the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Mar 2018
| 01 Mar 2018
Accelerating assimilation development for new observing systems using EFSO
Daisuke Hotta
Eugenia Kalnay
Takemasa Miyoshi
Tse-Chun Chen
To successfully assimilate data from a new observing system, it is necessary to develop appropriate data selection strategies, assimilating only the generally useful data. This development work is usually done by trial and error using observing system experiments (OSEs), which are very time and resource consuming. This study proposes a new, efficient methodology to accelerate the development using ensemble forecast sensitivity to observations (EFSO). First, non-cycled assimilation of the new observation data is conducted to compute EFSO diagnostics for each observation within a large sample. Second, the average EFSO conditionally sampled in terms of various factors is computed. Third, potential data selection criteria are designed based on the non-cycled EFSO statistics, and tested in cycled OSEs to verify the actual assimilation impact. The usefulness of this method is demonstrated with the assimilation of satellite precipitation data. It is shown that the EFSO-based method can efficiently suggest data selection criteria that significantly improve the assimilation results.
- Article
(4231 KB) - Full-text XML
-
Supplement
(468 KB) - BibTeX
- EndNote





Improvements in numerical weather prediction (NWP) depend fundamentally on the efficient assimilation of available observations. Technological advances in remote sensing have introduced a growing number of new observing systems. However, in most cases, assimilation of a new observing system is a difficult task: naively assimilating every observation usually degrades the forecasts. It is necessary to implement an appropriate data selection process, such as selection based on channels, locations, data quality flags, and background conditions, to assimilate mostly useful data that improve model forecasts. Sometimes this data selection process is called, or overlapped with the process of, quality control (QC). However, the “intrinsic” quality of the observational data is usually not the only reason for their “usefulness” in data assimilation (DA). Therefore, in this article, we use a more general term “data selection criteria” to refer to all data selection processes prior to the assimilation of a data set.
A common approach to test the impact of assimilating a new set of observations is to perform observing system experiments (OSEs), which compare two otherwise identical experiments, one which includes the assimilation of the new observing system (denoted TEST) and the other which does not (denoted CONTROL). This approach has a serious shortcoming: the signal from new observations in TEST is obscured by the presence of the many observations that are already assimilated in CONTROL, making it difficult to discern the impact of the newly assimilated observations. As a result, in order to detect statistically significant signals, it is usually required to conduct experiments over a long period of time (Geer, 2016). This makes any trial-and-error tuning of the data selection criteria by OSEs computationally very expensive and slow. Methods to accelerate this assimilation development processes are thus needed.
Forecast sensitivity to observations (FSO) is a diagnostic technique that allows for estimating how much each individual observation improved or degraded the forecast. It was introduced by Langland and Baker (2004) for a variational DA system using an adjoint formulation. This technique was then adopted in many operational and research NWP systems (e.g., Cardinali, 2009; Gelaro and Zhu, 2009; Ishibashi, 2010; Lorenc and Marriott, 2014; Zhang et al., 2015) and has turned out to be a powerful diagnostic tool. Its ensemble formulation, ensemble forecast sensitivity to observations (EFSO), was introduced by Liu and Kalnay (2008) and Li et al. (2010) for the local ensemble transform Kalman filter (LETKF; Hunt et al., 2007). It was then refined by Kalnay et al. (2012) so that it is applicable to any formulation of ensemble Kalman filter (EnKF), and it is simpler, easier to implement, and more accurate than the previous ensemble formulations. Ota et al. (2013) successfully implemented this new formulation in a quasi-operational global EnKF system of National Centers for Environmental Prediction (NCEP), and Sommer and Weissmann (2014, 2016) applied the method to a regional convective-scale LETKF system. Compared to the adjoint-based FSO, one great advantage of the ensemble-based EFSO method is that it does not require the tangent linear model, making implementation easier, especially for moist processes that are very difficult to linearize. However, the approximation of nonlinear error propagation using the ensemble error covariance with a limited ensemble size may introduce some errors. To suppress the spurious correlations, spatial localization of the covariance is needed in EFSO. The covariance localization further leads to the potential necessity of advection of the localization function, although this is technically easily solvable (Kalnay et al., 2012; Ota et al., 2013).
Since the (E)FSO method can estimate the assimilation impact of any each observation at the same time, it is much more economical than conducting many OSEs, making the idea of using (E)FSO to aid in assimilation development attractive. However, several characteristics of FSO may reduce the effectiveness of this approach. For example, Todling (2013) pointed out that the typically used 24 h forecast error reduction measured by a linearized total energy norm in FSO may not suitably reflect the general impact on forecasts through the 6 h cycle DA. In addition, the use of analyses made by the system itself as the verifying truth and the validity of the linear assumption in the adjoint model (or ensemble error covariance) can further make the (E)FSO estimates inaccurate. Gelaro and Zhu (2009) also discussed several differences between the FSO and OSEs. They compared the observation impacts estimated by FSO with those obtained from actual data-denial OSEs and concluded that they were only in reasonable agreement if the relative impact of a subset of observation to the total impact was considered. Therefore, the (E)FSO methods have been used mostly to monitor the performance of operational systems rather than to aid the assimilation development.
However, recent studies have demonstrated that it is indeed possible to use the EFSO information to detect and reject detrimental observations and improve the forecasts. Ota et al. (2013) showed that by applying EFSO to relatively small horizontal regions, observations that cause significant forecast degradation can be identified. Following their achievement, Hotta et al. (2017a) proposed a novel QC algorithm, termed “Proactive QC”, which detects detrimental observations after only 6 h from the analysis using EFSO and then repeats the analysis and forecast without using the identified data. They also showed that EFSO is applicable not only to a pure EnKF but also to hybrid variational-ensemble DA systems, and that the EFSO results are rather insensitive to the choice of verifying truth and evaluation lead time. The proactive QC is a method to apply EFSO online in DA cycles, which can adapt to the latest changes of the observing systems. However, since it requires future observation to compute the EFSO, it is applicable only to improve the “final analysis” but not to improve the “early analysis” that provides initial conditions to the extended forecasts.
In this study, we also explore the use of EFSO for observation selection (or QC), but in an offline approach. In contrast to the proactive QC, the EFSO is computed by offline assimilation of the data from a new observing system over a long period, and then the statistics of these EFSO samples are used to efficiently determine optimal data selection criteria for the new observing system. Section 2 describes the EFSO algorithm. Section 3 outlines our proposed methodology using EFSO to avoid expensive trial-and-error OSEs in the assimilation development. In Sect. 4, the method is demonstrated with the assimilation of a global precipitation data set, known as TRMM Multisatellite Precipitation Analysis (TMPA; Huffman et al., 2007, 2010). Section 5 summarizes this study and concludes with a discussion.
This section briefly reviews the EFSO formulation following Kalnay et al. (2012). Let us assume that our DA system has an assimilation window of 6 h and that we wish to quantify contributions from each of the observations assimilated at time 0 to the reduction (or increase) of the error of the forecast t hours later. Let and denote the ensemble mean forecasts valid at the evaluation time t that are initialized, respectively, at time −6 and 0 (that is, before and after the assimilation at time 0), denote the verifying state at time t, and C denote a positive definite matrix that defines the forecast error norm. The change of the forecast errors due to the assimilation is measured by
where
are the forecast errors after and before the assimilation, respectively. In the EnKF formulation, Kalnay et al. (2012) showed that Eq. (1) can be approximated as
where
(cf. Eq. 6 in Kalnay et al., 2012). Here K is the ensemble size, and R is the observation error covariance matrix. Ya=HXa is the matrix of analysis perturbations in observation space where H is the Jacobian of the observation operator H, and Xa is the matrix made up with K column vectors representing the analysis perturbation at time 0. In practice, the Ya can be computed either by applying the observation operator to the analysis members, or by applying the EnKF analysis equation to ) when the former method is not applicable. is like Xa but with each column vector representing the ensemble forecast perturbation valid at time t initialized at time 0. δy is the observation-minus-background (O−B) innovation vector at time 0 defined by , where yo is the column vector composed of the observations assimilated at time 0.
In practice, as with any EnKF with a small ensemble size compared with the rank of the covariance, covariance localization is necessary. We need to localize the (cross-)covariance so that Eq. (5) becomes
where the symbol ∘ represents element-wise multiplication (Schur product), and ρ is a matrix whose jth row is a localization function around the jth observation.
Equation (4) can be interpreted as an inner product of the innovation vector δy and the sensitivity vector , so that the contribution from a single observation, say the lth element of the observation vector yo, can be expressed as
This is the EFSO estimate of the impact of a single observation onto the t hour forecast.
