the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 10 Jul 2024
| 10 Jul 2024
Leading the Lorenz 63 system toward the prescribed regime by model predictive control coupled with data assimilation
Shunji Kotsuki
Recently, concerns have been growing about the intensification and increase in extreme weather events, including torrential rainfall and typhoons. For mitigating the damage caused by weather-induced disasters, recent studies have started developing weather control technologies to lead the weather to a desirable direction with feasible manipulations. This study proposes introducing the model predictive control (MPC), an advanced control method explored in control engineering, into the framework of the control simulation experiment (CSE). In contrast to previous CSE studies, the proposed method explicitly considers physical constraints, such as the maximum allowable manipulations, within the cost function of the MPC. As the first step toward applying the MPC to real weather control, this study performed a series of MPC experiments with the Lorenz 63 model. Our results showed that the Lorenz 63 system can be led to the positive regime with control inputs determined by the MPC. Furthermore, the MPC significantly reduced necessary forecast length compared to earlier CSE studies. It was beneficial to select a member that showed a larger regime shift for the initial state when dealing with uncertainty in initial states.
- Article
(3908 KB) - Full-text XML
- BibTeX
- EndNote





In recent years, concerns have been raised regarding the intensification and increase in extreme weather events such as torrential rainfall and typhoons. To mitigate the damage caused by weather-induced disasters, efforts have been made to improve the forecasting accuracy of stationary heavy rainfall and develop disaster prevention infrastructures, including dams and embankments. Recently, Japan's Moonshot program started exploring alternative countermeasures for mitigating weather-induced disasters. Specifically, the program aims at developing weather control technologies to lead the weather to a desirable regime with feasible manipulations. Under the program, researchers are exploring various engineering techniques such as cloud seeding and atmospheric heating. However, the possible magnitude of humans' manipulations of the atmosphere is limited. Therefore, simulation studies using numerical weather prediction (NWP) models are needed in addition to the engineering studies to develop effective control approaches with feasible manipulations.
To date, a few simulation studies with NWP models have been conducted for mitigating extreme events. For example, Henderson et al. (2005) conducted numerical experiments using a modified version of the Fifth-Generation Penn State/NCAR Mesoscale Model (MM5) 4D-Var to identify the temperature increments required for minimizing wind-related damage caused by Hurricane Andrew in 1992. However, the results may not be sufficiently realistic due to various experimental limitations (Henderson et al., 2005). The Typhoon Science and Technology Research Center of Yokohama National University proposed using sailing ships and artificial upwelling to reduce the intensity of tropical cyclones. Their simulations demonstrated that the drag enhancement caused by the sailing ships and sea surface temperature decrease by the artificial upwelling successfully weakened tropical cyclones (Hironori Fudeyasu; personal communication, 2023). Previous studies, however, examined impacts of the manipulations on specific extreme events through control experiments that simply compared simulations with and without manipulations. Here, a research framework is necessary to develop effective control approaches with feasible manipulations.
Miyoshi and Sun (2022; hereafter MS22) proposed a control simulation experiment (CSE), an experimental framework for systematically evaluating and exploring control approaches with unknown true values by expanding the observing systems simulation experiment (OSSE). They conducted CSEs with the three-variable Lorenz 63 model (Lorenz, 1963) and succeeded in leading the system to the positive regime with small control inputs. Sun et al. (2023; hereafter SMR23) also applied to CSEs for the 40-variable Lorenz 96 model (Lorenz, 1996), showing that their CSEs succeeded in reducing the number of extreme events of the Lorenz 96 model. Furthermore, Ouyang et al. (2023; hereafter OTK23) successfully reduced the total magnitude of control inputs with the Lorenz 63 model by approximately 20 % compared to MS22's approach by regulating the amplitude of control inputs based on the maximum growth rate of the singular vector. The previous CSE studies (MS22, SMR23, and OTK23) generated control inputs as differences between ensemble members that stay within and those that deviate from the desired regime. However, physical constraints, generally needed for real-world applications, cannot be explicitly considered in previous CSE studies. Therefore, it is worthwhile to explore other methodologies to determine control inputs.
In this study, we propose introducing the model predictive control (MPC) within the framework of CSE. The MPC is an advanced control method that repeats prediction and optimization with explicit consideration of constraints. While the MPC has been widely used in practical fields such as the process industry and power electronics (Schwenzer et al., 2021), there has been no study yet that used the MPC for mitigating weather-induced disasters to the best of our knowledge. As the first step toward applying the MPC to the real weather control, this study performs a series of MPC experiments with the Lorenz 63 model. Here we explore the way to implement the MPC within CSE and aim to reveal important issues to extend the MPC to high-dimensional NWP models.
The remaining sections of this paper are arranged as follows. Section 2 introduces the theory of the MPC and describes the experimental setting. In Sect. 3, we employ a series of MPC experiments with the Lorenz 63 model and discuss properties of the MPC applied to the chaotic dynamical systems. Finally, Sect. 4 provides a summary.
2.1 Model predictive control
2.1.1 Definition and procedure
This study explores using the MPC for controlling a chaotic dynamical system. Here, the MPC is a feedback control method that identifies control inputs to minimize the cost function under constraints at each time. In other words, the MPC is a control method that solves an optimal control problem (OCP) for a finite horizon at each time. Strictly speaking, the MPC considered in this study is nonlinear model predictive control (Chen and Shaw, 1982; Keerthi and Gilbert, 1988; Mayne and Michalska, 1990; Mayne et al., 2000).
First, we define the terminology and symbols. As shown in Fig. 1, the two key processes of the MPC are model-based prediction and optimization of control inputs in the OCP. For these processes, the prediction horizon, Tp, and the control horizon, Tc, are defined independently, where subscripts p and c denote prediction and control. Here, Tp (0<Tp) is the length of state prediction and Tc () is the length of the control inputs to be optimized. A new axis, τ, is the time axis for variables under the optimization and set to be different from the time axis, t. Therefore, τ=0 denotes the initial times of the horizons. Furthermore, variables in both horizons are marked with a superscript ∗; for example, a state x at τ=τi on the horizon at t=ti is denoted by .
Next, we describe the procedure of the MPC. First, the MPC requires the suitable design of a numerical model, ; a cost function, ; a set of constraints, ; and a first guess of control inputs, , from τ=0 to τ=Tc for the desirable control. Now, we consider the process of obtaining the control input, u, at t=ti based on the MPC.
-
The present state x(ti) is used as the initial state for an OCP (i.e., ).
-
The predicted state, , from τ=0 to τ=Tp is obtained by the numerical model, .
-
Based on , the solution is updated from τ=0 to τ=Tc through optimization (see Sect. 2.1.2).
-
Prediction (step 2) and optimization (step 3) are iterated with updated and until is sufficiently converged (see Sect. 2.1.2).
-
The control input, u(t), taken from finally updated from τ=0 to (), is used for the manipulation from t=ti to .
-
The process returns to step 1 and repeats these steps at .
