the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 21 Jul 2023
| 21 Jul 2023
Using orthogonal vectors to improve the ensemble space of the ensemble Kalman filter and its effect on data assimilation and forecasting
Yung-Yun Cheng
Shu-Chih Yang
Zhe-Hui Lin
Yung-An Lee
The space spanned by the background ensemble provides a basis for correcting forecast errors in the ensemble Kalman filter. However, the ensemble space may not fully capture the forecast errors due to the limited ensemble size and systematic model errors, which affect the assimilation performance. This study proposes a new algorithm to generate pseudomembers to properly expand the ensemble space during the analysis step. The pseudomembers adopt vectors orthogonal to the original ensemble and are included in the ensemble using the centered spherical simplex ensemble method. The new algorithm is investigated with a six-member ensemble Kalman filter implemented in the 40-variable Lorenz model. Our results suggest that the ensemble singular vector, the ensemble mean vector, and their orthogonal components can serve as effective pseudomembers for improving the analysis accuracy, especially when the background has large errors.
- Article
(3652 KB) - Full-text XML
- BibTeX
- EndNote





The ensemble Kalman filter (EnKF) has the great advantage of using flow-dependent background error covariance (BEC) and has been widely applied to state estimation in geophysics. The BEC is estimated by the background ensemble, and its characteristic is crucial since it determines how the observations are spread out to correct the model state. The space spanned by the background ensemble members (the ensemble space) is expected to capture the dynamically growing errors, and the ensemble space provides a basis for corrections.
However, the use of a finite ensemble size can cause the underestimation of background error variance, and the background error correlation is less optimally represented due to the sampling error. Therefore, the growing errors may not be well captured, and corrections from the EnKF are less optimal. Bocquet and Carrassi (2017) indicated that the stability of the EnKF relies on the subspace spanned by the ensemble members that represent the unstable–neutral subspace. In other words, maintaining the ensemble space is important for the EnKF performance. Strategies such as additive covariance inflation (Whitaker et al., 2008) or hybrid methods (Hamill and Snyder, 2000) are commonly used to increase the dimensionality of the ensemble. These methods expand the overall ensemble space but are operated empirically without a particular direction.
Previous studies have suggested that vectors stimulate the growing modes can improve the dimensionality of the ensemble space and the performance of the EnKF. For example, Carrassi et al. (2008) used bred vectors as the direction of the analysis increment to update the analysis states in an unstable area. Yang et al. (2015) used a two-sided method to apply the initial ensemble singular vectors (IESVs) as additive inflation to correct the fastest-growing errors in a quasi-geostrophic model. Chang et al. (2020), under the framework of a hybrid-gain data assimilation framework (Penny, 2014), used part of the variational information orthogonal to the EnKF analysis perturbation to correct the EnKF means. These studies emphasize the importance of generating additional effective correction. Inspired by these works, this study proposes generating pseudoensemble members to increase the ensemble space to better capture forecast errors without increasing the computational cost. We investigate whether the use of pseudomembers could improve the analysis and forecast and which type of pseudomember is most effective in this regard.
This paper is organized as follows. Section 2 introduces the generation of pseudomembers. Section 3 presents the impact of using pseudomembers for EnKF analysis. Section 4 provides the summary and discussion of this work.
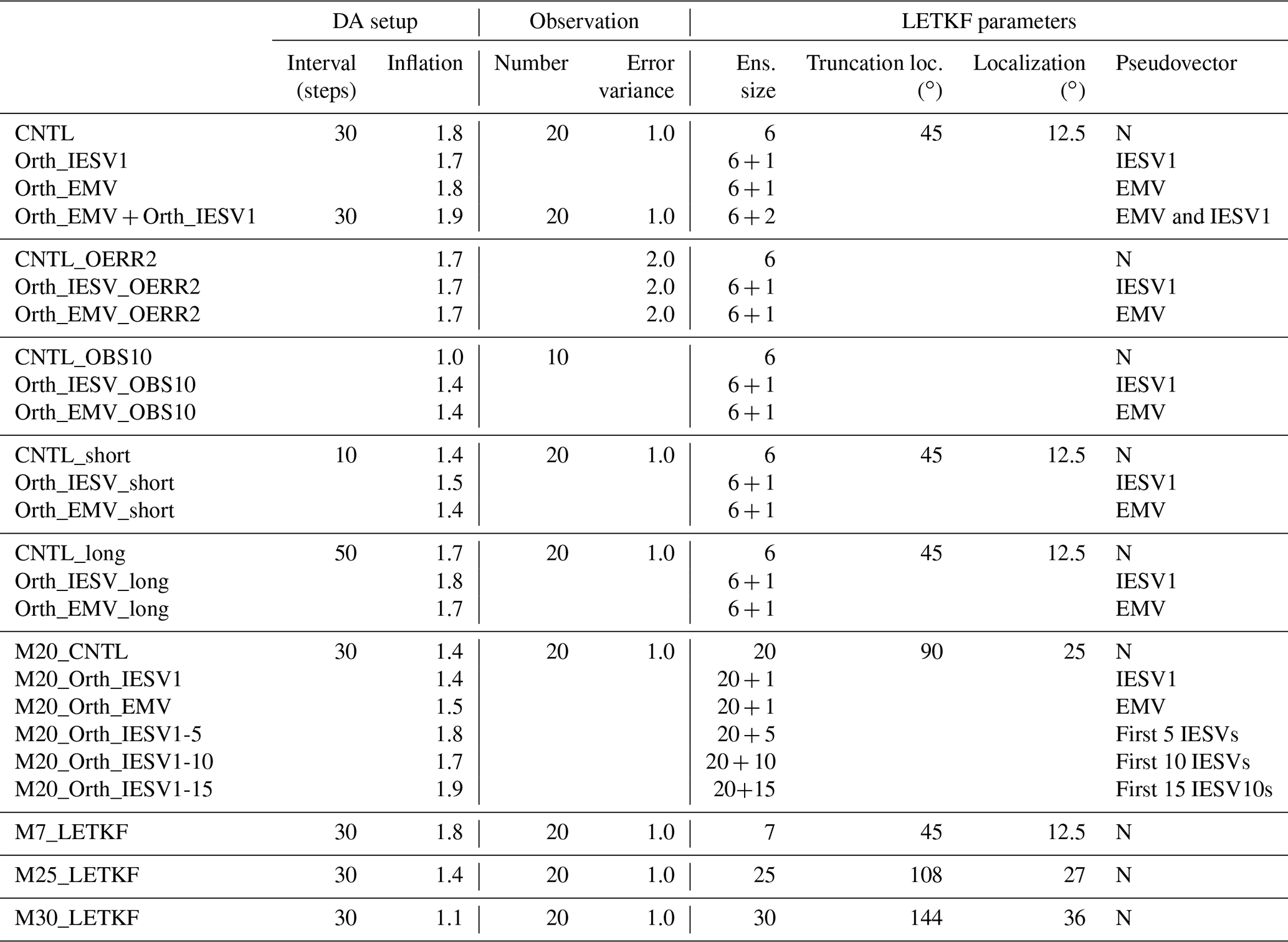
Table 1Lists of experiments and their corresponding configurations. The experiments with pseudomembers use the same settings as the standard LETKF, denoted with CNTL in each set of experiments.
