the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 13 Nov 2024
| 13 Nov 2024
Learning extreme vegetation response to climate drivers with recurrent neural networks
Francesco Martinuzzi
Miguel D. Mahecha
Gustau Camps-Valls
David Montero
Tristan Williams
Karin Mora
The spectral signatures of vegetation are indicative of ecosystem states and health. Spectral indices used to monitor vegetation are characterized by long-term trends, seasonal fluctuations, and responses to weather anomalies. This study investigates the potential of neural networks in learning and predicting vegetation response, including extreme behavior from meteorological data. While machine learning methods, particularly neural networks, have significantly advanced in modeling nonlinear dynamics, it has become standard practice to approach the problem using recurrent architectures capable of capturing nonlinear effects and accommodating both long- and short-term memory. We compare four recurrent-based learning models, which differ in their training and architecture for predicting spectral indices at different forest sites in Europe: (1) recurrent neural networks (RNNs), (2) long short-term memory networks (LSTMs), (3) gated recurrent unit networks (GRUs), and (4) echo state networks (ESNs). While our results show minimal quantitative differences in their performances, ESNs exhibit slightly superior results across various metrics. Overall, we show that recurrent network architectures prove generally suitable for vegetation state prediction yet exhibit limitations under extreme conditions. This study highlights the potential of recurrent network architectures for vegetation state prediction, emphasizing the need for further research to address limitations in modeling extreme conditions within ecosystem dynamics.
- Article
(4424 KB) - Full-text XML
- BibTeX
- EndNote





The recent increase in atmospheric CO2 concentrations only partly reflects anthropogenic emissions, as oceans and land ecosystems contribute to the carbon uptake (Eggleton, 2012; Le Quéré et al., 2018; Canadell et al., 2021). Forests and other terrestrial ecosystems absorb nearly a third of human-made emissions and establish an essential negative feedback within the global carbon cycle (Friedlingstein et al., 2006; Le Quéré et al., 2009). However, during extreme events such as persistent droughts and heat waves, ecosystems may release more CO2 into the atmosphere than they absorb, e.g., due to suppressed photosynthesis (von Buttlar et al., 2018; Sippel et al., 2018). Variations in the frequency and intensity of these events can lead to long-lasting environmental modifications, contributing to positive feedback loops that aggravate climate warming (Reichstein et al., 2013). For example, increases in drought intensities have been consistently linked to excess tree mortality (Grant, 1984; Fensham and Holman, 1999; Liang et al., 2003; Dobbertin et al., 2007), negatively impacting carbon sequestration potential (Van Mantgem et al., 2009). The frequency, intensity, and duration of extremes over the next few decades are expected to increase compared to previous decades (Seneviratne et al., 2021). Therefore, understanding how vegetation responds to climate drivers becomes crucial in land–atmosphere modeling (Mahecha et al., 2022, 2024).
The vegetation response changes over time, showing seasonal patterns and long-term trends (Slayback et al., 2003; Mahecha et al., 2010; De Jong et al., 2011, 2012; Linscheid et al., 2020; Schulz et al., 2024; Mora et al., 2024). This variability is partially inherited by climate variations, reflected in the dynamics of solar radiation, air temperature, and precipitation, which affect vital biosphere processes such as phenology, photosynthesis, respiration, and growth. However, the relationship between climate and biosphere involves complex interactions due to the nonlinear response of vegetation to climate drivers (Foley et al., 1998; Zeng et al., 2002; Papagiannopoulou et al., 2017; Schulz et al., 2024). In particular, ecosystems exhibit long-range memory effects (Johnstone et al., 2016; Pappas et al., 2017) that can put their resilience at risk (De Keersmaecker et al., 2016). For instance, extreme heat waves can negatively impact leaf growth and development that, when coupled with drought conditions, can induce tree mortality (Teskey et al., 2015). Extreme climate events can cause irreversible damage and reduce an ecosystem's resilience (Ghazoul et al., 2015; Bastos et al., 2023; Mahecha et al., 2024). These factors collectively contribute to the challenge of predicting the vegetation and climate system.
Traditionally, terrestrial biosphere models have played a pivotal role in simulating ecosystem responses to climate variability (Sitch et al., 2003; Krinner et al., 2005). These process-based models are inherently complex, as they do not only have to adhere to physical laws but also need to reflect biotic responses that are derived from empirical observations and difficult to parametrize. Hence, terrestrial biosphere models sometimes fall short in capturing the complexity of ecosystem dynamics accurately (Papale and Valentini, 2003). It has therefore been discussed to what degree machine learning (ML) techniques can alleviate these issues (Reichstein et al., 2019). These methods represent powerful modeling tools that are able to find patterns in data that process-based models may not be able to capture. As a consequence, applications of ML models in land–atmosphere interactions are wide-ranging, for example local-to-global flux upscaling (Papale et al., 2015; Jung et al., 2020; Nelson et al., 2024), quantifying dynamic properties of seasonal behavior (Schulz et al., 2024; Mora et al., 2024), or the prediction of ecosystem states (Kang et al., 2016; Zhang et al., 2021; Peng et al., 2022). More specifically, recurrent neural networks (RNNs) represent suitable architectures for modeling complex Earth system dynamics (Reichstein et al., 2019; Camps-Valls et al., 2021b) due to their ability to encode nonlinear temporal dependencies (Bengio et al., 1994; LeCun et al., 2015) and capacity to retain information from past inputs (Elman, 1990).
However, RNNs have technical challenges associated with gradient-based training, including the issues of vanishing and exploding gradients, which impede network convergence (Hochreiter, 1998; Pascanu et al., 2013). To tackle these problems, specialized RNN architectures have been developed. Long short-term memory (LSTM) networks (Hochreiter and Schmidhuber, 1997) maintain the gradient-based training of the original RNNs while addressing these problems through gating mechanisms. Another architecture, the gated recurrent unit (GRU) (Cho et al., 2014), further refines the LSTM approach, providing comparable results with computational efficiency (Chung et al., 2014). In contrast, echo state networks (ESNs) employ a distinct approach by training only the last layer through linear regression (Jaeger, 2001). The absence of derivatives guarantees non-vanishing or exploding gradients, offering an alternative training solution to gating. The improvements provided by both the gated models and the ESNs allowed the application of these models to different tasks such as rainfall–runoff modeling (Kratzert et al., 2018; Gauch et al., 2021), sea surface temperature estimation (Zhang et al., 2017; Walleshauser and Bollt, 2022), and chaotic systems' forecasting (Pathak et al., 2017, 2018; Vlachas et al., 2020; Chattopadhyay et al., 2020; Gauthier et al., 2022) among others.
Expanding on the utility of RNNs, particularly LSTMs, recent studies have demonstrated their effectiveness in addressing specific challenges within land–atmosphere interactions, modeling land fluxes from meteorological drivers (Reichstein et al., 2018). Further studies reinforced the suitability of RNN approaches for land–atmosphere interactions (Chen et al., 2021). In Besnard et al. (2019), the authors employ LSTMs to predict land fluxes from remote sensing data and climate variables to explore the memory effects of vegetation. Additionally, the work compares LSTMs with random forests, showing the better performance of deep learning models in this task. Further explorations in dynamic memory effects with LSTMs have been carried out by Kraft et al. (2019). Given the recent findings on the utility of RNNs and LSTMs in studying dynamics, it is timely to investigate if these tools can accurately predict extreme biosphere dynamics.
Can recurrent neural networks learn the vegetation's extreme responses to climate drivers? Recurrent architectures can embed the dynamics of target systems into their higher dimensional representation (Funahashi and Nakamura, 1993; Hart et al., 2020). When considering the nature of extremes in dynamical systems, they can be understood as specific regions of the phase space (Farazmand and Sapsis, 2019). Combining this with the embedding abilities of RNNs offers an explanation for the observed efficacy of ESNs and LSTMs in learning extreme events within controlled environments or “toy models” (Srinivasan et al., 2019; Lellep et al., 2020; Pyragas and Pyragas, 2020; Ray et al., 2021; Meiyazhagan et al., 2021; Pammi et al., 2023). However, the applicability of these findings to land–atmosphere interactions remains unclear. Unlike the systems investigated in previous studies, biosphere dynamics are characterized by stochasticity (Dijkstra, 2013), while their measurements present noise (Merchant et al., 2017). Therefore, exploring how recurrent architectures perform in the specific context of vegetation extremes in ecosystem dynamics is imperative.
To address this question, we investigate the ability of various recurrent architectures to model the response of vegetation states, i.e., spectral reflectance indices, to climate drivers. Vegetation interacts with sunlight, showing specific spectral responses that can be altered during extreme events such as heat waves. Vegetation indices, obtained from the spectral response through linear or nonlinear transformations, are used to quantify these changes, isolating vegetation properties from other influences such as soil background (Zeng et al., 2022); detailed lists of these indices are provided by Zeng et al. (2022) and Montero et al. (2023). Our study focuses on the normalized difference vegetation index (NDVI) (Rouse et al., 1974), which indicates vegetation greenness. To build a model that can accurately predict NDVI responses to climate conditions, we use climate-related variables, such as air temperature and precipitation, as inputs.
The goal of this study is threefold: (1) to further solidify the viability of the recurrent neural network approach to model ecosystem dynamics; (2) to investigate whether these models can capture extreme vegetation responses to climate drivers; and, finally, (3) to investigate whether a specific RNN architecture is more suited for these tasks. To evaluate the performance of the models, we use metrics such as the normalized root mean squared error (NRMSE) and symmetric mean absolute percentage error (SMAPE) in conjunction with information-theory-based measures, namely the entropy–complexity (EC) plots (Rosso et al., 2007). The latter approach quantifies each model's ability to capture the target dynamics. Using the model's residuals, defined as the difference between the prediction and the actual signal, the EC plots return an intuition of the model's ability to capture dynamics beyond the seasonality (Sippel et al., 2016). Additionally, we investigate whether recurrent architectures can effectively capture vegetation responses to extreme events. To our knowledge, no study has compared the performance of recurrent models in the context of extreme events or ecosystem dynamics.
The remainder of this paper is structured as follows. In Sect. 2.1, we present the data we used, including the site selection process and pre-processing steps. Next, in Sect. 2.2, we describe the architecture of the recurrent neural networks and formalize the task. Following this, Sect. 2.3 and 2.4 give a background on the methods of backpropagation training and echo state networks, respectively. In Sect. 2.5 we describe the procedure to identify extreme events in the NDVI time series. We detail the metrics used in the study in Sect. 2.6. More specifically, in Sect. 2.6.1, we introduce NRMSE and SMAPE; in Sect. 2.6.2, we illustrate the EC plots; finally, in Sect. 2.6.3, we describe the metrics used for evaluating model performance on predicting extreme events. We show our results in Sect. 3. In Sect. 3.1 we compare model performances using NRMSE and SMAPE. Additionally, in Sect. 3.2 we show the results for the EC plots. Finally, we illustrate the models' capability to predict extreme events in Sect. 3.3. We draw conclusions and discuss broader implications in Sect. 4.
2.1 Data and pre-processing
We used optical remote sensing data of forest sites to measure biosphere dynamics, specifically the normalized difference vegetation index (NDVI) (Rouse et al., 1974), which we define as the “target” variable. However, employing NDVI presents drawbacks (Camps-Valls et al., 2021a). Namely, it has a saturating and nonlinear connection to green biomass and responds to greenness rather than the actual plant photosynthesis process. Despite these limitations, this index has been used successfully for various purposes, including, but not limited to, evaluating ecosystem resilience (Yengoh et al., 2015) and tracking the decline of vegetation greenness in the Amazon forests (Hilker et al., 2014). Additionally, NDVI was shown to be a good indicator of vegetation response to extreme climate events (Liu et al., 2013).
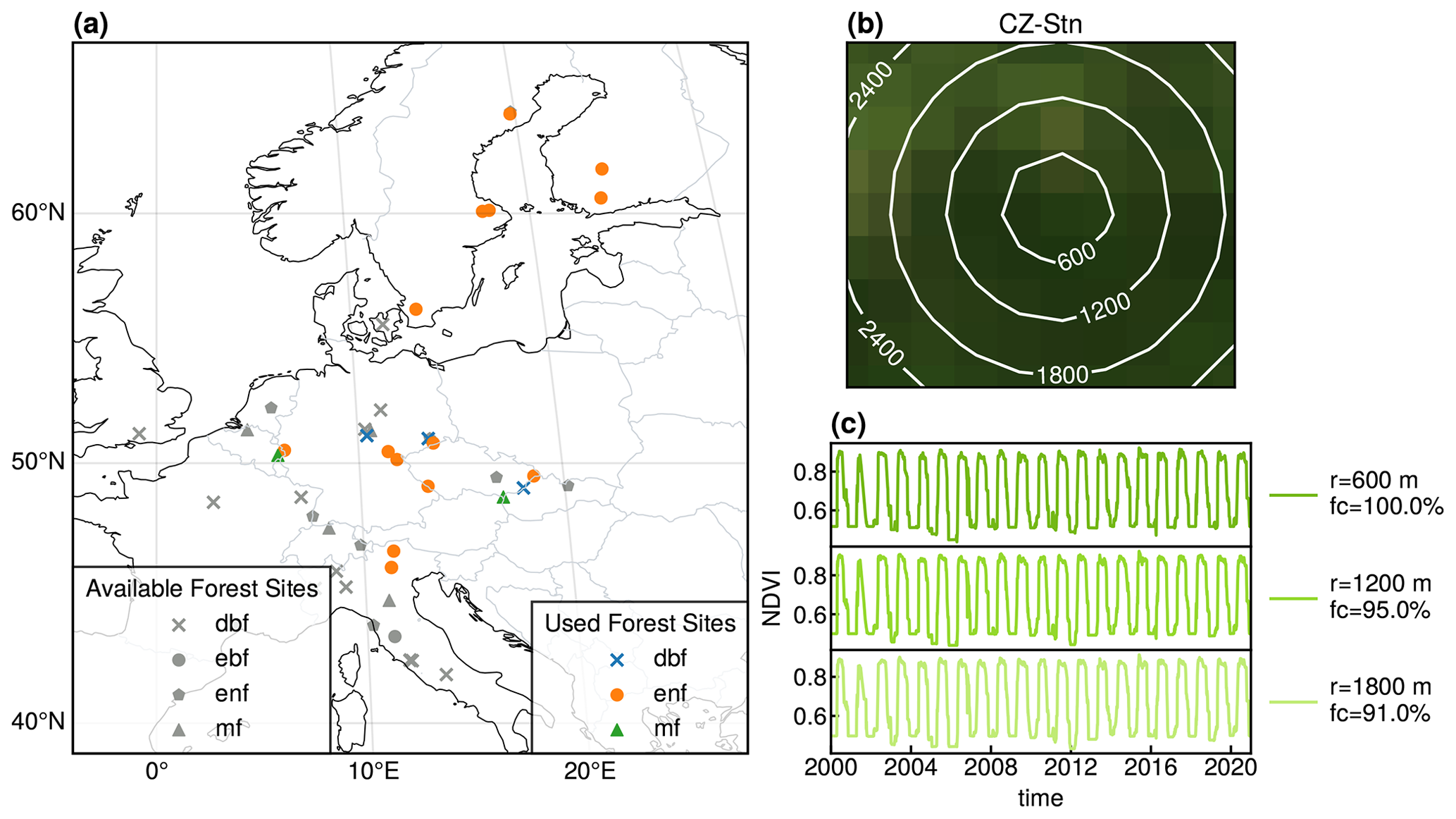
Figure 1Chosen locations and pre-processing. In (a), we show the available and used locations for the study and their forest type. We used locations with more than 80 % forest cover, not using the remaining ones depicted in gray in this figure. In (b), we show the process of including additional pixels into the cube for an example location (CZ-Stn). While different radii are shown, we use all the pixels in a single cube. Finally, in (c), we show the NDVI signal corresponding to the mean of the pixels in the area with radius r previously shown for the same example location. Additionally, it also indicates the percentage of the pixels that are flagged as forest (fc).
