the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 17 Apr 2019
| 17 Apr 2019
Inverting Rayleigh surface wave velocities for crustal thickness in eastern Tibet and the western Yangtze craton based on deep learning neural networks
Xianqiong Cheng
Qihe Liu
Pingping Li
Yuan Liu
Crustal thickness is an important factor affecting lithospheric structure and deep geodynamics. In this paper, a deep learning neural network based on a stacked sparse auto-encoder is proposed for the inversion of crustal thickness in eastern Tibet and the western Yangtze craton. First, with the phase velocity of the Rayleigh surface wave as input and the theoretical crustal thickness as output, 12 deep-sSAE neural networks are constructed, which are trained by 380 000 and tested by 120 000 theoretical models. We then invert the observed phase velocities through these 12 neural networks. According to the test error and misfit of other crustal thickness models, the optimal crustal thickness model is selected as the crustal thickness of the study area. Compared with other ways to detect crustal thickness such as seismic wave reflection and receiver function, we adopt a new way for inversion of earth model parameters, and realize that a deep learning neural network based on data driven with the highly non-linear mapping ability can be widely used by geophysicists, and our result has good agreement with high-resolution crustal thickness models. Compared with other methods, our experimental results based on a deep learning neural network and a new Rayleigh wave phase velocity model reveal some details: there is a northward-dipping Moho gradient zone in the Qiangtang block and a relatively shallow north-west–south-east oriented crust at the Songpan–Ganzi block. Crustal thickness around Xi'an and the Ordos basin is shallow, about 35 km. The change in crustal thickness in the Sichuan–Yunnan block is sharp, where crustal thickness is 60 km north-west and 35 km south-east. We conclude that the deep learning neural network is a promising, efficient, and believable geophysical inversion tool.
- Article
(18127 KB) - Full-text XML
- BibTeX
- EndNote




Eastern Tibet and the western Yangtze craton are one of the key areas for understanding the collision process between the Indo-European plate and are an important area for understanding the collision and contact relationship between the Qinghai–Tibet Plateau and the Yangtze craton. In the field of geosciences, because of the strong seismic activity, the nature of the two blocks is different, especially the special topography. The altitude of the two blocks suddenly rises from about 500 m in eastern Tibet to 5000 m in the western Yangtze craton. Many studies focus on understanding the crust and upper mantle structure in this region; there have especially been heated debates on crustal thickness. The discontinuity between the crust and the mantle is called Moho discontinuity, which varies greatly on a small scale and is an important factor in geodynamics, including crustal evolution, tectonic activity, gravity correction of the crustal effect, seismic tomography, and geothermal models. Many studies focus on obtaining the depth of Moho discontinuity called crustal thickness by various data and different methods.
Usually, the crustal thickness can be inverted by many kinds of data, such as inversion of deep seismic sounding profiles on the Chinese mainland for crustal thickness (Zeng et al., 1995), inversion of satellite gravity data for global crustal and lithospheric thickness (Fang, 1999), inversion of Bouguer gravity and topography data to calculate the crustal thickness of China and its surrounding areas (Huang et al., 2006; Guo et al., 2012), and an inversion receiver function used to calculate the crustal thickness and Poisson's ratio of the Chinese mainland (Chen et al., 2010; Zhu et al., 2012; Xu et al., 2007). In particular, one of the newest models' crust 1.0 at (Laske et al., 2013; Stolket al., 2013) is based on refraction and reflection seismology as well as receiver function studies. In addition, these data related to crustal thickness mentioned above, and crust thickness has significant effects on fundamental mode surface waves (Meier et al., 2007; Grad and Tiira, 2009). Dispersion characteristicz of surface waves provide a powerful tool to research the structure of the crust and upper mantle (Legendre et al., 2015). So far phase and group velocity measurements of fundamental mode surface waves have most commonly been used to constrain shear-velocity structure in the crust and upper mantle on a global scale (Zhou et al., 2006; Shapiro and Ritzwoller, 2002) or on a regional scale (Zhang et al., 2011; Yi et al., 2008); also, the newly developed ambient noise surface wave tomography has been used to constrain shear-velocity structure (Sun et al., 2010; Yao et al., 2006; Zheng et al., 2008; Zhou et al., 2012), with a few works to invert fundamental mode surface wave data for global or regional crustal thickness and to present a global or regional crustal thickness model (Devile et al., 1999; Meier et al., 2007; Das and Nolet 2001; Lebedev et al., 2013). Although the measurement period and method of group velocity and phase velocity are different, the detection depth and measurement error are also different, and phase velocity is more sensitive to deeper structure, so it is easier to infer deep structure from phase velocity measurements. We use phase velocity as input to infer the crustal thickness.
There are several inversion methods to get crustal thickness which can be broadly classified into two classes: (1) the model-driven method and (2) the data-driven method. For the model-driven method, the researchers mainly consider the physical relation between earth parameter space and data space to calculate an inversion function. Most model-driven methods deal with the inversion of crustal thickness as a linear problem. More importantly, their results largely depend on the initial earth model. Compared with model-driven method, another fully non-linear data-driven method is called a neural network, which is used to obtain crustal thickness (Devile et al., 1999; Meier et al., 2007). Data-driven, highly non-linear mapping neural networks are widely used in geophysical inversion methods, which use actual seismic logging data and their attributes to predict the earth's parameters. Compared with model-driven inversion, data-driven inversion does not need to consider the physical relationship between the parameters of the earth model and data space and can map and predict arbitrary non-linear relationship quickly and accurately. Neural networks can be very useful in situations where the forward relation is known, but the inverse mapping is unknown or difficult to establish by more conventional analytical or numerical methods (de Wit et al., 2013). So the aim of neural network inversion is to find the mapping from a set of training data. Neural networks have been widely used in different geophysical applications, well summarized by van der Baan and Jutten (2000) such as in electrical impedance tomography (Lampinen, and Vehtari, 2001) and in seismic processing including trace editing, travel time picking, horizon tracking, and velocity analysis. Devilee et al. (1999) were the first to use a neural network to invert surface wave velocities for Eurasian crustal thickness in a fully non-linear and probabilistic manner. Meier et al. (2007) further developed the methods of Devilee et al. (1999), and then inverted surface wave data for global crustal thickness on a grid globally using a neural network.
As seismology points out that there are many factors affecting phase velocity, inverting phase velocity for discontinuities within the earth forms a non-linear inverse problem (Meier et al., 2007). Because of strong non-linear relations between crust thickness and surface wave dispersion, we cannot treat it with a linear inverse problem as Montagner and Jobert (1988) stated. Although a shallow neural network with a lower number of hidden layers can present a non-linear inverse function, it maybe cannot learn or approximate the true inverse function well when the true inverse function is too complicated. In contrast, a deep learning neural network can overcome this defect since it has powerful representation abilities and can discover intricate structures in large data sets, because it makes use of the back-propagation algorithm to indicate how a machine should change its internal parameters that are used to compute the representation in each layer from the representation in the previous layer (LeCun et al., 2015).
In this paper, in view of the advantages and characteristics of a deep learning neural network, a new fast inverse method based on a data-driven, deep stacked sparse auto-encoders (sSAE) neural network is introduced to solve the non-linear geophysical inverse problems. We focus on deep learning neural networks to solve the non-linear inverse problem, and then apply them to retrieve the crustal thickness for eastern Tibet and the western Yangtze craton from the newest and high-resolution phase velocity maps. Based on normal mode theory we compute phase velocities for the sampled radially symmetric earth models to generate 500 000 theoretical models. First, the theoretical phase velocity of a Rayleigh surface wave under random noise is used as input to enhance the robustness of the neural network, and the corresponding theoretical crustal thickness is used as output. Twelve deep neural networks are constructed and trained by 380 000 and tested by 120 000 synthetic models. We then invert the observed phase velocities through these 12 neural networks. According to test errors and misfits with other crustal thickness models, the optimal crustal thickness model is selected as the crustal thickness of the study area.
To the best of our knowledge, we are the first to introduce deep learning neural networks to learn and invert crustal thickness, and our results show that crustal thickness is strongly non-linear with respect to phase velocity. The merits of our methods include the following: first, since deep learning neural networks can represent complex functions, it is possible to learn the crustal thickness inverse function precisely. Using a deep learning neural network, we can learn the relationship between surface wave phase velocity and model parameters on the basis of large data (i.e. 500 000 theoretical models in this study) and relax the a priori constraints on model parameters (the crustal thickness is limited to 20–100 km). Secondly, inverse mapping based on neural networks is of high efficiency because new observations can be inverted instantaneously once well-trained deep learning neural networks with multiple hidden layers are constructed. Thirdly, we can invert any combination of model parameters without resampling model space (we will invert crustal thickness and shear wave velocity simultaneously in future work). Last but not least, the results show that when the number of hidden layers reaches six and the test error is about 4.5e-6, the change in the number of neurons in each layer has little effect on the test error, which indicates that the deep learning neural network has strong robustness to the neural network structure with appropriate layers. In the following, we will first briefly introduce the deep learning neural network.
In geophysics the real inverse function is usually a very complicated one between data space and model space. The traditional linear inverse methods that treat the real inverse function as a linear one can resolve the linear relation problems. However, they depend on physical relationships between the parameter space and initial earth model. A neural network has its origins in attempts to find mathematical representations of information processing in biological systems (Bishop, 1995). The deeper strength of artificial neural networks (ANNs) is that more capabilities learn to infer complex, non-linear, underlying relationships without any a priori knowledge of the model (Bengio, 2009). A shallow neural network has gained in popularity in geophysics in the last decade and has been applied successfully to a variety of problems such as well-log, interpretation of seismic data, or geophysical inversion. Although a shallow neural network can present a non-linear inverse function, it can only learn the relatively simple inverse function. In contrast, many research results indicate that a deep learning neural network has a powerful representation ability and can apply big geophysical observable data to learn and approximate the complicated inverse function well (Lecun et al., 2015; Bengio et al., 2006; Liu et al., 2015).