2.1 General setup
This study conducts a series of Observation Simulation System Experiments (OSSEs) with the local ensemble transform Kalman filter (LETKF; Hunt et al., 2007) implemented in the 40-variable Lorenz-96 model (Lorenz, 1996; Lorenz and Emanuel, 1998) (see Appendix A for the detailed procedure). The standard set of experiments performs six-member LETKF every 30 steps with observations available every two grid points. Table 1 lists the details of the experiments and assimilation configurations.
Before performing data assimilation, a new vector is included as the extra ensemble member. The traditional double-sized method (Toth and Kalnay, 1993) requires an even number of included members and can lead to ill-conditioned problems during EnKF computation. Therefore, we adopt the centered spherical simplex ensemble (CSSE; Wang et al., 2004) method, which can add any number of members without modifying the ensemble mean and spread. More importantly, the CSSE method avoids ill-conditioned problems.
2.2 Deriving the vectors for pseudomembers
An added member is referred to as a pseudomember given that it is generated at the analysis time and is not used during the forecast stage. Two types of vectors are used for generating pseudomembers, including the initial ensemble singular vector (IESV) and ensemble mean vector (EMV). Given a set of ensemble forecasts, IESV finds fast-growing perturbations within a period by linearly combining the ensemble perturbations (Enomoto et al., 2015; Yang et al., 2015). In ensemble data assimilation, the EMV is used to define the ensemble perturbations (as the deviation) and is not accounted for in the degrees of freedom, although the perturbations evolve upon the mean state. However, it is likely that the forecast errors carry a component with the structure of the mean, such as the large-scale pattern, and will not be represented in the ensemble perturbations.
With the generated vector, we further use its component orthogonal to the ensemble space added as the pseudomember for EnKF computation. We first apply singular value decomposition (SVD) to find the orthogonal vectors to represent the space spanned by the ensemble members. Second, we use Eqs. (1) and (2) to obtain the orthogonal component of the generated vector (orthogonal IESV1 or orthogonal EMV).
where is the normalized generated vector, vi is the ith orthogonal vector of the ensemble space, vfinal proj is the total projection of the generated vector at all the orthogonal vectors of the ensemble space, and vorth is the orthogonal component of the generated vector. Finally, the orthogonal component of the generated vector is taken as the new ensemble perturbation for expanding the ensemble space.
The orthogonal vector is rescaled to have the amplitude of the background ensemble spread. Different experiments are designed. The control experiment (CNTL) conducts standard LETKF assimilation with six members and is taken as the baseline. We conduct four experiments with the added pseudomembers. The first two experiments use the global IESV1 and EMV, and the last one adds two orthogonal vectors from the IESV1 and EMV.
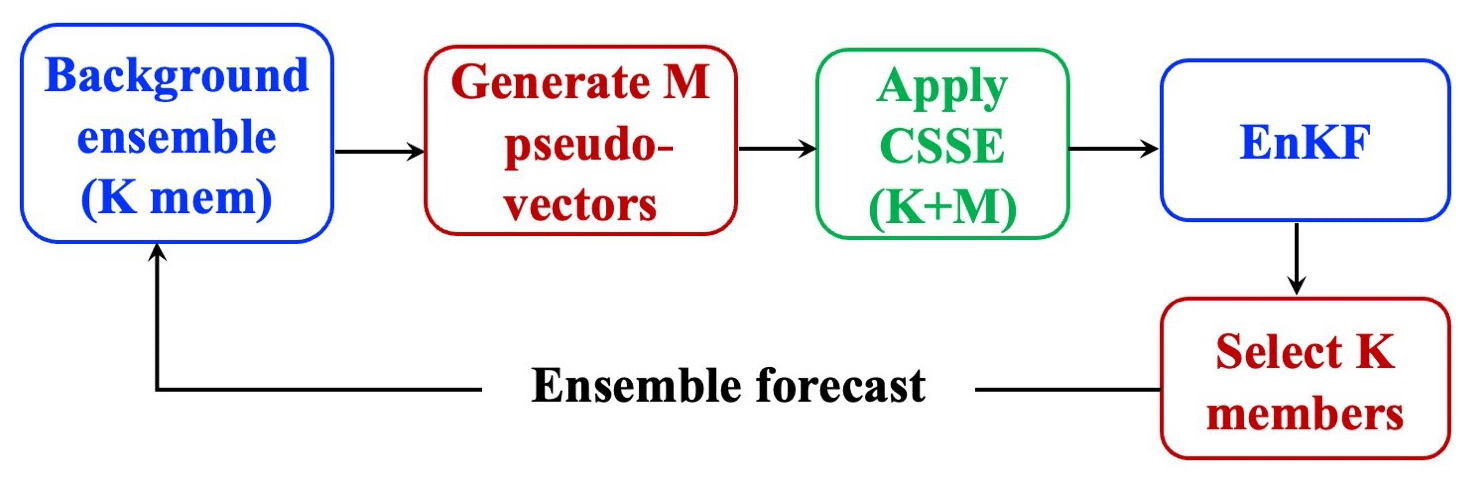
2.3 Setup of the increased-size EnKF system
Figure 1 shows the flow chart of our experiments. With the K-member background ensemble, M-member pseudovectors are generated. With CSSE, the ensemble size becomes (K+M), and the LETKF analysis is performed with the new ensemble. We conducted our experiments with offline and online frameworks. The offline framework, in which the LETKF analysis is not cycled, is used to investigate how the ensemble space varies after adding the pseudovector and to understand the benefits of the increased-size EnKF system by clean comparisons. The background ensemble is provided by the background ensemble of the CNTL at each analysis step. In contrast, the analysis is cycled in the online experimental framework to evaluate the accumulated feedback from the increased-size EnKF system. However, K members need to be selected from the new (K+M) members so that the following ensemble forecast is done without the need for extra computational costs. To do so, we remove the last M members with Eq. (3) to keep the ensemble mean and the ensemble spread the same as when using the (K+M) members.
where is the new ith member, is the mean of the (K+M) members, is the ith member perturbation, and σK+M and σK represent the ensemble spread of the (K+M) and K members, respectively. In Eq. (3), is used to ensure that the sum of the new perturbations of the first K members is equal to zero (Appendix B).
This subsection illustrates how including the pseudomember modifies the space spanned by ensemble members. The results are obtained from the offline setting, in which the orthogonal vector is directly included in the background ensemble of the standard LETKF experiment (CNTL) without cycling the impact. In this study, the orthogonal vector is computed and added globally and can modify the BEC whose structure determines the analysis correction. Here, we focus on the local maximum forecast error (LME) area, which is defined as a local area spanning seven grids and has the largest forecast error at its center.
