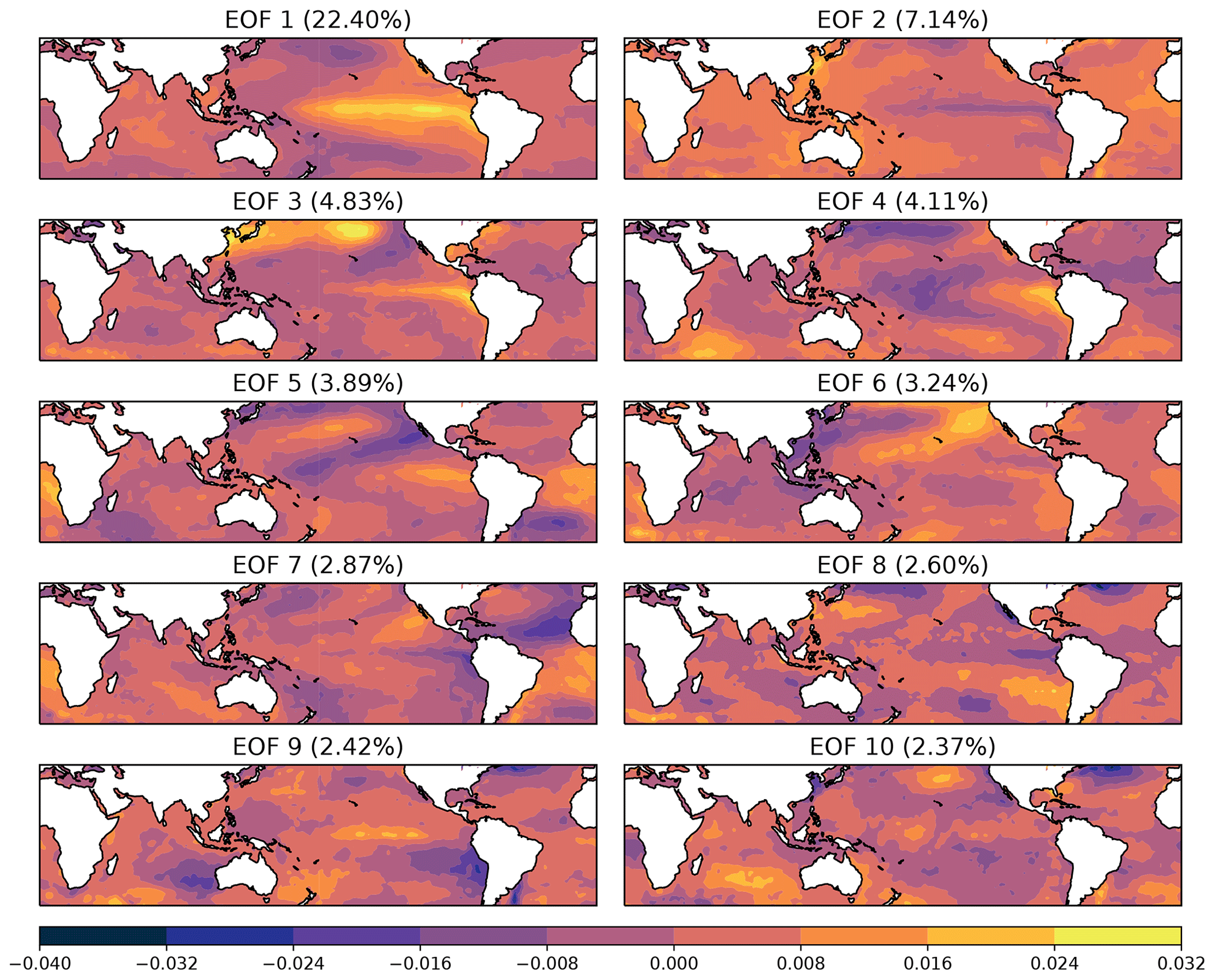
Figure 3Spatial patterns for the leading 10 modes obtained from PCA of SST anomalies.
We consider the results of a k-means clustering analysis of the data first. For each value of k, the algorithm is restarted 100 times with different initial conditions, and the partitioning found to have the lowest reconstruction error is chosen. As is typical of clustering procedures where the number of clusters must be specified a priori, determining the most appropriate choice of k is non-trivial. One commonly used heuristic is to inspect a “scree” plot of the within-cluster sum of squares (Tibshirani et al., 2001),
where is the size of cluster Ci as a function of the number of clusters. The preferred number of clusters k∗ is identified as the location of an elbow or kink in this curve if any such feature is present. Alternatively, various indices (see, e.g., Arbelaitz et al., 2013, for a review) or Monte Carlo procedures, such as the gap statistic (Tibshirani et al., 2001), have been proposed for assessing whether a given k is suitable. For the present application, plots of the normalized within-cluster sum of squares and the gap statistic computed using 100 Monte Carlo experiments for each k with a null model generated by PCA are shown in Fig. 4. The plot of Wk as a function of k does not show an obvious elbow at any particular k≤20; similarly, using the gap statistic curve, one would conclude that the k=1 cluster is preferred7. This simply reflects the fact that the anomaly data do not form well-separated clusters (with respect to the assumed Euclidean distance) in the full state space, making interpreting the different clusters as dynamically distinct regimes difficult, although this does not preclude using the clustering model as a discrete representation of the full dynamics (e.g., Kaiser et al., 2014).
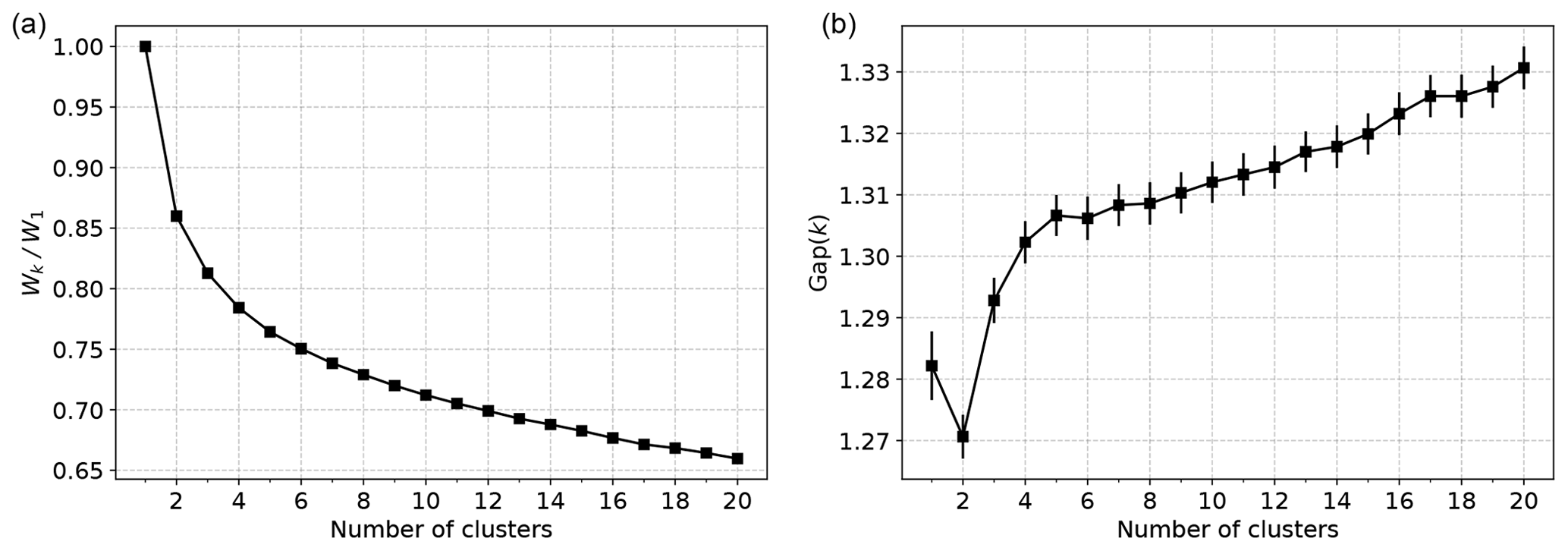
Figure 4Plots of the normalized within-cluster sum of squares (a), Wk, and the corresponding gap statistic Gap(k) (b) for k-means clustering of global SST anomalies.
The partitioning provided by a simple clustering method such as k-means may also still be useful in classifying samples so long as proximity in state space, or similarity more generally, carries meaningful information for an application. In the case of detrended SST anomalies, the magnitudes and spatial distribution of the anomalies are of themselves informative, and key drivers such as ENSO manifest as relatively large excursions from anomalies associated with higher-frequency variability. Consequently, a k-means clustering of the anomalies does result in a partition in which the cluster centroids, or a subset thereof, can be identified with physical modes, as the algorithm finds several clusters consisting of these extremes of the point cloud, while the remainder partition the bulk of the data. The simplest, if somewhat trivial, case for which this can be seen is for k=3 clusters, shown in Fig. 5. Two of the plotted centroids are recognizable as canonical El Niño and La Niña patterns, while the last corresponds to a near-climatological state. The former two clusters are dominated by months at the ends of the first principal axis (i.e., along the leading EOF). The fact that two clusters are required to represent both phases of the leading EOF is due to the fact that the overall sign of the cluster centroids, which correspond to points in the data space, is meaningful, unlike in PCA; note that the same is true for the convex coding methods to be considered below. To obtain some sense of the relative distributions of the points within each of the clusters, in Fig. 6 we show the projection of the data into two dimensions generated by metric multidimensional scaling (MDS). The points assigned to the first and second clusters are those furthest from the mean state, while the remaining cluster accounts for the bulk region. The difference between the first and second centroids is closely aligned with the leading EOF. Similar behavior results when a larger number of clusters is specified.

Figure 5Spatial patterns of the cluster centroids obtained from a k-means clustering of SST anomalies with k=3. The number of months assigned to each cluster is shown above each map.