Based on the analysis above, we design a deep learning neural network to obtain crustal thickness for eastern Tibet and the western Yangtze craton. Compared with shallow neural networks, a deep learning neural network allows computational models that are composed of multiple processing layers to learn representations of data with multiple levels of abstraction and can learn complex functions. The essence of deep learning is building an artificial neural network with deep structures to simulate the analysis and interpretation process of the human brain for data such as image, speech, or text. However, many research results suggest that gradient-based training of a deep neural network gets stuck in apparent local minima, which leads to poor results in practice (Bengio, 2009). Fortunately, the greedy layer-wise training algorithm proposed by Hinton and Salakhutdinov (2006) overcomes the optimization difficulty of deep networks effectively. The training processing of deep neural networks is divided into two steps. First, unsupervised learning methods are employed to pre-train each layer's parameters with the output of the previous layer as input, giving rise to initialize parameter values. After that, the gradient-based method is used to finely tune the whole neural network parameter values with respect to a supervised learning criterion as usual. The advantage of the unsupervised pre-training method at each layer can help guide the parameters of that layer towards better regions in parameter space (Bengio, 2009). There are multiple types of deep learning neural networks, such as convolutional neural networks, deep belief nets, and sSAE. sSAE works very well in learning useful high-level features for better representation of input raw data. Since the sSAE learning algorithm can automatically learn even better feature representations than the hand-engineered ones, sSAE is used widely in many domains such as computer vision, audio processing, and natural language processing (Hinton and Salakhutdinov, 2006; Deng et al., 2013). Similar to these problems, we need to extract earth feature representation from dispersion of surface waves. Here we introduce sparse auto-encoders briefly, and a detailed description of the network training method is given by Liu et al. (2015).
The structure of sSAE is stacked by sparse auto-encoders to extract abstract features. A typical sparse auto-encoder (SAE) can be seen as a neural network with three layers, as shown in Fig. 1, including one input layer, one hidden layer, and one output layer. The input vector and the output vector are denoted by v and , respectively. The matrix W is associated with the connection between the input layer and the hidden layer. Similarly, the matrix connects the hidden layer to the output layer. The vectors b and are the bias vectors associated with the units in the hidden layer and the output layer, respectively. The SAE is trained to encode the input vector v into some representation so that the input can be reconstructed from that representation. Let f(x) denote the activation function, and the activation vector of the hidden layer then is calculated (with an encoder) as
where z is the encoding result and some representation for the input v. The representation z or code is then mapped back (with a decoder into a construction of the same shape as v. The mapping happens through a similar transformation, e.g.
SAE is an unsupervised learning algorithm which sets the target values to be equal to the inputs and constrain outputs of the hidden layer which are near to zero and most hidden layers are inactive; the cost function is expressed as
Here J(W,b) is the cost function without a sparsity constraint, β controls the weight of the sparsity penalty term, S2 is the number of neurons in the hidden layer, and the index j sums over the hidden units in our network. is the average activation of hidden unit j, and ρ is a sparsity parameter, typically a small value close to zero.
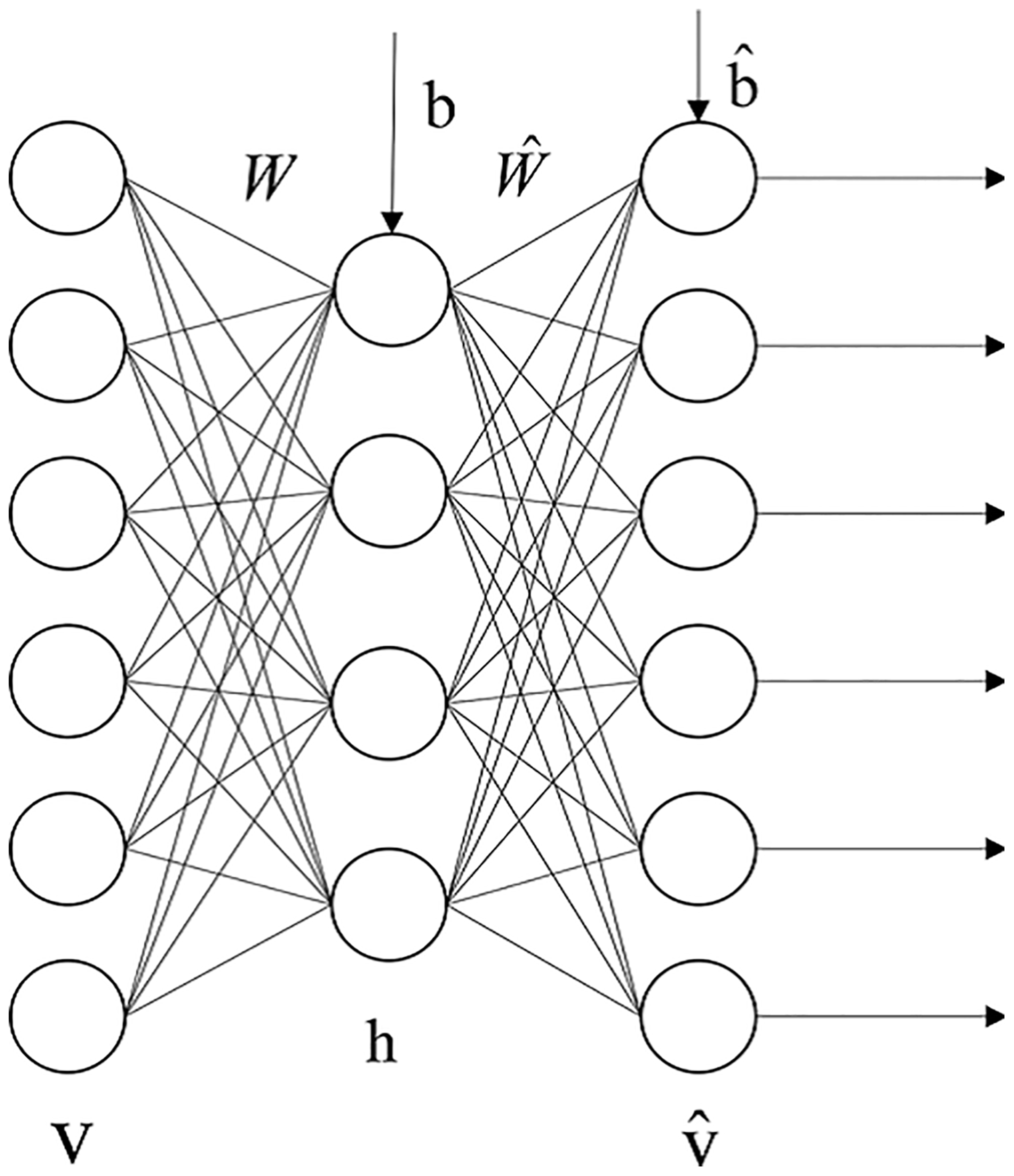
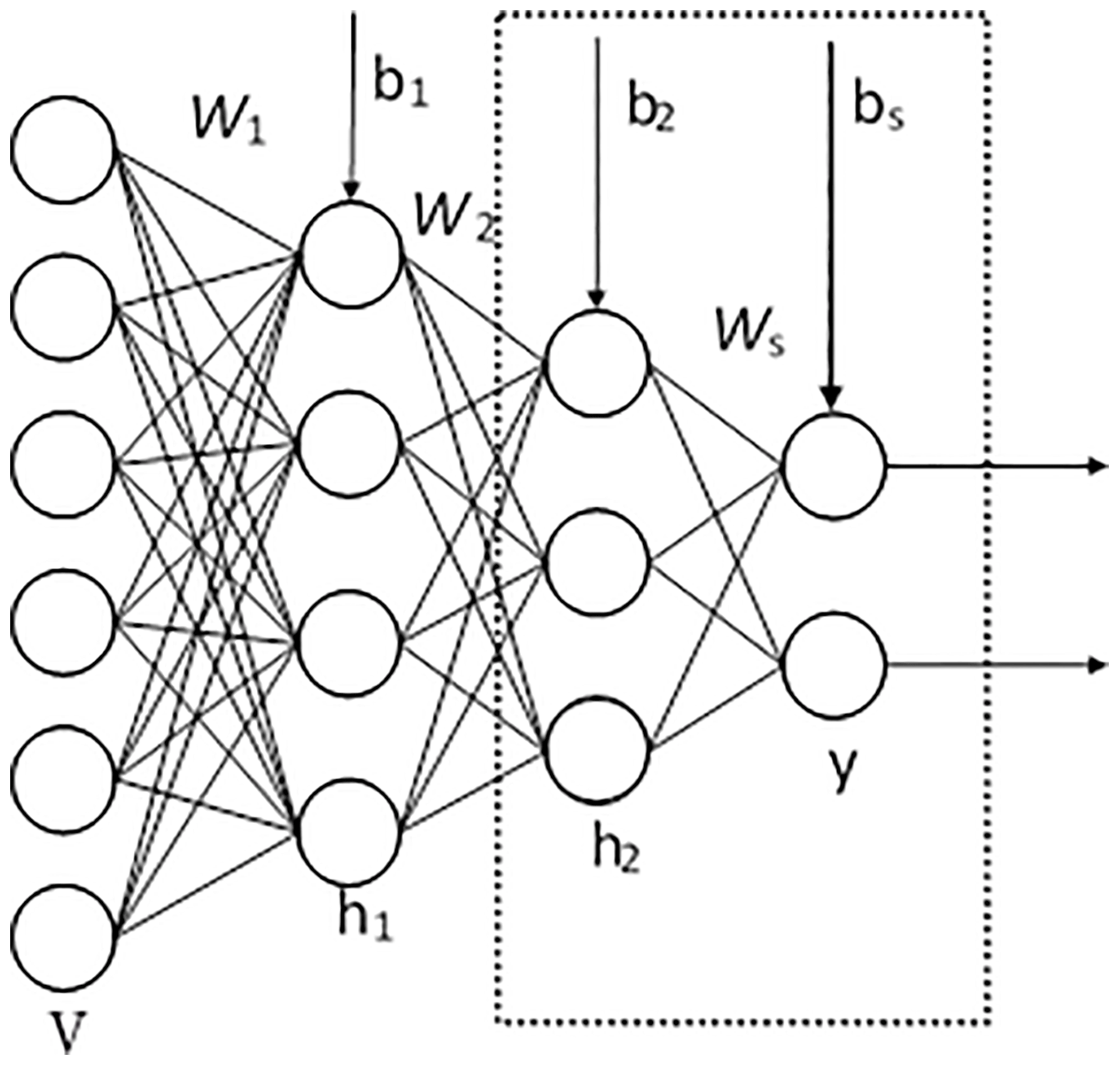
Further, sSAE are neural networks consisting of multiple layers of SAE in which SAE are stacked to form a deep neural network by feeding the representation of the SAE found on the layer below as input to the current layer. Using unsupervised pre-training methods, each layer is trained as sSAE by minimizing the error in reconstructing its input, which is the output code of the previous layer. After all layers are pre-trained, we add a logistic regression layer on top of the network, and then train the entire network by minimizing prediction error as we would train a traditional neural network. For example, an sSAE with two hidden layers is shown in Fig. 2. This sSAE is composed of two SAEs. The first SAE consists of the input layer and the first hidden layer, and the representation or code of the input v is . The second SAE comprises two hidden layers, and the code of h1 is . Each SAE is added to a decoder layer as shown in Fig. 1, and we can then employ unsupervised pre-training methods to train each SAE by expression (1). Finally, the matrix W1, W2 and bias vector b1 and b2 are initialized. We then apply supervised fine-tuning methods to train an entire network. Since our aim is to calculate crustal thickness and this is a regression problem, we attach a layer connected fully with the last layer of the encoder part (the matrix Ws). After that, we train this network as done in a traditional neural network.
