the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 05 Mar 2018
| 05 Mar 2018
A general theory on frequency and time–frequency analysis of irregularly sampled time series based on projection methods – Part 1: Frequency analysis
Guillaume Lenoir
Michel Crucifix
We develop a general framework for the frequency analysis of irregularly sampled time series. It is based on the Lomb–Scargle periodogram, but extended to algebraic operators accounting for the presence of a polynomial trend in the model for the data, in addition to a periodic component and a background noise. Special care is devoted to the correlation between the trend and the periodic component. This new periodogram is then cast into the Welch overlapping segment averaging (WOSA) method in order to reduce its variance. We also design a test of significance for the WOSA periodogram, against the background noise. The model for the background noise is a stationary Gaussian continuous autoregressive-moving-average (CARMA) process, more general than the classical Gaussian white or red noise processes. CARMA parameters are estimated following a Bayesian framework. We provide algorithms that compute the confidence levels for the WOSA periodogram and fully take into account the uncertainty in the CARMA noise parameters. Alternatively, a theory using point estimates of CARMA parameters provides analytical confidence levels for the WOSA periodogram, which are more accurate than Markov chain Monte Carlo (MCMC) confidence levels and, below some threshold for the number of data points, less costly in computing time. We then estimate the amplitude of the periodic component with least-squares methods, and derive an approximate proportionality between the squared amplitude and the periodogram. This proportionality leads to a new extension for the periodogram: the weighted WOSA periodogram, which we recommend for most frequency analyses with irregularly sampled data. The estimated signal amplitude also permits filtering in a frequency band. Our results generalise and unify methods developed in the fields of geosciences, engineering, astronomy and astrophysics. They also constitute the starting point for an extension to the continuous wavelet transform developed in a companion article (Lenoir and Crucifix, 2018). All the methods presented in this paper are available to the reader in the Python package WAVEPAL.
- Article
(6838 KB) - Full-text XML
- Companion paper
-
Supplement
(77589 KB) - BibTeX
- EndNote





In many areas of geophysics, one has to deal with irregularly sampled time series. However, most state-of-the-art tools for the frequency analysis are designed to work with regularly sampled data. Classical methods include the discrete Fourier transform (DFT), jointly with the Welch overlapping segment averaging (WOSA) method, developed by Welch (1967), or the multitaper method, designed in Thomson (1982) and Riedel and Sidorenko (1995). Given the excellent results they provide, it is tempting to interpolate the data and simply apply these techniques. Unfortunately, interpolation may seriously affect the analysis with unpredictable consequences for the scientific interpretation (Mudelsee, 2010, p. 224).
In order to deal with non-interpolated astronomical data, Lomb (1976) and Scargle (1982) proposed what is now known as the Lomb–Scargle periodogram (denoted here LS periodogram). The LS periodogram is at the basis of many algorithms proposed in the literature, in particular in astronomy, e.g. in Mortier et al. (2015), Vio et al. (2010), or Zechmeister and Kürster (2009), and in geophysics, e.g. in Schulz and Stattegger (1997), Schulz and Mudelsee (2002), Mudelsee et al. (2009), Pardo Igúzquiza and Rodríguez Tovar (2012), or Rehfeld et al. (2011). More specifically, in climate and paleoclimate, the time series are often very noisy, exhibit a trend, and potentially carry a wide range of periodic components (see e.g. Fig. 6). Considering all these properties, we design in this work an operator for the frequency analysis generalising the LS periodogram. The latter was built to analyse data which can be modelled as a periodic component plus noise. Since the periodic component may not necessarily oscillate around zero, Ferraz-Mello (1981) and Heck et al. (1985) extended the LS periodogram, proposing an operator that is suitable to analyse data which can be modelled as a periodic component plus a constant trend plus noise. Their operator is designed to take into account the correlation between the constant trend and the periodic component, and is now a classic tool for analysing astronomical irregularly spaced time series. In climate and paleoclimate, the periodic component may oscillate around a more complex trend than just a constant. This is why, in this work, we extend the previous result by proposing an operator that is suitable to analyse data which can be modelled as a periodic component plus a polynomial trend plus noise. Our operator is also designed to take into account the correlation between the trend and the periodic component. Our extended LS periodogram is, however, not sufficient to deal with very noisy data sets, and it also exhibits spectral leakage, like the DFT. In the world of regularly sampled and very noisy time series, smoothing techniques can be applied to reduce the variance of the periodogram, after tapering the time series in order to alleviate spectral leakage (see Harris, 1978). One of them is the WOSA method (Welch, 1967), which consists of segmenting the time series into overlapping segments, tapering them, taking the periodogram on each segment, and finally taking the average of all the periodograms. This technique was transferred to the world of irregularly sampled time series in the work of Schulz and Stattegger (1997), where they apply the classical LS periodogram to each tapered segment, and take the average. In this article, we generalise their work by applying the tapered WOSA method to our extended LS periodogram. Moreover, we show that it is preferable to weight the periodogram of each WOSA segment before taking the average in order to get a reliable representation of the squared amplitude of the periodic component. This leads us to define the weighted WOSA periodogram, which we recommend for most frequency analyses.
The periodogram is often accompanied by a test of significance for the spectral peaks, which relies on the choice of an additive background noise. Two traditional background noises are used in practice. The first one is the Gaussian white noise, which has a flat power spectral density, and which is a common choice with astronomical data sets, e.g. in Scargle (1982) or Heck et al. (1985). The second one is the Gaussian red noise or Ornstein–Uhlenbeck process, for which the power spectral density is a Lorentzian function centred at frequency zero, and which is a common choice with (palaeo-)climate time series, e.g. those in Schulz and Mudelsee (2002) or Ghil et al. (2002). Arguments in favour of a Gaussian red noise as the background stochastic process for climate time series are given in Hasselmann's influential paper (Hasselmann, 1976). Other background noises are also found in geophysics, often under the form of an autoregressive-moving-average (ARMA) process (see Mudelsee, 2010, p. 60, for an extensive list). In this work, we consider a general class of background noises, which are the continuous autoregressive-moving-average (CARMA) processes, defined in Sect. 3.2. A CARMA(p,q) process is the extension of an ARMA(p,q) process to a continuous time (Brockwell and Davis, 2016, Sect. 11.5). Gaussian white noise and Gaussian red noise are particular cases of a Gaussian CARMA process, i.e. they are a CARMA(0,0) process and a CARMA(1,0) process, respectively. Recent advances now allow for accurate estimation of the parameters of an irregularly sampled CARMA process from one of its samples (see Kelly et al., 2014).
Estimating the percentiles of the distribution of the weighted WOSA periodogram of an irregularly sampled CARMA process is the core of this paper. This gives the confidence levels for performing tests of significance at every frequency, i.e. test if the null hypothesis – the time series is a purely stochastic CARMA process – can be rejected (with some percentage of confidence) or not. We aim at developing a very general approach. Let us enumerate some key points.
-
Estimation of CARMA parameters is performed in a Bayesian framework and relies on state-of-the-art algorithms provided by Kelly et al. (2014). In the special case of a white noise, we provide an analytical solution.
-
Based on 1, we provide confidence levels computed with Markov chain Monte Carlo (MCMC) methods, that fully take into account the uncertainty of the parameters of the CARMA process, because we work with a distribution of values for the CARMA parameters instead of a unique set of values.
-
Alternatively to 2, if we opt for the traditional choice of a unique set of values for the parameters of the CARMA background noise, we develop a theory providing analytical confidence levels. Compared to a MCMC-based approach, the analytical method is more accurate and, if the number of data points is not too high, quicker to compute, especially at high confidence levels, e.g. 99 or 99.9 %. Computing high levels of confidence is required in some studies, for example in paleoceanography (Kemp, 2016).
-
Confidence levels are provided for any possible choice of the overlapping factor for the WOSA method, extending the traditional 50 % overlapping choice (Schulz and Stattegger, 1997; Schulz and Mudelsee, 2002).
-
Under the case of a white noise background, without WOSA segmentation and without tapering, we define the F periodogram as an alternative to the periodogram. It has the advantage of not requiring any parameter to be estimated.
Finally, we note that spectral power and estimated squared amplitude are no longer the same thing if the time series is irregularly sampled. Both quantities may be of physical interest. We estimate the amplitude of the periodic component with least-squares methods, and derive an approximate proportionality between the squared amplitude and the periodogram, from which we deduce the weights for the weighted WOSA periodogram. The estimated signal amplitude also gives access to filtering in a frequency band.
The paper is organised as follows. In Sect. 2, we introduce the notations and recall some basics of algebra. In Sect. 3, we define the model for the data and write the background noise term into a suitable mathematical form. Section 4 starts with some reminders about the Lomb–Scargle periodogram and then extends it to take into account the trend, and a second extension deals with the WOSA tapered case. In Sect. 5, we remind the reader that significance testing is nothing but a statistical hypothesis testing. Under the null hypothesis, we estimate the parameters of the CARMA process and estimate the distribution of the WOSA periodogram, either with Monte Carlo methods or analytically. In the case of a white noise background, we define the F periodogram as an alternative to the periodogram. Section 6 aims at computing the amplitude of the periodic component of the signal, and the difference between the squared amplitude and the periodogram is explained. Sections 7 and 8 are based on the results of Sect. 6. There, we propose a third extension for the LS periodogram and show how to perform filtering. Section 9 presents an example of analysis on a palaeoceanographic time series. Finally, a Python package named WAVEPAL is available to the reader and is presented in Sect. 10.
2.1 Notations
Let us introduce the notations for the time series. The measurements are done at the times respectively, and we assume there is no error in the measurements or in the times. They are cast into vectors belonging to ℝN:
We use here the bra–ket notation, which is common in physics. In ℝN, the transpose of |a〉 is 〈a|, i.e. , and in ℂN, 〈a| is the conjugate transpose of |a〉, i.e. . The inner product of |a〉 and |b〉 is 〈a|b〉.
-
Let A be a (m,n) matrix and B be a (n,m) matrix. If A is real, A′ denotes its transpose, and if A is complex, A∗ denotes its conjugate transpose. The trace of AB is denoted by tr(AB) and we have tr(AB)=tr(BA).
-
Let |Y〉 be a vector in ℝN and A be a (M,N) matrix. The notations A|Y〉 and |AY〉 refer to the same vector.
-
We use the terminology Gaussian white noise or simply white noise for a (multivariate) Gaussian random variable with constant mean and covariance matrix σ2I.
-
|Z〉 always denotes a standard multivariate Gaussian white noise, i.e.
where means “is equal in distribution” and I is the identity matrix.
-
A sequence of independent and identically distributed random variables is denoted by “iid”.
2.2 Orthogonal projections in ℝN
The orthogonal projection on a vector space spanned by the m linearly independent vectors |a1〉, ..., |am〉 in ℝN for some m∈ℕ0 (m≤N) is
where is the closed span of those m vectors, i.e. the set of all the linear combinations between them. V is a (N,m) matrix defined by
Like for any orthogonal projection, we have the following equalities:
The m linearly independent vectors |a1〉, ..., |am〉 may be orthonormalised by a Gram–Schmidt procedure, leading to m orthonormal vectors |b1〉, ..., |bm〉, and the orthogonal projection may then be rewritten as
Under that form, we see that the above projection has m eigenvalues equal to 1 and (N−m) eigenvalues equal to 0.
Let |c1〉, ..., |cq〉 be q linearly independent vectors in ℝN, with q≤m, and such that . Then is an orthogonal projection on , and
Moreover, for any vector , we have
We recommend the book of Brockwell and Davis (1991) for more details.
2.3 Quantifying the irregularity of the sampling
The biggest time step for which t1, ..., tN are a subsample of a regularly sampled time series is the greatest common divisor1 (GCD) of all the time steps of |t〉. In formulas,
where
and
where ℤ denotes the space of integer numbers. Quantifying the irregularity of the sampling is then straightforward. We define
This ratio is between 0 and 100 %, the latter value being reached with regularly sampled time series.
3.1 Definition
A suitable and general enough model to analyse the periodicity at frequency is
with Aω=Eωcos (ϕω), , and . The terms |cΩ〉 and |sΩ〉 are defined componentwise, i.e. and . We have added the subscript ω to differentiate between the probed frequency, ω, and the data frequency, Ω. Indeed, the periodogram (defined in Sect. 4), the amplitude periodogram (Sect. 6) and the weighted WOSA periodogram (Sect. 7) do not necessarily probe the signal at its true frequency Ω.
3.2 The background noise
3.2.1 Definition of a CARMA process
We follow here the definitions and conventions of Kelly et al. (2014), and technical details can be found in Brockwell and Davis (2016, Sect. 11.5).
The background noise term, |Noise〉, considered in this paper is a zero-mean stationary Gaussian CARMA process sampled at the times of |t〉. As explained in the following, it generalises traditional background noises used in geophysics.