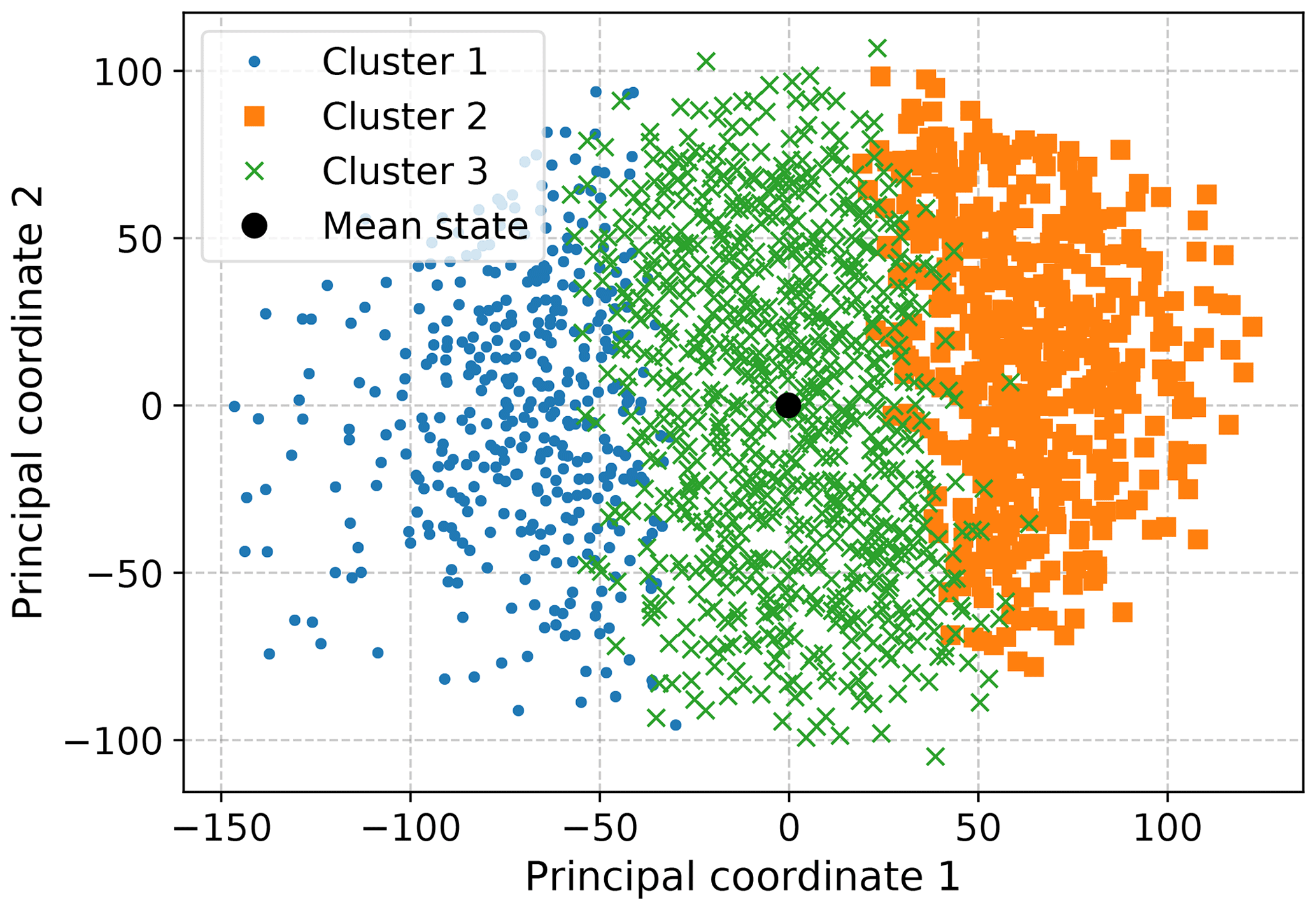
Figure 6Two-dimensional projection of HadISST SST anomalies obtained by metric MDS with a Euclidean distance measure. The assignment of each point to the clusters produced by k-means clustering with k=3 in Fig. 5 is also shown.
The fact that, due to the dominating role of ENSO variability, a k-means clustering results in several clusters corresponding to large-magnitude anomalies in turn implies that the corresponding centroids will be relatively close to the convex hull of the anomaly point cloud. Consequently, these centroids will also closely resemble a subset of the archetypes derived from an archetypal analysis of the same data, at least qualitatively. Relaxing the requirement that the dictionary vectors lie on the convex hull, one may still expect that a convex coding applied to the data will identify features along the same directions, albeit with inflated magnitude so as to reduce the resulting reconstruction error. To verify this, we perform a standard archetypal analysis and a regularized convex coding of the detrended anomalies, in each case restarting the optimization algorithm 100 times and choosing the best encoding from the multiple starts. The regularization in Eq. (12) is used; to illustrate the effect of this regularization, we show results for λW=0 (i.e., no regularization) and λW=103. The fitted archetypes for k=3 are shown in Fig. 7, and the corresponding dictionary vectors for the regularized convex coding are shown in Fig. 8. The patterns obtained using the two methods in Figs. 7 and 8 are very similar; in both cases, El Niño and La Niña patterns are found together with a third configuration containing a cold tongue in the equatorial Pacific with positive anomalies to the north and south, as noted by Hannachi and Trendafilov (2017). However, the magnitude of the anomalies is substantially larger when using an unregularized convex coding as the fitted dictionary vectors are chosen to sit well outside the observed point cloud. While the states correspond to very similar relative signs of anomalies, it is arguably more difficult to interpret the individual dictionary vectors found by the unregularized convex coding physically, as the large anomalies represent far more extreme states than are observed in the data. On the other hand, this also permits a much smaller reconstruction error for a given basis size and so may be preferable when a higher-fidelity reconstruction is required8. The effect of the regularization Eq. (12) is to penalize over-dispersion of the dictionary vectors and so select features that are insensitive to small variations in the input data. For sufficiently large λW, the resulting states lie on or within the convex hull of the data and as a result are more comparable to the states found by AA or k-means. This is illustrated in Fig. 9, from which it can be seen that the basis vectors produced by the regularized convex coding are closer (in Euclidean distance) to those produced by AA than the unregularized basis vectors.

Figure 7Spatial patterns of the archetypes found from AA with k=3 archetypes.
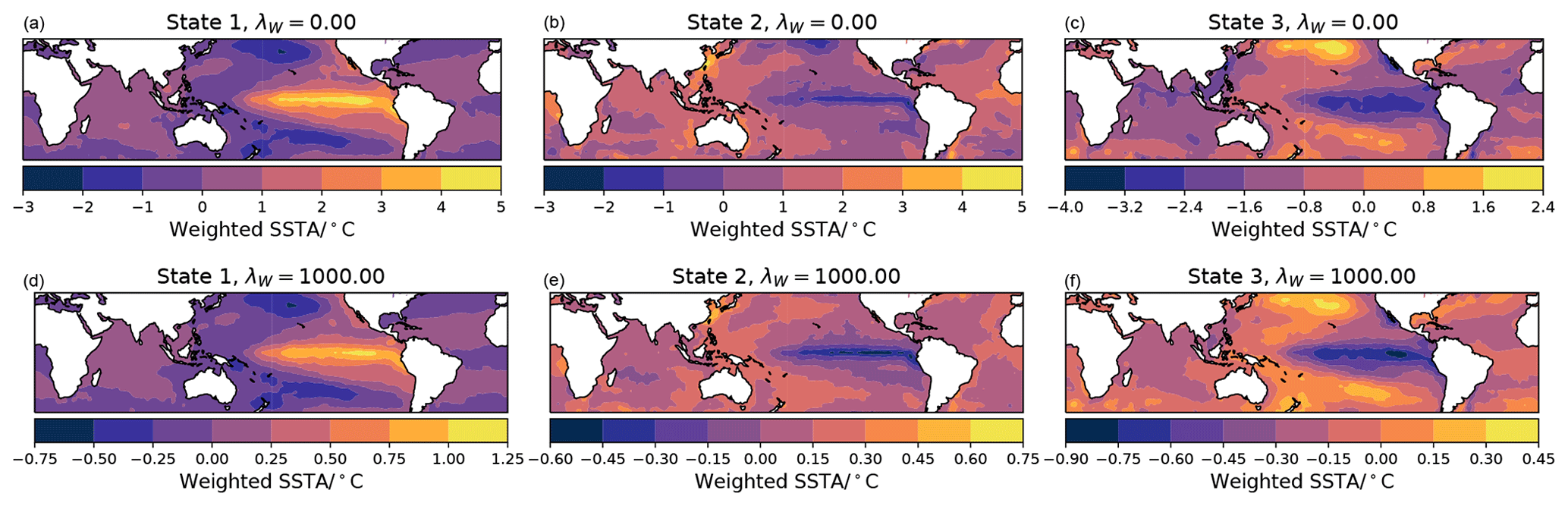
Figure 8Spatial patterns for the convex coding dictionary vectors for λW=0 (a–c) and λW=103.
