the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 22 Jun 2022
| 22 Jun 2022
A stochastic covariance shrinkage approach to particle rejuvenation in the ensemble transform particle filter
Amit N. Subrahmanya
Adrian Sandu
Rejuvenation in particle filters is necessary to prevent the collapse of the weights when the number of particles is insufficient to properly sample the high-probability regions of the state space. Rejuvenation is often implemented in a heuristic manner by the addition of random noise that widens the support of the ensemble. This work aims at improving canonical rejuvenation methodology by the introduction of additional prior information obtained from climatological samples; the dynamical particles used for importance sampling are augmented with samples obtained from stochastic covariance shrinkage. A localized variant of the proposed method is developed. Numerical experiments with the Lorenz '63 model show that modified filters significantly improve the analyses for low dynamical ensemble sizes. Furthermore, localization experiments with the Lorenz '96 model show that the proposed methodology is extendable to larger systems.
- Article
(2749 KB) - Full-text XML
- BibTeX
- EndNote





Ensemble-based data assimilation (Asch et al., 2016; Law et al., 2015; Reich and Cotter, 2015) aims to estimate the state of some dynamical system in a Bayesian framework and describes the uncertainty through an ensemble of possible states. Describing the distribution of state uncertainty to sufficient accuracy requires very large ensembles, a phenomenon referred to as the curse of dimensionality (Tan et al., 2018; Snyder et al., 2008). Several techniques such as the principle of maximum entropy (Jaynes, 2003) attempt to alleviate this burden by prescribing a distribution constrained by known information. The ensemble Kalman filter (Burgers et al., 1998; Evensen, 1994, 2009) constrains the underlying distributions only by the ensemble mean and covariance; the application of Bayes' rule transforms an assumed prior normal distribution into an assumed posterior normal distribution.
Previous work (Popov et al., 2020) has focused on augmenting the information represented by the ensemble with information derived from covariance shrinkage through a surrogate ensemble in the ensemble transform Kalman filter. In this paper, we extend this idea to the ensemble transport particle filter (ETPF, Reich, 2013). The ETPF transports a given ensemble that represents the posterior distribution using importance sampling (Liu, 2008) to another, equally sampled, ensemble whose moments, in the limit of infinitely many particles, approach the moments of the correct posterior distribution. Like all particle filters, the ETPF is susceptible to weight collapse. Recent attempts to apply particle filters to high-dimensional systems (Farchi and Bocquet, 2018; Van Leeuwen, 2009; Van Leeuwen et al., 2019) have seen some success. However, particle filters are not yet competitive with other state-of-the-art methods such as the ensemble Kalman filter.
This work explores a new approach to particle rejuvenation, which is necessary to prevent weight collapse in particle filters. Rejuvenation in particle filters is a particular type of stochastic regularization (Musso et al., 2001) and is typically implemented in a heuristic manner. Instead of heuristics, our approach makes use of prior information to enrich the ensemble subspace. The new contributions of this work are as follows: (1) we introduce an alternative way of performing particle rejuvenation in the ETPF by incorporating climatological covariance information, (2) we accomplish this by augmenting the dynamical (model) ensemble with synthetic anomalies with optimal scaling, accompanied by a statistically correct estimator, and (3) we show that this rejuvenation method significantly improves the analysis quality for low dynamical ensemble sizes.
This paper is organized as follows. Section 2 reviews the concept of Bayesian inference with the addition of prior information and its implementation in the context of importance sampling. Section 3 discusses the ensemble transform particle filter and its canonical rejuvenation heuristic. The concept of stochastic covariance shrinkage is proposed in Sect. 4, and the ETPF is extended to make use of this shrinkage. Numerical experiment results are reported in Sect. 5. Concluding remarks are given in Sect. 6.
Bayesian inference (Jaynes, 2003) aims at transforming prior information about the state of a system (represented by the distribution of a random variable Xf), additional qualitative and quantitative information (P), and information obtained by observing the system (Y) into combined posterior information (Xa):
where π(X∣P) represents the prior state probability density conditioned by all other relevant information, and is the observational likelihood conditioned by the forecast Xf and the prior information P. Here we consider the finite-dimensional case where , Y∈ℝm, where the supports of the prior and posterior probability densities are subsets of the respective spaces.
Classical particle filtering (Reich and Cotter, 2015) represents state distributions by collections of particles, i.e., ensembles of samples. Specifically, consider an ensemble of Nf particles . The prior distribution density is approximated weakly by the corresponding empirical measure,
where for are the prior importance weights associated with each particle such that and . Similarly, the posterior density is approximated weakly by an empirical measure based on the same sample values (particle states) but with different posterior importance weights for :
The posterior importance sampling weights are obtained from Eq. (1):
The ensemble of weights is denoted by , and wf and wa refer to the forecast and analysis weights, respectively. Using Eqs. (3) and (4), unbiased empirical estimates of the posterior mean and covariance,
respectively, are obtained by the importance sampling approach (Liu, 2008). The factor in front of the covariance estimate ensures that it is unbiased.
Our goal is to find an analysis ensemble of Na≤Nf realizations of the random variable Xa that represents the posterior distribution with equal weights. Specifically, the posterior density is approximated weakly by the empirical measure,
where the importance sampling weights are uniform and equal to (so as to be equally likely), and is the random variable corresponding to this measure which converges weakly in distribution to the exact posterior random variable Xa. We require that the empirical mean (5) is preserved by Eq. (6),
meaning that the weighted mean of the forecast ensemble is the mean of the analysis ensemble.
The optimal coupling (McCann, 1995; Reich and Cotter, 2015) between the prior empirical distribution Eq. (2) and the posterior empirical distribution Eq. (6) can be defined as an ensemble transformation,
where is the solution to the optimal transport Monge–Kantorovich problem (Villani, 2003). It is important to see that each element of T∗ is positive. The discrete optimal transportation problem is
where the distance measure of squared Euclidean distance is taken for a provably unique solution to the Monge–Kantorovich problem to exist (McCann and Guillen, 2011). The vector of ones of size q is represented by 1q. The problem Eq. (9) is a linear programming problem. A visualization of the optimal transport between two continuous distributions is given in Fig. 1.

Figure 1A visual representation of the continuous optimal transport procedure. The probability distribution is transported into the distribution through the optimal transport mapping T. The discrete version of the solution is given by Eq. (9).
The standard ETPF (Reich, 2013) makes the assumption that the prior and posterior ensemble sizes are the same: in Eq. (9). In the ETPF, most other prior information in P is typically ignored. The discrete optimal transport Eq. (8) formulation begets a mapping that, in the limit of ensemble size (), converges weakly to a mapping Ψ, such that Xa=Ψ(Xf) has the exact desired distribution given by Eq. (1) (Reich and Cotter, 2015, Theorem 5.19). A second-order extension to the ETPF (which we will call “ETPF2” here) (Acevedo et al., 2017) modifies the optimal transport Eq. (8) as follows:
where the additional term D is a matrix that ensures that the empirical covariance estimate from Eq. (5) is preserved by Eq. (6).
2.1 Localization
In high-dimensional geophysical problems, spatial error correlations decrease with increasing spatial distance between states. Due to the undersampled nature of the ensemble, these correlations may not be accurately approximated. Localization allows us to strictly enforce the shrinking of correlations between distant states. For localization in the ETPF, we follow the R-localization formulation given in Reich and Cotter (2015) and Acevedo et al. (2017). Figure 2 provides an illustration of R localization, with the full procedure described below.