A CARMA(p,q) process is simply the extension of an ARMA(p,q) process to a continuous time2. A zero-mean CARMA(p,q) process y(t) is the solution of the following stochastic differential equation:
where ϵ(t) is a continuous-time white noise process with zero mean and variance σ2. It is defined from the standard Brownian motion B(t) through the following formula:
The parameters α0, ... , αp−1 are the autoregressive coefficients, and the parameters β1, ..., βq are the moving average coefficients; by definition. When p>0, the process is stationary only if q<p and the roots of
have negative real parts. Strictly speaking, the derivatives of the Brownian motion , k>0, do not exist, and we therefore interpret Eq. (14) as being equivalent to the following measurement and state equations:
and
where is a vector of length p, , and
Equation (18) is nothing else but an Itô differential equation for the state vector |w(t)〉.
In practice, only CARMA processes of low order are useful in our framework, typically, , (1,0), (2,0), (2,1), since at a higher order, they often exhibit dominant spectral peaks (see Kelly et al., 2014), which is not what we want as a model for the spectral background. Indeed, on the basis of our model, Eq. (13), it is desirable that the spectral peaks come from the deterministic cosine and sine components. We now consider two useful particular cases of a CARMA process before analysing the general case.
3.2.2 Gaussian white noise
When p=0 and q=0, the process reduces to a white noise, normally distributed with zero mean and variance σ2. The |Noise〉 term in Eq. (13) is then simply
with K=σI.
3.2.3 Gaussian red noise
When p=1 and q=0, the CARMA(1,0) or CAR(1) process is an Ornstein–Uhlenbeck process or red noise (Uhlenbeck and Ornstein, 1930), which is quite of interest in geophysical and other applications (Mudelsee, 2010). Since we work with a discrete time series, it is necessary to find the solution of Eq. (14) at t1, ..., tN. This is done by integrating that equation between consecutive times, i.e. from ti−1 to ti . The components of the |Noise〉 vector are then as follows:
where
See Robinson (1977) and Brockwell and Davis (2016, p. 343) for more details. The requirement on stationarity, Eq. (16), imposes α>0. The generated time series has a constant mean equal to zero and a constant variance equal to . The |Noise〉 term in Eq. (13) can also be written under a matrix form:
where K is a (N,N) lower triangular matrix whose elements are
where we define ρ1=0. This matrix form is used in Sect. 5.3.3.
Note that, if the time series is regularly sampled, ρ is a constant and Eq. (21) becomes the equation of a finite-length AR(1) process, which is stationary since α>0 implies ρ<1.
3.2.4 The general Gaussian CARMA noise
The solution of Eq. (14) at the time tn (), that we denote by yn, is
where |ηn〉 follows a multivariate normal distribution with zero mean and covariance matrix Cn given by
The above formula requires the computation of matrix exponentials and numerical integration. This can be avoided by diagonalising matrix A, with . D is a diagonal matrix with diagonal elements given by the roots of Eq. (16):
and U is a Vandermonde matrix, with
Now, by defining , we get
The matrix exponential has been transformed into , which is simply a diagonal matrix with elements . The covariance matrix of , that we write Σn, also takes a relatively simple form:
which is a Hermitian matrix, and where |κ〉 is the last column of U−1. The initial condition y1 is determined by imposing stationarity, which is fulfilled only if |w1〉 has a zero mean and a covariance matrix V whose elements are
Stationarity implies that the process y(t) has a zero mean and variance . All the above formulas and how to get them can be found in Kelly et al. (2014), Jones and Ackerson (1990) and Brockwell and Davis (2016, Sect. 11.5.2).
Generation of a CARMA(p,q) process can be performed with the Kalman filter since Eqs. (29b) and (29a) are nothing but the state and measurement equations, respectively (see Kelly et al., 2014, for more details). Alternatively, |y〉 can be written under a matrix form as in Eq. (23). Matrix formalism is useful in Sect. 5.3.3. Let us start with Eq. (29b):
The covariance matrix of |ηn〉, , is of course real symmetric and positive semi-definite. We thus have the following Schur decomposition:
where Qn is a real matrix. Consequently,
where |ϵ1〉, ..., |ϵn〉 are iid standard Gaussian white noises. The product of the Λ's can be simplified. Its diagonal elements are as follows:
As stated above, |w1〉 follows a multivariate normal distribution with zero mean and covariance matrix V. We can use again the Schur decomposition to write , where W is a real matrix, yielding
with and for i>1. The CARMA process at time tn is then given by
Finally, the |Noise〉 term in Eq. (13) is
where K is a real matrix and |Z〉 has a length N×p. Matrix K is triangular if p=1, which is the particular case treated in Sect. 3.2.3.
3.3 The trend
The model for the trend must be as general as possible and compatible with a formalism based on orthogonal projections (see Sect. 4). This is the reason we choose a polynomial trend of some degree m:
where |tk〉 is defined componentwise, i.e. . Whether or not to consider the presence of a trend in the model for the data is left to the user, given that we can always interpret a polynomial trend of low order as a very low-frequency oscillation.
4.1 Lomb–Scargle periodogram
Consider the orthogonal projection of the data |X〉 onto the vector space spanned by the vectors cosine and sine, defined by and . The periodogram at the frequency is defined as the squared norm of that projection:
When the time series is regularly sampled with a constant time step Δt, and if we only consider the Fourier angular frequencies, (k=0, ..., N−1), the periodogram defined above is equal to the squared modulus of the DFT of real signals.
Now, rescale |cω〉 and |sω〉 such that they are orthonormal. This can be done by defining
where βω is the solution of
The spanned vector space naturally remains unchanged (see Fig. 1). These formulas are nothing but the Lomb–Scargle formulas (Scargle, 1982, Eq. 10). The periodogram is now
Note that, for any signal ,
and this is equal to 1 if .
Some properties of the LS periodogram are presented in Appendix A. Here and for the rest of the article, the frequency is considered as a continuous variable.
4.2 Periodogram and mean
The LS periodogram applies well to data which can be modelled as
However, the periodic components may not necessarily oscillate around zero, and a better model is
where . Subtracting the average of the data is then often done before applying the LS periodogram. But that mere operation implicitly assumes that , which is not necessarily the case. In other words, the data average is not necessarily equal to μ, the process mean. Figure 2a illustrates that fact. Note that this discrepancy occurs in regularly sampled data as well, at non-Fourier frequencies, i.e. when NΔt is not a multiple of the probing period. See Fig. 2b.
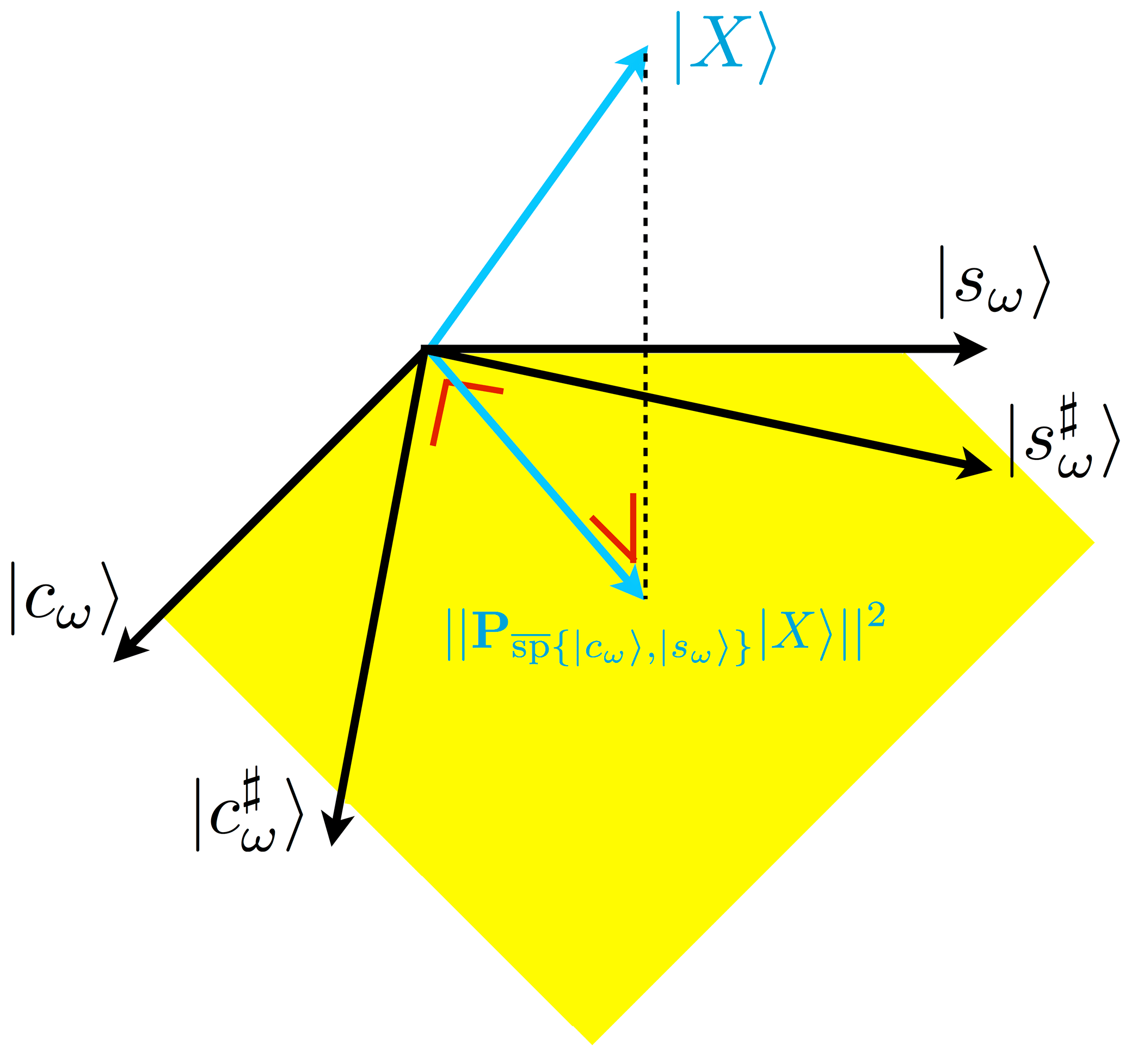
Figure 1Schematic view of the linear rescaling in ℝN leading to the Lomb–Scargle formulas. In yellow is drawn a subset of . A span is invariant under linear combinations of its vectors. The dashed line corresponds to the minimal Euclidean distance between the data |X〉 and .

Figure 2Signal average and sampling. (a) The continuous signal is in dashed blue and it is irregularly sampled at red dots. The continuous signal oscillates around 1 (blue line), which does not correspond to the average of the sampled signal (red line). (b) Same as panel (a) with a regularly sampled signal.
In order to deal with the mean in a suitable way, we define the periodogram as
Formula (47) is taken from Brockwell and Davis (1991), Ferraz-Mello (1981) or Heck et al. (1985); equivalence between them is shown in Appendix B. is also an orthogonal projection. A simple example will justify the principle. Consider the following purely deterministic mono-periodic signal with N data points:
with
and
The projection at ω is
We see that it is invariant with respect to μ, and we find back the signal minus its average. We thus have
where . This is a result similar to what we get with regularly sampled data and the DFT3.
Now, we do a Gram–Schmidt orthonormalisation like in Ferraz-Mello (1981) in order to simplify Formula (47). To this end, we define the three orthonormal vectors , |h1〉 and |h2〉 satisfying
Consequently,
and
Note that, for any signal , we have
and this is equal to 1 for a signal given by .
4.3 Periodogram and a polynomial trend
If we want to work with the full model, Eq. (13), which has a polynomial trend of degree m, we can naturally extend the result of Sect. 4.2 and work with
where and are determined from a Gram–Schmidt orthonormalisation starting with the orthonormalisation of |t0〉, ..., |tm〉.
It may happen that, for large m, the correlation matrix in the formula of orthogonal projection is singular. In that case, two options, less optimal, are possible: reduce the degree m, or perform the detrending before the spectral analysis, for example with a moving average.
Similarly to Sect. 4.2, we have, for any signal ,
and this is equal to 1 for a signal given by . Finally, we have a result similar to Eq. (51), in the sense that the projection given in Eq. (57) is invariant with respect to the parameters of the trend (but it naturally depends on the choice of the degree m).
4.4 Tapering the periodogram
A finite-length signal can be seen as an infinite-length signal multiplied by a rectangular window. This implies, among other things, that a mono-periodic signal will have a periodogram characterised by a peak of finite width, possibly with large side lobes, instead of a Dirac delta function. This is called spectral leakage.
The phenomenon has been deeply studied in the case of regularly sampled data. Leakage may be controlled by choosing alternatives to the default rectangular window. This is called windowing or tapering (see Harris, 1978, for an extensive list of windows). They all share the property of vanishing at the borders of the time series.