The EFSO can be computed based on different error norms. In this study, we use both a dry total energy norm and a moist total energy norm (Ehrendorfer et al., 1999). The generic moist total energy norm is defined as
where S represents the target region, σ is the vertical sigma-coordinate, and u′, v′, T′, q′, and denote, respectively, zonal and meridional wind, temperature, specific humidity, and surface pressure of the perturbation e. Cp, Rd, and L are the specific heat of the air at constant pressure, the gas constant of the dry air, and the latent heat of condensation per unit mass, respectively. Tr and Pr are the reference temperature and surface pressure, for which we use constant values of 280 K and 1000 hPa, respectively. The dry total energy norm is defined as in Eq. (8) but excluding the moisture term, .
The objective is to accelerate the process to determine observation selection criteria with which data from a new observing system can be effectively assimilated through an offline EFSO calculation. To achieve this, some important characteristics of the (E)FSO need to be first noted.
It has been shown that relative values of the (E)FSO among different sets of observations can be reasonably accurate compared to the true forecast impact (Gelaro and Zhu, 2009; Ota et al., 2013), despite some limitations (Gelaro and Zhu, 2009; Todling, 2013; Kalnay et al., 2012). However, it is important to note that the EFSO calculation assumes a given background state (first guess) x0|−6, a given set of observations yo assimilated at the analysis time, and a given verifying state at the evaluation time. If any of them change, the EFSO for individual observations also changes. Therefore, we should not consider EFSO some kind of “intrinsic property” or “quality” of the observation itself. The EFSO depends on the background state and the other observations assimilated at the same time. Adding a new type of observation may decrease the impact of the others. Particularly, an important consideration for our objective is that if cycled DA experiments are performed with different sets of observations, the changes in the background state can accumulate and thus one cycled DA experiment becomes different from another. In these circumstances, the EFSO value of a single observation is subject to stochastic fluctuations. To extract useful information, computing statistics over a sufficient number of observations becomes necessary.
In the method of proactive QC (Hotta et al., 2017a), since the EFSO is computed following each (online) DA cycle, the above conditions are mostly met. Specifically, the background state does not change when the data that passed the EFSO-based QC are assimilated again, which makes the EFSO for individual observations useful. However, when the EFSO is computed offline (i.e., independent of the cycled OSEs), EFSO statistics over many observations need to be made. In addition, to make the EFSO as close to the true forecast impact as possible, the changes of such conditions should be minimized. With these caveats in mind, we propose the procedure for using EFSO in the assimilation development as follows.
3.1 Step 1: computing EFSO samples for the new observing system using an offline DA
The flowchart in this step is shown in Fig. 1. Firstly, the CONTROL experiment is conducted, running DA cycles without using the new observing system, just as in the OSE framework. The ensemble first guesses (blue lines in Fig. 1) have to be saved at this time. Next, initiated from every one or several cycles in CONTROL, an “offline” (i.e., non-cycled) DA is performed (purple dotted lines in Fig. 1), assimilating all data from the new observing system (with no or minimal data screening) in addition to those assimilated in the CONTROL. Using a 6 h evaluation time, EFSO for each single observation from the new observing system is then computed using the formulation described in Sect. 2, which involves additional 6 h ensemble forecasts from the non-cycled analyses (red lines in Fig. 1) and an ensemble mean forecast from the first guess (cyan lines in Fig. 1). Hotta et al. (2017a) showed that a short 6 h evaluation time for EFSO is sufficient, which is good for saving computational cost and minimizing the nonlinear effects. Note that screening (QC) the new observations should be avoided in this offline assimilation because we want to obtain EFSO for all new observations, whether they improve the forecast or not. The offline assimilation in each cycle is independent: once the EFSO computation is done, the offline analyses are dropped (not cycled). A large sample of the single-observation EFSO data is thus collected from these multiple offline assimilation cycles.

3.2 Step 2: investigating the EFSO statistics for possible data selection strategies
Having the samples of EFSO for the new observations, we assess their average impacts, such as the average EFSO for a single observation (hereafter “per-obs EFSO”) or the rate of observations having positive impact (negative change in forecast errors), conditionally sampled based on various factors that could affect the assimilation impact of the observations. These factors should be simple so that they can be potentially used to formulate regular data selection criteria in the assimilation process. Examples of these factors can include: (1) geographical or vertical locations, (2) local time or phase of the diurnal/seasonal cycles, (3) channels for satellite radiance observations, (4) any kind of data quality flags provided with the data, (5) observed values or O−B departures, (6) in an ensemble DA system, statistical properties from the background ensemble, such as the number of precipitating members if assimilating precipitation, and (7) other meteorological conditions such as presence or absence of precipitation or clouds. Taking the average impacts from large samples reduces the stochastic fluctuations. These results tell us the relative usefulness in the assimilation among the new observations in terms of the chosen factors. Note that, as discussed before, the EFSO, which can be computed with various error norms, is not precisely identical to the actual forecast impact in the NWP, so it should not be expected that a set of precise optimal data selection criteria can be readily determined from the EFSO results. However, based on the comprehensive EFSO information with respect to many different factors, we can propose some data selection strategies that can be used in the assimilation of the new data, by keeping observations leading to larger beneficial average EFSO impacts and rejecting observations leading to smaller or even detrimental average EFSO impacts.
3.3 Step 3: verifying the actual forecast impact by OSEs
The data selection criteria proposed from Step 2 using the EFSO statistics need to be finally tested in regular OSEs, where subsets of new observations passing the criteria are assimilated in addition to those assimilated in CONTROL with DA cycles. The development is thought to be successful if the forecasts in TEST are better than that in CONTROL. If the forecasts are not improved, fine tuning of the selection criteria or other possible selection strategies suggested from Step 2 can be tried. This step is similar to running trial-and-error TEST experiments described in Sect. 1 without any EFSO information; however, with the valuable guidance from the EFSO statistics, the numbers of trials needed to obtain the optimal data selection criteria should be considerably reduced.
3.4 Notes on the methodology
We note that the above design is intended to increase the representativeness of the offline computed EFSO. The simultaneous assimilation of all observations already used in CONTROL minimizes the change in the observation set yo, and the non-cycled design minimizes the change in the background state x0|−6 due to potentially many detrimental observations in the new observing system. At this initial development stage, it is assumed that we do not know a good way to effectively assimilate the new data, so it is better to avoid accumulating their possibly detrimental effects to background states with cycled DA. In addition, it would be desirable, if possible, to use another analysis data set that is independent of CONTROL as the verifying truth to compute the EFSO, so that the errors caused by the undesirable correlations between the forecasts and the verifying analyses are avoided (Todling, 2013).
We further note that if the OSE results are not satisfactory, an iteration of the entire three-step procedure can be considered. The procedure is repeated by letting the new CONTROL assimilate the observations used in the previous CONTROL plus the new observations that pass the first-order data selection criteria derived in the previous time. This brings the new background state x0|−6 in the EFSO calculation closer to that in actual OSEs, allowing for more accurate estimation of the observation impacts, which should benefit the determination of the final optimal data selection criteria.
In order to test the methodology proposed above, we use a global satellite precipitation data set, TMPA (Huffman et al., 2007, 2010), as an example of a new observing system, and demonstrate how this method can work to efficiently formulate appropriate data selection criteria for the new data.
4.1 Background on the precipitation assimilation studies
Satellite precipitation estimates, such as TMPA, have not been widely used in DA because of several problems, including the non-Gaussian error distribution associated with precipitation, the error covariance between precipitation and other model variables, and the substantial model and observation errors (e.g., Errico et al., 2007; Tsuyuki and Miyoshi, 2007; Bauer et al., 2011; Lien et al., 2016a). Assimilation of all precipitation data without special treatments usually leads to no impacts or negative impacts. In spite of these issues, Lien et al. (2013, 2016b) and Kotsuki et al. (2017) conducted a series of experiments, from an idealized configuration to realistic systems, to show that it is possible to improve the medium-range forecasts in a global model by the assimilation of global precipitation data. The keys in their experiments are to use
-
an LETKF to exploit the flow-dependent background error correlation between prognostic variables and diagnosed precipitation;
-
a Gaussian transformation of the precipitation variable, which mitigates the inherent non-Gaussianity of precipitation data;
-
proper data selection criteria to exclude the “bad” observations that we cannot effectively use, including the important requirement that enough ensemble background members should have non-zero precipitation (Lien et al., 2013).
The great difficulty of assimilating precipitation data makes it an ideal example to demonstrate our proposed method to accelerate the assimilation development for a new observing system.