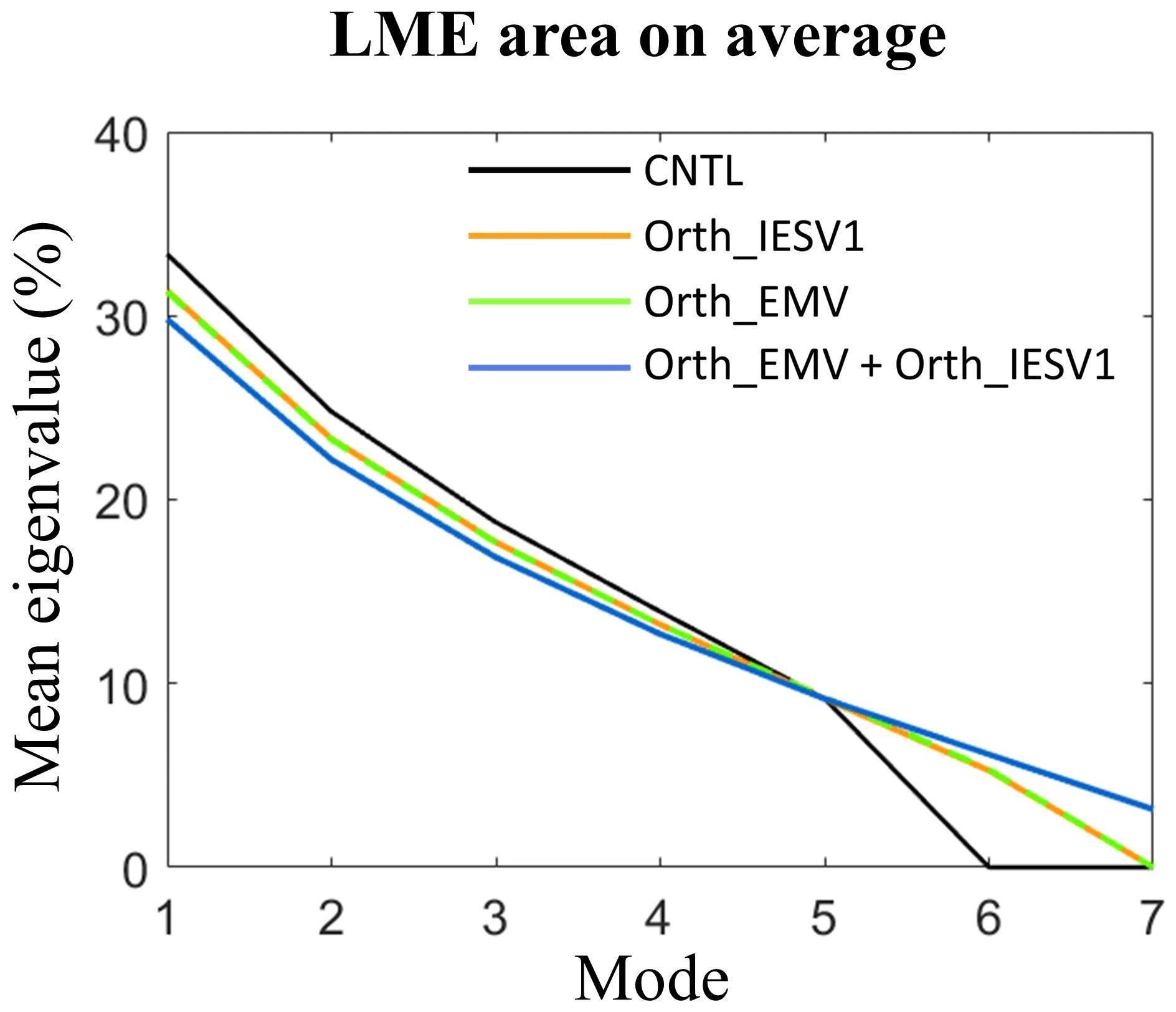
Figure 2The mean eigenvalue percentage (y axis) of the control run (black), the orthogonal IESV1 (orange), the orthogonal EMV (green), and the eight-member experiments (blue) in each eigenmode (x axis). The calculation is done using the ensemble perturbation in the local area spanning seven grids and centered at the grid with the maximum forecast error.
The characteristics of the ensemble space in the LME area are represented by the eigenspectrum of the local ensemble perturbation. Figure 2 shows the percentage of eigenvalues averaged for 550 DA cycles in the LME area. The ensemble space of CNTL (black) has five nonzero eigenvalues with six members. The newly added orthogonal vector successfully provides an independent mode in the ensemble space. With two orthogonal vectors, the eight-member (Fig. 2, blue) experiment (Orth_EMV + Orth_IESV1) can increase two independent modes, so the ensemble space is expanded into seven modes.
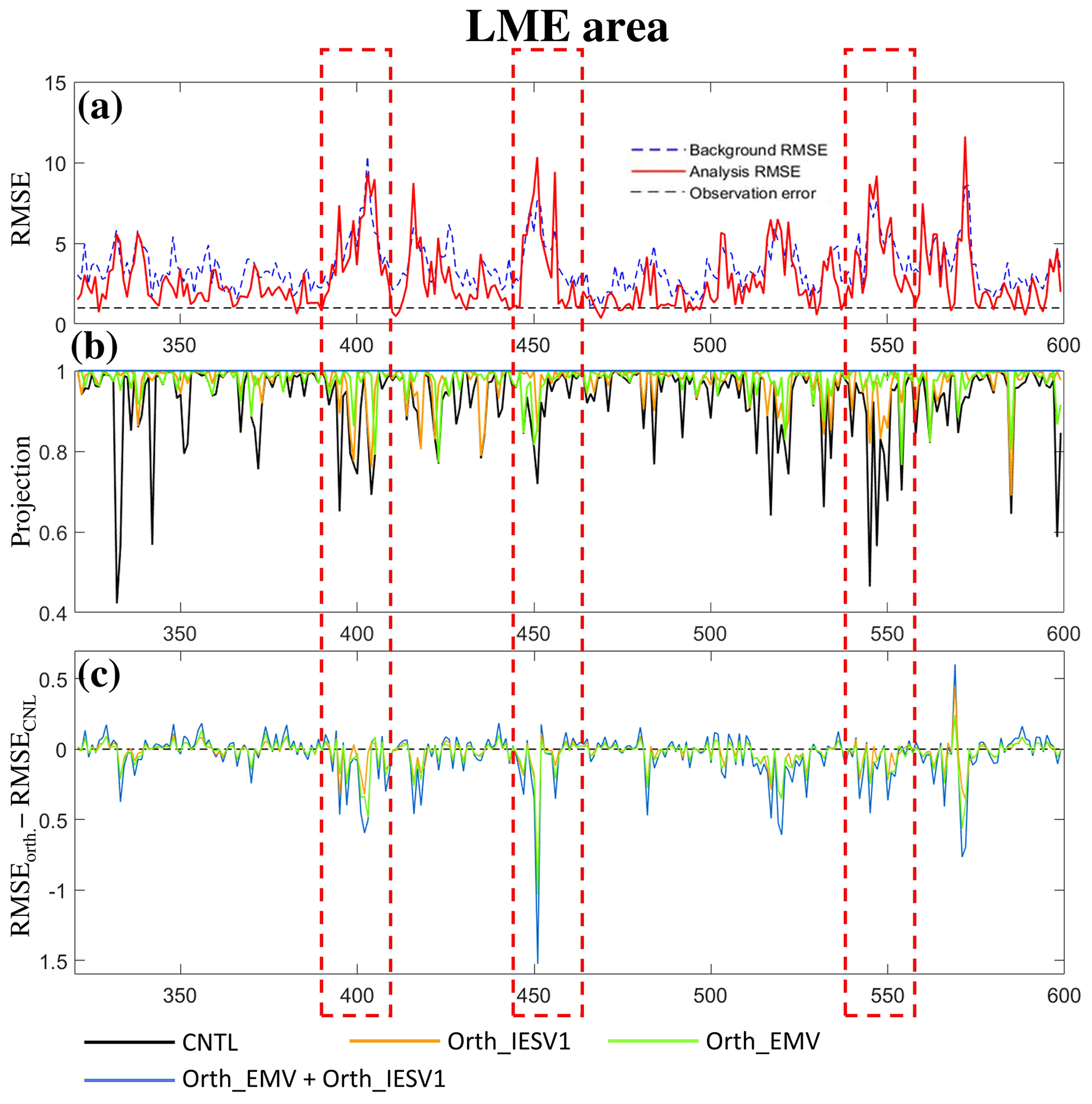
Figure 3Time series of (a) the background (dashed blue line) and analysis (red) RMSEs, (b) the projection on the background error, and (c) the RMSE differences between experiments using pseudomembers and CNTL (negative indicates improvement).