In the case of irregularly sampled data, building windows for controlling the leakage is a much more challenging task. Even with the default rectangular window, leakage is very irregular and is data and frequency dependent, due to the long-range correlations in frequency between the vectors on which we do the projection. To our knowledge, no general and stable solution for that issue is available in the literature. We thus recommend using the default rectangular window, i.e. do no tapering, if rt, defined in Eq. (12), is small, and use simple windows, like the sin 2 or the Gaussian window, for moderately irregularly sampled data (rt greater than 80 or 90 %). With tapering, Formula (57) becomes
where G is a frequency-independent diagonal matrix, which is used to weight the sine and cosine vectors. For example, with a sin 2 window, also called Hanning window, we have
4.5 Smoothing the periodogram with the WOSA method
4.5.1 The consistency problem
Besides spectral leakage, another issue with the periodogram is consistency. Indeed, for regularly sampled time series, the periodogram is known not to be a consistent estimator of the true spectrum as the number of data points tends to infinity (see Brockwell and Davis, 1991, chap. 10). Another view of the problem is that the periodogram remains very noisy regardless of the number of data points we have at our disposal. Smoothing procedures are therefore applied to reduce the variance of the periodogram. The drawback of any smoothing procedure is naturally a decrease of the frequency resolution. Among the smoothing methods available in the literature, two are traditionally used: multitaper methods (MTMs), developed by Thomson (1982) and Riedel and Sidorenko (1995), and the Welch overlapping segment averaging (WOSA) method (Welch, 1967). See Walden (2000) for a unified view.
Multitaper methods are certainly not generalisable to the case of irregularly sampled data, except in very specific cases that are not of interest in geophysics, like in Bronez (1988), which deals with band-limited signals, useful in the field of the telecommunications, or Fodor and Stark (2000), which considers regularly sampled time series with some gaps, useful for time series with a ratio rt, defined in Eq. (12), close to 100. We will then use the WOSA method applied to the LS periodogram, like in Schulz and Stattegger (1997) and Schulz and Mudelsee (2002), or to its relatives (Formulas 47, 57, or the most general 59).
4.5.2 Principle of the WOSA method
Trendless time series
The time series is divided into overlapping segments. The tapered LS periodogram is computed on every segment, and the WOSA periodogram is the average of all these tapered periodograms. This technique relies on the fact that the signal is stationary, as always in spectral analysis4. The length of the segments and the overlapping factor need to be chosen depending on how much we want to reduce the variance of the noise. As a general rule, shortening the segments will decrease the frequency resolution. Consequently, there is always a trade-off between the frequency resolution and the variance reduction.
For regularly sampled data, each segment of fixed length has the same number of data points. In the irregularly sampled case, it is not the case any more and we have two options.
-
Take segments with a fixed number of points and thus a variable length. In the non-tapered case, the periodogram on each segment provides deterministic peaks (coming from the deterministic sine–cosine components) with more or less the same height. But variable length segments will give deterministic peaks of variable width.
-
Take segments of fixed length but with a variable number of data points. The periodogram on each segment provides deterministic peaks with more or less the same width, except if there is a big gap at the beginning or at the end of the segment, such that its effective length is reduced. But they will have variable height since the number of data points is not constant.
We judge it is better to have peaks with similar width on each segment when averaging the periodograms in a frequency band. Consequently, we recommend the second option. An example of WOSA segmentation is shown in Fig. 8a.
Time series with a trend
The only difference with the previous case is that, for each segment, we consider the projection on |t0〉, ..., |tm〉 jointly with the tapered cosine and sine components. Formula (59) is applied to each segment with |Gcω〉 and |Gsω〉 localised on the WOSA segment, but |t0〉, ..., |tm〉 are taken on the full length of the time series, because the trend is the one of the whole time series.
4.5.3 The WOSA periodogram in formulas
Two parameters are required: the length of WOSA segments, D, and the overlapping factor, ; β=0 when there is no overlap. We denote by Q the number of WOSA segments, which is equal to
where ⌊⌋ is the floor function. Because of the rounding, D must be adjusted afterwards:
Define τq to be the starting time of the qth segment (). Note that τq is not necessarily equal to one of the components of |t〉. It follows that
The WOSA periodogram is then
Note that the sum of these orthogonal projections is no longer an orthogonal projection. and are the tapered cosine and sine on the qth segment. For example, with the Hanning (sin 2) window,
where
It may be shown that is invariant with the variable τq appearing in the cosine and sine terms, so that we can impose inside the cosine and sine terms.
In Formula (64), for each orthogonal projection, we apply a Gram–Schmidt orthonormalisation (similarly to Sect. 4.3):
where, for each q, and are orthonormal. We are now able to write the WOSA periodogram under a simple matrix form:
where
4.5.4 Practical considerations
First, note that the Gram–Schmidt orthonormalisation process requires at least m+3 data points. WOSA segments with less than m+3 points must therefore be ignored in the average of the periodograms.
Second, as we want to get deterministic peaks with more or less the same width on every segment, a WOSA segment is kept in the average if the data cover some percentage of its length D, namely,
where tq,1 and tq,2 are the times of the first and last data points inside in the qth segment, and C is the coverage factor. Its default value in WAVEPAL is 90 %.
Third, the frequency range on the qth segment is bounded by these two frequencies:
The maximal period (1∕fmin) corresponds to the effective length on the segment. The maximal frequency in the case of regularly sampled data must be the Nyquist frequency, . For irregularly sampled data, different choices for are possible. As suggested in Appendix A, an option is , but this choice is insufficient to avoid pseudo-aliasing issues. Imagine for example a regularly sampled time series with 1000 data points and Δt=1. Add one point at the end with the last time step being 0.1. The resulting irregularly sampled time series will thus have ΔtGCD=0.1. If we take fmax=5, it is obvious that some kind of aliasing will occur between f=0.5 and fmax. This it what we call pseudo-aliasing. A much better choice in this case is of course fmax=0.5. Section 5 of Bretthorst (1999) provides further discussions on this topic.
In practice,
where
and Hq is a diagonal matrix with
appears to work well. More justification and an example are provided in Part 2 of this study (Lenoir and Crucifix, 2018, Sect. 3.8), where it is shown that such a formula can handle aliasing issues in the case of time series with large gaps. Matrix Hq is similar to matrix Gq, defined in Sect. 4.4, but with elements taken at instead of tk. Quantity is equal to the maximum between the average time step and the average central time step if there is no tapering () and is equal to Δt in the regularly sampled case. These restrictions on the frequency bounds imply that the total number of WOSA segments, Q, in Formula (64), is not the same for all the frequencies. This is illustrated in Fig. 8b.
Fourth, in order to have a reliable average of the periodograms, we only represent the periodogram at the frequencies for which the number of WOSA segments is above some threshold. In WAVEPAL, default value for the threshold at frequency f is
where Q(f) is the number of WOSA segments at frequency f. It means that frequency f belongs to the range of frequencies of the WOSA periodogram if Q(f) is greater than or equal to the threshold.
5.1 Hypothesis testing
Significance testing allows us to test for the presence of periodic components in the signal. It is mathematically expressed as a hypothesis testing (see Brockwell and Davis, 1991, chap. 10). Taking our model, Eq. (13), the null hypothesis is
Therefore, . The alternative hypothesis is
The decision of accepting or rejecting the null hypothesis is based on the periodogram evaluated at ω, whose general formula is given in Eq. (64). The test is performed independently for each frequency (pointwise testing). Concretely, for each frequency, we compute the distribution of the periodogram under the null hypothesis, and then see if the data periodogram at that frequency is above or below a given percentile (e.g. the 95th) of that distribution. The percentile is called level of confidence. If the data periodogram is above the Xth percentile of the reference distribution, we reject the null hypothesis with X % of confidence. The level of significance is equal to (100−X) %, e.g. a 95 % confidence level is equivalent to a 5 % significance level. Hypothesis testing is, for this reason, often called significance testing. See Fig. 8c and 8d for an illustration on paleoclimate data. We recommend Priestley (1981, chap. 6) for more details on the methodology.
To perform significance testing, we thus need
5.2 Estimation of the parameters under the null hypothesis
5.2.1 Introduction
Under the null hypothesis, the signal is , and we thus need to estimate the parameters of the trend and those of the zero-mean CARMA process. The best statistical approach is to estimate them jointly, and marginalise over the parameters of the trend, since the periodogram is invariant with respect to these parameters, according to Sect. 4.3. But this would imply very involved computations that are way beyond the scope of this work. We are thus forced to a compromise and proceed as follows: data are detrended, , and then we estimate the parameters of the CARMA process, based on the model , where |Noise〉 is a zero-mean stationary Gaussian CARMA process sampled at the times of |t〉.
Estimation of CARMA parameters is done in a Bayesian framework. We analyse separately the case of the white noise, which is done analytically, and the case of CARMA(p,q) processes with p≥1, for which Markov chain Monte Carlo (MCMC) methods are required. Bayesian analysis provides a posterior distribution of the parameters based on priors.
5.2.2 Gaussian white noise
We want to estimate the two parameters of the white noise, the mean μ and the variance σ2. According to the Bayes theorem,
where Π is the probability density function (PDF) and D is the detrended data . Based on the PDF of a multivariate white noise, the likelihood function is
We take Jeffreys priors (Jeffreys, 1946) for μ and σ2:
Jeffreys priors are non-informative and invariant under reparametrisation. Note that Π(σ2) is log-uniform.
Since we do not actually need to estimate μ (see Sect. 4.3 and Formula 64), we marginalise over that variable,
with and . Rearranging terms gives
with , where is the (biased) variance of the detrended data5. With the variable change , we have
which is nothing but a gamma distribution:
Note that the mean of the distribution in Eq. (84) is equal to , which is the usual unbiased estimator of 1∕σ2. Finally, the PDF of σ2 is at its maximum at
This is obtained from the derivative of Eq. (82).
5.2.3 Gaussian CARMA(p,q) noise with p≥1
For other cases than the white noise, Kelly et al. (2014) provide robust algorithms to estimate the posterior distribution of the CARMA parameters and of the parameter μ of an irregularly sampled, purely stochastic, time series, which can be modelled as a CARMA process. Those algorithms are based on Bayesian inference and MCMC methods. In particular we recommend reading Sects. 3.3 and 3.6 of Kelly et al. (2014) for a discussion on the choice of the priors and for computational considerations, respectively. That paper is accompanied by a Python and C++ package called CARMA pack. Some outputs of CARMA pack are shown in Sect. 9.
5.3 Estimation of the distribution of the periodogram under the null hypothesis
5.3.1 Working with a trendless stochastic process
Under the null hypothesis, the signal is . The WOSA periodogram, Eq. (64), is invariant with respect to the parameters of the trend, so that we can pose γk=0 for all k and |X〉 reduces to a zero-mean CARMA process.
5.3.2 Monte Carlo approach
For each frequency, we need the distribution of the WOSA periodogram, Eq. (68), where |X〉 is now a CARMA process for which we know the distribution of its parameters, from Sect. 5.2. With Monte Carlo methods, we are thus able to estimate any percentile of the distribution of the periodogram. If |X〉 is a zero-mean white noise, |X〉 is sampled from a standard normal distribution multiplied by the square root of the variance, whose inverse is sampled from the gamma distribution (Eq. 84). If |X〉 is a CARMA(p,q) process with p≥1, |X〉 is generated with the Kalman filter (from the CARMA pack – see Sect. 5.2.3). An example of confidence levels is shown in Fig. 8d.
We are thus able to estimate confidence levels for the WOSA periodogram, taking into account the uncertainty in the parameters of the background noise.
5.3.3 Analytical approach
If we consider constant CARMA parameters, we show in this section that analytical confidence levels can be computed, even in the very tail of the distribution of the periodogram of the background noise. An example is given in Fig. 8c. The advantage of the analytical approach is twofold.
-
It provides confidence levels converging to the exact solution, as the number of conserved moments increases (see below). From a certain number of conserved moments, we can consider that convergence is numerically reached (see Fig. 9). Such an approach is particularly interesting for high confidence levels, as illustrated in Fig. 8c with the 99.9 % confidence level, for which a MCMC approach would require a huge number of samples to get a satisfactory accuracy.
-
As a consequence, for a given percentile, computing time is usually shorter with the analytical method than with the MCMC method. We note, however, that the MCMC approach generally needs less computing time when the number of data points becomes large, as shown in Appendix E.
First approximation
If the marginal posterior distribution of each CARMA parameter is unimodal, we take the parameter value at the maximum of its PDF (white noise case, see Eq. 85), or the median parameter6 (other cases). Note that multi-modality tends to appear more frequently for CARMA processes of high order. Working with a unique set of parameters allows us to find an analytical formula for the distribution of the WOSA periodogram. Considering the matrix forms of the CARMA noise (Eq. 20 or 38) and the WOSA periodogram (Eq. 68), we demonstrate the following theorem.
The WOSA periodogram, defined in Eq. (68), under the null hypothesis (76), is
where , K is the CARMA matrix defined in Eq. (20) or (38), and Q(ω) is the number of WOSA segments at ω.
, ..., are iid chi-square distributions with 1 degree of freedom, and λ1(ω), ..., λ2Q(ω)(ω) are the eigenvalues of and are non-negative. Matrix Mω is defined in Eq. (69).
Proof. Since the WOSA periodogram, Eq. (68), is invariant with respect to the parameters of the trend, we pose them as equal to zero and consider the zero-mean CARMA process
The periodogram is thus
with . Since |Z〉 is a standard multivariate normal distribution, we have
is a (2Q(ω),2Q(ω)) real symmetric positive semi-definite matrix. We can thus diagonalise it:
with D being a diagonal matrix with the 2Q(ω) non-negative eigenvalues of . We now have , and
where the distributions are iid.
The pseudo-spectrum is defined as the expected value of the
periodogram distribution:
The difference between the pseudo-spectrum and the traditional spectrum is explained in Appendix C.