We used NDVI values obtained from the Moderate Resolution Imaging Spectroradiometer (MODIS) in the FluxnetEO dataset v1.0 (Walther et al., 2022). This dataset is a multi-dimensional array of values referred to as a data cube (Mahecha et al., 2020). It comprises a collection of labeled univariate time series at the geographic location of eddy covariance towers. Eddy covariance towers are specialized measurement stations designed to capture and quantify land–atmosphere fluxes and meteorological conditions, providing insights into ecosystem health and functionality (Aubinet et al., 2012). The FluxnetEO datasets are gap-filled using measurements from eddy covariance towers, thus providing a higher-resolution product in time and space compared to the raw MODIS data.
The data cubes in the dataset present a spatial resolution of 500 m and a daily temporal resolution, covering the period of 2000–2020 (inclusive). The cubes span a pixel of size 3 km×3 km centered on the eddy covariance towers in each location. We further pre-processed the data by averaging the NDVI for each time step as the mean of all the pixels within the cube; see Fig. 1. Additionally, we smoothed the signal using a Savitzky–Golay filter (Savitzky and Golay, 1964; Steinier et al., 1972) with a 7 d window and a polynomial order of 3 (Chen et al., 2004) to eliminate any potential artifacts caused by noise.
We selected study sites based on their forest cover percentage, ensuring over 80 % forest cover in each cube; see Fig. 1. The forest masks were obtained from the Copernicus Global Land Service (CGLS) product (Buchhorn et al., 2020), which has a resolution of 100 m. These sites represent three different forest types: evergreen broadleaved forests (EBF), mixed forests (MF), and deciduous broadleaved forests (DBF). We chose to study forest sites because of their importance to the carbon cycle and because they are the least affected by human influence at a daily timescale. Consequently, we employed the described approach, detailed in Fig. 1, to minimize further imperfections in the vegetation signal caused by human intervention. As a result of this selection criterion, the number of study sites is reduced from 42 to 20.
In this study, we used climate variables as input variables to predict the target variable. Following machine learning terminology, we will refer to them as “features”. We selected air temperature (mean, minimum, and maximum), mean sea level pressure, mean global solar radiation, and precipitation as features. The climate data were obtained from the E-OBS product v26.0e (Cornes et al., 2018). Based on in situ observations, this dataset is spatially interpolated to cover most of the European continent. The spatial resolution is 0.1° (11.1 km×11.1 km), and the temporal resolution is daily. The time length of the feature variables is identical to the target variable and spans from 2000 to 2020 (inclusive). We split the data for training and testing as follows: years from 2000 to 2013 (inclusive) for training and validation. We use the remaining years, from 2014 to 2020, for testing, resulting in a 67 % and 33 % training and testing split ratio.
2.2 Approach and models
We aim to learn the NDVI behavior of forests as a proxy for ecosystem response to climate drivers. We use air temperature (mean, minimum, maximum), precipitation, pressure, and global solar radiation. We assume that the knowledge of the target variable is constrained to a certain period, after which only the features are available. Our goal is to build a model that, using those features, can predict the target variable. This is obtained by training the models on the available time interval, which comprises the years 2000–2013 (inclusive) for this study. After the training, the models only use feature variables to predict the NDVI for the remaining period, 2014–2020. Further details for the training setup can be found in Appendix B.
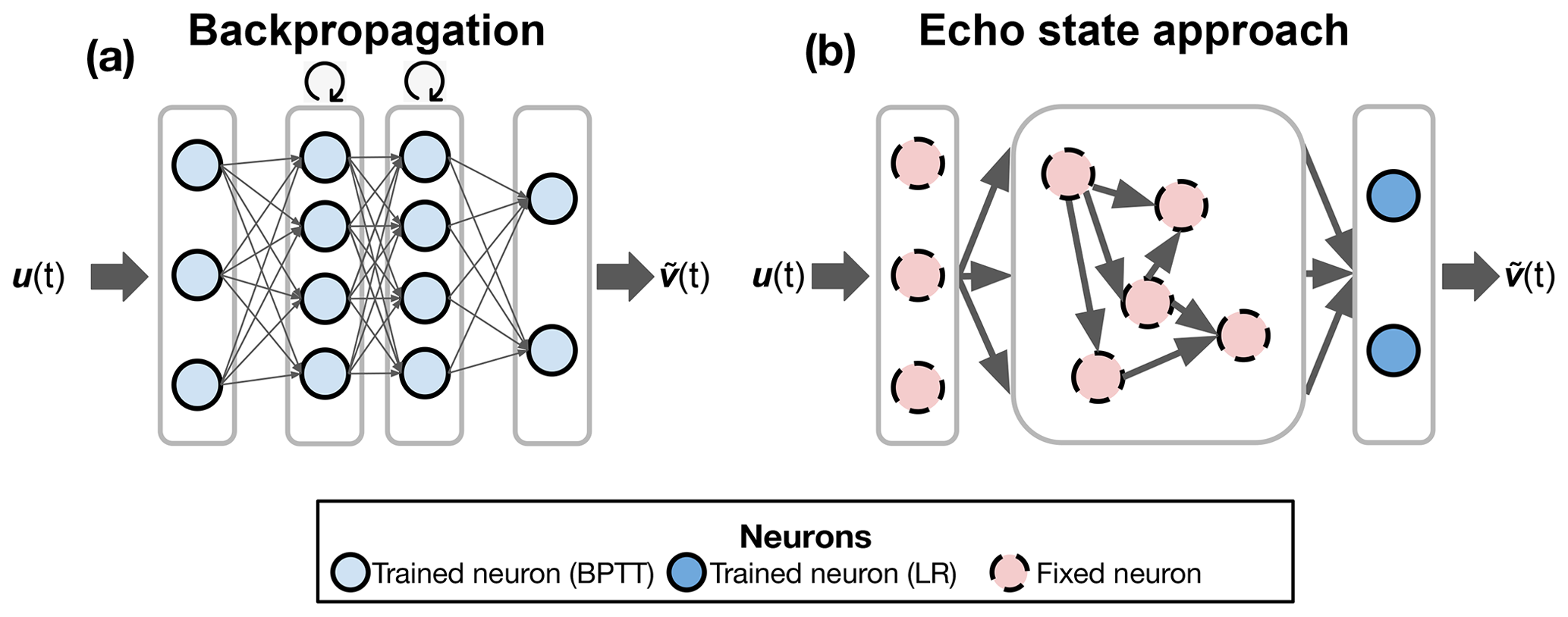
Figure 2Training methods. Both diagrams illustrate input and predicted data denoted by u(t) and , respectively. Diagram (a) presents the conventional approach used by RNNs, GRUs, and LSTMs, involving backpropagation through time (BPTT). In contrast, diagram (b) portrays the training methodology of ESNs. The initial two layers are randomly generated and remain untrained, while only the final layer undergoes one-shot training via linear regression (LR). Training encompasses the input layer (comprising three neurons in this instance), stacked recurrent layers (two layers, each with four neurons), and the output layer (two neurons). All these neurons are trained through backpropagation. The circular arrow atop signifies the recurrent layers. The number of neurons and internal recurrent layers serves visualization purposes only.
The task can be formalized as follows. We aim to approximate the target variable using input data u(t). In the context of this study, we retain a unidimensional approach with dv=1, given that we have a single target variable, the NDVI. We assume that both u(t) and v(t) are components of the same dynamical system. Under this assumption, the behavior v(t) is influenced by u(t), allowing us to leverage the information from u(t) to estimate v(t). Our setup consists of two sets of data, u(t) and v(t), which can be measured over a given time period . After time step t=T only u(t) remains measurable, and the goal of the recurrent architectures is to create a model efficient in modeling v(t) based solely on the available u(t) data (Lu et al., 2017). To summarize, the models use meteorological data of a given day to predict the response of the vegetation on that same day. Despite having different training methods, all the models in this study are built to perform this task.
We consider four different recurrent architectures: recurrent neural networks (RNNs), long short-term memory networks (LSTMs), gated recurrent-unit networks (GRUs), and echo state networks (ESNs). Each of these models presents an internal state , which encodes the temporal dependencies of the input data , where du=6 in our study, representing the dimension of the input data. The internal size dx is chosen to be dx>du. A defining feature of these architectures is the recursive transmission of internal states, facilitating historical data retention as the model progresses through subsequent steps. This evolution of the generic RNN model is given by (Sutskever, 2013)
where θ represents the weights and biases of the model, also called parameters, and H represents a generic RNN update function.
2.3 Training – backpropagation through time
Deep learning models like feed-forward neural networks (FFNNs) adjust their weights at each time step during training using a method called backpropagation (BP) (Rumelhart et al., 1986). BP relies on a “loss function” ℒ given by , where θ stands for the network's parameters. Leveraging the loss function, BP minimizes the difference between the model's predicted and actual output by adjusting the model's weights. To do this, BP calculates the gradient of the loss function with respect to each weight and then updates the network weights in a direction that minimizes the loss. One of the most common approaches to minimizing the loss function is stochastic gradient descent (SGD) (Bottou, 2012). However, one of BP's limitations is that it does not account for time dependencies.
For time-dependent models, such as RNNs, LSTMs, and GRUs, handling sequential data poses additional challenges. Backpropagation through time (BPTT) (Rumelhart et al., 1986) is a specialized training method designed for these architectures (Werbos, 1990). Central to BPTT is the notion of “unrolling” the network over time, effectively transforming it into a FFNN where backpropagation can be applied. This allows the model to calculate errors and update weights across the entire sequence, making it possible to capture long-term dependencies and patterns in time series data.
However, applying BPTT across the entire sequence can be computationally intense and time-consuming. Moreover, it often reduces the error to a very small amount by the end of the sequence. To avoid this issue, we use a truncated version of BPTT, limiting the backpropagation to a fixed number of steps, denoted by k (Williams and Zipser, 1995), which is smaller than the total number of training time steps, T (Aicher et al., 2020).
This truncated approach ensures efficiency but requires transferring the last hidden state from the truncated section to the initial state in the following sequence. This step maintains some memory and ensures the network's training process continuity.
The final output of all the models considered in this study comes from a feed-forward layer. The parameters of this layer are also trained using BP. The following equation describes the feed-forward layer:
where is the predicted output, is the hidden state of the model at time step t, is the weight matrix, and is a bias vector. Additionally, σ represents the activation function. This procedure is illustrated graphically in Fig. 2a. Finally, the full details of the models are given in Appendix A1 for the RNNs, Sect. A2 for the LSTMs, and Sect. A3 for the GRUs. The RNNs, LSTMs, and GRUs have been implemented using the PyTorch library (Paszke et al., 2019) accessed through Skorch (Tietz et al., 2017).
2.4 Training – echo state approach
Echo state networks (ESNs; Jaeger, 2001), along with liquid state machines (Maass et al., 2002), belong to the larger family of reservoir computing (RC) models, based on a shared theoretical background (Verstraeten et al., 2007). The fundamental idea of ESNs is to project the training data into a higher-dimensional, nonlinear system named the “reservoir” through an input layer. This process transforms the input data into vectors called “states”. After the data pass through the reservoir, the states are collected. The model is then trained by regressing these states against the target data.
More specifically, the ESNs have three layers: an input layer Win, a reservoir layer W, and an output layer Wout. A distinctive feature of ESNs is that the weights in the input and reservoir layers are fixed. These weights are generated randomly and do not change during training. This approach contrasts with conventional neural networks, where weights are continuously updated during training to reduce errors. For each training time step , the hidden states, indicated as x(t), are preserved and accumulated in a matrix . Indicated as a “state matrix”, this matrix effectively represents the system's dynamics. The last layer of the ESN is obtained through a linear regression operation that uses the states matrix to generate a feed-forward layer, creating the network's output layer:
where I is the identity matrix, and β is a regularization coefficient. The matrix is generated with the desired output stacked column-wise. While layers of recurrent models trained through BPTT can be stacked, ESNs are usually computed from a single inner layer (reservoir).
The construction and training of the ESN allow for the faster computational time of all the proposed models while also solving the vanishing and exploding gradients since no derivatives are taken at any step of the process. An illustration of the ESN approach to training is provided in Fig. 2b. The full details for the ESNs are given in Appendix A4. For the implementations of the ESNs, we relied on the Julia package ReservoirComputing.jl (Martinuzzi et al., 2022).
2.5 Anomalies and extremes in vegetation
In this study, we adopt the approach outlined by Lotsch et al. (2005) to define anomalies based on the seasonal variability observed in the signal. The process described in this section is depicted in Fig. 3. The anomalies at a given time l, denoted by A(l), are defined as follows:
Here, s(l) represents the signal at time l, is the mean of the signal at that time, and σ(l) refers to its standard deviation. In this context, the time variable l denotes the specific day of the year, i.e., the third of March, and is determined based on a multi-year mean. The normalization process ensures that the signal exhibits a zero mean, which facilitates identifying extreme events as data points that fall outside a specified distribution range.
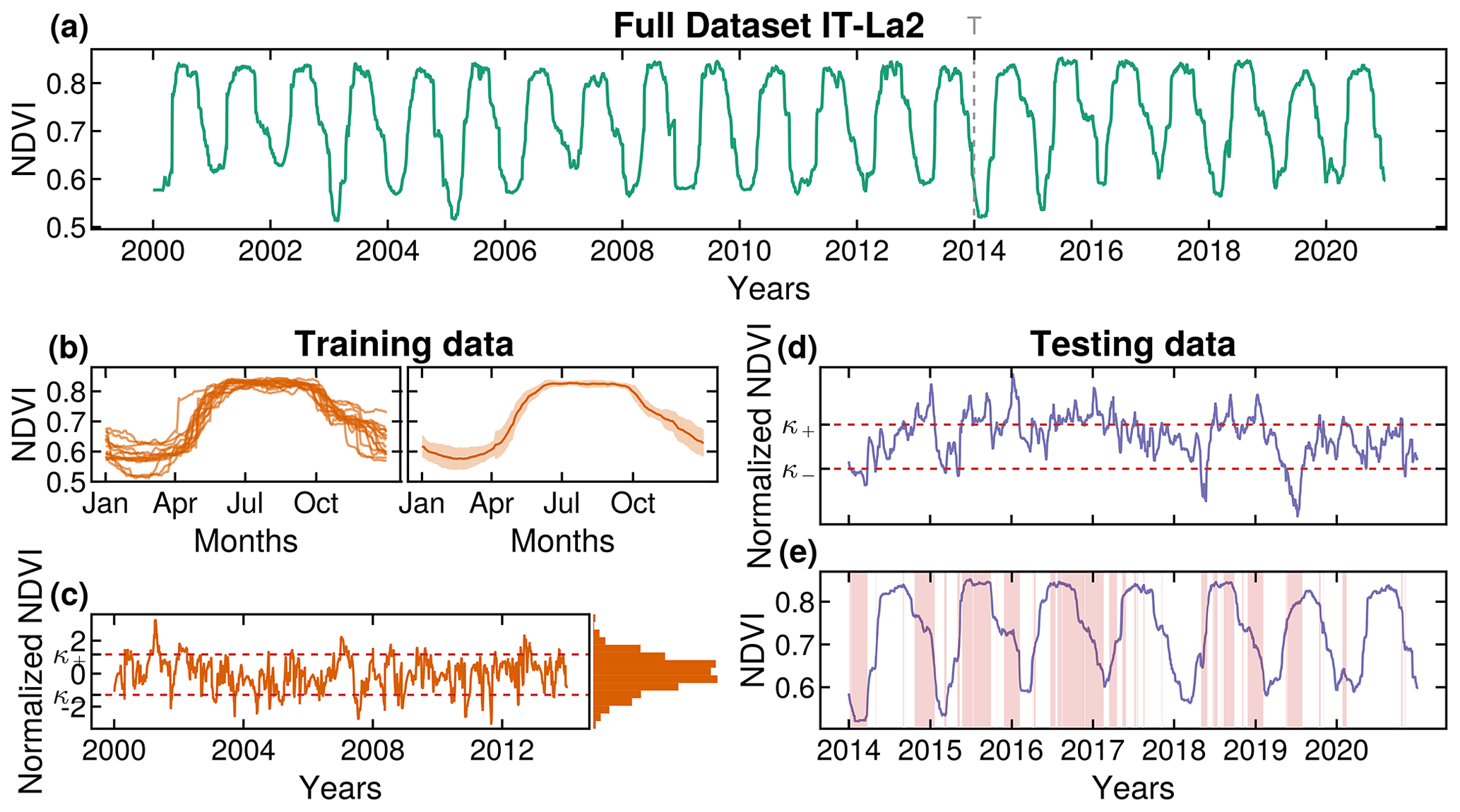
Figure 3Definition of extreme events. In (a), the NDVI of the dataset is plotted at an example location, IT-La2. The dotted gray line in 2014 represents the separation between training and testing data. The training data have length T (dotted line). In (b), we show each yearly cycle of the training data: on the left are the full signals, and on the right are the mean and standard deviation (SD). In (c), we show the result of the normalization of the training dataset using the mean and SD obtained in the previous step. At this stage, we also define the quantile (fixed at 0.90 in this example) and define the values of the thresholds κ+ and κ−. These values are then used in (d), where we identify the extremes in the normalized testing data. The normalization is also done using the mean and SD of the training data. Finally, in (e), the testing data are again shown in their raw form to showcase the extreme response of the vegetation. The extreme responses are highlighted by a red-shaded area.