4.2 Experimental design
We use the same system as in Lien et al. (2016b), assimilating the global TMPA data into a low-resolution version of the NCEP Global Forecast System (GFS) model with the LETKF. The model resolution is spectral T62 with 64 vertical levels. Thirty-two ensemble members and the 6 h assimilation cycle are used. The CONTROL experiment assimilates the rawinsonde observations processed in the NCEP Global Data Assimilation System (i.e., contained in the NCEP PREPBUFR data set). It is conducted for 13 months from 00:00 UTC 1 December 2007 to 00:00 UTC 1 January 2009. It is identical to the “RAOBS” experiment in Lien et al. (2016b), where more details can be found. This CONTROL serves as the basis of the following non-cycled EFSO calculation (Step 1), and as the reference of the cycled OSEs (Step 3). We note that in an operational system already assimilating more data, the improvement that additional assimilation of precipitation can achieve should be smaller.
For the TMPA precipitation assimilation, we also employ all the techniques developed in Lien et al. (2016a, b). Namely, the TMPA data are upscaled to the low-resolution T62 GFS grids and temporally integrated into 6 h accumulation amounts. The Gaussian transformations for the model/observation precipitation variables (i.e., the “GTbz” method in Lien et al., 2016b) are applied. Other details of the experimental configuration and the Gaussian transformation method are discussed in Lien et al. (2016b). These techniques are essential to achieve basic satisfactory performance of the TMPA assimilation; however, even with them, assimilating all available data does not lead to an optimal result. Lien et al. (2013, 2016b) determined the data selection criteria that can further improve the assimilation results using many trial-and-error OSEs. Here we assume no knowledge of the selection criteria, and we derive them using the proposed offline EFSO methodology.
4.3 Step 1: computing EFSO samples for the new observing system using an offline DA
As described above, the CONTROL experiment is cycled assimilation of rawinsonde observations. We then perform non-cycled offline assimilation of both the rawinsonde and TMPA to compute EFSO samples of the TMPA data, following the schematic in Fig. 1. Almost all available TMPA data are assimilated except those few whose innovation (difference between the observation and the model background value, ) is 5 times greater than the observation errors. The European Centre for Medium-range Weather Forecasts (ECMWF) ERA-Interim reanalysis is used as an independent verifying truth for EFSO computation. We follow the suggestion in Hotta et al. (2017a) to evaluate the forecast sensitivity at 6 h forecast time, while the localization function is not advected in this study. We assume that the 6 h forecast window is short enough so that the impact of localization advection is not essential. EFSO measured by both the moist total energy and dry total energy norms are computed. We note that for this purpose, EFSO has an advantage with respect to FSO, because FSO requires an adjoint model which has difficulties with moist processes (Janiskova and Cardinali, 2016); in addition, the use of the Gaussian transformation for assimilating precipitation in our experiments should also cause difficulties if using an adjoint method. We perform the offline assimilation and collect EFSO samples once every five cycles (30 h) over the entire year of 2008. Only every five cycles are computed for EFSO diagnostics in order to save computational cost while avoiding sampling the same hour in all the diurnal cycles. In total, we collect EFSO diagnostics for every single precipitation observation in 293 offline cycles, amounting to about 2.9 × 106 samples. The EFSO is computed using naturally the same number of ensemble members, 32, as in the DA experiments. It may be speculated whether such a small ensemble size is enough to produce useful EFSO results; thus, we also compute the EFSO with even fewer ensemble members to examine if the results significantly change, which will be discussed later.
4.4 Step 2: investigating the EFSO statistics for possible data selection strategies
The EFSO statistics can be conditionally computed based on various factors that can be potentially used to formulate data selection criteria. Based on the characteristics of the precipitation data, Lien et al. (2013) suggested that when there are too many non-precipitating background members, the ensemble background error covariance may not contain enough useful information for effective DA. Other factors that may affect the effectiveness of assimilation include the observed precipitation values, particularly whether they are zero or not, and the geographic locations of the observations. Therefore, we calculate the EFSO statistics based on these factors.
Figure 2 shows the per-obs EFSO (Fig. 2a, b) and the rate of observations with positive impacts (Fig. 2c, d), grouped by the number of precipitating members in the background. The temporally averaged total EFSO (i.e., total EFSO divided by the number of offline cycles, 293) in one cycle is also shown (bars in Fig. 2e, f), as well as the total observation numbers (in all 293 times) in each group (red lines in Fig. 2e, f). First, it is found that the EFSO measured by the moist total energy norm shows both larger per-obs forecast error reductions and higher positive impact rates than that measured by the dry total energy norm. This is an encouraging result, but it is not unexpected because the precipitation observation should contain useful information related to moisture. However, the results also show that the assimilation of precipitation can also improve the other dynamical variables if there are at least several (greater than about 10) precipitating background members, as seen in the EFSO values with the dry total energy norm. An explanation of these results is that when fewer members are precipitating, the assimilation is more difficult because there are fewer ensemble members with dynamics closer to the truth, and therefore the analysis increment is more uncertain. For both norms, the per-obs EFSO reaches its maximum when the number of precipitating members is around 22 (Fig. 2a, b). When the precipitating members are too many, the per-obs EFSO slightly reduces, possibly because the background states are already on average more accurate in this situation. Measured with the moist (dry) total energy norm (Fig. 2c, d), the percentages of beneficial observations increase gradually from about 52 % (50 %) when the number of precipitating members is less than 16 to about 54 % (53 %) when it is more than 20, and the overall beneficial rate for all precipitation observations is 53.5 % (51.8 %), which is consistent with the general experience that this rate is usually slightly above 50% (e.g., Gelaro et al., 2010). When accumulating all observations in one cycle, the total beneficial impact shown by the total EFSO (i.e., per-obs EFSO times observation numbers; bars in Fig. 2e, f) increases roughly monotonically with the number of precipitating members, due to the effect of observation numbers: except for the case of no precipitation in all members, there are more observations when there are many precipitating members (red lines in Fig. 2e, f).

Figure 2EFSO statistics for TMPA observations grouped by the number of precipitating members in the background and measured by (a, c, e) the moist total energy norm, and (b, d, f) the dry total energy norm in 6 h forecasts during the year 2008. (a, b) Average per-obs EFSO (10−4 J kg−1). (c, d) Percentage of observations with positive impacts. (e, f) Total EFSO per cycle (J kg−1). Also shown in red curves in (e, f) are the total numbers of observations (i.e., EFSO samples) in all 293 offline cycles (104; secondary y axis).
In addition, the EFSO statistics using the moist total energy norm are also computed separately under the condition of nonzero precipitation in the observation (hereafter R > 0; first column in Fig. 3) and zero precipitation in the observation (hereafter R = 0; second column in Fig. 3). For R > 0 observations, the average per-obs EFSO (Fig. 3a) is entirely beneficial (in terms of error reduction), but it is most beneficial when about half of the ensemble forecasts are precipitating and half are not, indicating that the observations of precipitation are most useful when there is high uncertainty in the forecasts. The percentage of the R > 0 observations that are beneficial (Fig. 3c) is astonishingly high, reaching almost 70 % under the condition that the number of precipitating members is between 5 and 13. Similarly it shows lower percentages with fewer or more precipitating members, but still much above 50 %. We note that in a realistic data assimilation system such very high beneficial rates should only be found when taking subsets of observations as in this example. In addition, the relatively inaccurate rawinsonde-only CONTROL, which allows the precipitation observations to contribute a larger amount of information, would be another reason for this high beneficial rate. With a modern operational system, such extremely high rates would be more difficult to see. The situation is quite different for R = 0 observations: if the number of precipitating ensemble members is 20 or less, assimilating the R = 0 observations has a detrimental effect, and it only becomes beneficial when most of the ensemble members are (wrongly) precipitating (Fig. 3b). The percentage of beneficial R = 0 observations is less than 50 % unless essentially all the ensemble members are precipitating (Fig. 3d).
