the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 18 Feb 2022
| 18 Feb 2022
Ensemble Riemannian data assimilation: towards large-scale dynamical systems
Ardeshir Ebtehaj
Peter Jan van Leeuwen
Gilad Lerman
Efi Foufoula-Georgiou
This paper presents the results of the ensemble Riemannian data assimilation for relatively high-dimensional nonlinear dynamical systems, focusing on the chaotic Lorenz-96 model and a two-layer quasi-geostrophic (QG) model of atmospheric circulation. The analysis state in this approach is inferred from a joint distribution that optimally couples the background probability distribution and the likelihood function, enabling formal treatment of systematic biases without any Gaussian assumptions. Despite the risk of the curse of dimensionality in the computation of the coupling distribution, comparisons with the classic implementation of the particle filter and the stochastic ensemble Kalman filter demonstrate that, with the same ensemble size, the presented methodology could improve the predictability of dynamical systems. In particular, under systematic errors, the root mean squared error of the analysis state can be reduced by 20 % (30 %) in the Lorenz-96 (QG) model.
- Article
(3551 KB) - Full-text XML
- BibTeX
- EndNote





The science of data assimilation (DA) aims to optimally estimate the probability distribution of a state variable of interest in an Earth system model (ESM) given the information content of observations and previous time forecasts to improve their predictive abilities (Kalnay, 2003; Carrassi et al., 2018). Current DA methodologies, either variational (Lorenc, 1986; Zupanski, 1993; Courtier et al., 1994; Rabier et al., 2000; Poterjoy and Zhang, 2014) or filtering (Kalman, 1960; Bishop et al., 2001; Anderson, 2001; Tippett et al., 2003; Janjić et al., 2011; Carrassi and Vannitsem, 2011; Anderson and Lei, 2013; Lei et al., 2018), largely rely on penalization of second-order statistics of errors over the Euclidean space without explicitly accounting for systematic model biases. For example, in the three-dimensional variational (3D-Var) DA (Lorenc, 1986; Courtier et al., 1998; Lorenc et al., 2000; Li et al., 2013), a least-squares cost function comprising weighted Euclidean distances of the state from the previous model forecasts (background state) and the observations is formulated. Solution of this cost function leads to an analysis state which is a weighted average of the forecasts and observations across multiple dimensions of the problem with the weights dictated by prescribed background and observation error covariance matrices. The variants of the Kalman filtering DA methods (Evensen, 1994; Reichle et al., 2002; Evensen, 2003; Nerger et al., 2012b; Houtekamer and Zhang, 2016) also follow the same principle, but in these methods, the background covariance contains information from past observations and model evolution.
Apart from the Euclidean distance, other measures and distance metrics, including the quadratic mutual information (Kapur, 1994), Kullback–Leibler (KL) divergence (Kullback and Leibler, 1951), Hellinger distance (Hellinger, 1909), and Wasserstein distance (Villani, 2003) have also been utilized in DA frameworks. Among others, Tagade and Ravela (2014) introduced a nonlinear filter, where the analysis is obtained through maximization of the quadratic mutual information. Maclean et al. (2017) utilized the Hellinger distance to measure the difference between the predicted and observed spatial patterns in oceanic flows. Chianese et al. (2018) introduced a variational DA method in which minimization of the KL divergence led to an approximation of the bias terms and model parameters. Similarly, Li et al. (2019) employed the KL divergence in an optimization framework to incorporate inequality constraints into the ensemble Kalman filter (EnKF, Evensen, 1994). Recently, Pulido and van Leeuwen (2019) developed a mapping particle filter in which particles are pushed towards the posterior density by minimizing the KL divergence between the posterior and a series of intermediate probability densities.
In filtering class of DA methodologies, coupling techniques have been proposed as an alternative to the classic Bayesian inference (El Moselhy and Marzouk, 2012; Spantini et al., 2019). El Moselhy and Marzouk (2012) presented a new approach to find an optimal transport map that pushes forward the background to the posterior distribution. The approach was extended for generalization of the EnKF by deriving nonlinear coupling between the forecast and posterior distributions (Spantini et al., 2019). In recent years, the Wasserstein or Earth mover's distance, originating from the theory of optimal mass transport (OMT, Monge, 1781; Kantorovich, 1942; Villani, 2003; Kolouri et al., 2017; Chen et al., 2017; Y. Chen et al., 2018; B. Chen et al., 2019), has also been gaining attention in the DA community. Reich (2013) introduced a new resampling approach in particle filters, using the OMT, to maximize the correlation between the prior and posterior ensemble members. Ning et al. (2014) further utilized the Wasserstein distance to treat position errors arising from uncertain model parameters. Following on this work, Feyeux et al. (2018) proposed to replace the weighted Euclidean distance with the Wasserstein distance in variational DA frameworks to treat position error. Tamang et al. (2020) proposed to use the Wasserstein distance to regularize a variational DA framework for treating systematic errors arising from the model forecast in chaotic systems.
However, DA frameworks utilizing the Wasserstein distance are computationally expensive as they require a joint distribution to be obtained that couples two marginal distributions. Finding this joint distribution often relies on interior-point optimization methods (Altman and Gondzio, 1999) or Orlin's algorithm (Orlin, 1993) that have super-cubic run time – making the Wasserstein DA computationally challenging even for relatively low-dimensional problems. More recently, to reduce the computational cost, Tamang et al. (2021) used entropic regularization of the OMT formulation (Cuturi, 2013) through a new framework, called ensemble Riemannian data assimilation (EnRDA), to cope with systematic errors and tested it on a three-dimensional Lorenz-63 model (Lorenz, 1963).
Unlike Euclidean DA with a known connection with the family of Gaussian distributions through Bayes' theorem, the EnRDA does not rely on any parametric assumptions about the input probability distributions. Therefore, it does not guarantee an analysis state with a minimum mean squared error. However, it enables us to optimally (i) interpolate between the forecast distribution and the normalized likelihood function without any parametric assumptions about their shapes and (ii) formally penalize systematic translations between them arising due to potential geophysical biases.
However, the computational complexity of finding an optimal joint coupling between two m-dimensional probability distributions supported on d points in each dimension using the entropic regularization is O(d2m). This might impose a significant limitation on the direct use of EnRDA for high-dimensional geophysical problems, where the problem dimension easily exceeds millions. As will be discussed later, the joint distribution in EnRDA is sampled at N2 support points, with N number of ensembles, reducing the computational complexity to O(N2) at the expense of losing accuracy in optimal estimation of the joint distribution. Therefore, beyond implementation in a low-dimensional dynamical system, such as the three-dimensional Lorenz-63, the key questions that we aim to answer are as follows. Does the effectiveness of the EnRDA implementation still remain valid in high-dimensional DA problems where the ensemble size is smaller than the problem dimension? How does EnRDA perform, under systematic errors, in comparison to classic ensemble DA techniques with a comparable ensemble size? To answer the above questions, we implement EnRDA in the relatively high-dimensional chaotic Lorenz-96 system (Lorenz, 1995) and a two-layer quasi-geostrophic (QG) model of atmospheric circulation (Pedlosky, 1987). The results demonstrate that EnRDA can potentially enhance predictability of high-dimensional dynamical systems, when the state variables are not necessarily Gaussian and are corrupted with systematic errors. Nevertheless, extensive future research is necessary to test the applicability of the EnRDA for large-scale Earth system models in which the problem dimension is significantly larger than the examined dynamical systems.
The outline of the paper is as follows. Section 2 provides a brief background on optimal mass transport and Wasserstein distance. A brief review of the EnRDA methodology is presented in Sect. 3. Section 4 presents different test cases of implementation on the Lorenz-96 and QG models and documents the performance of the presented approach in comparison with the classic implementation of the standard particle filter with resampling and the stochastic ensemble Kalman filter (SEnKF). A summary and concluding remarks are presented in Sect. 5. The details of the entropic regularization for the EnRDA and covariance inflation and localization procedures for the SEnKF are provided in Appendix A.
We provide a brief background on the theory of optimal mass transport (OMT) and Wasserstein barycenters. The OMT theory, first put forward by Monge (1781), aims to find the minimum cost of transporting distributed masses of materials from known source points to target points. The theory was later expanded as a new tool to compare probability distributions (Brenier, 1987; Villani, 2003) and since then has found its applications in the field of data assimilation (Ning et al., 2014; Feyeux et al., 2018; Li et al., 2018; Tamang et al., 2020), subsurface geophysical inverse problems (J. Chen et al., 2018; Yang et al., 2018; Yang and Engquist, 2018; Yong et al., 2019) and comparisons of climate model simulations (Vissio et al., 2020).
Let us consider a discrete source probability distribution and a target distribution with their respective probability masses and supported on m- and n-element column vectors xi∈ℝm and yj∈ℝn, respectively. The notation represents probability masses px containing non-negative real numbers supported on M points, whereas δx is the Dirac function at x. In the Monge formulation, the goal is to seek an optimal surjective transportation map that “pushes forward” the source distribution p(x) towards the target distribution p(y), with a minimum transportation cost as follows:
where represents the cost of transporting a unit mass from one support point in x to another one in y.
The problem formulation by Monge as expressed in Eq. (1), however, is non-convex, and the existence of an optimal transportation map is not guaranteed (Y. Chen et al., 2019), especially when the number of support points for the target distribution exceeds that of the source distribution (N>M) (Peyré and Cuturi, 2019). This limitation was overcome by Kantorovich (1942), who introduced a probabilistic formulation of OMT – allowing splitting of probability mass from a single source point to multiple target points. The Kantorovich formalism recasts the OMT problem in a linear programming framework that finds an optimal joint distribution or coupling that couples the marginal source and target distributions with the following optimality criterion:
where tr(⋅) is the trace of a matrix, (⋅)T is the transposition operator and 𝟙M represents an M-element column vector of ones. In the above formulation, the known denotes the so-called transportation cost matrix which is defined based on the ℓ2 norm or the Euclidean distance between the support points of the source and target distributions. Here, the (i,j)th element of optimal joint distribution Ua represents the respective amount of mass transported from support point xi to yj. Then, the 2-Wasserstein distance or metric between the marginal probability distributions is defined as the square root of the optimal transportation cost (Dobrushin, 1970; Villani, 2008). It should be noted that due to the linear equality and non-negativity constraints in Eq. (2), the family of joint distributions that satisfy these constraints forms a bounded convex polytope (Cuturi and Peyré, 2018) and, consequently, the optimal joint distribution Ua is located on one of the extreme points of such a polytope (Peyré and Cuturi, 2019).
Recall that, over the Euclidean space, the barycenter of a group of points is equivalent to their (weighted) mean value. The Wasserstein metric offers a Riemannian generalization of this problem and allows us to define the barycenter of a family of probability distributions (Rabin et al., 2011; Bigot and Klein, 2018; Srivastava et al., 2018). In particular, for a group of K probability mass functions , a Wasserstein barycenter pη is defined as their Fréchet mean (Fréchet, 1948) as follows (Agueh and Carlier, 2011):
where represent the weights associated with the respective distributions. In special cases where the group of K distributions is Gaussian with mean and positive definite covariance , the Wasserstein barycenter is also a Gaussian density 𝒩(μη,Ση) with and Ση is the unique positive definite root of the matrix equation (Agueh and Carlier, 2011).
