the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 06 Jul 2021
| 06 Jul 2021
Ensemble Riemannian data assimilation over the Wasserstein space
Ardeshir Ebtehaj
Peter J. van Leeuwen
Dongmian Zou
Gilad Lerman
In this paper, we present an ensemble data assimilation paradigm over a Riemannian manifold equipped with the Wasserstein metric. Unlike the Euclidean distance used in classic data assimilation methodologies, the Wasserstein metric can capture the translation and difference between the shapes of square-integrable probability distributions of the background state and observations. This enables us to formally penalize geophysical biases in state space with non-Gaussian distributions. The new approach is applied to dissipative and chaotic evolutionary dynamics, and its potential advantages and limitations are highlighted compared to the classic ensemble data assimilation approaches under systematic errors.
- Article
(4803 KB) - Full-text XML
- BibTeX
- EndNote





Extending the forecast skill of Earth system models (ESMs) relies on advancing the science of data assimilation (DA) (Tsuyuki and Miyoshi, 2007; Carrassi et al., 2018). A large body of current DA methodologies, either filtering (Kalman, 1960; Evensen, 1994; Reichle et al., 2002; Evensen, 2003) or variational approaches (Lorenc, 1986; Le Dimet and Talagrand, 1986; Talagrand and Courtier, 1987; Park and Županski, 2003; Trevisan et al., 2010; Carrassi and Vannitsem, 2010; Ebtehaj and Foufoula-Georgiou, 2013), are derived from basic principles of Bayesian inference under the assumption that the state space is unbiased and can be represented well with Gaussian distributions, which are not often consistent with reality (Bocquet et al., 2010; Pires et al., 2010). It is well documented that this drawback often limits the forecast skills of DA systems (Walker et al., 2001; Dee, 2005; Ebtehaj et al., 2014; B. Chen et al., 2019), especially under the presence of systematic errors (Dee, 2003).
Apart from particle filters (Spiller et al., 2008; Van Leeuwen, 2010), which are intrinsically designed for state space with a non-Gaussian distribution, numerous modifications to the variational DA (VDA) and ensemble-based filtering methods have been made to tackle the non-Gaussianity of geophysical processes (Pires et al., 1996; Han and Li, 2008; Mandel and Beezley, 2009; Anderson, 2010). As a few examples, in four-dimensional VDA, a quasi-static approach is proposed to ensure convergence by gradually increasing the assimilation intervals (Pires et al., 1996). To deal with multimodal systems, Kim et al. (2003) proposed modifications to the ensemble Kalman filter (EnKF; Evensen, 1994; Li et al., 2009) using an approximate implementation of Bayes' theorem in lieu of a linear interpolation via Kalman gain. For ensemble-based filters, Anderson (2010) proposed a new approach to account for non-Gaussian priors and posteriors by utilizing rank histograms (Anderson, 1996; Hamill, 2001). A hybrid ensemble approach was also suggested to combine advantages of both EnKF and particle filter (Mandel and Beezley, 2009).
Even though particle filters can handle non-Gaussian likelihood functions, when observations lie away from the support set of the particles, the ensemble variance tends to zero over time and can render the filter degenerate (Poterjoy and Anderson, 2016). In recent years, significant progress has been made to treat systematic errors through numerous ad hoc methods such as the field alignment technique (Ravela et al., 2007) and morphing EnKF (Beezley and Mandel, 2008) that can tackle position errors between observations and forecast. Dual state parameter EnKF (Moradkhani et al., 2005) was also developed to resolve systematic errors originating from parameter uncertainties. Additionally, bias-aware variants of the Kalman filter were designed (Drécourt et al., 2006; De Lannoy et al., 2007a, b; Kollat et al., 2008) to simultaneously update the state space and an a priori estimate of the additive biases. In parallel, the cumulative distribution function matching (Reichle and Koster, 2004) has garnered widespread attention in the land of DA.
From a geometrical perspective, Gaussian statistical inference methods exhibit a flat geometry (Amari, 2012). In particular, it is proved that linear autoregressive and moving average Markov stochastic models, which are driven by Gaussian noise, form dually flat manifolds (Amari, 2012). The notion of distance over such a geometrically flat space is defined over a straight line, which can be quantified by the Euclidean distance. Consequently, the Euclidean space has served as a major tool for explaining statistical inference techniques using linear Gaussian models and has been the cornerstone of DA techniques. It is important to note that the Euclidean distance remains (Ning et al., 2014) insensitive to the magnitude of translation between probability distributions with disjoint support sets – when used to interpolate between them.
Non-Gaussian statistical models often form geometrical manifolds, which is a topological space that is locally Euclidean. In the case of nonlinear regression, it is demonstrated that the statistical manifold exhibits a Riemannian geometry (Lauritzen, 1987) over which the notion of distance between probability distributions is geodesic that can not only capture translation but also the difference between the entire shape of probability distributions (Pennec, 2006). The question is, thus: how can we equip DA with a Riemannian geometry? To answer this question, and inspired by the theories of optimal mass transport (Villani, 2003), this paper presents the ensemble Riemannian data assimilation (EnRDA) framework using the Wasserstein metric or distance, which is a distance function defined between probability distributions, as explained in detail in Sect. 2.3.
In recent years, a few attempts have been made to utilize the Wasserstein metric in geophysical DA. Reich (2013) introduced an ensemble transform particle filter, where the optimal transport framework was utilized to guide the resampling phase of the filter. Ning et al. (2014) used the Wasserstein distance to reduce forecast uncertainty due to parameter estimation errors in dissipative evolutionary equations. Feyeux et al. (2018) suggested a novel approach employing the Wasserstein distance in lieu of the Euclidean distance to penalize the position error between state and observations. More recently, Tamang et al. (2020) introduced a Wasserstein regularization in a variational setting to correct for geophysical biases under chaotic dynamics.
The EnRDA extends the previous work through the following main contributions: (a) EnRDA defines DA as a discrete barycenter problem over the Wasserstein space for assimilation in the probability domain without any parametric or Gaussian assumption. The framework provides a continuum of nonparametric analysis probability histograms that naturally span between the distributions of the background state and observations through the optimal transport of probability masses. (b) The presented methodology operates in an ensemble setting and utilizes a regularization technique for improved computational efficiency. (c) The paper studies the advantages and limitations of DA over the Wasserstein space for dissipative advection–diffusion dynamics and a nonlinear chaotic Lorenz-63 model in comparison with the well-known ensemble-based methodologies.
The organization of the paper is as follows: Section 2 provides a brief background on Bayesian DA formulations and optimal mass transport. The mathematical formalism of EnRDA is described in Sect. 3. Section 4 presents the results and compares them with their Euclidean counterparts. Section 5 discusses the findings and ideas for future research.
2.1 Notations
Throughout the paper, small bold letters represent m element column vectors , where (⋅)T is the transposition operator. The m by n matrices are denoted by capital bold letters, whereas denotes those vectors (matrices) only containing nonnegative real numbers. The 1m refers to an m element vector of ones, and Im is an m×m identity matrix. A diagonal matrix with entries given by x∈ℝm is represented by . The notation denotes that the random vector x is drawn from a Gaussian distribution, with a mean μ and covariance Σ, and 𝔼X(x) is the expectation of x. The ℓq norm of x is defined as with q>0, and the square of the weighted ℓ2 norm of x is represented as , where B is a positive definite matrix. Notations of x⊙y and x⊘y represent the element-wise Hadamard product and the division between equal length vectors x and y, respectively. The notation denotes the Frobenius inner product between matrices A and B, and tr(⋅) and det[⋅] represent trace and determinant of a square matrix, respectively. Here, represents a discrete probability distribution with the respective histogram supported on xi, where represents a Kronecker delta function at xi. Throughout, the dimension of the state or observations is denoted by small letters, such as x∈ℝm, while the number of ensembles or support points of their respective probability distribution is shown by capital letters such as .
2.2 Data assimilation on Euclidean space
In this section, we provide a brief review of the derivation of classic variational DA and particle filters based on Bayes' theorem to set the stage for the presented ensemble Riemannian DA formalism.
2.2.1 Variational formulation
Let us consider the discrete time Markovian dynamics and the observations as follows:
where xt∈ℝm and yt∈ℝn represent the state variables and the observations at time t, and are the deterministic forward model and observation operator, and ωt∈ℝm and vt∈ℝn are the independent and identically distributed model and observation errors, respectively.
Recalling Bayes' theorem, dropping the time superscript without loss of generality, the posterior probability density function (pdf) of the state, given the observation, can be obtained as , where p(y|x) is proportional to the likelihood function, p(x) is the prior density, and p(y) denotes the distribution of observations. Letting represents the background state, ignoring the constant term log p(y), and assuming Gaussian distributions for the observation error and the prior, a logarithm of the posterior density leads to the following well-known three-dimensional variational (3D-Var) cost function (Lorenc, 1986; Kalnay, 2003):
As a result, the analysis state obtained by the minimization of the cost function in Eq. (2) is the mode of the posterior distribution that coincides with the posterior mean when errors are drawn from unbiased Gaussian densities and ℋ(⋅) is a linear operator. Using the Woodbury matrix inversion lemma (Woodbury, 1950), it can be easily demonstrated that, for a linear observation operator, the analysis states in the 3D-Var and Kalman filter are equivalent (Tarantola, 1987). As is evident, zero mean Gaussian assumptions lead to the penalization of the error through the weighted Euclidean norm.