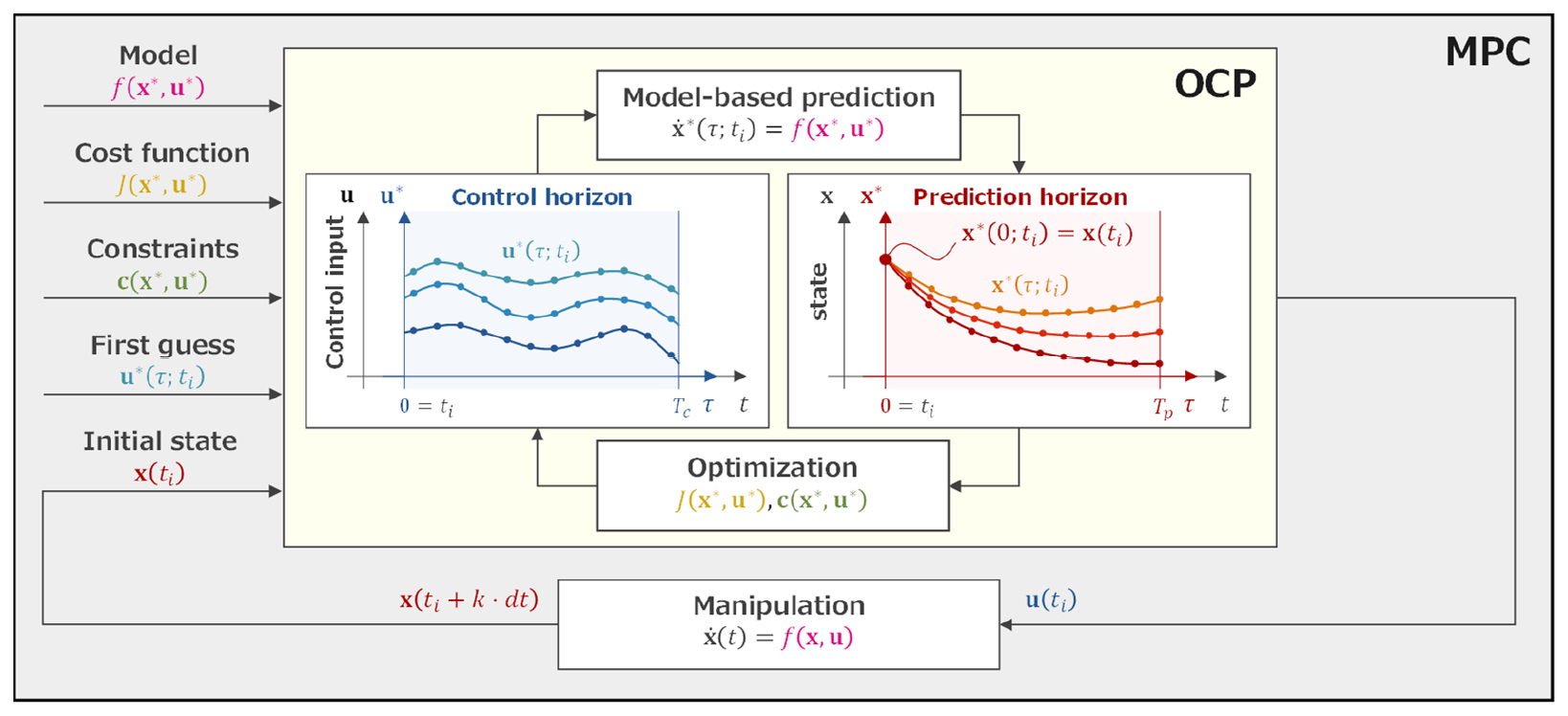
Figure 1Conceptual image of the model predictive control (MPC; the gray block). A numerical model, ; a cost function, ; a set of constraints, ; and a first guess of control inputs, , are given to the optimal control problem (OCP; the yellow block). The initial state, x(ti), is also given by the model time integration with manipulations. The OCP is solved by iterating prediction and optimization until the solution u(ti) is sufficiently converged. Finally, the manipulation is performed by applying the u(ti) to x(ti). The same process is repeated at the next time ().
2.1.2 Optimal control problem
As previously noted, the MPC identifies control inputs that allow the system to achieve a desirable state for a finite horizon by solving the OCP at each time. Here, we explain that the OCP can be regarded as a variational problem with constraints. We consider a basic OCP with control and prediction horizons being for ease of comprehension. The general equations of state for a nonlinear model and the initial state are given by
where their dimensions are and , respectively. The scalars n and l represent the number of model variables and manipulation variables, respectively. The general cost function of the OCP is given by
where is the terminal cost and is the stage cost. Both are scalar functions, and various control objectives can be considered by a suitable design of these functions. The general constraints of the problem are given by
where is a vector whose elements are equality constraints restricted to zero. The scalar j is the number of constraints. When inequality constraints are imposed, the constrained problem can be addressed by methods such as the penalty method or the slack variable technique. This study uses the penalty method, which adds large penalties to the cost function when the constraints are not satisfied (see Eq. 26). On the other hand, the slack variable technique converts inequality constraints to equality constraints by introducing dummy variables. The addition of the dummy variables, however, makes the OCP more complicated. Therefore, we did not use the slack variable technique in this study. In summary, the OCP is regarded as the following variational problem that optimizes the cost function, subject to the equation of state and constraints:
We note that the equation of state (Eq. 1) is also regarded as an equality constraint (the first equation in Eq. 6) by transposing of Eq. (1) to the right-hand side.
The following necessary conditions for optimal control inputs are obtained by converting the constrained problem to an unconstrained problem using the method of Lagrange multipliers (see Appendix A):
where is the Lagrange multiplier for the equation of state, is the Lagrange multiplier for the constraints, and is the Hamiltonian defined as
The derivation of the necessary conditions of the optimal control inputs is detailed in Appendix A. For nonlinear models, it is generally impossible to solve these equations analytically. Therefore, this study solves them using a numerical approach. Given the first guess of the control input, , temporal forward computations (Eqs. 7 and 8) are performed to obtain from τ=0 to τ=T. In this study, zero vectors are selected as the first guess of the control input, , because the minimization of the control input is also included in the cost function, , as seen later (Eq. 26). Furthermore, is obtained by temporal backward computations from τ=T to τ=0 (Eqs. 9 and 10). Consequently, and from τ=0 to τ=T can be obtained by applying an optimization algorithm to the nonlinear equations (Eqs. 11 and 12). Therefore, the OCP can be solved by iterating the prediction (Eq. 7) and optimization (Eqs. 11 and 12) until the solutions are sufficiently converged. In this study, the equations (Eqs. 7–12) are discretized with the fourth-order Runge–Kutta scheme. In addition, we used the Levenberg–Marquardt algorithm, which is the optimization algorithm for solving the nonlinear equations (Eqs. 11 and 12). In our preliminary experiments, the Levenberg-Marquardt algorithm solved the nonlinear equations stably compared to other optimization methods in SciPy libraries.
When the control horizon is shorter than the prediction horizon (Tc<Tp), the necessary conditions for optimal control inputs (Eqs. 7–12) are replaced by
where the subscript c denotes a function up to Tc with the control input, , and the subscript p denotes the function from Tc to Tp without the control input.
2.2 Model predictive control for the Lorenz 63 model
2.2.1 The Lorenz 63 model
This study uses the Lorenz 63 model for MPC experiments. The Lorenz 63 model is a three-variable nonlinear differential equation expressed as follows:
The model is known to behave in a chaotic manner under certain parameter values. In this study, σ=10, r=28, and are selected to form a butterfly pattern with two positive and negative regimes, following previous studies (MS22 and OTK23). Moreover, the model is discretized and integrated using the fourth-order Runge–Kutta scheme. One time step of integration is defined as dt=0.01 units of time throughout this study. With the Lorenz 63 model, the state vector becomes and the number of model variable is n=3.