As Meier et al. (2007) demonstrated, the neural network approach for solving inverse problems is best summarized by three major steps as shown in Fig. 3: (1) forward problem. In this stage we proceed by randomly sampling the model space and solve the forward problem for all visited models based on seismic wave normal mode theory. (2) Designing a neural network structure. In this stage taking phase velocities with random noise as input and theoretical crustal thickness as output, we train the deep learning neural networks and the optimized neural network is obtained. (3) Inverse problem. Based on trained networks, we invert crustal thickness from observed phase velocities.
In what follows we introduce how to train sSAE deep learning neural networks to model surface wave dispersion based on synthetic seismograms, and then invert dispersion curves based on the trained networks. Finally we compare our crustal model with other crustal thickness models, and discuss the geodynamic implications of our model.
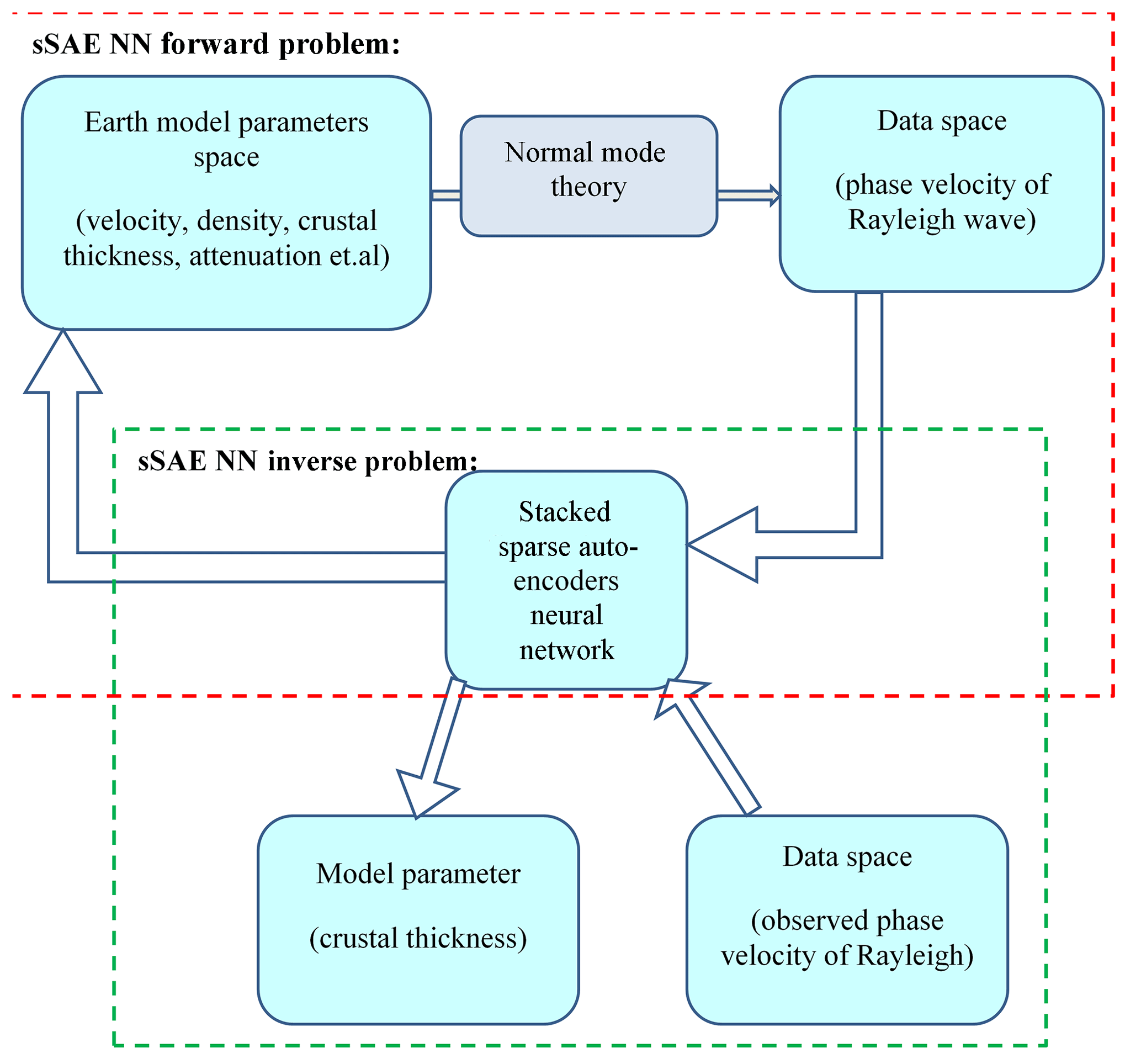
Figure 3Crustal thickness inversion based on an sSAE neural network composed of two parts: forward problem and inverse problem.
3.1 Data preparation
We closely follow the model parameterization methodology outlined in de Wit et al. (2014), which is based on the Preliminary Reference Earth Model (PREM, Dziewonski and Anderson, 1981) and is parameterized on a discrete set of 185 grid points used by the Mineos package (Masters et al., 2014). In addition, these models we have got show no correlations between physical parameters such as velocity, density, anisotropic parameter, and attenuation profiles. As with the model parameterization method mentioned above, we generate 500 000 synthetic models based on 1-D reference model PREM, which are randomly drawn from the prior model distribution; also, prior ranges for the various parameters in our model are given in Tables A.2–A.4. of de Wit et al. (2014). We use the Mineos package to compute phase velocity for fundamental mode Rayleigh waves for all 500 000 synthetic 1-D earth models. As for observation data used in the stage of inversion below, phase velocities are more sensitive to the deep structure than group velocity. Based on Rayleigh wave phase velocity from ambient noise (Xie et al., 2013) shown in Fig. 4 averaged from 10 to 35 mHz, we take these as input for our neural networks.
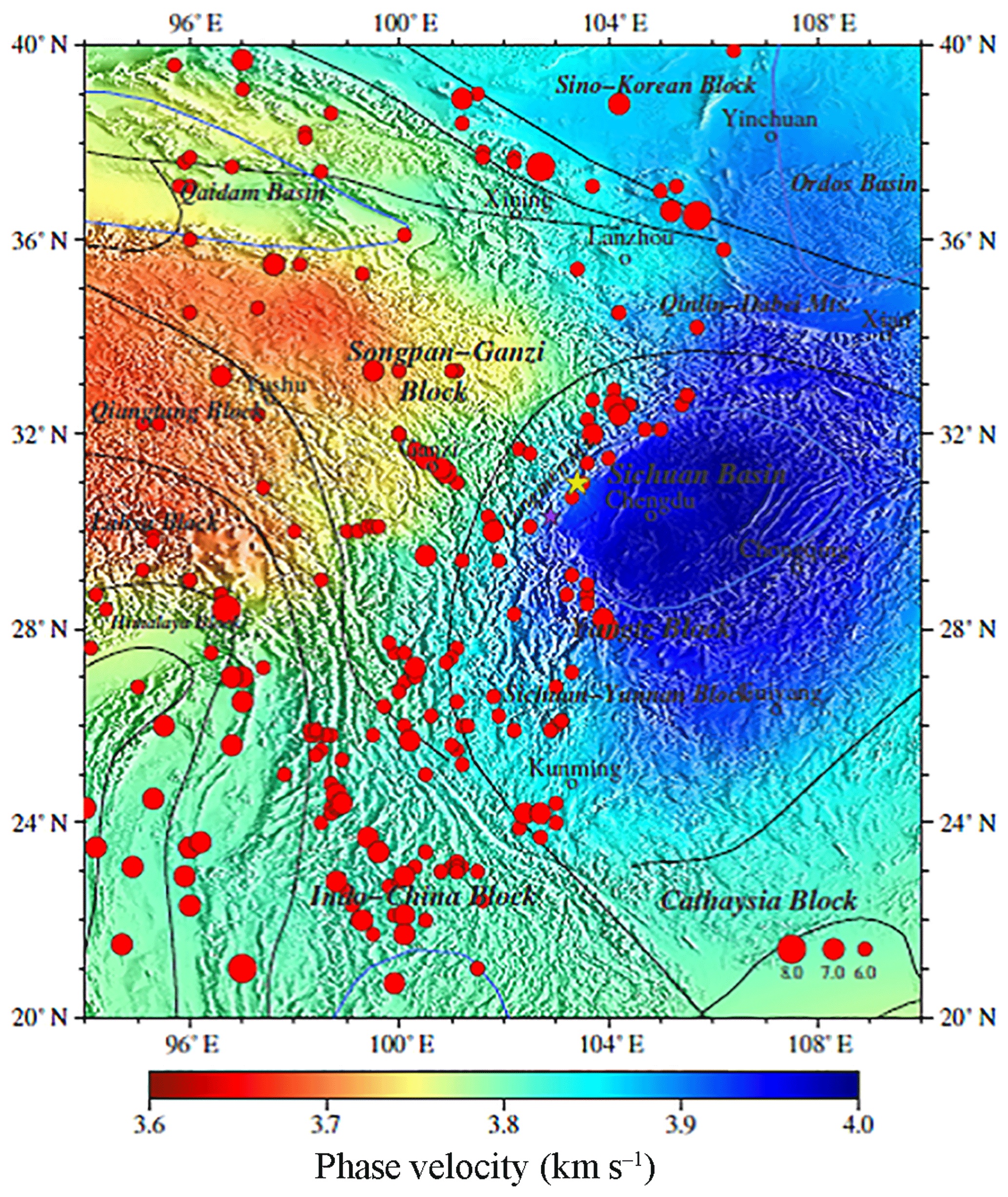
Figure 4Average phase velocity of the western Yangtze craton (Xie et al., 2013) from 10 to 35 mHz. The black lines in the figure show structure lines. The blue lines show boundaries of sedimentary basins. The red dots show seismic events in this region from 1975 to 2015, and the size of a dot demonstrates the size in magnitude from Ms 6.0 to Ms 8.0. The yellow and purple stars demonstrate the Wenchuan and Lushan earthquakes respectively. These are the same as Figs. 4, 6, and 7.