2.2.2 Particle filters
Particle filters (Gordon et al., 1993; Doucet and Johansen, 2009; Van Leeuwen et al., 2019) in DA were introduced to address the issue of a non-Gaussian distribution of the state by representing the prior and posterior distributions through a weighted ensemble of model outputs referred to as particles. In its standard discrete setting, using Monte Carlo simulations, the prior distribution p(x) is represented by a sum of equal-weight Kronecker delta functions as , where xi∈ℝm is the state variable represented by the ith particle.
Each of these M particles are then evolved through the nonlinear model in Eq. (1). Assuming that the conditional distribution is Gaussian, using Bayes' theorem, it can be shown that the posterior distribution p(x|y) can be approximated using a set of weighted particles as , where . The particles are then resampled from the posterior distribution p(x|y) based on their relative weights and are propagated forward in time according to the model dynamics.
As is evident, in particle filters, weights of each particle are updated using the Gaussian likelihood function under a zero mean error assumption. However, in the presence of systematic biases, when the support sets of particles and the observations are disjoint, only the weights of a few particles become significantly large, and the weights of other particles tend to zero. As the underlying dynamical system progresses in time, only those few particles, with relatively larger weights, are resampled, and the filter can gradually become degenerate in time (Poterjoy and Anderson, 2016).
2.3 Optimal mass transport
The theory of optimal mass transport (OMT), coined by Gaspard Monge (Monge, 1781) and later extended by Kantorovich (Kantorovich, 1942), was developed to minimize the transportation cost in resource allocation problems with purely practical motivations. Recent developments in mathematics discovered that OMT provides a rich ground to compare and morph probability distributions and uncover new connections to partial differential equations (Jordan et al., 1998; Otto, 2001) and functional analysis (Brenier, 1987; Benamou and Brenier, 2000; Villani, 2003).
In a discrete setting, let us define two discrete probability distributions, and , with their respective histograms, and , supported on xi and yj. A ground transportation cost matrix is defined such that its elements represent the cost of transporting unit probability masses from location xi to yj. The Kantorovich OMT problem determines an optimal transportation plan that can linearly map two probability histograms onto each other with minimum amount of total transportation cost, as follows:
The transportation plan can be interpreted as a joint distribution that couples the marginal histograms px and py. For the transportation cost with q=2, the OMT problem in Eq. (3) is convex and defines the square of the 2-Wasserstein distance between the histograms.
Wasserstein distance has some advantages compared to other measures of proximity, such as the Hellinger distance (Hellinger, 1909) or the Kullback–Leibler (KL) divergence (Kullback and Leibler, 1951). To elaborate on the advantages, we confine our consideration to the Gaussian densities over which the Wasserstein distance can be obtained in a closed form. In particular, interpolating over the 2-Wasserstein space between 𝒩(μx,Σx) and 𝒩(μy,Σy), using an interpolation parameter η, results in a Gaussian distribution 𝒩(μη,Ση), where and (Y. Chen et al., 2019).
Figure 1 shows the spectrum of interpolated distributions between two Gaussian pdf's for a range of . As shown, the interpolated densities using the Hellinger distance, which is Euclidean in the space of probability histograms, are bimodal. Although the Gaussian shape of the interpolated densities using the KL divergence is preserved, the variance of the interpolants is not necessarily bounded by the variances of the input Gaussian densities. Unlike these metrics, as shown, the Wasserstein distance moves the mean and preserves the shape of the interpolants through a natural morphing process.
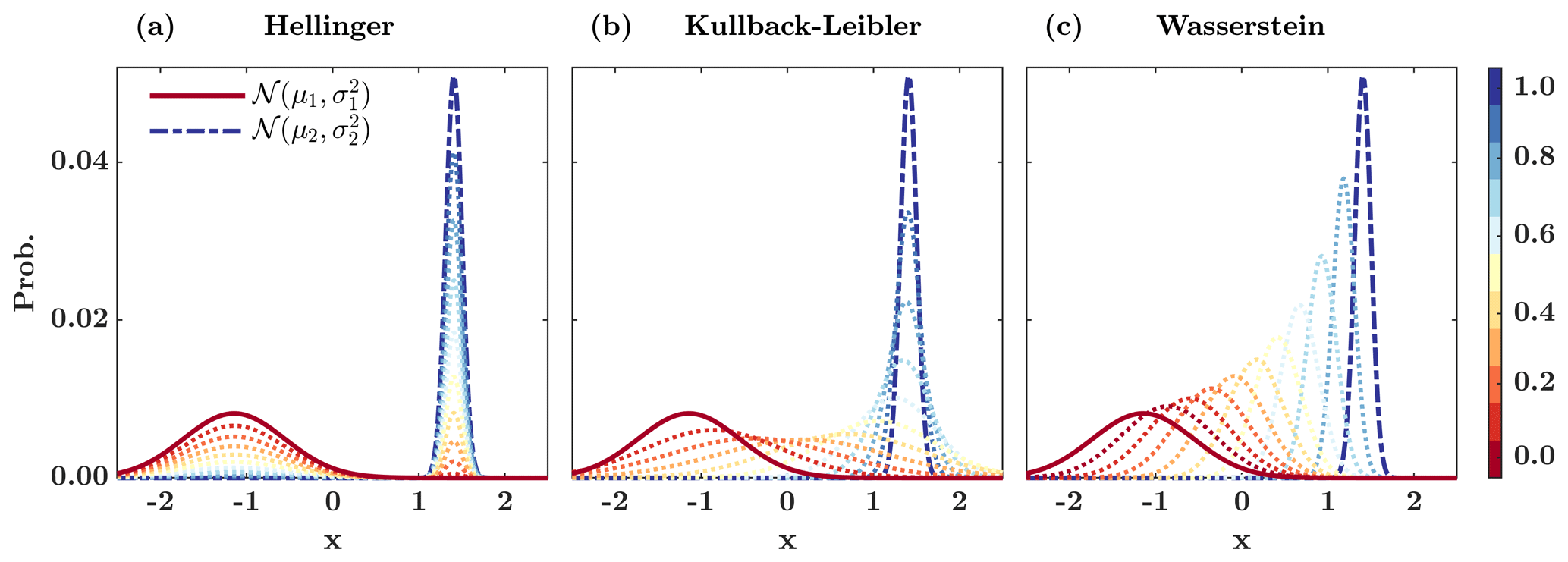
Figure 1Interpolation between two Gaussian distributions and , where , and act as a function of the interpolation or displacement parameter for the (a) Hellinger distance, (b) Kullback–Leibler divergence, and (c) 2-Wasserstein distance (Peyré and Cuturi, 2019)
As is previously noted, this metric is not limited to any Gaussian assumption. Figure 2 shows the 2-Wasserstein interpolation between a gamma and a Gaussian distribution. The results show that the Wasserstein metric penalizes the translation and mismatch between the shapes of the pdf's. It can be shown that , where and are the centered zero mean probability masses, and μx and μy are the respective mean values (Peyré and Cuturi, 2019).