After normalizing the data and delineating the anomalies, we characterize extreme events as data points falling outside a specific quantile, chosen to be 0.90, 0.91, …, or 0.99. Based on the selected quantile, we define two threshold parameters κ+ and κ− to represent positive and negative extremes, respectively. We determine these parameters individually for each site involved in our study.
During the training phase, which spans 2000 to 2014, we determine the threshold values κ+ and κ−. We apply these threshold values to the test dataset comprising the years from 2014 to 2020 to determine the extreme events in this latter dataset. The normalization of the data in the test datasets is done with the mean and SD values obtained from the training dataset.
2.6 Metrics
2.6.1 General metrics
In this study, we evaluated the predictive accuracy of our model using two primary metrics: the normalized root mean square error (NRMSE) and the symmetric mean absolute percentage error (SMAPE).
The NRMSE is derived from the root mean square error (RMSE) (Hyndman and Koehler, 2006) and is defined as
where v(t) represents the observed target variable at the tth observation among a total of N observations, and is the corresponding model prediction. To facilitate comparisons across different sites, we normalized this metric using the range of the observed data, which is computed as the difference between the maximum vmax and minimum vmin observed values, with .
In addition to NRMSE, we use SMAPE to assess the predictive performance of our model. SMAPE, which is a dimension-agnostic measure, is given by the formula
where n denotes the number of observations. This metric was chosen based on its ability to provide a symmetric measurement of the absolute percentage error, thereby affording a balanced view of the forecast accuracy (Makridakis, 1993; Hyndman and Koehler, 2006). Both of the metrics proposed in this section indicate better model performance as their value approaches zero.
2.6.2 Entropy–complexity plots
In this study, we also use information-theory-based quantifiers to analyze the model's residuals, defined as the differences between the model's prediction and the actual measurements. Based on the approach proposed by Sippel et al. (2016), we employ entropy–complexity (EC) plots. These plots return a visual representation of the amount of information still present in the residuals. Higher information content would indicate that the models do not sufficiently approximate the target variable. On the other hand, values of EC closer to white noise would suggest that the models fully reproduce the target variable's behavior. We illustrate this approach, closely following the exposition provided by Sippel et al. (2016).
To generate the EC plots, we consider a metric ℋ[P] of a probability distribution , with N possible states and with , to quantify the information content of a time series. One such metric is the Shannon entropy 𝒮[P],
which is maximized for the uniform distribution . We can then define the normalized entropy
which is the first metric used in the EC plots. In addition to the information content of a time series, we are interested in quantifying the complexity 𝒞[P]. Following Lopez-Ruiz et al. (1995), we use a definition of complexity 𝒞[P], which is the product of a measure of information, such as entropy ℋ[P], and a measure of disequilibrium 𝒬J[P,Pe].
In this context, disequilibrium takes the meaning of distance from the uniform distribution of the available states of a system. The definition of disequilibrium 𝒬J[P,Pe] makes use of the Jensen–Shannon divergence 𝒥[P,Pe], which quantifies the difference between probability distributions (Grosse et al., 2002), and it is defined as
where 𝒬0 is a normalization constant, (Lamberti et al., 2004; Rosso et al., 2007), chosen such that .
The computations of entropy and complexity rely on the probability distribution associated with the data. To determine this distribution, we leverage the method proposed by Bandt and Pompe (2002), which analyzes time series data by comparing neighboring values. It involves dividing the data into a set of patterns based on the order of the values and then calculating the probability of each pattern occurring (Rosso and Masoller, 2009). The pattern separation is obtained by embedding the time series in a D dimensional space with a time lag τ. We set D=6 and τ=1, as proposed by Rosso et al. (2007) and Sippel et al. (2016). The complexity measure's theoretical upper and lower bounds can now be computed (Martin et al., 2006) and are shown in the plots. The calculations of the EC plots were performed with the Julia package ComplexityMeasures.jl (Haaga and Datseris, 2023) from DynamicalSystems.jl (Datseris, 2018).
2.6.3 Extremes as binary events
To analyze extreme events, we set thresholds κ+ and κ−, as described earlier (in Sect. 2.5), to identify values as either extremes or not extremes. We adopt this binary approach for both the observed data and the data predicted by the models.
Following the method outlined by Hogan and Mason (2011), we classify the outcomes into four categories: hits a, where the model correctly identifies an extreme event; false alarms b, where the model incorrectly flags a value as an extreme event; misses c, where the model fails to identify an extreme event; and correct rejections d, where the model correctly identifies a non-extreme event.
Given n observation points, we employ the following metrics to assess the model's performance on detecting extremes, (Barnes et al., 2009). We define the probability of detection (POD) as the ratio of correctly identified extreme events and the total number of extreme events, the probability of false detection (POFD) as the ratio of incorrectly flagged extreme events and all events that are not extreme, the probability of false alarms (POFA) as the ratio of false alarms and all predicted extreme events, and the proportion correct (PC) as the ratio of all accurate predictions (both hits and correct rejections) and the total number of observations, given by
respectively. These metrics are standard tools for evaluating deep learning models for predicting atmospheric variables such as wind speed (Scheepens et al., 2023) and precipitation (Shi et al., 2015).
In the following, we first compare the different models by standard evaluation metrics such as the normalized root mean squared error, NRMSE, and the symmetric mean absolute percentage error, SMAPE (Sect. 3.1). Second, we extend the comparison to information-theoretic quantifiers in the entropy–complexity (EC) plane (Sect. 3.2). We perform this comparison for two cases: (i) the full-time series (FS), which encompasses all data points in the year, and (ii) the meteorological growing season (GS), which encompasses the months between May and September only. This division helps us differentiate the models' ability to capture the seasonal cycle, dominated by an oscillation, from their performance in the more stable growing season conditions, where more minor variations are likely harder to represent. Last, we focus on extreme events and compare the models' performance on extreme events in Sect. 3.3.
3.1 Comparison of prediction accuracy
We present our results in Table 1, showing that the ESN outperformed all other models for both the FS and GS signals, closely followed by the LSTM. While the GRU exhibited comparable results to the LSTM for the FS signal, the differences became more pronounced in the GS signal. In contrast, the RNN consistently delivered the least favorable results across the board and exhibited the highest standard deviation (SD) among the analyzed models. In Fig. C1, we include the comparison of these metrics per site, which shows great variation in the models' performance across different sites.
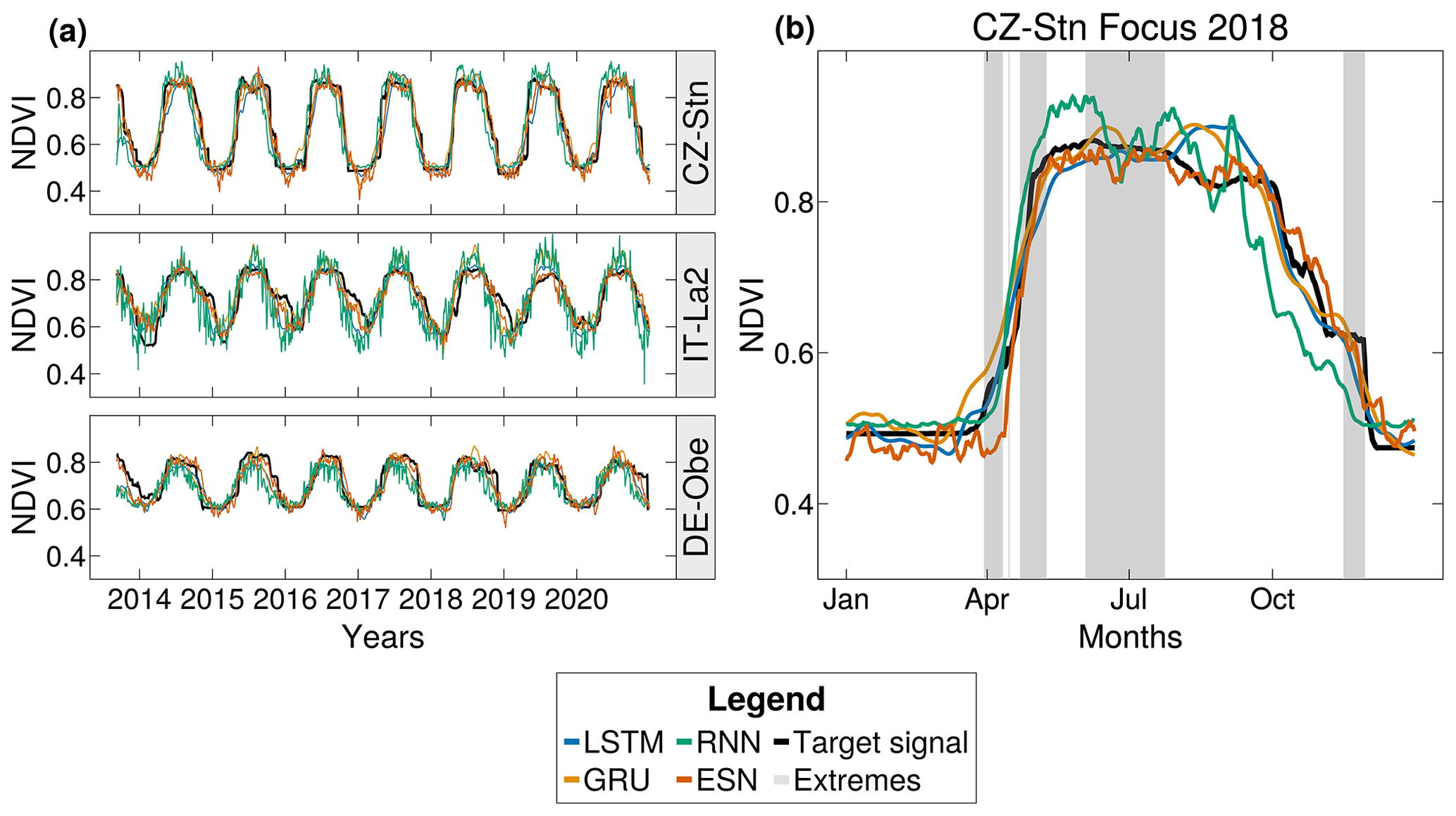
Figure 4Time series and predictions for selected locations. This figure illustrates the predictive performance of four distinct recurrent architectures at specified NDVI time-series locations. The target time series is shown in black, while the predictions only use a singular run from a set of 100 per model. Panel (a) delineates the results obtained at three selected locations: Germany, Italy, Czech Republic (CZ-Stn). Subsequently, panel (b) offers a magnified view of the outcomes at the CZ-Stn location in 2018, highlighting the extremes defined by a 90 % threshold using a grayed-out area. It is pertinent to underline that the predictions generated by the RNNs carry considerable noise, thereby affecting the interpretations drawn from the entropy–complexity plots.
The performance rankings of the models remained consistent when transitioning from the FS signal to the GS signal. Notably, the SMAPE metric indicated increased accuracy for all models, while the NRMSE metric suggested decreased accuracy. Similarly, we observe a reduction in the SD for the SMAPE but an increase in the NRMSE. This increase is very noticeable in the GRU and RNN models.
The models generally exhibited similar performance, with the ESN yielding slightly better results and the RNN demonstrating the least accurate forecasts. The gated methods showed similar performances. While these metrics provide an initial picture of the models' performance in the task, the results do not indicate a clear best performer among the models. These similarities in the results' metrics emphasize the need for further exploration using alternative evaluation tools.
Table 1Accuracy of the models. The table illustrates the performance of the four different models across various scenarios. “FS” represents the “full season”, representing the full dataset used for predictions without isolating specific events or months. “GS” denotes the “growing season”, which encompasses the peak summer months in addition to May and September. Models with the highest accuracy in each category are highlighted using bold text. The arrows pointing down (↓) near the metric's name indicate that smaller values represent higher accuracy. The means are calculated as the average of 100 runs for each of the 20 different locations, and then the mean of these 20 location-derived means is shown. Similarly, the standard deviations are calculated for each location over the 100 runs and then averaged to provide the overall standard deviation for each metric. Bold font indicates the best-performing model.

3.2 Comparison of the entropy–complexity
Drawing from information theory, we use entropy–complexity (EC) plots (introduced in Sect. 2.6.2) to examine the residuals, defined as the differences between the model's predictions and measurements. Residuals convey valuable information about a model's performance. In an ideal scenario, where a model perfectly represents a system's dynamics, these residuals would resemble white noise and be positioned in the lower-right corner of the EC plane (Sippel et al., 2016).
Figure 5 shows the EC plots of the models' residuals. Additionally, we show the mean of these metrics per model architecture across all sites. We find that the residuals cluster by model across all locations, with minimal overlap between each model's clusters. The LSTM and GRU models occupy the curve's ascending left side, indicating the presence of more structure in the residuals. In contrast, the ESN and, to a greater extent, the RNN are positioned closer to the white noise region, implying less structure in the residuals.
Comparing the FS signal to the GS signal shows no apparent differences in the results, underscoring the consistency of model performance. Based on the position of RNN residuals in the EC plots, we would expect a substantially improved performance of these models compared to the other model architectures. However, inspecting the predicted time series suggests a different explanation: the RNN model predictions show large variability (Fig. 4, which obfuscates the underlying dynamics. Because the EC plots capture the resulting residuals' noise, one can misinterpret the positioning of RNNs as favorable results.
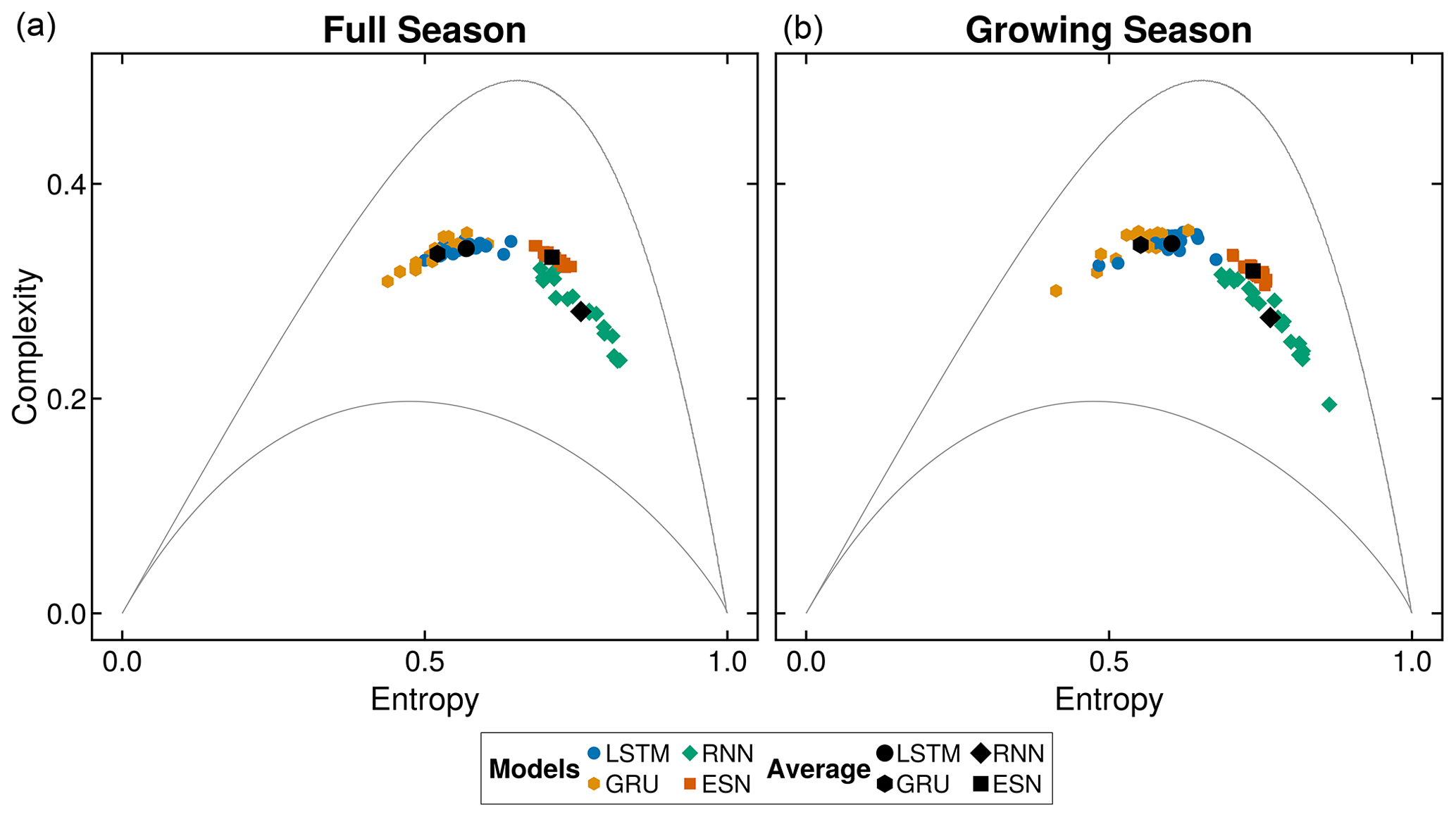
Figure 5Entropy–complexity curves of model's residuals. The entropy–complexity plots are computed from the residuals of each model at each location (color). The mean of each model's performance over all locations is shown in black. These plots visualize the amount of information and complexity left in the residuals. Ideal values would reside in the lower left corner, symbolizing white noise in the residuals. The gray lines denote the theoretical upper and lower bounds.