3.2 Training an sSAE deep learning neural network
It is well known that the artificial neural network can approximate any non-linear function to solve the non-linear inverse problem by using a corresponding set of input–output pairs. These examples are presented to a network in a so-called training process, during which the free parameters of a network are modified to approximate the function of interests (de Wit et al., 2014). Here adopting an sSAE deep learning neural network, with detailed methods presented in Sect. 2 above, we pre-train the neural network, taking the theoretical phase velocity of Rayleigh waves with random noise as inputs and the theoretical crustal thickness as outputs to attain the initial weights and bias for a neural network. And then we take the theoretical phase velocity of Rayleigh waves with random noise as input and crustal thickness as output to fine-tune the neural network as done in a traditional neural network.
How to find a satisfactory structure of a neural network is a difficult problem because neural network training is sensitive to the random initialization of the network parameters. Therefore, de Wit et al. (2014) pointed out that it is common practice to train several neural networks with different initializations and subsequently choose the network which performs best on a given synthetic test data set, and the network which performed best on the test set is used to draw inferences from the observed data (de Wit et al., 2014). After trying many times, we find the proportion of the training data set to test one is 3:1, which is reasonable (Fig. 5). The final test error depends on not only the number of input neurons, hidden layers, and intermediate neurons, but also on the number of trainings, batch sizes, and other optional parameters. In addition, the type of activation function, learning rate, zero masked fraction, and non-sparsity penalty value will affect final test errors. We give 12 cases and their corresponding test errors in Table 1.
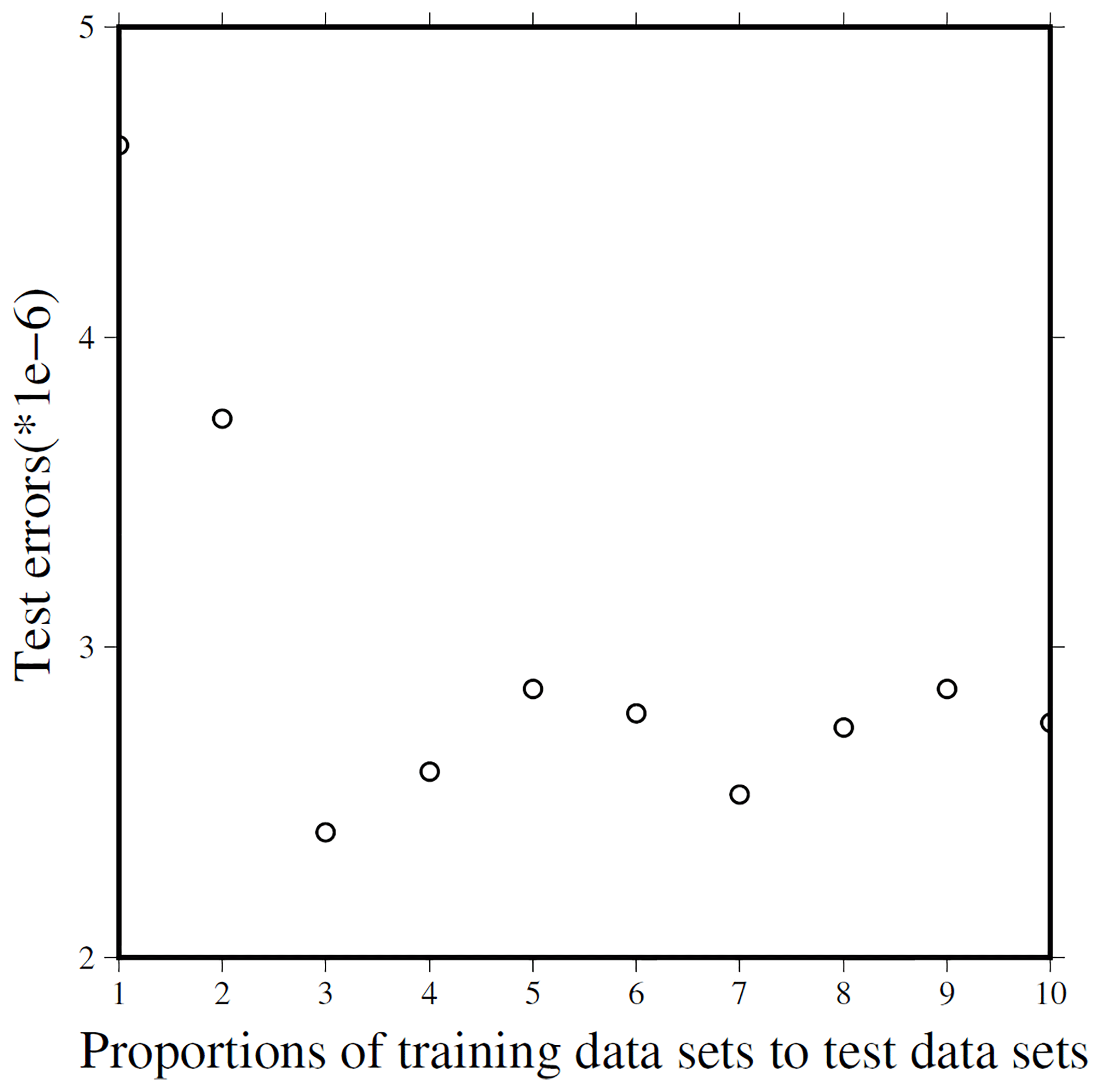
Figure 5The relationship between proportions of training data sets to test data sets and test errors.
3.3 Inverting crust thickness
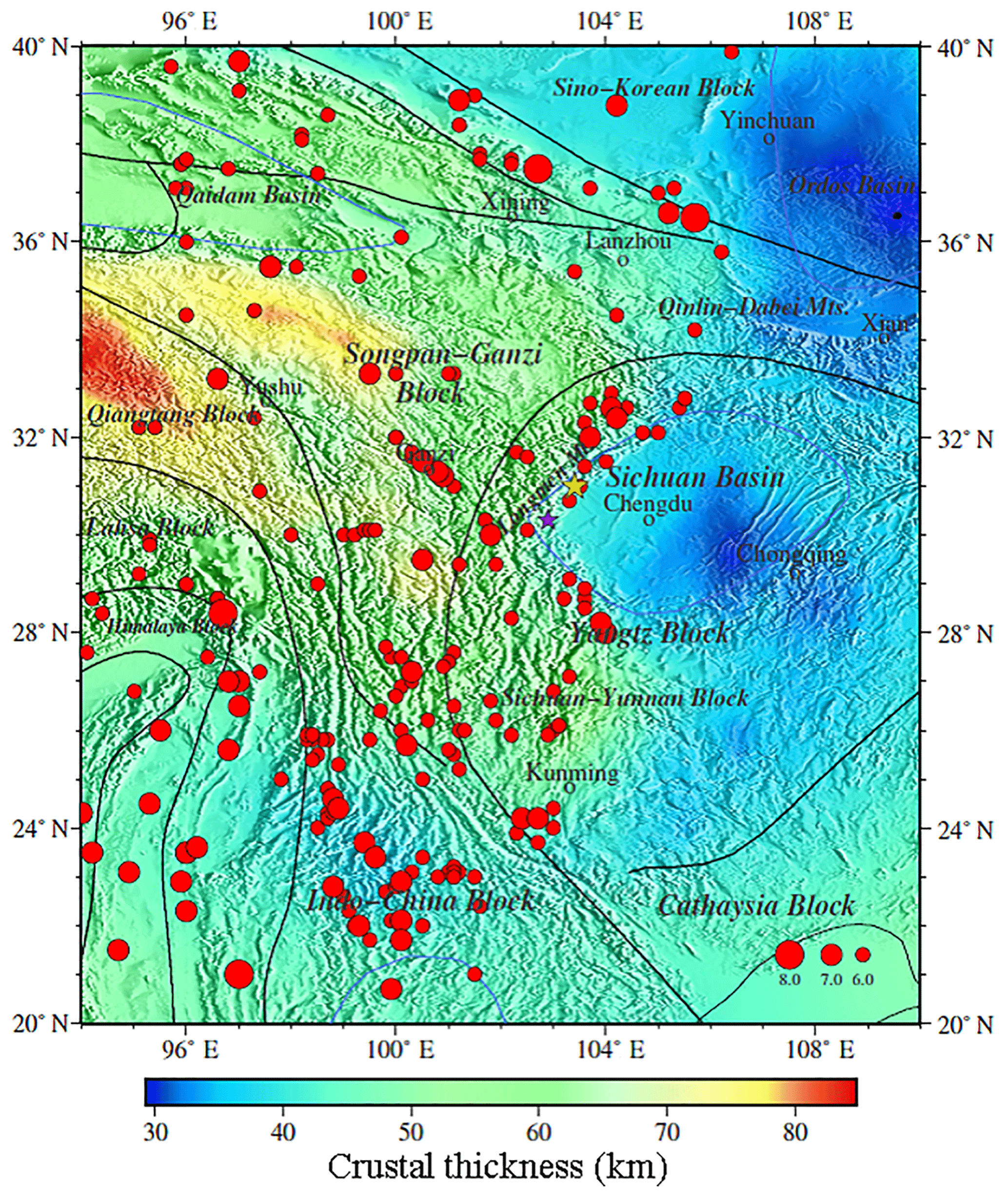
Based on all our 12 neural networks, we invert Rayleigh phase velocities (10–35.0 mHz) to attain 12 crustal thickness models for eastern Tibet and the western Yangtze craton. Considering not only the test errors of sSAE networks but also misfits and correlation coefficients of our 12 models with crustal thickness models from other studies, we choose the network structure indicated by * in Table 1. We find the best fit crustal thickness model from sSAE (Fig. 6). We compare our model with the crustal thickness model from the receiver function (Zhu et al., 2012), and the other two global crustal thickness models, CRUST2.0 from Bassin et al. (2000) based on refraction and reflection seismics as well as receiver function studies and the CUB2 model from Shapiro and Ritzwoller (2002) (Fig. 7), who inverted a similar data set for crustal thickness using a Monte Carlo approach. The correlation coefficients and scatter plots of our model versus ZJS, our model versus CRUST2.0, and our model versus CUB2 (Fig. 8) indicate overall agreement between the three models. However, the agreements of our model with CUB2 and CRUST2.0 are better than with ZJS, since model ZJS attained from Zhu et al. (2012) has relatively sparse stations with poor data coverage and lower resolution. In addition, taking the Monte Carlo method (Hansen et al., 2013) using four processors only for 1000 iterations, it takes 3 weeks to invert the Xie et al. (2013) data set to the crust thickness of the same region. As Shapiro and Ritzwoller (2002) pointed out, the major disadvantage of this method is computational expense. Maybe the result is high resolution after many more iterations using the Monte Carlo method. However, when we make use of sSAE, using only one processor, a six-layer network for 380 000 training samples and 120 000 test samples for network training takes 5 h, while a well-trained neural network inversion takes only a few seconds to complete.