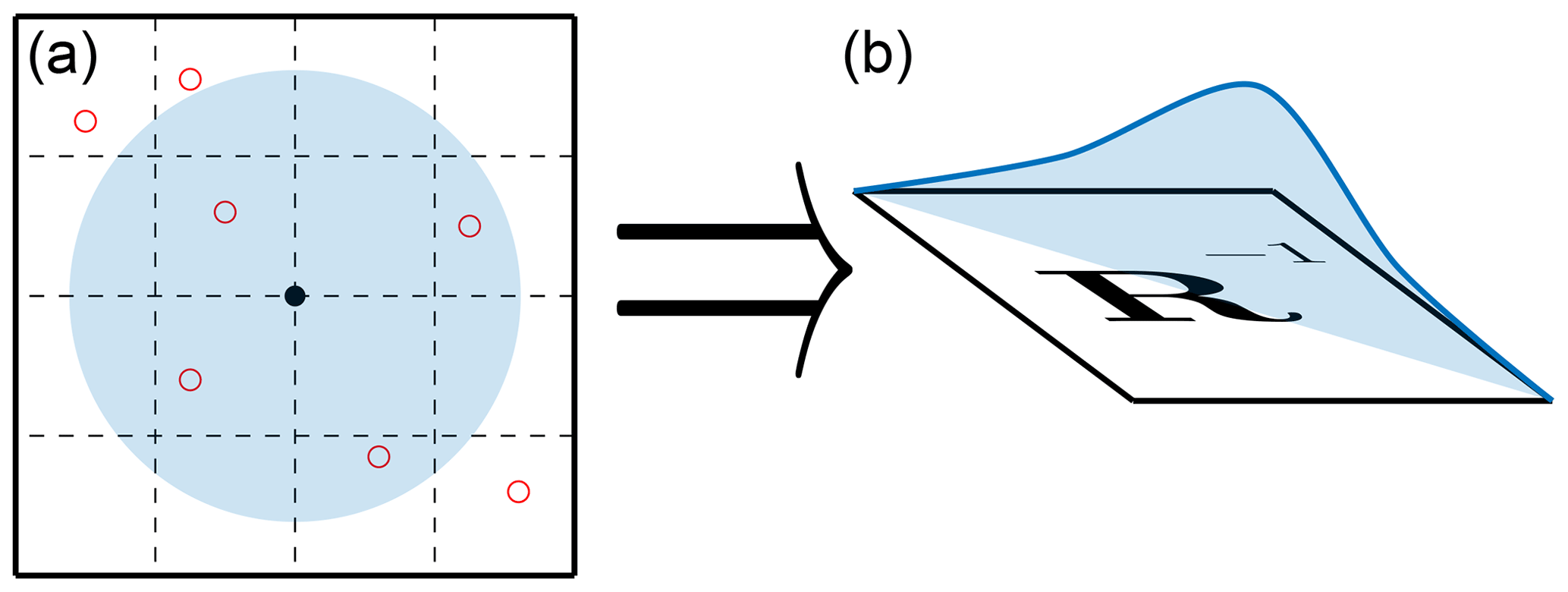
Figure 2A visual representation of R localization in the ETPF. Panel (a) represents the localization radius around the ith state variable represented by the black dot, with the observations represented by the open red dots. Panel (b) represents the decorrelation of R−1 along the diagonal.
Typically, the observation error distribution is assumed to be unbiased and Gaussian, with the probability density used to compute the weights in Eq. (4) for particular realizations of the observation Y, of the state X, and of the prior information P, defined as
where ℋ is the observation operator. In this case it can be fully parameterized by the observation error covariance , where m is the number of observations.
We assume that the observations are uncorrelated, making a diagonal matrix. For the ℓth state variable x(ℓ), we define the localized observation error covariance matrix Rℓ via
where d is some distance function defined between the ℓth state space variable and the jth observation space variable, r is the localization radius, ρ is a decorrelation function, and ∘ stands for the Hadamard element-wise product. In this work we use the Gaspari–Cohn decorrelation function (Gaspari and Cohn, 1999). The localized inverse of the observation error covariance (12) is then used in the generation of the weight ensemble , similarly to Eq. (4).
A different transform matrix is computed for each state variable. Specifically, consider the ensembles of the ℓth state space variable:
The Monge problem formulation in Eq. (9) is replaced with the localized formulation for the ℓth variable,
with the analysis ensemble of the ℓth state space variable given by
Particle and ensemble-based filters often underrepresent uncertainty (Asch et al., 2016) due to the relatively small number of samples when compared to the dimension of the state and data spaces. Over several data assimilation cycles multiple particles start carrying either unimportant or redundant information, which leads to weight collapse or to ensemble degeneracy (Strogatz, 2018). To alleviate these effects, methods such as inflation (Anderson, 2001; Popov and Sandu, 2020), rejuvenation (Reich, 2013), and resampling (Reich and Cotter, 2015; Attia and Sandu, 2015) have been developed.
In order to avoid ensemble collapse, the ETPF employs a particle rejuvenation approach (Acevedo et al., 2017; Reich, 2013; Chustagulprom et al., 2016) that perturbs the analysis ensemble by a random sampling from the ensemble of prior anomalies,
where is a matrix of i.i.d. samples from the standard normal distribution of size N, the rejuvenation factor τ (also called the bandwidth parameter) is a hyperparameter that controls the magnitude of the correction, and the ensemble anomalies,
are defined as the ensemble of deviations from the sample mean. Of note is the fact that the extra term in Eq. (16) ensures that the introduction of the random matrix η does not modify the mean of Xa. This is due to the fact that
Note that defining the matrix
allows us to write the ETPF with standard rejuvenation (16) as follows:
The matrix B acts as a stochastic perturbation of the optimal transport operator T∗. The choice of B preserves the linear constraints of the Monge–Kantorovich problem, Eq. (9), since and B1N=0N due to the property (18). This, of course, immediately calls into question the optimality of the transport for a finite ensemble, as adding this type of B matrix perturbs the transport mapping away from the optimum T∗.
In the context of ensemble methods, covariance shrinkage (Nino-Ruiz and Sandu, 2019, 2015; Nino-Ruiz et al., 2014) is used, similar to other canonical covariance tapering techniques such as inflation (Anderson, 2001; Popov and Sandu, 2020) and localization (Anderson, 2012; Hunt et al., 2007; Nino-Ruiz and Sandu, 2016; Nino-Ruiz et al., 2015; Petrie, 2008; Zhang et al., 2010), to enrich the information represented by an undersampled covariance matrix.
From a Bayesian perspective, covariance shrinkage seeks to incorporate additional prior information on error correlations into the analysis, in order to enhance the inference. In many data assimilation models, climatological covariance information is often available; i.e., it is known prior information. Climatological covariances are typically precomputed or derived from climatological models and are often employed in variational data assimilation (Lorenc et al., 2015).
Following Popov et al. (2020), we describe the stochastic covariance shrinkage technique. Instead of perturbing the transform matrix as in Eq. (20), we consider enhancing the dynamic ensemble , where N:=Nf with an M-member synthetic ensemble of samples independent of the dynamical ensemble, where . Each synthetic ensemble member is a biased sample distributed as
which is the full distribution of the forecast conditioned by the prior information that we have provided to the algorithm. Note that Eq. (21) is not the empirical measure distribution (2), which only has information from the ensemble members, but rather the “enhanced” distribution that is assumed to contain all the information from the forecast and the prior climatological information P. An illustration of this ensemble combination is shown in Fig. 3.
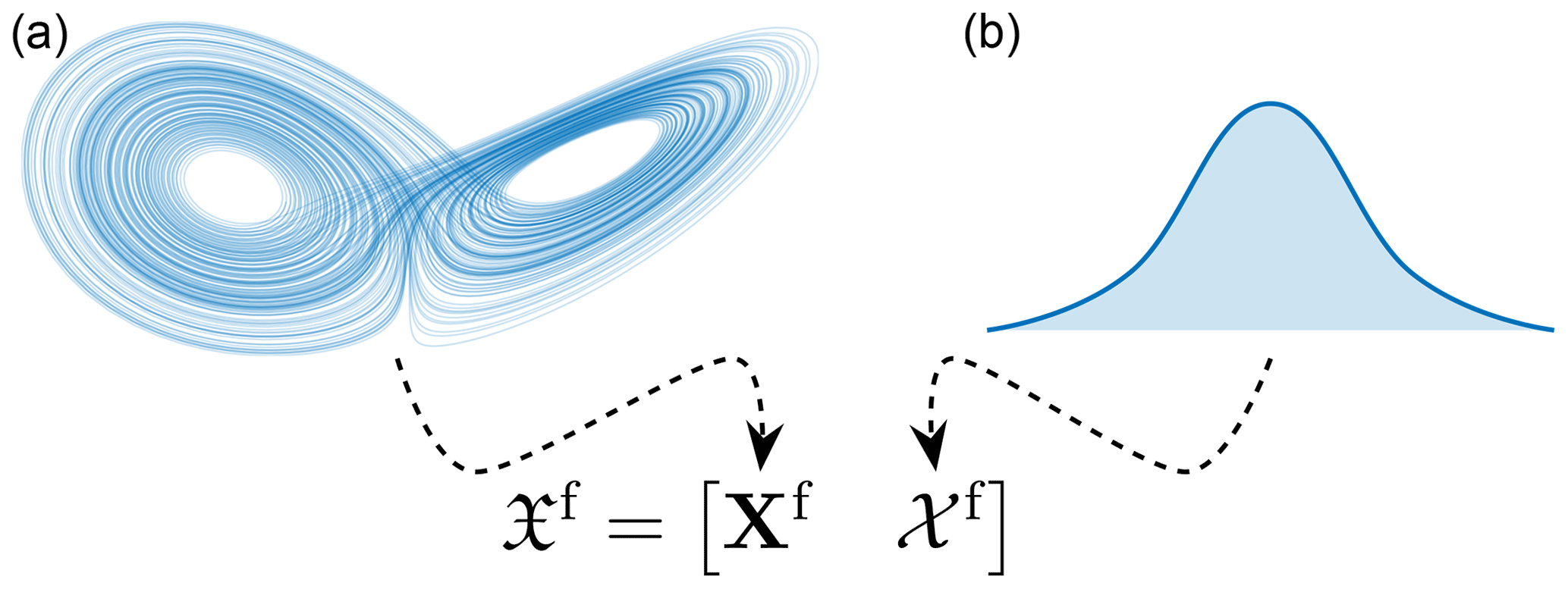
Figure 3A representation of the mixing of the dynamical ensemble Xf with the synthetic ensemble 𝒳f. The dynamical ensemble comes from the propagation of a dynamical system (here the Lorenz '63 system in panel a), while the synthetic ensemble comes from a climatological distribution (here represented by the bell curve in panel b).