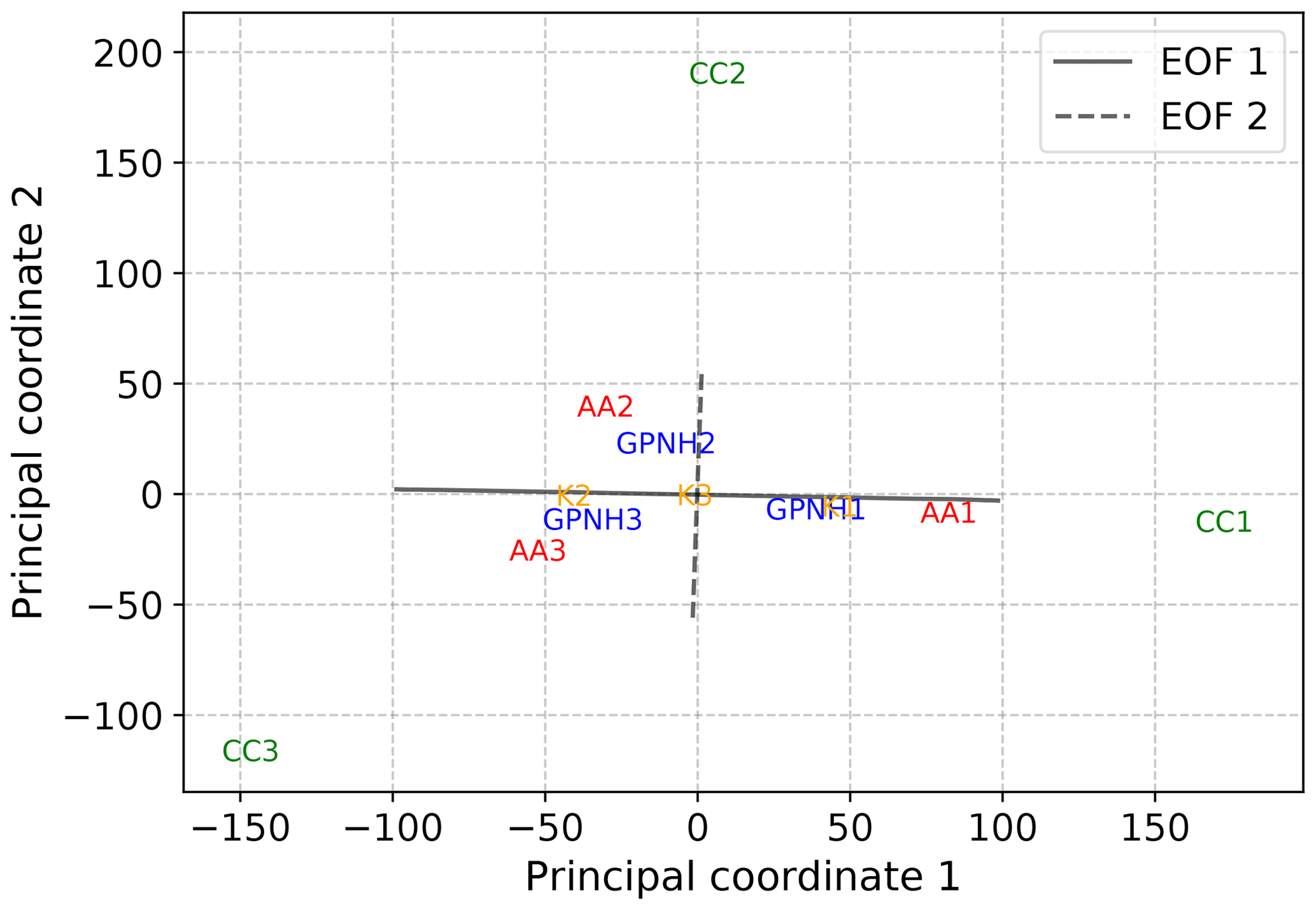
Figure 9Two-dimensional projection of basis vectors obtained by AA, convex coding, and k-means based on a metric MDS analysis with Euclidean dissimilarities. The projected locations of the basis vectors for each method are indicated by the labels AA, CC, GPNH, and K for AA, convex coding with λW=0, convex coding with λW=1000, and k-means, respectively. For reference, the images under the MDS projection of line segments lying along the directions of the first and second EOFs, with lengths proportional to the variance explained by each, are also shown.
This trade-off between reproducing the data with small errors and constraining the basis vectors to be close to the observed data is also evident in Fig. 10, where the reconstruction RMSEs within the training and held-out test datasets for each of the methods are plotted as a function of the dimension of the reduced-order representation. In the absence of any regularization, the RMSE produced by a convex coding of the data is close to the globally optimal result obtained from PCA. For λW=103, the obtained RMSE is larger and similar to that for AA, while k-means leads to the largest errors due to the very coarse representation of each data point by the centroid of its assigned cluster. It follows that, for a given number of basis vectors, an unregularized convex coding yields performance approaching that of PCA in terms of reconstruction errors, while AA and k-means in turn are more constrained and hence reproduce the data with somewhat larger errors. The ordering of the methods in terms of reconstruction error observed in Fig. 10 is expected to be the case more generally. As noted in Sect. 2, PCA provides the globally optimal reconstruction of the data matrix with a given rank, in the absence of any constraints, and so amounts to a lower bound on the achievable reconstruction error. Of the remaining methods, the additional freedom to locate the basis elements outside of the convex hull of the data when performing an unregularized convex coding allows for a lower reconstruction error than is achievable using archetypes. For a given basis size the hard clustering resulting from k-means generally results in the largest RMSE. For larger values of the regularization λW, the optimal basis elements sit within the convex hull of the data and provide a fuzzy representation of the data with a progressively increasing RMSE. In this particular analysis of SST data, the performance of the different methods with respect to reconstruction error is one distinguishing factor that may guide the choice of method; while all four produce similar large-scale spatial patterns, for a given basis size PCA provides the lowest reconstruction error and might be preferred if information loss is a significant concern.
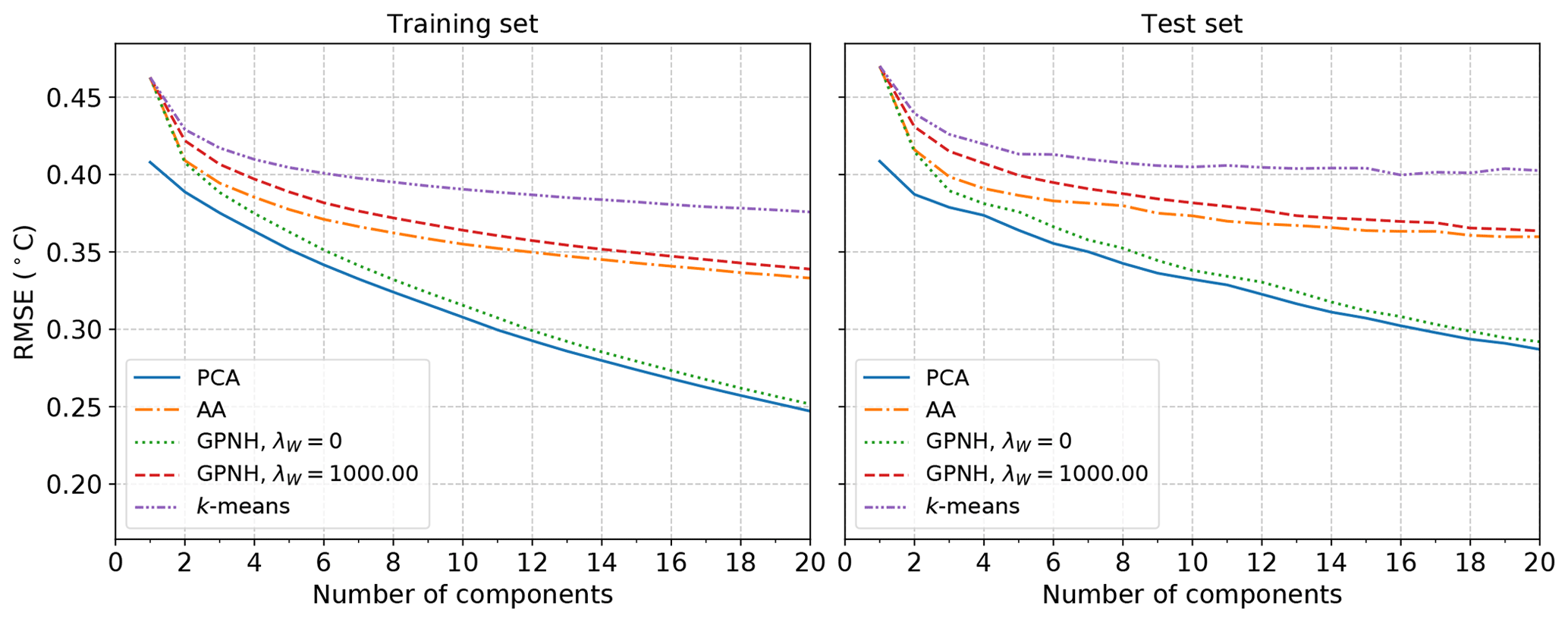
Figure 10Training and test set RMSE for the reconstruction of SST anomalies resulting from each of the methods.
3.2 Geopotential height anomalies
SST anomalies are an example of a dataset in which a dominant mode is well separated in scale from subleading modes of variability. As a result, all of the dimension reduction methods that we consider extract similar bases (patterns) with which to represent the data, and these can be identified with well-known physical modes. Moreover, physically interesting events such as extremes correspond to large-magnitude anomalies relative to the mean state, i.e., at the boundary of the point cloud, and so can be directly extracted by those methods that look for dictionary vectors in the convex hull of the data. This is not true for many variables of interest, however, and so we now compare the behavior of the methods when applied to data that do not exhibit these features.
We consider Northern Hemisphere (NH) daily mean anomalies of 500 hPa geopotential height, , between 1 January 1958 and 31 December 2018. The geopotential height data used are obtained from the Japanese 55-year Reanalysis (JRA-55, Kobayashi et al., 2015; Harada et al., 2016). Anomalies are formed by subtracting the climatological daily mean based on the 1 January 1981 to 31 December 2010 reference period. Unlike monthly SST, there is no clear scale separation in the resulting time series; in Fig. 11 we show the leading EOFs and the percentage of the total variance explained by each. Additionally, the characterization of regimes is more complicated. In particular, physically significant features in the height field are expected to be quasi-stationary or persistent (Michelangeli et al., 1995; Dole and Gordon, 1983; Mo and Ghil, 1988) and are not solely distinguished by their location in the state space. Such features may therefore be better identified as modes of the state space PDF, arising either due to longer residency times or frequent recurrence of particular states. Where this gives rise to regions of higher density in state space, clustering algorithms such as k-means might be expected to reasonably well represent the corresponding regimes. Convex reduction methods, on the other hand, default to being less sensitive to recurrence; as in the preceding SST example, the fitted dictionary vectors will correspond to points near the boundary of observed data. In doing so, AA and methods based on convex coding preferentially represent the data in terms of deep, but potentially infrequent or highly transient, lows or highs. While this remains an adequate representation simply for reconstructing the full observations, the resulting basis may be more difficult to relate to traditionally identified metastable atmospheric regimes, for instance.