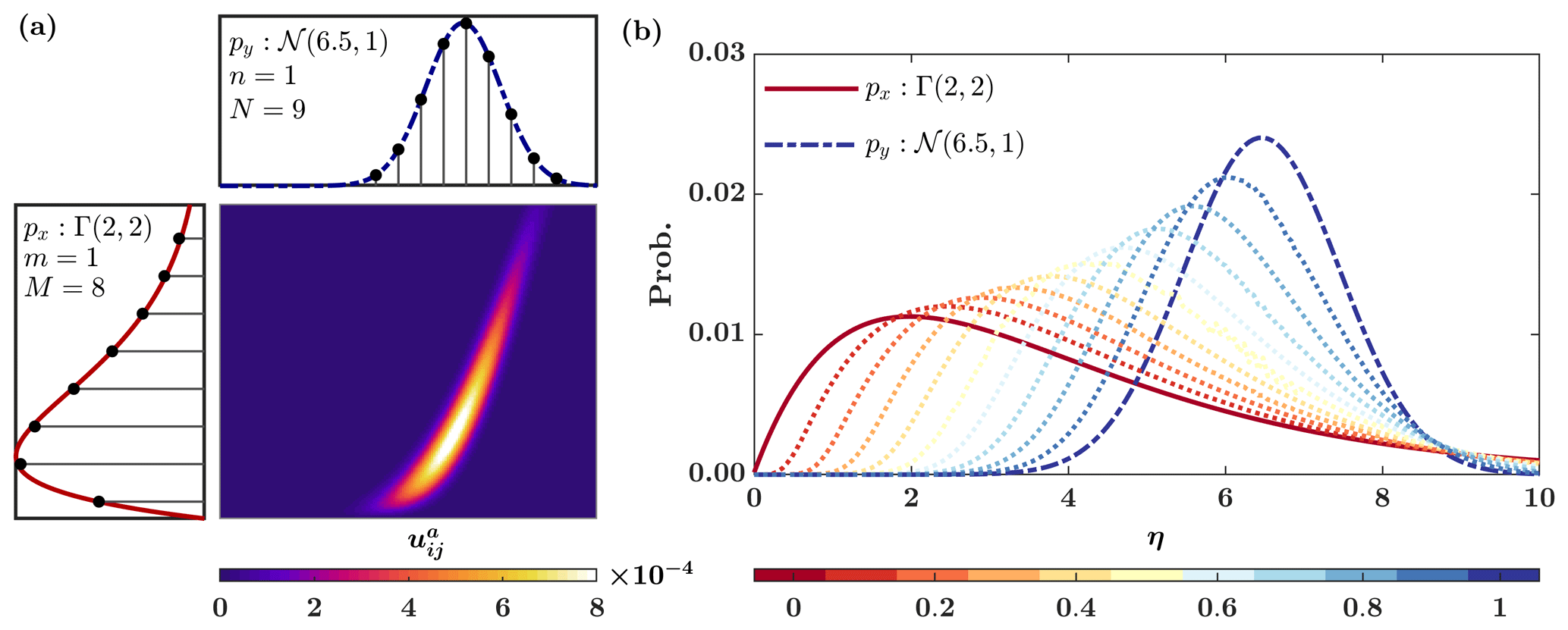
Figure 2(a) Optimal transportation plan or the joint distribution Ua between a gamma Γ(2,2) and a Gaussian marginal distribution 𝒩(6.5,1) and (b) the 2-Wasserstein interpolation between them for different values of the displacement parameter .
3.1 Problem formulation
First, let us recall that the weighted mean of a cloud of points in the Euclidean space is for a given family of nonnegative weights . This expected value is equivalent to solving the following variational problem:
The 3D-Var problem in Eq. (2) reduces to the above barycenter problem when the model and observation error covariances are diagonal with uniform error variances across multiple dimensions of the state space. For non-diagonal error covariances, it can be shown that the weight of the background and observation are and , respectively, where H is the linear approximation of the observation operator. Therefore, the 3D-Var DA can be interpreted as a barycenter problem in the Euclidean space, where the analysis state is the weighted mean of the background state and observation.
By changing the distance metric from Euclidean to the Wasserstein (Agueh and Carlier, 2011), a Riemannian barycenter can be defined as the Fréchet mean (Fréchet, 1948) of Np probability histograms with finite second-order moments, as follows:
Inspired by (Feyeux et al., 2018), the EnRDA defines the probability distribution of the analysis state p(xa)∈ℝM as the Fréchet barycenter over the Wasserstein space as follows:
where the displacement parameter η>0 assigns the relative weights to the observation and background term to capture their respective geodesic distances from the true state. Here is the Jacobian of the observation operator, assuming that is a smooth and a square (i.e., m=n) bijective map. The displacement parameter η is a hyperparameter, and its optimal value should be determined empirically using some reference data through cross-validation studies. For example, in practice, one may compute the mean squared error as a function of η, by comparing the analysis state and some ground-based observations, and use the minimum point of that function statically over a window of multiple assimilation cycles. It is also important to note that, due to the bijective assumption for the observation operator, the above formalism currently lacks the ability to propagate the information content of observed dimensions to unobserved ones. This limitation is discussed further in the Sect. 5.
The solution of the above DA formalism involves finding the optimal analysis transportation plan or the joint distribution , using Eq. (3), that couples the background and observation marginal histograms. We use McCann's method (McCann, 1997; Peyré and Cuturi, 2019) to obtain the analysis probability histogram, as follows:
where the analysis support points are . To solve Eq. (3), the widely used interior point methods (Altman and Gondzio, 1999) and Orlin's (Orlin, 1993) algorithm have a super-cubic run time with a computational complexity of O(M3log M), where M=N. Therefore, the use of the original OMT framework in EnRDA is a limitation in high-dimensional geophysical DA problems. To alleviate this computational cost, in the next Sect. 3.2, we discuss the use of entropic regularization.
To solve Eq. (6) in an ensemble setting, let us assume that, in the absence of any a priori information, the background probability distribution is initially represented by i=1…M ensemble members of the state variable xi∈ℝm as . An a priori assumption is needed to reconstruct the observation distribution at j=1…N supporting points. To that end, one may choose a parametric or a nonparametric model based on the past climatological information. Here, for simplicity, we assume a zero mean Gaussian representation with covariance (Burgers et al., 1998) to perturb the observation at each assimilation cycle. After each cycle, the probability histogram of the analysis state p(xa) is estimated using Eq. (7) over zij at M×N support points. Then p(xa) is resampled at M points using the multinomial sampling scheme (Li et al., 2015) to initialize the next time step forecast.
3.2 Entropic regularization of EnRDA
In order to speed up the computation of the coupling, the problem in Eq. (3) can be regularized as follows (Cuturi, 2013):
where γ>0 is the regularization parameter, and represents the Gibbs–Boltzmann relative entropy function. Note that the relative entropy is a concave function, and, thus its negative value is convex.
The Lagrangian function (ℒ) of Eq. (8) can be obtained by adding two dual variables or Lagrangian multipliers q∈ℝM and r∈ℝN as follows:
Setting the derivative of the Lagrangian function to zero, we have the following:
The entropic regularization keeps the problem in Eq. (8) strongly convex, and it can be shown (Peyré and Cuturi, 2019) that Eq. (10) leads to a unique optimal joint density with the following form:
where and are the unknown scaling variables and is the Gibbs kernel with elements , where cij are the elements of the cost matrix C.
From the mass conservation constraints in Eq. (8) and the scaling form of the optimal joint density in Eq. (11), we can derive the following:
The two unknown scaling variables v and w can then be iteratively solved using Sinkhorn's matrix scaling algorithm (Cuturi, 2013) as follows:
The Sinkhorn algorithm is initialized using w0=1N, and since the marginal densities and py are not zero vectors, the Hadamard division in Eq. (13) remains valid throughout the iterations. A summary of the EnRDA implementation is demonstrated in Algorithm 1.

The entropic regularization parameter plays an important role in the characterization of the joint density; however, there exists no closed-form solution for its optimal selection. Generally speaking, increasing the value of γ will increase the convexity of the cost function and, thus, computational efficiency; however, this comes at the expense of reduced coupling between the marginal histograms, which is consistent with the second law of thermodynamics.
As an example, the effects of γ on the coupling between two Gaussian mixture models and py are demonstrated in Fig. 3. It can be seen that, at smaller values of γ=0.001, the probability masses of the joint distribution are sparse and lie compactly along the main diagonal – capturing a strong coupling between the background state and observations. However, as the value of γ increases, the probability masses of the joint distribution spread out – reflecting less of a degree of dependency between the marginals. It is important to note that in limiting cases, such as γ→0, the solution of Eq. (8) converges to the true optimal joint histogram, while in cases such as γ→∞, the entropy of the analysis state increases and tends to . The regularization parameter is dependent on the elements of the transportation cost matrix C and varies according to the experimental settings. In practice, one can begin with the value of γ set as the largest element of the cost matrix C and gradually reduce it to find the minimum value of γ that provides a stable solution.
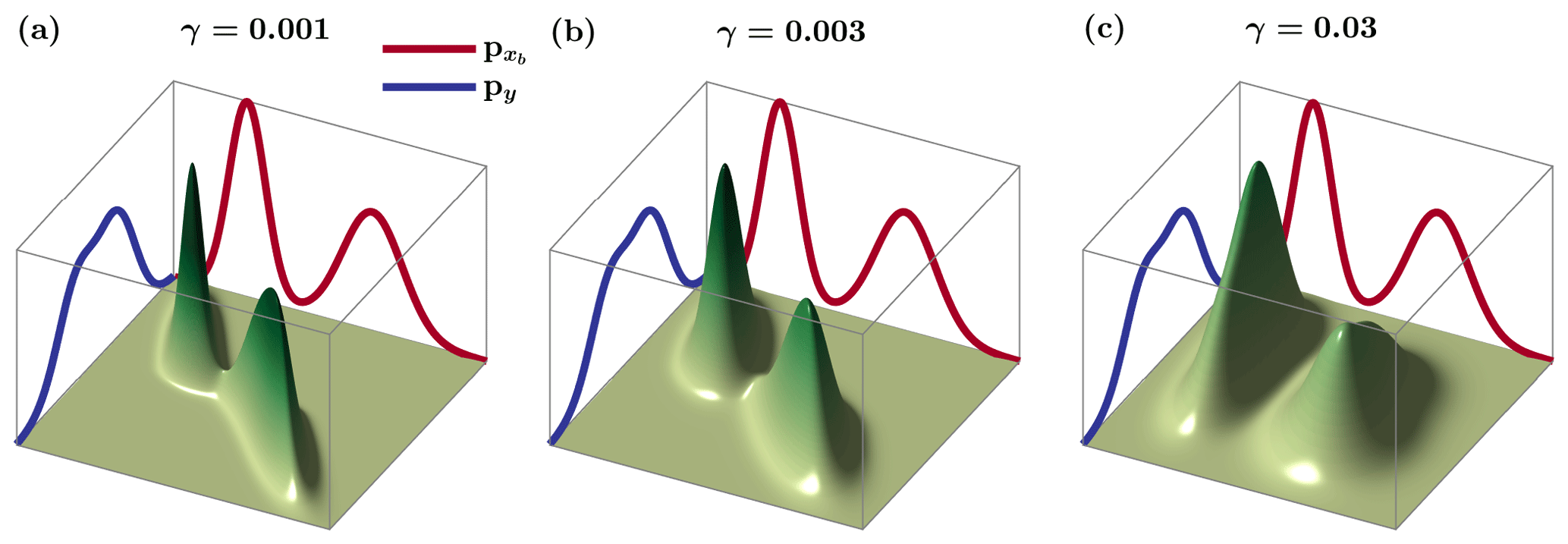
Figure 3The effect of the entropic regularization parameter γ on the optimal joint histogram coupling two Gaussian mixture models, where is and py is .