If the background noise is white, we have K=σI and this implies that , such that the pseudo-spectrum is
and is thus flat. This is a well-known result of the LS periodogram (Scargle, 1982), generalised here to more evolved periodograms. Moreover, if there is no WOSA segmentation (), the periodogram is exactly chi-square distributed with 2 degrees of freedom:
which is also a generalisation of a well-known result of the LS periodogram (Scargle, 1982).
The variance of the distribution of the periodogram, Eq. (86), is equal to , where is the Frobenius norm. As expected, it decreases with Q, as illustrated in Fig. 3.
Going back to Eq. (86), it is well-known that a linear combination of (independent) χ2 distributions is not analytically solvable. Fortunately, excellent approximations are available in Provost et al. (2009), allowing Monte Carlo methods to be avoided.
Second approximation
We approximate the linear combination of independent chi-square distributions, conserving its first d moments. When d→∞, the approximation converges to the exact distribution. In practice, estimation of a percentile is already very good with a very few moments, as illustrated in Fig. 9. Let us proceed step by step by increasing the number of conserved moments. Define .
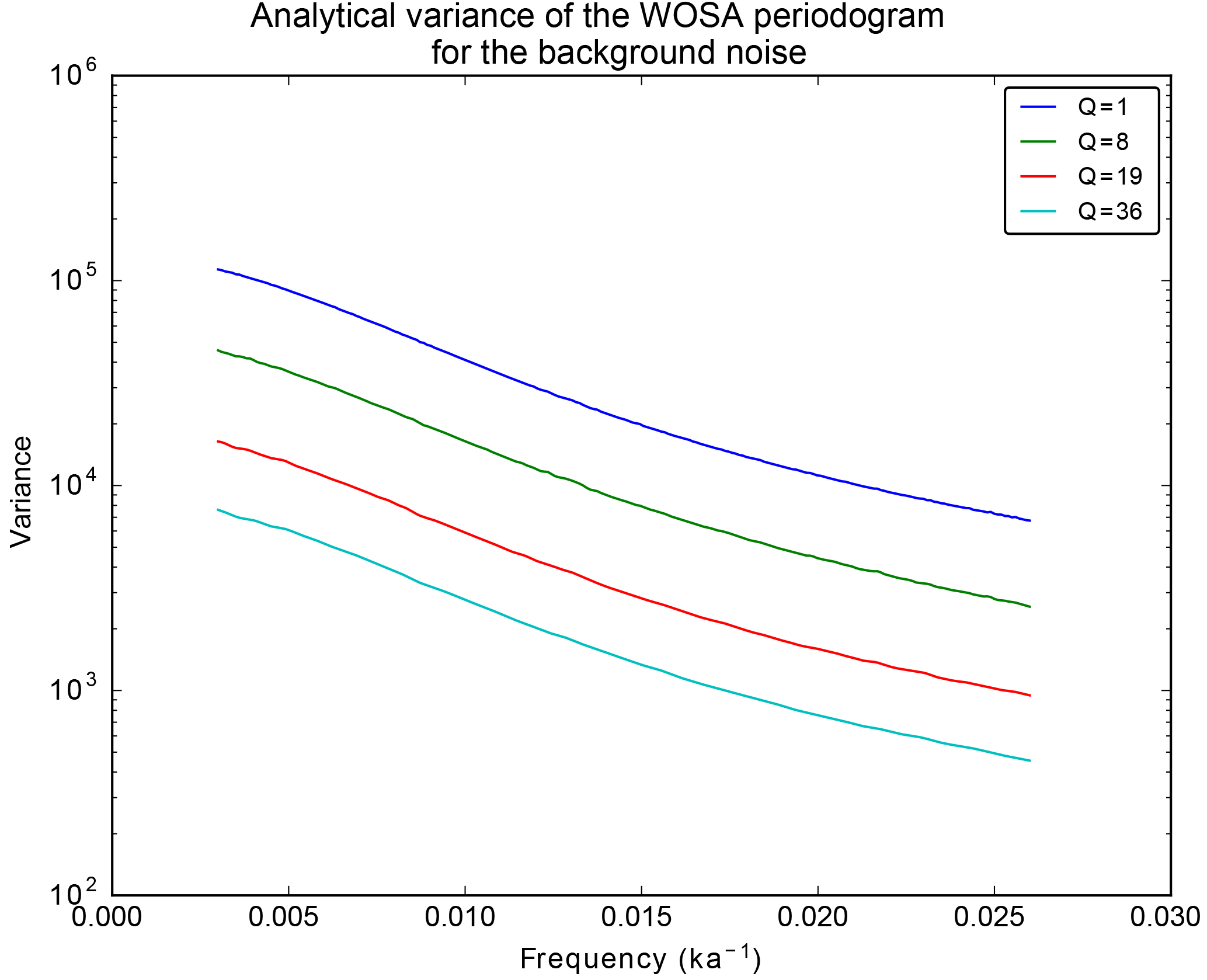
Figure 3Analytical variance of the WOSA periodogram for a Gaussian red noise with σ=2 and (see Sect. 3.2.3 for the definition of a red noise) for different values of Q. The frequency range is chosen such that, for each curve, Q(ω) is constant all along. The red noise is built on the irregularly sampled times of ODP1148 core (see Sect. 9).
1-moment approximation
We require the expected value of the process to be conserved, which is satisfied with the following approximation:
or, equivalently,
2-moment approximation
The approximate distribution of the linear combination of the chi-square distributions must have two parameters, and we conserve the expected value and variance. A chi-square distribution with M degrees of freedom provides a good fit:
Equating the expected values and variances gives
where and is the squared Frobenius norm of matrix A, i.e. the sum of its squared eigenvalues. Note that , where 2g is the scale parameter of the gamma distribution, which motivates the following d-moment approximation.
The d-moment approximation
We apply here the formulas presented in Provost et al. (2009). Let fX be the PDF of X. This distribution is approximated by the PDF of a dth degree gamma-polynomial distribution:
where the parameters α and β are estimated with the 2-moment approximation detailed above, and ξ0, ..., ξd are the solution of
Here, μ(1), ..., μ(d) are the exact first d moments of X and can be computed analytically by recurrence (see Eq. 5 of Provost et al., 2009), and η(h) is the hth moment of the gamma distribution, . The approximate cumulative distribution function (CDF) of X, evaluated at c0, is then
where γ(s,x) is the lower incomplete gamma function:
After all that chain of calculus, we reached our objective, that is, the estimation of a confidence level for the WOSA periodogram. It is given by the solution c0 of
for some p value p, e.g. p=0.95 for a 95 % confidence level.
The gamma-polynomial approximation can be extended to the generalised gamma-polynomial approximation. The latter is based on the generalised gamma distribution and is defined in Appendix D. It gives percentiles that usually converge faster than those given by the gamma-polynomial approximation. However, we observed that the generalised gamma-polynomial approximation is quite sensitive to the quality of the first guess for the three parameters of the generalised gamma distribution (see Appendix D). We thus recommend the use of the gamma-polynomial approximation as a first choice. Both options are available in WAVEPAL.
Finally, we mention that there exists an alternative expression to the above development, in terms of Laguerre polynomials (see Provost, 2005). It has the advantage of not requiring the matrix inversion in Eq. (100), the latter possibly being singular at large values of the degree d. However, we have not found any improvement on the stability or computing time using that approach.
5.4 The F periodogram for the white noise background
We have shown in Eq. (94) that the periodogram of a Gaussian white noise is exactly chi-square distributed if there is no WOSA segmentation. Significance testing against a white noise requires the estimation of the white noise variance after having detrended the data. Knowing that a F distribution is the ratio of independent chi-square distributions, it is possible to get rid of the detrending and variance estimation and deal with a well-known distribution, by working with
We call it the F periodogram. We already know that the numerator is invariant with respect to the parameters of the trend of the signal. It is clear that the denominator is invariant with respect to the parameters of the trend as well as with respect to the amplitudes of the periodic components (only the |Noise〉 term remains when applying it to Eq. 13). Moreover, that ratio is invariant with respect to the variance of the signal. Last but not least, the orthogonal projections in the numerator, , and in the denominator, , are done on spaces that are orthogonal to each other. Consequently, if we consider the null hypothesis (76) with a white noise, the numerator and the denominator follow independent chi-square distributions, and
where
and where is the Fisher–Snedecor distribution with parameters 2 and . In conclusion, the F periodogram can be an alternative to the periodogram when performing significance testing. It has the advantage of not requiring any parameter to be estimated and applies under the following conditions.
-
The background noise is assumed to be white.
-
There is no WOSA segmentation.
-
There is no tapering.
The F periodogram is available in WAVEPAL under the above requirements.
With a WOSA segmentation, projections at the numerator and at the denominator are not performed any more on orthogonal spaces, and this cannot therefore be applied.
The above results are a generalisation of formulas in Brockwell and Davis (1991) and Heck et al. (1985). See Appendix F for additional details.
6.1 Definition
Going back to Eq. (13), we now look for the amplitude at a given frequency . The estimation of is called the amplitude periodogram and is denoted by . We estimate Aω and Bω with a least-squares approach. We start with a trendless signal, and will show that the amplitude periodogram and the periodogram are approximately proportional.
6.2 Trendless signal
6.2.1 No tapering
The estimated amplitudes we look for, and , are the solution of
Since we look for the minimal distance, the solution is given by the orthogonal projection onto the vector space spanned by |cω〉 and |sω〉, namely
Let us develop this equation:
where
and we find the well-known expression for the solution of a least-squares problem:
Finally,
In the regularly sampled case, at the Fourier frequencies, the amplitude periodogram is proportional to the periodogram, with a factor 2∕N (or a factor 1∕N at ω=0 and ; the projection being done on the single cosine at those frequencies). It is no longer the case with irregularly sampled time series, and the proportionality is only approximate:
To prove the above formula, rewrite the model (Eq. 13) at Ω=ω:
where βω is defined in Eq. (42) and makes the phase-lagged sine and cosine orthogonal. Aω and Bω no longer have the same expressions as in Eq. (13), but we still have . We can rewrite Eq. (111) but this time with holding the above phase-lagged sine and cosine. We now make use of the approximation stated in Lomb (1976, p. 449):
Note that the sum of both is exactly equal to N. Equation (113) is then obtained, observing that . Basic trigonometry gives the following equalities for the relative error of the above approximations:
so that the two approximations of Eq. (115) reduce to only one:
The quality of this approximation is illustrated in Fig. 4.
6.2.2 With tapering
Like with the periodogram, leakage also appears in the amplitude periodogram. Consequently, it may be better to work with the projection on tapered cosine and sine if the data are not too irregularly sampled, as explained in Sect. 4.4. Consideration of the tapered case is also an important mathematical prerequisite for an extension to the continuous wavelet transform. This is developed in Part 2 of this study (Lenoir and Crucifix, 2018).
and are determined by projecting the data onto tapered cosine and sine:
Developing the equation gives
and
where is defined in Sect. 6.2.1 and G is defined in Sect. 4.4.

Figure 4Illustration of the quality of the approximations (a) Eq. (123a), (b) Eq. (123b) and (c) Eq. (126). In blue: no tapering (square taper); in green: sin 2 taper; in red: Gaussian taper. The approximation (117) is thus in blue in panel (a) or (b). Each panel represents the left-hand side of the equation, multiplied by 100, to express percentage. This indicates how small the numerator is compared to the denominator. The time vector |t〉 comes from the ODP1148 core (see Sect. 9) for which ΔtGCD=1 kyr.
Note that the approach we follow does not correspond to the classical least-squares problem as above since, in Eq. (118), the cosine and sine are tapered only on the left-hand side of the equality. However, one can reconstruct a signal from its projection coefficients with a different function than the one which is used to determine those coefficients (see Torrésani, 1995, Eq. II.8, p. 15, in which the similarity to is evident). Note that is a projection, since it is idempotent, but the projection is not orthogonal, because it is not symmetric.
Similarly to the non-tapered case, we now determine an approximate proportionality between the amplitude periodogram and the tapered periodogram. We start with the model (Eq. 13) evaluated at Ω=ω and written under the following form
where βω is introduced such that , or equivalently, such that is diagonal. A little development gives the formula for determining βω:
which is a generalisation of Eq. (42). We now make use of the following approximations:
which are similar to the approximation made in Eq. (117). That implies, with no extra approximation, the following formulas:
and
Note that in Eqs. (124) and (125), the sum of the two members is conserved and we find back Eq. (115) when G=I. Moreover, we approximate the following sum:
so that is diagonal. The quality of these approximations is illustrated in Fig. 4. Putting all of this together gives
from which we deduce
Finally, we mention that the above relation is also approximate in the case of regularly sampled time series.
6.3 Signal with a trend
We now work with the full model (Eq. 13) including the trend. Our aim is again to find the amplitude Eω, or, equivalently Aω and Bω. We proceed in the same way as in Sect. 6.2:
where
and
We can write , where is identical to except in the last two columns, where the cosine and sine are tapered by G. We thus obtain
and
where and are the two last components of vector .
