the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 26 May 2025
| 26 May 2025
Finite-size local dimension as a tool for extracting geometrical properties of attractors of dynamical systems
Martin Bonte
Stéphane Vannitsem
Local dimension computed using extreme value theory (EVT) is usually used as a tool to infer dynamical properties of a given state ζ of the chaotic attractor of the system. The dimension computed in this way is also known as the pointwise dimension in dynamical systems literature and is defined using a limit for an infinitely small neighborhood in the phase space around ζ. Since it is numerically impossible to achieve such a limit, and because dynamical systems theory predicts that this local dimension is almost constant over the attractor, understanding the properties of this tool for a finite scale R is crucial. We show that the dimension can considerably depend on R, and this view differs from the usual one in geophysics literature, where it is often considered that there is one dimension for a given dynamical state or process. We also systematically assess the reliability of the computed dimension given the number of points to compute it.
This interpretation of the R dependence of the local dimension is illustrated on the Lorenz 63 system not only for ρ=28, but also in the intermittent case where ρ=166.5. The latter case shows how the dimension can be used to infer some geometrical properties of the attractor in phase space. The Lorenz 96 system with n=50 dimensions is also used as a higher-dimension example. A dataset of radar images of precipitation (the RADCLIM dataset) is finally considered, with the goal of relating the computed dimension to the (in)stability of a given rain field.
- Article
(3475 KB) - Full-text XML
- BibTeX
- EndNote




When nowcasting the rain field, the future state is essentially predicted using Lagrangian persistence (Zawadzki et al., 1994; see Pierce et al., 2012, for a review of nowcasting). It is known that the errors in the estimation of the motion field (the wind) do not dominate the total error of the forecast (Bowler et al., 2007), but that taking into account the growth and dissipation of rain cells is essential for an accurate nowcast (Germann et al., 2006). In the case of convective events, the instability may be captured by the convective available potential energy (CAPE) available in numerical weather prediction (NWP) outputs, but convective situations can very quickly evolve. It would therefore be useful to have a real-time method to assess the stability of the current situation. Several techniques have been developed to produce probabilistic forecasts (Germann and Zawadzki, 2004; Bowler et al., 2007; Berenguer et al., 2011; Pulkkinen et al., 2019a). Despite these, it is still difficult to emit early warnings for very severe floods, for example, as witnessed by the 2021 flood in Belgium (Journée et al., 2023).
The idea behind the current work is to use the local dimension of a given state in phase space as a proxy for the complexity (and possibly the predictability) of the future of that state, following Faranda et al. (2017, 2022, 2023) and De Luca et al. (2020). The intuition supporting this idea is that points with a high dimension have a lot of different phase space directions in which to evolve on the attractor, so their direction of evolution would be more difficult to guess if one had to do it stochastically. Other phase space ideas for nowcasting were been explored in Foresti et al. (2024).
The computation of the dimension of manifolds and attractors of dynamical systems is a broad and old topic (Russell et al., 1980; see Abarbanel, 1996 and Ott, 2002 for textbook reviews in the context of dynamical systems and Camastra and Staiano, 2016, for a review on the dimension in the broader context of manifold dimension estimation). New algorithms were proposed for low-dimensional systems, producing mainly a global estimation of the dimension (Golay and Kanevski, 2014; Erba et al., 2019; Bac and Zinovyev, 2020). The focus is here on the dimension computed locally in phase space using the framework of the extreme value theory (EVT) as proposed in Faranda et al. (2012, 2017, 2019, 2023) and Pons et al. (2020, 2023).
The local dimension is also called the pointwise dimension, and its definition is (Ott, 2002)
where μ is a given measure on the attractor and B(R) is the n-dimensional ball centered on ζ. This definition implies that asymptotically (limits of both an infinite number of points and an infinitely small bulk size). A classical result in dynamical systems theory is that, if μ is ergodic, the dimension is asymptotically the same for all points, Dp(ζ)=D1 (D1 is the information dimension), except for a zero-measure set of points (Pons et al., 2020; Ott, 2002; Pesin, 1997).
It is obviously impossible to numerically reach the limit R→0 in Eq. (1), and the question is then how to choose some finite value of R, as raised, for example, in Pons et al. (2020). Datseris et al. (2023) suggests that N (the number of points at a distance smaller than R from the computation point ζ) just needs to be higher than 100–1000. A similar conclusion is reached in Caby (2019). The idea of evaluating the impact of finite radius R was followed in Little et al. (2017) using the principal component analysis (PCA) technique in order to identify a scale where the manifold could be approximated by a plane. A similar idea was used to evaluate the robustness to multiscaling of a good estimator in Camastra and Staiano (2016).