Table 1Deep learning neural network structures in this article.
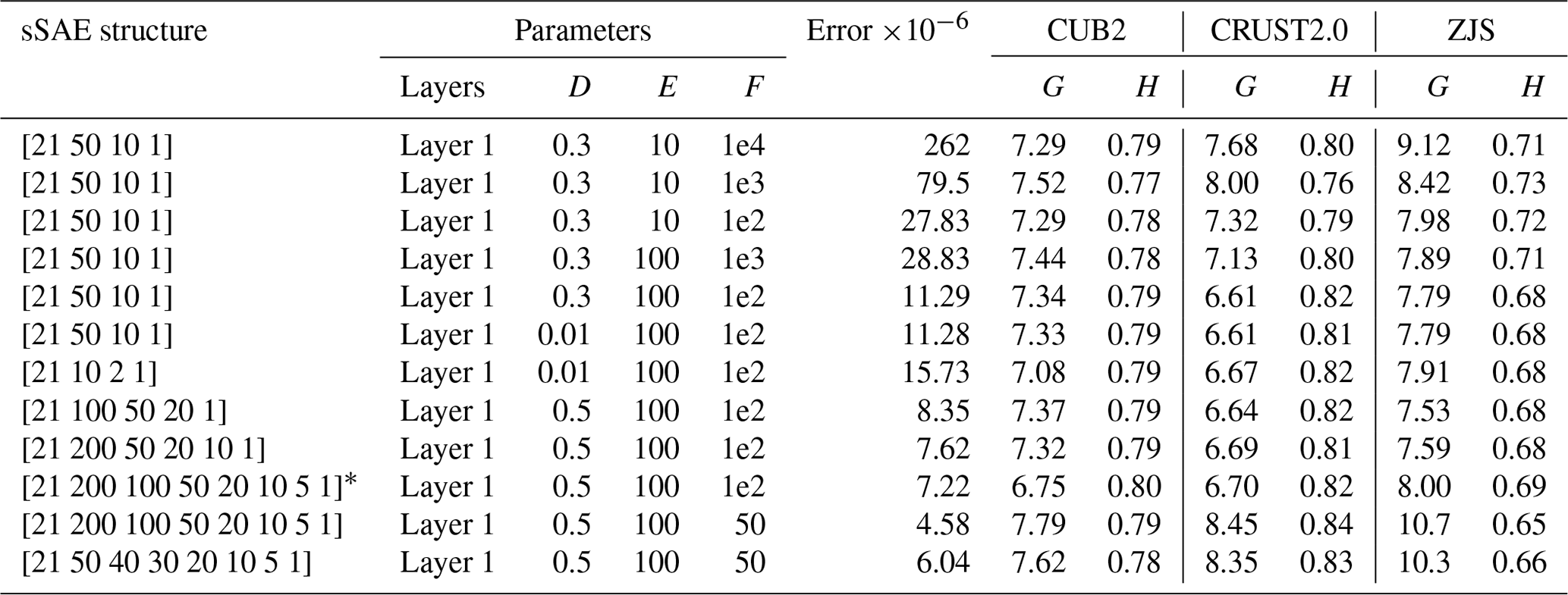
In this article, we fixed the following three parameters in every situation: A – type of activation function (sigmoid); B – learning rate (1); C – zero masked fraction (0.5). Various parameters: D – non-sparsity penalty, which is zero except for layer 1 in every sASE structure; E – number of epochs; F – size of batch. G – RMS misfit of our result with other model; H – correlation coefficient of our result with another model. * – selected sSAE neural network structure.
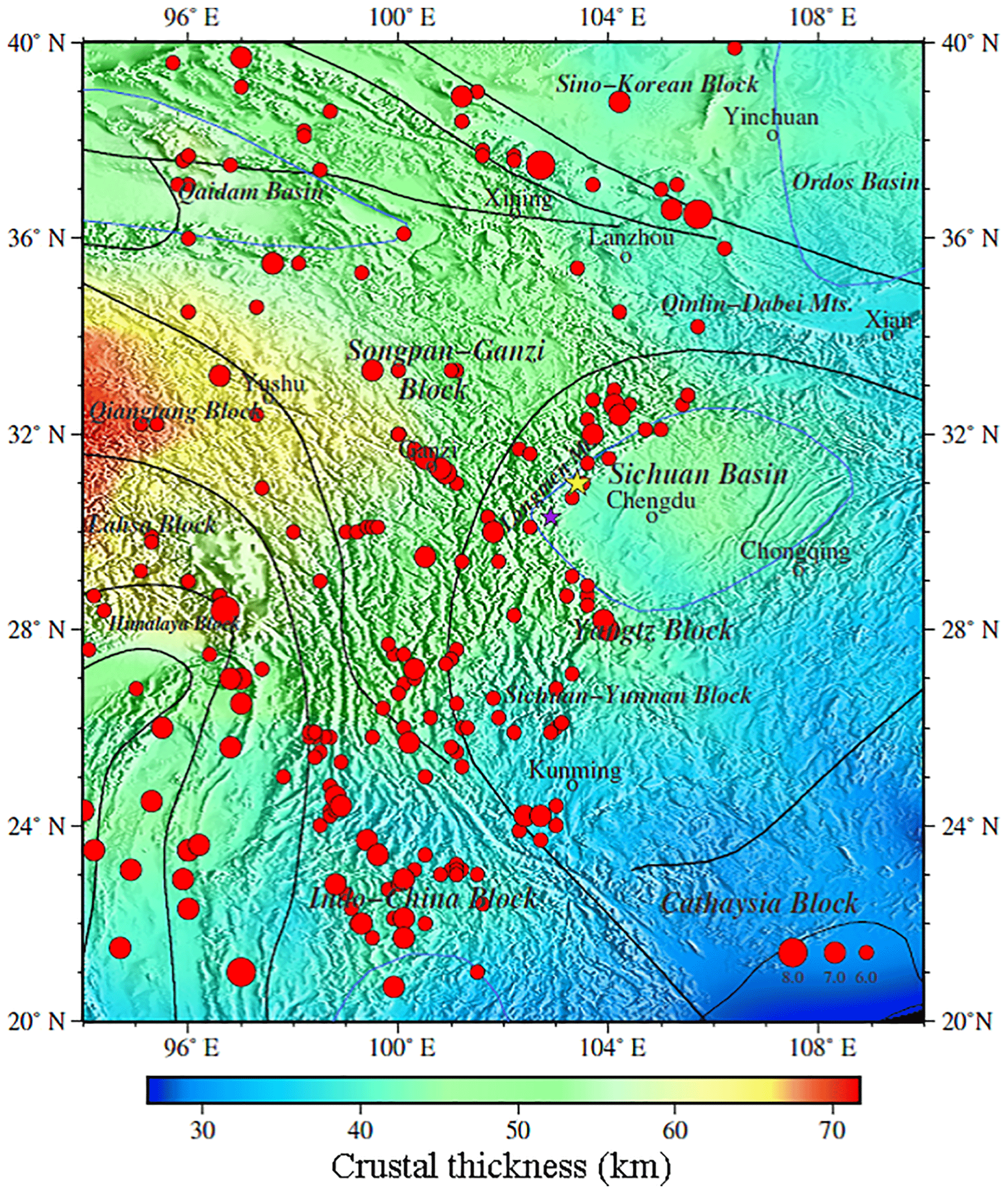
Figure 7Crustal thickness of model CUB2 from Shapiro and Ritzwoller (2002). Note: the colour scale is not exactly the same as Fig. 6.