2.2.2 The optimal control problem with the Lorenz 63 model
This study considers a control problem, namely keeping the Lorenz 63 system in the positive regime (x≥0) following previous studies (MS22 and OTK23). Note that our approach includes minimization of the control inputs owing to Eq. (26). The equations of state (Eq. 14) are given by
where and . As previously noted, one of the control objectives in this problem is leading the Lorenz 63 system to the positive regime. Therefore, the inequality constraint, , is imposed from τ=0 to τ=Tp. In this study, the penalty method is introduced to treat the inequality constraint and the penalty function for is defined as follows:
The inequality constraint can be considered in the cost function as follows. Including the minimization of the control inputs, the cost function is given by
where is the tunable penalty parameter that balances weights of magnitude of the control input ( and the inequality constraint in the cost function. The third term of Eq. (26) corresponds to the terminal cost (see Eq. 3) and is necessary for considering explicitly the terminal state of within the prediction horizon. This study employs from our preliminary investigations. Consequently, the necessary conditions for the optimal control inputs (Eqs. 14–19) are formulated using the following equations for the control problem of the Lorenz 63 model:
where . As discussed later, this control problem can be extended to other experimental settings, such as manipulating only one-variable control input (see Sect. 3.3) and adding a constraint for the L2 norm of control inputs (see Sect. 3.4).
2.3 Control simulation experiment with model predictive control
The CSE is an experimental framework that controls the nature run (NR), extended from OSSE. The key concept of CSE is that the true state of the NR is unknown, but manipulations can be added to the NR, assuming a realistic atmosphere.
Based on previous studies (Kalnay et al., 2007; Yang et al., 2012; MS22; OTK23), the experimental setting of our CSE is determined as follows. We first employ a free run with the Lorenz 63 model for 2 009 000 steps without any manipulations. The initial values of the free run are generated by random numbers N(0.0, 2.0) for x, y, and z independently. Observations are generated at every To=8 steps by adding uncorrelated Gaussian noise into the free run, where the subscript o denotes the observation. The DA cycles are performed by assimilating the generated observations for the last 2 008 000 steps by the ensemble Kalman filter (EnKF) (Evensen, 1994). This study employs the perturbed observation method (Burgers et al., 1998) as the EnKF to obtain a stable analysis ensemble under the nonlinear system (Lawson and Hansen, 2004). We discarded the first 8000 steps of the 2 008 000-step DA cycles for CSE. The root-mean-square errors (RMSEs) and multiplicative inflation parameters of 2 000 000-step DA cycles are shown in Table 1. In this study, 1000 independent CSEs for 2000 steps are performed from different starting points to evaluate the CSEs statistically. OTK23 noted that starting points around the large x are generally difficult for leading the system to the positive regime for the Lorenz 63 model. Therefore, the 1000 different starting points are sampled sequentially from the points satisfying in the 2 000 000-step DA cycles.
We employ three indicators to evaluate CSEs. The first index is the success rate (SR), which denotes the percentage of cases that satisfy x≥0 for entire experimental period (i.e., 2000 steps) among the 1000 CSEs. The mean total failure (MTF) and mean total control inputs (MTCIs) are defined as the mean of and of the 1000 CSEs, respectively.
The procedure of the CSE with MPC is designed as follows:
-
At a certain time t=ti, the observation yo(ti) is simulated from the NR.
-
DA is employed to obtain an analysis ensemble, Xa(ti).
-
The ensemble forecast, Xb(t), from t=ti to is computed from the analysis ensemble, Xa(ti).
-
If at least one member indicates a regime shift (RS) during the ensemble forecast, the process continues to step 5. Otherwise, the NR evolves until and returns to step 1.
-
The OCP is solved to obtain control input u(t) from t=ti to from the control input after iterations, , from τ=0 to τ=To.
-
The NR is evolved from t=ti to by applying the obtained control input u(t). In addition, the Xb(t) from t=ti to is computed by applying the same control input to the analysis ensemble, Xa(ti), for DA at the next time. Notably, the control inputs are applied to through the numerical model f(x,u) (see Eq. 1) rather than direct addition to x(t).
-
The process returns to step 1 and repeats these steps at .
Here, is an ensemble of state and m is the ensemble size. Superscripts a and b denote analysis and background, respectively.
This procedure is illustrated in Fig. 2. For simplicity, the flow diagrams of the CSE are divided into two cases: without a RS in Fig. 2a and with a RS in Fig. 2b. The procedure of the CSE for forecasts without a RS in Fig. 2a is identical to the OSSE. In contrast, the procedure of the CSE for forecasts with a RS in Fig. 2b has additional processes for identifying and applying control inputs. The upper illustration in Fig. 2c shows a conceptual image of identifying control inputs, and the lower illustration shows an application of control inputs to the NR through the Lorenz 63 model. Importantly, the NR cannot be used as the initial state of the OCP because it is always unknown. Therefore, an analysis ensemble is used as the initial state. As discussed later (Sect. 3.5), the initial state for the OCP substantially affects the control results, and the member with the smallest state x (i.e., the largest RS) in the ensemble forecast (step 3) is selected as the initial state in this study unless otherwise specified. In addition, Tc=8 steps is selected throughout this study from our preliminary investigations.
Table 1The RMSEs and the multiplicative inflation parameters used in this study for each ensemble size, m. The multiplicative inflation is applied to background ensemble perturbations. The inflation parameters were manually tuned so that analysis RMSEs are minimized over the 2 000 000-step OSSEs.

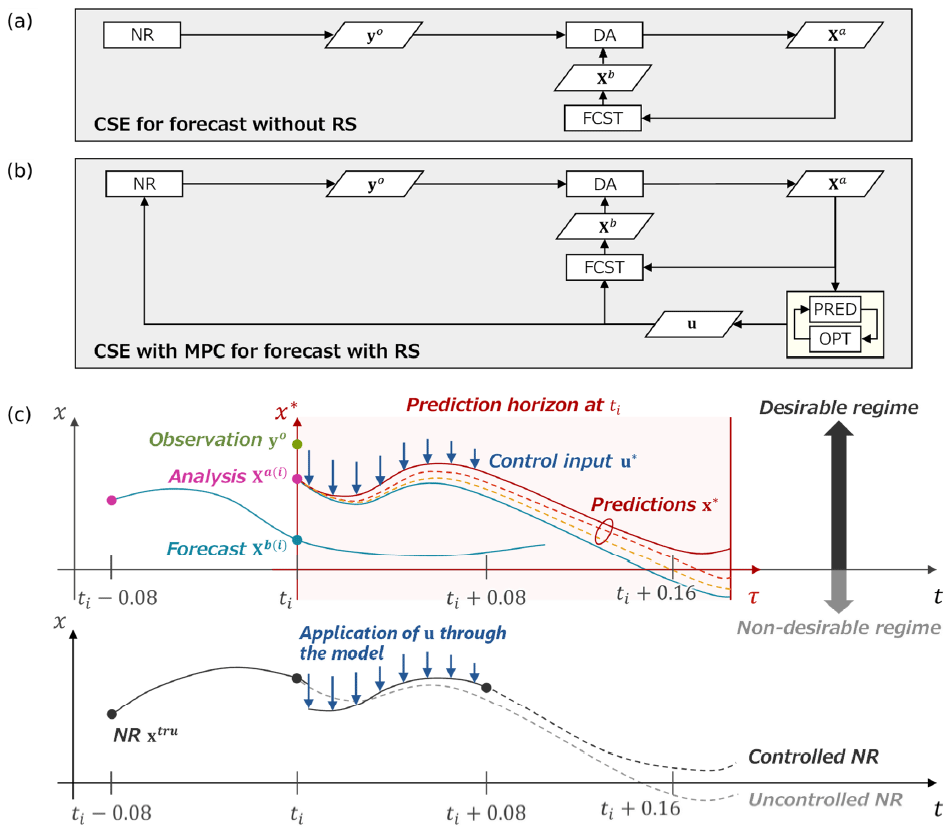
Figure 2Flow diagram and conceptual image of the CSE with MPC. (a) Flow diagram of CSE for forecasts without a RS, which is identical to OSSE. (b) Flow diagram of the CSE with MPC for forecasts with a RS, which has additional processes for identifying and applying control inputs. (c) Conceptual image of the CSE with MPC. The upper illustration shows an image of identifying control inputs, and the lower illustration shows an application of control inputs to the NR.