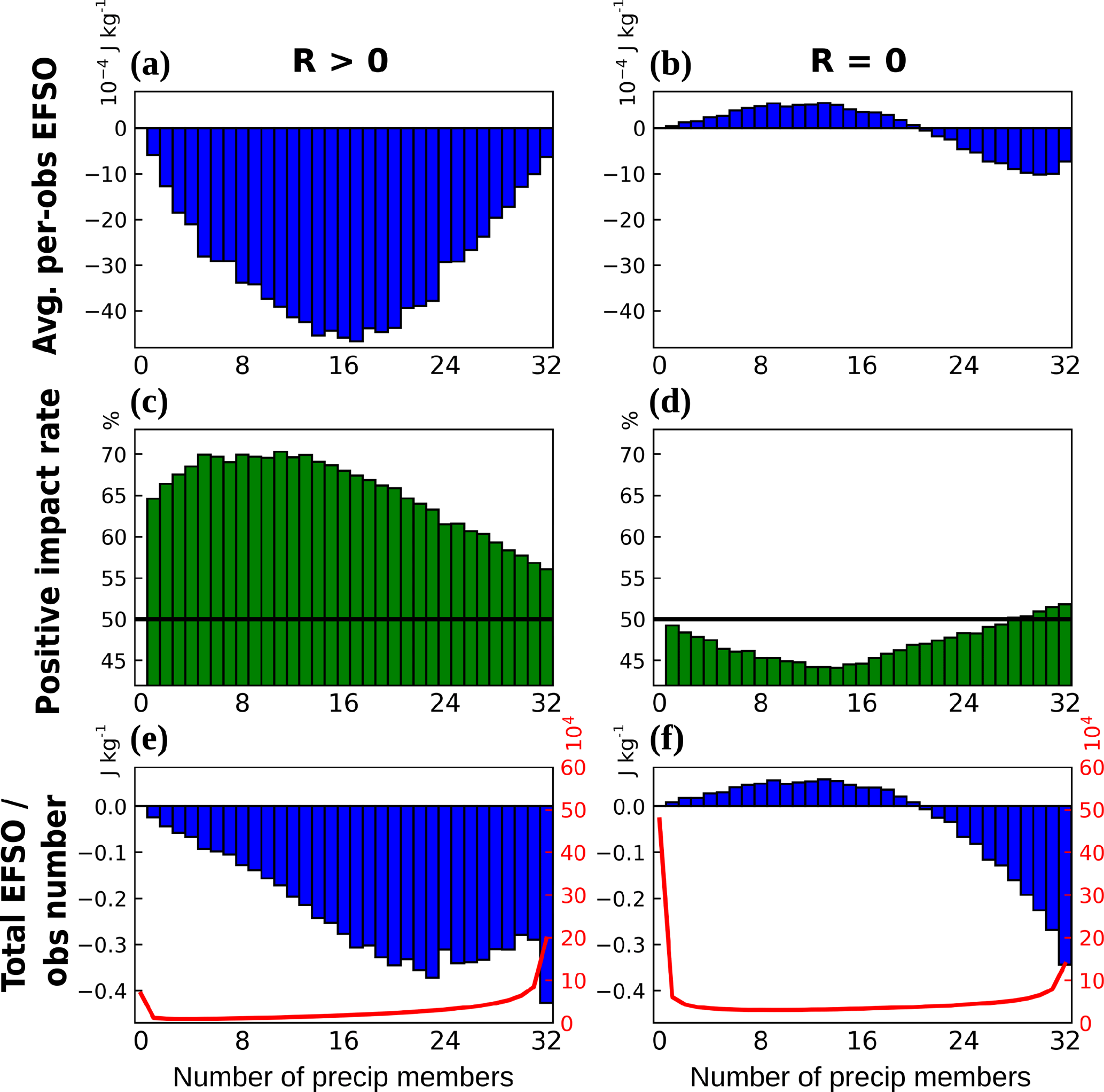
Figure 3Same as Fig. 2, but for EFSO measured by the moist total energy norm and computed separately for (first column) non-zero precipitation observations (R > 0) and (second column) zero precipitation observations (R = 0).
To validate if these EFSO statistics computed based on the 32-member ensemble are robust, we compute the same EFSO statistics using only the first 8, 16, and 24 members. We note that this verification only varies the number of ensemble members for the EFSO computation but not that in the (offline) DA; namely, the precipitation observations are still assimilated using 32 members, but the EFSO is computed (Eq. 6) using ensemble forecasts of fewer members to the evaluation time (). Figures like Fig. 3 but computed from fewer members are shown in Supplement. Comparing Fig. 3 and Figs. S1–S3 in the Supplement, we conclude that the average per-obs EFSO statistics over the large samples hardly change even with a very small ensemble size, 8 members, but the rates of beneficial observations become generally closer to 50 % with fewer members. We think that the insensitivity of per-obs EFSO to the ensemble sizes is due to the average over large samples from multiple cycles, which overcomes the errors in individual observations. In contrast, the beneficial rates are more sensitive to the ensemble size because small errors in near-neutral impact observations can easily change their signs. However, for the purpose of this work, since the important information we would like to know from these EFSO statistics is just the qualitative usefulness among different groups of observations, an ensemble size of 32 or even fewer is shown to be enough for the EFSO computation given the sufficient sample size.
Next, Fig. 4a, b shows the EFSO statistics (using the moist total energy norm) with respect to the geographic locations. Overall, the areas which benefitted the most from the precipitation assimilation are the storm-track regions, located within 30–50∘ N and ∘ S over the three major oceans. Most of the ocean regions show positive impacts and positive impact rates of greater than 50%. The marine stratocumulus regions are an exception, showing detrimental impacts over the ocean. The land regions show marginal or negative impacts. These two different measures show generally similar patterns, but the detrimental regions over the land are more clearly highlighted with the positive impact rate. Here we show an interesting comparison of these EFSO maps to the correlation map between the 6 h accumulated precipitation in the 3 to 9 h T62 GFS model forecasts and the TMPA observations at the corresponding times (Fig. 4c), which was obtained in Lien et al. (2016a). Note that Fig. 4c is similar to Fig. 10 in Lien et al. (2016a), but for all seasons combined. This correlation score represents a simple measure of the statistical “consistency” between the model and the observation climatology; details on this correlation calculation are described in Lien et al. (2016a). It was hypothesized in Lien et al. (2016a) that the precipitation observations distributed over the regions with higher correlations could be more useful for data assimilation, but that the data over very low correlation regions would be difficult to use mainly because of large model errors. Here a great similarity is found between the average EFSO map (Fig. 4a) and the correlation map (Fig. 4c), indicating that the hypothesis in Lien et al. (2016a) was reasonable, and that the effectiveness of the precipitation assimilation is in fact strongly dependent on the geographic locations, which can be explained by the systematic inconsistency between model and observed precipitation (Lien et al., 2016a). We note again that the intrinsic quality of each observation is not the only reason for its good or bad EFSO or assimilation impact.
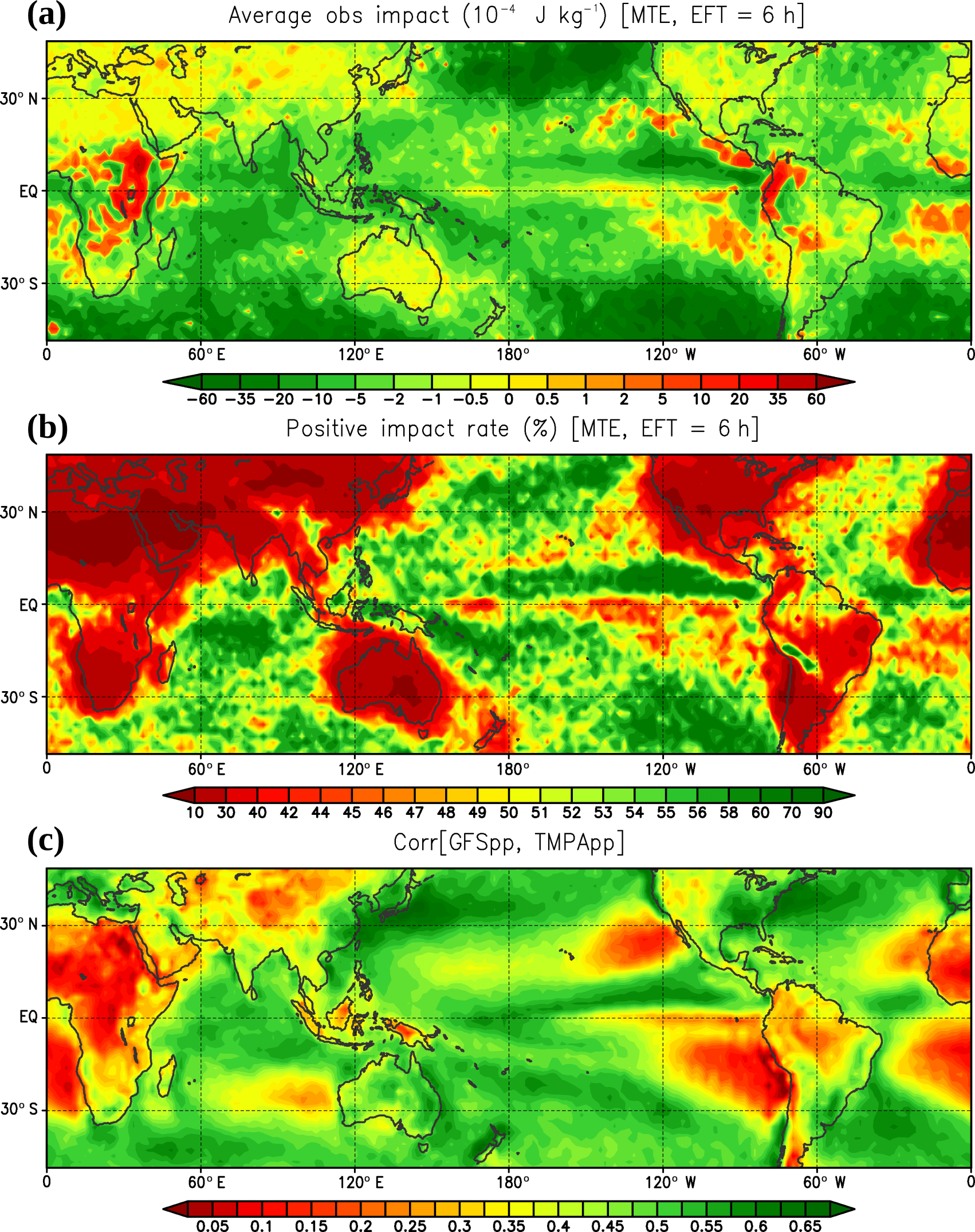
Figure 4The maps of (a) the average per-obs EFSO (10−4 J kg−1) and (b) the rate (percent) of observations having positive impacts from the same precipitation EFSO sample (measured by the moist total energy norm) used in Fig. 2. (c) The maps of correlation between the 6 h accumulated precipitation in the 3 to 9 h T62 GFS model forecasts and the TMPA observations at the corresponding times during the 2001–2010 period. This correlation map is similar to Fig. 10 in Lien et al. (2016a), but for all seasons combined. Details on this correlation calculation are described in Lien et al. (2016a).