In this section, to be self content, we provide a brief summary of the EnRDA methodology, while more details can be found in Tamang et al. (2021). Let us assume that the evolution of the ith ensemble member xi∈ℝm of ESM simulations can be presented as the following stochastic dynamical system:
where is the deterministic nonlinear model operator, evolving the model state in time with a stochastic error term . This dynamical system is observed at time t through an observation equation , where maps the state to the observation space and υt∈ℝn represents an additive observation error. Note that the error terms are not necessarily drawn from Gaussian distributions but need to have finite second-order moments.
Hereafter, we drop the time superscript for brevity and represent the model (or background) probability distribution as with its probability mass vector . Furthermore, the normalized likelihood function is represented as centered at the given observation y with its probability mass vector . The probability distribution of the analysis state, p(xa), is then defined as the Wasserstein barycenter between forecast distribution and the normalized likelihood function:
where is a displacement parameter that controls the relative weight of the background and observation. The displacement parameter η is a hyperparameter that captures the relative weights of the histogram of the background state and likelihood function in characterization of the analysis state distribution as a Wasserstein barycenter. The optimal value of η needs to be determined offline using reference data through cross-validation studies. It is important to note that the above formalism requires all dimensions to be observable, and thus those dimensions with no observations cannot be updated, which is a limitation of the current formalism compared to the Euclidean DA. This limitation is further discussed later on in Sect. 5.
To solve the above DA problem, we need to characterize the background distribution and the normalized likelihood function. Similar to the approach used in the particle filter (Gordon et al., 1993; van Leeuwen, 2010), we suggest approximating them through ensemble realizations. To construct the histogram of the normalized likelihood function, we can draw N samples at each assimilation cycle by perturbing the available observation y with the observation error 𝒩(0,R).
To obtain the Wasserstein barycenter p(xa) in Eq. (5), we use the McCann formalism (McCann, 1997; Peyré and Cuturi, 2019):
where represent the support points of the analysis distribution and are the elements of the joint distribution . It is important to note that the analysis state histogram, at each assimilation cycle, is supported on at most points, which is the maximum number of non-zero entries in the optimal joint coupling (Peyré and Cuturi, 2019). To keep the number of ensemble members constant throughout, M ensemble members are resampled from p(xa) using the multinomial resampling scheme (Li et al., 2015).
Computation of the joint distribution in Eq. (2) is computationally expensive as explained previously and can be prohibitive for high-dimensional geophysical problems. As suggested by Cuturi (2013), to reduce the computational cost, we regularize the cost function in the optimal transportation plan formulation of EnRDA by a Gibbs–Boltzmann entropy function:
where is a regularization parameter. The entropic regularization transforms the original OMT formulation to a strictly convex problem, which can then be efficiently solved using Sinkhorn's algorithm (Sinkhorn, 1967). The details of Sinkhorn's algorithm for solving regularized optimal transportation problems are presented in Appendix A1. The regularization parameter γ balances the solution between the optimal joint distribution and the one that maximizes the relative entropy. It is evident from Eq. (7) that at the limit γ→0, the solution of Eq. (7) converges to the analysis joint distribution with a minimum morphing cost. However, as the value of γ increases, the convexity of the problem also increases, enabling the deployment of more efficient optimization algorithms than classic solvers of linear programming problems (Dantzig et al., 1955; Orlin, 1993). At the same time, the number of non-zero entries of the joint coupling increases from to MN points as γ→∞, which results in a maximum entropy solution that converges to . For a more comprehensive explanation of EnRDA, one can refer to Tamang et al. (2021). It should be noted that EnRDA formulation allows the number of ensemble members to be different from the number of perturbed observations, i.e., M≠N. The values of M and N need to be chosen to adjust the trade-off between accuracy and computational cost.
As an example, we examine here the solution of Eq. (5) between a banana-shaped distribution denoted by and a bivariate Gaussian distribution as a function of the displacement parameter – resembling the background distribution p(x) and the normalized likelihood function , respectively, with regularization parameter γ=1000. As seen from Fig. 1, for lower values of η, the analysis state distribution is closer to the observation, and its shape resembles the Gaussian distribution. However, as the value of η increases, the analysis state distribution moves closer to the background distribution and starts morphing into a banana-shaped distribution. Therefore, the analysis state distribution is defined as the one that is sufficiently close to the background distribution and the normalized likelihood function not only based on their shape, but also their central location – depending on the displacement parameter. Thus, unlike the Euclidean barycenter, this approach does not guarantee that the mean or mode of the analysis state probability distribution is a minimum mean-squared error estimate of the initial condition.
It is important to note that in the original OMT formulation, the number of support points required for the optimal joint coupling U scales with the problem dimension (dm), making it potentially restrictive for the high-dimensional problems, where d represents the number of support points in each dimension and m is the number of dimensions. The presented EnRDA setting bypasses this problem by sampling the joint distribution using only N ensemble members. However, such approximation might lead to errors in optimal estimation of the joint coupling that are translated into the analysis state. In the next section, we present results from systems of well-known dynamics to investigate whether EnRDA can lead to a proper approximation of the analysis state under systematic errors in relatively high-dimensional nonlinear problems when compared to classic ensemble DA approaches with comparable ensemble size.
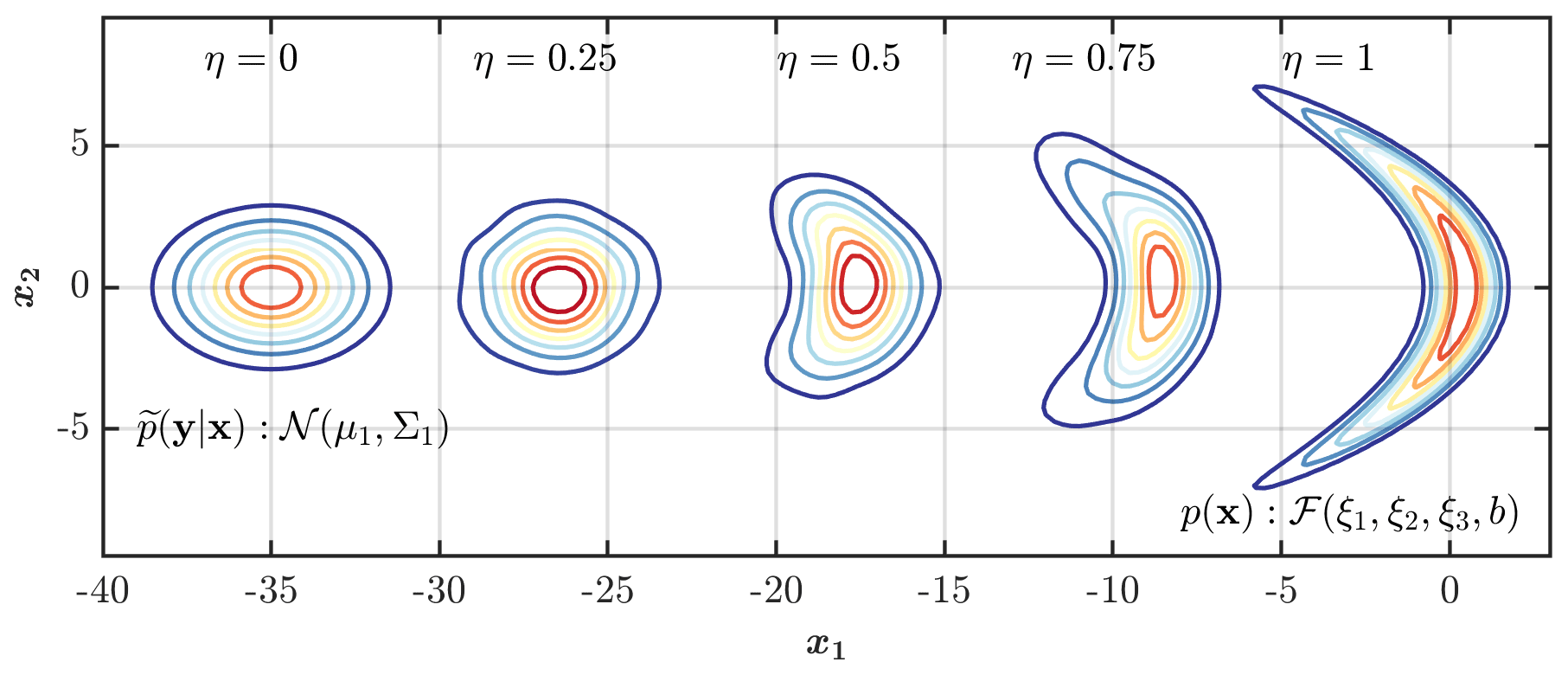
Figure 1The analysis distribution obtained as a Wasserstein barycenter for different values of the displacement parameter between a background distribution represented by a banana-shaped distribution with ξ1=0.02, ξ2=0.06, ξ3=1.6, and b=8 and the normalized likelihood function represented by a bivariate Gaussian , where and .
4.1 Lorenz-96
The Lorenz model (Lorenz-96, Lorenz, 1995), which is widely adopted as a test bed for numerous DA experiments (Trevisan and Palatella, 2011; Tang et al., 2014; Shen and Tang, 2015; Lguensat et al., 2017; Tian et al., 2018), offers a simplified representation of the extra-tropical dynamics in the Earth's atmosphere. The model coordinates at K dimensions represent the state of an arbitrary atmospheric quantity measured along the Earth's latitudes at K equally spaced longitudinal slices. The model is designed to mimic the continuous-time variation in atmospheric quantities due to interactions between three major components, namely, advection, internal dissipation, and external forcing. The model dynamics is represented as follows:
where is a constant external forcing independent of the model state. The Lorenz-96 model has cyclic boundaries with , x0=xK, and . It is known that for small values of , the system approaches a steady-state condition with each coordinate value converging to the external forcing xk→F, ∀k, whereas for , chaos develops (Lorenz and Emanuel, 1998). For a standard model setup with F=8, the system is known to exhibit highly chaotic behavior with the largest Lyapunov exponent of 1.67 (Brajard et al., 2020).
Experimental setup, results, and discussion
We focus on the 40-dimensional Lorenz-96 system (i.e., K=40) and compare EnRDA results with the classic implementation of the PF (Gordon et al., 1993; Van Leeuwen, 2009; van Leeuwen, 2010; Poterjoy and Anderson, 2016) and the SEnKF (Evensen, 1994; Houtekamer and Mitchell, 1998; Burgers et al., 1998; Janjić et al., 2011; Anderson, 2016; Van Leeuwen, 2020). Similarly to the experimental setting suggested in Lorenz and Emanuel (1998) and Nerger et al. (2012a), we initialize the model by choosing x20=8.008 and xk=8 for all other model coordinates. In order to avoid any initial transient effect, the model in Eq. (8) is integrated for 1000 time steps using the fourth-order Runge–Kutta approximation (Runge, 1895; Kutta, 1901) with a non-dimensional time step of Δt=0.01, and the endpoint of the run is utilized as the initial condition for DA experimentation.