3.1 Impacts on the nature run
First, CSE is conducted with the Lorenz 63 model to verify the impacts of the MPC on the NR. The control objective is leading the system to the positive regime under the minimization of the three-variable control inputs. Here, Tp=20 steps and m=50 are selected, as discussed later in Sect. 3.2.
The NR and the L2 norm of control inputs, ∥u∥, are shown in Figs. 3 and 4. The butterfly pattern appears in Fig. 3a because no control input is applied. In contrast, the NR successfully keeps the positive regime with consideration of the inequality constraint by the MPC in Figs. 3b and 4a. This result indicates that the NR can be controlled by the short forecast (i.e., Tp=20 steps). Importantly, the value of ∥u∥ identified by the MPC is applied to the time derivative of states (i.e., . Therefore, the magnitude of the control inputs added to x during dt=0.01 is ∥u∥⋅dt. As demonstrated in Fig. 4b, the maximum value of the control inputs added to x during dt is approximately , which is smaller than the maximum value of states.
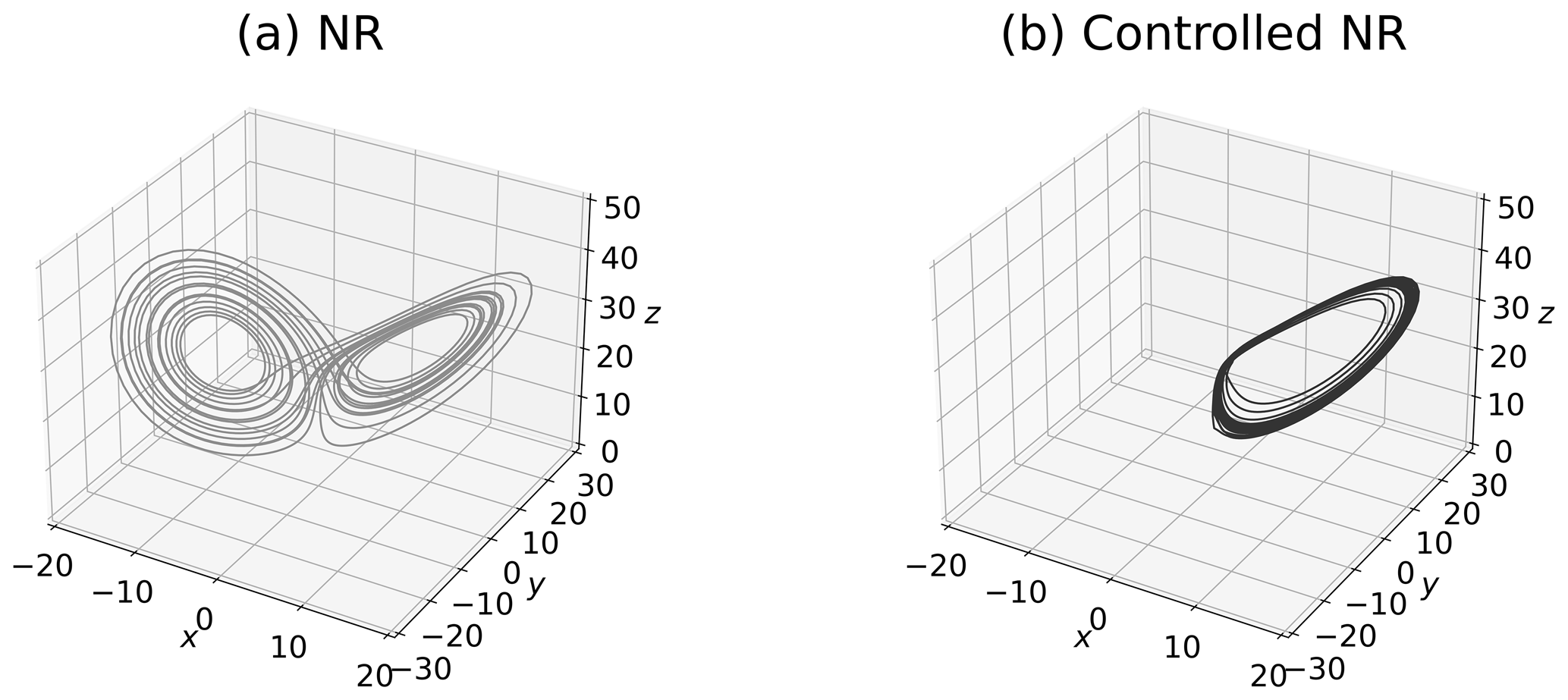
Figure 3The NR and controlled NR of the Lorenz 63 model for 2000 steps. Each starting point is selected from the 24th step of 2 000 000-step DA cycles. Panel (a) shows the uncontrolled NR without the MPC. Panel (b) shows the controlled NR by the MPC with Tp=20 steps, Tc=8 steps, and m=50.

Figure 4The controlled NR and the L2 norm of control inputs with Tp=20 steps, Tc=8 steps, and m=50. The starting point is the 24th step of 2 000 000-step DA cycles. Panel (a) shows the time series of state x. Panel (b) shows the L2 norm of control inputs, ∥u∥.
Figure 5 shows the prediction of the state and optimization of the control inputs in each horizon at an arbitrary selected step (the 232nd step of the CSE of Fig. 4). Since the forecast (dashed blue line) from the initial state shows a RS, the control is activated to solve the OCP. As demonstrated in Fig. 5a, the trajectory of the controlled prediction gradually shifts to satisfy by iterative computations; finally, is satisfied (solid red line). The uncontrolled NR shows a RS (dashed gray line); in contrast, the controlled NR can avoid the RS (solid black line) through the addition of control inputs (Fig. 5b, c, and d) after iterations. Note that the final prediction in the OCP and the controlled NR are not identical because the prediction in the OCP used an initial state from the member with the largest RS rather than the NR.

Figure 5The prediction of the state and optimization of the control inputs in the horizon at an arbitrary selected step (the 232nd step of the CSE of Fig. 4). Iterative computations were performed 356 times for solving the OCP in this case. (a) The predictions, NRs, forecast, analysis, and observation in Tp. Panels (b), (c), and (d) show the control inputs , , and during optimization in Tc.
3.2 Sensitivity to the prediction horizon and the ensemble size
Here, we investigate the sensitivity to Tp and m for MPC performance. For that purpose, we conducted 1000 independent CSEs and summarized their SR, MTF, and MTCIs in Fig. 6. The darker color in Fig. 6 indicates better controllability. Higher values of m generally yield better results, increasing the SR and reducing MTF and MTCIs. However, improvements owing to the increased ensemble size, m, converge for m≥50 in many cases. The reasons for the improved results with larger ensemble size, m, are discussed in Sect. 3.5. In addition, the results with shorter Tp, such as Tp=10 steps, tend to be worse; the MTCIs in particular would increase because the control would be difficult by delaying the timing of control activation. On the other hand, longer Tp would not necessarily improve the results. In particular, it considerably worsens at Tp=50 steps, presumably because of discrete approximation errors involving state evolution in Tp.