6.4 With WOSA
The signal being stationary, we can estimate the amplitude on overlapping segments and take the average. That gives a better estimation, more robust against the background noise, but it has the disadvantage of widening the peaks and thus reducing the resolution in frequency. We simply take Eq. (132), apply it to each segment7, and compute the average. We have
6.5 Amplitude periodogram or periodogram?
So far, we have studied in detail the periodogram and its confidence levels as well as the estimated amplitude. Of course, confidence levels can also be determined for the amplitude, with Monte Carlo simulations, or with an analytical approximation similar to Sect. 5.3.3.
In the regularly sampled case, at Fourier frequencies, the cosine and sine vectors are orthogonal, so that, in the non-tapered case and with a constant trend, there is no difference between the periodogram and the amplitude periodogram, up to a multiplicative constant. Even with WOSA segmentation, the number of data points being identical on each segment, that multiplicative constant remains invariant.
In the irregularly sampled case, choosing one or the other depends on what one wants to conserve. On the one hand, the periodogram conserves the flatness of the white noise pseudo-spectrum (see Eq. 93) and can therefore be of interest to study the background noise of the time series. On the other hand, the amplitude periodogram gives direct access to the estimated signal amplitude. Another criteria to take into account is the computing time. Indeed, the amplitude periodogram requires matrix inversions (or, equivalently, resolution of linear systems) and is then slower to compute, while the periodogram allows orthogonal projections to be dealt with and is computationally more efficient. Finally, we mention that, with a trendless signal, the difference between both is rather explicit (see Eq. 118):
versus
This is variance (multiplied by the number of data points) versus squared amplitude. A compromise between the amplitude periodogram and the periodogram is the weighted periodogram, which is defined in the next section.
Taking into account the approximate linearity between the amplitude periodogram and the tapered periodogram, Eq. (128), a possibility is to perform the frequency analysis with a weighted version of the WOSA periodogram. On each WOSA segment, the periodogram is weighted by . The advantage of the weighted WOSA periodogram is to provide deterministic peaks (coming from ) of more or less equal power on all the WOSA segments, thus alleviating the issue stated in Sect. 4.5.2. The disadvantage is that the pseudo-spectrum of a white noise is not flat any more (Eq. 93 is not valid any more, except when Q=1). Working with the weighted version is done by modifying matrix Mω, Eq. (69), which is now
Note that the weights wq are the same on each segment when the time series is regularly sampled, so that the whole WOSA periodogram is, in that case, just multiplied by a constant, and the pseudo-spectrum of a white noise is flat. We observed that the weighted periodogram is often very close to the amplitude periodogram, like in the example presented in Fig. 10. We thus recommend the use of the weighted WOSA periodogram in most analyses.
When filtering is to be performed, the amplitude periodogram must be computed as well. This is the topic of the next section.
We want to reconstruct the deterministic periodic part, of our model (Eq. 13) evaluated at Ω=ω. From Eq. (132), we can extract and , and reconstruction at a single frequency is therefore direct. Reconstruction on a frequency range can be done by summing over ω.
Note that, in theory, reconstruction could be done segment by segment, using the WOSA method. But, in practice, we observe that it does not give good results with stationary signals. Of course, if the signal is not stationary, reconstruction segment by segment is a clever choice, but, with such signals, it is better to use more appropriate tools such as the wavelet transform. See the second part of this study (Lenoir and Crucifix, 2018), in which some examples of filtering are given.
The time series we use to illustrate the theoretical results is the benthic foraminiferal δ18O record from Jian et al. (2003) that holds 608 data points with distinct ages and covers the last 6 million years. An example of frequency analysis is described below.
9.1 Preliminary analysis
We first look at the sampling; ΔtGCD=1 kyr, and rt=10.13 %. Following the recommendation of Sect. 4.4, we therefore use the default rectangular window taper. The sampling and its distribution are drawn in Fig. 5. We then choose the degree of the polynomial trend to be m=7; see Fig. 6. This choice for m is justified by a sensitivity analysis performed in Sect. 9.4. We remind the reader that the time series is not detrended before estimating the spectral power of the data, but it is detrended before estimating the confidence levels.
9.2 CARMA(p,q) background noise analysis
We choose the order of the background noise CARMA process. We opt for the traditional red noise background (Hasselmann, 1976), p=1 and q=0. Note that we observe similar confidence levels with other choices (see the sensitivity analysis in Sect. 9.5). We then estimate the parameters of the stationary CARMA process (here, a red noise) on the detrended data. This is done with the algorithm provided by Kelly et al. (2014) (see Sect. 5.2.3). Quality of the fit is analysed in Fig. 7a, c and e. Figure 7a analyses the residuals. If the detrended data are a Gaussian red noise, the residuals must be distributed as a Gaussian white noise. We see that the distribution is indeed close to a Gaussian. Figure 7c shows the autocorrelation function (ACF) of the residuals. If the residuals are a Gaussian white noise sequence, they must be uncorrelated at any lag. We can therefore arrange the residuals on a regular grid with a unit step and then take the classical ACF, which can only be applied to regularly sampled data. Figure 7c is consistent with the assumption that the residuals are uncorrelated. Figure 7e shows the ACF of the squared residuals. If the residuals are a Gaussian white noise sequence, the squared residuals are a white noise sequence (which is not Gaussian any more) and must therefore be uncorrelated at any lag. Deviations from the confidence grey zone indicate that the variance is changing with time and the signal is therefore not stationary. This is actually what is happening with our time series. Changes in variance are already visible on the raw time series (Fig. 6). Remember that, at this stage, we are within the world of the null hypothesis, Eq. (76), and slight violation of the goodness of fit may be due to the presence of additive periodic deterministic components, that is the alternative hypothesis.
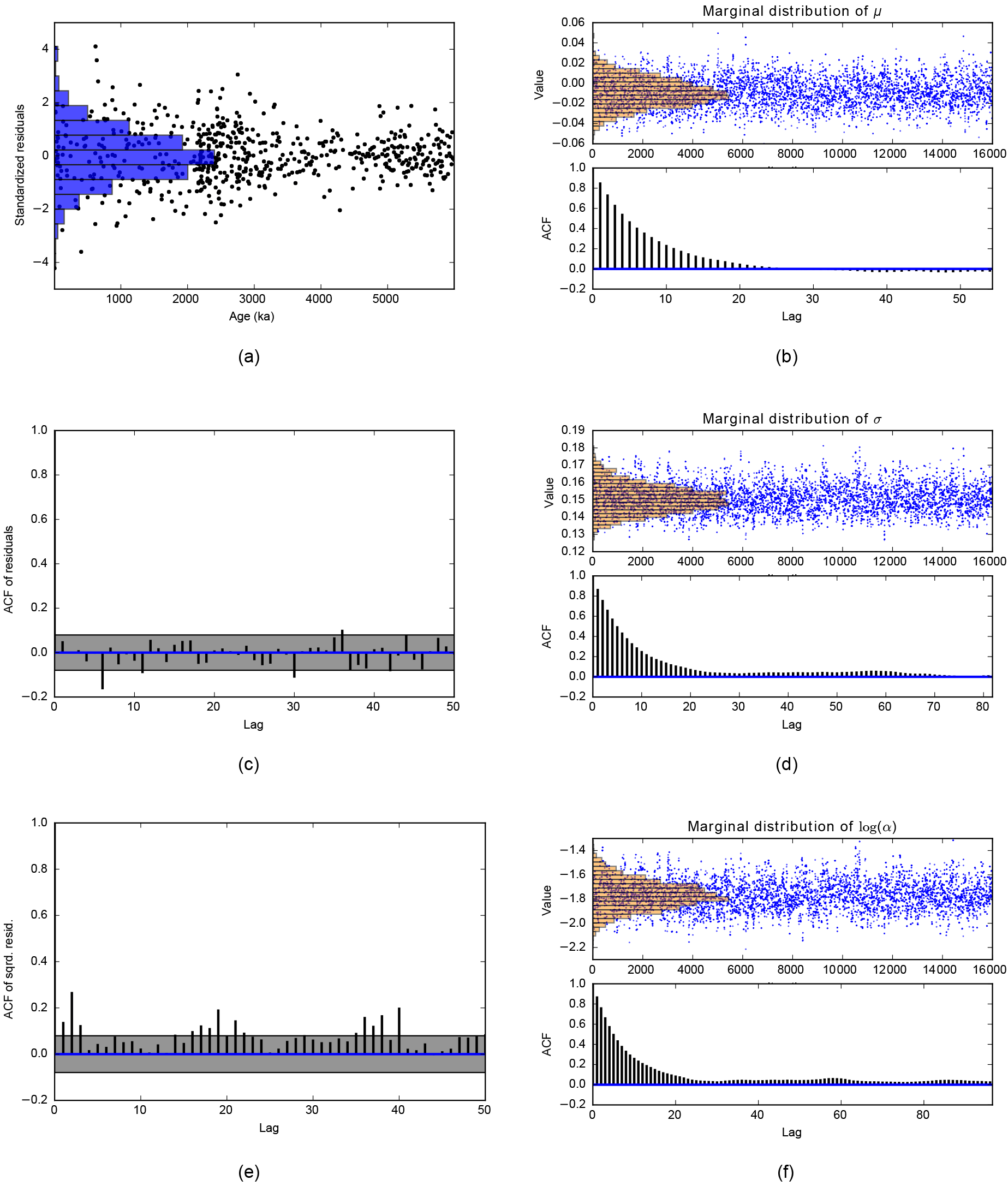
Figure 7CARMA(1,0) background noise analysis. Panels (a), (c) and (e) assess the fit. (a) Standardised residuals. (c) ACF of the residuals. (e) ACF of the squared residuals. The lag refers to an arbitrary scale on which the data are regularly spaced with a unit step. The grey portion is the 95 % confidence region. Panels (b), (d) and (f) show the samples of the MCMC and the posterior marginal distributions (top panel), jointly with the ACF of the MCMC samples (bottom panel). (b) Mean. (d) Standard deviation of the white noise term. Panel (f) shows log (α), where α is defined in Sect. 3.2.3.
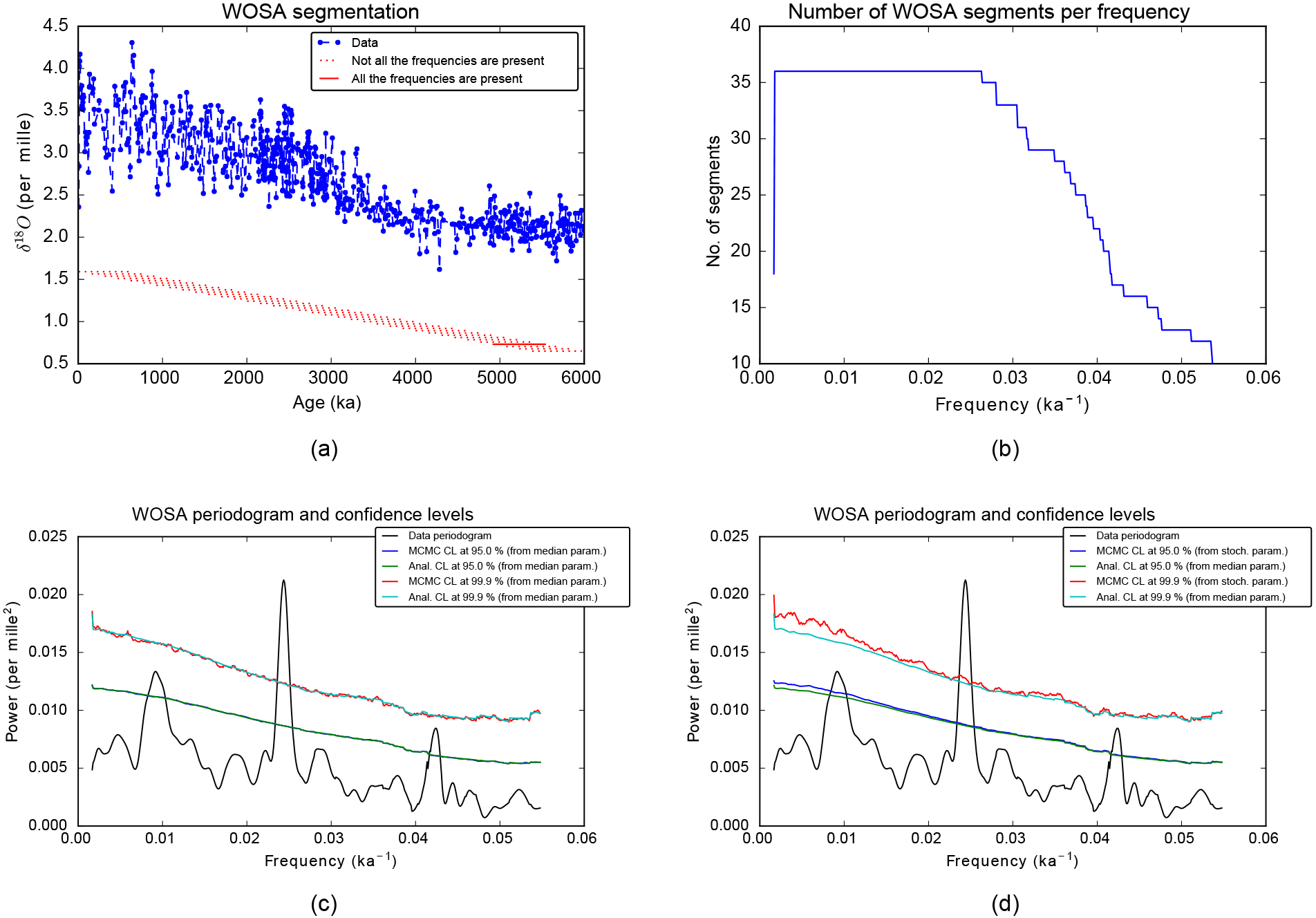
Figure 8Frequency analysis. (a) The time series, in blue, and the WOSA segments, in red. (b) Number of WOSA segments per frequency. (c, d) Weighted WOSA periodogram and the confidence levels (CL) at 95 and 99.9 %. Analytical CL (Anal. CL) are computed with the median parameters of the red noise process. In panel (c), the MCMC CL are computed from the MCMC red noise time series, all generated with the median red noise parameters. In panel (d), the MCMC CL are computed from the MCMC red noise time series, generated with stochastic parameters, that are taken from the joint posterior distribution of the parameters of the red noise process.