Augmenting the dynamical ensembles with the synthetic ensembles leads to the total N+M-member ensemble:
with weights with respect to .
Taking Af to be the anomalies of the dynamic ensemble (17) and
to be the anomalies of the synthetic ensemble, the empirical covariance of the total ensemble can be written as
where the constituent empirical (unbiased) covariances are defined in terms of the weights
In the covariance shrinkage approach, to ensure that the sample mean of the augmented ensemble is the same as that of the dynamic ensemble, the synthetic ensemble is constructed with a mean equal to the sample mean of the dynamic ensemble:
Thus, constructing the synthetic ensemble only requires us to sample the synthetic anomalies. Consider a climatological covariance matrix 𝒫. The synthetic anomalies are sampled from some unbiased distribution with covariance μ𝒫, where μ is a scaling factor defined later. In the Gaussian case,
An alternate choice of distribution that we explore is the symmetric Laplacian distribution (Kozubowski et al., 2013),
which is described by the probability density function
where K is the modified Bessel function of the second kind (Olver et al., 2010). The choice of Laplacian distribution is motivated by robust statistics techniques (Rao et al., 2017). The resulting sampled covariance would therefore be an estimate of the scaled climatological covariance:
Remark 1. In order to stay consistent with the mean estimate, the sampled anomalies are replaced with their mean zero counterparts:
The weights 𝔴f are divided into two classes: those that are associated with the dynamic ensemble and those that are associated with the synthetic ensemble,
where the parameter γ is known as the covariance shrinkage factor. One choice to calculate γ is the Rao–Blackwell–Ledoit–Wolf (RBLW) estimator (Chen et al., 2009; Nino-Ruiz and Sandu, 2016, Eq. 9)
where the sphericity factor,
represents the mismatch between the climatological covariance (called the “target” in the statistical literature) and sample covariance matrices. Note that, if , then and, from Eq. (33), γRBLW→1. This represents a particular degenerate case whereby the dynamical ensemble is deemed to not be needed and the climatological distribution is deemed to perfectly represent the forecast.
In this framework (Chen et al., 2009), the scaling parameter for the climatological covariance is defined as
Remark 2. The RBLW estimator (33) makes the assumption that the underlying distribution of the dynamic ensemble is Gaussian. Typically this assumption is violated for dynamical systems of interest.
Remark 3. In the statistical literature, the target covariance is often taken to be the identity, 𝒫=I, which implies that in Eq. (34). The assumption that the target is a climatological covariance is natural generalization in the specific context of sequential data assimilation.
Remark 4. The scaling of the target matrix 𝒫 is not of any consequence. Let be a scalar scaling of the target matrix: then , implying that , rendering the matrix scaling inconsequential for computing μ. For γRBLW, observe that the trace is a linear operation, and thus the scaling of 𝒞 plays no role in computing .
Using the prior weight ensemble determined by Eq. (32), the importance sampling weights of the total ensemble 𝔛f can be computed using Eq. (4), begetting the weight ensemble 𝔴a. By leveraging this, the resulting analysis ensemble based on prior states and importance sampling weights of N+M states is transported into an equally weighted posterior ensemble of N states through the transformation
where the optimal transport matrix is computed by solving Eq. (9).
Recall that in the traditional method of rejuvenation (20), the optimal transport matrix is perturbed randomly into a nearby transport matrix; no new prior information is introduced. We take a fundamentally different approach by incorporating “unseen” prior information derived from a climatological covariance. To this end, before the Monge–Kantorovich problem (9) is solved, we augment the empirical measure distribution (2) with samples from the climatological distribution to accommodate the total ensemble (22),
with being the random variable corresponding to this measure, estimating the distribution (21), and the weights (32) coming from the RBLW shrinkage factor (33). In effect we attempt to avoid ensemble collapse by enhancing the empirical measure distribution (37) with new prior information, as opposed to a reweighing of the old prior information. We denote our method as “FETPF”, standing for “foresight” ETPF, as we believe including prior information in the analysis procedure is a type of foresight. When this procedure is combined with localization as described in Sect. 2.1, we arrive at the localized FETPF, or LFETPF, algorithm.
4.1 Convergence of the FETPF
In this section we show that the FETPF reduces to (generalized) variants of the ETPF in two different ways: in the synthetic ensemble limit and in the synthetic distribution limit.
Assume that the synthetic sample distribution is inexact in the mean and covariance, violating the assumption made in Eq. (21). As the dynamical ensemble size N increases, the shrinkage factor γRBLW in Eq. (33) approaches 0. This means that in the limit of an infinite dynamical ensemble, the FETPF reduces to the ETPF.
Assume by contrast that the synthetic sample distribution is exact, meaning that the climatology produces samples indistinguishable from the forecast and that the assumption in Eq. (21) is fully satisfied. For a finite dynamical ensemble, the shrinkage factor γRBLW in Eq. (33) approaches 1, and the synthetic ensemble is taken as the forecast. This reduces to the ETPF in the case when the dynamical ensemble size is equal to the synthetic ensemble size N=M and should result in an equivalent formulation when M>N.
This leaves a gap, however, as the shrinkage factor γRBLW only accounts for the covariance; thus, if the synthetic ensemble distribution effectively predicts the covariance but does not predict the higher-order moments well, then the synthetic ensemble will still violate Eq. (21) even when it is treated as the forecast. Thus, an ideal shrinkage factor superior to Eq. (33) that takes into account more than just the covariance is required, though this is significantly outside the scope of this work.
Remark 5. Most ensemble-based methods, including the ETPF, can produce physically unrealistic analysis ensemble members because of the linear nature of the optimal transport matrix. As the ETPF and FETPF perform inference that converges in distribution to the exact analysis distribution, as the dynamical ensemble size N grows, the algorithms produce physically realistic realizations with probability 1.
4.2 Multiple climatological covariance matrices
It is conceivable that multiple climatological models give rise to multiple climatological covariances, or alternatively multiple candidates for the most “common” behavior of the model are to be chosen.
Given a collection of target covariances, {𝒫j}j∈𝒥, we must choose the appropriate covariance from which to sample. We consider the sphericity of the mismatch between the target and forecast covariances: Eq. (34). Based on the authors' numerical experience, we select the target covariance that corresponds to the highest sphericity of the mismatch:
We can justify this choice by realizing that the smaller the sphericity, the closer our samples are to that of canonical rejuvenation techniques. The aim of climatological shrinkage is to introduce unknown information into our inference procedure, and thus the target covariance with the highest mismatch introduces the highest amount of outside information.
Remark 6. It is also possible to construct “multi-target” shrinkage estimators (Lancewicki and Aladjem, 2014) that consider all target matrices simultaneously.
We start with a short introduction to test problem configurations and the numerical experiment setups.
In order to stay in line with other particle rejuvenation techniques, anomaly inflation is used as a heuristic to try and overcome deficiencies in the descriptive power of the synthetic ensemble. Formally,
which is equivalent to assuming an inflated scaling factor μ in Eq. (35). We therefore have two parameters that can be configured in the rejuvenation technique: M, the size of our synthetic ensemble, and α, the inflation applied to its realizations. It is important that inflation only be applied to the synthetic ensemble and not the dynamical ensemble, so as not to violate the physical constraints of the dynamics.
In our experiments we report the error of the analysis mean with respect to the truth (reference), measured by the spatiotemporal root mean square error (RMSE):
where T stands for the relevant measured timeframe of the experiments.
We now describe the 3-variable Lorenz '63 model and the 40-variable Lorenz '96 model that are used in the experiments. We use the implementation of both these problems from the ODE test problem suite (Computational Science Laboratory, 2020; Roberts et al., 2019).
5.1 Lorenz '63 model
For the first set of numerical experiments, we use the Lorenz '63 system (Lorenz, 1963):
with chaotic canonical parameter values σ=10, ρ=28, and . We observe the first component, with Gaussian unbiased observation error, with a very large variance of R=8.