It should be noted that a higher SR does not necessarily indicate lower MTF. For example, focusing on m=30, the SR of Tp=10 steps (SR=0.487) is much lower than the SR of Tp=40 steps (SR=0.921). However, the MTF of Tp=10 steps ( is lower than the MTF of Tp=40 steps (). Therefore, control would fail more frequently, but not significantly, with Tp=10 steps than with Tp=40 steps.
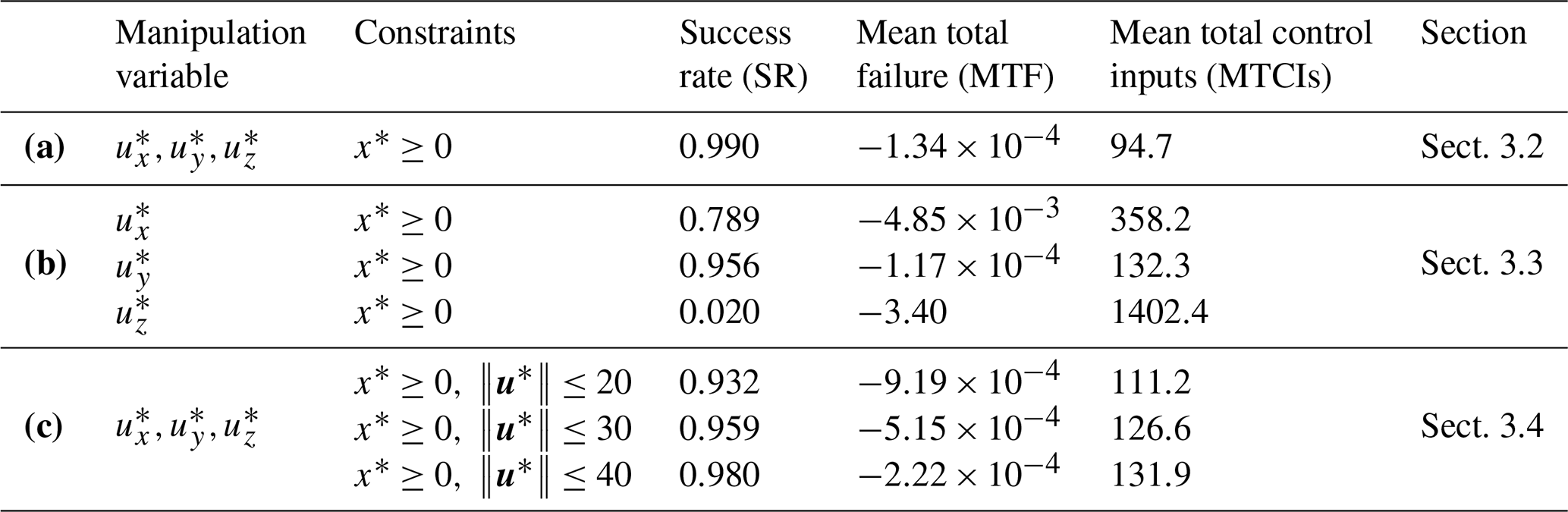
Hereafter, the experiment with Tp=20 steps and m=50 is considered to be a standard experimental setting in this study because the parameters yielded one of the best performances. The SR, MTF, and MTCIs in several experimental settings with Tp=20 steps and m=50, including the experiments discussed later (see Sect. 3.3 and 3.4), are summarized in Table 2.

Figure 6Sensitivity to the prediction horizon, Tp, and the ensemble size, m, with three evaluation indicators: (a) success rate (SR), (b) mean total failure (MTF), and (c) mean total control inputs (MTCIs). Darker colors in (a), (b), and (c) indicate better controllability.
Table 2Summary of the success rate (SR), mean total failure (MTF), and mean total control inputs (MTCIs) for results in each experimental setting, with Tp=20 steps and m=50 in 1000 CSEs. Row (a) shows the results of the standard MPC experiment. Row (b) shows the results of MPC experiments with only one-variable control input, and row (c) shows the results of MPC experiments with an additional constraint for the L2 norm of control inputs.
3.3 MPC experiments with one-variable control input
For realistic control scenarios, it is important to consider control problems in which limited control inputs relative to model dimensions are available. Here, this section investigates the CSE with one-variable control input.
Figure 7a, b, and c show the NRs controlled only by ux, uy, or uz, respectively. While the NR controlled by ux (Fig. 7a) shows a pattern fluctuating around x=0, the NR controlled by uy (Fig. 7b) exhibits a pattern similar to the case of three-variable control inputs (Fig. 3b). Intriguingly, the NR controlled by uz demonstrates an unstable pattern that does not significantly deviate from x≥0. In addition, the SR, MTF, and MTCIs for the 1000 CSEs are listed in Table 2b. Compared with the case of three-variable control inputs presented in Table 2a, the case with only uy is slightly inferior yet comparable; the controllability of the case with ux is more difficult, and the difficulty escalates further when employing uz. In particular, the MTCIs are larger for the case with only uy, ux, and uz, in that order. Therefore, the NR controlled by ux slightly fluctuates in the x direction, and the NR controlled by uz significantly fluctuates in the z direction.
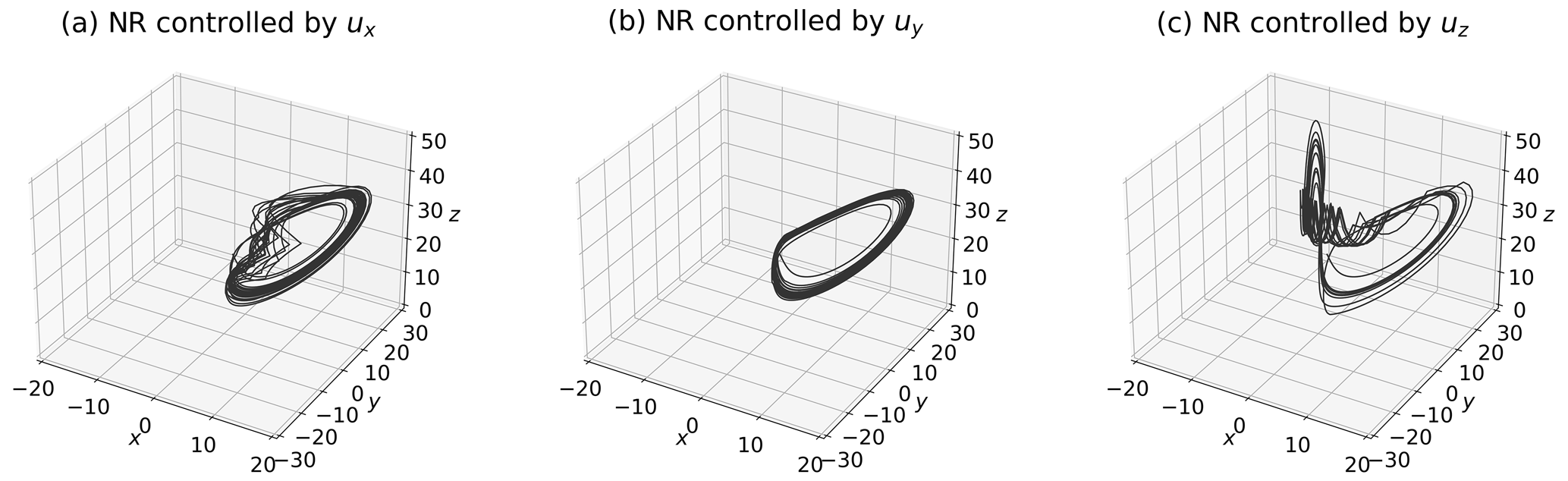
Figure 7The NRs controlled by one-variable control input: (a) controlled by ux, (b) controlled by uy, and (c) controlled by uz. Each starting point is identical to Fig. 3 (i.e., the 24th step of 2 000 000-step DA cycles).