In order to demonstrate the performance of EnRDA and quantify its effectiveness, we focus on the linear advection–diffusion equation and the chaotic Lorenz-63 model (Lorenz, 1963). The advection–diffusion model explains a wide range of heat, mass, and momentum transport across the land, vegetation, and atmospheric continuum and has been utilized to evaluate the performance of DA methodologies (Zhang et al., 1997; Hurkmans et al., 2006; Ning et al., 2014; Ebtehaj et al., 2014; Berardi et al., 2016). Similarly, the Lorenz-63 model, as a chaotic model of atmospheric convection, has been widely used in testing the performance of DA methodologies (Miller et al., 1994; Nakano et al., 2007; Van Leeuwen, 2010; Goodliff et al., 2015; Tandeo et al., 2015; Tamang et al., 2020). Throughout, under controlled experimental settings with foreknown model and observation errors, we run the forward models under systematic errors and compare the results of EnRDA with a particle filter (PF) and an EnKF.
4.1 Advection–diffusion equation
4.1.1 State space Characterization
The advection–diffusion is a special case of the Navier–Stokes partial differential equation. In its linear form, with constant diffusivity in an incompressible fluid flow, it is expressed for a mass conserved physical quantity x(s,t) as follows:
where s∈ℝn represents a n-dimensional spatial domain at time t. In the above expression, is the advection velocity vector, and represents the diffusivity matrix. Given the initial condition , owing to its linearity, the solution at time t can be obtained by convolving the initial condition with a Kronecker delta function δ(s−a t) followed by a convolution with the fundamental Gaussian kernel , where Σ=2 D t.
4.1.2 Experimental setup and results
In this subsection, we first highlight the difference between Euclidean and Wasserstein barycenters using a 2-D advection–diffusion model and then compare the results of EnRDA with the PF and EnKF on a 1-D advection–diffusion equation.
Figure 4 shows the results of an assimilation experiment using the 2-D advection–diffusion equation where the underlying state is bimodal. This experiment is designed to demonstrate the differences between the Euclidean and Wasserstein barycenters in the presences of bias in a non-Gaussian state space. In particular, the state space is characterized over a spatial domain and with a discretization of . The advection–diffusion is considered to be an isotropic process with true model parameters set as (L/T), and (L2/T). The shown state variable is obtained after evolving two Kronecker delta functions and for T=0–25 and T=0–35 (T), respectively.

Figure 4The true state xtr, the background state xb, and observation y (a)–(c) with systematic errors under a 2-D advection–diffusion dynamics, as well as the Euclidean (d)–(f) and the Wasserstein barycenters (g)–(i), between xb and y for different displacement parameters η. The entropic regularization parameter is set to γ=0.003, and the black plus signs show the location of the modes for the true state.
To resemble a model with systematic errors, background state is obtained by increasing the advective velocity to 0.12 (L/T) while diffusivity is reduced to 0.01 (L2/T; Fig. 4b). Observations are not considered to have position biases; however, a systematic representative error is imposed, assuming that the sensing system has a lower resolution than the model. To that end, we evolve two Kronecker delta functions, and , with a mass less than the true state for same time period of T=0–25 and T=0–35 (T) and then upscale the field by a factor of 2 through box averaging (Fig. 4c).
As shown in Fig. 4g–i, the Wasserstein barycenter preserves the shape of the state variable well and gradually moves the mass towards the background state as the value of η increases, while the bias remains almost constant, and the unbiased root mean squared error (ubrmse) increases from 0.12 to 0.95. The error quality metrics are constantly below the Euclidean counterpart. As shown in Fig. 4d–f, the shape of the Euclidean barycenter for smaller values of η is not well recovered due to the position error. As η increases from 0.25 to 0.75, the Euclidean barycenter is nudged towards the background state and begins to recover the shape. The bias is reduced by more than 30 %, from 0.15 to 0.05; however, this occurs at the expense of an almost threefold increase in ubrmse, from 0.3 to 1.1. The reason for the reduction in the bias is that the positive differences between the Euclidean barycenter and the true state are compensated by their negative differences. However, ubrmse is quadratic and, thus, measures the average magnitude of the error irrespective of its signs.
For the 1-D case, the state space is characterized over a spatial domain with a discretization of Δs=0.1. The model parameters are chosen to be a=0.8 (L/T) and D=0.25 (L2/T). The initial state resembles a bimodal mixture of Gaussian distributions obtained by superposition of two Kronecker delta functions – evolved for time 15 and 25 (T), respectively. The ground truth of the trajectory is then obtained by evolving the initial state at a time step of Δt=0.5 over a window of T=0–30 (T) in the absence of any model error.
The observations are obtained at assimilation intervals 10Δt, assuming an identity observation operator, through corrupting the ground truth by a heteroscedastic Gaussian noise with a variance ϵy=5 % of the squared values of the ground truth state. We introduce both systematic and random errors in the model simulations. For the systematic error, model velocity and diffusivity coefficient are set to (L/T) and (L2/T), respectively. To impose the random error, a heteroscedastic Gaussian noise with variance ϵb=2 % is added at every Δt to model simulations. In total, 100 ensemble members are used in EnRDA, and the regularization and displacement parameters are set to γ=3 and η=0.2 through the previously outlined trial and error procedures. To obtain a robust comparison of EnRDA with PF and EnKF, each with 100 particles (ensemble members), the experiment is repeated for 50 independent simulations.
The evolution of the initial state over a time period T=0–30 (T) and the results comparing EnRDA with PF and EnKF at 5, 15, and 25 (T) are shown in Fig. 5. As demonstrated, during all time steps, EnRDA reduces the analysis uncertainty in terms of both bias and ubrmse. The shape of the entire state space is also properly preserved and remains closer to the ground truth. The EnKF performance is comparable to EnRDA during the initial time steps; however, the performance degrades and the error statistics gradually increases as the system evolves over time. Among the two traditional ensemble-based methodologies, the PF acquires the highest error statistics owing to the well-known problem of filter degeneracy (Poterjoy and Anderson, 2016), which is exacerbated by the presence of systematic errors.

Figure 5(a) Temporal evolution of a bimodal initial state under a linear 1-D advection–diffusion equation (b)–(d) by the particle filter (PF), ensemble Kalman filter (EnKF), and ensemble Riemannian data assimilation for three time snapshots at 5, 15, and 25 (T). The bias and ubrmse of the analysis states are also reported in the legends.
We should emphasize that the presented results do not imply that EnRDA always performs better than PF and EnKF. The EnKF at the limiting case M→∞, in the absence of bias, is a minimum mean squared error estimator and attains the lowest possible posterior variance for linear systems, also referred to as the Cramér–Rao lower bound (Cramér, 1999; Rao et al., 1973). Thus, when the errors are drawn from zero mean Gaussian distributions with a linear observation operator, EnKF can outperform EnRDA in terms of the mean squared error.
4.2 Lorenz-63
4.2.1 State space characterization
The Lorenz system (Lorenz-63; Lorenz, 1963) is derived through the truncation of the Fourier series of the Rayleigh–Bénard convection model. This model can be interpreted as a simplistic local weather system only involving the effect of local shear stress and buoyancy forces. In the following, the system is expressed using coupled ordinary differential equations that describe the temporal evolution of three coordinates x, y, and z representing the rate of convective overturn, horizontal, and vertical temperature variations:
where σ represents the Prandtl number, ρ is a normalized Rayleigh number proportional to the difference in temperature gradient through the depth of the fluid, and β denotes a horizontal wave number of the convective motion. It is well established that, for parameter values of σ=10, ρ=28, and , the system exhibits chaotic behavior, with the phase space revolving around two unstable stationary points located at () and ().