3.3 Extreme events
In this section, we use the metrics introduced in Sect. 2.6.3 to evaluate the models' ability to capture extreme vegetation dynamics. Fig. 6a shows a distinct division in the probability of detection (POD): the LSTM and ESN models exhibit low values, indicating an inability to detect extreme events. The RNN and GRU models show higher values, indicating better performance. However, the POD values are generally low for all models. Furthermore, all models display some level of overlap in the confidence bands. Finally, it is possible to observe a worsening of the results with increased quantiles. Figure 6b shows a lower probability of false detection (POFD) of ESNs, indicating that they perform better at avoiding the prediction of extremes when there are none compared to the other models. Conversely, the RNN, which predicts noisy behavior, as shown in Sect. 3.1, exhibits higher POFD values. The probability of false alarms (POFA; Fig. 6c) follows a similar pattern, with the ESN outperforming the other models. The GRU and LSTM display more comparable behaviors, while the RNN lags behind, showing the least favorable performance among all models. The displayed metric consistently leans towards the higher end of the potential value range. Like in the case of the POD, the values of the POFA get worse with each increase in the quantiles. Finally, Fig. 6d shows the probability of correctness (PC). The ESN leads the graph despite showing the lowest POD. Following closely are the LSTM and GRU, which exhibit similar performance. The RNN maintains the poorest performance across all metrics, emphasizing its limitations in capturing extreme vegetation dynamics.
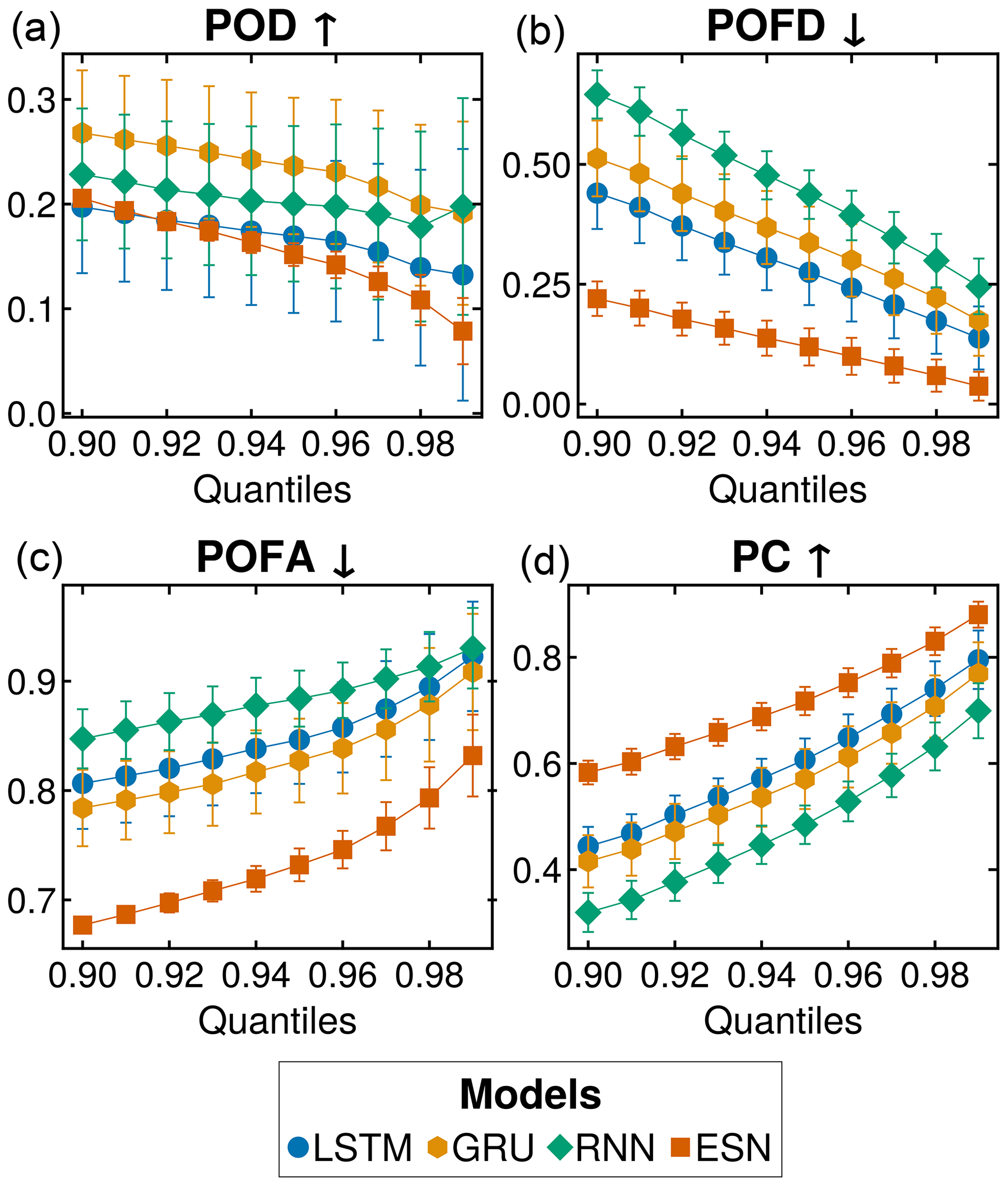
Figure 6Extremes as binary events across all sites. The results of quantiles spanning 0.90 to 0.99 are shown. All values are expressed as percentages. In (a), we show the detection percentage (POD), indicating how many extreme events have been detected. In (b), we show the percentage of false detection (POFD). In (c) we depict the probability of false alarms (POFA). Finally, in (d) we show the proportion correct (PC). The error bars represent the standard deviation over 100 simulations with different initializations for each model. The arrows (up ↑ and down ↓) by the metric's name indicate the direction of the optimal values.
To examine the prediction performance of extreme NDVI reduction during the summer season, we focus on June, July, and August using only κ−, showcased in Fig. 7. In Fig. 7a, we see the probability of detection (POD) for different models. The RNN performs best, outperforming the LSTM, GRU, and ESN, delivering similar results. Figure 7b shows the probability of false detection (POFD). Here, the RNN performs the worst, while the ESN stands out with the best values and the lowest standard deviation (SD) among all models. The gating-based models, LSTM and GRU, perform almost identically. We find similar performances among models in Fig. 7c. The ESN demonstrates a decrease in the probability of false alarms (POFA) values for the 0.92 quantiles. Any small gaps in performance observed for lower quantiles are effectively bridged at higher values. Finally, Fig. 7d illustrates the ESN as the top-performing model, exhibiting the lowest SD among the models. The gated models, LSTM and GRU, display similar performances, while the RNN ranks as the poorest-performing model in this analysis of NDVI summertime decreases. Figure C2 shows the variability of the results across all analyzed locations.
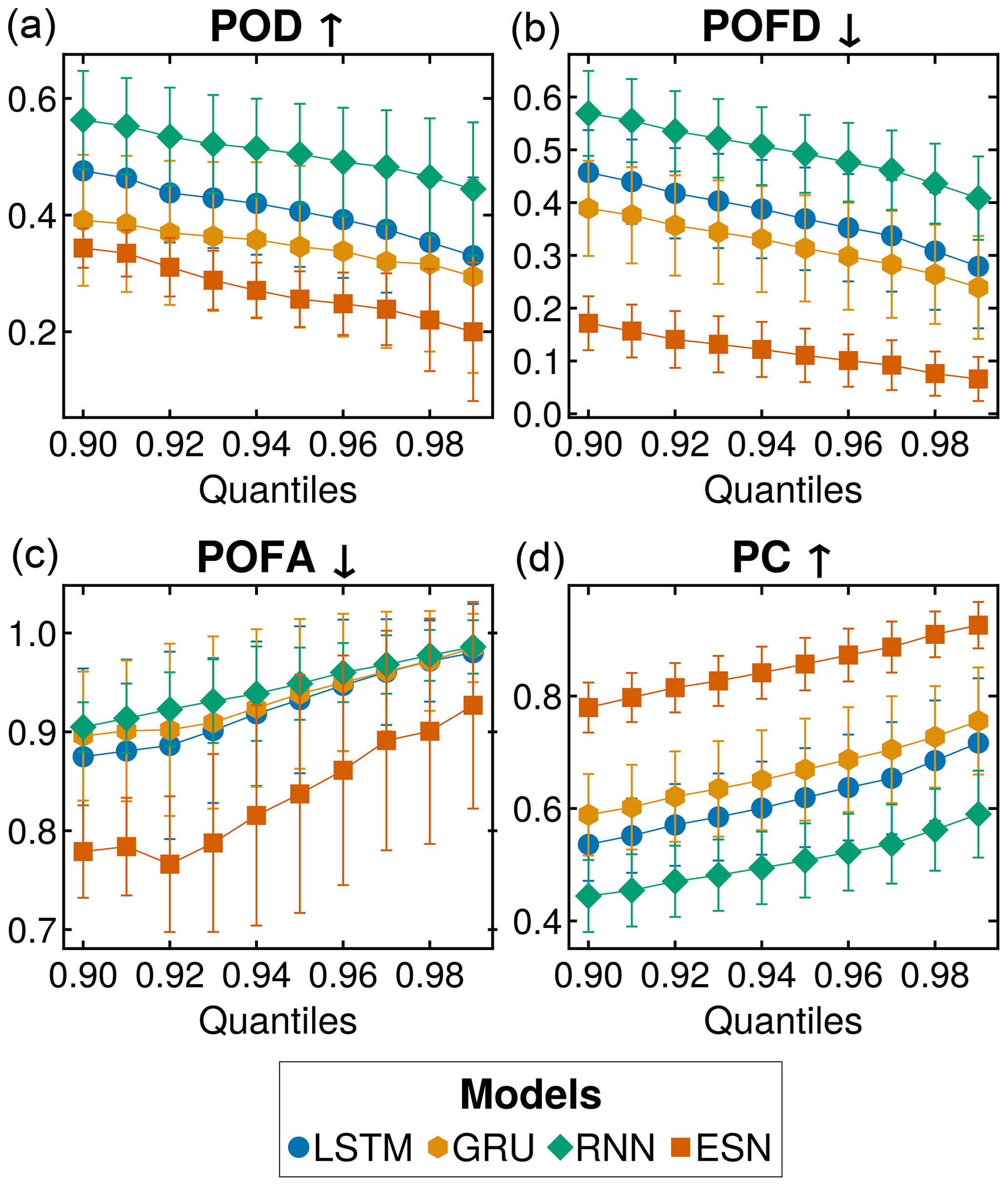
Figure 7Negative extreme events for summer months across all sites. Only the negative extremes during the summer period are considered here. The results of quantiles spanning 0.90 to 0.99 are shown. All values are expressed as percentages. In (a), we show the detection percentage (POD), indicating how many extreme events have been detected. In (b), we show the percentage of false detection (POFD). In (c) we depict the probability of false alarms (POFA). Finally, (d) we show the proportion correct (PC). The error bars represent the standard deviation over 100 simulations with different initializations for each model. The arrows (up ↑ and down ↓) by the metric's name indicate the direction of the optimal values.
We first discuss the performance of the models and their comparison in modeling vegetation greenness in response to climate drivers (Sect. 4.1). Then, we analyze their performance in learning the extremes in NDVI (Sect. 4.2). Finally, we discuss some limitations of this study and future research directions (Sect. 4.3).
4.1 Model's performance and comparison
Similar to previous studies (Benson et al., 2024; Kladny et al., 2024), this work seeks to understand the ability of recurrent neural network architectures to model vegetation greenness. Based on the analyzed metrics, gated architectures and ESNs appear almost equally effective, with ESNs having a slight advantage. The models' performance varies considerably across sites, as illustrated in Fig. C1. Such variability can explain the overlap in the standard deviation and is probably due to the different dynamics of the locations investigated that span different climate zones and forest types.
Additionally, we also provide a comparison of entropy–complexity (EC) plots in Fig. 5. Contrary to the previous metrics, RNNs seem to outperform all other models in the EC plots. However, the presence of disproportionate high noise in the EC plots skewed the results towards the white noise range. Generally, this would indicate the absence of structure in the residuals and point to a good behavior of the prediction. Further investigation into the actual dynamics of the prediction showed that this was due to the high levels of noise. Furthermore, the EC plots clear the distinction between similarly performing models, i.e., gated architectures and ESNs. While these models show comparable performances of NRMSE and SMAPE, they are clearly distinct in the EC plots, highlighting the better performance of the ESNs. Thus, our results illustrate that it is crucial not to rely solely on a single set of metrics when evaluating results in similar studies.
4.2 Do the models capture extremes?
Our results for the analysis of vegetation extreme responses to climate drivers using daily data showed that none of the models notably outperformed the others across all the metrics considered, as seen in Fig. 6. The ESNs performed well in avoiding false alarms but failed to obtain a high accuracy when predicting extremes, performing similarly to LSTMs. ESNs also showed the lowest standard deviation among all the models considered. RNNs performed worst among all metrics analyzed. Overall, all the models showed poor results for this task. When considering negative extremes in the summer season, indicating a decrease in the productivity of vegetation, the results showed again that the recurrent architectures could not correctly capture extremes in vegetation responses to climate forcing (Fig. 7). The ESNs performed best in avoiding false extremes and the overall accuracy of the task's execution, while the RNNs showed the worst prediction performance.
Motivated by recent ESN applications to data from laboratory experiments (Pammi et al., 2023), we expected ESNs to outperform the other models in the extreme prediction task. Instead, the results showed that, while the ESN provided good results, they were not outstanding compared to the BPTT gated models. Additionally, none of the models showed good results, contrary to other applications in hydrology showcasing the successful application of recurrent models to extremes (Frame et al., 2022).
4.3 Limitation and future directions
Often, remote sensing studies are subject to a series of data limitations. However, in this case, the data went through rigorous quality checks and corrections (Walther et al., 2022). When sensed from space in discrete wavelengths, such optical data remain a coarse abstraction of the biological states of the forest under scrutiny. More critical limitation arises from the availability of daily data solely spanning the last 21 years. Although this is a long time span from a remote sensing perspective, it can be regarded as a short period for training machine learning models, which require abundant data points for optimal performance.