3.4 MPC experiments constrained by magnitudes of control inputs
Here, we show that the MPC can consider constraints for control inputs in addition to the constraint for state (i.e., . Therefore, we consider MPC experiments with additional inequality constraints: the L2 norm of the control inputs . Namely, this section discusses MPC experiments constrained by the magnitude of control inputs. For that purpose, this study also treats with the penalty method whose function is given by
In this study, is selected as the penalty parameter for from our preliminary experiments.
Figure 8 shows the NRs and the L2 norm of the control inputs with additional . In all cases of U, the NRs (Fig. 8a, c, and e) indicate patterns similar to the case without (Fig. 3b). The L2 norm of the control inputs, ∥u∗∥, satisfies the constraint for each U (Fig. 8b, d, and f), especially for a larger U. However, with a smaller U (i.e., U=20), the L2 norm of control inputs occasionally exceeds the prescribed upper limit significantly. This is because the penalty method adds a penalty weighted by to the cost function and does not guarantee satisfying the constraint every time. Therefore, different results can be obtained by adjusting . For example, by increasing , can be more strictly satisfied instead of decreasing the weight for . The SR, MTF, and MTCIs for the 1000 CSEs are presented in Table 2c. Compared with the result in the absence of listed in Table 2a, the result with is worse overall because the constraint imposes more difficulty on the control problem. In addition, the MTCIs decrease for a smaller U, but the SR and MTF do worsen accordingly.
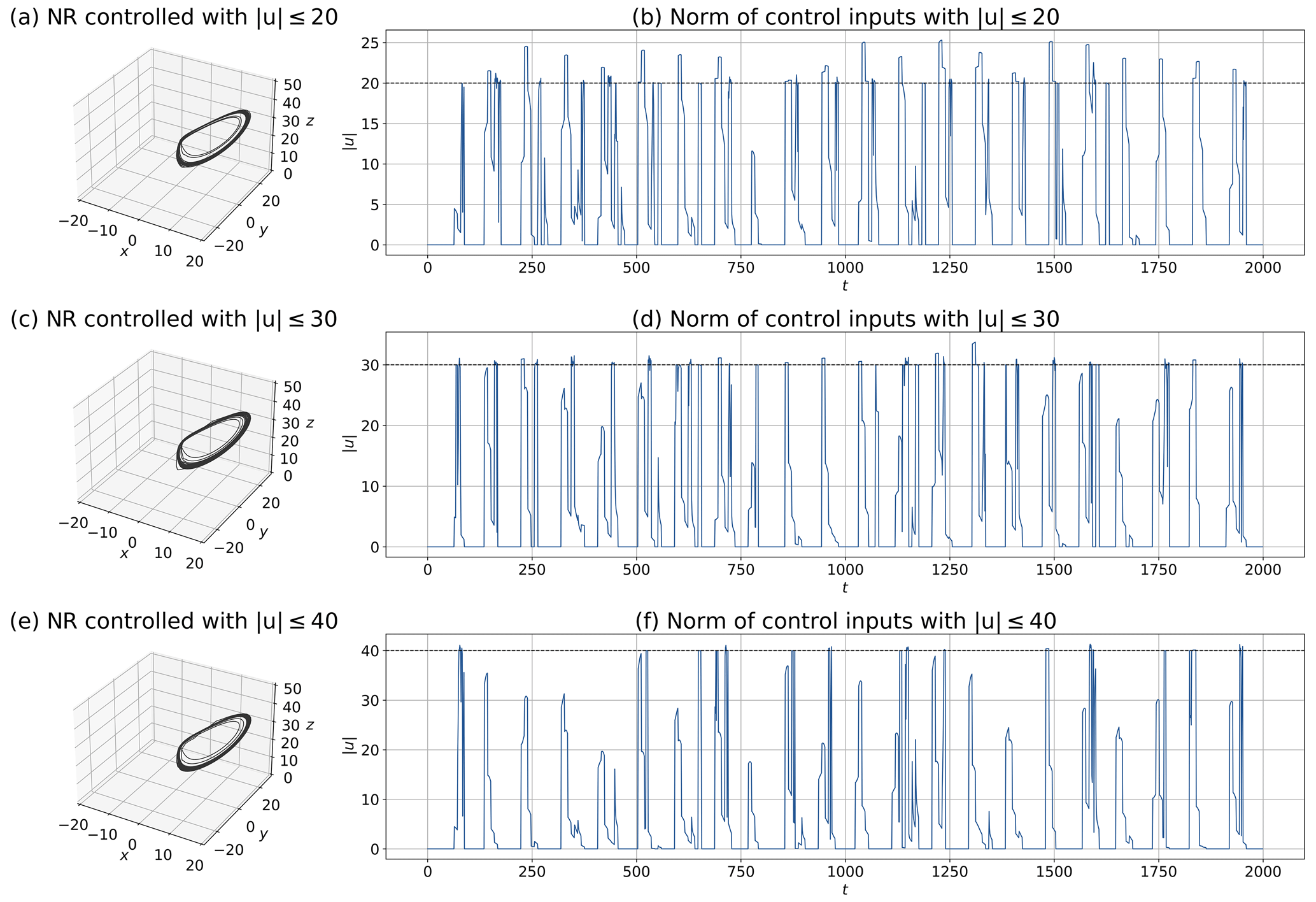
Figure 8MPC experiments with inequality constraints for control inputs with : (a, b) U=20, (c, d) U=30, and (e, f) U=40. Panels (a), (c), and (e) show the NRs, and panels (b), (d), and (f) show the L2 norm of control inputs. The dashed lines in panels (b), (d), and (f) show the prescribed upper limits of the control inputs (i.e., U=20, 30, and 40). Each starting point is identical to Fig. 3 (i.e., the 24th step of 2 000 000-step DA cycles).
3.5 Sensitivity to the initial state
For controlling NRs, it would be preferable to use the NR as the initial state for identifying control inputs. However, the state estimated by DA must be used because the true value is always unknown. Therefore, there is uncertainty in MPC-derived control inputs based on the states estimated by DA. This uncertainty may not cause serious problems for some systems without strong nonlinearity. Chaotic dynamical systems, however, require careful explorations of options for stable control because small uncertainties can cause large differences. Here, we discuss the initial state that would be valid for leading a chaotic dynamical system to a prescribed regime.