The expansion of the ensemble space can further modify the analysis correction. This can be illustrated by the projection of forecast errors onto the orthogonal vectors of the new ensemble space and the reduction in the analysis errors with the additional orthogonal vector in the LME area. The calculation of the projection is similar to Eq. (2), except is replaced with the error of the background ensemble mean, and the amplitude of vfinal proj is calculated at each analysis cycle in each experiment. We compare how well the modification of the ensemble space can help to capture the error of the background ensemble mean. The projection of CNTL decreases when the LETKF performs poorly in reducing the background error (black line in Fig. 3b vs. Fig. 3a). This also confirms that LETKF assimilation is less successful when the ensemble cannot capture the forecast error well. All experiments with the additional orthogonal vector successfully increase the projection and provide a more effective correction to reduce the error (Fig. 3c), especially at the analysis times when the CNTL analysis errors are larger than the background errors (highlighted by the dashed red boxes in Fig. 3). Furthermore, Orth_EMV + Orth_IESV1 has the best performance in capturing forecast errors and reducing analysis errors. Note that the projection of the forecast errors only illustrates how well the ensemble space encompasses the forecast errors. It should be noted that the forecast errors in the LME area, spanning seven grids, can be fully represented by seven orthogonal vectors (Orth_EMV + Orth_IESV1), but the background errors may not be completely removed due to issues such as the underrepresentation of background error variance. Nevertheless, the offline experiments confirm the potential of adding the orthogonal vector to provide more effective corrections, and the improvement is highly flow dependent.
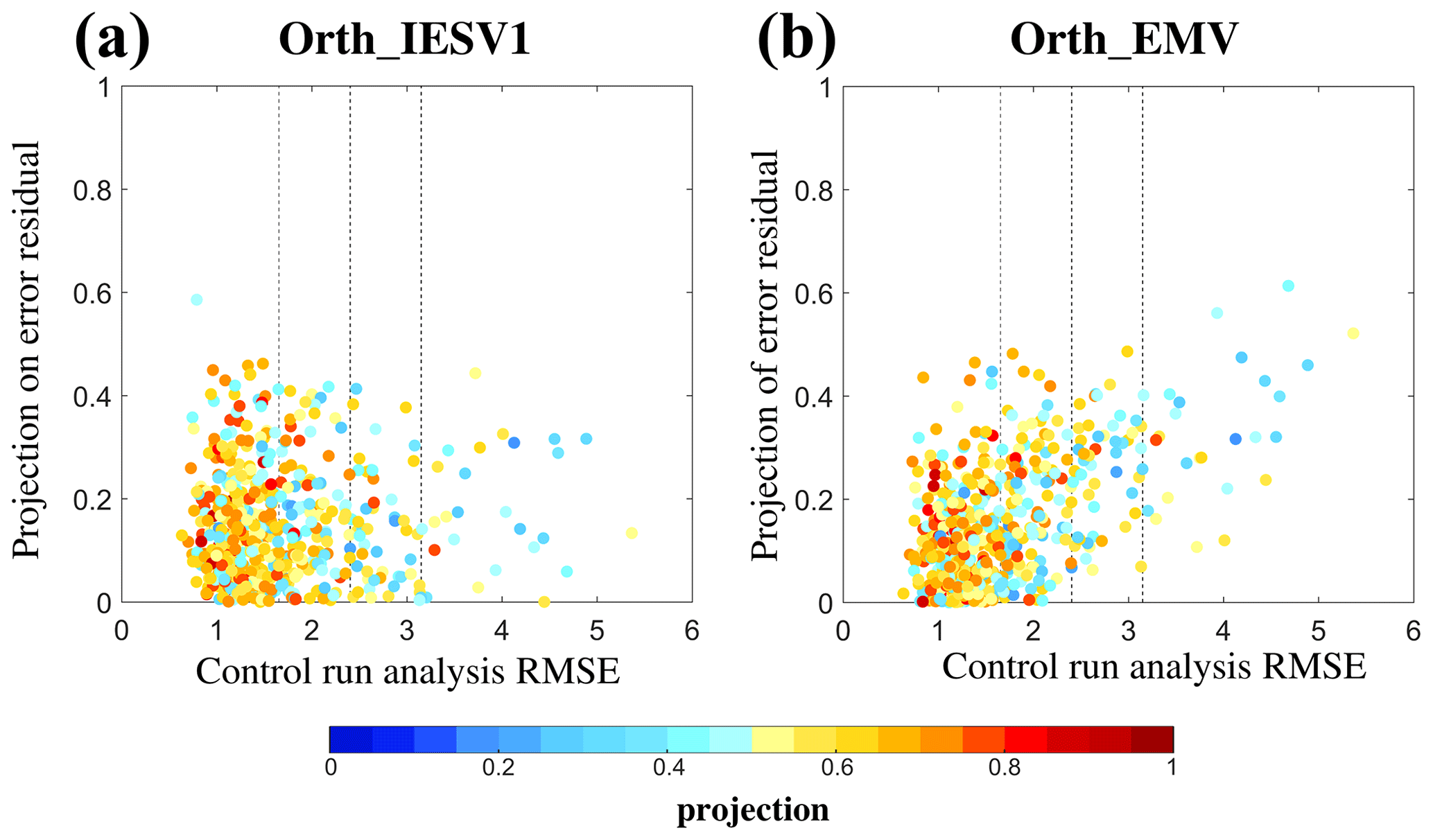
Figure 4Scatter plots of the projection on the background error (shading) according to the control analysis RMSE (x axis) and the projection of the added pseudomember on the forecast errors residual: (a) orthogonal IESV1 and (b) orthogonal EMV experiments.