We perform 10 000 assimilation steps but discard the first 1000 that are used for spinup. The time interval between successive observations is Δt=0.12. We perform 20 independent runs and take the mean of the results to obtain an accurate estimate of the expected error. All reported results are for statistically significant differences.
This problem setup is challenging for the ensemble Kalman filter, which does not converge even for larger ensemble sizes. Therefore, this is a relevant test for non-Gaussian algorithms.
5.2 Lorenz '63 FETPF analysis results
As discussed previously, the canonical choice for the shrinkage covariance is the identity matrix. It has been the authors' experience that for most dynamical systems this choice is poor. Moreover, the sequential data assimilation problem typically provides ways to calculate climatological approximations to the covariance. We take advantage of such techniques in this paper.
The first type of climatological covariance that we investigate is that of the distribution over the whole manifold of the dynamics. The trace-state-normalized
matrix that is obtained by taking the temporal covariance of 50 000 sample points on the attractor of the canonical Lorenz '63 model is
with condition number 15.88.
Our first round of experiments compares the canonical method of rejuvenation in the ETPF and the ETPF2 with a rejuvenation factor of τ=0.04 in Eq. (19) (see Acevedo et al., 2017) to the stochastic covariance shrinkage technique for both Gaussian and Laplacian samples. A dynamic ensemble size M=100, the inflation factors , and the target covariance (43) are used. The baseline error is computed using a sequential importance resampling (SIR) filter with an ensemble of N=105 particles.
The results for the first round of experiments are shown in Fig. 4. From the results, all possible ETPF-based algorithms seem to converge to the SIR baseline for around N=100 particles. The differences between the various algorithms only become apparent at smaller ensemble sizes. As reported in Acevedo et al. (2017), the second-order accurate ETPF2 performs better than the standard ETPF.
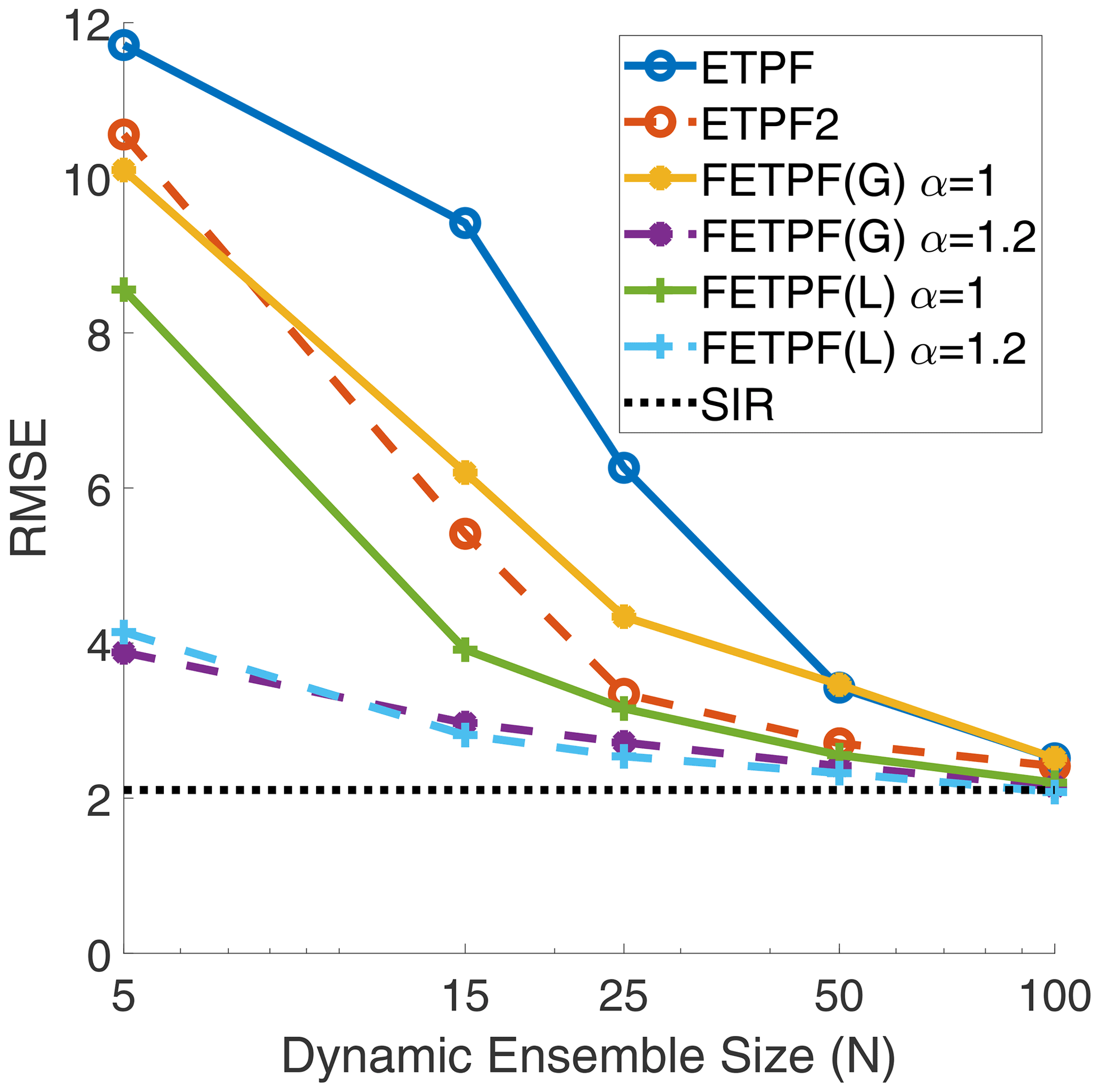
Figure 4For the Lorenz '63 model, analysis RMSE versus dynamic ensemble size (N) of the Gaussian (G) and Laplacian (L) covariance shrinkage approaches (FETPF) to particle rejuvenation for a synthetic ensemble size of M=100 and for various values of synthetic anomaly inflation, α, from Eq. (39), with respect to a canonical particle rejuvenation approach for the first-order ETPF and the second-order ETPF (denoted ETPF2) for an optimal rejuvenation factor τ=0.04. The target covariance is taken to be Eq. (43). The baseline error is denoted by the “true” SIR filter.
The FETPF without synthetic inflation performs worse than both the ETPF and the ETPF2 for Gaussian synthetic samples, while it performs better when equipped with Laplacian synthetic samples. When the synthetic samples are inflated with inflation factor α=1.2, the FETPF performs significantly better than all other algorithms.
The second round of experiments uses multiple values of the climatological covariance 𝒫. The rest of the setup is identical to the previous experiment. To test multiple covariances, we run an ETPF with N=100 with 20 000 evenly spaced state snapshots over a time interval of 2400 time units and calculate the trace-state-normalized forecast covariances. Under a square Frobenius norm distance, we cluster the empirical covariance matrices of the same ensemble at different times using the k-means algorithm (Tan et al., 2018) into two clusters. The collection of climatological covariances for Lorenz '63 thus consists of the centroids of each cluster,
with condition numbers 13.68 and 16.98, respectively. As can be seen, the clusters are mainly split by the correlation factors of z with respect to the other variables being positive or negative.
The second round of experiments is reported in Fig. 5 using the climatological covariances (44). The analysis of the results is largely similar to the previous experiment, with the only difference being that the FETPF with multiple covariances does not seem to require synthetic inflation. As the covariance chosen depends on the dynamical ensemble, these results indicate that a temporally varying climatological distribution might induce an even greater decrease in error.