Similar to the suggested experimental setting in van Leeuwen (2010), we obtain the ground truth by integrating Eq. (8) with a time step of Δt over a time period of T= 0–20 in the absence of any model error. The observations are assumed to be available at each assimilation time interval of 10Δt and deviated from the ground truth by a Gaussian error , with and the correlation matrix with 1 on the diagonals, 0.5 on the first sub- and super-diagonals, and 0 everywhere else. The observation time step of 10Δt is equivalent to 12 h in global ESMs (Lorenz, 1995).
To characterize the distribution of the background state for each DA methodology, 50 (5000) ensemble members (particles) for the SEnKF and EnRDA (PF) are generated using model errors with for t>0 and , where throughout Im represents an m×m identity matrix. To alleviate the known degeneracy problem in the PF, a higher number of particles was used. Furthermore, to introduce additional systematic background error, we utilize an erroneous external forcing of Fm=6 instead of the “true” forcing value F=8. To have a robust inference, the average values of the error metrics are reported for 50 experiments using different random realizations. As will be elaborated later on, we set the EnRDA displacement parameter η=0.44, determined through a cross-validation study based on a minimum mean-squared error criterion. This tuning is similar to tuning inflation and localization parameters in a typical EnKF or tuning length scales in 3D- or 4D-Var. Note that we already introduced some systematic error because the truth has zero model error, while the prior does have model errors. In a fully unbiased setup the truth and the prior are drawn from the same distribution.
The results of EnRDA are shown in Fig. 2. In Fig. 2a, the temporal evolution of the ground truth and EnRDA analysis state is shown over all dimensions of Lorenz-96, while a snapshot at time 10 (t) is presented in Fig. 2b. The analysis state obtained from EnRDA follows the ground truth reasonably well during all time steps, with a root mean squared error (RMSE) of 0.85. The comparison of EnRDA with the classic implementations of the SEnKF and PF are shown in Fig. 3. It can be seen that the RMSE of the PF increases sharply over time, suggesting that the problem of filter degeneracy still exists despite the higher number of particles. This problem is exacerbated due to the presence of bias causing a rapid collapse of the ensemble variance over time as more particles fall outside of the support set of the likelihood function. The root mean squared error of both the SEnKF and EnRDA is stabilized over time and is smaller by ∼20 % (80 %) in EnRDA compared to the SEnKF (PF). It is important to note that the presence of systematic bias due to erroneous choice of the external forcing inherently favors EnRDA over SEnKF since the latter is a minimum variance unbiased estimator at the limit M→∞, where M represents the number of ensemble members.
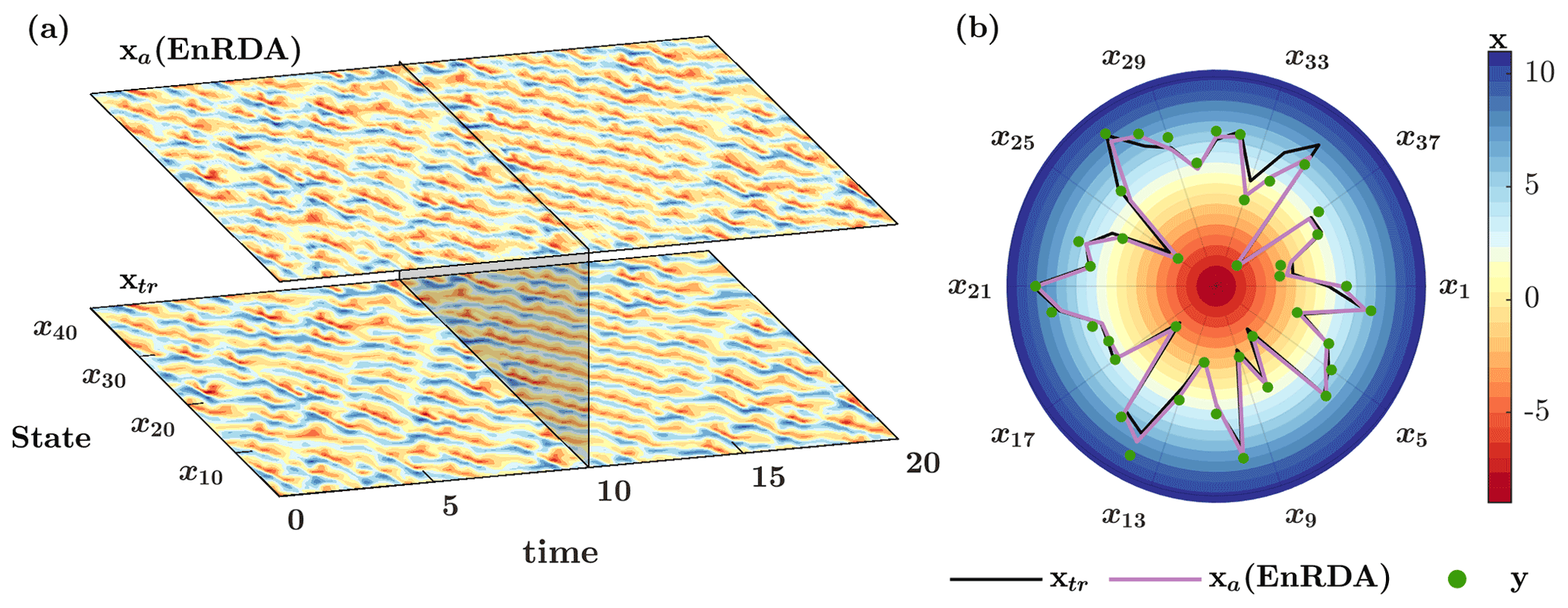
Figure 2(a) Temporal evolution of the ground truth xtr and analysis state xa by ensemble Riemannian data assimilation (EnRDA) for K=40 dimensions of Lorenz-96 over T=0–20 (t) and (b) their snapshots at T=10 (t) together with the available observations y.
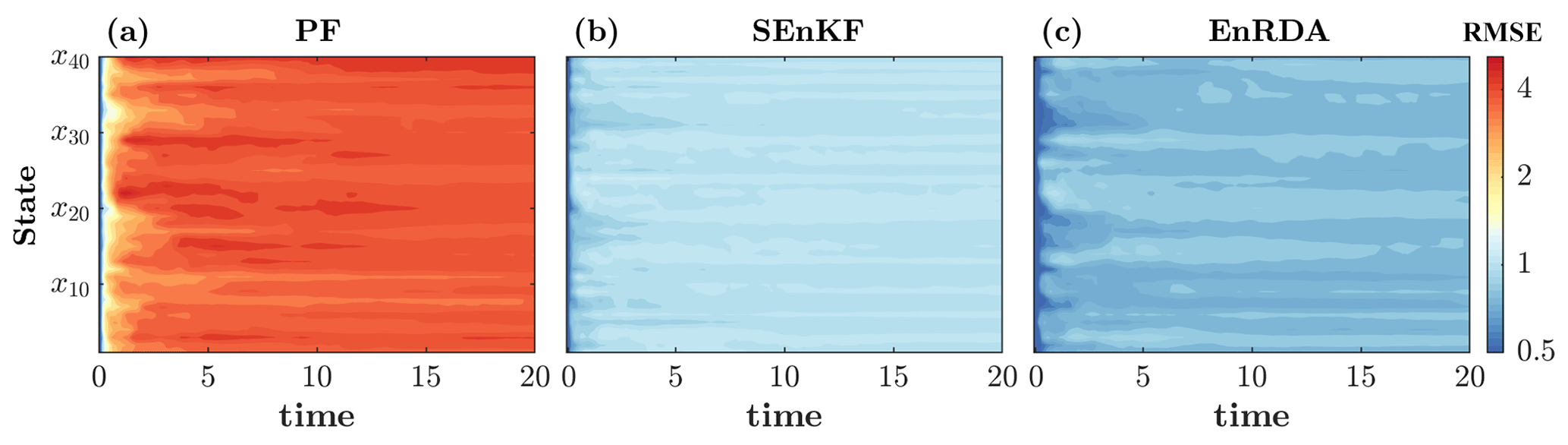
Figure 3Temporal evolution of the root mean squared error (RMSE) for the (a) particle filter (PF) with 5000 particles, (b) stochastic ensemble Kalman filter (SEnKF), and (c) EnRDA, each with 50 ensemble members in a 40-dimensional Lorenz-96 system. The results report the mean values of 50 independent simulations.
As previously noted, the displacement parameter η plays an important role in EnRDA as it controls the shape and position of the analysis state distribution relative to the background distribution and the normalized likelihood function. Currently, there exists no known closed-form solution for optimal approximation of this parameter. Therefore, in this paper, we focus on determining its optimal value through heuristic cross-validation by an offline bias-variance trade-off analysis. Specifically, we quantify the RMSE of the EnRDA analysis state for different values of η for 50 independent simulations.
The bias and RMSE, together with their respective 5th–95th percentile bounds, as functions of the displacement parameter η are shown in Fig. 4a. As explained earlier, when η increases, the analysis distribution moves towards the background distribution. Since the background state is systematically biased due to the erroneous external forcing, the analysis bias increases monotonically with η, while the RMSE shows a minimum point. Therefore, there exists a form of bias-variance trade-off in the analysis error which leads to an approximation of an optimal value of η based on a minimum RMSE criterion. It is important to note that the background uncertainty and thus the optimal value of η vary in response to the ensemble size as shown in Fig. 4b. The reason is that a larger number of ensemble members reduces the uncertainty in the characterization of the background, but the bias is not affected. To compensate, a larger optimal value for η is needed. This optimal value approaches an asymptotic value as the ensemble sample size increases and will achieve the highest value at the limit M→∞, when the sample moments converge to the biased forecast moments.