The marginal posterior distributions of the CARMA parameters are shown in Fig. 7b, d and f, jointly with the ACF of the MCMC samples. Each distribution is unimodal, and we may therefore use the analytical approach of Sect. 5.3.3 to estimate the confidence levels. Based on the ACFs of the MCMC samples of the three parameters, we skim off the initial joint distribution of the parameters to make their samples almost uncorrelated. In this example, we pick up 1231 samples among the 16 000 initial ones. This number of 1231 samples results from the fact that we impose an ACF which is less than 0.2 for each marginal distribution8.
9.3 Frequency analysis
We compute the weighted WOSA periodogram of Sect. 7. The frequency range is automatically determined from the results of Sect. 4.5.4. The length of the WOSA segments depends on the required frequency resolution. Here we choose segments of about 600 kyr and a 75 % overlapping. The WOSA segmentation is presented in Fig. 8a.
The weighted WOSA periodogram and its 95 and 99.9 % confidence levels are presented in Fig. 8c and d. Both figures display the analytical confidence levels, which are computed with the median parameters of the red noise process (that is, the median of 1231 samples of the distributions shown in Fig. 7b, d and f) and a 12-moment gamma-polynomial approximation (Sect. 5.3.3). We can check for the convergence of the gamma-polynomial approximation, at some frequencies. This is presented in Fig. 9. Figure 8c also shows the MCMC confidence levels, computed from 50 000 red noise time series, all generated with the median red noise parameters. As we can see in Fig. 8c, the matching between the analytical and MCMC confidence levels is excellent, also in the very tail of the distribution, at the 99.9 % confidence level. We can go a step further and take into account the uncertainty in the CARMA parameters, as explained in Sect. 5.3.2. Figure 8d presents the MCMC confidence levels that are computed from 50 000 red noise time series, generated with stochastic parameters, that are taken from the joint posterior distribution of the parameters of the red noise process. The number of WOSA segments per frequency, denoted by Q(f) in Sects. 4 to 7, is in Fig. 8b, and provides an indication of the noise damping per frequency. Indeed, the variability due to the background noise is increasingly damped as the number of WOSA segments grows.
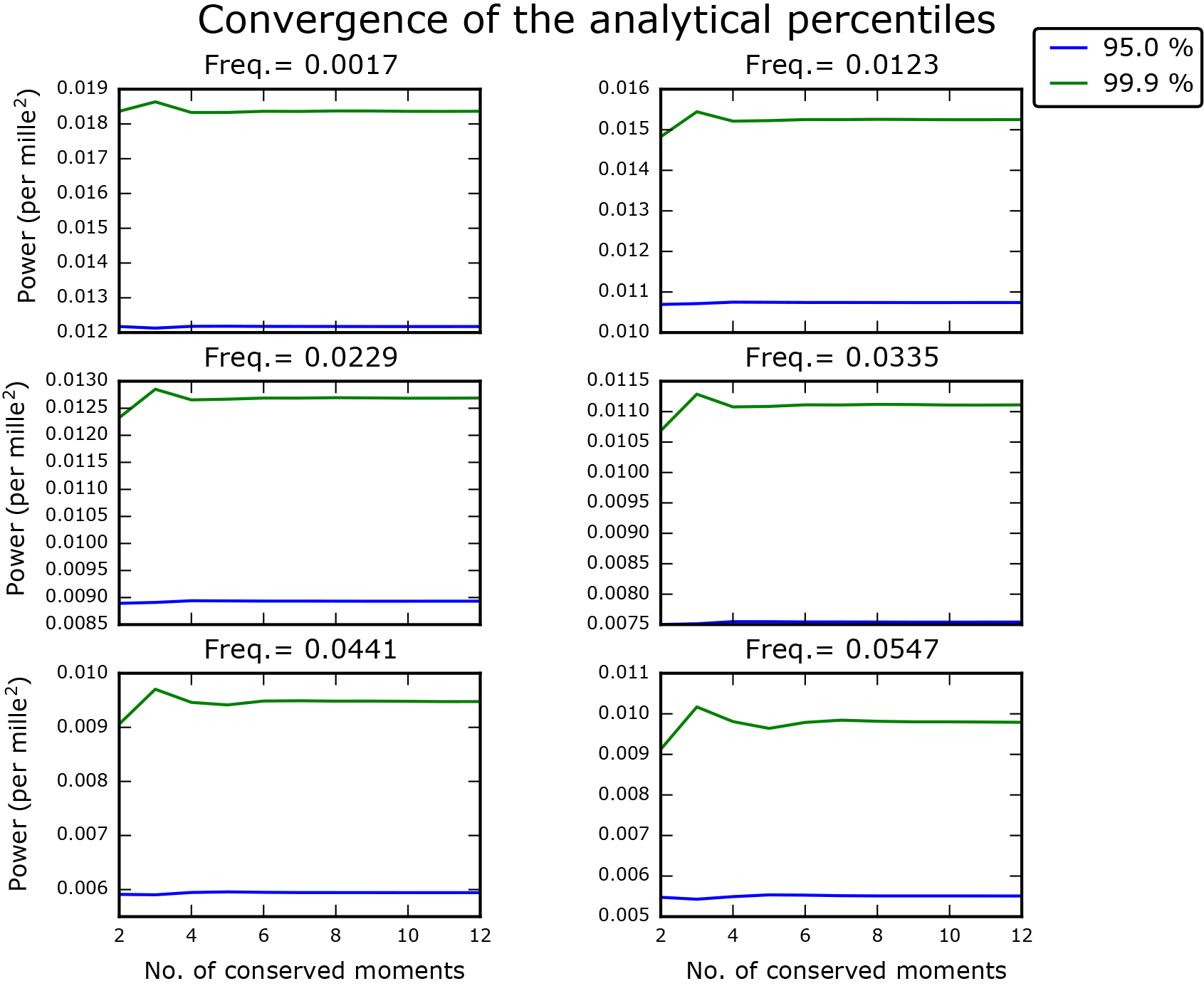
Figure 9At six particular frequencies, check for the convergence of the analytical percentiles.
We also compute the amplitude periodogram, Eq. (134), which is actually very close to the weighted periodogram, as shown in Fig. 10. Similar results are obtained using other tapers (not shown). This illustrates the quality of the approximations made in Sect. 6.2.2. Note that the estimation of the amplitude Eω of the model (Eq. 13) is always biased by the background noise (we observe in Fig. 10 that the peaks emerge from a baseline which is well above zero).
9.4 Sensitivity analysis for the degree of the polynomial trend
We show in Fig. 11 that the degree m of the polynomial trend, taken between 5 and 10, does not substantially influence the WOSA periodogram. Below m=5, the trend no longer fits the data correctly (from a mere visual inspection), while above m=10, spurious oscillations may appear.

Figure 10Comparison between the amplitude periodogram (= squared amplitude) and the weighted periodogram. The green curve is the same as the black curve of Fig. 8c and d.
Note that we do not apply here the Akaike information criterion (AIC) (Akaike, 1974). Indeed, defining a stochastic model for the trend and estimating its likelihood is quite tedious in our case, since we work with CARMA stochastic processes. Moreover, at this stage, we do not want to choose yet between the orders of the CARMA process.
9.5 Sensitivity analysis for the order of the CARMA process
Figure 12 displays the confidence levels for various orders of the CARMA process: , , and . It is clear that the CARMA(0,0) (= white noise) does not capture enough spectral variability to perform significance testing and that using a CARMA(2,0) or a CARMA(2,1) is basically equivalent to using a red noise.

Figure 11(a) Trends of different degrees for the time series. (b) Weighted WOSA periodograms for different degrees of the trend. Each periodogram is normalised like in Eq. (58) in order to make a meaningful comparison.
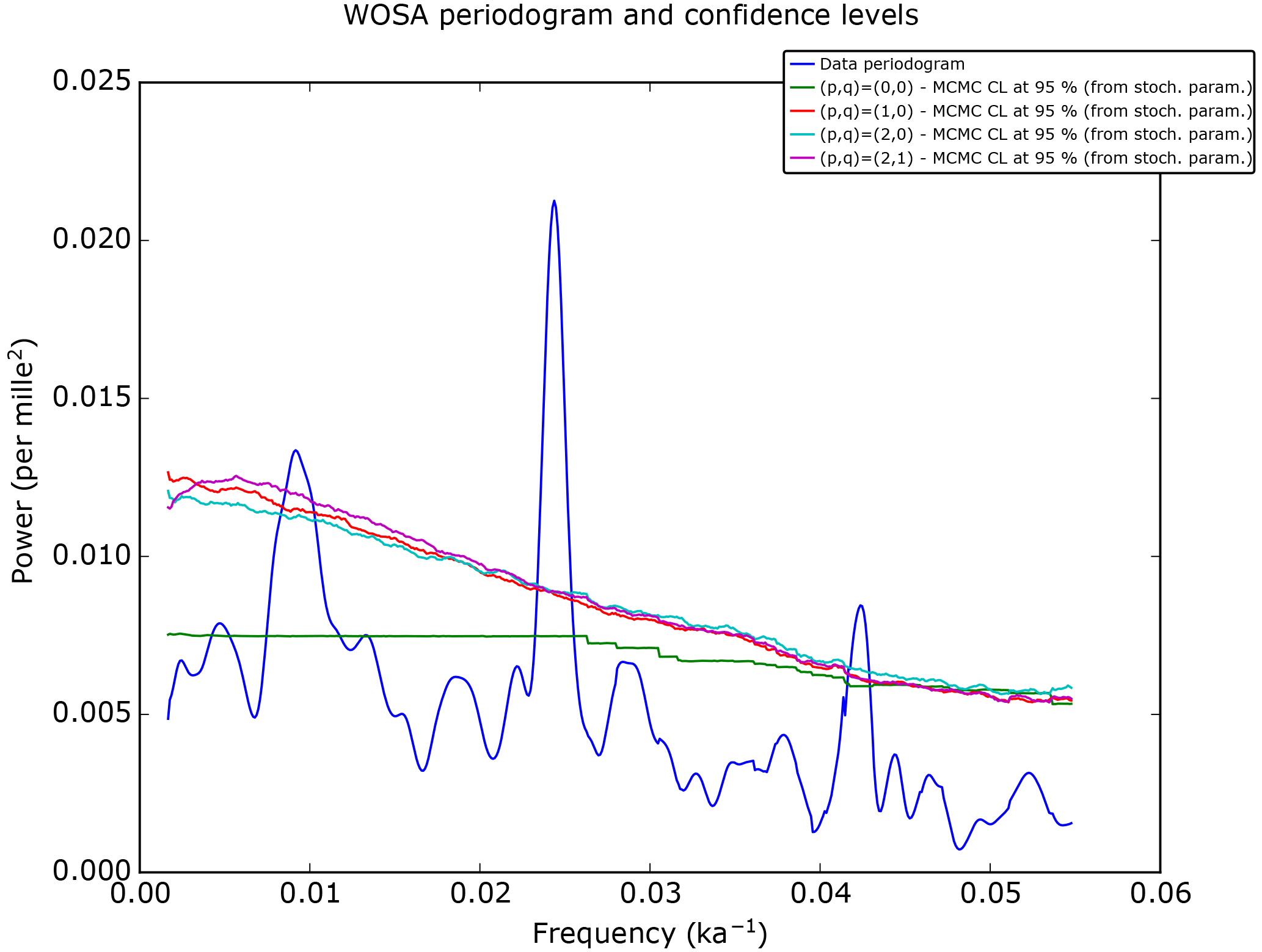
Figure 12The weighted WOSA periodogram and its 95 % confidence levels for different orders (p,q) of the CARMA process. Note that the marginal posterior distributions of some parameters of the CARMA(2,0) and CARMA(2,1) processes are multimodal, so the analytical approach cannot be applied, and MCMC confidence levels must therefore be used.
WAVEPAL is a package, written in Python 2.X, that performs frequency and time–frequency analyses of irregularly sampled time series, significance testing against a stationary Gaussian CARMA(p,q) process, and filtering. Frequency analysis is based on the theory developed in this article, and time–frequency analysis relies on the theory developed in Part 2 of this study (Lenoir and Crucifix, 2018). It is available at https://github.com/guillaumelenoir/WAVEPAL.