Figure 4 sorts the projection of the CNTL background ensemble on the background error according to the CNTL analysis RMSE and the projection of the added orthogonal vector on the forecast error residual. The forecast error residual is the unexplained forecast error after removing the projection of the original background ensemble from the original forecast error. All calculations are performed on the whole domain. First, a large CNTL analysis RMSE corresponds to the low projection of the original background ensemble on forecast errors (i.e., blue dots with large RMSEs). In general, the larger the CTRL RMSE is, the higher the orthogonal vector capturing the residual error. Compared to the orthogonal IESV1, the orthogonal EMV projects more onto the forecast error residual at most analysis times. Therefore, the orthogonal EMV is more useful to increase the ensemble space to reduce the analysis errors in this example.
Table 2The mean and standard deviation (SD) of the analysis RMSE of 10 experiments using the standard configuration. Each experiment is initialized with a different random seed. RMSE is only computed for the analysis times when the CNTL analysis RMSE is 2 standard deviations larger than the mean CNTL analysis RMSE. The number in the brackets indicates the improvement rate with respective to the CNTL RMSE.
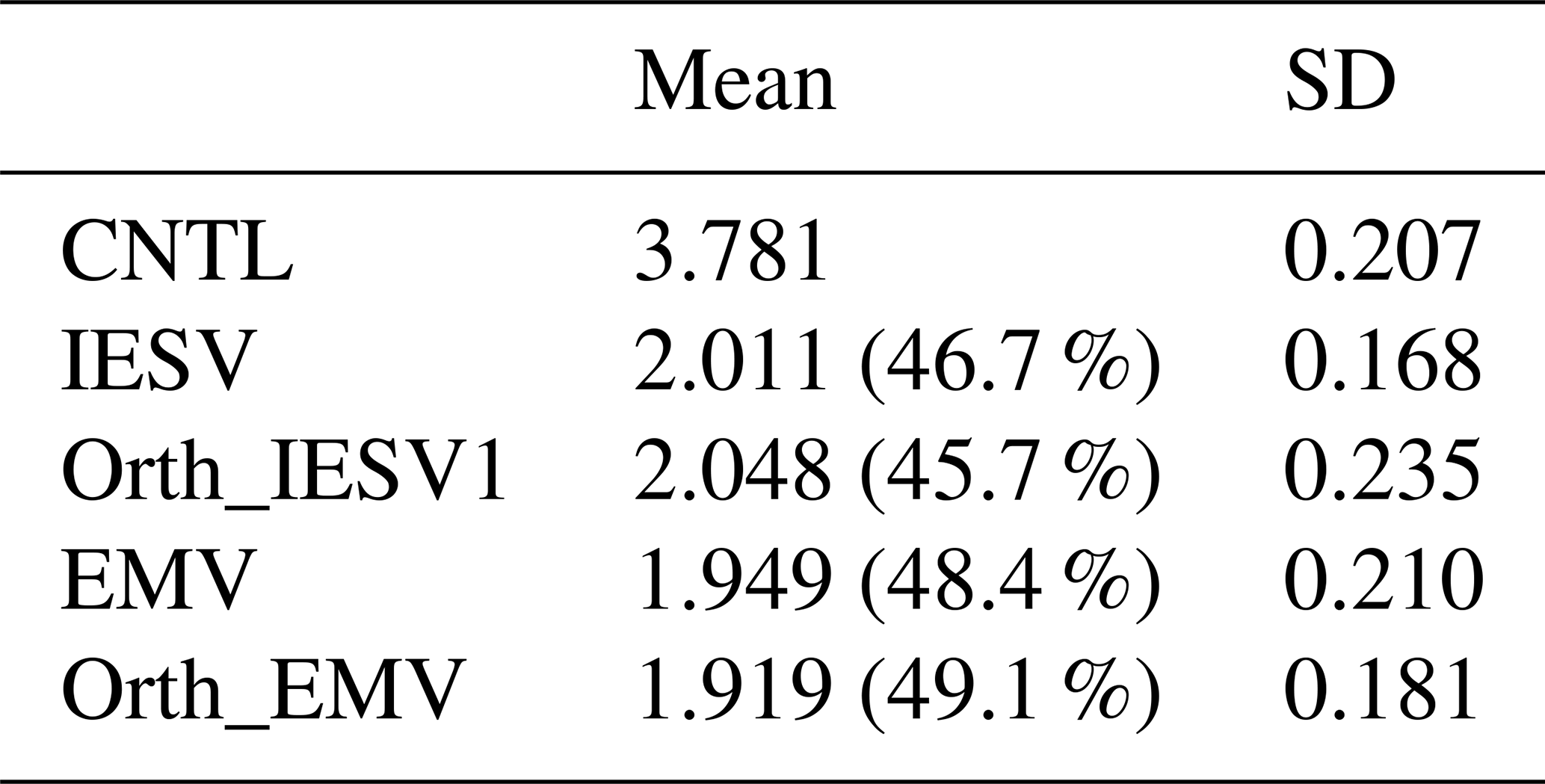
We further compare the results of the online experiments, in which the impact of using the additional pseudovector is cycled during the analysis step and further feedbacks into the next background ensemble through analysis cycling. We evaluate the analysis error based on the RMSE of the analysis ensemble mean, and the experiments with the standard configuration are repeated 10 times with different initial random seeds to show the statistical robustness. Based on Fig. 3, Table 2 focuses on the analysis cycles, whose analysis RMSE values in the CNTL are 2 standard deviations larger than the mean CNTL RMSE. This highlights the effect of adding the new vectors in LETKF assimilation when the original background ensemble is less capable of reducing forecast errors. With 10 randomly initialized standard experiments, adding the IESV1 or EMV as the pseudovector is always effective in improving the CNTL analysis. When the CTRL has large analysis errors, both the IESV1 and EMV can have a mean improvement rate larger than 46 %. This indicates that the additional correction is beneficial for correcting the growing error and thus results in positive feedback. On average, the Orth_EMV shows a larger mean improvement than the EMV. It should be noted that adding the Orth_IESV1 always has a better performance than CNTL and sometimes than the IESV1. However, the Orth_IEVS1 may overly expand the subgrowing direction of the ensemble space, and the overcorrection results in a poorer performance than the IESV1 experiments. Therefore, the Orth_IESV1 has a smaller improvement rate than the IESV on average, and the standard deviation of RMSE is much larger than that of the IESV1.