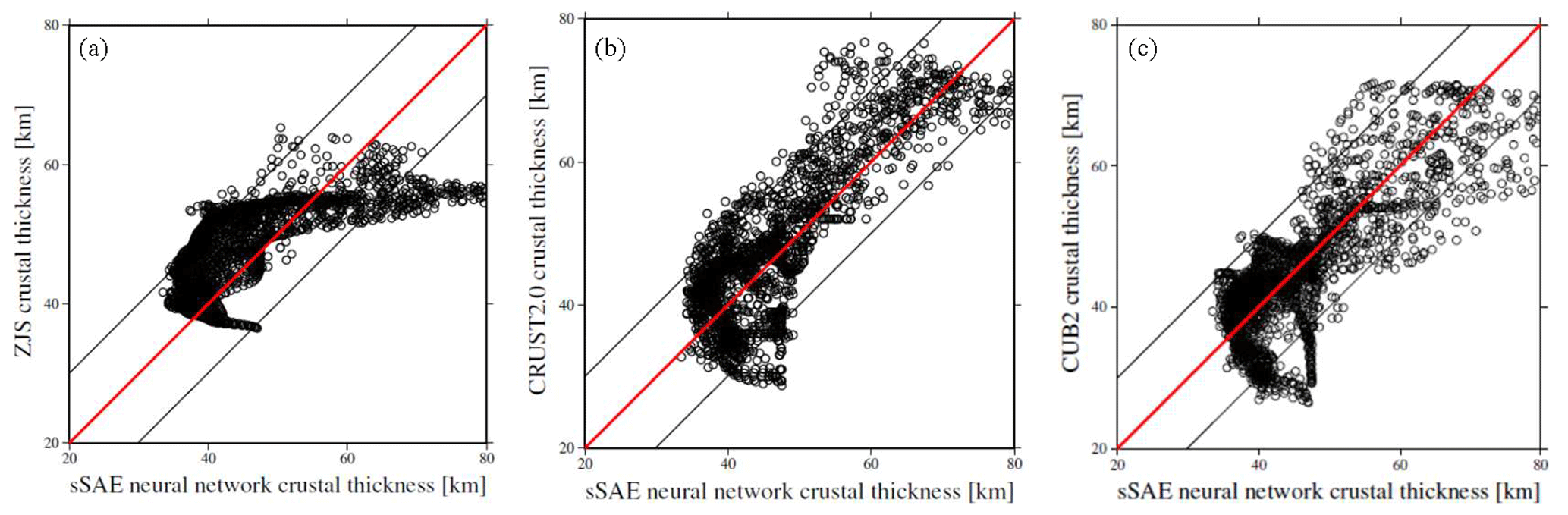
Figure 8(a–c) Scatter plots of our model versus ZJS, our model versus CRUST2.0, and our model versus CUB2.
On the one hand, our results show that deep learning neural networks can effectively invert crustal thickness because they have the ability to represent complex inverse functions.
A deep neural network can offer improvement over a shallow neural network as shown in Table 1. Test errors of a deep learning neural network may be affected by the number of hidden layers in networks. The test error of a deep learning neural network may be affected by the number of hidden layers in the network, which indicates that the more hidden layers, the smaller the test error. When the number of hidden layers in networks increases from three to six, we can attain from Table 1 that the test error decreases from to . In addition, the robustness of deep learning neural networks is strong. When the number of hidden layers in a network reaches six, the change in the number of neurons in each layer has little influence on test errors, about .
In addition, we conclude that different training parameters have different effects on training results. We think that the size of a batch is more important than epochs, as shown in Table 1. The size of a batch decreases from 1×104 to 1×103 and test errors decrease from to ; however, epochs increase from 10 to 100, and corresponding test errors change a little. The neural network structure indicated by * in Table 1 reveals misfits of our model with models CUB2, CRUST2.0, and ZJS are relatively low at 6.75, 6.70, and 8.0, and corresponding correlation coefficients are relatively high at 0.8, 0.82, and 0.69 respectively; however, the test error is and is not minimum. This tells us that the test error may not be the only criterion determining which neural network is best, because over-fitting may lead to small test errors.
Compared with the works of Meier et al. (2007), in order to enhance robustness of neural networks, random noise is added to synthetic phase velocity as input in training progress. However, we have not considered the uncertainty of crustal thickness, which should be revealed by the deep mixture density network in a probabilistic manner in our future work.

Figure 9The relative error of the average phase velocity between the phase velocity calculated by our model and the phase velocity observed by Xie et al. (2013).
On the other hand, we can attain the crustal thickness and resultant geodynamic implications in a research region from our result. We find relatively good agreement of our result (Fig. 6) with CUB2 (Fig. 7), CRUST2.0, (Fig. 8) and other recent studies (Qian et al., 2018; Xu et al., 2016; Wang et al., 2015). All these models indicate that crustal thickness is deeper to the west of the Longmen Mountains than to the east of the Longmen Mountains, which all showed an approximately 45 km thick crust below the Sichuan basin, thickening beneath the Longmen Mountains and the high Tibetan Plateau to about 60–80 km. Since we make use of a regional high-resolution phase velocity model, our result reveals more details. In order to prove that these anomalies are persistent, only accidents, or inversion artifacts, we verify two aspects: one is that because our model gives a point estimate without uncertainty information, we propose the relative error between the phase velocity calculated based on our model and the phase velocity observed in the same region (Xie et al., 2013) to verify the uncertainty and non-uniqueness of the inversion results (Figs. 9 and 10). The relative error calculation formula is shown in Eq. (4).
RE – relative error of average phase velocity; Phacal – calculated average phase velocity based on our model; Phaobs – observed average phase velocity from Xie et al. (2013).
The relative error between east and west is significantly different (Fig. 9). The reason is that in our research area, as shown in Fig. 1b of Xie et al. (2013), the stations in the east are much denser than in the west, and the Rayleigh wave measurements has a higher resolution in the east. Therefore, compared with the west, the training data in the east are more dense, resulting in higher prediction accuracy of the neural network in the east and lower prediction accuracy in the west. Using the same parameters but for a traditional shallow neural network with three layers (one input layer, one intermediate layer, and one output layer), we train this shallow neural network and obtain a relative error with the observed average phase velocity. The histogram error of the relative error of the shallow network is larger than that of our deep learning network (Fig. 10). We can conclude that our model is more reliable in the eastern part of the Longmen Mountains, especially in Chengdu, the Qinling–Dabei fold belt, the Xi'an and Ordos basins, and the Sichuan–Yunnan block, and so the crust thickness anomaly in these areas is worth explaining. Another reference is to the results of other studies conducted by C. Y. Wang et al. (2010) in the same area, who attained the crustal thickness estimated by the H–k stacking method based on the broadband tele-seismic data recorded at 132 seismic stations in the Longmen Mountains and adjacent regions (26–35∘ N, 98–109∘ E) (Fig. 11).
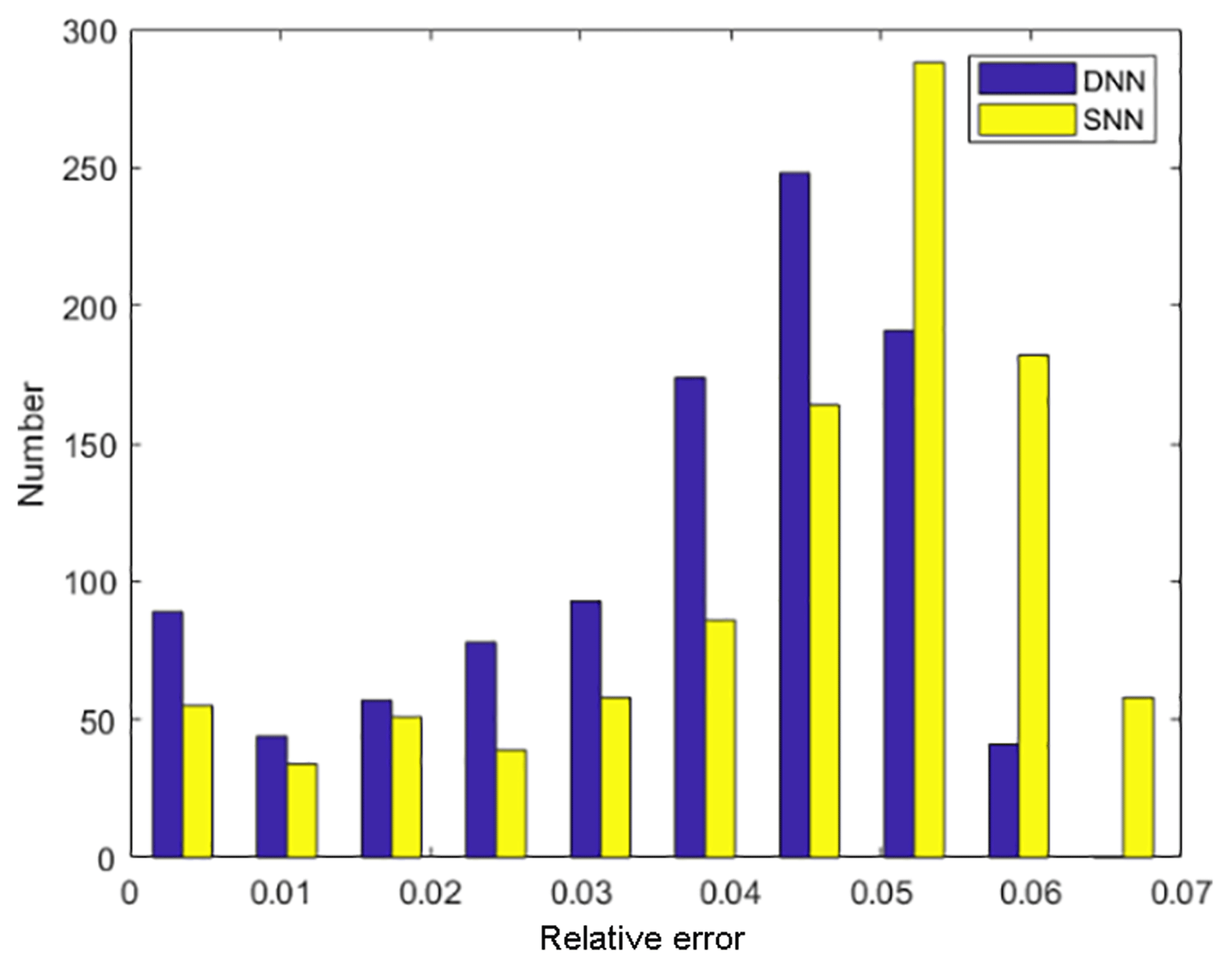
Figure 10The histogram of the relative error of the shallow neural network (SNN) and deep neural network (DNN).