4.2.2 Experimental setup and results
Throughout the paper, we use the classic multinomial resampling for implementation of EnRDA and particle filter. Apart from the systematic error component, we utilize the standard experimental setting used in numerous DA studies (Miller et al., 1994; Furtado et al., 2008; Van Leeuwen, 2010; Amezcua et al., 2014). In order to obtain the ground truth of the model trajectory, the system is initialized at x0=(1.508870, −1.531271, and 25.46091) and integrated with a time step of Δt=0.01 over a time period of T=0–20 (T) using the fourth-order Runge–Kutta approximation (Runge, 1895; Kutta, 1901). The observations are obtained at every assimilation interval 40Δt by assuming identity observation operator and perturbing the ground truth with Gaussian noise , where and the correlation matrix is populated with 1 on the diagonal entries, 0.5 on the first sub- and super-diagonals, and 0.25 on the second sub- and super-diagonals.
In order to characterize the distribution of the background state, 100 particles (ensemble members) are used, among all DA methods, by adding to the ground truth a zero mean Gaussian noise , with at the initial time. To introduce systematic errors, the model parameters are set to , , and . The random errors are also introduced in time by adding a Gaussian noise at every Δt, with . Throughout the paper, to draw a robust statistical inference about the error statistics, the DA experiments are repeated for 50 independent simulations. As described previously, to properly account for the effects of both bias and ubrmse, the optimal value of the displacement parameter η in EnRDA can be selected based on an offline analysis of the minimum mean squared error. However, to provide a fair comparison between EnRDA and other filtering methods, at each assimilation cycle, we set when the observation operator is an identity matrix. Note that, while the observation error covariance remains constant in time, the background error covariance is obtained from simulated ensembles and changes in time dynamically. This selection assures that the relative weights assigned to the background state and observations remain at the same order of magnitude among different methods.
Figure 6 shows the temporal evolution of the ground truth and the analysis state by the PF (first column), EnKF (second column), and EnRDA (third column) over a time period of T=0–15 (T). As is evident, the PF is well capable of capturing the ground truth when observations lie within the particle spread. However, when the observations lie far apart from the support set of particles (Fig. 6; dashed box), and the distribution of the background state and observations become disjoint, the filter becomes degenerate, and the analysis state (particle mean) deviates from the ground truth (Fig. 6g; dashed box). As a result, the bias of PF along the z dimension is markedly lower than that of the EnKF and EnRDA, while ubrmse is significantly higher, whereas EnRDA is capable of capturing the true state well – even when ensemble spread and observations are far apart from each other. Although EnKF does not suffer from the same problem of filter degeneracy as the particle filter, in earlier time steps from 2.5 to 7.5 (T), it struggles to adequately nudge the analysis state towards the ground truth when ensemble members are far from the observations due to the imposed systematic bias. EnRDA seems to be robust to the propagation of systematic errors in this region and follows the true trajectory well.
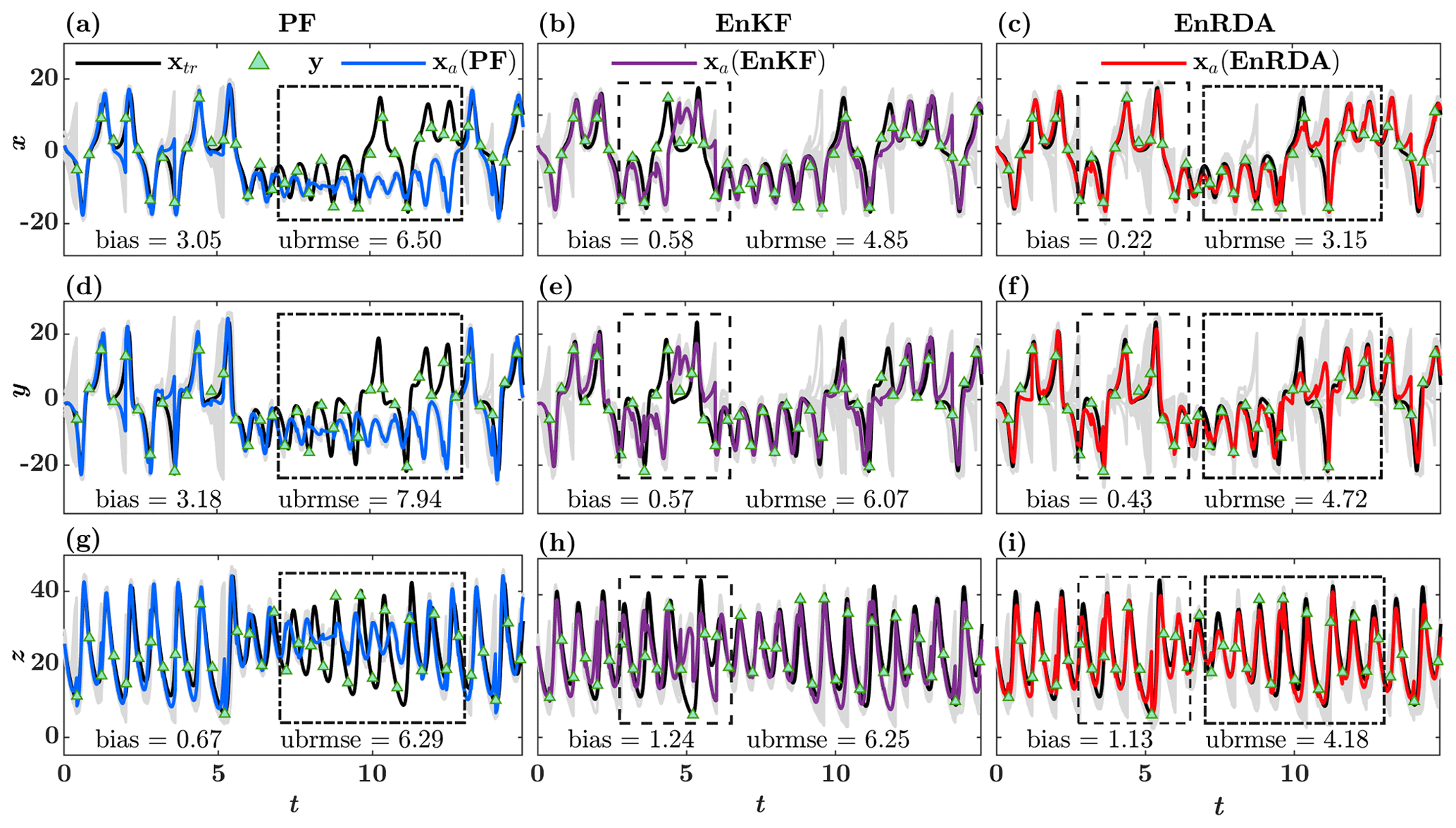
Figure 6Temporal evolution of the true state xtr in Lorenz-63, observations y, and the analysis state xa for the particle filter (PF) (a, d, g), ensemble Kalman filter (EnKF) (b, e, h), and ensemble Riemannian data assimilation (EnRDA) (c, f, i), with 100 particles (ensemble members). The temporal evolution of the particles and ensemble members are shown with solid gray lines. Also shown within dashed boxes are the windows of time over which the DA methods exhibit large errors.