We performed 1000 independent CSEs and computed the SR, MTF, and MTCIs for five kinds of initial states: random (all mem.), mean (all mem.), random (RS mem.), mean (RS mem.), and largest (RS mem.), respectively. The (all mem.) label denotes selection among all members in the analysis ensemble, and the (RS mem.) label denotes selection among the members of the analysis ensemble showing RSs. The random label denotes a randomly sampled member, the mean label denotes the mean of the members, and the largest label denotes the member showing the largest RS. For example, mean (all mem.) indicates the mean analysis ensemble. The results are shown in Fig. 9. The experiment with the largest (RS mem.) state yielded the best results, showing the highest SR and the smallest MTF and MTCIs. Furthermore, Fig. 9 shows that it is better to use a member selected from the (RS mem.) group rather than (all mem.) as the initial state. We presume that it is safer to select a member showing a larger RS for the initial state when uncertainty exists in initial state. Therefore, the improvement with a larger ensemble size, m, in Sect. 3.2 is attributed to the fact that a larger ensemble size, m, can provide a member with a larger RS. Consequently, obtaining a member with a larger RS would be important for successfully leading chaotic dynamical systems to the prescribed regime by the MPC.
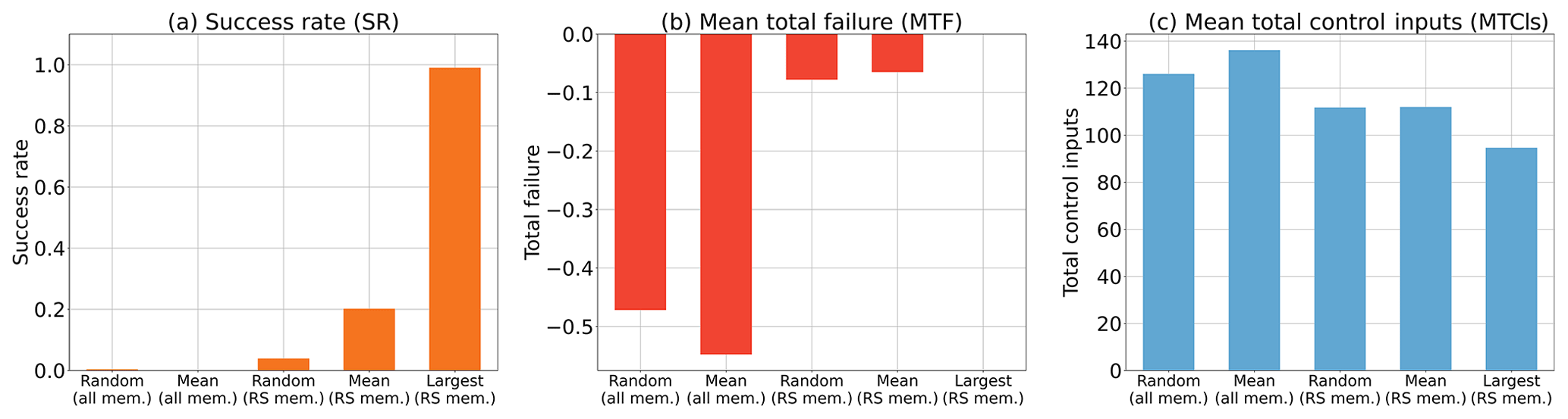
Figure 9Sensitivity to the initial state, with Tp=20 steps and m=50. Three evaluation indicators are shown for (a) success rate (SR), (b) mean total failure (MTF), and (c) mean total control inputs (MTCIs), respectively. The (all mem.) label denotes selection from among all members in the analysis ensemble, and the (RS mem.) label denotes selection from among the members of the analysis ensemble showing RSs. The Random label denotes a randomly sampled member, the Mean label denotes the mean of the members, and the Largest label denotes the member showing the largest RS.
In this study, we propose introducing the MPC within the framework of CSE. The advantage of using the MPC is that control objectives and constraints can be explicitly considered. Therefore, we expect that this approach will be useful for realistic weather control by designing a suitable cost function and constraints.
We conducted MPC experiments with the Lorenz 63 model and successfully led the system to the positive regime. The previous CSE studies (MS22 and OTK23) required longer forecasts (about 300 steps) for successful controls with the Lorenz 63 model, whereas our approach required much shorter forecasts, such as with 20 steps. We also confirmed that controllability would be difficult with limited variables of control inputs or with additional constraints. In our discussion, we suggest that it is safer to select a member showing a larger RS for the initial state when dealing with uncertainty in initial states.
This study is an investigation of the first phase of the MPC for weather control. In the future, this approach will be investigated with more realistic NWP models. In addition, several improvements remain for the MPC to be applied to weather control. Our present approach requires many iterations to solve the OCP, and temporal forward and backward computations are required for each iteration. This means that it is computationally difficult to apply the present approach to high-dimensional NWP models as it is. Therefore, further studies are needed to explore faster approaches to solve OCPs for high-dimensional models. For this challenge, we expect the continuation/generalized minimal residual (C/GMRES) method (Ohtsuka, 2004) and quantum annealing (Inoue and Yoshida, 2020) to be fast solvers for the MPC. Furthermore, we need to consider a variety of uncertainties such as model errors and weather shifts during identifying control inputs. Therefore, uncertainty quantification is also an important research topic prior to real-world field experiments.
Finally, we emphasize caution in weather control research. The achievement of control for extreme events would be an innovative way to mitigate weather-induced disasters. However, the side effects of weather control must be carefully examined from an ethical, legal, and social issues (ELSI) perspective. In particular, we need to discuss not only the destructive side effects caused by control failures, but also the impact on biodiversity and many industries (e.g., electricity production). Our research program also addresses such social issues with legal and ethical researchers. Further ELSI research will also be conducted to satisfy responsible and innovative research for weather control studies.
Here, we derive the necessary conditions for optimal control inputs. For simplicity, we consider the following problem:
A Lagrangian function is introduced to convert the constrained problem to an unconstrained problem. The Lagrangian is defined as
In addition, a Hamiltonian is defined as follows:
is then represented using H; it is divided into terms and other terms in the integral as follows:
The stationary condition of , which does not have constraints explicitly, is equal to the stationary condition of the original constrained problem. Namely, the original constrained problem was converted to an unconstrained problem. We note that this is not valid for special cases in which the linear independence constraint qualification is not satisfied. The stationary condition of is that its variation, (i.e., infinitesimal change), is zero. After applying the Taylor expansion and disregarding higher-than-second-order terms of δx∗ and δu∗, is given by
Importantly, because is fixed by x(t). In addition, δλ∗ and δρ∗ are disregarded because consideration of these variations only yields already obtained conditions (i.e., and ). According to Eq. (A6), the condition for to be zero is that the coefficients of δx∗ and δu∗ are zero. By summarizing the conditions from Eq. (A6), the equation of state, and the other constraints, the necessary conditions for optimal control inputs can be derived as follows:
The Lorenz 63 system is known to increase the amplitude of x before RSs (e.g., Fig. 2 of MS22 and OTK23). Therefore, it is more difficult to prevent RSs for CSEs starting from a larger x. OTK23 investigated the influence of starting points in the previous CSE approach. Their result showed that the number of successes for preventing the initial RS is almost zero when the CSEs start from x≥15. Here, we investigate CSEs starting from x≥15 with our approach. The experiment setting in this appendix is the same as in Sect. 3.2, except for the starting points.
Table B1 compares the SR, MTF, and MTCIs of 1000 independent CSEs for two starting point settings (i.e., and x≥15). This result shows that the controllability of the case for x≥15 (Table B1 b) is almost equivalent to the case for (Table B1a). This is because the proposed method requires short forecasts with, e.g., 20 steps to lead the system to the positive regime, in contrast to the previous CSE approach (MS22 and OTK23) that requires longer forecasts with, e.g., about 300 steps. This is a promising result, showing improved controllability compared to the previous CSE approach.