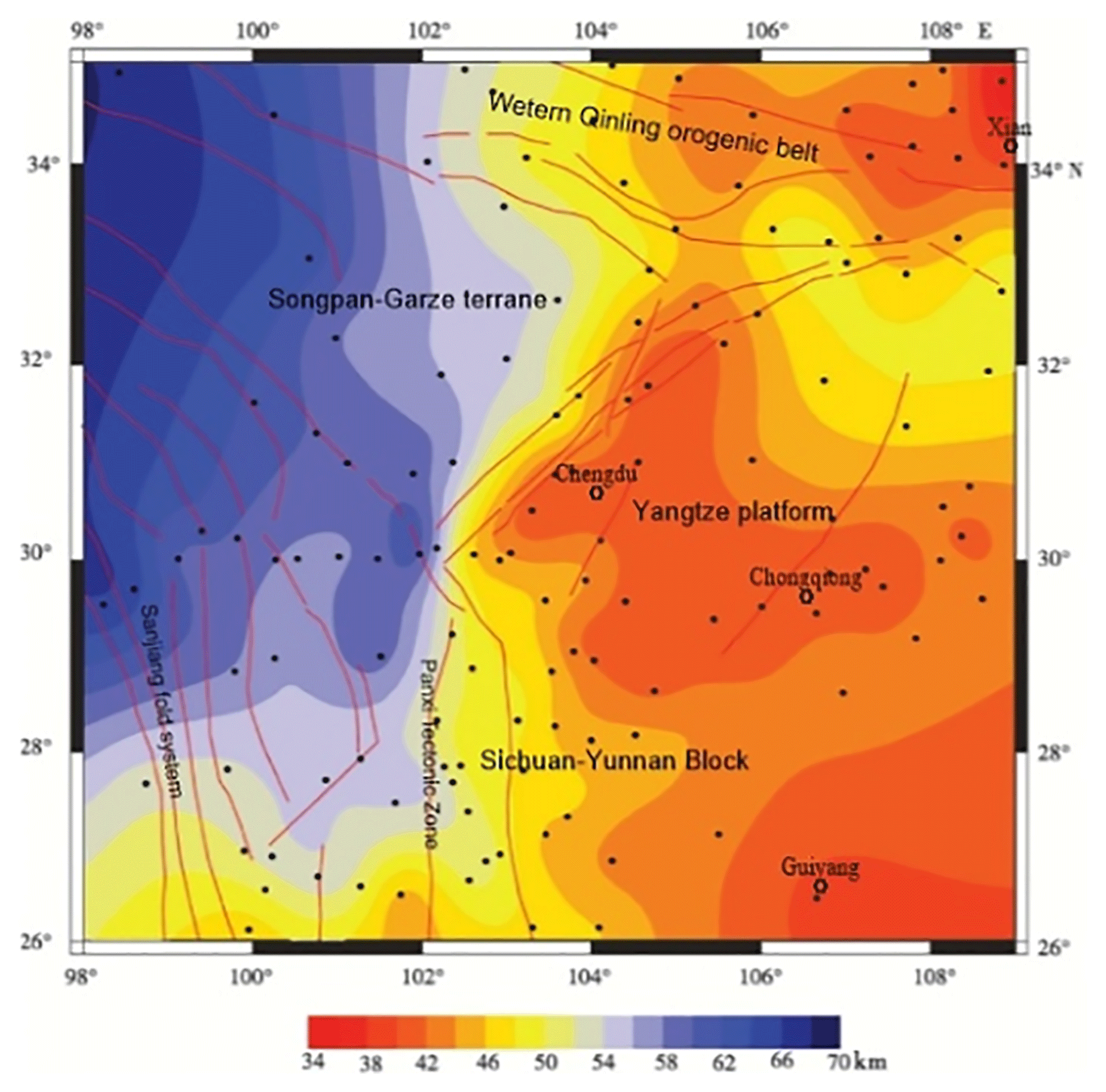
Figure 11Contour map of crustal thickness estimated by h–k stacking analysis based on the receiver function (C. Y. Wang et al., 2010). Small black solid circles indicate the seismic station used by C. Y. Wang et al. (2010).
Our result reveals similar details to C. Y. Wang et al. (2010): the crustal thickness of the eastern Tibetan Plateau is complex and varies greatly. The average crust thickness is about above 60 km, especially about 70–75 km at the Qiangtang block, under which there is a northward-dipping Moho gradient zone. There is a relatively shallow crust at the Songpa–Ganzi block and is characteristic of a decrease in northwest–southeast orientation. Our model still shows some changes in the thickness of the crust in this area. For example, the thickness of the crust around Chengdu is relatively thin, especially in the north-eastern part of Chengdu, about 50 km thick under the Qinlin–Dabei fold belt, and the thickness of the crust in the north-east to the Sichuan basin is about 45–48 km. In addition, crustal thickness around Xi'an and the Ordos basin is about 35 km. By contrast, a change in the crustal thickness in the Sichuan–Yunnan block varies greatly, with a thickness of about 60 km in the north-west and about 35 km in the south-east. From a geological viewpoint, eastern Tibet and the western Yangtze craton have a very complex structure and tectonics, where several tectonic blocks, including the Yangtze Platform, the Songpan–Ganzi Fold System, the Qiangtang block, and the Indochina block, interact with each other. It is a site of important processes associated with the India–Asia collision and abutment against the stable Yangtze Platform, including strong compressional deformation with crust shortening and thickening; the plateau surface has been elevated to 4–5 km, and the Tibetan crust has doubled in thickness since the collision (Chen and Wilson, 1996; Flesch et al., 2005; Z. Wang et al., 2010). East–west crustal extension and strong earthquakes often occur on the active faults inside and on the edge of the plateau and are the most active seismic areas within the mainland. Based on the analysis of the distribution of the epicentres during 1970–2015, the results show that a large earthquake occurred in the brittle upper crust of the Longmenshan fault zone in Sichuan and Yunnan, and the crustal thickness changed sharply by about 10 km. The Ms 8.0 Wenchuan earthquake in 2008 and the Ms 7.0 Lushan earthquake in 2013 were caused by the reactions associated with the Songpan–Ganzi Fold System and the Qiangtang block obliquely colliding with the Yangtze Platform. The reason may be that main fault cut off the Moho discontinuity where materials exchange between crust and mantle, and accumulated press triggers a series of earthquakes frequently.
Making use of an sSAE deep learning network, we present a crustal thickness map of eastern Tibet and the western Yangtze craton (Fig. 7). The data sets consist of phase velocities of Rayleigh waves from Xie et al. (2013) at discrete frequencies of 10.0, 12.5, 15.0, 17.5, 20.0, 22.5, 25.0, 27.5, 30.0, 32.5, and 35.0 mHz. We conclude the following.
-
Neural network structure is essential for inversion results, determined by the following parameters: the number of hidden layers, the number of neurons per layer, number of epoch, batch size, type of activation function, learning rate, and non-sparsity penalty. We find that the number of parameters in hidden layers and the size of a batch are crucial for training neural networks. After many tests, the number of hidden layers was set to 6; the number of neurons was 200, 100, 50, 20, 10, and 5. The number of periods and the batch size were both set to 100, the activation function was sigmoid, and the learning rate was 1; higher resolution and a more reliable crustal thickness model were attained.
-
By training the deep network with six hidden layers and the traditional shallow network with only one hidden layer, the relative error between the phase velocity predicted by the deep network and the observed average phase velocity is smaller than that between the phase velocity predicted by the traditional shallow network and observed average phase velocity, indicating that the inversion result based on the deep network is more reliable than that of the traditional shallow network.
-
Using only one processor, a six-layer sSAE network for 380 000 training samples and 120 000 test samples for network training takes 5 h, while a well-trained neural network inversion takes only a few seconds to complete. To complete the same inversion task, it takes 3 weeks to use the Monte Carlo method for four processors. We demonstrate that sSAE deep network inversion is more efficient than Monte Carlo inversion.
-
Comparing our model with current knowledge about crustal structure as represented by ZJS, CRUST2.0, and CUB2, the overall agreement with these three models is very good, and agreement is generally better with CUB2 and CRUST2.0, which are attained from relatively dense stations with rich data coverage and higher resolution. Our result reveals more details in Chengdu, the Qinling–Dabei fold belt, the Xi'an and Ordos basins, and the Sichuan–Yunnan block.
Data and results of calculations are available by e-mail request.
XC carried out the main investigation and formal analyses of this work and wrote the initial draft. QL put forward the inversion method and designed the structure of the neural network. PL performed the realizing inversion. YL revised the written work and contributed to the final text.
The authors declare that they have no conflict of interest.
Our work was supported by the National Natural Science Foundation of China (grant nos. 41774095 and 91755215). The authors are grateful to Xie Jiayi for providing the phase velocity maps, Shapiro Nikolai for making model CUB2 available, Gabi Laske for making model CRUST1.0 available, and Zhu Jieshou for making model ZJS available.
This paper was edited by Richard Gloaguen and reviewed by Harry Matchette-Downes and three anonymous referees.