4.5 Step 3: verifying the actual forecast impacts by OSEs
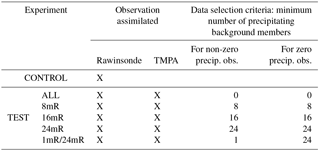
With the guidance from the EFSO statistics obtained in Step 2, we propose several data selection criteria and verify their actual forecast impact by OSE. We focus on the two factors on which the EFSO largely depends: the number of precipitating members in the background and whether the observed precipitation values are zero or not. First, only the impact of the number of precipitating members is considered. We know from the EFSO statistics (Figs. 2 and 3) that the precipitation assimilation may be effective only when there are enough precipitating members in the model background. Therefore, a series of OSEs using different thresholds of the number of background precipitating members for data selection are performed:
-
ALL: all the precipitation observations are assimilated irrespective of the number of precipitating members.
-
8mR: the precipitation observations are assimilated if at least eight members are precipitating.
-
16mR: as 8mR but with at least 16 members precipitating.
-
24mR: as 8mR but with at least 24 members precipitating.
The experimental settings are summarized in Table 1. The additional 1mR/24mR experiment guided by the EFSO statistics and its results will be described later. All these experiments are conducted for the same 13-month period as in CONTROL, and 5-day forecasts are done every cycle and verified against the ERA-Interim reanalysis. Considering the adjustment time required for the changing observation network, the results in the first month are discarded so that the 1-year (2008) results are verified.
Table 1Settings of CONTROL and all TEST (i.e., ALL, 8mR, 16mR, 24mR, 1mR/24mR) experiments.
Figures 5 and 6 show that the assimilation of precipitation gives significant positive impacts in the global average for all these experiments, reducing the errors compared to CONTROL. In terms of global root-mean-square errors (RMSEs) in 24 h forecasts (Fig. 5), it is found that assimilating all the observations under the requirement that having at least a subgroup of members be precipitating improves the forecasts further, especially in the 500 hPa zonal wind and temperature. The 24mR seems to be the optimal threshold, while assimilating too many observations (i.e., 8mR and ALL) reduces the improvement. We note that although the globally average per-obs EFSO estimates suggest mostly beneficial or neutral impacts when at least one member is precipitating (Fig. 2), especially with the moist total energy norm, using a stricter criterion (i.e., 24mR) is actually more advantageous as verified in these cycled OSEs. The 24mR criterion used in Lien et al. (2016b) was obtained by the trial-and-error approach; here we re-investigate this data selection criterion from the EFSO perspective.
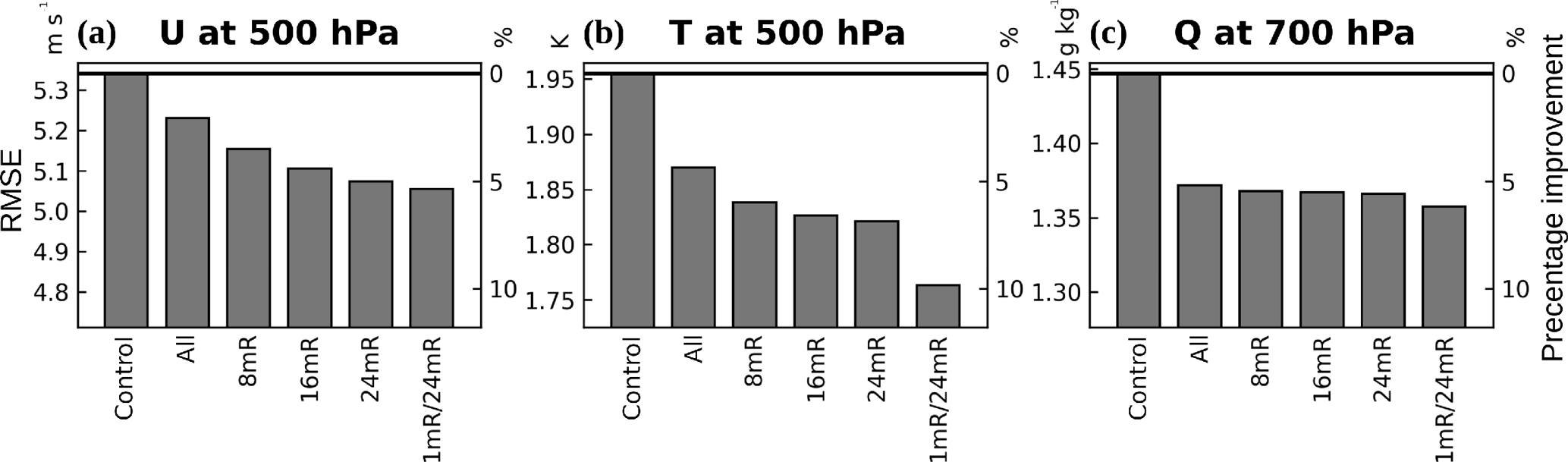
Figure 5One-year global RMSE (verified against the ERA-Interim reanalysis) of (a) 500 hPa u wind (m s−1), (b) 500 hPa temperature (K), and (c) 700 hPa specific humidity (g kg−1) in the 24 h forecasts for the cycled OSEs. The left axes show the absolute values; the right axes show the relative improvement to CONTROL in percentage. The thick horizontal lines indicate the RMSE in CONTROL as a reference.