The metrics we used are known to be sensitive to noise. Using various metrics, we identified limitations in methods such as the EC plots (Fig. 5). For instance, the noise in the RNN's prediction was incorrectly attributed to residual noise, distorting the outcomes. Moreover, standard metrics like NRMSE and SMAPE provide a narrowed view. This is evident when comparing ESNs and LSTMs: even though they had similar scores with these metrics, their distinctions were clear in the EC plots.
Most existing studies center on creating a single global model, which is key to understanding performances beyond the training sample (Kraft et al., 2019; Diaconu et al., 2022). However, we opted to train individual models for each site to understand how, under optimal conditions, each architecture could capture the specific dynamics of an ecosystem without the need for extrapolation. In this way, we could focus on the models' inherent capability to understand each ecosystem's dynamics, and we are sure that model differences do not arise due to different data demands for generalizations. Increasing the locations and features and expanding the models are necessary future steps for the continued investigation of modeling extremes in vegetation with ML. It has been shown that including additional features and multiple locations improves the ML model performance in hydrological applications (Kratzert et al., 2024; Fang et al., 2022). While similar studies do exist in the context of biosphere dynamics (Kraft et al., 2019), more investigation is needed. For example, including more locations, as highlighted in Kratzert et al. (2024) represents the easiest way to improve performance. Investigating the effects of more location on the performance of ML for vegetation extremes would be an important contribution for the continued adoption of ML models in predicting biosphere dynamics.
ESN and LSTM demonstrated comparable performance in modeling vegetation greenness. However, these models exhibited limited predictive capability for extreme events. Spatial information has proven helpful in similar studies (Requena-Mesa et al., 2021; Diaconu et al., 2022; Robin et al., 2022; Benson et al., 2024; Kladny et al., 2024), and it could be beneficial to explore the extent to which it contributes to extreme conditions. Furthermore, the models used could be tailored more to the task. In Bonavita et al. (2023), the authors point out the limitations in using the mean-squared-error loss function, a practice still widely diffused in the field and adopted in this paper. Furthermore, Rudy and Sapsis (2023) show the superior performance of loss functions based on weighting and relative entropy compared to other loss functions in learning extreme events. Finally, further investigations could benefit from deeper explorations of ESNs. With their user-friendly nature, straightforward hyperparameter tuning, and fast training, they stand out as a robust modeling method, able to compete with top-tier deep learning architectures such as LSTMs.
We compared the performance of four recurrent neural network architectures in modeling biosphere dynamics, i.e., spectral vegetation indices, in response to climate drivers. Using daily data, we assessed the effectiveness of these network architectures in capturing extreme anomalies within these vegetation dynamics. To discern variations in performance across different scenarios, we employed various metrics such as normalized root mean square error and symmetric mean absolute percentage error paired with information theory quantifiers. Our findings revealed that ESNs and LSTMs performed similarly across most analyzed metrics, indicating that no single model outperformed the others. Additionally, all the models under investigation failed to model the extreme responses of the vegetation. This work highlights the necessity to continue refining and developing specialized models that can more adeptly capture extreme vegetation response to meteorological drivers.
In this appendix, we provide the mathematical details behind the models used in this study. Starting from Sect. A1, we introduce the simple version of the RNN, which provides the basic equation for all following models. Subsequently, in Sects. A2 and A3, we illustrate the gated approaches of LSTMs and GRUs, respectively. Finally, in Sect. A4, we showcase the ESNs. While the general approach for all the models shows some similarities, different constructions exhibit variations in complexity (Freire et al., 2021, 2024) and training speed (Cerina et al., 2020; Sun et al., 2022).
A1 Recurrent neural networks
The most basic version of RNN was proposed by Elman (1990). The equations used to obtain the hidden state can be described as follows:
where σ is the activation function, and are the weight matrices, and is a bias vector. In addition, is the input vector at time t.
The main problem of this model is the vanishing and exploding gradient due to the multiple calculations of the gradient during backpropagation through time (Werbos, 1988).
A2 Long short-term memory
For LSTMs the hidden state is obtained as follows (Hochreiter and Schmidhuber, 1997):
where f(t) is the forget gate, i(t) is the input gate, and o(t) is the output gate. The activation functions σg are usually set to be sigmoid, and σx is set to be the hyperbolic tangent. However, it can be set to unity for some variations of the model (e.g., “peephole” LSTM, Gers and Schmidhuber, 2000). The matrices and for are the weight matrices, while the vectors for are bias vectors. The vector represents the input vector at time t.
A3 Gated recurrent units
The equations to obtain the hidden state for GRUs are defined as follows (Cho et al., 2014):
where r(t) is the reset gate, z(t) is the update gate, and is the input signal. The activation functions σ are set to be sigmoid. As in the LSTM, the matrices and for are the weight matrices, while the vectors for are bias vectors.
A4 Echo state networks
The hidden state for the ESN is defined as (Jaeger, 2001)
where α is the leaky coefficient, and is the input data. Similarly to before, the matrices and are the weights matrices, with the difference that this time these matrices do not undergo training or change. Since they are kept fixed, the initialization of these matrices also plays a role in predicting the model. The standard choices are to create Win, also called input matrix, as a dense matrix with weights randomly sampled from a uniform distribution in the range . The weight matrix W is usually referred to as the reservoir matrix, and it is usually built from an Erdős–Rényi graph configuration. This matrix shows a high sparsity, usually in the 1 %–10 % range, and its values are also randomly sampled from a uniform distribution . Subsequently, the matrix is scaled to obtain a chosen spectral radius ρ(W). The values of the spectral radius, size of the matrix, and its sparsity are the main hyperparameters for ESN models.
The output is obtained through a linear feed-forward layer:
where is the output matrix. This matrix is the only one whose weights undergo training. Unlike the models illustrated before, this training is not done using BPTT but simple linear regression. During the training phase, all the inputs are passed through the ESN, and the respective expansions (hidden states) are saved column-wise in a state matrix , where T is the length of the training set . In a similar way, the matrix that is built with the desired output is stacked column-wise. This way, the output layer can be obtained using ridge regression with the following closed form:
where I is the identity matrix, and β is a regularization coefficient.

B1 Experimental settings
All the figures in this paper (except Fig. 1) have been obtained using the Julia language (Bezanson et al., 2017) package Makie.jl (Danisch and Krumbiegel, 2021). All the models have been optimized using grid search. For each optimal set of hyperparameters, 100 different runs have been carried out for each model and site. Unless specified otherwise, the results showcased are mean and standard deviation over these 100 runs per location, over all locations. All the simulations are run on a machine fitted with an NVIDIA RTX A6000 graphics processing unit (GPU) and 504 GB of random access memory (RAM).
B2 Details of the models
In the proposed models based on truncated BPTT, the parameters are optimized using the stochastic optimization method called Adam (Kingma and Ba, 2014), while dropout (Srivastava et al., 2014) is used to protect against over-fitting. Additionally, early stopping is employed to halt training when the validation loss has not changed, with a patience factor of 50 epochs. The weights θW are initialized using the technique proposed in (Glorot and Bengio, 2010), drawing from a uniform distribution. The biases θb are initialized by drawing values from a uniform distribution.
Different layers of recurrent networks are also stacked on top of each other, providing a deeper model. The number of layers and weights per layer is also optimized. All the hyper-parameters undergo optimization using grid search with the root mean square error (RMSE) as a guiding measure. Split temporal cross-validation is used (Cerqueira et al., 2020). In this technique, the training data are subdivided into smaller sections of increasing length, called folds. Each fold contains both training and testing data, with a chosen split between them. We used three folds for cross-validation, with 20 % of the training dataset left for validation in each fold.
B3 Grid search parameters
Table A1 provides the parameters used for the grid search in this study. The values are either given as a list, divided by a comma (), or as an interval, separated by a colon (). In the first case, the values indicated are the values used. In the second case, the values used are between the first and last, with a step size indicated by the second value.

Here, we compute the models' performance across all study sites. Following the nomenclature introduced in Sect. 2.6.3, the F1 score is defined as follows (Powers, 2020):
The results are shown in Fig. C2, which provides an additional overview of the algorithms' performance with respect to extremes.
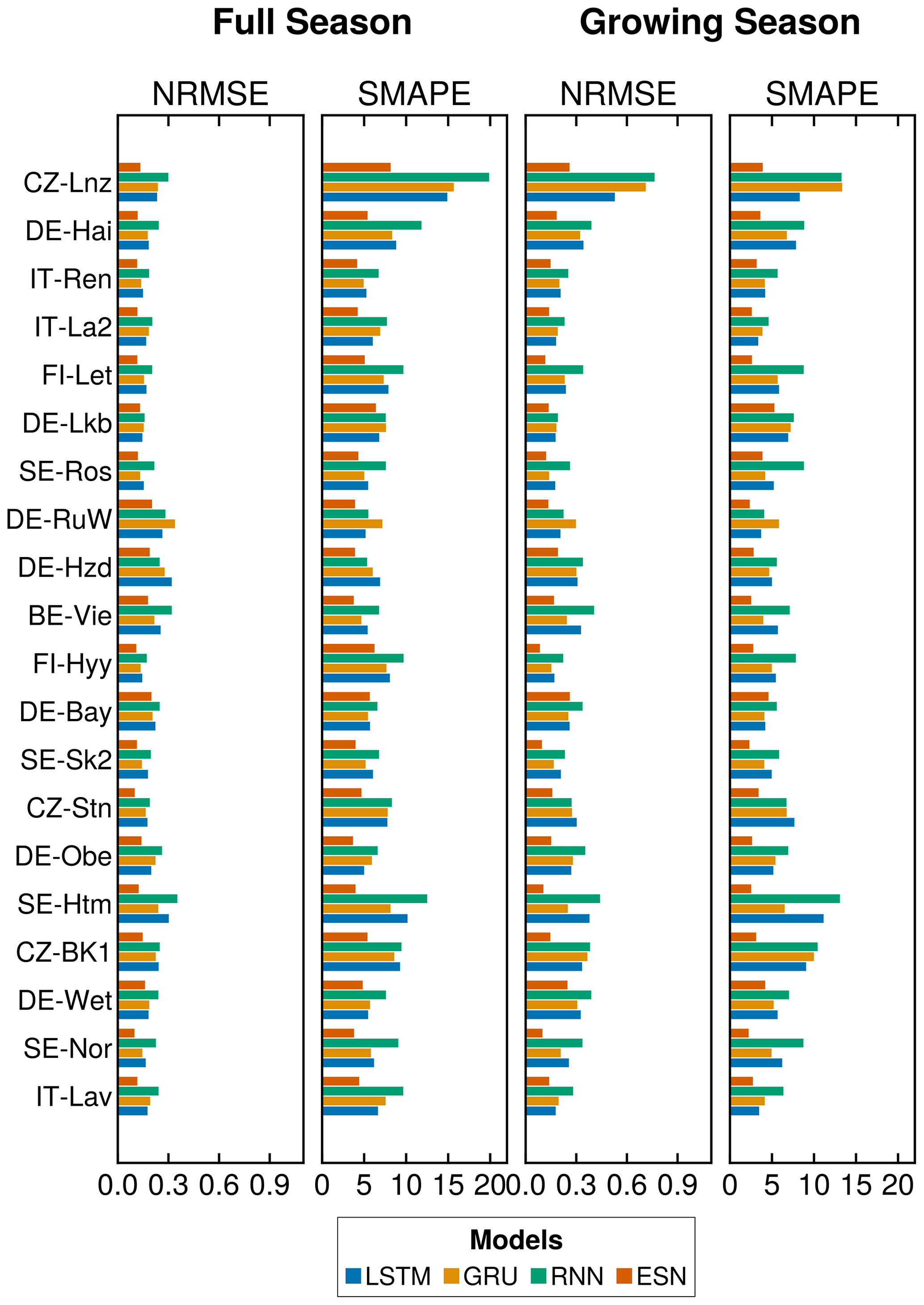
Figure C1Mean results across locations. We show the metrics for all the analyzed locations and all models. Full season refers to the use of the full dataset for the results. Growing season indicates that we only utilized the months between May and September (included). The figure shows the mean of 100 runs per location.
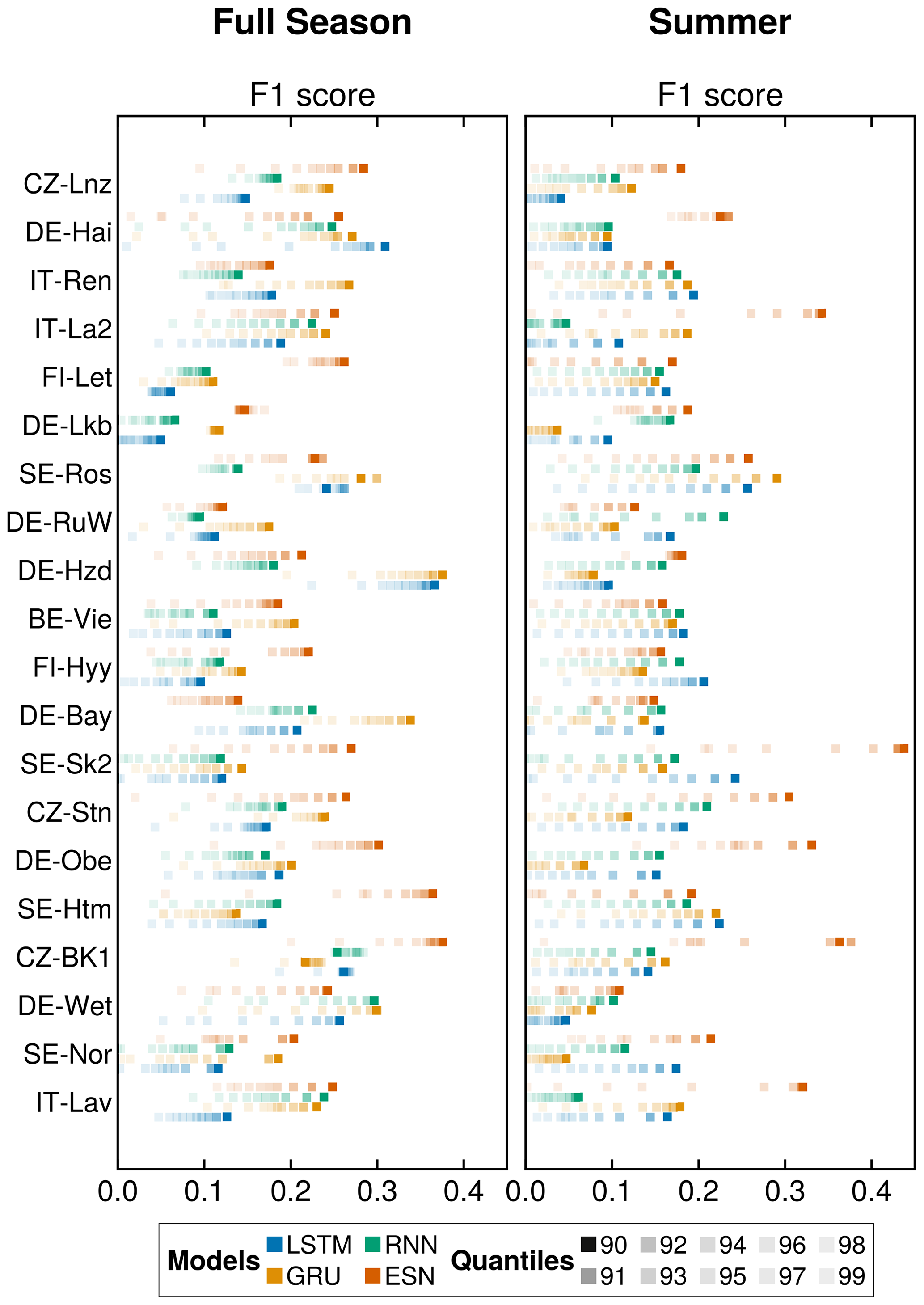
Figure C2Mean F1 score results across locations. We show the F1 score for all the analyzed locations and all models. Full season refers to the use of the full dataset for the results. Summer indicates that we only utilized the months between May and September (included). The figure shows the mean of 100 runs per location.
The code for this study is available at https://github.com/MartinuzziFrancesco/rnn-ndvi (Martinuzzi, 2023).
The data used in this study are available online:
-
E-OBS dataset (Cornes et al., 2018) at https://www.ecad.eu/download/ensembles/download.php
-
FluxnetEO dataset (Walther et al., 2022) at https://meta.icos-cp.eu/collections/tEAkpU6UduMMONrFyym5-tUW.