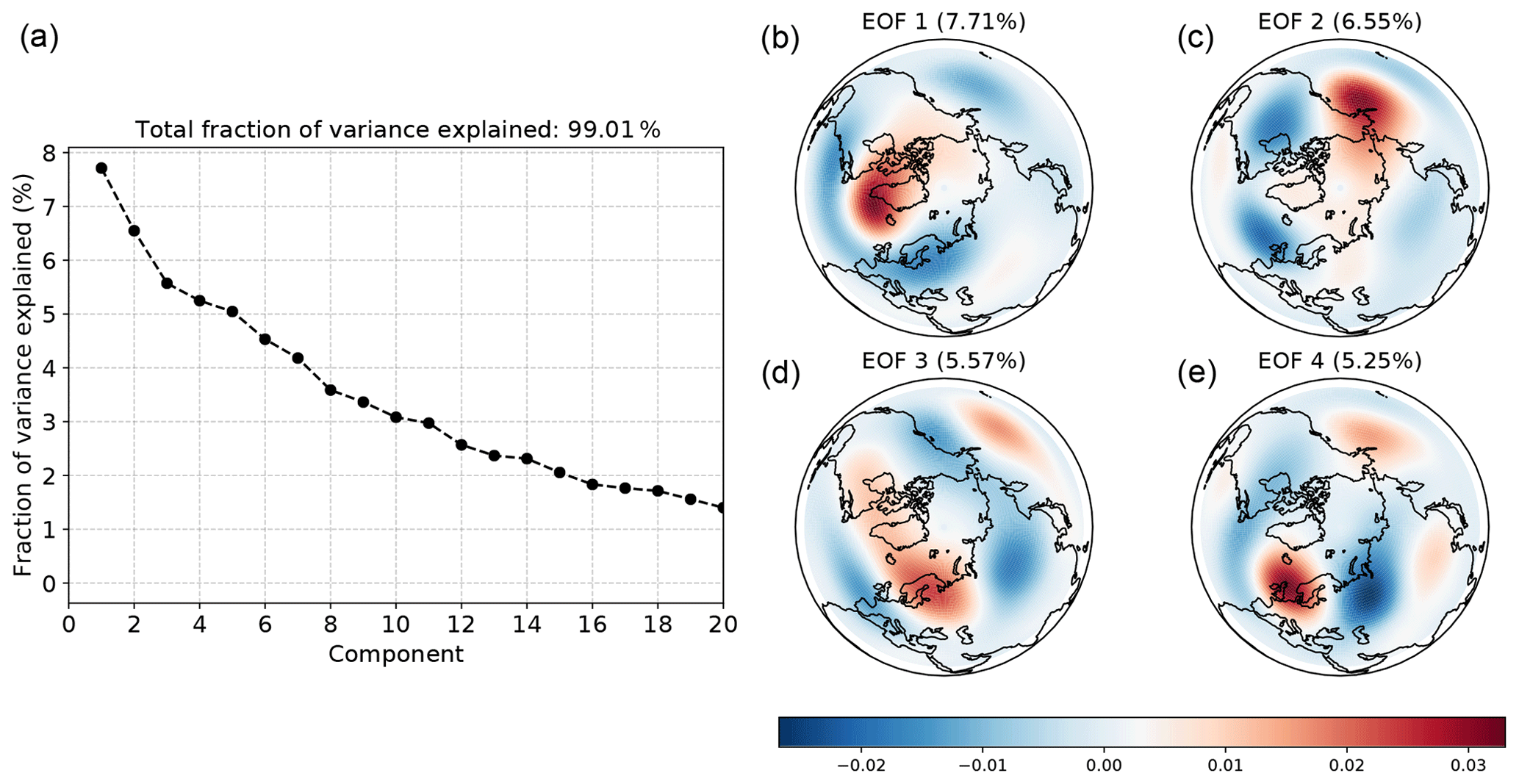
Figure 11Fraction of the total variance associated with each of the first 20 of 167 retained EOF modes of daily NH 500 hPa geopotential anomalies (a) and the spatial patterns associated with the leading 4 modes. The 167 retained modes account for approximately 99 % of the variance.
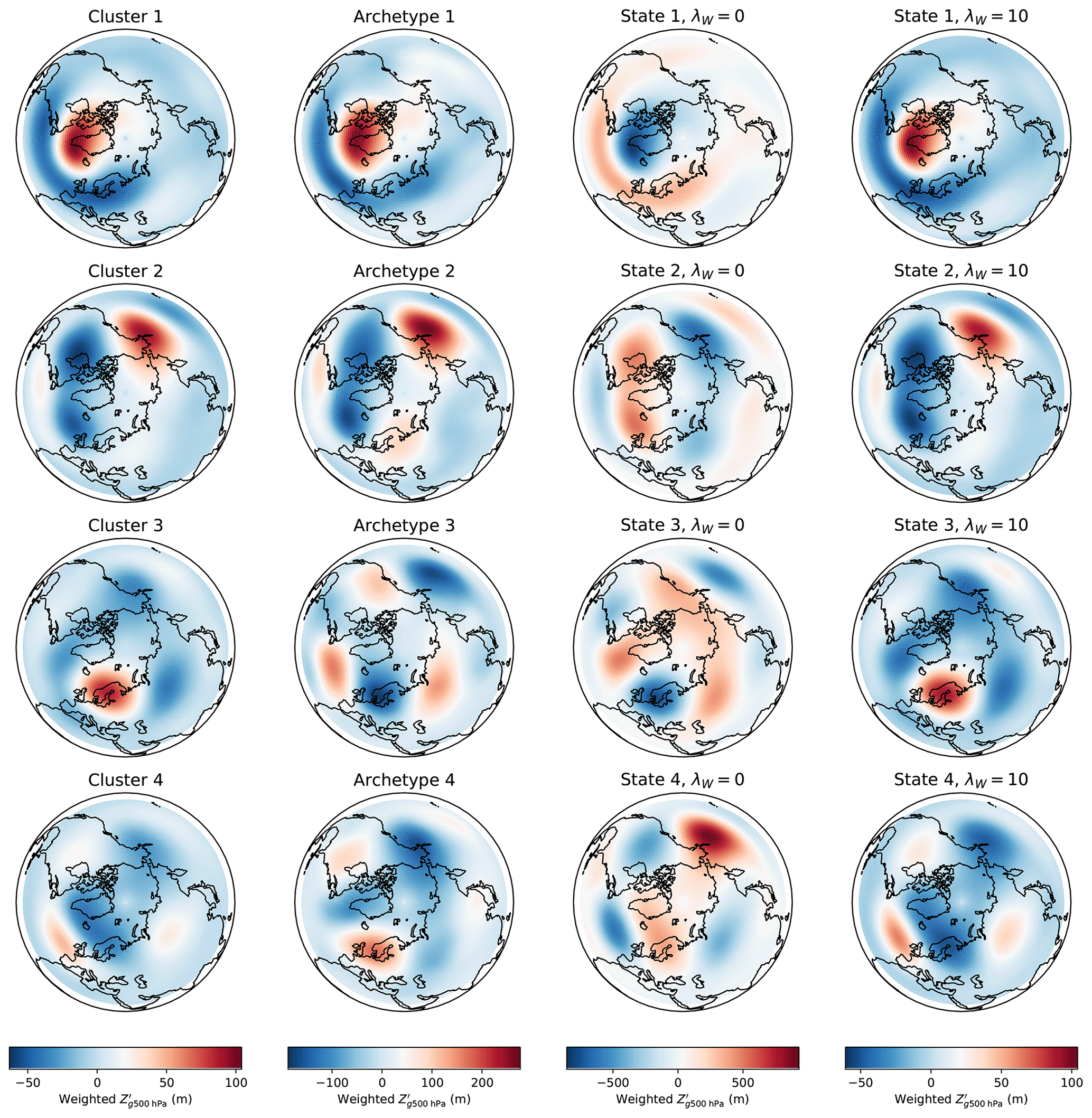
Figure 12Spatial patterns of geopotential height anomalies corresponding to the k-means centroids (first column), archetypes (second column), convex coding basis vectors with λW=0 (third column), and convex coding basis vectors with λW=10.
In the case of NH geopotential height anomalies, the cluster centroids, archetypes, and dictionary basis vectors that result from applying k-means, AA, and convex coding to the leading 167 PCs9 of are shown for k=4 clusters in Fig. 12. Note that inspection of the scree plots (not shown) does not indicate a strong preference for a given number of clusters or states for k≤20, and we choose k=4 as a simple example. The relative dispositions of each of the states with respect to each other, as measured by Euclidean distance, are visualized in Fig. 13 on the basis of a two-dimensional metric MDS. In some respects, the performance of the different methods is similar to that seen in the SST example; for example, as expected on general grounds, the ordering of the methods with respect to achieved RMSE (not shown) is the same as in Fig. 10. Similarly, AA and the unregularized convex coding select, by design, basis vectors that lie on or outside of the convex hull of the data, with the latter having the freedom to choose a basis corresponding to much larger departures from the mean so as to reduce the reconstruction error; note that the precise degree to which the basis vectors lie outside the convex hull will depend on the particular data at hand, but the behavior is otherwise generic. However, unlike the SST case, the data do not exhibit a dominant axis of variability; i.e., there is no clear scale separation between modes. In Fig. 13 this manifests as the absence of a clearly preferred axis along which the basis vectors are distributed10; cf. Fig. 9. As the variance in the data is not dominated by a single principal axis, the basis vectors extracted by each of the methods are more evenly distributed around the point cloud, in turn leading to greater differences between the fitted bases.