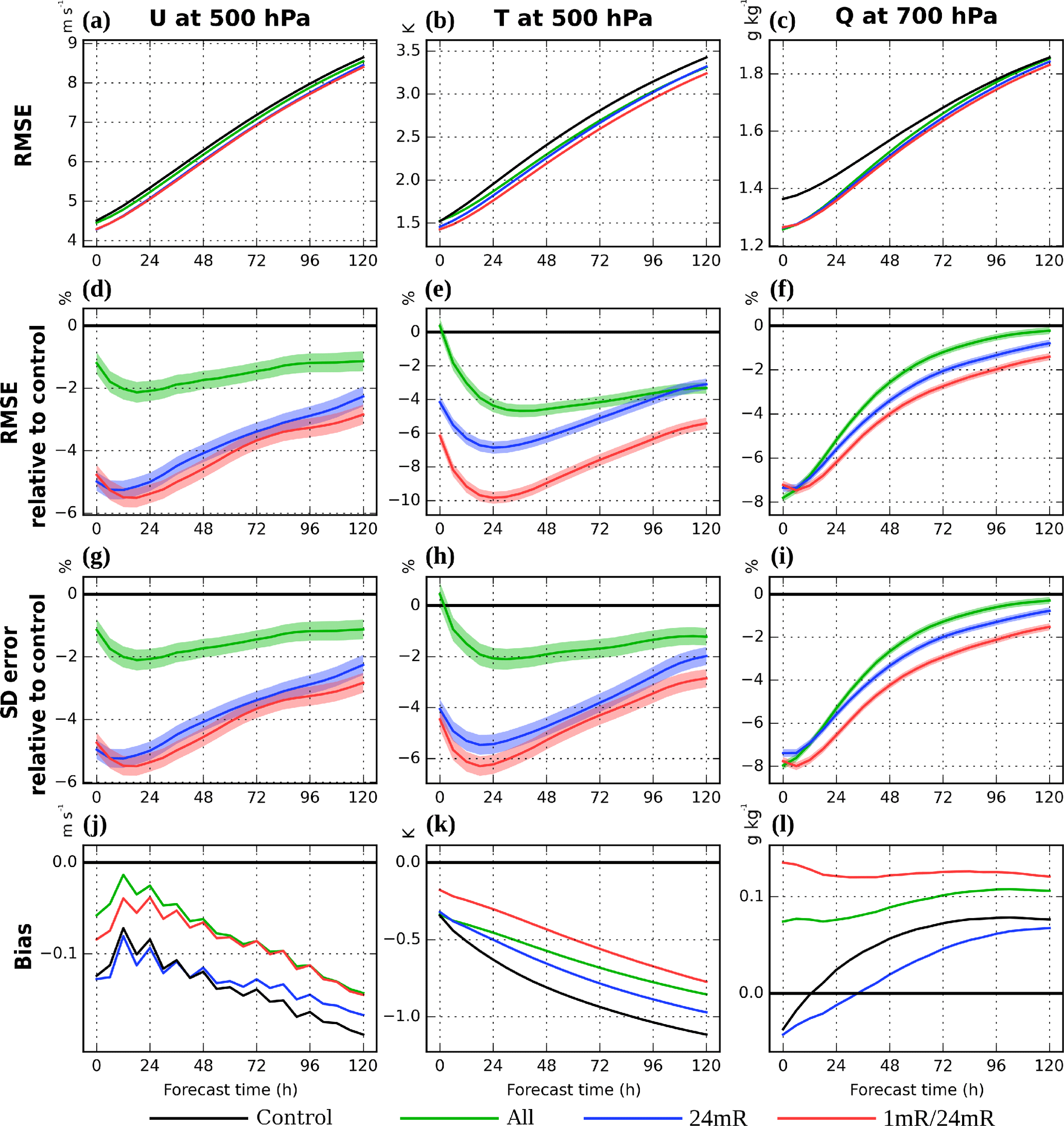
Figure 6(a–c) RMSE, (d–f) RMSE relative to CONTROL (percent), (g–i) standard deviations of errors (i.e., random errors) relative to CONTROL (percent), and (j–l) biases during the 5-day forecasts of (a, d, g, j) 500 hPa u wind, (b, e, h, k) 500 hPa temperature, and (c, f, i, l) 700 hPa specific humidity for the cycled OSEs. They are verified globally against the ERA-Interim reanalysis over a 1-year period. The light color shading associated with each experiment indicates the 95 % significance interval compared to CONTROL based on a paired-difference t test.
Figure 6 shows the 5-day forecast RMSEs and biases versus the forecast time for a subset of experiments. Compared to CONTROL, the ALL (green) and 24mR (blue) experiments improve the forecasts over the entire 5-day period in all variables except for 500 hPa temperature at the analysis time in ALL, and the improvement in 24mR compared to ALL is also clearly seen. The improvement in wind and temperature is large throughout the 5-day forecasts, while the benefit of not using the precipitation observations with fewer precipitating background members (i.e., 24mR) is significant in these dynamical variables (Fig. 6d, e). For the moisture variable, the difference between ALL and 24mR is much smaller in early forecasts, indicating that the 24mR criterion is less important for the moisture variable (Fig. 6f). This is consistent with what we found by investigating the EFSO statistics with different energy norms: achieving effective forecast error reduction measured by the dry total energy norm (which is associated only with the dynamical variables) requires more background precipitating members than that measured by the moist total energy norm. Note that these results are statistically significant as seen by the lighter color shading associated with each experiment indicating the 95 % significance interval compared to CONTROL based on a paired-difference t test (e.g., Geer, 2016).
We mentioned that the “24mR” criterion based on the background members using a single threshold for all observations was proposed and studied in Lien et al. (2013, 2016b) without employing this offline EFSO guidance, but the results of the current study clearly show that the EFSO statistics can indeed help our understanding of why this criterion is so useful. Furthermore, here we will demonstrate the power of the offline EFSO approach by introducing another experiment with more detailed data selection criteria which could only be derived with the information from the EFSO statistics. Since Fig. 3 indicates that R > 0 observations have particularly larger beneficial impacts compared to the other cases, we assimilate all R > 0 observations as long as at least one member is precipitating (1mR). For R = 0 observations, these EFSO results suggest that they should not be assimilated unless most of the ensemble members are incorrectly predicting precipitation (Fig. 3b, d), so we assimilate them only if at least 24 members are precipitating (24mR). This experiment is therefore named 1mR/24mR (Table 1).
The OSE result (5-day global forecast impact) of this two-threshold data selection criteria can also be seen in Figs. 5 and 6. This 1mR/24mR experiment based on the offline EFSO guidance outperforms any single-threshold experiment and also all the results obtained in Lien et al. (2016b) without employing the EFSO guidance. The improvement is particularly large in the 500 hPa temperature forecast, showing an additional ∼ 3 % reduction in the RMSE compared to 24mR in the 24 h forecasts (Fig. 5b). Furthermore, although the EFSO only estimates the 6 h forecast error reduction, the forecast improvement from using this data selection lasts throughout the 5 days (Fig. 6).
To investigate further the impact of the 1mR/24mR experiments, we show the biases compared to the ERA-Interim reanalysis in Fig. 6j–l. The magnitudes and changes of biases from the precipitation assimilation are rather small compared to the RMSE for 500 hPa u wind and 700 hPa moisture. However, the magnitude of 500 hPa temperature bias is large in our model compared to its RMSE, and the precipitation assimilation corrects it in the longer forecast time. This can be additionally examined by looking at the standard deviation of errors which represents “debiased RMSEs” or “random errors”, shown in Fig. 6g–i. In this bias-free verification, the 500 hPa temperature improvement in all the precipitation assimilation experiments over CONTROL becomes smaller than that measured by the RMSE, and the improvement of 1mR/24mR over 24mR also becomes smaller, because a portion of this improvement in the RMSE is achieved by reducing the bias. For 500 hPa u wind and 700 hPa moisture, their errors are much less affected by removing their biases, meaning that their biases are negligibly small compared to the RMSEs. It is also noted that the magnitude of the improvement in 500 hPa temperature becomes similar to that in 500 hPa u wind, which might be implied by geostrophic balance. Nonetheless, the 1mR/24mR is still better than 24mR in all variables, indicating the usefulness of our EFSO methodology, despite the existence of the model bias.
The regional verifications are shown in Fig. 7. The improvement from using 1mR/24mR is seen in most of the verification regions and variables within the entire 5-day forecast period, so we believe that the optimality of 1mR/24mR is robust. Note that most of these differences in forecast RMSEs are statistically significant (shown by the light color shading). However, for tropical regions, the 1mR/24mR does not analyze well the 500 hPa u wind and 700 hPa moisture (at the analysis time; Fig. 7g, i), but it becomes better than the other experiments with forecast length, possibly due to the improvement in other variables/regions at the analysis time. The improvements in the tropical forecasts made with 1mR/24mR after day 2 are remarkable.