Bassin, C., Laske, G., and Masters, G.: The current limits of resolution for surface wave tomography in north America, EOS T. Am. Geophys. Un., 81, F897, 2000.
Bengio, Y.: Learning deep architectures for AI, Foundations and trends in Machine Learning, 2, 1–127, 2009.
Bengio, Y., Lamblin, P., Popovici, D., and Larochelle, H.: Greedy layer-wise training of deep networks, in: Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 153–160, 2006.
Bishop, C. M.: Neural Networks for Pattern Recognition, Oxford University Press, Oxford, UK, 1995.
Chen, S. and Wilson, C. J. L.: Emplacement of the Longmen Shan Thrust – Nappe Belt along the eastern margin of the Tibetan Plateau, J. Struct. Geol., 18, 413–430, 1996.
Chen, Y., Niu, F., and Liu, R.: Crustal structure beneath China from receiver function analysis, J. Geophys. Res., 115, B03307, https://doi.org/10.1029/2009JB006386, 2010.
Das, T. and Nolet, G.: Crustal thickness estimation using high frequency Rayleigh waves, Geophys. Res. Lett., 123, 169–184, 2001.
de Wit, R. W., Valentine, A. P., and Trampert, J.: Bayesian inference of Earth's radial seismic structure from body-wave travel times using neural networks, Geophys. J. Int., 195, 408–422, 2013.
de Wit, R. W. L., Käufl, P. J., Valentine, A. P., and Trampert, J.: Bayesian inversion of free oscillations for Earth's radial (an)elastic structure, Phys. Earth Planet. In., 237, 1–17, https://doi.org/10.1016/j.pepi.2014.09.004, 2014.
Deng, J., Zhang, Z., Marchi, E., and Schuller, B: Sparse Autoencoder-Based Feature Transfer Learning for Speech Emotion Recognition, in: Proceedings of the 5th Biannu Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 511–516, 2013.
Devilee, R., Curtis, A., and Roy-Chowdhury, K.: An efficient, probabilistic neural network approach to solving inverse problems: inverting surface wave velocities for Eurasian crustal thickness, J. Geophys. Res., 104, 28841–28857, 1999.
Dziewonski, A. M. and Anderson, D. L.: Preliminary reference Earth model, Phys. Earth Planet. In., 25, 297–356, 1981.
Fang, J.: Global crustal and lithosphere thickness inverted by using satellite gravity data, Crustal deformation and Earthquake, 19, 26–31, 1999 (in Chinese).
Flesch, L. M., Holt, W. E., Silver, P. G., Stephenson, M., Wang, C. Y., and Chan, W. W.: Constraining the extent of crust – mantle coupling in central Asia using GPS, geologic, and shear wave splitting data, Earth Planet. Sc. Lett., 238, 248–268, 2005.
Grad, M. and Tiira, T.: The moho depth map of the European Plate, Geophys. J. Int., 176, 279–292, 2009.
Guo, L. H., Meng, X. H., Shi, L., and Chen, Z. X.: Preferential filtering method and its application to Bouguer gravity anomaly of Chinese continent, Chinese J. Geophys., 55, 4078–4088, 2012 (in Chinese).
Hansen, T. M., Cordua, K. S., Looms, M. C., and Mosegaard, K.: SIPPI: A Matlab toolbox for sampling the solution to inverse problems with complex prior information: Part 1 – Methodology, Comput. Geosci., 52, 470–480, 2013.
Hinton, G. E. and Salakhutdinov, R. R.: Reducing the dimensionality of data with neural networks, Science, 313, 504–507, 2006.
Huang, J. P., Fu, R. S., Xu, P. ,Huang, J. H., and Zheng, Y.: Inversion of gravity and topography data for the crust thickness of China and its adjacency, Acta Seismologica Sinica, 28, 250–258, 2006.
Lampinen, J. and Vehtari, A.: Bayesian approach for neural networks-review and case studies, Neural Networks, 14, 257–274,2001.
Laske, G., Masters, G., Ma, Z., and Pasyanos, M.: Update on CRUST1.0 – A 1-degree Global Model of Earth's Crust, Geophys. Res. Abstracts, 15, Abstract EGU2013-2658, 2013.
Lebedev, S., Adam, J. M. C., and Meier, T.: Mapping the moho with seismic surface waves: a review, resolution analysis, and recommended inversion strategies, Tectonophysics, 609, 377–394, 2013.
LeCun, Y., Bengio, Y., and Hinton, G. E.: Deep Learning, Nature, 521, 436–444, 2015.
Legendre, C. P., Deschamps, F., Zhao, L., and Chen, Q. F.: Rayleigh-wave dispersion reveals crust-mantle decoupling beneath eastern Tibet, Scientific reports, 2015.
Liu, Q., Hu, X., Ye, M., Cheng, X., and Li, F.: Gas Recognition under Sensor Drift by Using Deep Learning, Int. J. Intell. Syst., 30, 907–922, https://doi.org/10.1002/int.21731, 2015.
Masters, G., Barmine, M. P., and Kientz, S.: Pasadena: Calif. Inst. of Technol., Mineos User's Manual, Computational Infrastructure for Geodynamics, 2014.
Montagner, J.-P. and Jobert, N.: Vectorial tomography–ii. Application to the indian ocean, Geophys. J. Int., 94, 309–344, 1988.
Meier, U., Curtis, A., and Trampert, J.: Global crustal thickness from neural network inversion of surface wave data, Geophys. J. Int., 169, 706–722, 2007.
Qian, H., Mechie, J., Li, H., Xue, G., Su, H., and Cui, X.: Structure of the crust and mantle down to 700 km depth beneath the Longmenshan from P receiver functions, Tectonics, 37, 1688–1708, 2018.
Shapiro, N. M. and Ritzwoller, M. H.: Monte-Carlo inversion for a global shear-velocity model of the crust and upper mantle, Geophys. J. Int., 151, 88–105, 2002.
Stolk, W., Kaban, M., Beekman, F., Tesauro, M., Mooney, W. D., and Cloetingh, S.: High resolution regional crustal models from irregularly distributed data: application to Asia and adjacent areas, Tectonophysics, 602, 55–68, 2013.
Sun, X., Song, X., Zheng, S., Yang, Y., and Ritzwoller, M.: Three dimensional shear wave velocity structure of the crust and upper mantle beneath China from ambient noise surface wave tomography, Earthquake Sci., 23, 449–463, 2010.
van der Baan, M. and Jutten, C.: Neural networks in geophysical applications, Geophysics, 65, 1032–1047, 2000.
Wang, C. Y., Lou, H., Yao, Z. X., Luo, X. H., and Li, Z. Y.: Crustal thicknesses and poisson's ratios in Longmen shan mountains and adjacent regions, Quaternary Sciences, 30, 652–661, 2010 (in Chinese).
Wang, S. J., Wang, F. Y., Zhang, J. S., Liu, B. F., Zhang, C. K., Zhao, J. R., Duan, Y. L., Song, X. H., and Deng, X. G.: A study of deep seismogenic environment in Lushan Ms7.0 earthquake zone by wide-angle seismic reflection/refraction profile, Chinese J. Geophys., 58, 474–485, 2015.
Wang, Z., Zhao, D., and Wang, J.: Deep structure and seismogenesis of the north – south seismic zone in southwest China, J. Geophys. Res.-Sol. Ea., 115, https://doi.org/10.1029/2010JB007797, 2010.
Xie, J., Ritzwoller, M. H., Shen, W., Yang, Y., Zheng, Y., and Zhou, L.: Crustal radial anisotropy across Eastern Tibet and the Western Yangtze Craton, J. Geophys. Res., 118, 4226–4252, https://doi.org/10.1002/jgrb.50296, 2013.
Xu, L., Rondenay, S., and Van Der Hilst, R. D.: Structure of the Crust beneath the southeastern Tibetan Plateau from teleseismic Receiver Functions, Phys. Earth Planet. In., 165, 176–193, 2007.
Xu, X., Keller, G. R., Gao, R., Guo, X., and Zhu, X. Uplift of the Longmen Shan area in the eastern Tibetan plateau: An integrated geophysical and geodynamic analysis, Int. Geol. Rev., 58, 14–31,2016.
Yi, G. X., Yao, H. J., Zhu, J. S., and Van, D. H. R. D.: Rayleigh-wave phase velocity distribution in China continent and its adjacent regions, Chinese J. Geophys. 51, 265–274, 2008.
Yao, H., Van Der Hilst, R. D., and De Hoop, M. V.: Surface-wave array tomography in SE Tibet from ambient seismic noise and two-station analysis–I. Phase-velocity maps, Geophys. J. Int., 166, 732–744, 2006.
Zeng, R. S., Sun, W. G., Mao, T. E., and Zhong, Y. L.: The depth of Moho in the mainland of China, Acta Seismologica Sinica, 17, 322–327, 1995 (in Chinese).
Zhang, Q., Sandvol, E., Ni, J., Yang, Y., and Chen, Y. J.: Rayleigh wave tomography of the northeastern margin of the Tibetan Plateau, Earth Planet. Sc. Lett., 304, 103–112, 2011.
Zheng, S., Sun, X., Song, X., Yang, Y., and Ritzwoller, M. H.: Surface wave tomography of China from ambient seismic noise correlation, Geochem. Geophy. Geosys., 9, Q05020, https://doi.org/10.1029/2008GC001981, 2008.
Zhou, L., Xie, J., Shen, W., Zheng, Y., Yang, Y., Shi, H., and Ritzwoller, M. H.: The structure of the crust and uppermost mantle beneath South China from ambient noise and earthquake tomography, Geophys. J. Int., 189, 1565–1583, 2012.
Zhou, Y., Nolet, G., Dahlen, F., and Laske, G.: Global upper-mantle structure from finite-frequency surface-wave tomography, J. Geophys. Res., 111, B04304, https://doi.org/10.1029/2005JB003677, 2006.
Zhu, J. S., Zhao, J. M., Jiang, X. T., Fan, J., and Liang, C. T.: Crustal flow beneath the eastern margin of the Tibetan plateau, Earthquake Science, 25, 469–483, 2012.