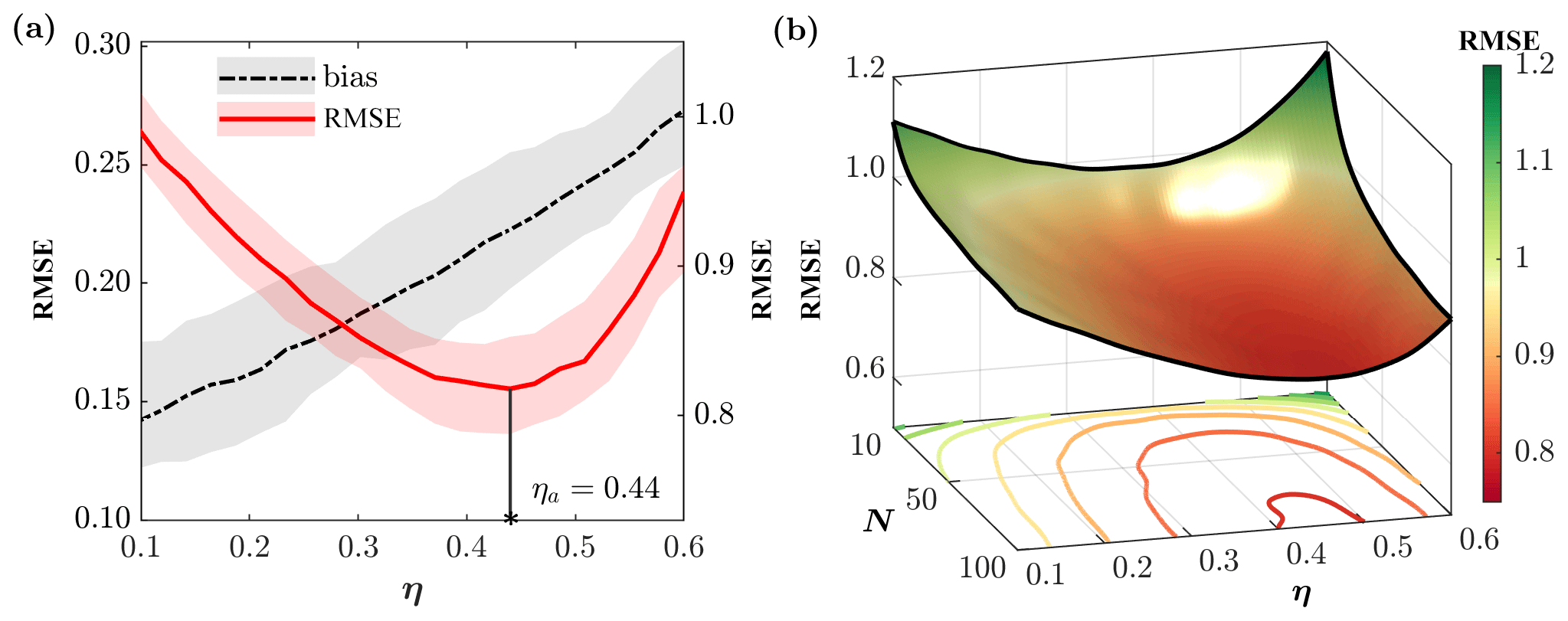
Figure 4(a) Bias and RMSE for a range of displacement parameter in EnRDA with 50 ensemble members, obtained across 40 dimensions of the Lorenz-96 system. The shaded regions indicate the 5th–95th percentile bound for the respective error metrics obtained from 50 independent simulations. (b) Variation of RMSE as a function of the number of ensemble members and η.
One may argue that such a tuning favors EnRDA since it explicitly accounts for the effects of bias, either in background or observations, while there is no bias-correction mechanism in the implementation of the SEnKF and the PF. To make a fairer comparison, we investigate an alternative approach to approximate the displacement parameter solely based on the known error covariance matrices at each assimilation cycle. Recall that in classic DA, the analysis state is essentially the Euclidean barycenter, where the relative weights of the background state and observations are optimally characterized based on the error covariances under zero bias assumptions. However, over the Wasserstein space, the displacement parameter determines the weight between the entire distribution of the background and the normalized likelihood function. Theoretically, knowing the Wasserstein distances from ground truth to both likelihood function and forecast probability distribution enables us to obtain an optimal value for η. Even though such distances are not known in reality, the total Wasserstein distance between the normalized likelihood function and the forecast distribution is known at each assimilation cycle. Therefore, an estimate of the distance between the ground truth and the normalized likelihood function or the forecast distribution leads to an approximation of η.
It is known that the square of the Wasserstein distance between two equal-mean Gaussian distributions 𝒩(μ,Σ1) and 𝒩(μ,Σ2) is (Y. Chen et al., 2019). Therefore, under the assumption that only the background state is biased, the square of the Wasserstein distance between the true state xtr, as a Dirac delta function, and the normalized likelihood function reduces to tr(R). At the same time, the square of the Wasserstein distance between the normalized likelihood function and forecast distribution is tr(CTUa). Therefore, we can approximate the interpolation parameter as without any explicit a priori knowledge of bias.
Comparisons of the RMSE values for the studied DA methodologies as a function of ensemble size are shown in Fig. 5. For EnRDA, the displacement parameter is obtained from the bias-aware cross-validation (η=0.44, EnRDA-I) and from the known error covariances as explained above (EnRDA-II). The SEnKF and EnRDA result in smaller error metrics with a much smaller ensemble size than the PF. As seen, EnRDA can perform well even for smaller ensemble sizes as low as 20. Its results quickly stabilize with more than 40 ensemble members and exhibit a marginal improvement over the SEnKF (12 %–24 %) in the presence of bias. The RMSE of the SEnKF also stabilizes quickly but remains above the standard deviation of the observation error, indicating that in the presence of bias, the lowest possible variance, known as the Cramer–Rao lower bound (Cramér, 1999; Rao et al., 1973), cannot be met.
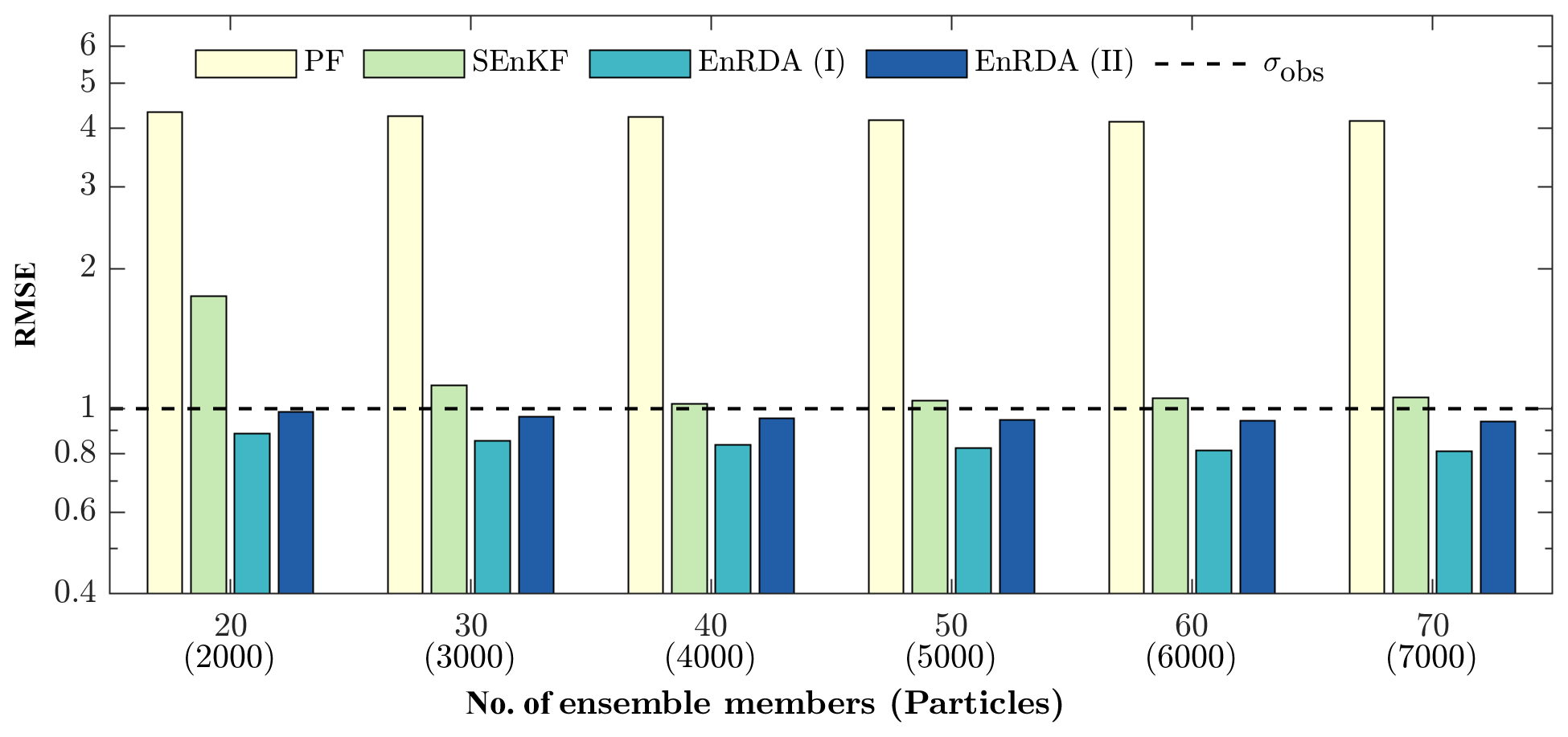
Figure 5The RMSE for the different number of ensemble members/particles in the PF, SEnKF, and EnRDA when the displacement parameter is obtained from bias-aware cross-validation (ENRDA-I) and a dynamic approach without a priori knowledge of bias (EnRDA-II) for the Lorenz-96 system. The dashed line is the standard deviation of the observation error.
It is also important to note that the higher RMSE of the PF compared to the SEnKF and EnRDA is due to the problem of filter degeneracy, which is further exacerbated by the presence of systematic errors in model forecasts (Poterjoy and Anderson, 2016). To alleviate this problem, one may investigate the use of methodologies suggested in recent years, including the auxiliary particle filter where the weights of the particles at each assimilation cycle are defined based on the likelihood function from the next cycle using a pre-model run (Pitt and Shephard, 1999), the backtracking particle filter in which the analysis state is backtracked to identify the time step when the filter became degenerate (Spiller et al., 2008) as well as sampling from a transition density to pull back particles towards observations (van Leeuwen, 2010).
To further test the efficiency of EnRDA, another configuration of the Lorenz-96 is implemented using a Laplace-distributed observation error at each assimilation interval of 10Δt with variance (Lei and Bickel, 2011; Spantini et al., 2019). Similar to the setting of earlier implementations using Gaussian observation error, 50 (5000) ensemble members (particles) for the SEnKF and EnRDA (PF) are generated. On average, the EnRDA reduces the RMSE by 26 % (47 %) compared to the SEnKF (PF) using 50 random realizations.
4.2 Quasi-geostrophic model
The multilayered QG (Pedlosky, 1987) model is known as one of the simplest circulation models capable of providing a reasonable representation of the mesoscale variability in geophysical flows. In its simplified form, the QG model describes the conservation of potential vorticity in K vertically mixed vertical layers:
where and represent the zonal and meridional components of the velocity field, obtained from the geostrophic approximation, is the streamfunction in K layers, and λ and ϕ are the zonal and meridional coordinates, respectively.
For a two-layer QG model (K=2), the potential vorticity at any time step is the sum of the relative vorticity, the planetary vorticity and the stretching term, given by
where is the Laplace operator, is the Coriolis parameter linearly varying with the meridional coordinate ϕ (β-plane approximation), f0 is the Coriolis parameter at mid-basin where ϕ=ϕ0, is the reduced value of the gravitational acceleration g, and ρk and hk are the density and thickness of the kth layer, respectively. The QG model has been the subject of numerous experiments to test the performance of DA techniques (Evensen, 1994; Evensen and Van Leeuwen, 1996; Fisher and Gürol, 2017; Penny et al., 2019; Cotter et al., 2020).
Experimental setup, results and discussion
Due to the high dimensionality of the QG model and the well-known problem of filter degeneracy in the PF, we chose to omit its application to the QG model. Similarly to the study conducted in Evensen (1992, 1994), the streamfunction is chosen as the state variable for the DA experiments. The streamfunction field, at each vertical layer, is discretized over a uniform grid of dimension mλ×mϕ with a spacing of km, where mλ=65 and mϕ=33. The model domain is assumed to have periodic boundaries along the zonal direction and free-slip conditions, that is, holds on the northern and southern boundaries. The standard model parameter values of s−1, m−1 s−1, and g=9.81 m s−2 are used. The total depth of the atmospheric column is set to 10 km with depths and densities of the top and bottom layers as km and ρ1=1 and ρ2=1.05 kg m−3, respectively. We first initialize the streamfunction in the two layers as a function of the zonal and meridional coordinates by setting m2 s−1 and .