We proposed a general theory for the detection of the periodicities of irregularly sampled time series. This is based on a general model for the data, which is the sum of a polynomial trend, a periodic component and a Gaussian CARMA stochastic process. In order to perform the frequency analysis, we designed new algebraic operators that match the structure of our model, as extensions of the Lomb–Scargle periodogram and the WOSA method. A test of significance for the spectral peaks was designed as a hypothesis testing, and we investigated in detail the estimation of the percentiles of the distribution of our algebraic operators under the null hypothesis. Finally, we showed that the least-squares estimation of the squared amplitude of the periodic component and the periodogram are no longer proportional if the time series is irregularly sampled. Approximate proportionality relations were proposed and are at the basis of the weighted WOSA periodogram, which is the analysis tool that we recommend for most frequency analyses. The general approach presented in this paper allows an extension to the continuous wavelet transform, which is developed in Part 2 of this study (Lenoir and Crucifix, 2018).
The Python code generating the figures of this article is available in the Supplement.
We present some properties of the LS periodogram, defined in Sect. 4.1.
A1 Periodicity of the periodogram
The LS periodogram and all its generalisations (e.g. Eq. 64) exhibit a periodicity similar to the DFT of regularly sampled real processes: the periodogram over the frequency range repeats itself periodically. Moreover, the periodogram at frequency −f is equal to the periodogram at frequency +f. Consequently, we must work at most on the frequency range to avoid aliasing.
A2 Total reconstruction
Integrating the orthogonal projection between frequency 0 and 1∕2ΔtGCD does not give the identity operator. We only have an approximate equality. Using Lomb's approximation, given in Eq. (115), and no extra approximation, some algebra gives
It is interesting to compare it with the integration of complex exponentials, which gives exactly the identity operator:
where . The above formula may be interpreted as a form of Parseval's identity. That property of exact reconstruction is, incidentally, at the basis of the multitaper method (Lenoir, 2017, chap. 4). With that property and the no less interesting mathematical properties of the complex exponentials, it is legitimate to ask why we would not work with the projection on a complex exponential instead of a projection on cosine and sine. The main disadvantage of working with exponentials is the loss of power in the negative frequencies. Indeed, the trendless model (Eq. 13) at Ω=ω can be rewritten as
where . In the case of irregularly sampled time series, we no longer have, in general, , so that some power is lost in the negative frequencies when projecting on . We could then think about performing the projection on , but this does not lead to the identity operator when integrating from frequency to .
A3 Invariance under time translation
As stated in Scargle (1982), the LS periodogram is invariant under time translation. is of course invariant under such a transformation. The result can be generalised to more evolved projections. Indeed, is also invariant under time translation, provided all the powers of |t〉 from 0 to m are taken into account. That projection is also invariant under time dilatation if the frequency is contracted accordingly.
We show here the equivalence between some published formulas, with notations that are a mix between those of the cited articles and those of the present one in order to facilitate the reading.
Brockwell and Davis (1991, p. 335) work with
It is defined for regularly sampled time series, and is suitable for irregularly sampled time series as well. That formula is the same as Eq. (47).
Ferraz-Mello (1981) considers irregularly sampled time series and defines the intensity (p. 620) by
where and ; |f〉 contains the measurements (this is |X〉 in the present article) and |h1〉 and |h2〉 are exactly the same as in Eq. (53). I(ω) is thus equal to Eq. (55).
Heck et al. (1985) deal with irregularly sampled time series and define (their Eq. 1, p. 65):
where ν denotes the frequency () and A(ν) is a (N,2) matrix whose first column is and second column is . Equation (B3) is nothing but the squared norm of the orthogonal projection of the data |X〉 onto the span of those two vectors. By a Gram–Schmidt orthonormalisation, it is easy to see that , where |h1〉 and |h2〉 are defined in Eq. (53). We thus have the periodogram defined in Eq. (55).
We define the pseudo-spectrum as the expected value of the WOSA periodogram under the null hypothesis (see Sect. 5.1):
where , in which |Noise〉 is a zero-mean stationary Gaussian CARMA process sampled at the times of |t〉, and the expectation is taken on the samples of the CARMA noise. With what we have seen in Sect. 5.3.2 and 5.3.3, the periodogram is either obtained with Monte Carlo methods or analytically with some approximations. In the former case, is estimated by taking the numerical average of the periodogram at each frequency. In the latter case, an analytical formula for the pseudo-spectrum is available. Indeed, the process under the null hypothesis is , where K is defined in Eqs. (20) or (38), and we have
where the different terms are defined in Theorem 1.
When dealing with a trendless signal, we can perform the WOSA on the classical tapered periodogram, and the pseudo-spectrum becomes
In the case of regularly sampled data, Eq. (C3) converges to the spectrum S(ω) as the number of data points increases (up to a multiplicative factor Δt, the time step). See Walden (2000) where it is shown that is a mean-square-consistent and asymptotically unbiased estimator of the spectrum. The spectrum S(ω), also called Fourier power spectrum, of a regularly sampled zero-mean real stationary process |X〉 is defined by the following (see Sect. 10.3 of Brockwell and Davis, 1991):
Now, considering Eq. (96), we thus have, for trendless regularly sampled time series, the following 1-moment approximation:
With that approximation, the spectrum S(ω), which is well known for some processes such as ARMA processes, gives access to the confidence levels. The above formula is widely used in the literature on regularly sampled time series in the case of one WOSA segment (Q=1), for which the 1-moment approximation is good enough (see, for instance, Eq. 17 in Torrence and Compo, 1998).
In the case of irregularly sampled data, the spectrum S(ω) can be defined over the frequency range . This follows from the spectral representation theorem (Priestley, 1981, chap. 4) applied to irregularly sampled time series. But usually strongly differs from S(ω), except in the white noise case where the spectrum is flat. Building estimators of the spectrum S(ω) in the case of irregularly sampled time series actually seems very challenging, as briefly discussed in Sect. 4.5.1.
We extend the gamma-polynomial approximation of Sect. 5.3.3 to the generalised gamma-polynomial approximation. Both conserve the first d moments of the distribution X. The generalised gamma-polynomial approximation is based on the generalised gamma distribution, which has three parameters, such that the prerequisite of a d-moment approximation is a 3-moment approximation with the generalised gamma distribution.
D1 3-moment approximation
We work with the generalised gamma distribution, which has three parameters,
Its PDF is
where Γ is the gamma function. It reduces to the gamma distribution when δ=1. Its moments are
Equating the first 3 moments () of the generalised gamma to the first 3 moments of X gives α, β and δ. But, that requires the zeros of a nonlinear 3-dimensional function to be found. We observed that root-finding algorithms may be sensitive to the choice of the first guess, and particular attention must therefore be dedicated to it.
In Stacy and Mihram (1965), it is shown that, if Y follows a generalised gamma distribution, working with ln (Y) allows the parameters α, β, δ to be easily found. Indeed, it only requires a root-finding for a monotonic unidimensional function. Unfortunately, the distribution of the logarithm of a linear combination of chi-square distributions is not known. We thus use the 2-moment approximation, for which we can find the moments of the logarithm of the distribution. Indeed, if we write , in which g and M are determined from Eq. (98), and Z=ln (Y), some calculus gives us the cumulant generating function of Z:
from which we obtain the cumulants. The first three are
where ψi is the polygamma function (ψ0 is the digamma function). From the cumulants, we have the expected value κ(1), the variance κ(2) and the skewness . Applying Eq. (21) of Stacy and Mihram (1965) gives us the parameters α0, β0, δ0 for Y, parameters that we then use as a first guess for the generalised-gamma approximation of X.
D2 The d-moment approximation
We extend here the formulas10 presented in Provost et al. (2009). Let fX be the PDF of X; fX is approximated by the PDF of a dth degree generalised gamma-polynomial distribution:
where the parameters α, β and δ are estimated with the above 3-moment approximation; ξ0, ..., ξd are the solution of Eq. (100), where . The estimation of a confidence level for the WOSA periodogram is then the solution c0 of
for some p value p, e.g. p=0.95 for a 95 % confidence level. If we pose δ=1, the generalised gamma-polynomial approximation reduces to the gamma-polynomial approximation presented in Sect. 5.3.3.
A comparison between the computing times, for generating the WOSA periodogram, with the analytical and with the MCMC significance levels, based on the hypothesis of a red noise background, is presented in Fig. E1. They are expressed in function of the number of data points, which are disposed on a regular time grid in order to make a meaningful comparison. Confidence levels with the analytical approach are estimated with a 10-moment approximation, and the number of samples for the MCMC approach is 10 000 for the 95th percentiles and 100 000 for the 99th percentiles. The other parameters are default parameters of WAVEPAL. All the runs were performed on the same computer11.
We see that the analytical approach is faster than the MCMC approach as long as the number of data points is below some threshold, the latter increasing with the level of confidence. Indeed, the analytical approach delivers computing times of the same order of magnitude regardless of the percentile (the two blue curves in Fig. E1a and b are of the same order of magnitude), unlike the MCMC approach, which must require more samples as the level of confidence increases in order to keep a sufficient accuracy. The difference between both computing times therefore increases as the level of confidence increases.
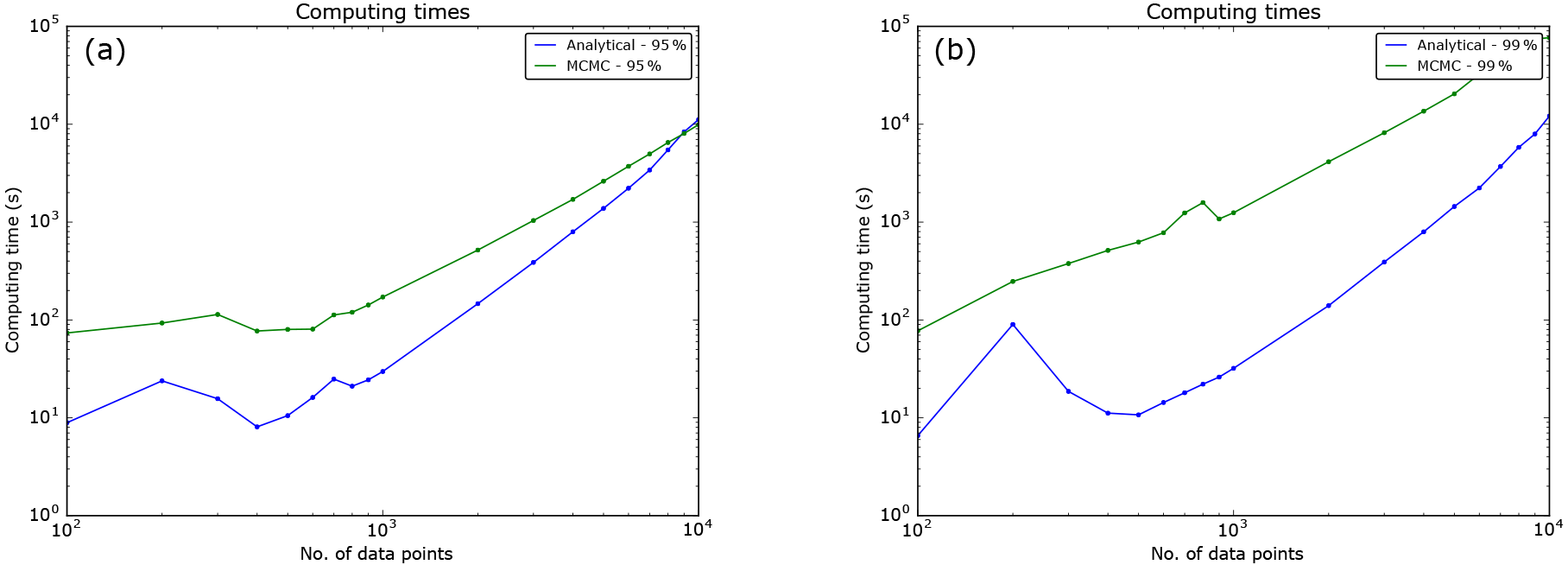
Figure E1Computing times for generating the WOSA periodogram with analytical (blue) and MCMC (green) confidence levels, in function of the number of data points (disposed on a regular time grid). Log–log scale. (a) 95th percentiles. (b) 99th percentiles.
The formula of the F periodogram (Eq. 104) is based on Brockwell and Davis (1991, pp. 335–336). In that book, the authors work with a constant trend. We have generalised the formula in order to deal with a polynomial trend.
A slightly different formula was published in Heck et al. (1985, p. 65), again with a constant trend. The F periodogram is denoted by θF in their paper. In the case of a generalisation to a polynomial trend, their formula becomes
but, unlike Eq. (104), it has a denominator which is not invariant with respect to the parameters of the trend.
The supplement related to this article is available online at: https://doi.org/10.5194/npg-25-145-2018-supplement.
The authors declare that they have no conflict of interest.