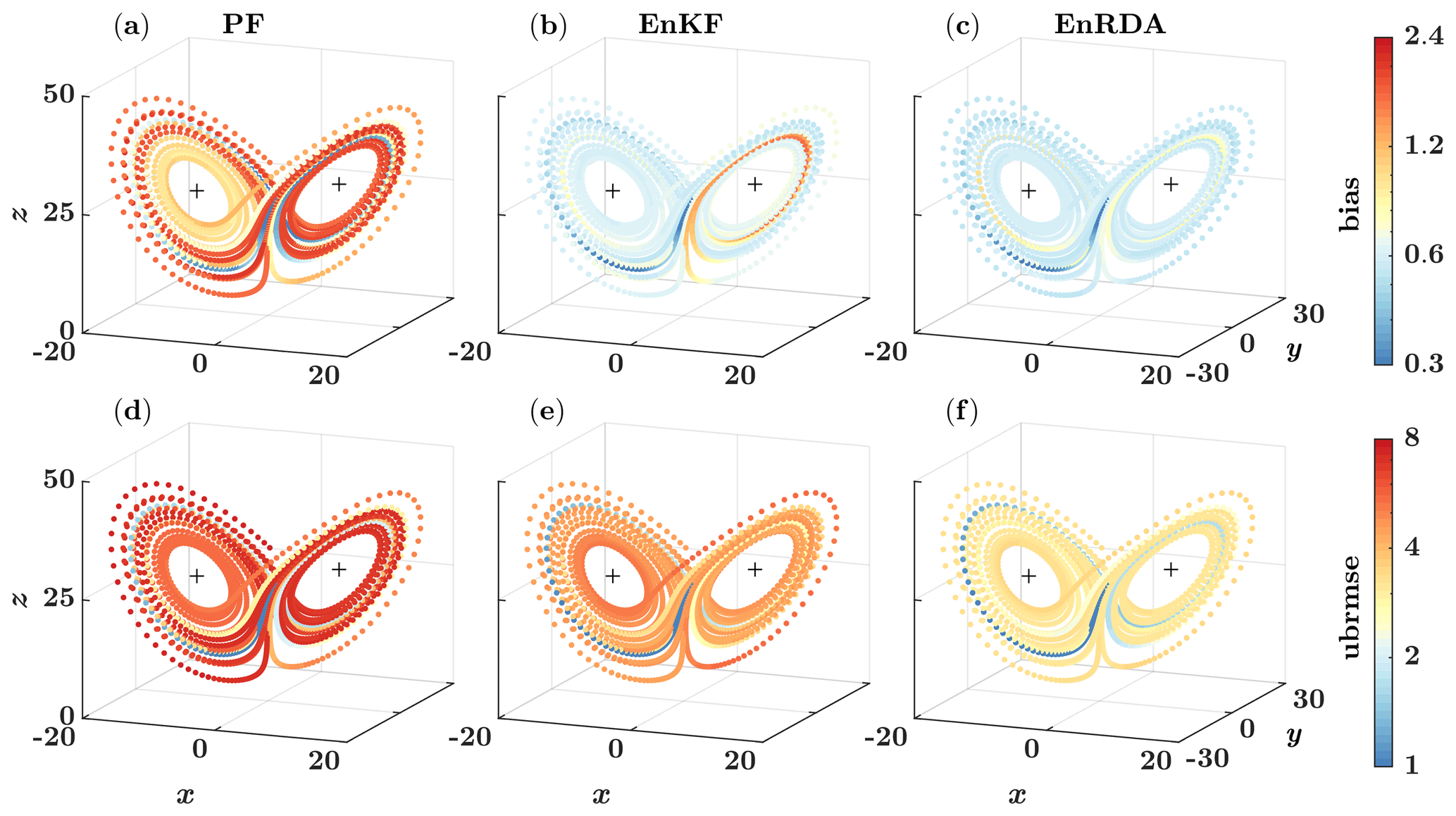
Figure 7Temporal evolution of bias and ubrmse along three dimensions of the Lorenz-63 for the (a, d) particle filter (PF), (b, e) ensemble Kalman filter (EnKF), and (c, f) ensemble Riemannian data assimilation (EnRDA), each with 100 particles (ensemble members). The mean values are computed over 50 independent simulations.
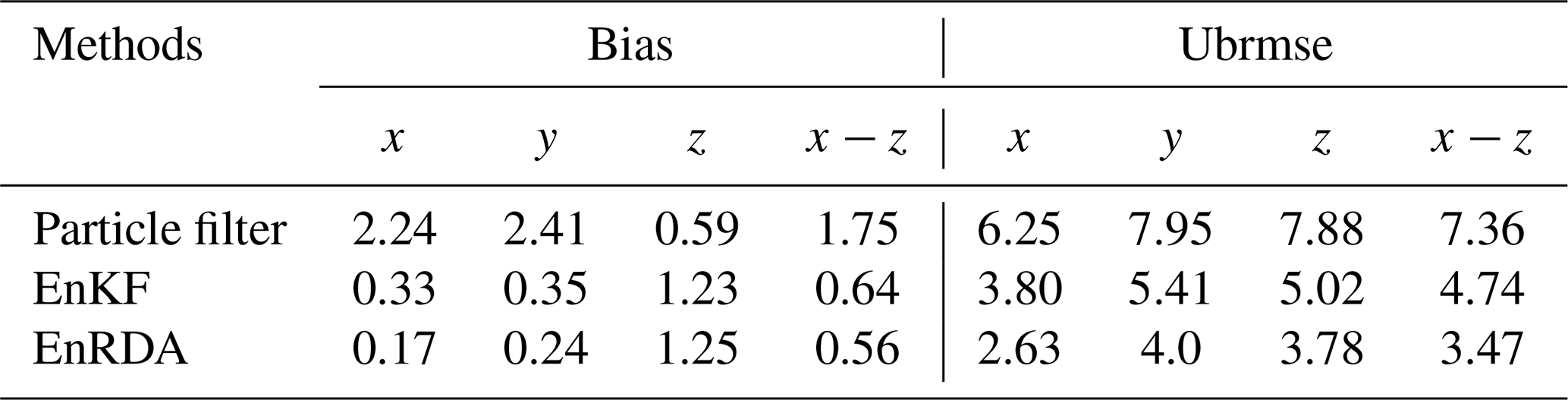
The time evolution of the bias and ubrmse for 50 independent simulations, with the same error structure, is color-coded over the phase space in Fig. 7. As shown, the error quality metrics are relatively lower for EnRDA than other DA methodologies. Nevertheless, we can see that the improvement compared to EnKF is modest. In particular, across all dimensions of the problem, the mean bias and ubrmse decreased in EnRDA by 68 (13) % and 53 (27) % compared to the particle filter (EnKF). More details about the expected values of the bias and ubrmse are reported in Table 1. We emphasize that the presented results shall be interpreted in light of the presence of systematic errors. In fact, EnRDA cannot reduce the analysis error variance beyond a minimum mean squared estimator such as EnKF in the absence of bias.
Table 1Expected values of the bias and ubrmse for the particle filter (PF), ensemble Kalman filter (EnKF), and ensemble Riemannian data assimilation (EnRDA) for 50 independent simulations of Lorenz-63 across all problem dimensions.
In this study, we introduced an ensemble data assimilation (DA) methodology over a Riemannian manifold, namely ensemble Riemannian DA (EnRDA), and illustrated its performance in comparison with other ensemble-based DA techniques for dissipative and chaotic dynamics. We demonstrated that the presented methodology is capable of assimilating information in the probability domain, which is characterized by the families of distributions with finite second-order moments. The key message is that when the probability distribution of the forecast and observations exhibit a non-Gaussian structure, and their support sets are disjoint due to the presence of systematic errors; the Wasserstein metric can be leveraged to potentially extend the geophysical forecast skills. However, future research for a comprehensive comparison with existing filtering and bias correction methodologies is needed to completely characterize relative pros and cons of the proposed approach, especially when it comes to the ensemble size and optimal selection of the displacement parameter η.
We explained the role of the static regularization and displacement parameter in EnRDA and empirically examined their effects on the optimal joint histogram, coupling the background state and observations, and, consequently, on the analysis state. Nevertheless, future studies are required to characterize closed-form or heuristic expressions to expand our understating of their impacts on the forecast uncertainty dynamically. As was explained earlier, unlike the Euclidean DA methodologies that assimilate available information using different relative weights across multiple dimensions through the error covariance matrices, a scalar displacement parameter is utilized in EnRDA that interpolates uniformly between all dimensions of the problem. Future research can be devoted to developing a framework that utilizes a dynamic vector representation of the displacement parameters to effectively tackle possible the heterogeneity of uncertainty across multiple dimensions.
In its current form, EnRDA requires the observation operator to be smooth and bijective. This is a limitation when observations of all problem dimensions are not available and the propagation of observations to non-observed dimensions is desired. Extending the EnRDA methodology to include partially observed systems seems to be an important future research area. This could include performing a rough inversion for unobserved components of the system offline or extending the methodology in the direction of particle flows (Van Leeuwen et al., 2019). Another promising area is to use EnRDA only over the observed dimensions of the state space and, similar to the EnKF, use the ensemble covariance to update the unobserved part of state space through a hybrid approach. Furthermore, it is important to note that several bias correction methodologies are available that explicitly add a bias term to the control vector in variational and filtering DA techniques (Dee, 2003; Reichle and Koster, 2004; De Lannoy et al., 2007b). Future research is required to compare the performance of EnRDA with other bias correction methodologies to fully characterize its relative advantages and disadvantages.
We should mention that EnRDA is computationally expensive as it involves the estimation of the coupling through the Wasserstein distance. On a desktop machine with a 3.4 GHz CPU clock rate, it took around 1600 s to complete 50 independent simulations on Lorenz-63 for EnRDA compared to 651 (590) s for the PF (EnKF) with 100 particles (ensemble members). Since the computational cost is nonlinearly related to the problem dimension, it is expected that it grows significantly for large-scale geophysical DA and becomes a limiting factor. Furthermore, in high-dimensional geophysical problems, the computational cost of determining optimal displacement parameter η through cross-validation can be high. Although the entropic regularization works well for the presented low-dimensional problems, future research is needed to test its efficiency in high-dimensional problems. Constraining the solution of the coupling on a submanifold of probability distributions with a Gaussian mixture structure (Y. Chen et al., 2019) can also be a future research direction for lowering the computational cost. Furthermore, recent advances in approximation of the Wasserstein distance, using a combination of 1-D Radon projections and dimensionality reduction (Meng et al., 2019), can significantly reduce the computational cost to make EnRDA a viable methodology for tackling high-dimensional geophysical DA problems.