From the initial value of the streamfunction field in each layer, potential vorticity is obtained using a nine-point second-order finite difference scheme to compute the Laplacian in Eq. (10). The model in Eq. (9) is then integrated with a time step of Δt=0.5 h using the fourth-order Runge–Kutta approximation to advect and obtain potential vorticity at internal grid points for the next time step. The streamfunction at the next time step is then calculated from this potential vorticity by solving the set of Helmholtz equations (Eq. 10). To avoid any form of initial transient behavior and to create vortex structures in the streamfunction, the QG model is integrated first for 720 time steps, and then the endpoint of the run is used as the initial condition for subsequent DA experimentation.
The ground truth of the streamfunction is obtained by integrating the QG model with a time step of Δt over a time period of T= 0–15 d in the absence of any model error. Observations are assumed to be available at an assimilation time interval of 24Δt or 12 h. To construct observations, representative, random and systematic errors are applied to the ground truth. The representative error is applied by lowering the resolution of the ground truth through box averaging over a window of size nλ×nϕ, where nλ=5 and nϕ=3. Then a heteroscedastic Gaussian observation noise with bias 0.6×106 m2 s−1 and a standard deviation of 10 % of the mean magnitude of the ground truth is applied.
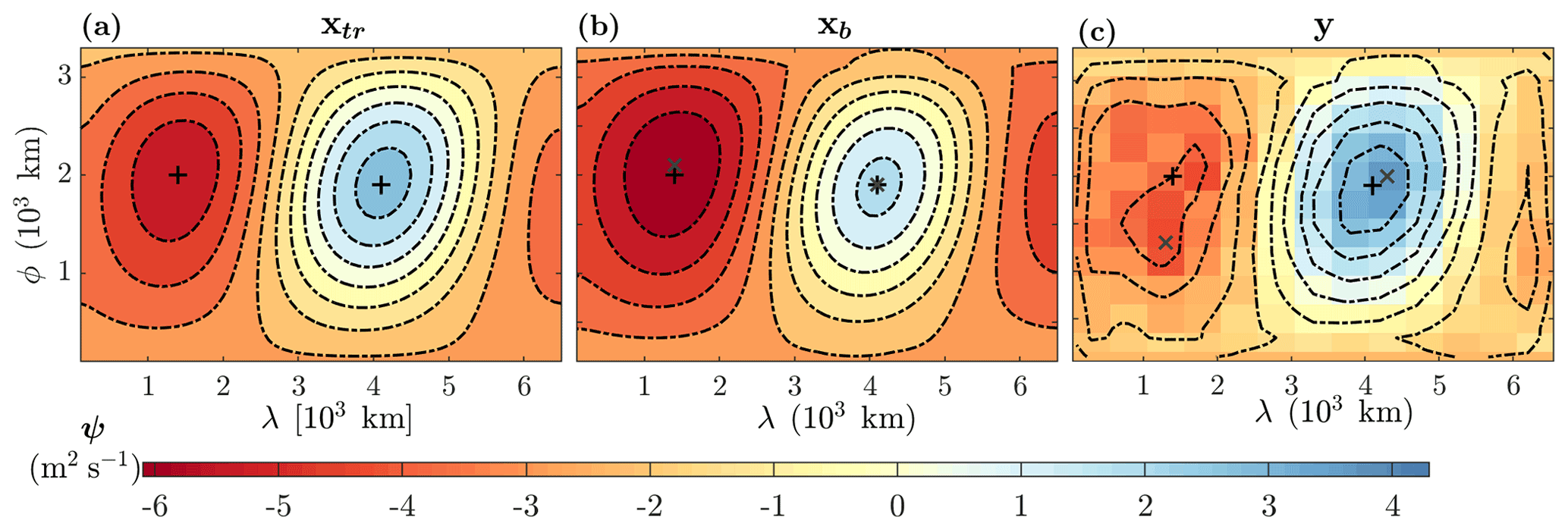
Figure 6(a) The true state xtr, (b) background state xb, and (c) observations y for the bottom layer field of the streamfunction in the quasi-geostrophic model at the first assimilation cycle T=12 h. The black plus (grey cross) signs show the location of the global extrema for the true state (background and observation).
To characterize the distribution of the background state, 50 ensemble members for both SEnKF and EnRDA are generated using model errors for each layer with m4 s−2 and m4 s−2 for t>0, where the factor grows linearly from 0 at the northern and southern boundaries to 1 at mid-basin. To introduce systematic errors in the forecast, we utilize a multiplicative error of 0.015 % in the QG model by multiplying the potential vorticity obtained from Eq. (10) at every Δt by a factor of 1.00015. At each assimilation cycle, N=500 samples of the observations are obtained by perturbing the observations with the heteroscedastic Gaussian observation noise with standard deviation 10 % of the mean magnitude of the ground truth.
In the SEnKF, to alleviate the well-known problem of undersampling (Anderson, 2012) and improve its performance, we utilize covariance inflation (Anderson and Anderson, 1999) and localization (Houtekamer and Mitchell, 2001; Hamill, 2001) as discussed in Appendix A2. For EnRDA, similar to the Lorenz-96 setup (Sect. 4.1), the displacement parameter is set to η=0.4 through a cross-validation study based on a minimum RMSE criterion as shown in Table 1. To increase the robustness of the inference about the results, the quality metrics are averaged using 10 simulations with different random realizations.

Figure 7The streamfunction analysis state xa by (a) SEnKF and (d) EnRDA as well as (b, e) their respective absolute error fields and (c, f) zonal mean of the error for the bottom layer of the quasi-geostrophic model at the first assimilation cycle T=12 h. The RMSE values (×106 m2 s−1) for the entire fields are also reported in (a) and (d).
The true state, background state, and observations of the bottom layer streamfunction at the first assimilation cycle T=12 h are shown in Fig. 6. It can be seen that both the background state and the observations show possible systematic biases as the position and the values of their global extrema are significantly different from the ground truth.
The results of the DA experiments using the SEnKF and EnRDA at the first assimilation cycle for the bottom layer are also shown in Fig. 7. It can be seen that, in the SEnKF, the streamfunction values are slightly overestimated, signaling the persistence of bias in the analysis state (Fig. 7a). This is further evident as the analysis error field is coherent and structured (Fig. 7b). On the other hand, it appears that EnRDA (Fig. 7d) results in a more incoherent error field with a reduced bias (Fig. 7e). The RMSE for the EnRDA (0.28×106 m2 s−1) is lower than the one by the SEnKF (0.46×106 m2 s−1). However, the difference between the two methods shrinks over T= 0–15 d, and the mean analysis RMSE over both layers by the EnRDA (SEnKF) reaches 0.21×106 (0.25×106) m2 s−1. Furthermore, in the SEnKF, due to the presence of systematic error, the zonal mean of the absolute error is consistently higher than that of the EnRDA (see Fig. 7c and f). To test the effects of non-Gaussian errors on the performance of EnRDA, analogous to the experiments conducted for Lorenz-96, we examined a Laplace noise with the same variance used for the Gaussian errors. The results show that EnRDA performance does not change appreciably and that the improvement remains on the same order of magnitude as reported for the Gaussian observation errors.
Table 1Average root mean squared error (RMSE) values as a function of the displacement parameter for ensemble Riemannian data assimilation (EnRDA) from 10 independent simulations of the two-layer quasi-geostrophic model.
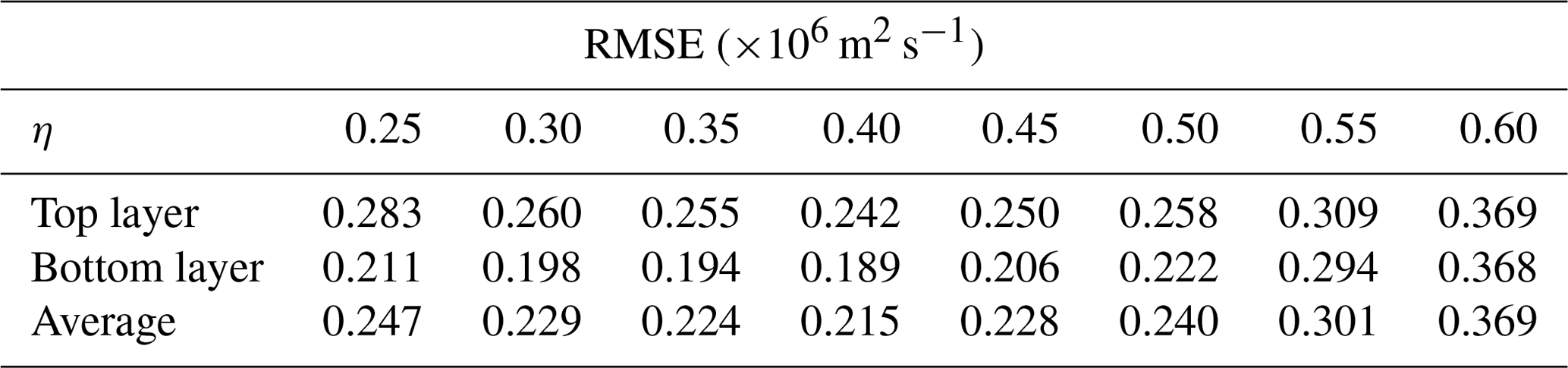
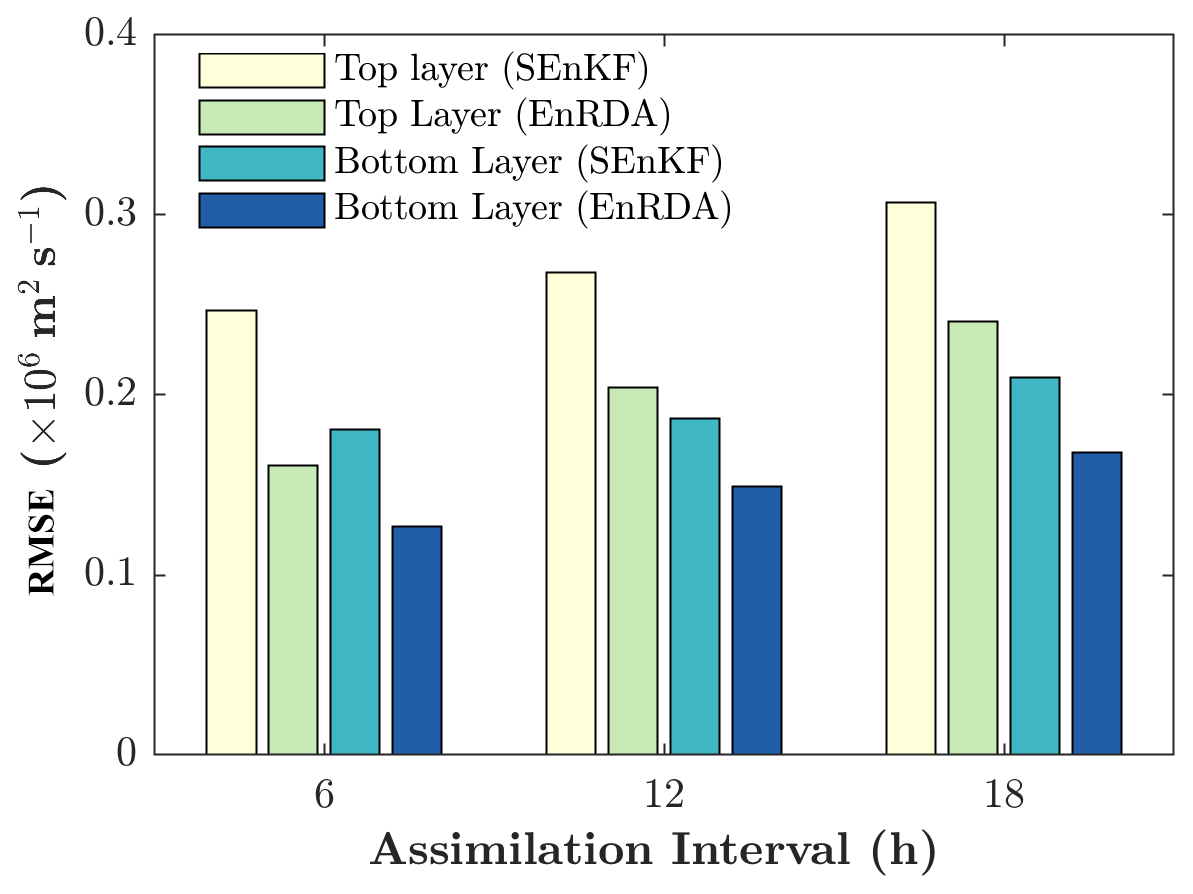
Figure 8The average RMSE values as a function of assimilation intervals 6, 12 and 18 h in the SEnKF and EnRDA for the two-layer quasi-geostrophic model.