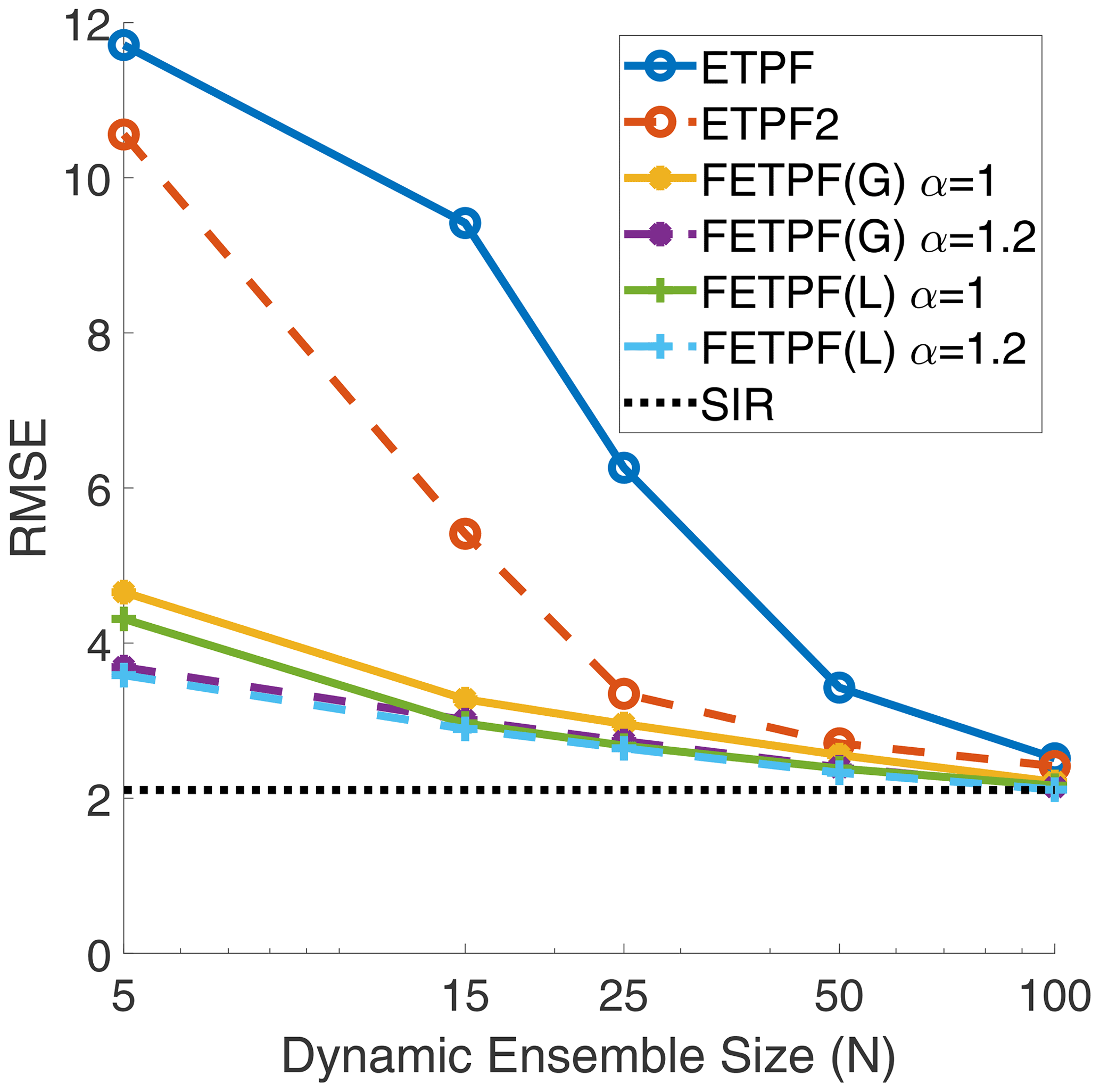
Figure 5For the Lorenz '63 model, analysis RMSE versus dynamic ensemble size (N) of the Gaussian (G) and Laplacian (L) covariance shrinkage approaches (FETPF) to particle rejuvenation with the multi-target covariances (44) for a synthetic ensemble size of M=100 and for various values of synthetic anomaly inflation (α) with respect to a canonical particle rejuvenation approach for the first-order ETPF and the second-order ETPF (denoted ETPF2) for the rejuvenation factor τ=0.04. The baseline error is denoted by the “true” SIR filter.
The results empirically show that supplementing the ensemble with additional synthetic information during assimilation is more effective than randomly perturbing the ensemble post-assimilation, for a small problem. The authors hypothesize that the results point strongly towards the need to intelligently and adaptively choose the target covariance matrices and to the need for better operational calculation of the covariance shrinkage factor γ.
5.3 Lorenz '63 parameter search
Our third round of experiments with the Lorenz '63 system seeks to understand the effect of selecting the two free parameters, i.e., the synthetic ensemble size M and the synthetic ensemble inflation factor α. We keep the dynamic ensemble size to a small constant size of N=5 and vary M in the range [0,200], with α varying in the range [1,1.2].
Figure 6 shows the spatiotemporal RMSE for various values of M and α, with Gaussian synthetic samples using the single target matrix (43). The results are not surprising. An increase in the synthetic ensemble size M corresponds to a decrease in error. Similarly, an increase in the inflation factor also corresponds to a decrease in error. Furthermore, the factors are complementary, meaning that increasing both decreases the error even more significantly.
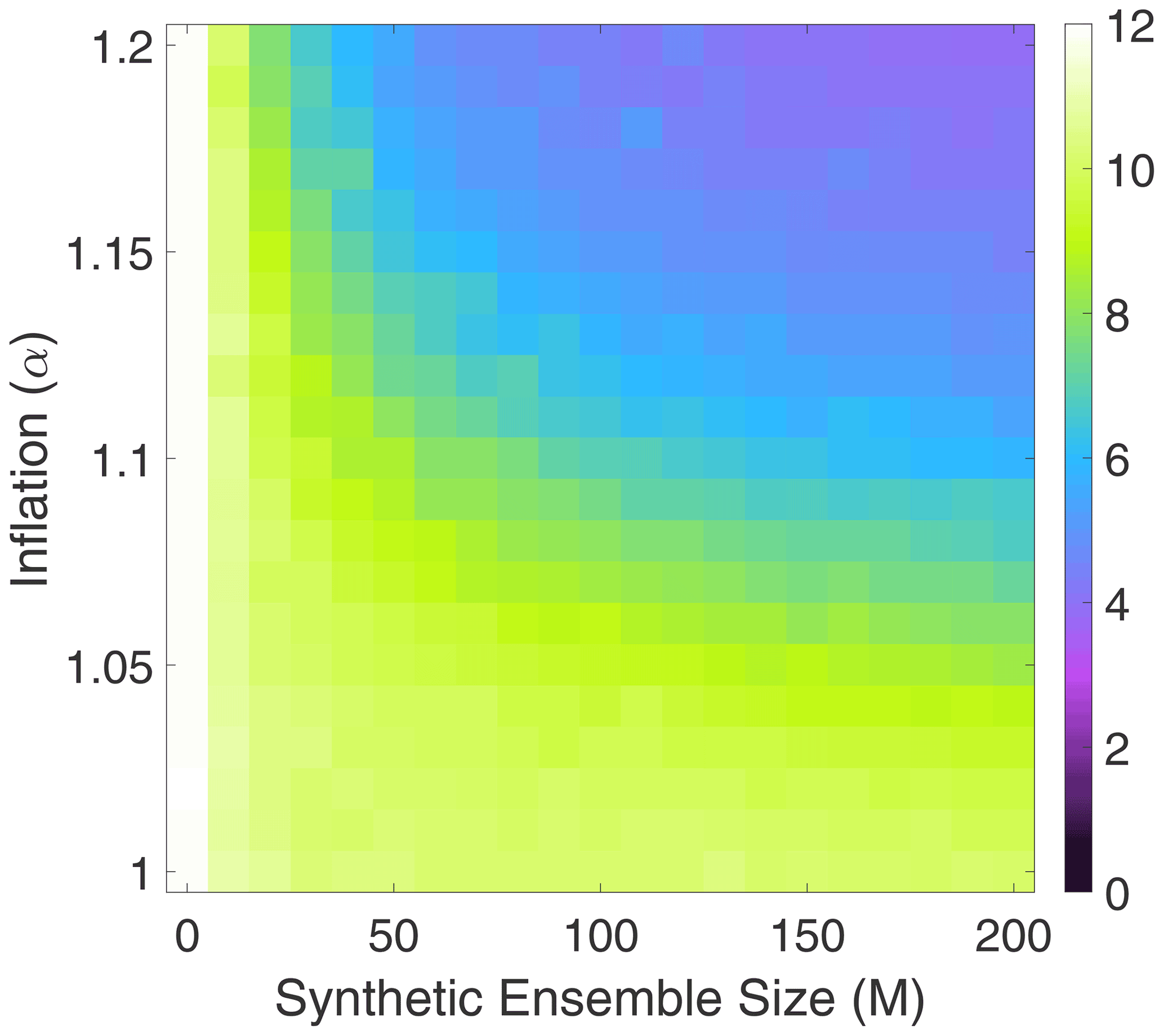
Figure 6For the Lorenz '63 model, analysis RMSE of the covariance shrinkage approach to particle rejuvenation (FETPF) for different values of the synthetic ensemble size M and synthetic inflation factor α and for a dynamical ensemble size of N=5.
An interesting effect is that very large synthetic ensemble sizes are required to correspond to a noticeable decrease in error relative to the dimension of the system. This might pose a challenge when this algorithm is utilized without further corrections such as localization.
5.4 Lorenz '63 γRBLW histograms
Our fourth experiment with the Lorenz '63 equations looks at the distribution of the values of the shrinkage parameter γRBLW from Eq. (33) that is obtained through the assimilation procedure. We test with the Gaussian (Eq. 27) and Laplacian (Eq. 28) on the climatological distribution with no synthetic inflation (39) (α=1).