FM and KM conceptualized the work, and FM carried out the simulations. KM, MDM, GCV, and TW provided suggestions for the analysis. KM and MDM supervised the work. DM formulated the data pre-processing pipeline, while FM implemented it. FM wrote the manuscript with contributions from all authors.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
We thank Sophia Walther for explaining the FluxnetEO data set to us in detail. This research was supported by grants from the European Space Agency and ESA (AI4Science – Deep Extremes and Deep Earth System Data Lab). Francesco Martinuzzi and Miguel D. Mahecha acknowledge the financial support from the Federal Ministry of Education and Research of Germany and from the Sächsische Staatsministerium für Wissenschaft, Kultur und Tourismus in the program of the Center of Excellence for AI Research “Center for Scalable Data Analytics and Artificial Intelligence Dresden/Leipzig”, project identification no. ScaDS.AI. Miguel D. Mahecha acknowledges support from the Sächsische Staatsministerium für Wissenschaft, Kultur und Tourismus (SMWK project 232171353). We thank the Breathing Nature community for the interdisciplinary exchange. Karin Mora acknowledges funding by the Sächsische Staatsministerium für Wissenschaft, Kultur und Tourismus (SMWK 3-7304/35/6-2021/48880). Karin Mora and Miguel D. Mahecha acknowledge the funding by the European Space Agency (ESA) AI4Science via the DeepFeatures project. David Montero and Miguel D. Mahecha acknowledge support from the “Digital Forest” project, Niedersächsisches Ministerium für Wissenschaft und Kultur (MWK) via the Niedersächsisches Vorab (ZN3679) program. Miguel D. Mahecha acknowledges support from the German Aerospace Center, DLR (ML4Earth; grant no. 50EE2201B). We thank the European Union for funding XAIDA via Horizon 2020 grant no. 101003469.
This research has been supported by the Federal Ministry of Education and Research of Germany and by the Sächsische Staatsministerium für Wissenschaft, Kultur und Tourismus (ScaDS.AI); the European Space Agency (ESA) (contract no. 4000143500/23/I-DT); the Programm Niedersächsisches Vorab (grant no. ZN 3679); the German Aerospace Center (DLR; grant no. 50EE2201B); the European Commission (XAIDA; grant no. 101003469); and the Saxon State Ministry for Science, Culture and Tourism (SMWK; grant nos. 232171353 and 3-7304/35/6-2021/48880).
This paper was edited by Zoltan Toth and reviewed by two anonymous referees.
Aicher, C., Foti, N. J., and Fox, E. B.: Adaptively truncating backpropagation through time to control gradient bias, in: Uncertainty in Artificial Intelligence, PMLR, 799–808, http://proceedings.mlr.press/v115/aicher20a/aicher20a.pdf (last access: 4 November 2024), 2020. a
Aubinet, M., Vesala, T., and Papale, D.: Eddy covariance: a practical guide to measurement and data analysis, Springer Science & Business Media, https://doi.org/10.1007/978-94-007-2351-1, 2012. a
Bandt, C. and Pompe, B.: Permutation entropy: a natural complexity measure for time series, Phys. Rev. Lett., 88, 174102, https://doi.org/10.1103/PhysRevLett.88.174102, 2002. a
Barnes, L. R., Schultz, D. M., Gruntfest, E. C., Hayden, M. H., and Benight, C. C.: Corrigendum: False alarm rate or false alarm ratio?, Weather Forecast., 24, 1452–1454, 2009. a
Bastos, A., Sippel, S., Frank, D., Mahecha, M. D., Zaehle, S., Zscheischler, J., and Reichstein, M.: A joint framework for studying compound ecoclimatic events, Nat. Rev. Earth Environ., 4, 333–350, 2023. a
Bengio, Y., Simard, P., and Frasconi, P.: Learning long-term dependencies with gradient descent is difficult, IEEE T. Neural Network., 5, 157–166, 1994. a
Benson, V., Robin, C., Requena-Mesa, C., Alonso, L., Carvalhais, N., Cortés, J., Gao, Z., Linscheid, N., Weynants, M., and Reichstein, M.: Multi-modal learning for geospatial vegetation forecasting, in: Conference on Computer Vision and Pattern Recognition, 16–22 June 2024, Seattle, Washington, United States, https://doi.org/10.1109/CVPR52733.2024.02625, 2024. a, b
Besnard, S., Carvalhais, N., Arain, M. A., Black, A., Brede, B., Buchmann, N., Chen, J., Clevers, J. G. W., Dutrieux, L. P., Gans, F., Herold, M., Jung, M., Kosugi, Y., Knohl, A., Law, B. E., Paul-Limoges, E., Lohila, A. Merbold, L., Roupsard, O., Valentini, R., Wolf, S., Zhang, X., and Reichstein, M.: Memory effects of climate and vegetation affecting net ecosystem CO2 fluxes in global forests, PloS one, 14, e0211510, https://doi.org/10.1371/journal.pone.0211510, 2019. a
Bezanson, J., Edelman, A., Karpinski, S., and Shah, V. B.: Julia: A fresh approach to numerical computing, SIAM review, 59, 65–98, 2017. a
Bonavita, M., Schneider, R., Arcucci, R., Chantry, M., Chrust, M., Geer, A., Le Saux, B., and Vitolo, C.: 2022 ECMWF-ESA workshop report: current status, progress and opportunities in machine learning for Earth System observation and prediction, npj Climate and Atmospheric Science, 6, 87, https://doi.org/10.1038/s41612-023-00387-2, 2023. a
Bottou, L.: Stochastic gradient descent tricks, in: Neural Networks: Tricks of the Trade: Second Edition, Springer, 421–436, ISBN 978-3-642-35288-1, 2012. a
Buchhorn, M., Smets, B., Bertels, L., Roo, B. D., Lesiv, M., Tsendbazar, N.-E., Herold, M., and Fritz, S.: Copernicus Global Land Service: Land Cover 100m: collection 3: epoch 2019: Globe, Zenodo [data set], https://doi.org/10.5281/zenodo.3939050, 2020. a
Camps-Valls, G., Campos-Taberner, M., Moreno-Martínez, Á., Walther, S., Duveiller, G., Cescatti, A., Mahecha, M. D., Muñoz-Marí, J., García-Haro, F. J., Guanter, L., Jung, M., Gamon, J. A., Reichstein, M., and Running, S. W.: A unified vegetation index for quantifying the terrestrial biosphere, Science Advances, 7, eabc7447, https://doi.org/10.1126/sciadv.abc7447, 2021a. a
Camps-Valls, G., Tuia, D., Zhu, X. X., and Reichstein, M.: Deep learning for the Earth Sciences: A comprehensive approach to remote sensing, climate science and geosciences, John Wiley & Sons, ISBN 1119646146, 2021b. a
Canadell, J., Monteiro, P., Costa, M., Cotrim da Cunha, L., Cox, P., Eliseev, A., Henson, S., Ishii, M., Jaccard, S., Koven, C., Lohila, A., Patra, P., Piao, S., Rogelj, J., Syampungani, S., Zaehle, S., and Zickfeld, K.: Global Carbon and other Biogeochemical Cycles and Feedbacks, in: Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change, edited by Masson-Delmotte, V., Zhai, P., Pirani, A., Connors, S., Péan, C., Berger, S., Caud, N., Chen, Y., Goldfarb, L., Gomis, M., Huang, M., Leitzell, K., Lonnoy, E., Matthews, J., Maycock, T., Waterfield, T., Yelekçi, O., Yu, R., and Zhou, B., p. 673–816, Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, https://doi.org/10.1017/9781009157896.007, 2021. a
Cerina, L., Santambrogio, M. D., Franco, G., Gallicchio, C., and Micheli, A.: Efficient embedded machine learning applications using echo state networks, in: 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), IEEE, 1299–1302, https://doi.org/10.23919/DATE48585.2020.9116334, 2020. a
Cerqueira, V., Torgo, L., and Mozetič, I.: Evaluating time series forecasting models: An empirical study on performance estimation methods, Machine Learning, 109, 1997–2028, 2020. a
Chattopadhyay, A., Hassanzadeh, P., and Subramanian, D.: Data-driven predictions of a multiscale Lorenz 96 chaotic system using machine-learning methods: reservoir computing, artificial neural network, and long short-term memory network, Nonlin. Processes Geophys., 27, 373–389, https://doi.org/10.5194/npg-27-373-2020, 2020. a
Chen, J., Jönsson, P., Tamura, M., Gu, Z., Matsushita, B., and Eklundh, L.: A simple method for reconstructing a high-quality NDVI time-series data set based on the Savitzky–Golay filter, Remote Sens. Environ., 91, 332–344, 2004. a
Chen, Z., Liu, H., Xu, C., Wu, X., Liang, B., Cao, J., and Chen, D.: Modeling vegetation greenness and its climate sensitivity with deep-learning technology, Ecol. Evol., 11, 7335–7345, 2021. a
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y.: Learning phrase representations using RNN encoder-decoder for statistical machine translation, in: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, October 2014, 1724–1734, https://doi.org/10.3115/v1/D14-1179, 2014. a, b
Chung, J., Gulcehre, C., Cho, K., and Bengio, Y.: Empirical evaluation of gated recurrent neural networks on sequence modeling, arXiv [preprint], https://doi.org/10.48550/arXiv.1412.3555, 2014. a
Cornes, R. C., van der Schrier, G., van den Besselaar, E. J., and Jones, P. D.: An ensemble version of the E-OBS temperature and precipitation data sets, J. Geophys. Res.-Atmos., 123, 9391–9409, 2018 (data available at: https://www.ecad.eu/download/ensembles/download.php, last access: 1 June 2023). a, b
Danisch, S. and Krumbiegel, J.: Makie.jl: Flexible high-performance data visualization for Julia, Journal of Open Source Software, 6, 3349, https://doi.org/10.21105/joss.03349, 2021. a
Datseris, G.: DynamicalSystems.jl: A Julia software library for chaos and nonlinear dynamics, Journal of Open Source Software, 3, 598, https://doi.org/10.21105/joss.00598, 2018. a
De Jong, R., de Bruin, S., de Wit, A., Schaepman, M. E., and Dent, D. L.: Analysis of monotonic greening and browning trends from global NDVI time-series, Remote Sens. Environ., 115, 692–702, 2011. a
De Jong, R., Verbesselt, J., Schaepman, M. E., and De Bruin, S.: Trend changes in global greening and browning: contribution of short-term trends to longer-term change, Glob. Change Biol., 18, 642–655, 2012. a
De Keersmaecker, W., van Rooijen, N., Lhermitte, S., Tits, L., Schaminée, J., Coppin, P., Honnay, O., and Somers, B.: Species-rich semi-natural grasslands have a higher resistance but a lower resilience than intensively managed agricultural grasslands in response to climate anomalies, J. Appl. Ecol., 53, 430–439, https://doi.org/10.1111/1365-2664.12595, 2016. a
Diaconu, C.-A., Saha, S., Günnemann, S., and Zhu, X. X.: Understanding the Role of Weather Data for Earth Surface Forecasting using a ConvLSTM-based Model, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Louisiana, United States, 12–24 June 2022, 1362–1371, https://openaccess.thecvf.com/content/CVPR2022W/EarthVision/html/Diaconu_Understanding_the_Role_of_Weather_Data_for_Earth_Surface_Forecasting_CVPRW_2022_paper.html (last access: 4 November 2024), 2022. a, b
Dijkstra, H. A.: Nonlinear climate dynamics, Cambridge University Press, ISBN 9781139034135, https://doi.org/10.1017/CBO9781139034135, 2013. a
Dobbertin, M., Wermelinger, B., Bigler, C., Bürgi, M., Carron, M., Forster, B., Gimmi, U., and Rigling, A.: Linking increasing drought stress to Scots pine mortality and bark beetle infestations, Sci. World J., 7, 231–239, 2007. a
Eggleton, T.: A short introduction to climate change, Cambridge University Press, ISBN 9781139524353, https://doi.org/10.1017/CBO9781139524353, 2012. a
Elman, J. L.: Finding structure in time, Cognitive Sci., 14, 179–211, 1990. a, b
Fang, K., Kifer, D., Lawson, K., Feng, D., and Shen, C.: The data synergy effects of time-series deep learning models in hydrology, Water Resour. Res., 58, e2021WR029583, https://doi.org/10.1029/2021WR029583, 2022. a
Farazmand, M. and Sapsis, T. P.: Extreme events: Mechanisms and prediction, Appl. Mech. Rev., 71, 050801, https://doi.org/10.1115/1.4042065, 2019. a
Fensham, R. and Holman, J.: Temporal and spatial patterns in drought-related tree dieback in Australian savanna, J. Appl. Ecol., 36, 1035–1050, 1999. a
Foley, J. A., Levis, S., Prentice, I. C., Pollard, D., and Thompson, S. L.: Coupling dynamic models of climate and vegetation, Glob. Change Biol., 4, 561–579, 1998. a
Frame, J. M., Kratzert, F., Klotz, D., Gauch, M., Shalev, G., Gilon, O., Qualls, L. M., Gupta, H. V., and Nearing, G. S.: Deep learning rainfall–runoff predictions of extreme events, Hydrol. Earth Syst. Sci., 26, 3377–3392, https://doi.org/10.5194/hess-26-3377-2022, 2022. a
Freire, P., Srivallapanondh, S., Spinnler, B., Napoli, A., Costa, N., Prilepsky, J. E., and Turitsyn, S. K.: Computational Complexity Optimization of Neural Network-Based Equalizers in Digital Signal Processing: A Comprehensive Approach, J. Lightwave Technol., 42, 4177–4201, https://doi.org/10.1109/JLT.2024.3386886, 2024. a
Freire, P. J., Osadchuk, Y., Spinnler, B., Napoli, A., Schairer, W., Costa, N., Prilepsky, J. E., and Turitsyn, S. K.: Performance versus complexity study of neural network equalizers in coherent optical systems, J. Lightwave Technol., 39, 6085–6096, 2021. a
Friedlingstein, P., Cox, P., Betts, R., Bopp, L., von Bloh, W., Brovkin, V., Cadule, P., Doney, S., Eby, M., Fung, I., Bala, G., John, J., Jones, C., Joos, F., Kato, T., Kawamiya, M., Knorr, W., Lindsay, K., Matthews, H. D., Raddatz, T., Rayner, P., Reick, C., Roeckner, E., Schnitzler, K.-G., Schnur, R., Strassmann, K., Weaver, A. J., Yoshikawa, C., and Zeng, N.: Climate–carbon cycle feedback analysis: results from the C4MIP model intercomparison, J. Climate, 19, 3337–3353, 2006. a
Funahashi, K.-i. and Nakamura, Y.: Approximation of dynamical systems by continuous time recurrent neural networks, Neural Networks, 6, 801–806, 1993. a
Gauch, M., Kratzert, F., Klotz, D., Nearing, G., Lin, J., and Hochreiter, S.: Rainfall–runoff prediction at multiple timescales with a single Long Short-Term Memory network, Hydrol. Earth Syst. Sci., 25, 2045–2062, https://doi.org/10.5194/hess-25-2045-2021, 2021. a
Gauthier, D. J., Fischer, I., and Röhm, A.: Learning unseen coexisting attractors, Chaos: An Interdisciplinary Journal of Nonlinear Science, 32, 113107,
doi10.1063/5.0116784, 2022. a
Gers, F. and Schmidhuber, J.: Recurrent nets that time and count, in: Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for the New Millennium, IEEE, Como, Italy, 27–27 July 2000, https://doi.org/10.1109/ijcnn.2000.861302, 2000. a