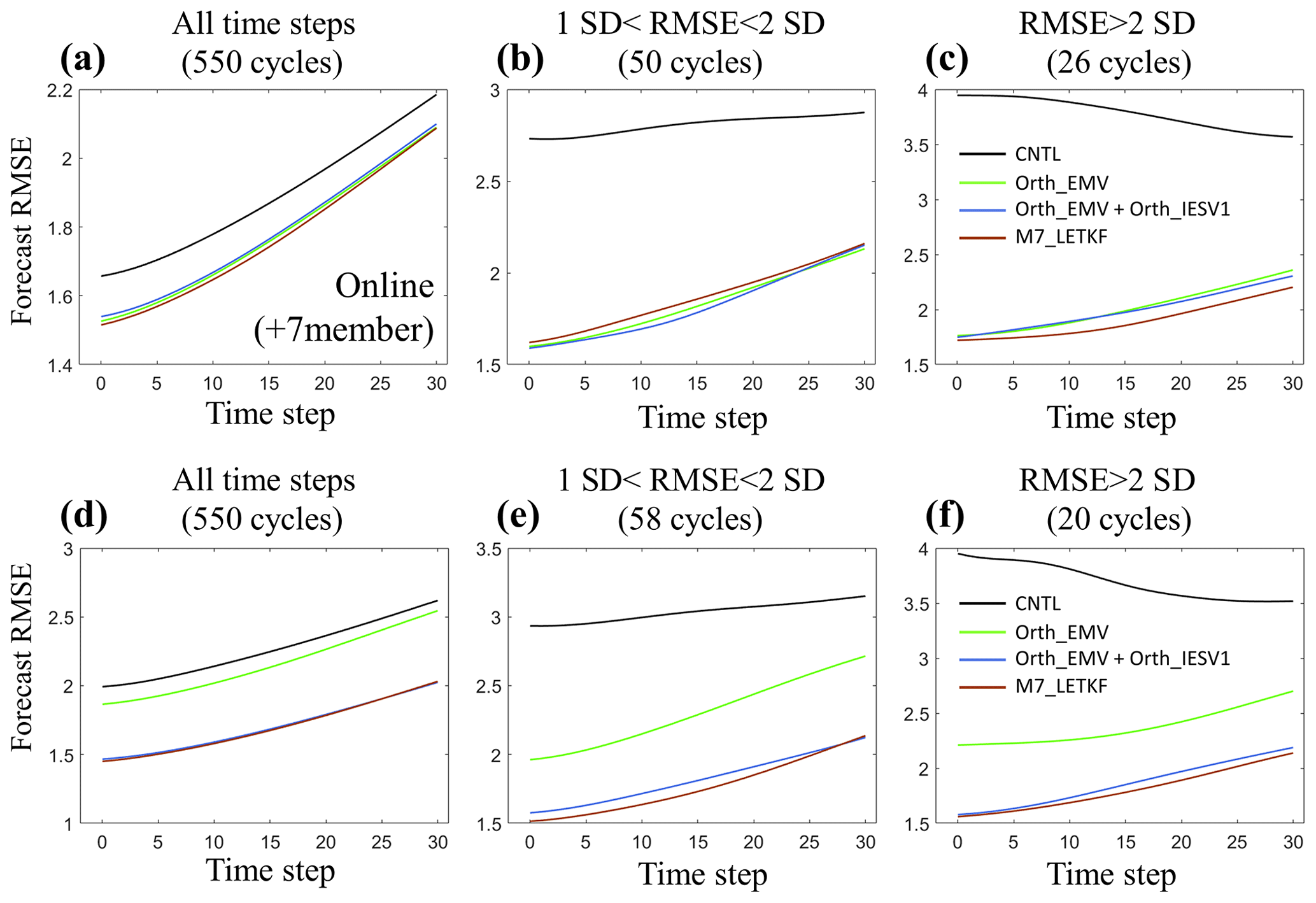
Figure 5Mean analysis and forecast RMSEs (y axis) during the 30-step integration (x axis) with different experiments. Panels (a–c) show the perfect model experiments and (d, e) the imperfect model experiments. Panels (a) and (d) are averaged for all analysis cycles. Panels (b) and (e) use the cycles when the CNTL analysis RMSE values are between 1 and 2 standard deviations larger than the mean RMSE. Panels (c) and (f) use the cycles when the CNTL analysis RMSE values are 2 standard deviations larger than the mean RMSE. In the imperfect model experiments, the F value in the governing equations of the Lorenz-96 model is changed from 8 to 7.8, and the inflation increases to 2.3.
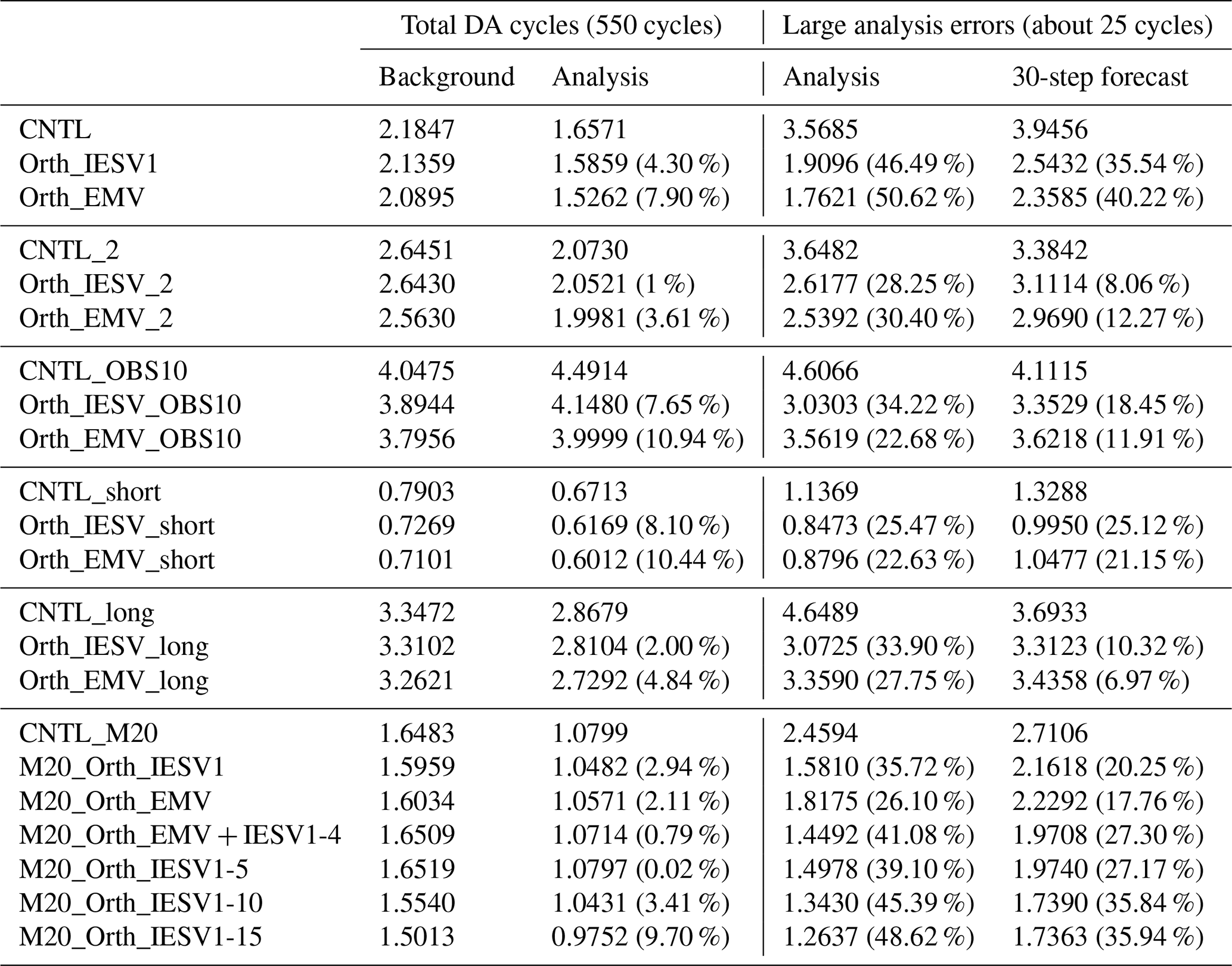
Table 3 summarizes the performance of the six-member experiments with different assimilation configurations, and experiments are conducted using one of the initial conditions used in the CTRL experiments. Our results confirm that adding the orthogonal vector is always beneficial in improving the analysis accuracy under different assimilation configurations, including larger observation error, sparse observations, and short or long assimilation intervals. We further compare experiments using one or two orthogonal vectors with the standard LETKF with seven members. While using more members introduces more computation during the ensemble forecast, experiments using the pseudovectors for assimilation do not have extra computation for performing ensemble forecasting. Orth_EMV + Orth_IESV1 successfully combines the advantages of using the orthogonal IESV1 and the orthogonal EMV, and thus, it has better performance than both single-pseudomember experiments, especially for groups with large analysis errors (Fig. 5b and c). More importantly, Orth_EMV + Orth_IESV1 outperforms in the group with mildly large analysis errors (Fig. 5b). However, when the analysis error grows to a certain range, the seven-member standard LETKF (M7_LETKF) has the best performance. Such an improvement with pseudomembers is still valid and even more evident when the model is imperfect (Fig. 5d–f), and Orth_EMV + Orth_IESV1 has a comparable performance with M7_LETKF in general (Fig. 5d).