We further examined the performance of the EnRDA and the SEnKF on the QG model with a ±50 % change in the assimilation interval of 12 h as shown in Fig. 8. To make the comparison fair between different assimilation intervals which have a different number of assimilation cycles and to eliminate the impact of transient behavior, we only report the statistics for the last 15 assimilation steps. With the increase in assimilation interval, the systematic error grows in the forecast largely due to the multiplicative error being added to the forecast at every time step. Therefore, as is expected, with the increase in assimilation interval, the RMSE grows monotonically and the performance of the DA methodologies degrades. However, the EnRDA demonstrates consistent improvement over a bias-blind implementation of the SEnKF (20 %–33 %) across the range of assimilation intervals. On average, using a cluster with 24 cores and a clock rate of 2.5 GHz, it took around 3.5 h to complete one independent simulation on the QG model for EnRDA compared to 2.5 h for EnKF, each with 50 ensemble members.
In this study, we demonstrated that data assimilation (DA) over the Wasserstein space through the EnRDA (Tamang et al., 2021) can be properly scaled and result in improved predictability of non-Gaussian geophysical dynamics at relatively high dimensions, under systematic errors. In particular, we applied the EnRDA to the 40-dimensional chaotic Lorenz-96 system and a two-layer quasi-geostrophic representation of atmospheric circulation and compared its results with the stochastic ensemble Kalman filter and the particle filter with comparable ensemble size. Under the made assumptions and experimental settings, EnRDA improved the root mean squared error by almost 20 % (30 %) for the Lorenz-96 (QG) model when compared to the classic Euclidean DA techniques. We need to emphasize that in the absence of systematic errors, Euclidean DA methodologies definitely demonstrate improved performance over EnRDA in terms of the root mean squared error. Despite the reported improvements, further comprehensive comparisons with the Euclidean DA methodologies equipped with bias-correction methodologies, such as the cumulative distribution function (CDF) matching (Reichle et al., 2004), are required to fully characterize the pros and cons of DA over the Wasserstein space.
One of the major weaknesses of the presented methodology in its current form is that all dimensions of the problem are assumed to be observable. This is an important issue when it comes to the assimilation of sparse data. Future research is needed to address partial observability in DA over the Wasserstein space. A possible direction is through multi-marginal optimal mass transport (Pass, 2015), which could enable us to couple different dimensions of the problem and propagate the information content of sparse observations to unobserved dimensions. Moreover, currently, the displacement parameter is constant across multiple dimensions of the problem. Future research is needed to understand how the displacement parameter can be estimated differently depending on the error structure across different dimensions of the state space. Another option is to perform the EnRDA only in that part of the state space that is directly observed and use the ensemble covariance to update the unobserved part of state space, similar to a SEnKF. We anticipate that expanding the application of the presented methodology for assimilating satellite data into land–atmosphere models could be another promising future direction of research given the fact that these models are often markedly biased (Dee and Da Silva, 1998; Chepurin et al., 2005; De Lannoy et al., 2007; Lin et al., 2017).
It should be noted that the experimental settings presented here only deal with the univariate state variable. The use of a scalar regularization parameter in the EnRDA penalizes the transportation cost matrix elements uniformly even when the physical variables of interest are different by orders of magnitude. A possible future solution to this problem can be obtained by rather utilizing Mahalanobis or a weighted Euclidean distance (Olver et al., 2006) in lieu of the Euclidean distance to obtain a modified ground transportation cost matrix.
Although EnRDA demonstrated a reasonable performance on the presented dynamical systems without significant computational burden, the computational complexity might be a limiting factor for its large-scale implementation. In Earth system models, where the dimension easily exceeds hundred of millions, dimensionality reduction might be necessary. One might hypothesize that the optimal transportation plan remains unaltered for the change in the basis. Thus, future research can be devoted to examining the optimal transportation plan for the principal components (Olver et al., 2006) of the geophysical state variables of interest to significantly lower its computational cost.
A1 Sinkhorn's algorithm for optimal mass transport
To solve the regularized optimal mass transport problem in Eq. (7), we utilize Sinkhorn's algorithm (Sinkhorn, 1967). To that end, first, the Lagrangian form of Eq. (7) using two Lagrange multipliers a∈ℝM and b∈ℝN is obtained as follows:
Now, we set the first-order derivative of the Lagrangian form in Eq. (A1) with respect to the (i,j)th element of the joint distribution (uij) to zero:
which ultimately leads to . This can be rewritten in matrix form as Ua=diag(s)Vdiag(t), where is Gibb's kernel of the cost matrix C and s∈ℝM and t∈ℝN are the unknown scaling vectors. The notation represents a diagonal matrix with its diagonal entries provided by x∈ℝM.
By setting the derivatives of the Lagrangian with respect to the Lagrange multipliers to zero, we recover the two conditions, which we can write as px=diag(s)Vdiag(t)𝟙N and , leading to
where the notation x⊘y represents a Hadamard element-wise division of equal-length vectors. The form presented in Eq. (A3) is known as the matrix scaling problem (Borobia and Cantó, 1998) and can be efficiently solved iteratively:
where i is the iteration count and the algorithm is initialized with a positive vector t(0)=𝟙N. In our implementation, we set the iteration termination criterion as or i>300. After the convergence of the solution for s and t, the optimal joint distribution can be obtained as Ua=diag(s)Vdiag(t).
A2 Covariance inflation and localization in the ensemble Kalman filter
The ensemble size in the SEnKF, if much smaller than the state dimension, such as in the presented case of the quasi-geostrophic model, leads to underestimation of the forecast error covariance matrix and subsequently filter divergence problems. To alleviate this problem, a covariance inflation procedure can be implemented by multiplying the forecast error covariance matrix by an inflation factor τ>1 (Anderson and Anderson, 1999) where its optimal value depends on the ensemble size (Hamill et al., 2001) and other characteristics of the problem at hand.
The covariance localization procedure in the SEnKF further attempts to improve its performance by ignoring the spurious long-range dependence in the ensemble background covariance by applying a prespecified cutoff threshold to the correlation structure of the field. An SEnKF equipped with a tuned localization procedure can be efficiently used in high-dimensional atmospheric and ocean models even with fewer than 100 ensemble members (Anderson, 2012). The covariance localization in an SEnKF is accomplished by modifying the Kalman gain matrix through implementation of a Hadamard element-wise product of the forecast error covariance matrix with a distance-based correlation matrix :
where X⊙Y represent the Hadamard element-wise product between equal size matrices X and Y.
Following the work of Gaspari and Cohn (1999), we utilized the fifth-order piece-wise rational function that depends on a single length scale parameter d and a Euclidean distance matrix for obtaining the (i,j)th element of the localizing correlation matrix ρ:
where , and d is the length scale.
In our implementation of the SEnKF in the QG model, the inflation factor and length scale were chosen between τ= 1.01–1.08 and d= 400–1800 (km), respectively, depending on the experimental setup through trial and error analysis to minimize the root mean squared error.
A demo code for EnRDA in the MATLAB programming language can be downloaded at https://github.com/tamangsk/EnRDA (last access: 15 January 2022; https://doi.org/10.5281/zenodo.5047392; tamangsk, 2021).
No data sets were used in this article.
SKT and AE designed the study. SKT implemented the formulation and analyzed the results. PJvL, GL and EFG provided conceptual advice, and all the authors contributed to the writing.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors thank the Minnesota Supercomputing Institute (MSI) at the University of Minnesota for providing resources that contributed to the research results reported within this paper.
This research has been supported by the National Aeronautics and Space Administration Remote Sensing Theory program (RST, grant no. 80NSSC20K1717), the Interdisciplinary Research in Earth Science program (IDS, grant no. 80NSSC20K1294), the New (Early Career) Investigator Program (NIP, grant no. 80NSSC18K0742), the European Research Council, H2020 European Research Council (CUNDA (grant no. 694509)), and the National Science Foundation (grant nos. DMS1830418 and ECCS-1839441).
This paper was edited by Alberto Carrassi and reviewed by two anonymous referees.