Ghazoul, J., Burivalova, Z., Garcia-Ulloa, J., and King, L. A.: Conceptualizing forest degradation, Trends Ecol. Evol., 30, 622–632, 2015. a
Glorot, X. and Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks, in: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, edited by Teh, Y. W. and Titterington, M., vol. 9 of Proceedings of Machine Learning Research, PMLR, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010, 249–256, https://proceedings.mlr.press/v9/glorot10a.html (last access: 25 October 2024), 2010. a
Grant, P. J.: Drought effect on high-altitude forests, Ruahine range, North Island, New Zealand, New Zeal. J. Bot., 22, 15–27, 1984. a
Grosse, I., Bernaola-Galván, P., Carpena, P., Román-Roldán, R., Oliver, J., and Stanley, H. E.: Analysis of symbolic sequences using the Jensen-Shannon divergence, Phys. Rev. E, 65, 041905, https://doi.org/10.1103/PhysRevE.65.041905, 2002. a
Haaga, K. A. and Datseris, G.: JuliaDynamics/ComplexityMeasures.jl: v2.7.2, Zenodo [software], https://doi.org/10.5281/zenodo.7862020, 2023. a
Hart, A., Hook, J., and Dawes, J.: Embedding and approximation theorems for echo state networks, Neural Networks, 128, 234–247, 2020. a
Hilker, T., Lyapustin, A. I., Tucker, C. J., Hall, F. G., Myneni, R. B., Wang, Y., Bi, J., Mendes de Moura, Y., and Sellers, P. J.: Vegetation dynamics and rainfall sensitivity of the Amazon, P. Natl. Acad. Sci. USA, 111, 16041–16046, 2014. a
Hochreiter, S.: The vanishing gradient problem during learning recurrent neural nets and problem solutions, Int. J. Uncertain. Fuzz., 6, 107–116, 1998. a
Hochreiter, S. and Schmidhuber, J.: Long short-term memory, Neural Comput., 9, 1735–1780, 1997. a, b
Hogan, R. J. and Mason, I. B.: Deterministic Forecasts of Binary Events, in: Forecast Verification: A Practitioner's Guide in Atmospheric Science, 2nd edn., https://doi.org/10.1002/9781119960003.ch3, 2011. a
Hyndman, R. J. and Koehler, A. B.: Another look at measures of forecast accuracy, International J. Forecasting, 22, 679–688, https://doi.org/10.1016/j.ijforecast.2006.03.001, 2006. a, b
Jaeger, H.: The “echo state” approach to analysing and training recurrent neural networks-with an erratum note, Bonn, Germany: German National Research Center for Information Technology GMD Technical Report, 148, 13, https://www.ai.rug.nl/minds/uploads/EchoStatesTechRep.pdf (last access: 25 October 2024), 2001. a, b, c
Johnstone, J. F., Allen, C. D., Franklin, J. F., Frelich, L. E., Harvey, B. J., Higuera, P. E., Mack, M. C., Meentemeyer, R. K., Metz, M. R., Perry, G. L. W., Schoennagel, T., and Turner, M. G.: Changing disturbance regimes, ecological memory, and forest resilience, Front. Ecol. Environ., 14, 369–378, 2016. a
Jung, M., Schwalm, C., Migliavacca, M., Walther, S., Camps-Valls, G., Koirala, S., Anthoni, P., Besnard, S., Bodesheim, P., Carvalhais, N., Chevallier, F., Gans, F., Goll, D. S., Haverd, V., Köhler, P., Ichii, K., Jain, A. K., Liu, J., Lombardozzi, D., Nabel, J. E. M. S., Nelson, J. A., O'Sullivan, M., Pallandt, M., Papale, D., Peters, W., Pongratz, J., Rödenbeck, C., Sitch, S., Tramontana, G., Walker, A., Weber, U., and Reichstein, M.: Scaling carbon fluxes from eddy covariance sites to globe: synthesis and evaluation of the FLUXCOM approach, Biogeosciences, 17, 1343–1365, https://doi.org/10.5194/bg-17-1343-2020, 2020. a
Kang, L., Di, L., Deng, M., Yu, E., and Xu, Y.: Forecasting vegetation index based on vegetation-meteorological factor interactions with artificial neural network, in: 2016 Fifth International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Tianjin, China, 18–20 July 2016, 1–6, https://doi.org/10.1109/Agro-Geoinformatics.2016.7577673, 2016. a
Kingma, D. P. and Ba, J.: Adam: A method for stochastic optimization, arXiv [preprint], https://doi.org/10.48550/arXiv.1412.6980, 2014. a
Kladny, K.-R., Milanta, M., Mraz, O., Hufkens, K., and Stocker, B. D.: Enhanced prediction of vegetation responses to extreme drought using deep learning and Earth observation data, Ecol. Inform., 80, 102474, https://doi.org/10.1016/j.ecoinf.2024.102474, 2024. a, b
Kraft, B., Jung, M., Körner, M., Requena Mesa, C., Cortés, J., and Reichstein, M.: Identifying dynamic memory effects on vegetation state using recurrent neural networks, Frontiers in Big Data, 2, 31, https://doi.org/10.3389/fdata.2019.00031, 2019. a, b, c
Kratzert, F., Klotz, D., Brenner, C., Schulz, K., and Herrnegger, M.: Rainfall–runoff modelling using Long Short-Term Memory (LSTM) networks, Hydrol. Earth Syst. Sci., 22, 6005–6022, https://doi.org/10.5194/hess-22-6005-2018, 2018. a
Kratzert, F., Gauch, M., Klotz, D., and Nearing, G.: HESS Opinions: Never train a Long Short-Term Memory (LSTM) network on a single basin, Hydrol. Earth Syst. Sci., 28, 4187–4201, https://doi.org/10.5194/hess-28-4187-2024, 2024. a, b
Krinner, G., Viovy, N., de Noblet-Ducoudré, N., Ogée, J., Polcher, J., Friedlingstein, P., Ciais, P., Sitch, S., and Prentice, I. C.: A dynamic global vegetation model for studies of the coupled atmosphere-biosphere system, Global Biogeochem. Cy., 19, GB1015, https://doi.org/10.1029/2003GB002199, 2005. a
Lamberti, P. W., Martin, M., Plastino, A., and Rosso, O.: Intensive entropic non-triviality measure, Physica A, 334, 119–131, 2004. a
LeCun, Y., Bengio, Y., and Hinton, G.: Deep learning, Nature, 521, 436–444, 2015. a
Lellep, M., Prexl, J., Linkmann, M., and Eckhardt, B.: Using machine learning to predict extreme events in the Hénon map, Chaos: An Interdisciplinary Journal of Nonlinear Science, 30, 013113, https://doi.org/10.1063/1.5121844, 2020. a
Le Quéré, C., Raupach, M. R., Canadell, J. G., Marland, G., Bopp, L., Ciais, P., Conway, T. J., Doney, S. C., Feely, R. A., Foster, P., Friedlingstein, P., Gurney, K., Houghton, R. A., House, J. I., Huntingford, C., Levy, P. E., Lomas, M. R., Majkut, J. Metzl, N., Ometto, J. P., Peters, G. P., Prentice, I. C., Randerson, J. T., Running, S. W., Sarmiento, J. L., Schuster, U. Sitch, S., Takahashi, T., Viovy, N., van der Werf, G. R., and Woodward, F. I.: Trends in the sources and sinks of carbon dioxide, Nat. Geosci., 2, 831–836, 2009. a
Le Quéré, C., Andrew, R. M., Friedlingstein, P., Sitch, S., Hauck, J., Pongratz, J., Pickers, P. A., Korsbakken, J. I., Peters, G. P., Canadell, J. G., Arneth, A., Arora, V. K., Barbero, L., Bastos, A., Bopp, L., Chevallier, F., Chini, L. P., Ciais, P., Doney, S. C., Gkritzalis, T., Goll, D. S., Harris, I., Haverd, V., Hoffman, F. M., Hoppema, M., Houghton, R. A., Hurtt, G., Ilyina, T., Jain, A. K., Johannessen, T., Jones, C. D., Kato, E., Keeling, R. F., Goldewijk, K. K., Landschützer, P., Lefèvre, N., Lienert, S., Liu, Z., Lombardozzi, D., Metzl, N., Munro, D. R., Nabel, J. E. M. S., Nakaoka, S., Neill, C., Olsen, A., Ono, T., Patra, P., Peregon, A., Peters, W., Peylin, P., Pfeil, B., Pierrot, D., Poulter, B., Rehder, G., Resplandy, L., Robertson, E., Rocher, M., Rödenbeck, C., Schuster, U., Schwinger, J., Séférian, R., Skjelvan, I., Steinhoff, T., Sutton, A., Tans, P. P., Tian, H., Tilbrook, B., Tubiello, F. N., van der Laan-Luijkx, I. T., van der Werf, G. R., Viovy, N., Walker, A. P., Wiltshire, A. J., Wright, R., Zaehle, S., and Zheng, B.: Global Carbon Budget 2018, Earth Syst. Sci. Data, 10, 2141–2194, https://doi.org/10.5194/essd-10-2141-2018, 2018. a
Liang, E., Shao, X., Kong, Z., and Lin, J.: The extreme drought in the 1920s and its effect on tree growth deduced from tree ring analysis: a case study in North China, Ann. For. Sci., 60, 145–152, 2003. a
Linscheid, N., Estupinan-Suarez, L. M., Brenning, A., Carvalhais, N., Cremer, F., Gans, F., Rammig, A., Reichstein, M., Sierra, C. A., and Mahecha, M. D.: Towards a global understanding of vegetation–climate dynamics at multiple timescales, Biogeosciences, 17, 945–962, https://doi.org/10.5194/bg-17-945-2020, 2020. a
Liu, G., Liu, H., and Yin, Y.: Global patterns of NDVI-indicated vegetation extremes and their sensitivity to climate extremes, Environ. Res. Lett., 8, 025009, https://doi.org/10.1088/1748-9326/8/2/025009, 2013. a
Lopez-Ruiz, R., Mancini, H. L., and Calbet, X.: A statistical measure of complexity, Phys. Lett. A, 209, 321–326, 1995. a
Lotsch, A., Friedl, M. A., Anderson, B. T., and Tucker, C. J.: Response of terrestrial ecosystems to recent Northern Hemispheric drought, Geophys. Res. Lett., 32, L06705, https://doi.org/10.1029/2004GL022043, 2005. a
Lu, Z., Pathak, J., Hunt, B., Girvan, M., Brockett, R., and Ott, E.: Reservoir observers: Model-free inference of unmeasured variables in chaotic systems, Chaos: An Interdisciplinary Journal of Nonlinear Science, 27, 041102, https://doi.org/10.1063/1.4979665, 2017. a
Maass, W., Natschläger, T., and Markram, H.: Real-time computing without stable states: A new framework for neural computation based on perturbations, Neural Comput., 14, 2531–2560, 2002. a
Mahecha, M. D., Fürst, L. M., Gobron, N., and Lange, H.: Identifying multiple spatiotemporal patterns: A refined view on terrestrial photosynthetic activity, Pattern Recogn. Lett., 31, 2309–2317, 2010. a
Mahecha, M. D., Gans, F., Brandt, G., Christiansen, R., Cornell, S. E., Fomferra, N., Kraemer, G., Peters, J., Bodesheim, P., Camps-Valls, G., Donges, J. F., Dorigo, W., Estupinan-Suarez, L. M., Gutierrez-Velez, V. H., Gutwin, M., Jung, M., Londoño, M. C., Miralles, D. G., Papastefanou, P., and Reichstein, M.: Earth system data cubes unravel global multivariate dynamics, Earth Syst. Dynam., 11, 201–234, https://doi.org/10.5194/esd-11-201-2020, 2020. a
Mahecha, M. D., Bastos, A., Bohn, F. J., Eisenhauer, N., Feilhauer, H., Hartmann, H., Hickler, T., Kalesse-Los, H., Migliavacca, M., Otto, F. E. L., Peng, J., Quaas, J., Tegen, I., Weigelt, A., Wendisch, M., and Wirth, C.: Biodiversity loss and climate extremes – study the feedbacks, Nature, 612, 30–32, 2022. a
Mahecha, M. D., Bastos, A., Bohn, F. J., Eisenhauer, N., Feilhauer, H., Hickler, T., Kalesse-Los, H., Migliavacca, M., Otto, F. E. L., Peng, J., Sippel, S., Tegen, I., Weigelt, A., Wendisch, M., Wirth, C., Al-Halbouni, D., Deneke, H., Doktor, D., Dunker, S., Duveiller, G., Ehrlich, A., Foth, A., García-García, A., Guerra, C. A., Guimarães-Steinicke, C., Hartmann, H., Henning, S., Herrmann, H., Hu, P., Ji, C., Kattenborn, T., Kolleck, N., Kretschmer, M., Kühn, I., Luttkus, M. L., Maahn, M., Mönks, M., Mora, K., Pöhlker, M., Reichstein, M., Rüger, N., Sánchez-Parra, B., Schäfer, M., Stratmann, F., Tesche, M., Wehner, B., Wieneke, S., Winkler, A. J., Wolf, S., Zaehle, S., Zscheischler, J., and Quaas, J.: Biodiversity and Climate Extremes: Known Interactions and Research Gaps, Earth's Future, 12, e2023EF003963, https://doi.org/10.1029/2023EF003963, 2024. a, b
Makridakis, S.: Accuracy measures: theoretical and practical concerns, Int. J. Forecasting, 9, 527–529, 1993. a
Martin, M., Plastino, A., and Rosso, O.: Generalized statistical complexity measures: Geometrical and analytical properties, Physica A, 369, 439–462, 2006. a
Martinuzzi, F.: rnn-ndvi, GitHub [code], https://github.com/MartinuzziFrancesco/rnn-ndvi (last access: 4 November 2024), 2023. a
Martinuzzi, F., Rackauckas, C., Abdelrehim, A., Mahecha, M. D., and Mora, K.: ReservoirComputing. jl: An Efficient and Modular Library for Reservoir Computing Models, J. Mach. Learn. Res. [code], http://jmlr.org/papers/v23/22-0611.html (last access: 4 November 2024), 2022. a
Meiyazhagan, J., Sudharsan, S., and Senthilvelan, M.: Model-free prediction of emergence of extreme events in a parametrically driven nonlinear dynamical system by deep learning, Eur. Phys. J. B, 94, 156, https://doi.org/10.1140/epjb/s10051-021-00167-y, 2021. a
Merchant, C. J., Paul, F., Popp, T., Ablain, M., Bontemps, S., Defourny, P., Hollmann, R., Lavergne, T., Laeng, A., de Leeuw, G., Mittaz, J., Poulsen, C., Povey, A. C., Reuter, M., Sathyendranath, S., Sandven, S., Sofieva, V. F., and Wagner, W.: Uncertainty information in climate data records from Earth observation, Earth Syst. Sci. Data, 9, 511–527, https://doi.org/10.5194/essd-9-511-2017, 2017. a
Montero, D., Aybar, C., Mahecha, M. D., Martinuzzi, F., Söchting, M., and Wieneke, S.: A standardized catalogue of spectral indices to advance the use of remote sensing in Earth system research, Scientific Data, 10, 197, https://doi.org/10.1038/s41597-023-02096-0, 2023. a
Mora, K., Rzanny, M., Wäldchen, J., Feilhauer, H., Kattenborn, T., Kraemer, G., Mäder, P., Svidzinska, D., Wolf, S., and Mahecha, M. D.: Macrophenological dynamics from citizen science plant occurrence data, Methods in Ecol. Evol., 15, 1422–1437, https://doi.org/10.1111/2041-210X.14365, 2024. a, b
Nelson, J. A., Walther, S., Gans, F., Kraft, B., Weber, U., Novick, K., Buchmann, N., Migliavacca, M., Wohlfahrt, G., Šigut, L., Ibrom, A., Papale, D., Göckede, M., Duveiller, G., Knohl, A., Hörtnagl, L., Scott, R. L., Zhang, W., Hamdi, Z. M., Reichstein, M., Aranda-Barranco, S., Ardö, J., Op de Beeck, M., Billdesbach, D., Bowling, D., Bracho, R., Brümmer, C., Camps-Valls, G., Chen, S., Cleverly, J. R., Desai, A., Dong, G., El-Madany, T. S., Euskirchen, E. S., Feigenwinter, I., Galvagno, M., Gerosa, G., Gielen, B., Goded, I., Goslee, S., Gough, C. M., Heinesch, B., Ichii, K., Jackowicz-Korczynski, M. A., Klosterhalfen, A., Knox, S., Kobayashi, H., Kohonen, K.-M., Korkiakoski, M., Mammarella, I., Mana, G., Marzuoli, R., Matamala, R., Metzger, S., Montagnani, L., Nicolini, G., O'Halloran, T., Ourcival, J.-M., Peichl, M., Pendall, E., Ruiz Reverter, B., Roland, M., Sabbatini, S., Sachs, T., Schmidt, M., Schwalm, C. R., Shekhar, A., Silberstein, R., Silveira, M. L., Spano, D., Tagesson, T., Tramontana, G., Trotta, C., Turco, F., Vesala, T., Vincke, C., Vitale, D., Vivoni, E. R., Wang, Y., Woodgate, W., Yepez, E. A., Zhang, J., Zona, D., and Jung, M.: X-BASE: the first terrestrial carbon and water flux products from an extended data-driven scaling framework, FLUXCOM-X, EGUsphere [preprint], https://doi.org/10.5194/egusphere-2024-165, 2024. a