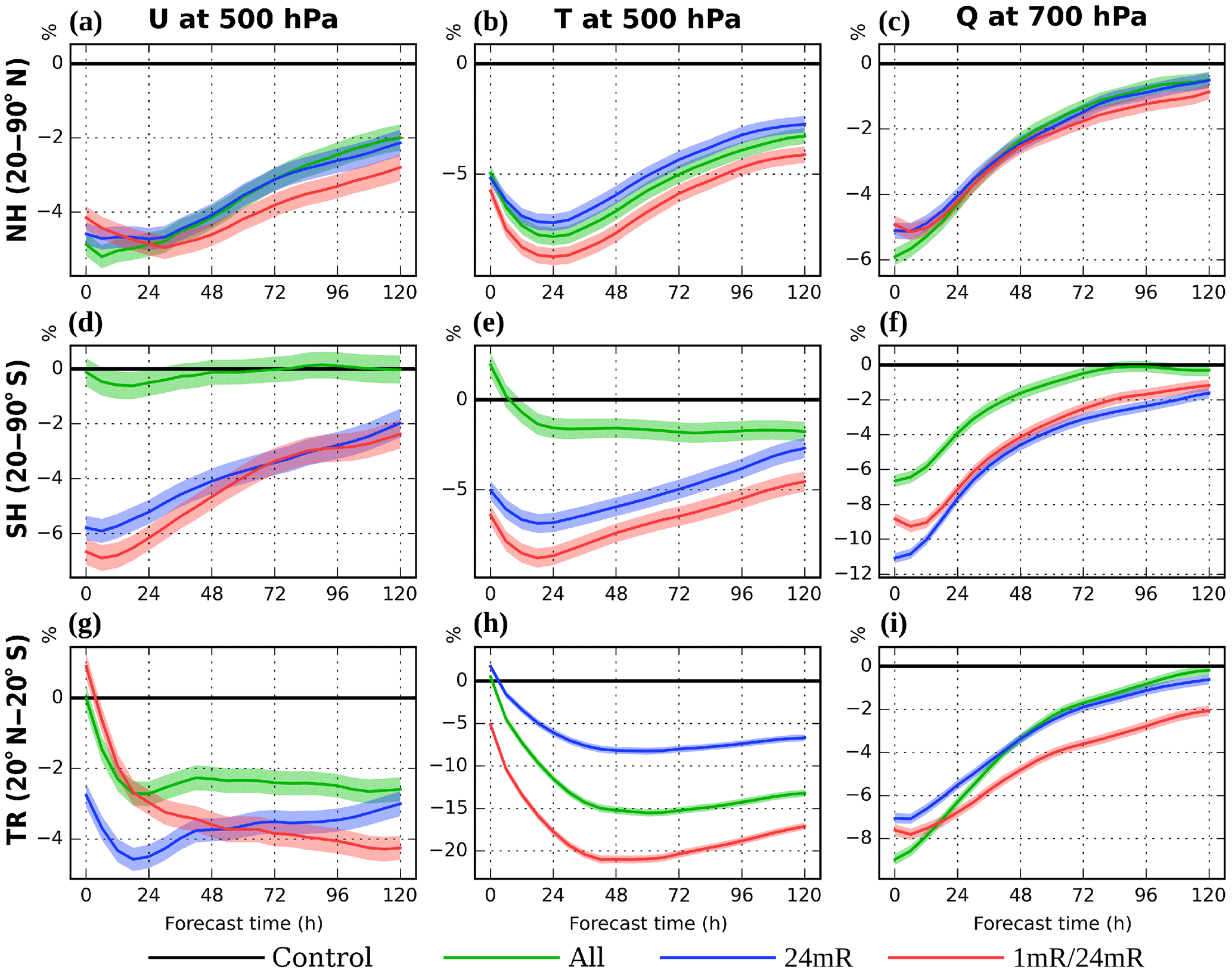
Figure 7Same as Fig. 6, but for RMSE relative to CONTROL (percent) in different verification regions: (a–c) Northern Hemisphere extratropics (NH; 20–90∘ N), (d–f) Southern Hemisphere extratropics (SH; 20–90∘ S), and (g–i) tropics (TR; 20∘ N–20∘ S).
These experiments demonstrate the power of the EFSO approach to guide the development of the data selection strategies in assimilating new observing systems. We only need to compute the EFSO from the offline assimilation experiments once, over a sufficiently long period to collect a large sample, and then the statistics can be done comprehensively based on many different factors. These statistics can provide much useful information. For example, it would be unlikely that one could formulate the 1mR/24mR criteria with just a few trial-and-error experiments without knowing the EFSO statistics.
Lastly, we note that we also tried to make use of the geographical dependence (Fig. 4) of EFSO to formulate the data selection criteria used in OSEs, such as (1) applying constant geographic masks defined by single thresholds of average per-obs EFSO values in Fig. 4, used in addition to the current 24mR or 1mR/24mR criteria and (2) further separating EFSO statistics in Figs. 2 and 3 to different latitudinal bands and defining different data selection criteria for them. However, although the results from these experiments are similarly good, none of them could outperform 1mR/24mR, which produces the best results we have obtained.
A common approach to develop the data selection strategies and criteria for assimilating a new observing system is to perform OSEs, which is usually very time and resource consuming. Here, we propose a new methodology based on the EFSO method that allows us to estimate the forecast impact of each observation. We propose that the EFSO statistics from a large sample can be used to guide the development of the data selection criteria in a more straightforward manner and thus accelerate the development work.
The proposed method consists of three steps:
-
Conducting an offline (not cycled) DA experiment, assimilating most of available new observational data with no or minimal screening or QC. From the offline assimilation, compute large samples of per-obs EFSO data for the new observing system.
-
Computing the average per-obs EFSO and/or the percentage of beneficial observations conditionally sampled based on various factors that can be potentially used to formulate criteria for data selection, such as location, time, satellite channels, data quality flags, and model background conditions. Based on these statistics indicating the relative forecast impacts by the assimilation of the new observations under different conditions, potential data selection criteria can be proposed for keeping more beneficial observations.
-
Verifying the actual forecast impact of the data selection criteria by applying them in cycled OSEs.
We demonstrate this method with the assimilation of TMPA global satellite precipitation data, which have been studied by Lien et al. (2016a, b). It is shown that the EFSO approach supports the data selection criterion proposed in Lien et al. (2013, 2016b) based on the number of precipitating members in the model background. In addition, it further provides useful information for refining the data selection criteria, so that in this study we obtain a result significantly better than the best obtained by Lien et al. (2016b). This example shows how the EFSO method can be used to accelerate the development of an optimal data selection strategy for assimilating new observing systems.
The setup of this demonstrative experiment is intermediate; compared with the modern operational configuration, the resolution is too low, and the observation data used in the CONTROL experiment are much limited, consisting of just rawinsondes. We believe that the use of this intermediate setup does not hinder the objective of this study, which is to demonstrate the methodology of using EFSO to accelerate the development of the quality control in data assimilation. However, in an operational system already assimilating more data, the improvement that additional assimilation of precipitation can achieve will be smaller. Regarding this aspect, we think that this method could indeed still be useful when abundant observations are already used in CONTROL, because the guidance provided by EFSO statistics is relevant, independent information that is not obscured by the existing observations. Nevertheless, experiments with more realistic configurations are required to convincingly prove the usefulness of this method in the assimilation development with a state-of-the-art operational NWP system.
Moreover, since this EFSO-based methodology provides an efficient way to clarify under what conditions observations are helpful or not, we believe that it should be useful for instrument and algorithm developers to collaborate with DA scientists, so that the EFSO information can be used to improve the quality of the assimilated observations. Such a collaboration is taking place between scientists at the University of Maryland and the University of Wisconsin, with the aim of identifying the origin of occasional negative EFSO impacts of high-latitude MODIS winds.
We note that this method works offline based on the static data selection criteria derived with the aid of EFSO statistics in advance of the cycling DA, whereas Proactive QC (Ota et al., 2013; Hotta et al., 2017a) works online based on the dynamical criteria decided by the flow-dependent EFSO diagnostics. An important issue that is not covered in this study is how to assign appropriate observation error variance for the new observation data. Using an idea similar to EFSO, Hotta et al. (2017b) presented a new ensemble sensitivity technique, called ensemble forecast sensitivity to observation error covariance (EFSR), that allows for estimating how forecast errors would change by perturbing a prescribed observation error covariance matrix, thereby enabling systematic tuning of the observation error covariance for new observing systems. The EFSO-based data selection presented in this study together with EFSR can thus provide a framework for accelerating assimilation development of new observations aided by the ensemble forecast sensitivity diagnostics.
The GFS-LETKF code with the EFSO computation functionality is available at https://github.com/takemasa-miyoshi/letkf.
The TMPA data used in this study are TRMM 3B42, version 7, available at the NASA website, https://pmm.nasa.gov/data-access/downloads/trmm. The rawinsonde observations are extracted from the NCEP BREPBUFR observation data set, available at https://rda.ucar.edu/datasets/ds337.0/. The ERA-Interim reanalysis data used for verification are available at http://apps.ecmwf.int/datasets/.
The supplement related to this article is available online at: https://doi.org/10.5194/npg-25-129-2018-supplement.
GYL and EK initiated this study at University of Maryland. GYL developed the global precipitation assimilation system with the low-resolution NCEP GFS model and developed the idea of “EFSO from offline assimilation”. He then designed and conducted all experiments after moving to RIKEN Advanced Institute for Computational Science (AICS). DH initially implemented the EFSO diagnostics into the system and shared valuable thoughts on the methodology of using EFSO for assimilation development. EK and TM were the advisors of this work. EK provided insightful suggestions on this study and improved the final manuscript. TCC shared thoughts on the interpretation of the EFSO and the relationship between this study and the proactive QC method.