Figure 7 shows an approximation to the distributions of γRBLW for several choices of the dynamical ensemble size N with all other settings kept the same as in the previous experiments. As shown in Sect. 4.1, the shrinkage factor γRBLW tends towards a distribution that starts resembling a degenerate distribution around zero as N increases. For Gaussian samples, this happens in a smooth fashion, but for Laplacian samples something interesting occurs. For N=5, the distribution of γRBLW is significantly much more skewed towards smaller values, meaning that less confidence is placed in the synthetic ensemble. While the authors do not see a convincing explanation for this behavior, the effect does explain why the Laplacian distributed synthetic samples were an improvement over Gaussian samples in Sect. 5.2.
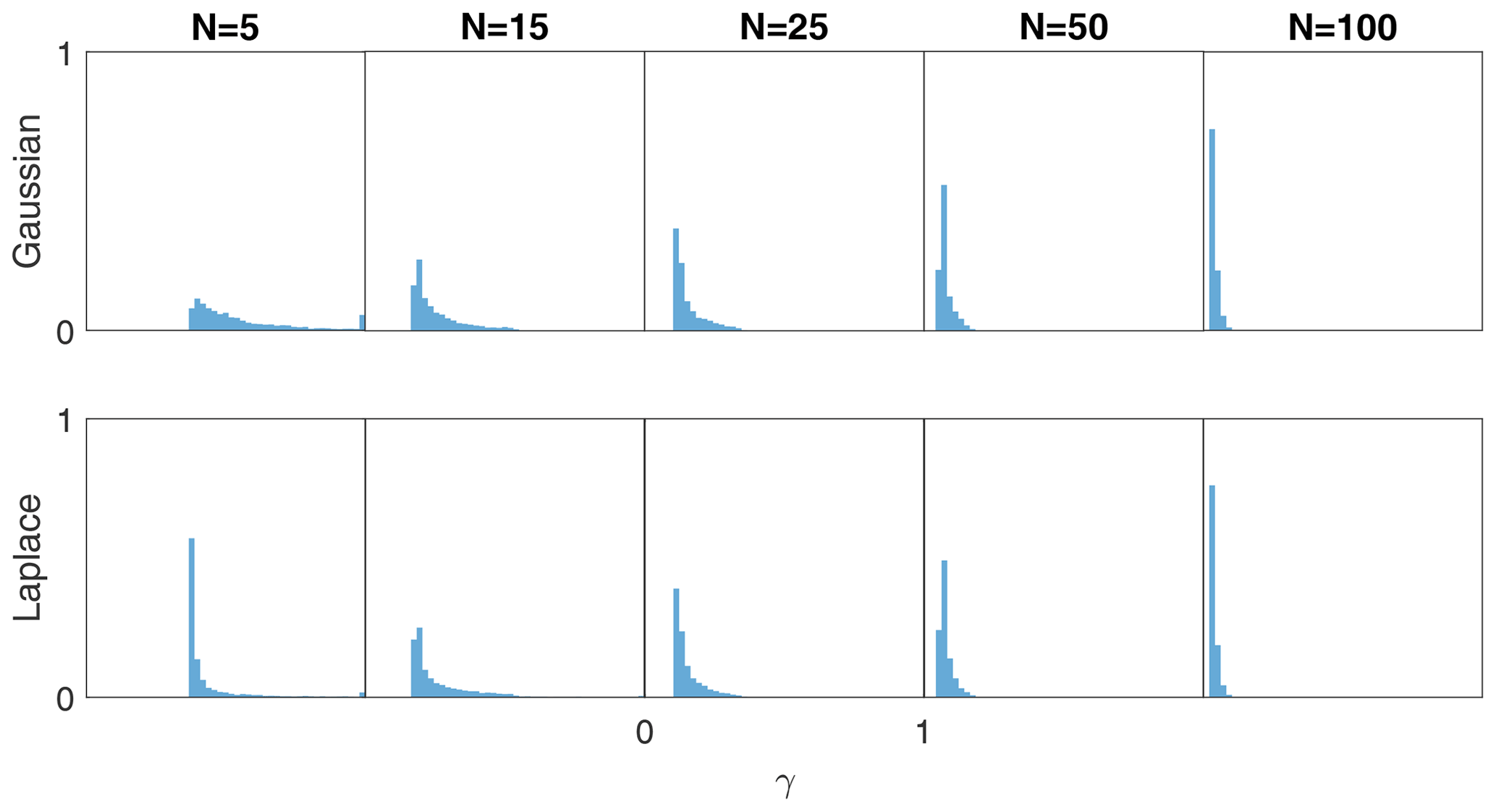
5.5 Lorenz '96 model
For numerical experiments with localization, we use the Lorenz '96 system (Lorenz, 1996; van Kekem, 2018):
with x0=x40, , and x41=x1. The Lorenz '96 system provides a more challenging medium-dimensional assimilation scenario. We perform 1000 assimilation steps but discard the first 100 that are used for spinup. The time interval between successive observations is Δt=0.05. We perform four independent runs and take the mean of the results to obtain an accurate estimate of the expected error.
We test with two observation operators. First, we consider a standard linear observation operator
that observes all states with an observation covariance of R=I40. Second, we use the nonlinear observation operator (Asch et al., 2016),
where ∘ stands for element-wise operations (multiplication and exponentiation), and stands for element-wise absolute values that observe all states in a nonlinear fashion with the observation covariance R=I40. We set the control parameter to ω=5 for a moderately nonlinear system.
The matrix 𝒫 is computed in a similar way to Eq. (43) for the Lorenz '63 model and is shown in Fig. 8.

For localization, we take the Gaspari–Cohn (Gaspari and Cohn, 1999) decorrelation function. As observed in Farchi and Bocquet (2018), a relatively small localization radius is needed for the LETPF to converge. We take a radius of r=1 variable with the internal parameter of to more closely match the standard Gaussian localization function (see Petrie, 2008, for more details on the internal parameter). This effectively means that three variables of either size are taken into consideration for every state variable.
5.6 Lorenz '96 localization results
For the Lorenz '96 experiments we aim to compare LFETPF to the LETPF and to the localized ensemble transform Kalman filter (LETKF). We set the synthetic ensemble size to a constant M=100 and the synthetic ensemble inflation factor to α=1.05. The inflation factor α=1.05 is also used in the LETKF. We vary the dynamical ensemble size in the range and plot the spatiotemporal analysis RMSE over the time interval after spinup. For the LETPF, a constant high rejuvenation value of τ=0.2 is utilized in order to ensure convergence.
For the linear observation operator (46), the results of this experiment can be seen in Fig. 9. The proposed LFETPF did converge, for a dynamical ensemble size of as little as N=4, as compared to the LETPF, which required a minimum ensemble size of N=14, in line with the number of positive Lyapunov modes of the system. The proposed LFETPF performed slightly worse than the LETPF, which we suspect would be rectified by a larger choice of M. Both the particle filters performed worse than the state-of-the-art LETKF.

Figure 9For the Lorenz '96 model with the linear observation operator (46): analysis RMSE versus dynamic ensemble size (N) of the LETPF with rejuvenation factor τ=0.2 versus the Gaussian (G) localized covariance shrinkage approach (LFETPF) to particle rejuvenation for a synthetic ensemble size of M=100 and for synthetic anomaly inflation, α=1.05, versus the LETKF (Hunt et al., 2007) method with inflation α=1.05.
For the nonlinear observation operator (47), the results are plotted in Fig. 10. Similarly to the linear observation operator, both the LETKF and LFETPF require very few ensemble members to converge, with the LETPF again requiring around N=14 ensemble members. The LETKF still beats both particle filters even in this non-Gaussian setting. These results show that the R-localization approach used for the ETPF is likely breaking many of the nice non-Gaussian features of the algorithm, as the algorithm should theoretically perform significantly better than a Kalman-filtering-based approach in this setting.