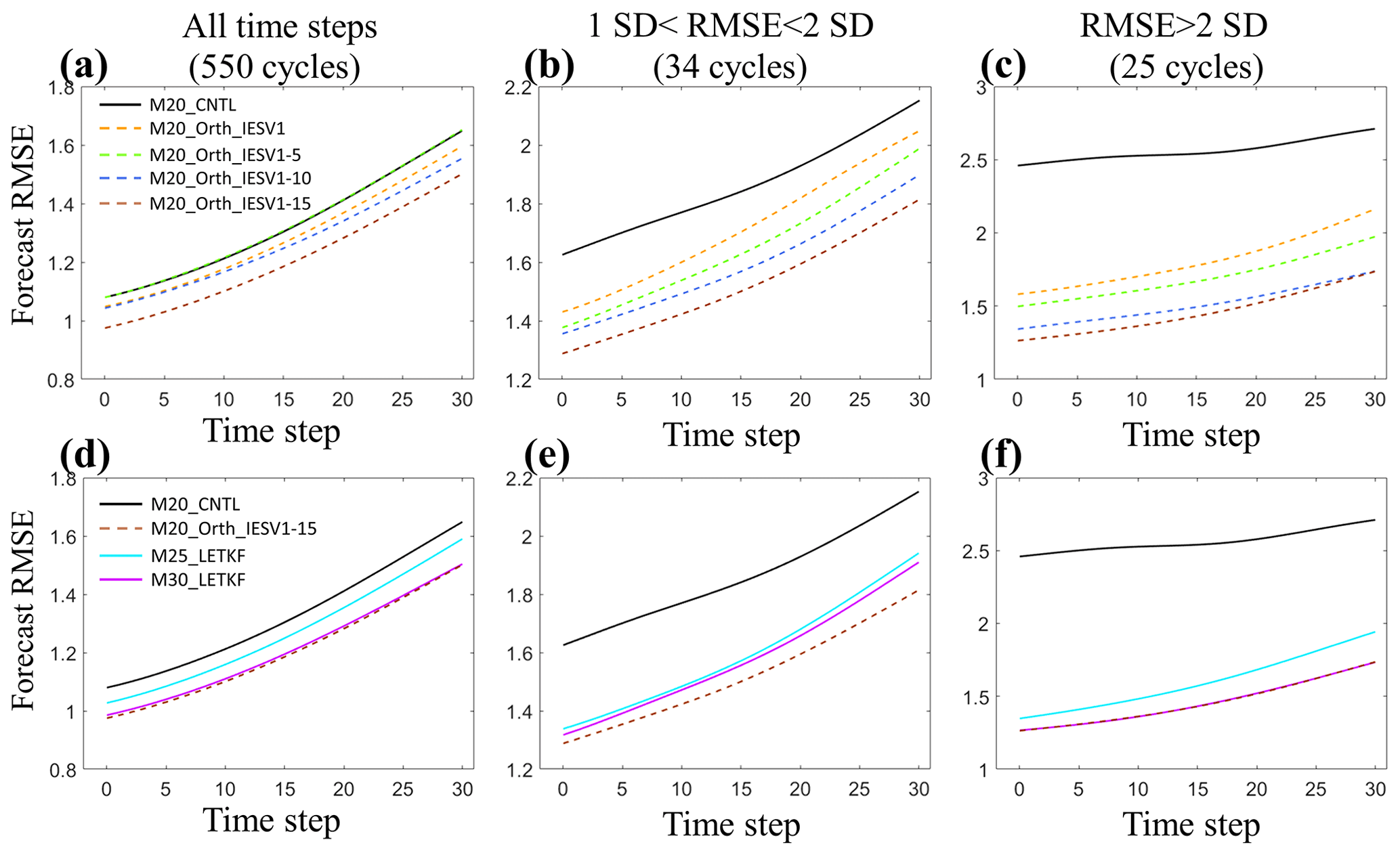
Figure 6The same as Fig. 5 except for different experiments. CNTL_M20, M25-mem_LETKF, and M30_LETKF use the standard LETKF with 20, 25, and 30 members, respectively. M20_Orth_IESV1, M20_Orth_IESV1-5, M20_Orth_IESV1-10, and M20_Orth_IESV1-15 use 20 members and orthogonal components of IESVs as the pseudomembers.
We further justify this method with a large ensemble size (20 members) and investigate how many pseudomembers can be useful. As shown in Table 3, the benefit of adding pseudomembers based on IESVs increases as the number of pseudomembers increases, particularly when the standard LETKF (M20_CNTL) has a large analysis RMSE. Using more than 10 IESVs can reduce the analysis RMSE by 45 %, and the IESV1 (M20_Orth_IESV1) provides the dominant effect. The improvement rate with 15 IESVs saturates for the following 30-step forecast. Such a performance (M20_Orth_IESV1-15) is better than the 25-member standard LETKF in general and even better than the 30-member standard LETKF for the group of mildly large analysis errors (Fig. 6). The forecast computation is only 66 % of the 30-member LETKF. This also confirms that IESV-based pseudomembers can effectively expand the ensemble space to capture the growing forecast errors. We also note that M20_Orth_EMV is less effective than M20_Orth_IESV1 in the case of a large ensemble. The reason that the EMV as the pseudomember is very effective with the small ensemble is because the ensemble space spanned by the ensemble perturbations cannot capture the background error well, and the corrections for the background mean can be less optimal. This limitation is more evident for the large-scale error due to using a small localization. As a result, the structure of the ensemble mean largely projects on the background error (Fig. 4), and thus using the EMV as the pseudomember leads to a good performance. With a large ensemble size and a large localization, the large-scale error in the background mean state is much reduced, and thus the EMV is less effective in being used as the pseudomember. In comparison, the ensemble forecast can better capture the error evolution with more members, leading to a more robust IESV1. Nevertheless, including the orthogonal EMV is still more beneficial than using all pseudomembers with IESVs (M20_Orth_EMV + IESV1-4 vs. M20_Orth_IESV1-5).