The authors declare that they have no conflict of interest.
This study was initially conducted at University of Maryland, partially
supported by NASA grants NNX11AH39G, NNX11AL25G, and NNX13AG68G; NOAA grants
NA10OAR4310248, CICS-PAEKLETKF11, and NA16NWS4680009; and the Office of Naval
Research (ONR) grant N000141010149 under the National Oceanographic
Partnership Program (NOPP). After Guo-Yuan Lien moved to RIKEN AICS, the work
continued with additional support by JST CREST Grant JPMJCR1312 and the Japan
Aerospace Exploration Agency (JAXA) Precipitation Measuring Mission (PMM).
The authors thank Yoichiro Ota for providing initial EFSO code
implemented in another DA system as a reference of the EFSO implementation.
We also thank two anonymous referees and the editor, Zoltan Toth,
for their insightful comments and
suggestions.Edited by: Zoltan Toth
Reviewed by: two
anonymous referees
Bauer, P., Ohring, G., Kummerow, C., and Auligne, T.: Assimilating satellite observations of clouds and precipitation into NWP models, B. Am. Meteor. Soc., 92, ES25–ES28, https://doi.org/10.1175/2011BAMS3182.1, 2011.
Cardinali, C.: Monitoring the observation impact on the short-range forecast, Q. J. Roy. Meteor. Soc., 135, 239–250, https://doi.org/10.1002/qj.366, 2009.
Ehrendorfer, M., Errico, R. M., and Raeder, K. D.: Singular-vector perturbation growth in a primitive equation model with moist physics, J. Atmos. Sci., 56, 1627–1648, https://doi.org/10.1175/1520-0469(1999)056>1627:SVPGIA<2.0.CO;21999.
Errico, R. M., Bauer, P., and Mahfouf, J.-F.: Issues regarding the assimilation of cloud and precipitation data, J. Atmos. Sci., 64, 3785–3798, https://doi.org/10.1175/2006JAS2044.1, 2007.
Geer, A. J.: Significance of changes in medium-range forecast scores, Tellus A, 68, 30229, https://doi.org/10.3402/tellusa.v68.30229, 2016.
Gelaro, R. and Zhu, Y.: Examination of observation impacts derived from observing system experiments (OSEs) and adjoint models, Tellus A, 61, 179–193, https://doi.org/10.1111/j.1600-0870.2008.00388.x, 2009.
Gelaro, R., Langland, R. H., Pellerin, S., and Todling, R.: The THORPEX observation impact intercomparison experiment, Mon. Weather Rev., 138, 4009–4025, https://doi.org/10.1175/2010MWR3393.1, 2010.
Hotta, D., Chen, T.-C., Kalnay, E., Ota, Y., and Miyoshi, T.: Proactive QC: a fully flow-dependent quality control scheme based on EFSO, Mon. Weather Rev., 145, 3331–3354, https://doi.org/10.1175/MWR-D-16-0290.1, 2017a.
Hotta, D., Kalnay, E., Ota, Y., and Miyoshi, T.: EFSR: Ensemble forecast sensitivity to observation error covariance, Mon. Weather Rev., 145, 5015–5031, https://doi.org/10.1175/MWR-D-17-0122.1, 2017b.
Huffman, G. J., Bolvin, D. T., Nelkin, E. J., Wolff, D. B., Adler, R. F., Gu, G., Hong, Y., Bowman, K. P., and Stocker, E. F.: The TRMM Multisatellite Precipitation Analysis (TMPA): Quasi-global, multiyear, combined-sensor precipitation estimates at fine scales, J. Hydrometeorol., 8, 38–55, https://doi.org/10.1175/JHM560.1, 2007.
Huffman, G. J., Adler, R., Bolvin, D., and Nelkin, E.: The TRMM Multi-Satellite Precipitation Analysis (TMPA), in Satellite Rainfall Applications for Surface Hydrology, edited by: Gebremichael, M. and Hossain, F., 3–22, Springer Netherlands, 2010.
Hunt, B. R., Kostelich, E. J., and Szunyogh, I.: Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter, Physica D, 230, 112–126, https://doi.org/10.1016/j.physd.2006.11.008, 2007.
Ishibashi, T.: Optimization of error covariance matrices and estimation of observation data impact in the JMA global 4D-Var system, CAS/JSC WGNE Research Activities in Atmospheric and Oceanic Modelling, available at: http://wgne.meteoinfo.ru/publications/wgne-blue-book/ , 40, 1–11, 2010.
Janiskova, M. and Cardinali, C.: On the impact of the diabatic component in the Forecast Sensitivity Observation Impact diagnostics, Tech. Memo. 786, ECMWF, 18 pp., 2016.
Kalnay, E., Ota, Y., Miyoshi, T., and Liu, J.: A simpler formulation of forecast sensitivity to observations: application to ensemble Kalman filters, Tellus A, 64, 18462, https://doi.org/10.3402/tellusa.v64i0.18462, 2012.
Kotsuki, S., Miyoshi, T., Terasaki, K., Lien, G.-Y., and Kalnay, E.: Assimilating the global satellite mapping of precipitation data with the Nonhydrostatic Icosahedral Atmospheric Model (NICAM), J. Geophys. Res. Atmos., 122, 631–650, https://doi.org/10.1002/2016JD025355, 2017.
Langland, R. H. and Baker, N. L.: Estimation of observation impact using the NRL atmospheric variational data assimilation adjoint system, Tellus, 56A, 189–201, 2004.
Li, H., Liu, J. and Kalnay, E.: Correction of “Estimating observation impact without adjoint model in an ensemble Kalman filter”, Q. J. Roy. Meteor. Soc., 136, 1652–1654, https://doi.org/10.1002/qj.658, 2010.
Lien, G.-Y., Kalnay, E., and Miyoshi, T.: Effective assimilation of global precipitation: Simulation experiments, Tellus A, 65, 19915, https://doi.org/10.3402/tellusa.v65i0.19915, 2013.
Lien, G.-Y., Kalnay, E., Miyoshi, T., and Huffman, G. J.: Statistical properties of global precipitation in the NCEP GFS model and TMPA observations for data assimilation, Mon. Weather Rev., 144, 663–679, https://doi.org/10.1175/MWR-D-15-0150.1, 2016a.
Lien, G.-Y., Miyoshi, T., and Kalnay, E.: Assimilation of TRMM Multisatellite Precipitation Analysis with a low-resolution NCEP Global Forecast System, Mon. Weather Rev., 144, 643–661, https://doi.org/10.1175/MWR-D-15-0149.1, 2016b.
Liu, J. and Kalnay, E.: Estimating observation impact without adjoint model in an ensemble Kalman filter, Q. J. Roy. Meteor. Soc., 134, 1327–1335, https://doi.org/10.1002/qj.280, 2008.
Lorenc, A. C. and Marriott, R. T.: Forecast sensitivity to observations in the Met Office Global numerical weather prediction system, Q. J. Roy. Meteor. Soc., 140, 209–224, https://doi.org/10.1002/qj.2122, 2014.
Ota, Y., Derber, J. C., Miyoshi, T., and Kalnay, E.: Ensemble-based observation impact estimates using the NCEP GFS, Tellus A, 65, 20038, https://doi.org/10.3402/tellusa.v65i0.20038, 2013.
Sommer, M. and Weissmann, M.: Observation impact in a convective-scale localized ensemble transform Kalman filter, Q. J. Roy. Meteor. Soc., 140, 2672–2679, https://doi.org/10.1002/qj.2343, 2014.
Sommer, M. and Weissmann, M.: Ensemble-based approximation of observation impact using an observation-based verification metric, Tellus A, 68, 27885, https://doi.org/10.3402/tellusa.v68.27885, 2016.
Todling, R.: Comparing two approaches for assessing observation impact, Mon. Weather Rev., 141, 1484–1505, https://doi.org/10.1175/MWR-D-12-00100.1, 2013.
Tsuyuki, T. and Miyoshi, T.: Recent progress of data assimilation methods in meteorology, J. Meteor. Soc. Jpn., 85B, 331–361, https://doi.org/10.2151/jmsj.85B.331, 2007.
Zhang, X., Wang, H., Huang, X.-Y., Gao, F., and Jacobs, N. A.: Using adjoint-based forecast sensitivity method to evaluate TAMDAR data impacts on regional forecasts, Adv. Meteorol., 2015, 427616, https://doi.org/10.1155/2015/427616, 2015.