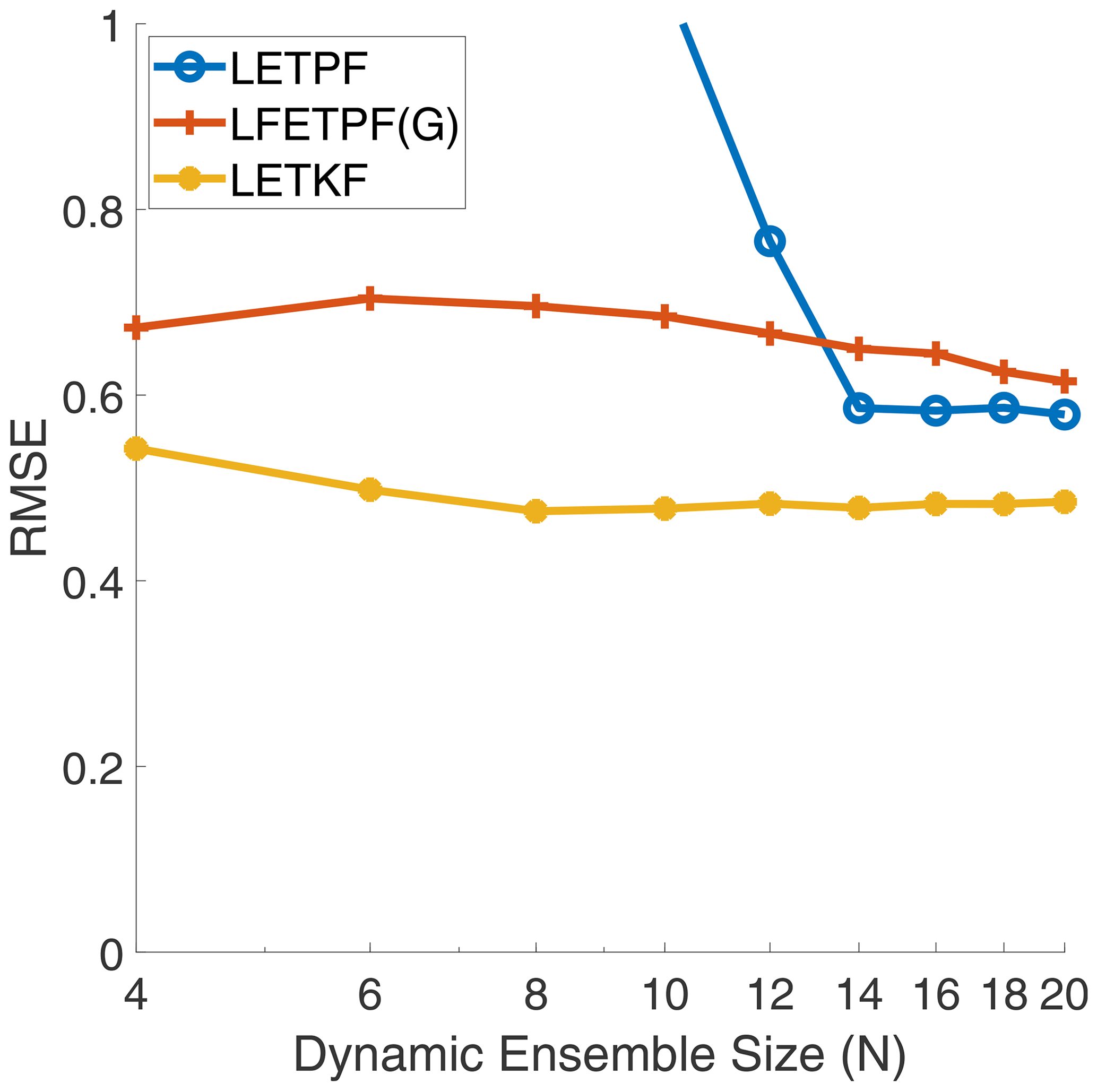
Figure 10For the Lorenz '96 model with the nonlinear observation operator (47): analysis RMSE versus dynamic ensemble size (N) of the LETPF with rejuvenation factor τ=0.2 versus the Gaussian (G) localized covariance shrinkage approach (LFETPF) to particle rejuvenation for a synthetic ensemble size of M=100 and for synthetic anomaly inflation, α=1.05, versus the LETKF (Hunt et al., 2007) method with inflation α=1.05.
This paper introduces a stochastic covariance shrinkage-based particle rejuvenation technique for the ensemble transport particle filter. Instead of incorporating synthetic noise as an attempt to regularize the distribution of the ensemble, we attempt to incorporate an ensemble derived from some known prior information. This is done through the use of synthetic anomalies. These synthetic anomalies are sampled from any chosen distribution family, such that they are consistent with the climatological covariance information. We provide a philosophical justification for why we believe our approach is more in line with the assumptions underlying Bayesian inference.
Numerical experiments with the simple three-variable Lorenz system show that the use of climatological prior information to perform rejuvenation leads to reduced analysis errors than the typical rejuvenation approach. Additionally, the FETPF methodology seems to be much more stable for smaller dynamical ensemble sizes than the original rejuvenation approach. This leads us to believe that the stochastic shrinkage approach augments the original ensemble in a meaningful way.
Numerical experiments with localization techniques show that the LFETPF is comparable in performance to the LETPF; however, a large synthetic ensemble size is likely needed. Future work combining the LFETPF and the LFETKF (Popov et al., 2020) in a hybrid filtering approach (Acevedo et al., 2017) might provide a happy medium between the LFETPF and the LFETKF.
One limitation of this work is the focus on synthetic Gaussian samples. Methods such as generative adversarial networks (Aggarwal, 2018) (known as GANs) could be utilized to give more complex synthetic samples that mimic “true” samples in meaningful ways. Another related limitation is our focus solely on the RBLW (Chen et al., 2009) shrinkage factor. While it has been the authors' experience that other factors do not perform as well in this setting, further research into building factors specifically tailored for ensemble-based data assimilation methods is warranted.
By far the largest limitation of this work is common to research on particle filters: the large-dimensional setting. While localization methods have begun the foray of particle filters into the medium-dimensional setting, alternatives to R localization in the ETPF coupled with stochastic shrinkage may provide an avenue to a higher-dimensional setting.
It is the authors' belief that future research into all the limitations that have been identified might significantly improve the performance of the FETPF and create a method that can be applied to operational problems.
The version of ODE test problems used to generate all the experiments in this work is available at the persistent link https://github.com/ComputationalScienceLaboratory/ODE-Test-Problems/releases/tag/v0.0.1 (Computational Science Laboratory, 2020; https://doi.org/10.5281/zenodo.6676706, Roberts et al., 2022). The data assimilation code including the ETPF, ETPF2, LETPF, FETPF, and LFETP used in this work can be found at the persistent link https://github.com/ComputationalScienceLaboratory/DATools/releases/tag/2022-06-10 (Computational Science Laboratory, 2022; https://doi.org/10.5281/zenodo.6676745, Popov et al., 2022).
All data for this work were generated through the software packages above and can be made available by a request to the authors.
All the authors contributed to the final draft of the work. Additionally, AAP wrote the first draft and contributed to the numerical experiments, ANS contributed to the numerical experiments, and AS contributed to the formulation of the initial idea.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We would like to thank the rest of the members of the Computational Science Laboratory at Virginia Tech.
This research has been supported by the Division of Mathematical Sciences (grant no. NSF CDS&E-MSS–1953113) and the Advanced Scientific Computing Research (grant no. DOE ASCR DE–SC0021313).
This paper was edited by Olivier Talagrand and reviewed by Manuel Pulido and Alban Farchi.