Figure 13Two-dimensional projection of spatial patterns of geopotential height anomalies obtained using the various dimension reduction methods by metric MDS. The results of transforming line segments lying along the directions of the first and second EOFs, as in Fig. 9, are also shown.
While all the methods identify a feature that is strongly reminiscent of the North Atlantic Oscillation, there is somewhat more variation in the remaining representative states, in contrast to the case of SST anomalies. In particular, the centroids identified by k-means are no longer in close correspondence to the representative states constructed by either AA or an unregularized convex coding. The k-means centroids are characterized by relatively small magnitude anomalies with positive amplitude at longitudes associated with blocking (Pelly and Hoskins, 2003); in particular, the location of the anticyclonic anomaly in cluster 3 in Fig. 12 closely coincides with the center of action of the EU1 (Barnston and Livezey, 1987) or SCA (Bueh and Nakamura, 2007) pattern associated with Scandinavian blocking. The archetypes, in comparison, appear to exhibit a more pronounced wave-train structure, in addition to corresponding to generally larger magnitude anomalies. As expected, the basis obtained via an unregularized convex coding represents far larger anomalies again, defining representative states that are much more extreme than the bulk of the observed daily anomaly fields. The role of the regularization in feature selection is clearly illustrated by comparing the two right-most columns of Fig. 12. By increasing the regularization parameter, the method can be tuned to place less emphasis on capturing large-amplitude, noisy variations and target less sensitive features in the data. In this case, for λW≈1 the convex coding basis vectors are in close agreement with the archetypes, while for λW≈10 they essentially coincide with the k-means centroids. In this sense, by appropriate choice of regularization it is possible to interpolate between a representation of the data in terms of points on the convex hull and mean features, depending on how much weight is placed on minimizing the reconstruction error. While here we consider only a few levels of regularization for illustrative purposes, in general the degree to which this is done, i.e., the choice of λW, can be guided by standard model selection methods, such as cross-validation.
In the absence of any regularization, the patterns obtained by a convex coding and by AA correspond to extreme departures from the mean state but cannot necessarily be directly interpreted as individually representing particular physical extremes. As noted above, this arises due to the fact that such extremes are not necessarily associated with boundaries in state space but may instead be due to extended residence or persistence of a given (non-extreme) state. This difficulty in directly relating atmospheric extremes to a basis produced by AA or similar methods can be clearly demonstrated by considering the representation of a given event in terms of this basis. A dramatic example is provided by the 2010 summer heatwave in western Russia that saw an extended period of well-above-average daily temperatures and poor air quality and was associated with substantial excess mortality and economic losses (Barriopedro et al., 2011; Shaposhnikov et al., 2014). The upper-level circulation during July 2010 was characterized by persistent blocking over eastern Europe (Dole et al., 2011; Matsueda, 2011). The associated monthly mean pattern of height anomalies for that month (see, e.g., Fig. 2 of Dole et al., 2011) most closely resembles the pattern for cluster 3 obtained with k-means in Fig. 12. Consistent with this is the fact that most days during July 2010 are assigned to this cluster, as shown in Fig. 14. Consequently, cluster 3 might be reasonably well interpreted as representing (a class of) European blocking events.
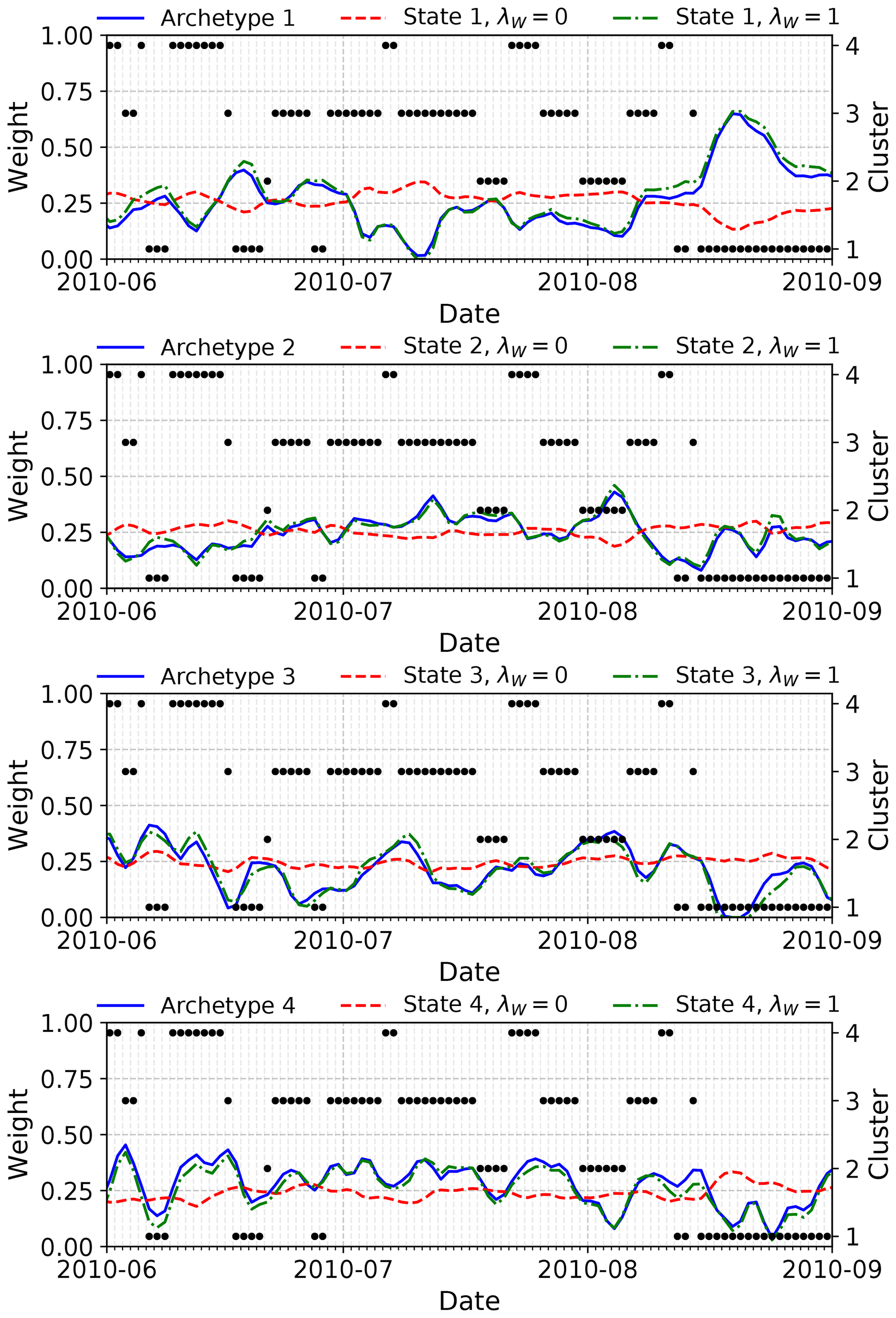
Figure 14Time series of basis weights (lines) associated with each archetype produced by AA and the states produced by convex coding with and without regularization, for k=4 states during the 2010 boreal summer. The corresponding k-means cluster assignments for each day are shown as points. Note that the monthly mean for July 2010 associated with the heatwave event most closely resembles cluster 3 in the k-means clustering, to which most of the daily anomalies for that month are also assigned.
In contrast, despite the severity of this event, individual daily height anomalies during July 2010 are not unambiguously identified as extremes by AA or the less constrained convex coding. In Fig. 14 we show the time series of weights associated with the basis vectors found by AA and by convex coding either without regularization, λW=0, or with a regularization parameter, λW=1, which for these data yields dictionary vectors very similar to those found by AA. For all three cases, roughly equal weights are assigned to each basis vector during July 2010. The complete anomaly is therefore represented as a mixture of all of the dictionary vectors rather than being assigned to a single characteristic type of extreme. Evidently, any single basis pattern extracted by these methods does not directly correspond to a particular indicator of extreme weather conditions; extreme events of practical concern may be spread across multiple basis vectors, making identifying such events in this representation more difficult. The hard clustering obtained using k-means is perhaps more easily interpreted in this case, as the resulting cluster affiliations show frequent occurrences of the European blocking cluster (i.e., cluster 3 in Figs. 12 and 14) during the peak heatwave period, with a smaller number of days assigned to clusters 2 and 4, suggesting a clearer picture of residence in a single, persistent blocking state. On the other hand, the coarse representation of the actual anomalies by the single cluster 3 centroid is poor compared to the reconstruction provided by AA and convex coding but could be improved by, for example, making use of a soft clustering algorithm instead. To summarize, in the geopotential height case where extreme events are defined not just by large anomalies but also by persistent structures, methods such as k-means or the regularized convex coding applied here provide a more direct starting point for analyses of such events. These methods better identify the relevant structures and so provide bases that are more amenable to interpretation in terms of physical extremes. Unregularized convex coding and archetypal analysis, on the other hand, are less appropriate in this respect, as they do not yield a direct assignment of extreme events to individual states.
Finally, it is worth noting that, as in the SST case study, the ambiguous classification of events provided by the convex-hull-based methods is less of a problem when state space location alone (e.g., temperature anomalies) is in itself a relevant feature. When this is not the case, as here, methods that take advantage of state space density, either due to recurrence or persistence, may be more easily interpreted, or alternatively hybrid approaches could be used in order to partition the state space.