This study proposed a new idea of adding cost-free pseudomembers to expand the ensemble space and to improve the performance of EnKF assimilation and forecast. Based on the Lorenz-96 model, this idea is investigated with offline and online frameworks. Two types of pseudoensemble members are compared, including the global IESV1 and EMV. Both are very effective in expanding the ensemble space in sensitive areas, while the orthogonal EMV is most effective in improving the analysis accuracy with a small ensemble size. With a large ensemble size, the structure of the mean state is less effective as the pseudomember, compared to IESV1. The effective improvement with IESV1 indicates the importance of maintaining the direction of growing error in the ensemble space. We also confirm that adding more pseudomembers with the EMV and IESVs can further improve the analysis and forecast accuracy.
In the current operational ensemble DA system, additive covariance inflation is commonly adopted to improve the EnKF performance. However, how to choose additive inflation is ad hoc and may even break the balance of the structure of the original ensemble space and degrade the performance of the data assimilation system. The newly proposed simple idea could be a gentle alternative. In the future, we plan to explore the feasibility of this idea in a real model, such as using the orthogonal EMV as the pseudomember for ocean ensemble data assimilation.
The Lorenz-96 model has been used to study the issue of error growth and the probability of atmosphere and weather forecasting (van Kekem et al., 2018). The governing equation of the Lorenz-96 model is
where n is the dimension of the system, j is the index of the analysis grids, and F is the external forcing term. can be interpreted as some atmospheric quantity measured along the same latitude of the earth (Lorenz, 2006).
This appendix proves that, with K members, the ensemble mean and the ensemble spread adjusted by Eq. (3) are the same as those derived with (K+M) members.
With denoting the ensemble mean of the (K+M) ensemble members, we define vi as the ith ensemble member and as the perturbation deviated from .
We select the first K members and define the new ith member with Eq. (B1).
In Eq. (B1), σK+M is the standard deviation of the (K+M) members, and σK is the standard deviation of the first K members.
Since , the mean of the new K ensemble members is . In addition, is the scaling factor to ensure that the new ensemble spread of the K member has the same ensemble spread as the (K+M) members.
Details of the experiment data can be reproduced by the code. The control run and code have been released on https://doi.org/10.5281/zenodo.8116811.
YYC is responsible for all plots, initial analysis, and some writing. SCY proposed the idea, led the project, and organized and refined the paper. ZHL provided the initial framework of the experiments, and YAL provided significant discussions and inputs for this research.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors are very thankful for the valuable discussion with Jeff Steward. The authors are also very grateful for the initial discussion with Takemasa Miyoshi from RIKEN.
This research has been supported by the Taiwan National Science and Technology Council (grant nos. 111-2111-M008-030 and 110-2923-M-008-003-MY2).
This paper was edited by Zoltan Toth and reviewed by two anonymous referees.
Bocquet, M. and Carrassi, A.: Four-dimensional ensemble variational data assimilation and the unstable subspace, Tellus A, 69, 1304504, https://doi.org/10.1080/16000870.2017.1304504, 2017.
Carrassi, A., Trevisan, A., Descamps, L., Talagrand, O., and Uboldi, F.: Controlling instabilities along a 3DVar analysis cycle by assimilating in the unstable subspace: a comparison with the EnKF, Nonlin. Processes Geophys., 15, 503–521, https://doi.org/10.5194/npg-15-503-2008, 2008.
Chang, S., Penny, G., and Yang, S.-C.: Hybrid Gain Data Assimilation using Variational Corrections in the Subspace Orthogonal to the Ensemble, Mon. Weather Rev., 148, 2331–2350, https://doi.org/10.1175/MWR-D-19-0128.1, 2020.
Enomoto, T., Yamane, S., and Ohfuchi, W.: Simple sensitivity using ensemble forecasts, J. Meteorol. Soc. Jpn., 93, 199–213, https://doi.org/10.2151/jmsj.2015-011, 2015.
Hamill, T. M. and Snyder, C.: A Hybrid Ensemble Kalman Filter–3D Variational Analysis Scheme, Mon. Weather Rev., 128, 2905–2919, https://doi.org/10.1175/1520-0493(2000)128<2905:AHEKFV>2.0.CO;2, 2000.
Hunt, B. R., Kostelich, E. J., and Szunyogh, I.: Efficient data assimilation for spatiotemporal chaos: A local ensemble Kalman filter, Physica D, 230, 112–126, 2007.
Lorenz, E. N.: Predictablilty: A problem partly solved, Conference Paper, Seminar on Predictability, ECMWF, 1–18, 1996.
Lorenz, E. N.: Predictability – A Problem partly solved, in: Predictability of Weather and Climate, edited by: Palmer, T. N. and Hagedorn, R., Cambridge University Press, Cambridge, Chap. 3, 40–58, 2006.
Lorenz, E. N. and Emanuel, K. A.: Optimal sites for supplementary weather observations: Simulation with a small model, J. Atmos.Sci., 55, 399–414, 1998.
Penny, S. G: The hybrid local ensemble transform Kalman filter, Mon. Weather Rev., 142, 2139–2149, https://doi.org/10.1175/MWR-D-13-00131.1, 2014.
Toth, Z. and Kalnay, E.: Ensemble forecasting at NMC: The generation of perturbations, B. Am. Meteorol. Soc., 74, 2317–2330, 1993.
van Kekem, D. L.: Dynamics of the Lorenz-96 model: Bifurcations, symmetries and waves, PhD thesis, University of Groningen, ISBN 978-94-034-0979-5, 2018.
Wang, X., Bishop, C. H., and Julier, S. J.: Which is better, an ensemble of positive-negative pairs or a centered spherical simplex ensemble?, Mon. Weather Rev., 132, 1590–1605, 2004.
Whitaker, J. S., Hamill, T. M., Wei, X., Song, Y., and Toth, Z.: Ensemble data assimilation with the NCEP Global Forecast System, Mon. Weather Rev., 136, 463–481, https://doi.org/10.1175/2007MWR2018.1, 2008.
Yang, S.-C., Kalnay, E., and Enomoto, T.: Ensemble singular vecotrs and their use as additive inflation in ENKF, Tellus A, 67, 26536, https://doi.org/10.3402/tellusa.v67.26536, 2015.
yungyun: yungyun0721/orthogonal_vector_code: initial_code_release (v1.0), Zenodo [code and data set], https://doi.org/10.5281/zenodo.8116811, 2023.
- Abstract
- Introduction
- Methodology and experimental design
- Results
- Summary and conclusion
- Appendix A: Introduction of the Lorenz-96 model
- Appendix B: Proof of Eq. (3)
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methodology and experimental design
- Results
- Summary and conclusion
- Appendix A: Introduction of the Lorenz-96 model
- Appendix B: Proof of Eq. (3)
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References