Agueh, M. and Carlier, G.: Barycenters in the Wasserstein space, SIAM J. Math. Anal., 43, 904–924, 2011. a, b
Altman, A. and Gondzio, J.: Regularized symmetric indefinite systems in interior point methods for linear and quadratic optimization, Optim. Method. Softw., 11, 275–302, 1999. a
Anderson, J. and Lei, L.: Empirical localization of observation impact in ensemble Kalman filters, Mon. Weather Rev., 141, 4140–4153, 2013. a
Anderson, J. L.: An ensemble adjustment Kalman filter for data assimilation, Mon. Weather Rev., 129, 2884–2903, 2001. a
Anderson, J. L.: Localization and sampling error correction in ensemble Kalman filter data assimilation, Mon. Weather Rev., 140, 2359–2371, 2012. a, b
Anderson, J. L.: Reducing correlation sampling error in ensemble Kalman filter data assimilation, Mon. Weather Rev., 144, 913–925, 2016. a
Anderson, J. L. and Anderson, S. L.: A Monte Carlo implementation of the nonlinear filtering problem to produce ensemble assimilations and forecasts, Mon. Weather Rev., 127, 2741–2758, 1999. a, b
Bigot, J. and Klein, T.: Characterization of barycenters in the Wasserstein space by averaging optimal transport maps, ESAIM-Probab. Stat., 22, 35–57, https://doi.org/10.1051/ps/2017020, 2018. a
Bishop, C. H., Etherton, B. J., and Majumdar, S. J.: Adaptive sampling with the ensemble transform Kalman filter. Part I: Theoretical aspects, Mon. Weather Rev., 129, 420–436, 2001. a
Borobia, A. and Cantó, R.: Matrix scaling: A geometric proof of sinkhorn's theorem, Linear Algebra Appl., 268, 1–8, 1998. a
Brajard, J., Carrassi, A., Bocquet, M., and Bertino, L.: Combining data assimilation and machine learning to emulate a dynamical model from sparse and noisy observations: a case study with the Lorenz 96 model, Journal of Computational Science, 44, 101171, https://doi.org/10.1016/j.jocs.2020.101171, 2020. a
Brenier, Y.: Décomposition polaire et réarrangement monotone des champs de vecteurs, C. R. Acad. Sci. Paris, Série I Math., 305, 805–808, 1987. a
Burgers, G., Jan van Leeuwen, P., and Evensen, G.: Analysis scheme in the ensemble Kalman filter, Mon. Weather Rev., 126, 1719–1724, 1998. a
Carrassi, A. and Vannitsem, S.: State and parameter estimation with the extended Kalman filter: an alternative formulation of the model error dynamics, Q. J. Roy. Meteor. Soc., 137, 435–451, 2011. a
Carrassi, A., Bocquet, M., Bertino, L., and Evensen, G.: Data assimilation in the geosciences: An overview of methods, issues, and perspectives, WIREs Clim. Change, 9, e535, https://doi.org/10.1002/wcc.535, 2018. a
Chen, B., Dang, L., Gu, Y., Zheng, N., and Prıncipe, J. C.: Minimum Error Entropy Kalman Filter, arXiv [preprint], arXiv:1904.06617, 17 April 2019. a
Chen, J., Chen, Y., Wu, H., and Yang, D.: The quadratic Wasserstein metric for earthquake location, J. Comput. Phys., 373, 188–209, 2018. a
Chen, Y., Georgiou, T. T., and Tannenbaum, A.: Matrix optimal mass transport: a quantum mechanical approach, IEEE T. Automat. Contr., 63, 2612–2619, 2017. a
Chen, Y., Georgiou, T. T., and Tannenbaum, A.: Wasserstein geometry of quantum states and optimal transport of matrix-valued measures, in: Emerging Applications of Control and Systems Theory, Springer, 139–150, https://doi.org/10.1007/978-3-319-67068-3_10, 2018. a
Chen, Y., Georgiou, T. T., and Tannenbaum, A.: Optimal transport for Gaussian mixture models, IEEE Access, 7, 6269–6278, 2019. a, b
Chepurin, G. A., Carton, J. A., and Dee, D.: Forecast model bias correction in ocean data assimilation, Mon. Weather Rev., 33, 1328–1342, 2005. a
Chianese, E., Galletti, A., Giunta, G., Landi, T., Marcellino, L., Montella, R., and Riccio, A.: Spatiotemporally resolved ambient particulate matter concentration by fusing observational data and ensemble chemical transport model simulations, Ecol. Model., 385, 173–181, 2018. a
Cotter, C., Crisan, D., Holm, D., Pan, W., and Shevchenko, I.: Modelling uncertainty using stochastic transport noise in a 2-layer quasi-geostrophic model, Foundations of Data Science, 2, 173–205, 2020. a
Courtier, P., Thépaut, J.-N., and Hollingsworth, A.: A strategy for operational implementation of 4D-Var, using an incremental approach, Q. J. Roy. Meteor. Soc., 120, 1367–1387, 1994. a
Courtier, P., Andersson, E., Heckley, W., Vasiljevic, D., Hamrud, M., Hollingsworth, A., Rabier, F., Fisher, M., and Pailleux, J.: The ECMWF implementation of three-dimensional variational assimilation (3D-Var). I: Formulation, Q. J. Roy. Meteor. Soc., 124, 1783–1807, 1998. a
Cramér, H.: Mathematical methods of statistics, Princeton University Press, vol. 9, ISBN: 9780691005478, 1999. a
Cuturi, M.: Sinkhorn distances: Lightspeed computation of optimal transport, in: Advances in neural information processing systems, edited by: Burges, C. J. C., Bottou, L., Welling, M., Ghahramani, Z., and Weinberger, K. Q., Curran Associates, Inc., 26, 2292–2300, https://proceedings.neurips.cc/paper/2013/file/af21d0c97db2e27e13572cbf59eb343d-Paper.pdf (last access: 9 February 2022), 2013. a, b
Cuturi, M. and Peyré, G.: Semidual regularized optimal transport, SIAM Rev., 60, 941–965, 2018. a
Dantzig, G. B., Orden, A., and Wolfe, P.: The generalized simplex method for minimizing a linear form under linear inequality restraints, Pac. J. Math., 5, 183–195, 1955. a
Dee, D. P. and Da Silva, A. M.: Data assimilation in the presence of forecast bias, Q. J. Roy. Meteor. Soc., 124, 269–295, 1998. a
De Lannoy, G. J., Reichle, R. H., Houser, P. R., Pauwels, V., and Verhoest, N. E.: Correcting for forecast bias in soil moisture assimilation with the ensemble Kalman filter, Water Resour. Res., 43, W09410, https://doi.org/10.1029/2006WR005449, 2007. a
Dobrushin, R. L.: Prescribing a system of random variables by conditional distributions, Theor. Probab. Appl., 15, 458–486, 1970. a
El Moselhy, T. A. and Marzouk, Y. M.: Bayesian inference with optimal maps, J. Comput. Phys., 231, 7815–7850, 2012. a, b
Evensen, G.: Using the extended Kalman filter with a multilayer quasi-geostrophic ocean model, J. Geophys. Res., 97, 17905–17924, 1992. a
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res., 99, 10143–10162, https://doi.org/10.1029/94JC00572, 1994. a, b, c, d, e
Evensen, G.: The ensemble Kalman filter: Theoretical formulation and practical implementation, Ocean Dynam., 53, 343–367, 2003. a
Evensen, G. and Van Leeuwen, P. J.: Assimilation of Geosat altimeter data for the Agulhas current using the ensemble Kalman filter with a quasigeostrophic model, Mon. Weather Rev., 124, 85–96, 1996. a
Feyeux, N., Vidard, A., and Nodet, M.: Optimal transport for variational data assimilation, Nonlin. Processes Geophys., 25, 55–66, https://doi.org/10.5194/npg-25-55-2018, 2018. a, b
Fisher, M. and Gürol, S.: Parallelization in the time dimension of four-dimensional variational data assimilation, Q. J. Roy. Meteor. Soc., 143, 1136–1147, 2017. a
Fréchet, M.: Les éléments aléatoires de nature quelconque dans un espace distancié, Annales de l'institut Henri Poincaré, 10, 215–310, 1948 (in French). a
Gaspari, G. and Cohn, S. E.: Construction of correlation functions in two and three dimensions, Q. J. Roy. Meteor. Soc., 125, 723–757, 1999. a
Gordon, N. J., Salmond, D. J., and Smith, A. F.: Novel approach to nonlinear/non-Gaussian Bayesian state estimation, in: IEE proceedings F (radar and signal processing), IET, 140, 107–113, 1993. a, b
Hamill, T. M.: Interpretation of rank histograms for verifying ensemble forecasts, Mon. Weather Rev., 129, 550–560, 2001. a
Hamill, T. M., Whitaker, J. S., and Snyder, C.: Distance-dependent filtering of background error covariance estimates in an ensemble Kalman filter, Mon. Weather Rev., 129, 2776–2790, 2001. a
Hellinger, E.: Neue begründung der theorie quadratischer formen von unendlichvielen veränderlichen, J. Reine Angew. Math., 1909, 210–271, 1909 (in German). a
Houtekamer, P. L. and Mitchell, H. L.: Data assimilation using an ensemble Kalman filter technique, Mon. Weather Rev., 126, 796–811, 1998. a
Houtekamer, P. L. and Mitchell, H. L.: A sequential ensemble Kalman filter for atmospheric data assimilation, Mon. Weather Rev., 129, 123–137, 2001. a
Houtekamer, P. L. and Zhang, F.: Review of the ensemble Kalman filter for atmospheric data assimilation, Mon. Weather Rev., 144, 4489–4532, 2016. a
Janjić, T., Nerger, L., Albertella, A., Schröter, J., and Skachko, S.: On domain localization in ensemble-based Kalman filter algorithms, Mon. Weather Rev., 139, 2046–2060, 2011. a, b
Kalman, R. E.: A New Approach to Linear Filtering and Prediction Problems, J. Basic Eng.-T. ASME, 82, 35–45, https://doi.org/10.1115/1.3662552, 1960. a
Kalnay, E.: Atmospheric modeling, data assimilation and predictability, Cambridge University Press, Cambridge, ISBN: 9780511802270, 2003. a
Kantorovich, L. V.: On the translocation of masses, in: Dokl. Akad. Nauk. USSR (NS), 37, 199–201, 1942. a, b
Kapur, J. N.: Measures of information and their applications, Wiley-Interscience, https://doi.org/10.2307/2533186, 1994. a
Kolouri, S., Park, S. R., Thorpe, M., Slepcev, D., and Rohde, G. K.: Optimal mass transport: Signal processing and machine-learning applications, IEEE Signal Proc. Mag., 34, 43–59, 2017. a
Kullback, S. and Leibler, R. A.: On information and sufficiency, Ann. Math. Stat., 22, 79–86, 1951. a
Kutta, W.: Beitrag zur naherungsweisen Integration totaler Differentialgleichungen, Z. Math. Phys., 46, 435–453, 1901 (in German). a
Lei, J. and Bickel, P.: A moment matching ensemble filter for nonlinear non-Gaussian data assimilation, Mon. Weather Rev., 139, 3964–3973, 2011. a
Lei, L., Whitaker, J. S., and Bishop, C.: Improving assimilation of radiance observations by implementing model space localization in an ensemble Kalman filter, J. Adv. Model. Earth Sy., 10, 3221–3232, 2018. a
Lguensat, R., Tandeo, P., Ailliot, P., Pulido, M., and Fablet, R.: The analog data assimilation, Mon. Weather Rev., 145, 4093–4107, 2017. a
Li, L., Vidard, A., Le Dimet, F.-X., and Ma, J.: Topological data assimilation using Wasserstein distance, Inverse Problems, 35, 015006, https://doi.org/10.1088/1361-6420/aae993, 2018. a