Representing a high-dimensional dataset in terms of a highly reduced basis or dictionary is an essential step in many climate analyses. Beyond the practical necessity of doing so, it is usually also desirable for the individual elements of the representation to be identifiable with physically relevant features for the sake of interpretation. A wide range of popular dimension reduction methods, including PCA, k-means clustering, AA, and convex coding, can be written down as particular forms of a basic matrix factorization problem. These methods differ in the details of the measure of cost that is optimized and the feasible solution regions, with the result that different methods yield representations suitable for targeting different features of the data. Of the methods considered here, PCA extracts directions in state space corresponding to maximal variability, k-means locates central points, and AA and similar convex codings identify points on or outside the convex hull of the observed data and so find a representation in terms of extreme points in state space. As different features may be relevant for different applications, it is important to consider these distinctions between these factorization methods and carefully choose a method that is effective for extracting the features of interest.
In some cases, the representations obtained using different dimension reduction methods are very similar, and one can identify more or less easily interpretable features using any given method. This is exemplified by our first case study of SST anomalies, in which the presence of the dominant ENSO mode ensures that PCA, k-means clustering, AA, and convex coding all identify similar bases corresponding to well-known physical modes. In this case, the main distinction between the methods arises in the nature of the classification of the data (e.g., hard versus soft clustering) and the accuracy with which the original data can be reconstructed for a given level of compression.
As our second case study demonstrates, neglecting the important role played by temporal persistence in dynamically relevant features can lead to representations that are difficult to interpret and may not be as effective for studying persistent states. Clustering-based approaches, or more generally methods that attempt to approximate modes in the PDF rather than targeting the tails of the distribution, are likely to be a better choice in these circumstances. This can also be achieved by appropriate regularization so as to reduce sensitivity to transient features or outliers, which otherwise drive the definition of the basis in methods such as AA. In all of the methods that we have considered, a lack of independence in time is not explicitly modeled. Extensions to the simple methods that we have considered to account for non-independence are also possible, albeit usually at the cost of increased complexity. Singular spectrum analysis (see, e.g., Jolliffe, 1986) is a familiar example of one such extension for PCA. Similar generalizations can also be constructed for convex decompositions of the data. For instance, by virtue of the decomposability of the least squares cost function, it is possible to construct a joint convex discretization of instantaneous and lagged values of the variables of interest, which forms the basis of the scalable probabilistic approximation method (Gerber et al., 2020). In this approach, the decomposition may be parameterized in terms of a transition matrix relating the weights at different times, thus naturally incorporating a temporal constraint into the discretization. An associated regularization parameter allows the amount of temporal regularization to be appropriately tuned. Moreover, because the optimization problem remains separable in this case, the individual optimization steps can be parallelized and the method remains scalable. More sophisticated regularization strategies (Horenko, 2020) can further improve upon the performance of the method, even in the case of relatively small sample sizes and feature degeneracies.
The idea of imposing temporal regularization via assumed dynamics for the latent weights suggests that another approach to better target particular features is to start from an appropriately defined generative model or otherwise explicitly incorporate appropriate time dependence when constructing a reduction method. An underlying probabilistic model is already suggested by the stochastic constraints that are imposed on the weights in AA and in convex coding, a feature that is already taken advantage of in the case of the scalable probabilistic approximation. Corresponding latent variable models can naturally be constructed for PCA (Roweis, 1998; Tipping and Bishop, 1999) and AA (Seth and Eugster, 2016). From the point of view of incorporating temporal dependence between samples, starting from a probabilistic model is fruitful as it is conceptually straightforward to incorporate a model for the dynamics of the latent weights zt (Lawrence, 2005; Wang et al., 2006; Damianou et al., 2011). Taken together with a choice of conditional distribution for the observations, point estimation in the latent variable model is once again achieved by optimization of a suitable loss function. Regularization is in this context provided by suitable choice of prior distributions for the dictionary and weights. An additional advantage of starting from a generative model is the possibility of applying the full machinery of Bayesian inference rather than obtaining only point estimates (Mnih and Salakhutdinov, 2008; Salakhutdinov and Mnih, 2008; Virtanen et al., 2008; Shan and Banerjee, 2010; Gönen et al., 2013), although scaling such analyses remains a challenging issue. While this approach appears to be natural for constructing dimension reduction methods that may flexibly take into account more complicated dependence structures, it is by no means guaranteed to provide improved low-dimensional representations of the data and likely depends heavily on choices such as the assumed generative process for the weights. For example, in simple constructions with weights drawn according to a Gaussian process, in the absence of strong prior information the fitted bases are driven to be very similar to those found by ordinary PCA in order to maximize the likelihood of the observed data, while at the same time being substantially more expensive to fit. Thus, the development of temporally regularized methods derived from underlying stochastic models remains a topic for further investigation.
As noted in Sect. 2, the optimization problem posed in either the convex coding case or by AA cannot be solved analytically. Moreover, the combined cost function is not convex in the full set of variables W and Z (or C and Z for AA). It is, though, convex in either W or Z separately, when the other is held fixed, and local stationary points may be straightforwardly found by alternating updates of the basis and weights. For instance, using the penalty function Eq. (12), we may update W with fixed Z via
For fixed W, Z may then be updated by projected gradient descent. An alternative that avoids having to perform direct projection onto the simplex (Mørup and Hansen, 2012) is to reparameterize the latent weights Z as
which automatically satisfies the stochastic constraint on z(t), and Hti is required only to be non-negative, making the necessary projection trivial. The factors W and H may then be updated via, e.g., a sequence of projected gradient descent update steps of the form
where, for simplicity, we have assumed that the derivative of the penalty term ΦW may be written in the form
which is the case if, for instance, ΦW∝Tr[WGWWT] for some symmetric matrix GW. The step-size parameters ηW and ηH may either be fixed or determined by performing a line search. This procedure may be iterated until the successive changes in the total cost fall below a given tolerance. As convergence to a global minimum is not guaranteed, in practice this procedure is repeated for multiple initial guesses for W and Z to try to improve the likelihood of locating the optimal solution. Inspecting the update equations Eq. (A3), the cost per iteration is seen to scale as . In particular, in the usual case of interest with , the leading contribution to the cost is linear in each of d, T, and k, i.e., O(dTk), making the method suitable for large datasets and comparable with k-means and similar decompositions (Mørup and Hansen, 2012; Gerber et al., 2020).
The HadISST SST dataset used in this study is provided by the UK Met Office Hadley Centre and may be accessed at https://www.metoffice.gov.uk/hadobs/hadisst/ (Rayner et al., 2003). The JRA-55 geopotential height data used are made available through the JRA-55 project and may be accessed following the procedures described at https://jra.kishou.go.jp/JRA-55/index_en.html (Kobayashi et al., 2015). All source code used to perform the analyses presented in the main text may be found at https://doi.org/10.5281/zenodo.3723948 (Harries and O'Kane, 2020). The PCA and k-means results and the visualizations using metric MDS were obtained using the routines provided by the scikit-learn Python package (Pedregosa et al., 2011). Plots were generated using Python package Matplotlib (Hunter, 2007).
All of the authors designed the study. TJO'K proposed the specific case studies, and DH implemented the code to perform the numerical comparisons and generated all plots and figures. All of the authors contributed to the direction of the study, discussion of results, and the writing and approval of the manuscript.
The authors declare that they have no conflict of interest.
The authors would like to thank Illia Horenko for continual guidance and for his valuable inputs over the course of this project and Vassili Kitsios and Didier Monselesan for encouragement and helpful discussions about the various methods.
This research has been supported by the Australian Commonwealth Scientific and Industrial Research Organisation (CSIRO) through a ResearchPlus postdoctoral fellowship and by the CSIRO Decadal Climate Forecasting Project.
This paper was edited by Zoltan Toth and reviewed by two anonymous referees.