Acevedo, W., de Wiljes, J., and Reich, S.: Second-order accurate ensemble transform particle filters, SIAM J. Sci. Comput., 39, A1834–A1850, 2017. a, b, c, d, e, f
Aggarwal, C. C.: Neural networks and deep learning, Springer, https://doi.org/10.1007/978-3-319-94463-0, 2018. a
Anderson, J. L.: An ensemble adjustment Kalman filter for data assimilation, Mon. Weather Rev., 129, 2884–2903, 2001. a, b
Anderson, J. L.: Localization and sampling error correction in ensemble Kalman filter data assimilation, Mon. Weather Rev., 140, 2359–2371, 2012. a
Asch, M., Bocquet, M., and Nodet, M.: Data assimilation: methods, algorithms, and applications, SIAM, https://doi.org/10.1137/1.9781611974546, 2016. a, b, c
Attia, A. and Sandu, A.: A hybrid Monte–Carlo sampling filter for non-Gaussian data assimilation, AIMS Geosciences, 3, 41–78, https://doi.org/10.3934/geosci.2015.1.41, 2015. a
Burgers, G., van Leeuwen, P. J., and Evensen, G.: Analysis scheme in the ensemble Kalman filter, Mon. Weather Rev., 126, 1719–1724, 1998. a
Chen, Y., Wiesel, A., and Hero, A. O.: Shrinkage estimation of high dimensional covariance matrices, in: 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, 19–24 April 2009, Taipei, Taiwan, IEEE, 2937–2940, https://doi.org/10.1109/ICASSP.2009.4960239, 2009. a, b, c
Chustagulprom, N., Reich, S., and Reinhardt, M.: A hybrid ensemble transform particle filter for nonlinear and spatially extended dynamical systems, SIAM/ASA Journal on Uncertainty Quantification, 4, 592–608, 2016. a
Computational Science Laboratory: ODE Test Problems, GitHub [code], https://github.com/ComputationalScienceLaboratory/ODE-Test-Problems/releases/tag/v0.0.1 (last access: 10 June 2022), 2020. a, b
Computational Science Laboratory: DA Tools, GitHub [code], https://github.com/ComputationalScienceLaboratory/DATools/releases/tag/2022-06-10, last access: 10 June 2022. a
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res.-Oceans, 99, 10143–10162, 1994. a
Evensen, G.: Data assimilation: the ensemble Kalman filter, Springer Science & Business Media, https://doi.org/10.1007/978-3-642-03711-5, 2009. a
Farchi, A. and Bocquet, M.: Review article: Comparison of local particle filters and new implementations, Nonlin. Processes Geophys., 25, 765–807, https://doi.org/10.5194/npg-25-765-2018, 2018. a, b
Gaspari, G. and Cohn, S. E.: Construction of correlation functions in two and three dimensions, Q. J. Roy. Meteor. Soc., 125, 723–757, 1999. a, b
Hunt, B. R., Kostelich, E. J., and Szunyogh, I.: Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter, Physica D, 230, 112–126, 2007. a, b, c
Jaynes, E. T.: Probability theory: The logic of science, Cambridge university press, https://doi.org/10.1017/CBO9780511790423, 2003. a, b
Kozubowski, T. J., Podgórski, K., and Rychlik, I.: Multivariate generalized Laplace distribution and related random fields, J. Multivariate Anal., 113, 59–72, 2013. a
Lancewicki, T. and Aladjem, M.: Multi-target shrinkage estimation for covariance matrices, IEEE T. Signal Proces., 62, 6380–6390, 2014. a
Law, K., Stuart, A., and Zygalakis, K.: Data assimilation: a mathematical introduction, vol. 62, Springer, https://doi.org/10.1007/978-3-319-20325-6, 2015. a
Liu, J. S.: Monte Carlo strategies in scientific computing, Springer Science & Business Media, https://doi.org/10.1007/978-0-387-76371-2, 2008. a, b
Lorenc, A. C., Bowler, N. E., Clayton, A. M., Pring, S. R., and Fairbairn, D.: Comparison of hybrid-4DEnVar and hybrid-4DVar data assimilation methods for global NWP, Mon. Weather Rev., 143, 212–229, 2015. a
Lorenz, E. N.: Deterministic nonperiodic flow, J. Atmos. Sci., 20, 130–141, 1963. a
Lorenz, E. N.: Predictability: A problem partly solved, in: Proc. Seminar on Predictability, 4–8 September 1995, Shinfield Park, Reading, UK, vol. 1, 1996. a
McCann, R. J.: Existence and uniqueness of monotone measure-preserving maps, Duke Math. J., 80, 309–324, https://doi.org/10.1215/S0012-7094-95-08013-2, 1995. a
McCann, R. J. and Guillen, N.: Five lectures on optimal transportation: geometry, regularity and applications, Analysis and geometry of metric measure spaces: lecture notes of the séminaire de Mathématiques Supérieure (SMS) Montréal, 145–180, https://doi.org/10.1090/crmp/056/06, 2011. a
Musso, C., Oudjane, N., and Le Gland, F.: Improving regularised particle filters, in: Sequential Monte Carlo methods in practice, Springer, 247–271, https://doi.org/10.1007/978-1-4757-3437-9_12, 2001. a
Nino-Ruiz, E. D. and Sandu, A.: Ensemble Kalman filter implementations based on shrinkage covariance matrix estimation, Ocean Dynam., 65, 1423–1439, https://doi.org/10.1007/s10236-015-0888-9, 2015. a
Nino-Ruiz, E. D. and Sandu, A.: An ensemble Kalman filter implementation based on modified Cholesky decomposition for inverse covariance matrix estimation, arXiv [preprint], arXiv:1605.08875, 28 May 2016. a, b
Nino-Ruiz, E. D. and Sandu, A.: Efficient parallel implementation of DDDAS inference using an ensemble Kalman filter with shrinkage covariance matrix estimation, Cluster Comput., 22, 2211–2221, https://doi.org/10.1007/s10586-017-1407-1, 2019. a
Nino-Ruiz, E. D., Sandu, A., and Anderson, J. L.: An efficient implementation of the ensemble Kalman filter based on an iterative Sherman–Morrison formula, Stat. Comput., 25, 561–577, https://doi.org/10.1007/s11222-014-9454-4, 2014. a
Nino-Ruiz, E. D., Sandu, A., and Deng, X.: A parallel ensemble Kalman filter implementation based on modified Cholesky decomposition, in: Proceedings of the 6th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems, Supercomputing 2015 of ScalA '15, 15 November 2015, Austin, Texas, https://doi.org/10.1145/2832080.2832084, 2015. a
Olver, F. W., Lozier, D. W., Boisvert, R. F., and Clark, C. W.: NIST handbook of mathematical functions hardback and CD-ROM, Cambridge university press, ISBN 978-0521140638, 2010. a
Petrie, R.: Localization in the ensemble Kalman filter, MSc Atmosphere, Ocean and Climate University of Reading, http://www.met.rdg.ac.uk/mscdissertations/Localization%20in%20the%20ensemble%20Kalman%20Filter.pdf (last access: 16 June 2022), 2008. a, b
Popov, A. A. and Sandu, A.: An Explicit Probabilistic Derivation of Inflation in a Scalar Ensemble Kalman Filter for Finite Step, Finite Ensemble Convergence, arXiv [preprint], arXiv:2003.13162, 29 March 2020. a, b
Popov, A. A., Sandu, A., Nino-Ruiz, E. D., and Evensen, G.: A Stochastic Covariance Shrinkage Approach in Ensemble Transform Kalman Filtering, arXiv [preprint], arXiv:2003.00354, 29 February 2020. a, b, c
Popov, A. A., Bhattacharjee, A., Subrahmanya, A. N., and Sandu, A.: ComputationalScienceLaboratory/DATools: v0.0.1 (v0.0.1), Zenodo [code], https://doi.org/10.5281/zenodo.6676745, 2022. a
Rao, V., Sandu, A., Ng, M., and Nino-Ruiz, E. D.: Robust Data Assimilation using L1 and Huber norms, SIAM J. Sci. Comput., 39, B548–B570, 2017. a
Reich, S.: A nonparametric ensemble transform method for Bayesian inference, SIAM J. Sci. Comput., 35, A2013–A2024, 2013. a, b, c, d
Reich, S. and Cotter, C.: Probabilistic forecasting and Bayesian data assimilation, Cambridge University Press, https://doi.org/10.1017/CBO9781107706804, 2015. a, b, c, d, e, f
Roberts, S., Popov, A. A., and Sandu, A.: ODE Test Problems: a MATLAB suite of initial value problems, CoRR, arXiv [preprint], arXiv:1901.04098, 14 January 2019. a
Roberts, S., Popov, A. A., Sarshar, A., Gomillion, R., and Sandu, A.: ComputationalScienceLaboratory/ODE-Test-Problems: v0.0.1 (v0.0.1), Zenodo [code], https://doi.org/10.5281/zenodo.6676706, 2022. a
Snyder, C., Bengtsson, T., Bickel, P., and Anderson, J.: Obstacles to high-dimensional particle filtering, Mon. Weather Rev., 136, 4629–4640, 2008. a
Strogatz, S. H.: Nonlinear dynamics and chaos with student solutions manual: With applications to physics, biology, chemistry, and engineering, CRC press, ISBN 978-0813349107, 2018. a
Tan, P.-N., Steinbach, M., Karpatne, A., and Kumar, V.: Introduction to Data Mining, 2nd edn., Pearson, ISBN 978-0133128901, 2018. a, b
van Kekem, D. L.: Dynamics of the Lorenz-96 model: Bifurcations, symmetries and waves, PhD thesis, University of Groningen, ISBN 978-94-034-0979-5, 2018. a
Van Leeuwen, P. J.: Particle filtering in geophysical systems, Mon. Weather Rev., 137, 4089–4114, 2009. a
Van Leeuwen, P. J., Künsch, H. R., Nerger, L., Potthast, R., and Reich, S.: Particle filters for high-dimensional geoscience applications: A review, Q. J. Roy. Meteor. Soc., 145, 2335–2365, 2019. a
Villani, C.: Topics in optimal transportation, American Mathematical Soc., 58, ISBN 978-1-4704-6726-5, 2003. a
Zhang, Y., Liu, N., and Oliver, D. S.: Ensemble filter methods with perturbed observations applied to nonlinear problems, Computat. Geosci., 14, 249–261, 2010. a
- Abstract
- Introduction
- Optimal coupling with prior information and the ensemble transform particle filter
- Particle rejuvenation in the ETPF
- Particle rejuvenation through stochastic shrinkage
- Numerical experiments
- Conclusions
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Optimal coupling with prior information and the ensemble transform particle filter
- Particle rejuvenation in the ETPF
- Particle rejuvenation through stochastic shrinkage
- Numerical experiments
- Conclusions
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References