Finally, in the presented formalism, we define the analysis state distribution through an optimal coupling between forecast and observation distributions. Future lines of research can be devoted to coupling the forecast distribution with a normalized version of the likelihood function towards establishing connections with Bayesian data assimilation.
A demo code for EnRDA in the MATLAB programming language can be downloaded at https://github.com/tamangsk/EnRDA (https://doi.org/10.5281/zenodo.5047392; Tamang, 2021).
No data sets were used in this article.
SKT and AE designed the study. SKT implemented the formulation and analyzed the results. PJvL and GL provided conceptual advice, and all authors contributed to the writing.
The authors declare that they have no conflict of interest.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research has been supported by the National Aeronautics and Space Administration (Terrestrial Hydrology Program – THP; grant no. 80NSSC18K1528), the New (Early Career) Investigator Program (NIP; grant no. 80NSSC18K0742), the European Research Council, H2020 European Research Council (CUNDA (grant no. 694509)), and the National Science Foundation (grant no. DMS1830418).
This paper was edited by Alberto Carrassi and reviewed by two anonymous referees.
Agueh, M. and Carlier, G.: Barycenters in the Wasserstein space, SIAM J. Math. Anal., 43, 904–924, 2011. a
Altman, A. and Gondzio, J.: Regularized symmetric indefinite systems in interior point methods for linear and quadratic optimization, Optim. Method. Softw., 11, 275–302, 1999. a
Amari, S.: Differential-geometrical methods in statistics, vol. 28, Springer Science & Business Media, New York, NY, 2012. a, b
Amezcua, J., Ide, K., Kalnay, E., and Reich, S.: Ensemble transform Kalman–Bucy filters, Q. J. Roy. Meteor. Soc., 140, 995–1004, 2014. a
Anderson, J. L.: A method for producing and evaluating probabilistic forecasts from ensemble model integrations, J. Climate, 9, 1518–1530, 1996. a
Anderson, J. L.: A non-Gaussian ensemble filter update for data assimilation, Mon. Weather Rev., 138, 4186–4198, 2010. a, b
Beezley, J. D. and Mandel, J.: Morphing ensemble Kalman filters, Tellus A, 60, 131–140, 2008. a
Benamou, J.-D. and Brenier, Y.: A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem, Numer. Math., 84, 375–393, 2000. a
Berardi, M., Andrisani, A., Lopez, L., and Vurro, M.: A new data assimilation technique based on ensemble Kalman filter and Brownian bridges: an application to Richards’ equation, Comput. Phys. Commun., 208, 43–53, 2016. a
Bocquet, M., Pires, C. A., and Wu, L.: Beyond Gaussian statistical modeling in geophysical data assimilation, Mon. Weather Rev., 138, 2997–3023, 2010. a
Brenier, Y.: Décomposition polaire et réarrangement monotone des champs de vecteurs, CR Acad. Sci. Paris Sér. I Math., 305, 805–808, 1987. a
Burgers, G., Jan van Leeuwen, P., and Evensen, G.: Analysis scheme in the ensemble Kalman filter, Mon. Weather Rev., 126, 1719–1724, 1998. a
Carrassi, A. and Vannitsem, S.: Accounting for model error in variational data assimilation: A deterministic formulation, Mon. Weather Rev., 138, 3369–3386, 2010. a
Carrassi, A., Bocquet, M., Bertino, L., and Evensen, G.: Data assimilation in the geosciences: An overview of methods, issues, and perspectives, WIRES Clim. Change, 9, e535, https://doi.org/10.1002/wcc.535, 2018. a
Chen, B., Dang, L., Gu, Y., Zheng, N., and Principe, J. C.: Minimum Error Entropy Kalman Filter, IEEE Trans. Syst. Man Cybern. Syst., https://doi.org/10.1109/tsmc.2019.2957269, 2019. a
Chen, Y., Georgiou, T. T., and Tannenbaum, A.: Optimal transport for Gaussian mixture models, IEEE Access, 7, 6269–6278, 2019. a, b
Cramér, H.: Mathematical methods of statistics, vol. 9, Princeton University Press, Princeton, NJ, 1999. a
Cuturi, M.: Sinkhorn distances: Lightspeed computation of optimal transport, in: Advances in neural information processing systems, edited by: Burges, C. J. C., Bottou, L., Welling, M., Ghahramani, Z., and Weinberger, K. Q., Curran Associates, Inc., pp. 2292–2300, available at: https://proceedings.neurips.cc/paper/2013/file/af21d0c97db2e27e13572cbf59eb343d-Paper.pdf (last access: 1 May 2020), 2013. a, b
Dee, D. P.: Detection and correction of model bias during data assimilation, Meteorological Training Course Lecture Series, ECMWF, Reading, United Kingdom, 2003. a, b
Dee, D. P.: Bias and data assimilation, Q. J. Roy. Meteor. Soc., 131, 3323–3343, 2005. a
De Lannoy, G. J., Houser, P. R., Pauwels, V. R., and Verhoest, N. E.: State and bias estimation for soil moisture profiles by an ensemble Kalman filter: Effect of assimilation depth and frequency, Water Resour. Res., 43, W06401, https://doi.org/10.1029/2006WR005100, 2007a. a
De Lannoy, G. J., Reichle, R. H., Houser, P. R., Pauwels, V., and Verhoest, N. E.: Correcting for forecast bias in soil moisture assimilation with the ensemble Kalman filter, Water Resour. Res., 43, W09410, https://doi.org/10.1029/2006WR005449, 2007b. a, b
Doucet, A. and Johansen, A. M.: A tutorial on particle filtering and smoothing: Fifteen years later, Handbook of nonlinear filtering, 12, Oxford University Press, Oxford, 656–704, 2009. a
Drécourt, J.-P., Madsen, H., and Rosbjerg, D.: Bias aware Kalman filters: Comparison and improvements, Adv. Water Resour., 29, 707–718, 2006. a
Ebtehaj, A. M. and Foufoula-Georgiou, E.: On variational downscaling, fusion, and assimilation of hydrometeorological states: A unified framework via regularization, Water Resour. Res., 49, 5944–5963, 2013. a
Ebtehaj, A. M., Zupanski, M., Lerman, G., and Foufoula-Georgiou, E.: Variational data assimilation via sparse regularisation, Tellus A, 66, 21789 pp., https://doi.org/10.3402/tellusa.v66.21789, 2014. a, b
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res.-Oceans, 99, 10143–10162, 1994. a, b
Evensen, G.: The ensemble Kalman filter: Theoretical formulation and practical implementation, Ocean Dynam., 53, 343–367, 2003. a
Feyeux, N., Vidard, A., and Nodet, M.: Optimal transport for variational data assimilation, Nonlin. Processes Geophys., 25, 55–66, https://doi.org/10.5194/npg-25-55-2018, 2018. a, b
Fréchet, M.: Les éléments aléatoires de nature quelconque dans un espace distancié, Ann. I. H. Poincare, 10, 215–310, 1948. a
Furtado, H. C. M., de Campos Velho, H. F., and Macau, E. E. N.: Data assimilation: Particle filter and artificial neural networks, in: J. Phys. Conf. Ser., 135, 012073, https://doi.org/10.1088/1742-6596/135/1/012073, 2008. a
Goodliff, M., Amezcua, J., and Van Leeuwen, P. J.: Comparing hybrid data assimilation methods on the Lorenz 1963 model with increasing non-linearity, Tellus A, 67, 26928 pp., https://doi.org/10.3402/tellusa.v67.26928, 2015. a
Gordon, N. J., Salmond, D. J., and Smith, A. F.: Novel approach to nonlinear/non-Gaussian Bayesian state estimation, in: IEE Proc.-F, 140, 107–113, 1993. a
Hamill, T. M.: Interpretation of rank histograms for verifying ensemble forecasts, Mon. Weather Rev., 129, 550–560, 2001. a
Han, X. and Li, X.: An evaluation of the nonlinear/non-Gaussian filters for the sequential data assimilation, Remote Sens. Environ., 112, 1434–1449, 2008. a
Hellinger, E.: Neue begründung der theorie quadratischer formen von unendlichvielen veränderlichen, J. Reine Angew. Math., 1909, 210–271, 1909. a
Hurkmans, R., Paniconi, C., and Troch, P. A.: Numerical assessment of a dynamical relaxation data assimilation scheme for a catchment hydrological model, Hydrol. Process., 20, 549–563, 2006. a
Jordan, R., Kinderlehrer, D., and Otto, F.: The variational formulation of the Fokker-Planck equation, SIAM J. Math. Anal., 29, 1–17, https://doi.org/10.1137/S0036141096303359, 1998. a
Kalman, R. E.: A new approach to linear filtering and prediction problems, J. Basic Eng., 82, 35–45, 1960. a
Kalnay, E.: Atmospheric modeling, data assimilation and predictability, Cambridge University Press, Cambridge, UK, 2003. a