Aloise, D., Deshpande, A., Hansen, P., and Popat, P.: NP-hardness of Euclidean sum-of-squares clustering, Mach. Learn., 75, 245–248, https://doi.org/10.1007/s10994-009-5103-0, 2009. a
Arbelaitz, O., Gurrutxaga, I., Muguerza, J., Pérez, J. M., and Perona, I.: An extensive comparative study of cluster validity indices, Pattern Recognition, 46, 243–256, 2013. a
Banerjee, A., Merugu, S., Dhillon, I. S., and Ghosh, J.: Clustering with Bregman Divergences, J. Mach. Learn. Res., 6, 1705–1749, https://doi.org/10.1007/s10994-005-5825-6, 2005. a
Barnston, A. G. and Livezey, R. E.: Classification, Seasonality and Persistence of Low-Frequency Atmospheric Circulation Patterns, Mon. Weather Rev., 115, 1083–1126, https://doi.org/10.1175/1520-0493(1987)115<1083:csapol>2.0.co;2, 1987. a
Barriopedro, D., Fischer, E. M., Luterbacher, J., Trigo, R. M., and García-Herrera, R.: The Hot Summer of 2010: Redrawing the Temperature Record Map of Europe, Science, 332, 220–224, https://doi.org/10.1126/science.1201224, 2011. a
Bezdek, J. C., Ehrlich, R., and Full, W.: FCM: The Fuzzy c-Means Clustering Algorithm, Comput. Geosci., 10, 191–203, https://doi.org/10.1109/igarss.1988.569600, 1984. a
Bregman, L.: The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming, USSR Comp. Math. Math+, 7, 200–217, https://doi.org/10.1016/0041-5553(67)90040-7, 1967. a
Bueh, C. and Nakamura, H.: Scandinavian pattern and its climatic impact, Q. J. Roy. Meteor. Soc., 133, 2117–2131, https://doi.org/10.1002/qj.173, 2007. a
Cheng, X. and Wallace, J. M.: Cluster Analysis of the Northern Hemisphere Wintertime 500-hPa Height Field: Spatial Patterns, J. Atmos. Sci., 50, 2674–2696, https://doi.org/10.1175/1520-0469(1993)050<2674:CAOTNH>2.0.CO;2, 1993. a
Christiansen, B.: Atmospheric Circulation Regimes: Can Cluster Analysis Provide the Number?, J. Climate, 20, 2229–2250, https://doi.org/10.1175/JCLI4107.1, 2007. a
Cutler, A. and Breiman, L.: Archetypal Analysis, Technometrics, 36, 338–347, 1994. a
Damianou, A. C., Titsias, M. K., and Lawrence, N. D.: Variational Gaussian Process Dynamical Systems, in: Advances in Neural Information Processing Systems 24 (NIPS 2011), 12–17 December 2011, Granada, Spain, 2510–2518, 2011. a
Ding, C. and He, X.: K-means clustering via principal component analysis, in: Proceedings of the twenty-first international conference on Machine learning (ICML 2004), 4–8 July 2004, Banff, Canada, 29–37, 2004. a
Dole, R. M., Hoerling, M., Perlwitz, J., Eischeid, J., Pegion, P., Zhang, T., Quan, X.-W., Xu, T., and Murray, D.: Was there a basis for anticipating the 2010 Russian heat wave?, Geophys. Res. Lett., 38, L06702, https://doi.org/10.1029/2010GL046582, 2011. a, b
Dole, R. M. and Gordon, N. D.: Persistent Anomalies of the Extratropical Northern Hemisphere Wintertime Circulation: Geographical Distribution and Regional Persistence Characteristics, Mon. Weather Rev., 111, 1567–1586, https://doi.org/10.1175/1520-0493(1983)111<1567:PAOTEN>2.0.CO;2, 1983. a, b
Dommenget, D. and Latif, M.: A cautionary note on the interpretation of EOFs, J. Climate, 15, 216–225, https://doi.org/10.1175/1520-0442(2002)015<0216:ACNOTI>2.0.CO;2, 2002. a
Dunn, J. C.: A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters, J. Cybernetics, 3, 32–57, https://doi.org/10.1080/01969727308546046, 1973. a
Eckart, C. and Young, G.: The approximation of one matrix by another of lower rank, Psychometrika, 1, 211–218, https://doi.org/10.1007/BF02288367, 1936. a
Efimov, V., Prusov, A., and Shokurov, M.: Patterns of interannual variability defined by a cluster analysis and their relation with ENSO, Q. J. Roy. Meteor. Soc., 121, 1651–1679, 1995. a
Fereday, D. R., Knight, J. R., Scaife, A. A., Folland, C. K., and Philipp, A.: Cluster Analysis of North Atlantic–European Circulation Types and Links with Tropical Pacific Sea Surface Temperatures, J. Climate, 21, 3687–3703, https://doi.org/10.1175/2007JCLI1875.1, 2008. a
Forgey, E.: Cluster analysis of multivariate data: Efficiency vs. interpretability of classification, Biometrics, 21, 768–769, 1965. a
Gerber, S., Pospisil, L., Navandar, M., and Horenko, I.: Low-cost scalable discretization, prediction, and feature selection for complex systems, Sci. Adv., 6, eaaw0961, https://doi.org/10.1126/sciadv.aaw0961, 2020. a, b, c, d, e, f
Gönen, M., Khan, S., and Kaski, S.: Kernelized Bayesian matrix factorization, in: Proceedings of the 30th International Conference on Machine Learning (ICML 2013), 17–19 June 2013, Atlanta, USA, 864–872, 2013. a
Hannachi, A. and Legras, B.: Simulated annealing and weather regimes classification, Tellus A, 47, 955–973, https://doi.org/10.1034/j.1600-0870.1995.00203.x, 1995. a
Hannachi, A. and Trendafilov, N.: Archetypal analysis: Mining weather and climate extremes, J. Climate, 30, 6927–6944, https://doi.org/10.1175/JCLI-D-16-0798.1, 2017. a, b, c, d
Hannachi, A., Jolliffe, I. T., and Stephenson, D. B.: Empirical orthogonal functions and related techniques in atmospheric science: A review, Int. J. Climatol., 27, 1119–1152, https://doi.org/10.1002/joc.1499, 2007. a
Harada, Y., Kamahori, H., Kobayashi, C., Endo, H., Kobayashi, S., Ota, Y., Onoda, H., Onogi, K., Miyaoka, K., and Takahashi, K.: The JRA-55 Reanalysis: Representation of Atmospheric Circulation and Climate Variability, J. Meteorol. Soc. Jpn. Ser. II, 94, 269–302, https://doi.org/10.2151/jmsj.2016-015, 2016. a
Harries, D. and O'Kane, T. J.: Matrix factorization case studies code, Zenodo, https://doi.org/10.5281/zenodo.3723948, 2020. a
Hartigan, J. A. and Wong, M. A.: Algorithm AS 136: A K-Means Clustering Algorithm, J. Roy. Stat. Soc. C-App., 28, 100–108, https://doi.org/10.2307/2346830, 1979. a
Hastie, T., Tibshirani, R., and Friedman, J.: The Elements of Statistical Learning: Data Mining, Inference and Prediction, Springer, New York, USA, 2005. a
Horenko, I.: On a scalable entropic breaching of the overfitting barrier in machine learning, Neural Computation, arXiv [preprint], arXiv:2002.03176, 8 February 2020. a
Hunter, J. D.: Matplotlib: A 2D graphics environment, Comput. Sci. Eng., 9, 90–95, https://doi.org/10.1109/MCSE.2007.55, 2007. a
Huth, R., Beck, C., Philipp, A., Demuzere, M., Ustrnul, Z., Cahynová, M., Kyselý, J., and Tveito, O. E.: Classifications of Atmospheric Circulation Patterns, Ann. NY Acad. Sci., 1146, 105–152, https://doi.org/10.1196/annals.1446.019, 2008. a
Jenatton, R., Obozinski, G., and Bach, F.: Structured Sparse Principal Component Analysis, in: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 13–15 May 2010, Sardinia, Italy, 366–373, 2010. a, b
Jolliffe, I.: Principal component analysis, Springer Verlag, New York, USA, 1986. a, b
Jolliffe, I. T., Trendafilov, N. T., and Uddin, M.: A Modified Principal Component Technique Based on the LASSO, J. Comput. Graph. Stat., 12, 531–547, https://doi.org/10.1198/1061860032148, 2003. a, b
Kaiser, E., Noack, B. R., Cordier, L., Spohn, A., Segond, M., Abel, M., Daviller, G., Östh, J., Krajnović, S., and Niven, R. K.: Cluster-based reduced-order modelling of a mixing layer, J. Fluid Mech., 754, 365–414, 2014. a
Kaiser, H. F.: The varimax criterion for analytic rotation in factor analysis, Psychometrika, 23, 187–200, https://doi.org/10.1007/BF02289233, 1958. a
Kidson, J. W.: The Utility Of Surface And Upper Air Data In Synoptic Climatological Specification Of Surface Climatic Variables, Int. J. Climatol., 17, 399–413, https://doi.org/10.1002/(SICI)1097-0088(19970330)17:4<399::AID-JOC108>3.0.CO;2-M, 1997. a
Kidson, J. W.: An analysis of New Zealand synoptic types and their use in defining weather regimes, Int. J. Climatol., 20, 299–316, https://doi.org/10.1002/(SICI)1097-0088(20000315)20:3<299::AID-JOC474>3.0.CO;2-B, 2000. a
Kobayashi, S., Ota, Y., Harada, Y., Ebita, A., Moriya, M., Onoda, H., Onogi, K., Kamahori, H., Kobayashi, C., Endo, H., Miyaoka, K., and Takahashi, K.: The JRA-55 Reanalysis: General Specifications and Basic Characteristics, J. Meteorol. Soc. Jpn. Ser. II, 93, 5–48, https://doi.org/10.2151/jmsj.2015-001, 2015 (data available at: https://jra.kishou.go.jp/JRA-55/index_en.html, last access: 12 April 2019). a, b
Lau, K.-M., Sheu, P.-J., and Kang, I.-S.: Multiscale Low-Frequency Circulation Modes in the Global Atmosphere, J. Atmos. Sci., 51, 1169–1193, 1994. a
Lawrence, N.: Probabilistic Non-linear Principal Component Analysis with Gaussian Process Latent Variable Models, J. Mach. Learn. Res., 6, 1783–1816, 2005. a
Lee, D. D. and Seung, H. S.: Unsupervised Learning by Convex and Conic Coding, in: Advances in Neural Information Processing Systems 9 (NIPS 1996), 2–5 December 1996, Denver, USA, 515–521, 1997. a, b
Lee, H., Battle, A., Raina, R., and Ng, A. Y.: Efficient Sparse Coding Algorithms, in: Advances in Neural Information Processing Systems 19 (NIPS 2006), 4–7 December 2006, Vancouver, Canada, 801–808, 2007. a, b
Legras, B., Desponts, T., and Piguet, B.: Cluster analysis and weather regimes, in: Seminar on the Nature and Prediction of Extra Tropical Weather Systems, 7–11 September 1987, Reading, UK, 123–150, 1987. a
Li, T. and Ding, C.: The Relationships Among Various Nonnegative Matrix Factorization Methods for Clustering, in: Proceedings of the Sixth International Conference on Data Mining (ICDM'06), 18–22 December 2006, Hong Kong, China, 362–371, 2006. a
Lloyd, S.: Least squares quantization in PCM, IEEE T. Inform. Theory, 28, 129–137, https://doi.org/10.1109/TIT.1982.1056489, 1982. a, b
Lorenz, E. N.: Empirical Orthogonal Functions and Statistical Weather Prediction, Tech. rep., Massachusetts Institute of Technology, Cambridge, UK, 1956. a