Li, R., Jan, N. M., Huang, B., and Prasad, V.: Constrained ensemble Kalman filter based on Kullback–Leibler divergence, J. Process Contr., 81, 150–161, 2019. a
Li, T., Bolic, M., and Djuric, P. M.: Resampling methods for particle filtering: classification, implementation, and strategies, IEEE Signal Proc. Mag., 32, 70–86, 2015. a
Li, Z., Zang, Z., Li, Q. B., Chao, Y., Chen, D., Ye, Z., Liu, Y., and Liou, K. N.: A three-dimensional variational data assimilation system for multiple aerosol species with WRF/Chem and an application to PM2.5 prediction, Atmos. Chem. Phys., 13, 4265–4278, https://doi.org/10.5194/acp-13-4265-2013, 2013. a
Lin, L.-F., Ebtehaj, A. M., Flores, A. N., Bastola, S., and Bras, R. L.: Combined assimilation of satellite precipitation and soil moisture: A case study using trmm and smos data, Mon. Weather Rev., 145, 4997–5014, 2017. a
Lorenc, A. C., Ballard, S. P., Bell, R. S., Ingleby, N. B., Andrews, P. L. F., Barker, D. M., Bray, J. R., Clayton, A. M., Dalby, T., Li, D., Payne, T. J., and Saunders, F. W.: The Met. Office global three-dimensional variational data assimilation scheme, Q. J. Roy. Meteor. Soc., 126, 2991–3012, 2000. a
Lorenc, A. C.: Analysis methods for numerical weather prediction, Q. J. Roy. Meteor. Soc., 112, 1177–1194, 1986. a, b
Lorenz, E. N.: Deterministic nonperiodic flow, J. Atmos. Sci., 20, 130–141, 1963. a
Lorenz, E. N.: Predictability – a problem partly solved, in: Predictability of Weather and Climate, Seminar on Predictability, Shinfield Park, Reading, UK, 4–8 September 1995, ECMWF, https://doi.org/10.1017/CBO9780511617652.004, 1995. a, b, c
Lorenz, E. N. and Emanuel, K. A.: Optimal sites for supplementary weather observations: Simulation with a small model, J. Atmos. Sci., 55, 399–414, 1998. a, b
Maclean, J., Santitissadeekorn, N., and Jones, C. K.: A coherent structure approach for parameter estimation in Lagrangian Data Assimilation, Physica D, 360, 36–45, 2017. a
McCann, R. J.: A convexity principle for interacting gases, Adv. Math., 128, 153–179, 1997. a
Monge, G.: Mémoire sur la théorie des déblais et des remblais, Histoire de l'Académie Royale des Sciences de Paris, 1781 (in French). a, b
Nerger, L., Janjić, T., Schröter, J., and Hiller, W.: A regulated localization scheme for ensemble-based Kalman filters, Q. J. Roy. Meteor. Soc., 138, 802–812, 2012a. a
Nerger, L., Janjić, T., Schröter, J., and Hiller, W.: A unification of ensemble square root Kalman filters, Mon. Weather Rev., 140, 2335–2345, 2012b. a
Ning, L., Carli, F. P., Ebtehaj, A. M., Foufoula-Georgiou, E., and Georgiou, T. T.: Coping with model error in variational data assimilation using optimal mass transport, Water Resour. Res., 50, 5817–5830, 2014. a, b
Olver, P. J., Shakiban, C., and Shakiban, C.: Applied linear algebra, Springer, vol. 1, ISBN: 9780131473829, 2006. a, b
Orlin, J. B.: A faster strongly polynomial minimum cost flow algorithm, Oper. Res., 41, 338–350, 1993. a, b
Pass, B.: Multi-marginal optimal transport: theory and applications, ESAIM-Math. Model. Num., 49, 1771–1790, 2015. a
Pedlosky, J.: Geophysical fluid dynamics, Springer, vol. 710, https://doi.org/10.1007/978-1-4612-4650-3, 1987. a, b
Penny, S., Bach, E., Bhargava, K., Chang, C.-C., Da, C., Sun, L., and Yoshida, T.: Strongly coupled data assimilation in multiscale media: Experiments using a quasi-geostrophic coupled model, J. Adv. Model. Earth Sy., 11, 1803–1829, 2019. a
Peyré, G. and Cuturi, M.: Computational optimal transport, Foundations and Trends in Machine Learning, 11, 355–607, 2019. a, b, c, d
Pitt, M. K. and Shephard, N.: Filtering via simulation: Auxiliary particle filters, J. Am. Stat. Assoc., 94, 590–599, 1999. a
Poterjoy, J. and Anderson, J. L.: Efficient assimilation of simulated observations in a high-dimensional geophysical system using a localized particle filter, Mon. Weather Rev., 144, 2007–2020, 2016. a, b
Poterjoy, J. and Zhang, F.: Intercomparison and coupling of ensemble and four-dimensional variational data assimilation methods for the analysis and forecasting of Hurricane Karl (2010), Mon. Weather Rev., 142, 3347–3364, 2014. a
Pulido, M. and van Leeuwen, P. J.: Sequential Monte Carlo with kernel embedded mappings: The mapping particle filter, J. Comput. Phys., 396, 400–415, 2019. a
Rabier, F., Järvinen, H., Klinker, E., Mahfouf, J.-F., and Simmons, A.: The ECMWF operational implementation of four-dimensional variational assimilation. I: Experimental results with simplified physics, Q. J. Roy. Meteor. Soc., 126, 1143–1170, 2000. a
Rabin, J., Peyré, G., Delon, J., and Bernot, M.: Wasserstein barycenter and its application to texture mixing, in: International Conference on Scale Space and Variational Methods in Computer Vision, Springer, 435–446, ISBN: 9783642247859, 2011. a
Rao, C. R., Rao, C. R., Statistiker, M., Rao, C. R., and Rao, C. R.: Linear statistical inference and its applications, Wiley New York, vol. 2, ISBN: 9780471708230, 1973. a
Reich, S.: A nonparametric ensemble transform method for Bayesian inference, SIAM J. Sci. Comput., 35, A2013–A2024, 2013. a
Reichle, R. H., McLaughlin, D. B., and Entekhabi, D.: Hydrologic data assimilation with the ensemble Kalman filter, Mon. Weather Rev., 130, 103–114, 2002. a
Reichle, R. H., Koster, R. D., Dong, J., and Berg, A. A.: Global Soil Moisture from Satellite Observations, Land Surface Models, and Ground Data: Implications for Data Assimilation, J. Hydrometeorol., 5, 430–442, https://doi.org/10.1175/1525-7541(2004)005<0430:GSMFSO>2.0.CO;2, 2004. a
Runge, C.: Über die numerische Auflösung von Differentialgleichungen, Mathematische Annalen, 46, 167–178, 1895 (in German). a
Shen, Z. and Tang, Y.: A modified ensemble Kalman particle filter for non-Gaussian systems with nonlinear measurement functions, J. Adv. Model. Earth Sy., 7, 50–66, 2015. a
Sinkhorn, R.: Diagonal Equivalence to Matrices with Prescribed Row and Column Sums, Am. Math. Mon., 74, 402–405, https://doi.org/10.2307/2314570, 1967. a, b
Spantini, A., Baptista, R., and Marzouk, Y.: Coupling techniques for nonlinear ensemble filtering, arXiv [preprint], arXiv:1907.00389, 30 June 2019. a, b, c
Spiller, E. T., Budhiraja, A., Ide, K., and Jones, C. K.: Modified particle filter methods for assimilating Lagrangian data into a point-vortex model, Physica D, 237, 1498–1506, 2008. a
Srivastava, S., Li, C., and Dunson, D. B.: Scalable Bayes via barycenter in Wasserstein space, J. Mach. Learn. Res., 19, 312–346, 2018. a
Tagade, P. and Ravela, S.: On a quadratic information measure for data assimilation, in: 2014 American Control Conference, IEEE, 598–603, https://doi.org/10.1109/ACC.2014.6859127, 2014. a
Tamang, S. K., Ebtehaj, A., Zou, D., and Lerman, G.: Regularized Variational Data Assimilation for Bias Treatment using the Wasserstein Metric, Q. J. Roy. Meteor. Soc., 146, 2332–2346, 2020. a, b
Tamang, S. K., Ebtehaj, A., van Leeuwen, P. J., Zou, D., and Lerman, G.: Ensemble Riemannian data assimilation over the Wasserstein space, Nonlin. Processes Geophys., 28, 295–309, https://doi.org/10.5194/npg-28-295-2021, 2021. a, b, c, d
tamangsk: tamangsk/EnRDA: Ensemble Riemannian Data Assimilation, Version v1.0, Zenodo [code], https://doi.org/10.5281/zenodo.5047392, 2021 (data available at: https://github.com/tamangsk/EnRDA, last access: last access: 9 February 2022). a
Tang, Y., Deng, Z., Manoj, K., and Chen, D.: A practical scheme of the sigma-point Kalman filter for high-dimensional systems, J. Adv. Model. Earth Sy., 6, 21–37, 2014. a
Tian, X., Zhang, H., Feng, X., and Xie, Y.: Nonlinear least squares En4DVar to 4DEnVar methods for data assimilation: Formulation, analysis, and preliminary evaluation, Mon. Weather Rev., 146, 77–93, 2018. a
Tippett, M. K., Anderson, J. L., Bishop, C. H., Hamill, T. M., and Whitaker, J. S.: Ensemble square root filters, Mon. Weather Rev., 131, 1485–1490, 2003. a
Trevisan, A. and Palatella, L.: On the Kalman Filter error covariance collapse into the unstable subspace, Nonlin. Processes Geophys., 18, 243–250, https://doi.org/10.5194/npg-18-243-2011, 2011. a
Van Leeuwen, P. J.: Particle filtering in geophysical systems, Mon. Weather Rev., 137, 4089–4114, 2009. a
van Leeuwen, P. J.: Nonlinear data assimilation in geosciences: an extremely efficient particle filter, Q. J. Roy. Meteor. Soc., 136, 1991–1999, 2010. a, b, c, d
Van Leeuwen, P. J.: A consistent interpretation of the stochastic version of the Ensemble Kalman Filter, Q. J. Roy. Meteor. Soc., 146, 2815–2825, 2020. a
Villani, C.: Topics in optimal transportation, American Mathematical Soc., Providence, RI, Volume 58, https://doi.org/10.1090/gsm/058, 2003. a, b, c
Villani, C.: Optimal transport: old and new, Springer Science & Business Media, vol. 338, ISBN 9783662501801, 2008. a
Vissio, G., Lembo, V., Lucarini, V., and Ghil, M.: Evaluating the performance of climate models based on Wasserstein distance, Geophys. Res. Lett., 47, e2020GL089385, https://doi.org/10.1029/2020GL089385, 2020. a
Yang, Y. and Engquist, B.: Analysis of optimal transport and related misfit functions in full-waveform inversion, Geophysics, 83, A7–A12, 2018. a
Yang, Y., Engquist, B., Sun, J., and Hamfeldt, B. F.: Application of optimal transport and the quadratic Wasserstein metric to full-waveform inversion, Geophysics, 83, R43–R62, 2018. a
Yong, P., Huang, J., Li, Z., Liao, W., and Qu, L.: Least-squares reverse time migration via linearized waveform inversion using a Wasserstein metric, Geophysics, 84, S411–S423, 2019. a
Zupanski, M.: Regional 4-Dimensional Variational Data Assimilation in a Quasi-Operational Forecasting Environment, Mon. Weather Rev., 121, 2396–2408, 1993. a
- Abstract
- Introduction
- Background on OMT and the Wasserstein barycenter
- EnRDA
- Numerical experiments and results
- Summary and concluding remarks
- Appendix A
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Background on OMT and the Wasserstein barycenter
- EnRDA
- Numerical experiments and results
- Summary and concluding remarks
- Appendix A
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References