The authors are very grateful to Reik Donner, Laurent Jacques, Lilian Vanderveken, and Samuel Nicolay, for
their comments on a preliminary version of the paper. This work is
supported by the Belgian Federal Science Policy Office under contract
BR/12/A2/STOCHCLIM. Guillaume Lenoir is currently supported by the FSR-FNRS grant PDR T.1056.15 (HOPES).
Edited by: Jinqiao Duan
Reviewed by: two anonymous referees
Akaike, H.: A new look at the statistical model identification, IEEE T. Automat. Contr., 19, 716–723, https://doi.org/10.1109/TAC.1974.1100705, 1974. a
Bretthorst, L.: Nonuniform Sampling: Bandwidth and Aliasing, in: AIP Conference Proceedings – Bayesian Inference and Maximum Entropy Methods in Science and Engineering, edited by: Rychert, J., Gary, E., and Smith, R., vol. 567, 1–28, Boise, Idaho, USA, https://doi.org/10.1063/1.1381847, 1999. a
Brockwell, P. and Davis, R.: Time Series: Theory and Methods, Springer Series in Statistics, Second edn., Springer, New York, USA, 1991. a, b, c, d, e, f, g, h
Brockwell, P. and Davis, R.: Introduction to Time Series and Forecasting, Springer Texts in Statistics, Third edn., Springer International Publishing, https://doi.org/10.1007/978-3-319-29854-2, 2016. a, b, c, d
Bronez, T.: Spectral estimation of irregularly sampled multidimensional processes by generalized prolate spheroidal sequences, IEEE T. Acoust. Speech, 36, 1862–1873, https://doi.org/10.1109/29.9031, 1988. a
Ferraz-Mello, S.: Estimation of Periods from Unequally Spaced Observations, Astron. J., 86, 619–624, https://doi.org/10.1086/112924, 1981. a, b, c, d
Fodor, I. and Stark, P.: Multitaper spectrum estimation for time series with gaps, IEEE T. Signal Proces., 48, 3472–3483, https://doi.org/10.1109/78.887039, 2000. a
Ghil, M., Allen, M. R., Dettinger, M. D., Ide, K., Kondrashov, D., Mann, M. E., Robertson, A. W., Saunders, A., Tian, Y., Varadi, F., and Yiou, P.: Advanced spectral methods for climatic time series, Rev. Geophys., 40, 1003, https://doi.org/10.1029/2000RG000092, 2002. a
Harris, F.: On the use of windows for harmonic analysis with the discrete Fourier transform, Proceedings of the IEEE, 66, 51–83, https://doi.org/10.1109/PROC.1978.10837, 1978. a, b
Hasselmann, K.: Stochastic climate models Part I. Theory, Tellus, 28, 473–485, https://doi.org/10.1111/j.2153-3490.1976.tb00696.x, 1976. a, b
Heck, A., Manfroid, J., and Mersch, G.: On period determination methods, Astron. Astrophys. Sup., 59, 63–72, 1985. a, b, c, d, e, f
Jeffreys, H.: An Invariant Form for the Prior Probability in Estimation Problems, P. Roy. Soc. Lond. A Mat., 186, 453–461, https://doi.org/10.1098/rspa.1946.0056, 1946. a
Jian, Z., Zhao, Q., Cheng, X., Wang, J., Wang, P., and Su, X.: Pliocene-Pleistocene stable isotope and paleoceanographic changes in the northern South China Sea, Palaeogeogr. Palaeocl., 193, 425–442, https://doi.org/10.1016/S0031-0182(03)00259-1, 2003. a
Jones, R. and Ackerson, L.: Serial correlation in unequally spaced longitudinal data, Biometrika, 77, 721–731, https://doi.org/10.1093/biomet/77.4.721, 1990. a
Kelly, B., Becker, A., Sobolewska, M., Siemiginowska, A., and Uttley, P.: Flexible and Scalable Methods for Quantifying Stochastic Variability in the Era of Massive Time-domain Astronomical Data Sets, Astrophys. J., 788, 33, https://doi.org/10.1088/0004-637X/788/1/33, 2014. a, b, c, d, e, f, g, h, i
Kemp, D.: Optimizing significance testing of astronomical forcing in cyclostratigraphy, Paleoceanography, 31, 1516–1531, https://doi.org/10.1002/2016PA002963, 2016. a
Lenoir, G.: Time-frequency analysis of regularly and irregularly sampled time series: Projection and multitaper methods, PhD thesis, Université catholique de Louvain – Faculté des Sciences – Georges Lemaître Centre for Earth and Climate Research, Louvain-la-Neuve, Belgium, available at: https://dial.uclouvain.be/pr/boreal/object/boreal:191751 (last access: 22 February 2018), 2017. a
Lenoir, G. and Crucifix, M.: A general theory on frequency and time–frequency analysis of irregularly sampled time series based on projection methods – Part 2: Extension to time–frequency analysis, Nonlin. Processes Geophys., 25, 175–200, https://doi.org/10.5194/npg-25-175-2018, 2018. a, b, c, d, e, f
Lomb, N.: Least-squares frequency analysis of unequally spaced data, Astrophys. Space Sci., 39, 447–462, https://doi.org/10.1007/BF00648343, 1976. a, b
Mortier, A., Faria, J. P., Correia, C. M., Santerne, A., and Santos, N. C.: BGLS: A Bayesian formalism for the generalised Lomb-Scargle periodogram, Astron. Astrophys., 573, A101, https://doi.org/10.1051/0004-6361/201424908, 2015. a
Mudelsee, M.: Climate Time Series Analysis – Classical Statistical and Bootstrap Methods, in: Atmospheric and Oceanographic Sciences Library, vol. 42, Springer, Dordrecht, the Netherlands, 2010. a, b, c
Mudelsee, M., Scholz, D., Röthlisberger, R., Fleitmann, D., Mangini, A., and Wolff, E. W.: Climate spectrum estimation in the presence of timescale errors, Nonlin. Processes Geophys., 16, 43–56, https://doi.org/10.5194/npg-16-43-2009, 2009. a
Pardo Igúzquiza, E. and Rodríguez Tovar, F.: Spectral and cross-spectral analysis of uneven time series with the smoothed Lomb-Scargle periodogram and Monte Carlo evaluation of statistical significance, Comput. Geosci., 49, 207–216, https://doi.org/10.1016/j.cageo.2012.06.018, 2012. a
Priestley, M.: Spectral Analysis and Time Series, Two Volumes Set, Probability and Mathematical Statistics – A series of Monographs and Textbooks, Third edn., Academic Press, London, UK, San Diego, USA, 1981. a, b, c
Provost, S.: Moment-Based Density Approximants, The Mathematica Journal, 9, 727–756, available at: http://www.mathematica-journal.com/issue/v9i4/DensityApproximants.html (last access: 22 February 2018), 2005. a
Provost, S., Ha, H.-T., and Sanjel, D.: On approximating the distribution of indefinite quadratic forms, Statistics, 43, 597–609, https://doi.org/10.1080/02331880902732123, 2009. a, b, c, d, e
Rehfeld, K., Marwan, N., Heitzig, J., and Kurths, J.: Comparison of correlation analysis techniques for irregularly sampled time series, Nonlin. Processes Geophys., 18, 389–404, https://doi.org/10.5194/npg-18-389-2011, 2011. a
Riedel, K. and Sidorenko, A.: Minimum bias multiple taper spectral estimation, IEEE T. Signal Proces., 43, 188–195, https://doi.org/10.1109/78.365298, 1995. a, b
Robinson, P.: Estimation of a time series model from unequally spaced data, Stoch. Proc. Appl., 6, 9–24, https://doi.org/10.1016/0304-4149(77)90013-8, 1977. a
Scargle, J.: Studies in astronomical time series analysis II – Statistical aspects of spectral analysis of unevenly spaced data, Astrophys. J., 263, 835–853, https://doi.org/10.1086/160554, 1982. a, b, c, d, e, f
Schulz, M. and Mudelsee, M.: REDFIT: estimating red-noise spectra directly from unevenly spaced paleoclimatic time series, Comput. Geosci., 28, 421–426, https://doi.org/10.1016/S0098-3004(01)00044-9, 2002. a, b, c, d
Schulz, M. and Stattegger, K.: SPECTRUM: spectral analysis of unevenly spaced paleoclimatic time series, Comput. Geosci., 23, 929–945, https://doi.org/10.1016/S0098-3004(97)00087-3, 1997. a, b, c, d
Stacy, E. W. and Mihram, G. A.: Parameter Estimation for a Generalized Gamma Distribution, Technometrics, 7, 349–358, https://doi.org/10.1080/00401706.1965.10490268, 1965. a, b
Thomson, D.: Spectrum estimation and harmonic analysis, Proceedings of the IEEE, 70, 1055–1096, https://doi.org/10.1109/PROC.1982.12433, 1982. a, b
Torrence, C. and Compo, G.: A Practical Guide to Wavelet Analysis, B. Am. Meteorol. Soc., 79, 61–78, https://doi.org/10.1175/1520-0477(1998)079<0061:APGTWA>2.0.CO;2, 1998. a
Torrésani, B.: Analyse continue par ondelettes, Savoirs actuels/Série physique, CNRS Editions and EDP Sciences, Paris, France, 1995. a
Uhlenbeck, G. E. and Ornstein, L. S.: On the Theory of the Brownian Motion, Phys. Rev., 36, 823–841, https://doi.org/10.1103/PhysRev.36.823, 1930. a
Vio, R., Andreani, P., and Biggs, A.: Unevenly-sampled signals: a general formalism for the Lomb-Scargle periodogram, Astron. Astrophys., 519, A85, https://doi.org/10.1051/0004-6361/201014079, 2010. a
Walden, A. T.: A unified view of multitaper multivariate spectral estimation, Biometrika, 87, 767–788, https://doi.org/10.1093/biomet/87.4.767, 2000. a, b
Welch, P.: The use of fast Fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms, IEEE T. Acoust. Speech, 15, 70–73, https://doi.org/10.1109/TAU.1967.1161901, 1967. a, b, c
Zechmeister, M. and Kürster, M.: The generalised Lomb-Scargle periodogram, Astron. Astrophys., 496, 577–584, https://doi.org/10.1051/0004-6361:200811296, 2009. a
The GCD is usually defined on the integers, but we can extend it to rational numbers. In practice, t1, ..., tN come from measurements with a finite precision and are thus rational numbers.
A CARMA(p,q) process sampled at the times of an infinite regularly sampled time series is an ARMA(p,q) process.
If we have , where and ω is a Fourier frequency, then . Var is here the biased variance, which is defined as the squared norm of the signal minus its average value, and divided by N.
Basically, the spectrum cannot be defined without that hypothesis. See the Wiener–Khinchin theorem, e.g. in Priestley (1981, chap. 4)
For CARMA processes with p>0 and q≥0, the marginal posterior distribution is obtained by MCMC methods, and determining the maximum of the PDF thus requires some post-processing, such as smoothing the distribution. A simple alternative is to take the median.
We remind the reader that the vectors |tk〉 associated to the trend are taken on the whole time series. Only the (tapered) cosine and sine are taken on the WOSA segment.
As explained in Sect. 9.3, these 1231 samples are then used to compute the median parameters, producing the analytical confidence levels of Fig. 8c and d and the MCMC confidence levels of Fig. 8c. The MCMC confidence levels of Fig. 8d are computed from 50 000 samples of the parameters, after skimming off a distribution with much more samples.
In that book, the authors work with the projection on complex exponentials, , instead of a projection on cosine and sine. But this is asymptotically the same since, asymptotically, the cosine and sine are orthogonal at all the frequencies.
In Provost et al. (2009), formulas are given for the gamma-polynomial distribution, but as suggested by the authors, they can easily be generalised to the generalised gamma-polynomial distribution
CPU type: SandyBridge 2.3 GHz. RAM: 64 GB.
- Abstract
- Introduction
- Notations and mathematical background
- The model for the data
- Periodogram and relatives
- Significance testing with the periodogram
- The amplitude periodogram
- The weighted WOSA periodogram
- Filtering
- Application on palaeoceanographic data
- WAVEPAL Python package
- Conclusions
- Code availability
- Appendix A: Some properties of the Lomb–Scargle periodogram
- Appendix B: Periodogram and mean: equivalence between published formulas
- Appendix C: On the pseudo-spectrum
- Appendix D: The generalised gamma-polynomial distribution as an approximation for the linear combination of chi-square distributions
- Appendix E: Computing time: analytical versus Monte Carlo significance levels
- Appendix F: On the F periodogram
- Competing interests
- Acknowledgements
- References
- Supplement
- Abstract
- Introduction
- Notations and mathematical background
- The model for the data
- Periodogram and relatives
- Significance testing with the periodogram
- The amplitude periodogram
- The weighted WOSA periodogram
- Filtering
- Application on palaeoceanographic data
- WAVEPAL Python package
- Conclusions
- Code availability
- Appendix A: Some properties of the Lomb–Scargle periodogram
- Appendix B: Periodogram and mean: equivalence between published formulas
- Appendix C: On the pseudo-spectrum
- Appendix D: The generalised gamma-polynomial distribution as an approximation for the linear combination of chi-square distributions
- Appendix E: Computing time: analytical versus Monte Carlo significance levels
- Appendix F: On the F periodogram
- Competing interests
- Acknowledgements
- References
- Supplement