MacKay, D. J. C.: Information theory, inference and learning algorithms, Cambridge University Press, Cambridge, UK, 2003. a
MacQueen, J.: Some methods for classification and analysis of multivariate observations, in: Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, 21 June–18 July 1965 and 27 December 1965–7 January 1966, Berkeley, USA, 281–297, 1967. a
Mahajan, M., Nimbhorkar, P., and Varadarajan, K.: The planar k-means problem is NP-hard, Theor. Comput. Sci., 442, 13–21, https://doi.org/10.1016/j.tcs.2010.05.034, 2012. a
Mairal, J., Bach, F., Ponce, J., and Sapiro, G.: Online Dictionary Learning for Sparse Coding, in: Proceedings of the Twenty-Sixth International Conference on Machine Learning, 14–18 June 2009, Montreal, Canada, 689–696, 2009. a, b
Matsueda, M.: Predictability of Euro-Russian blocking in summer of 2010, Geophys. Res. Lett., 38, L06801, https://doi.org/10.1029/2010GL046557, 2011. a
Michelangeli, P.-A., Vautard, R., and Legras, B.: Weather Regimes: Recurrence and Quasi Stationarity, J. Atmos. Sci., 52, 1237–1256, https://doi.org/10.1175/1520-0469(1995)052<1237:WRRAQS>2.0.CO;2, 1995. a, b
Mnih, A. and Salakhutdinov, R. R.: Probabilistic Matrix Factorization, in: Advances in Neural Information Processing Systems 20 (NIPS 2007), 3–6 December 2007, Vancouver, Canada, 1257–1264, 2008. a
Mo, K. and Ghil, M.: Cluster analysis of multiple planetary flow regimes, J. Geophys. Res.-Atmos., 93, 10927–10952, https://doi.org/10.1029/JD093iD09p10927, 1988. a, b, c
Molteni, F., Tibaldi, S., and Palmer, T. N.: Regimes in the wintertime circulation over northern extratropics. I: Observational evidence, Q. J. Roy. Meteor. Soc., 116, 31–67, https://doi.org/10.1002/qj.49711649103, 1990. a
Monahan, A. H., Fyfe, J. C., Ambaum, M. H. P., Stephenson, D. B., and North, G. R.: Empirical Orthogonal Functions: The Medium is the Message, J. Climate, 22, 6501–6514, https://doi.org/10.1175/2009JCLI3062.1, 2009. a
Mørup, M. and Hansen, L. K.: Archetypal analysis for machine learning and data mining, Neurocomputing, 80, 54–63, https://doi.org/10.1016/j.neucom.2011.06.033, 2012. a, b, c, d, e
Neal, R., Fereday, D., Crocker, R., and Comer, R. E.: A flexible approach to defining weather patterns and their application in weather forecasting over Europe, Meteorol. Appl., 23, 389–400, https://doi.org/10.1002/met.1563, 2016. a
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E.: Scikit-learn: Machine Learning in Python, J. Mach. Learn. Res., 12, 2825–2830, 2011. a
Pelly, J. L. and Hoskins, B. J.: A New Perspective on Blocking, J. Atmos. Sci., 60, 743–755, https://doi.org/10.1175/1520-0469(2003)060<0743:ANPOB>2.0.CO;2, 2003. a
Pohl, B. and Fauchereau, N.: The Southern Annular Mode Seen through Weather Regimes, J. Climate, 25, 3336–3354, https://doi.org/10.1175/JCLI-D-11-00160.1, 2012. a
Rayner, N. A., Parker, D. E., Horton, E. B., Folland, C. K., Alexander, L. V., Rowell, D. P., Kent, E. C., and Kaplan, A.: Global analyses of sea surface temperature, sea ice, and night marine air temperature since the late nineteenth century, J. Geophys. Res.-Atmos., 108, 4407, https://doi.org/10.1029/2002JD002670, 2003 (data available at: https://www.metoffice.gov.uk/hadobs/hadisst/, last access: 29 April 2019). a, b
Renwick, J. A.: Persistent Positive Anomalies in the Southern Hemisphere Circulation, Mon. Weather Rev., 133, 977–988, https://doi.org/10.1175/MWR2900.1, 2005. a
Richman, M. B.: Rotation of Principal Components, J. Climatol., 6, 293–335, https://doi.org/10.1177/1746847713485834, 1986. a
Roweis, S. T.: EM algorithms for PCA and SPCA, in: Advances in Neural Information Processing Systems 10 (NIPS 1997), 1–6 December 1997, Denver, USA, 626–632, 1998. a, b
Ruspini, E. H.: A New Approach to Clustering, Inform. Control, 15, 22–32, 1969. a
Salakhutdinov, R. and Mnih, A.: Bayesian Probabilistic Matrix Factorization using Markov Chain Monte Carlo, in: Proceedings of the Twenty-Fifth International Conference on Machine Learning (ICML'08), 5–9 July 2008, Helsinki, Finland, 880–887, 2008. a
Seth, S. and Eugster, M. J.: Probabilistic archetypal analysis, Mach. Learn., 102, 85–113, https://doi.org/10.1007/s10994-015-5498-8, 2016. a, b, c
Shan, H. and Banerjee, A.: Generalized Probabilistic Matrix Factorizations for Collaborative Filtering, in: Proceedings of the Tenth IEEE International Conference on Data Mining, 14–17 December 2010, Sydney, Australia, 1025–1030, 2010. a
Shaposhnikov, D., Revich, B., Bellander, T., Bedada, G. B., Bottai, M., Kharkova, T., Kvasha, E., Lezina, E., Lind, T., Semutnikova, E., and Pershagen, G.: Mortality related to air pollution with the Moscow heat wave and wildfire of 2010, Epidemiology, 25, 359–364, https://doi.org/10.1097/EDE.0000000000000090, 2014. a
Singh, A. P. and Gordon, G. J.: A Unified View of Matrix Factorization Models, in: Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Part II, 15–19 September 2008, Antwerp, Belgium, 358–373, 2008. a, b
Steinschneider, S. and Lall, U.: Daily Precipitation and Tropical Moisture Exports across the Eastern United States: An Application of Archetypal Analysis to Identify Spatiotemporal Structure, J. Climate, 28, 8585–8602, https://doi.org/10.1175/JCLI-D-15-0340.1, 2015. a
Stone, E. and Cutler, A.: Introduction to archetypal analysis of spatio-temporal dynamics, Physica D, 96, 110–131, https://doi.org/10.1016/0167-2789(96)00016-4, 1996. a
Stone, R. C.: Weather types at Brisbane, Queensland: An example of the use of principal components and cluster analysis, Int. J. Climatol., 9, 3–32, https://doi.org/10.1002/joc.3370090103, 1989. a
Straus, D. M., Corti, S., and Molteni, F.: Circulation Regimes: Chaotic Variability versus SST-Forced Predictability, J. Climate, 20, 2251–2272, https://doi.org/10.1175/JCLI4070.1, 2007. a
Tibshirani, R., Walther, G., and Hastie, T.: Estimating the number of clusters in a data set via the gap statistic, J. Roy. Stat. Soc. B, 63, 411–423, https://doi.org/10.1111/1467-9868.00293, 2001. a, b
Tipping, M. E. and Bishop, C. M.: Probabilistic Principal Component Analysis, J. Roy. Stat. Soc. B, 61, 611–622, https://doi.org/10.1111/1467-9868.00196, 1999. a, b
Virtanen, T., Cemgil, A. T., and Godsill, S.: Bayesian extensions to non-negative matrix factorisation for audio signal modelling, in: Proceedings of the 2008 IEEE International Conference on Acoustics, Speech, and Signal Processing, 30 March–4 April 2008, Las Vegas, USA, 1825–1828, 2008. a
Wang, C., Xie, S.-P., and Carton, J. A.: A Global Survey of Ocean–Atmosphere Interaction and Climate Variability, American Geophysical Union (AGU), 1–19, https://doi.org/10.1029/147GM01, 2004. a
Wang, J., Hertzmann, A., and Fleet, D. J.: Gaussian Process Dynamical Models, in: Advances in Neural Information Processing Systems 18 (NIPS 2005), 5–8 December 2005, Vancouver, Canada, 1441–1448, 2006. a
Witten, D. M., Tibshirani, R., and Hastie, T.: A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis, Biostatistics, 10, 515–534, https://doi.org/10.1093/biostatistics/kxp008, 2009. a, b
A simple example would be a naïve analysis of noisy annular data, for which k-means may give rise to centroids lying within the annulus; as noted above, in general the success of all of the methods considered in the following will depend on the underlying topology of the data.
Probabilistic formulations of PCA and AA have also been proposed (Roweis, 1998; Tipping and Bishop, 1999; Seth and Eugster, 2016), in which the problem is formulated as inference under an appropriate latent variable model; similarly, soft k-means is well known to be closely related to Gaussian mixture modeling, e.g., MacKay (2003). For simplicity, in the following comparisons we will only consider the deterministic formulations of the methods.
In the following, we use notation appropriate for a time series of observations with separate samples indexed by time t, but of course the discussion is not limited to this case.
The ℓp-norm of a vector x∈ℝd is given by for p>0, while for p=0 the ℓ0-norm is defined as the number of non-zero components of x.
See Ding and He (2004) for additional discussion of the relationship between PCA and k-means.
Of course, in practice proper estimates of the out-of-sample performance would be obtained by an appropriate cross-validation procedure or similar. However, as here we are primarily interested in the qualitative differences between the different methods in terms of extracting recognizable states, we do not focus on the technical details of model selection or optimizing predictive performance and simply present these out-of-sample estimates to show the general features of each method.
We note that, when using a null model generated by PCA, the gap curve in Fig. 4 might be considered to indicate possible clustering into five clusters within the single, large cluster. However, this conclusion depends strongly on the precise null model used to generate the reference data.
Similar remarks can be made for the AA/PCH-δ model proposed in Mørup and Hansen (2012).
Clustering on the PCs was done so as to reduce the overall cost of the methods; we have checked that, for small numbers of clusters, the spatial patterns that result are very similar.
Similar behavior is evident for different numbers of states; e.g., for k=3 the MDS projection results in a triangular arrangement of points with the climatological point located close to the centroid of the resulting shape.