Table B1Comparison of the success rate (SR), mean total failure (MTF), and mean total control inputs (MTCIs) for two starting point settings, with Tp=20 steps and m=50 in 1000 CSEs. Row (a) shows the results of the MPC experiment whose starting points are . Row (b) shows the results of the MPC experiment whose starting points are x≥15.
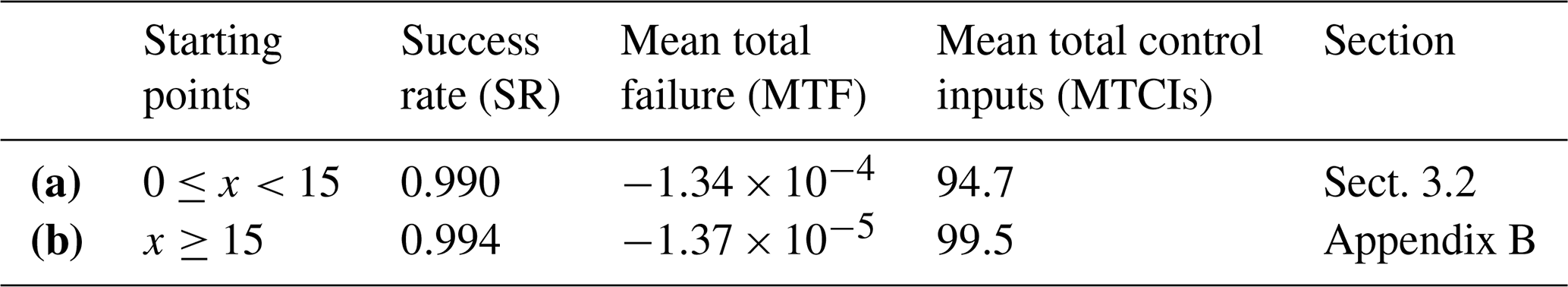
The code that supports the findings of this study is available from the corresponding author upon reasonable request. In addition, all of the data and codes used in this study are stored for 5 years at Chiba University.
The authors declare that all data supporting the findings of this study are available within the figures and tables of the paper.
FK and SK conceptualized this study. FK conducted the numerical experiments and wrote the paper. SK supervised and directed this study.
The contact author has declared that neither of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The authors thank members of the Moonshot R&D program for valuable discussions.
This study was partly supported by the Japan Science and Technology Agency Moonshot R&D program (grant nos. JPMJMS2284 and JPMJMS2389), the Japan Society for the Promotion of Science (JSPS) via KAKENHI (grant no. JP21H04571), and the IAAR Research Support Program of Chiba University.
This paper was edited by Pierre Tandeo and reviewed by two anonymous referees.
Burgers, G., van Leeuwen, P. J., and Evensen, G.: Analysis Scheme in the Ensemble Kalman Filter, Mon. Weather Rev., 126, 1719–1724, https://doi.org/10.1175/1520-0493(1998)126<1719:ASITEK>2.0.CO;2, 1998.
Chen, C. C. and Shaw, L.: On receding horizon feedback control, Automatica, 18, 349–352, https://doi.org/10.1016/0005-1098(82)90096-6, 1982.
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res.-Oceans, 99, 10143–10162, https://doi.org/10.1029/94JC00572, 1994.
Henderson, J. M., Hoffman, R. N., Leidner, S. M., Nehrkorn, T., and Grassotti, C.: A 4D-Var study on the potential of weather control and exigent weather forecasting, Q. J. Roy. Meteor. Soc., 131, 3037–3051, https://doi.org/10.1256/qj.05.72, 2005.
Inoue, D. and Yoshida, H.: Model Predictive Control for Finite Input Systems using the D-Wave Quantum Annealer, Sci. Rep.-UK, 10, 1591, https://doi.org/10.1038/s41598-020-58081-9, 2020.
Kalnay, E., Li, H., Miyoshi, T., Yang, S.-C., and Ballabrera-Poy, J.: 4-D-Var or ensemble Kalman filter?, Tellus A, 59, 758–773, https://doi.org/10.1111/j.1600-0870.2007.00261.x, 2007.
Keerthi, S. S. and Gilbert, E. G.: Optimal infinite-horizon feedback laws for a general class of constrained discrete-time systems: Stability and moving-horizon approximations, J. Optim. Theor. Appl., 57, 265–293, https://doi.org/10.1007/BF00938540, 1988.
Lawson, W. G. and Hansen, J. A.: Implications of Stochastic and Deterministic Filters as Ensemble-Based Data Assimilation Methods in Varying Regimes of Error Growth, Mon. Weather Rev., 132, 1966–1981, https://doi.org/10.1175/1520-0493(2004)132<1966:IOSADF>2.0.CO;2, 2004.
Lorenz, E. N.: Deterministic Nonperiodic Flow, J. Atmos. Sci., 20, 130–141, https://doi.org/10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2, 1963.
Lorenz, E. N.: Predictability – A problem partly solved. Proc, Seminar on Predictability, Seminar on Predictability, Reading, 4–8 September 1995, ECMWF, 1–18, https://www.ecmwf.int/en/elibrary/75462-predictability-problem-partly-solved (last access: 23 January 2024), 1996.
Mayne, D. Q. and Michalska, H.: Receding horizon control of nonlinear systems, IEEE T. Automat. Contr., 35, 814–824, https://doi.org/10.1109/9.57020, 1990.
Mayne, D. Q., Rawlings, J. B., Rao, C. V., and Scokaert, P. O. M.: Constrained model predictive control: Stability and optimality, Automatica, 36, 789–814, https://doi.org/10.1016/S0005-1098(99)00214-9, 2000.
Miyoshi, T. and Sun, Q.: Control simulation experiment with Lorenz's butterfly attractor, Nonlin. Processes Geophys., 29, 133–139, https://doi.org/10.5194/npg-29-133-2022, 2022.
Ohtsuka, T.: A continuation/GMRES method for fast computation of nonlinear receding horizon control, Automatica, 40, 563–574, https://doi.org/10.1016/j.automatica.2003.11.005, 2004.
Ouyang, M., Tokuda, K., and Kotsuki, S.: Reducing manipulations in a control simulation experiment based on instability vectors with the Lorenz-63 model, Nonlin. Processes Geophys., 30, 183–193, https://doi.org/10.5194/npg-30-183-2023, 2023.
Schwenzer, M., Ay, M., Bergs, T., and Abel, D.: Review on model predictive control: an engineering perspective, Int. J. Adv. Manuf. Technol., 117, 1327–1349, https://doi.org/10.1007/s00170-021-07682-3, 2021.
Sun, Q., Miyoshi, T., and Richard, S.: Control simulation experiments of extreme events with the Lorenz-96 model, Nonlin. Processes Geophys., 30, 117–128, https://doi.org/10.5194/npg-30-117-2023, 2023.
Yang, S.-C., Kalnay, E., and Hunt, B.: Handling Nonlinearity in an Ensemble Kalman Filter: Experiments with the Three-Variable Lorenz Model, Mon. Weather Rev., 140, 2628–2646, https://doi.org/10.1175/MWR-D-11-00313.1, 2012.
- Abstract
- Introduction
- Method and experiments
- Results and discussion
- Conclusions
- Appendix A: Derivation of the necessary conditions for the optimal control input
- Appendix B: MPC experiments with starting points around the large x
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Method and experiments
- Results and discussion
- Conclusions
- Appendix A: Derivation of the necessary conditions for the optimal control input
- Appendix B: MPC experiments with starting points around the large x
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References