Pammi, V. A., Clerc, M. G., Coulibaly, S., and Barbay, S.: Extreme Events Prediction from Nonlocal Partial Information in a Spatiotemporally Chaotic Microcavity Laser, Phys. Rev. Lett., 130, 223801, https://doi.org/10.1103/PhysRevLett.130.223801, 2023. a, b
Papagiannopoulou, C., Miralles, D. G., Decubber, S., Demuzere, M., Verhoest, N. E. C., Dorigo, W. A., and Waegeman, W.: A non-linear Granger-causality framework to investigate climate–vegetation dynamics, Geosci. Model Dev., 10, 1945–1960, https://doi.org/10.5194/gmd-10-1945-2017, 2017. a
Papale, D. and Valentini, R.: A new assessment of European forests carbon exchanges by eddy fluxes and artificial neural network spatialization, Glob. Change Biol., 9, 525–535, 2003. a
Papale, D., Black, T. A., Carvalhais, N., Cescatti, A., Chen, J., Jung, M., Kiely, G., Lasslop, G., Mahecha, M. D., Margolis, H., Merbold, L., Montagnani, L., Moors, E., Olesen, J. E., Reichstein, M., Tramontana, G., van Gorsel, E., Wohlfahrt, G., and Ráduly, B.: Effect of spatial sampling from European flux towers for estimating carbon and water fluxes with artificial neural networks, J. Geophys. Res.-Biogeo., 120, 1941–1957, 2015. a
Pappas, C., Mahecha, M. D., Frank, D. C., Babst, F., and Koutsoyiannis, D.: Ecosystem functioning is enveloped by hydrometeorological variability, Nature Ecology & Evolution, 1, 1263–1270, 2017. a
Pascanu, R., Mikolov, T., and Bengio, Y.: On the difficulty of training recurrent neural networks, in: International conference on machine learning, Atlanta, GA, USA, 16–21 June 2013, Pmlr, 1310–1318, https://proceedings.mlr.press/v28/pascanu13.pdf (last access: 4 November 2024), 2013. a
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S.: Pytorch: An imperative style, high-performance deep learning library, GitHub [code], https://github.com/pytorch/pytorch (last access: 4 November 2024), 2019. a
Pathak, J., Lu, Z., Hunt, B. R., Girvan, M., and Ott, E.: Using machine learning to replicate chaotic attractors and calculate Lyapunov exponents from data, Chaos: An Interdisciplinary Journal of Nonlinear Science, 27, 121102, https://doi.org/10.1063/1.5010300, 2017. a
Pathak, J., Hunt, B., Girvan, M., Lu, Z., and Ott, E.: Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach, Phys. Rev. Lett., 120, 024102, https://doi.org/10.1103/PhysRevLett.120.024102, 2018. a
Peng, Q., Li, X., Shen, R., He, B., Chen, X., Peng, Y., and Yuan, W.: How well can we predict vegetation growth through the coming growing season?, Science of Remote Sensing, 5, 100043, https://doi.org/10.1016/j.srs.2022.100043, 2022. a
Powers, D. M.: Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation, arXiv [preprint], https://doi.org/10.48550/arXiv.2010.16061, 2020. a
Pyragas, V. and Pyragas, K.: Using reservoir computer to predict and prevent extreme events, Phys. Lett. A, 384, 126591, https://doi.org/10.1016/j.physleta.2020.126591, 2020. a
Ray, A., Chakraborty, T., and Ghosh, D.: Optimized ensemble deep learning framework for scalable forecasting of dynamics containing extreme events, Chaos: An Interdisciplinary Journal of Nonlinear Science, 31, 111105, https://doi.org/10.1063/5.0074213, 2021. a
Reichstein, M., Bahn, M., Ciais, P., Frank, D., Mahecha, M. D., Seneviratne, S. I., Zscheischler, J., Beer, C., Buchmann, N., Frank, D. C., Papale, D. Rammig, A., Smith, P., Thonicke, K., van der Velde, M., Vicca, S., Walz, A., and Wattenbach, M.: Climate extremes and the carbon cycle, Nature, 500, 287–295, 2013. a
Reichstein, M., Besnard, S., Carvalhais, N., Gans, F., Jung, M., Kraft, B., and Mahecha, M.: Modelling landsurface time-series with recurrent neural nets, in: IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018, 7640–7643, https://doi.org/10.1109/IGARSS.2018.8518007, 2018. a
Reichstein, M., Camps-Valls, G., Stevens, B., Jung, M., Denzler, J., and Carvalhais, N.: Deep learning and process understanding for data-driven Earth system science, Nature, 566, 195–204, 2019. a, b
Requena-Mesa, C., Benson, V., Reichstein, M., Runge, J., and Denzler, J.: EarthNet2021: A large-scale dataset and challenge for Earth surface forecasting as a guided video prediction task, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021, 1132–1142, https://doi.ieeecomputersociety.org/10.1109/CVPRW53098.2021.00124 (last access: 4 November 2024), 2021. a
Robin, C., Requena-Mesa, C., Benson, V., Alonso, L., Poehls, J., Carvalhais, N., and Reichstein, M.: Learning to forecast vegetation greenness at fine resolution over Africa with ConvLSTMs, arXiv [preprint], https://doi.org/10.48550/arXiv.2210.13648, 2022. a
Rosso, O. A. and Masoller, C.: Detecting and quantifying temporal correlations in stochastic resonance via information theory measures, Eur. Phys. J. B, 69, 37–43, 2009. a
Rosso, O. A., Larrondo, H., Martin, M. T., Plastino, A., and Fuentes, M. A.: Distinguishing noise from chaos, Phys. Rev. Lett., 99, 154102, https://doi.org/10.1103/PhysRevLett.99.154102, 2007. a, b, c
Rouse, J. W., Haas, R. H., Schell, J. A., and Deering, D. W.: Monitoring vegetation systems in the Great Plains with ERTS, NASA Spec. Publ, 351, 309, https://ntrs.nasa.gov/citations/19740022614 (last access: 4 November 2024), 1974. a, b
Rudy, S. H. and Sapsis, T. P.: Output-weighted and relative entropy loss functions for deep learning precursors of extreme events, Physica D, 443, 133570, https://doi.org/10.1016/j.physd.2022.133570, 2023. a
Rumelhart, D. E., Hinton, G. E., and Williams, R. J.: Learning representations by back-propagating errors, Nature, 323, 533–536, 1986. a, b
Savitzky, A. and Golay, M. J.: Smoothing and differentiation of data by simplified least squares procedures, Anal. Chem., 36, 1627–1639, 1964. a
Scheepens, D. R., Schicker, I., Hlaváčková-Schindler, K., and Plant, C.: Adapting a deep convolutional RNN model with imbalanced regression loss for improved spatio-temporal forecasting of extreme wind speed events in the short to medium range, Geosci. Model Dev., 16, 251–270, https://doi.org/10.5194/gmd-16-251-2023, 2023. a
Schulz, L., Vollmer, J., Mahecha, M. D., and Mora, K.: Nonlinear spectral analysis extracts harmonics from land-atmosphere fluxes, arXiv [preprint], https://doi.org/10.48550/arXiv.2407.19237, 2024. a, b, c
Seneviratne, S., Zhang, X., Adnan, M., Badi, W., Dereczynski, C., Di Luca, A., Ghosh, S., Iskandar, I., Kossin, J., Lewis, S., Otto, F., Pinto, I., Satoh, M., Vicente-Serrano, S., Wehner, M., and Zhou, B.: Weather and Climate Extreme Events in a Changing Climate, in: Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change, edited by: Masson-Delmotte, V., Zhai, P., Pirani, A., Connors, S., Péan, C., Berger, S., Caud, N., Chen, Y., Goldfarb, L., Gomis, M., Huang, M., Leitzell, K., Lonnoy, E., Matthews, J., Maycock, T., Waterfield, T., Yelekçi, O., Yu, R., and Zhou, B., Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 1513–1766, https://doi.org/10.1017/9781009157896.013, 2021. a
Shi, X., Chen, Z., Wang, H., Yeung, D.-Y., Wong, W.-K., and Woo, W.-C.: Convolutional LSTM network: A machine learning approach for precipitation nowcasting, Adv. Neur. In., 28, 802–810, https://dl.acm.org/doi/10.5555/2969239.2969329 (last access: 4 November 2024), 2015. a
Sippel, S., Lange, H., Mahecha, M. D., Hauhs, M., Bodesheim, P., Kaminski, T., Gans, F., and Rosso, O. A.: Diagnosing the dynamics of observed and simulated ecosystem gross primary productivity with time causal information theory quantifiers, PloS one, 11, e0164960, https://doi.org/10.1371/journal.pone.0164960, 2016. a, b, c, d, e
Sippel, S., Reichstein, M., Ma, X., Mahecha, M. D., Lange, H., Flach, M., and Frank, D.: Drought, heat, and the carbon cycle: a review, Current Climate Change Reports, 4, 266–286, 2018. a
Sitch, S., Smith, B., Prentice, I. C., Arneth, A., Bondeau, A., Cramer, W., Kaplan, J. O., Levis, S., Lucht, W., Sykes, M. T., Thonicke, K., and Venevsky, S.: Evaluation of ecosystem dynamics, plant geography and terrestrial carbon cycling in the LPJ dynamic global vegetation model, Glob. Change Biol., 9, 161–185, 2003. a
Slayback, D. A., Pinzon, J. E., Los, S. O., and Tucker, C. J.: Northern hemisphere photosynthetic trends 1982–99, Glob. Change Biol., 9, 1–15, https://doi.org/10.1046/j.1365-2486.2003.00507.x, 2003. a
Srinivasan, P. A., Guastoni, L., Azizpour, H., Schlatter, P., and Vinuesa, R.: Predictions of turbulent shear flows using deep neural networks, Physical Review Fluids, 4, 054603, https://doi.org/10.1103/PhysRevFluids.4.054603, 2019. a
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting, J. Mach. Learn. Res., 15, 1929–1958, 2014. a
Steinier, J., Termonia, Y., and Deltour, J.: Smoothing and differentiation of data by simplified least square procedure, Anal. Chem., 44, 1906–1909, 1972. a
Sun, C., Song, M., Cai, D., Zhang, B., Hong, S., and Li, H.: A systematic review of echo state networks from design to application, IEEE Transactions on Artificial Intelligence, 5, 23–37, 2022. a
Sutskever, I.: Training recurrent neural networks, PhD thesis, University of Toronto Toronto, ON, Canada, ISBN 9780499220660, 2013. a
Teskey, R., Wertin, T., Bauweraerts, I., Ameye, M., McGuire, M. A., and Steppe, K.: Responses of tree species to heat waves and extreme heat events, Plant Cell Environ., 38, 1699–1712, 2015. a
Tietz, M., Fan, T. J., Nouri, D., Bossan, B., and skorch Developers: skorch: A scikit-learn compatible neural network library that wraps PyTorch, Skorch [code], https://skorch.readthedocs.io/en/stable/ (last access: 25 October 2024), 2017. a
Van Mantgem, P. J., Stephenson, N. L., Byrne, J. C., Daniels, L. D., Franklin, J. F., Fulé, P. Z., Harmon, M. E., Larson, A. J., Smith, J. M., Taylor, A. H., and Veblen, T. T.: Widespread increase of tree mortality rates in the western United States, Science, 323, 521–524, 2009. a
Verstraeten, D., Schrauwen, B., d'Haene, M., and Stroobandt, D.: An experimental unification of reservoir computing methods, Neural Networks, 20, 391–403, 2007. a
Vlachas, P., Pathak, J., Hunt, B., Sapsis, T., Girvan, M., Ott, E., and Koumoutsakos, P.: Backpropagation algorithms and Reservoir Computing in Recurrent Neural Networks for the forecasting of complex spatiotemporal dynamics, Neural Networks, 126, 191–217, https://doi.org/10.1016/j.neunet.2020.02.016, 2020. a
von Buttlar, J., Zscheischler, J., Rammig, A., Sippel, S., Reichstein, M., Knohl, A., Jung, M., Menzer, O., Arain, M. A., Buchmann, N., Cescatti, A., Gianelle, D., Kiely, G., Law, B. E., Magliulo, V., Margolis, H., McCaughey, H., Merbold, L., Migliavacca, M., Montagnani, L., Oechel, W., Pavelka, M., Peichl, M., Rambal, S., Raschi, A., Scott, R. L., Vaccari, F. P., van Gorsel, E., Varlagin, A., Wohlfahrt, G., and Mahecha, M. D.: Impacts of droughts and extreme-temperature events on gross primary production and ecosystem respiration: a systematic assessment across ecosystems and climate zones, Biogeosciences, 15, 1293–1318, https://doi.org/10.5194/bg-15-1293-2018, 2018. a
Walleshauser, B. and Bollt, E.: Predicting sea surface temperatures with coupled reservoir computers, Nonlin. Processes Geophys., 29, 255–264, https://doi.org/10.5194/npg-29-255-2022, 2022. a
Walther, S., Besnard, S., Nelson, J. A., El-Madany, T. S., Migliavacca, M., Weber, U., Carvalhais, N., Ermida, S. L., Brümmer, C., Schrader, F., Prokushkin, A. S., Panov, A. V., and Jung, M.: Technical note: A view from space on global flux towers by MODIS and Landsat: the FluxnetEO data set, Biogeosciences, 19, 2805–2840, https://doi.org/10.5194/bg-19-2805-2022, 2022 (data available at: https://meta.icos-cp.eu/collections/tEAkpU6UduMMONrFyym5-tUW, last access: 25 October 2024). a, b, c
Werbos, P. J.: Generalization of backpropagation with application to a recurrent gas market model, Neural Networks, 1, 339–356, 1988. a
Werbos, P. J.: Backpropagation through time: what it does and how to do it, P. IEEE, 78, 1550–1560, 1990. a
Williams, R. J. and Zipser, D.: Gradient-based learning algorithms for recurrent, Backpropagation: Theory, Architectures, and Applications, 433, 17, https://gwern.net/doc/ai/nn/rnn/1995-williams.pdf (last access: 4 November 2024), 1995. a
Yengoh, G. T., Dent, D., Olsson, L., Tengberg, A. E., and Tucker III, C. J.: Use of the Normalized Difference Vegetation Index (NDVI) to assess Land degradation at multiple scales: current status, future trends, and practical considerations, Springer, ISBN 978-3-319-24112-8, 2015. a
Zeng, N., Hales, K., and Neelin, J. D.: Nonlinear dynamics in a coupled vegetation–atmosphere system and implications for desert–forest gradient, J. Climate, 15, 3474–3487, 2002. a
Zeng, Y., Hao, D., Huete, A., Dechant, B., Berry, J., Chen, J. M., Joiner, J., Frankenberg, C., Bond-Lamberty, B., Ryu, Y., Xiao, J., Asrar, G. R., and Chen, M.: Optical vegetation indices for monitoring terrestrial ecosystems globally, Nature Reviews Earth & Environment, 3, 477–493, 2022. a, b
Zhang, Q., Wang, H., Dong, J., Zhong, G., and Sun, X.: Prediction of sea surface temperature using long short-term memory, IEEE Geosci. Remote S., 14, 1745–1749, 2017. a
Zhang, Z., Xin, Q., and Li, W.: Machine Learning-Based Modeling of Vegetation Leaf Area Index and Gross Primary Productivity Across North America and Comparison With a Process-Based Model, J. Adv. Model. Earth Sy., 13, e2021MS002802, https://doi.org/10.1029/2021MS002802, 2021. a
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Recurrent neural network details
- Appendix B: Computational details
- Appendix C: Site comparison
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Recurrent neural network details
- Appendix B: Computational details
- Appendix C: Site comparison
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References