Kantorovich, L. V.: On the translocation of masses, Dokl. Akad. Nauk. USSR (NS), 37, 199–201, 1942. a
Kim, S., Eyink, G. L., Restrepo, J. M., Alexander, F. J., and Johnson, G.: Ensemble filtering for nonlinear dynamics, Mon. Weather Rev., 131, 2586–2594, 2003. a
Kollat, J., Reed, P., and Rizzo, D.: Addressing model bias and uncertainty in three dimensional groundwater transport forecasts for a physical aquifer experiment, Geophys. Res. Lett., 35, L17402, https://doi.org/10.1029/2008GL035021, 2008. a
Kullback, S. and Leibler, R. A.: On information and sufficiency, Ann. Math. Stat., 22, 79–86, 1951. a
Kutta, W.: Beitrag zur naherungsweisen Integration totaler Differentialgleichungen, Z. Math. Phys., 46, 435–453, 1901. a
Lauritzen, S. L.: Statistical manifolds, Differential Geometry in Statistical Inference, 10, 163–216, 1987. a
Le Dimet, F.-X. and Talagrand, O.: Variational algorithms for analysis and assimilation of meteorological observations: theoretical aspects, Tellus A, 38, 97–110, 1986. a
Li, H., Kalnay, E., and Miyoshi, T.: Simultaneous estimation of covariance inflation and observation errors within an ensemble Kalman filter, Q. J. Roy. Meteor. Soc., 135, 523–533, 2009. a
Li, T., Bolic, M., and Djuric, P. M.: Resampling methods for particle filtering: classification, implementation, and strategies, IEEE Signal Proc. Mag., 32, 70–86, 2015. a
Lorenc, A. C.: Analysis methods for numerical weather prediction, Q. J. Roy. Meteor. Soc., 112, 1177–1194, 1986. a, b
Lorenz, E. N.: Deterministic nonperiodic flow, J. Atmos. Sci., 20, 130–141, 1963. a, b
Mandel, J. and Beezley, J. D.: An ensemble Kalman-particle predictor-corrector filter for non-Gaussian data assimilation, in: International Conference on Computational Science, Springer, Berlin, Heidelberg, pp. 470–478, 2009. a, b
McCann, R. J.: A convexity principle for interacting gases, Adv. Math., 128, 153–179, 1997. a
Meng, C., Ke, Y., Zhang, J., Zhang, M., Zhong, W., and Ma, P.: Large-scale optimal transport map estimation using projection pursuit, in: Advances in Neural Information Processing Systems, edited by: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R., vol. 32, Curran Associates, Inc., available at: https://proceedings.neurips.cc/paper/2019/file/4bbbe6cb5982b9110413c40f3cce680b-Paper.pdf (last access: 1 August 2020), 2019. a
Miller, R. N., Ghil, M., and Gauthiez, F.: Advanced data assimilation in strongly nonlinear dynamical systems, J. Atmos. Sci., 51, 1037–1056, 1994. a, b
Monge, G.: Mémoire sur la théorie des déblais et des remblais, Histoire de l'Académie Royale des Sciences de Paris, pp. 666–704, 1781. a
Moradkhani, H., Sorooshian, S., Gupta, H. V., and Houser, P. R.: Dual state–parameter estimation of hydrological models using ensemble Kalman filter, Adv. Water Resour., 28, 135–147, 2005. a
Nakano, S., Ueno, G., and Higuchi, T.: Merging particle filter for sequential data assimilation, Nonlin. Processes Geophys., 14, 395–408, https://doi.org/10.5194/npg-14-395-2007, 2007. a
Ning, L., Carli, F. P., Ebtehaj, A. M., Foufoula-Georgiou, E., and Georgiou, T. T.: Coping with model error in variational data assimilation using optimal mass transport, Water Resour. Res., 50, 5817–5830, 2014. a, b, c
Orlin, J. B.: A faster strongly polynomial minimum cost flow algorithm, Oper. Res., 41, 338–350, 1993. a
Otto, F.: The geometry of dissipative evolution equations: The porous medium equation, Commun. Part. Diff. Eq., 26, 101–174, https://doi.org/10.1081/PDE-100002243, 2001. a
Park, S. K. and Županski, D.: Four-dimensional variational data assimilation for mesoscale and storm-scale applications, Meteorol. Atmos. Phys., 82, 173–208, 2003. a
Pennec, X.: Intrinsic statistics on Riemannian manifolds: Basic tools for geometric measurements, J. Math. Imaging Vis., 25, 127, https://doi.org/10.1007/s10851-006-6228-4, 2006. a
Peyré, G. and Cuturi, M.: Computational optimal transport, Foundations and Trends® in Machine Learning, 11, 355–607, 2019. a, b, c, d
Pires, C., Vautard, R., and Talagrand, O.: On extending the limits of variational assimilation in nonlinear chaotic systems, Tellus A, 48, 96–121, 1996. a, b
Pires, C. A., Talagrand, O., and Bocquet, M.: Diagnosis and impacts of non-Gaussianity of innovations in data assimilation, Physica D, 239, 1701–1717, 2010. a
Poterjoy, J. and Anderson, J. L.: Efficient assimilation of simulated observations in a high-dimensional geophysical system using a localized particle filter, Mon. Weather Rev., 144, 2007–2020, 2016. a, b, c
Rao, C. R., Rao, C. R., Statistiker, M., Rao, C. R., and Rao, C. R.: Linear statistical inference and its applications, vol. 2, Wiley New York, New York, NY, 1973. a
Ravela, S., Emanuel, K., and McLaughlin, D.: Data assimilation by field alignment, Physica D, 230, 127–145, 2007. a
Reich, S.: A nonparametric ensemble transform method for Bayesian inference, SIAM J. Sci. Comput., 35, A2013–A2024, 2013. a
Reichle, R. H. and Koster, R. D.: Bias reduction in short records of satellite soil moisture, Geophys. Res. Lett., 31, L19501, https://doi.org/10.1029/2004GL020938, 2004. a, b
Reichle, R. H., McLaughlin, D. B., and Entekhabi, D.: Hydrologic data assimilation with the ensemble Kalman filter, Mon. Weather Rev., 130, 103–114, 2002. a
Runge, C.: Über die numerische Auflösung von Differentialgleichungen, Math. Ann., 46, 167–178, 1895. a
Spiller, E. T., Budhiraja, A., Ide, K., and Jones, C. K.: Modified particle filter methods for assimilating Lagrangian data into a point-vortex model, Physica D, 237, 1498–1506, 2008. a
Talagrand, O. and Courtier, P.: Variational assimilation of meteorological observations with the adjoint vorticity equation. I: Theory, Q. J. Roy. Meteor. Soc., 113, 1311–1328, 1987. a
Tamang, S. K.: tamangsk/EnRDA: Ensemble Riemannian Data Assimilation (Version v1.0), Zenodo [data set], https://doi.org/10.5281/zenodo.5047392, 2021. a
Tamang, S. K., Ebtehaj, A., Zou, D., and Lerman, G.: Regularized Variational Data Assimilation for Bias Treatment using the Wasserstein Metric, Q. J. Roy. Meteor. Soc., 146, 2332–2346, 2020. a, b
Tandeo, P., Ailliot, P., Ruiz, J., Hannart, A., Chapron, B., Cuzol, A., Monbet, V., Easton, R., and Fablet, R.: Combining analog method and ensemble data assimilation: application to the Lorenz-63 chaotic system, in: Machine learning and data mining approaches to climate science, Springer, Cham, Switzerland, pp. 3–12, 2015. a
Tarantola, A.: Inverse problem theory and methods for model parameter estimation, vol. 89, SIAM, Philadelphia, PA, 2005. a
Trevisan, A., D'Isidoro, M., and Talagrand, O.: Four-dimensional variational assimilation in the unstable subspace and the optimal subspace dimension, Q. J. Roy. Meteor. Soc., 136, 487–496, 2010. a
Tsuyuki, T. and Miyoshi, T.: Recent progress of data assimilation methods in meteorology, J. Meteorol. Soc. Jpn. Ser. II, 85, 331–361, 2007. a
Van Leeuwen, P. J.: Nonlinear data assimilation in geosciences: an extremely efficient particle filter, Q. J. Roy. Meteor. Soc., 136, 1991–1999, 2010. a, b, c
Van Leeuwen, P. J., Künsch, H. R., Nerger, L., Potthast, R., and Reich, S.: Particle filters for high-dimensional geoscience applications: A review, Q. J. Roy. Meteor. Soc., 145, 2335–2365, 2019. a, b
Villani, C.: Topics in optimal transportation, 58, American Mathematical Soc., Providence, RI, https://doi.org/10.1090/gsm/058, 2003. a, b
Walker, J. P., Willgoose, G. R., and Kalma, J. D.: One-dimensional soil moisture profile retrieval by assimilation of near-surface measurements: A simplified soil moisture model and field application, J. Hydrometeorol., 2, 356–373, 2001. a
Woodbury, M. A.: Inverting modified matrices, Statistical Research Group, Princeton, NJ, Memo. Rep., 42, 1950. a
Zhang, X., Heemink, A., and Van Eijkeren, J.: Data assimilation in transport models, Appl. Math. Model., 21, 2–14, 1997. a