In this work, we use a maximum likelihood estimator to estimate the local EVT dimension for different values of R. This estimator turns out to be exactly a local version of the Takens estimator for the global dimension (Takens, 1985). The estimations of the dimension for the different values of R are then used to infer local information on the attractor.
As the focus of the current work is on the non-asymptotic estimation of the dimension, we obviously want to consider only values of the dimension which will not significantly change if more points are added to the dataset: in this sense, we want to be within the limit of infinite number of points. We therefore need some techniques to assess whether the dimension computed for some value of R has sufficiently converged or not.
The main findings of this work are as follows:
-
The non-asymptotic local dimension depends on the scale R: this can be used to get information on the phase space structures. This new interpretation of the dimension as dependent on R contrasts with the usual notion of dimension. We illustrate this approach on the Lorenz 63 system for ρ=28 and for ρ=166.5. The latter displays chaotic intermittency (see Sparrow, 1982; Ott, 2002), inducing a phase space geometry well suited for illustrating our interpretation of the dependence of the dimension on R. Another reason to study the behavior of the dimension for intermittent systems comes from the fact that our main goal is to compute the dimension for rain fields, which are known to be intermittent.
-
The question of the number of points N needed to have a robust estimation of the dimension is also explored. The question is raised in Pons et al. (2020) and Datseris et al. (2023) for the EVT dimension. For the correlation dimension (Grassberger and Procaccia, 1983), the definition of the dimension (size∼Rdimension) implies, at a fixed R, that the needed value of N grows exponentially with the dimension (Eckmann and Ruelle, 1992; Camastra and Staiano, 2016).
The normalized root mean squared error (NRMSE) (metric proposed in Datseris et al., 2023) is used in this work to assess the quality of the fit at a given scale R. The confidence bounds provided by the likelihood function are also computed, and it is shown that the true value of the dimension is around the estimated value with a 10 % error and with 95.5 % confidence if N>427, which is seemingly in contradiction with the mentioned argument of Eckmann and Ruelle (1992). We introduce a quantity (denoted as s hereafter) which sheds some light on this. This gives a possible answer to the question of the maximal dimension that one can measure with the EVT method and under which conditions this is possible.
-
The applicability to high-dimensional systems is also explored in the context of the Lorenz 96 with n=50 dimensions, for which the dependence of the dimension on R gives some characterization of the phase space.
A radar-estimated rain field over Belgium is investigated with the same tools. In this case, the dimensions for some computation points ζ can be reliably estimated but only for very narrow ranges of R, and this makes it difficult to draw conclusions on the dynamical properties of the state based on the values of the dimension. The dimension ranges essentially between 10 and 30, with a lot of values between 15 and 20. Not surprisingly, we also find a correlation between the convective rain rate from the ERA5 reanalysis and the relevant range of values of R.
This paper is organized as follows. In Sect. 2, we first introduce the pointwise dimension and show how it is computed in the EVT framework. We also derive the expression of the maximum likelihood estimator of the dimension and of the bounds of the confidence interval using the likelihood function. After that, we introduce the NRMSE score and interpret the estimated dimension. We also introduce the quantity s in order to understand the maximum dimension that one can compute using a given number of points.
Section 3 introduces the results of the computed dimension on the Lorenz 63 system (for ρ=28 and ρ=166.5) and discuss the interpretation in detail. The intermittent case illustrates well that the dimension depends on the radius R and can be used to evaluate the geometric properties of the attractor, such as the distance of chaotic points to the laminar regime.
Large systems (Lorenz 96 with n=50 dimensions and the radar dataset) are considered in Sect. 4, and the final section briefly summarizes the work.
Given a measure on the attractor, the pointwise dimension for a computation point ζ is defined in terms of the natural measure μ on the attractor by Eq. (1):
This is equivalent to
That is, the measure of the ball B(R) of radius R around ζ scales as .
The measure μ is often chosen to be the natural measure of the system: given any trajectory long enough originating from a typical initial condition of the system, μ(A) is defined for any subset A of the phase space as the fraction of points of the trajectory inside A or equivalently as the fraction of time spend by the system in A (see Ott, 2002; Kantz and Schreiber, 2003). This means that the whole set of points of the trajectory is as if it was sampled from the measure μ. Some points may have to be discarded at the beginning of the trajectory in order to ensure that it is on the attractor.
This natural measure is invariant by definition: , where Φt is the flow of the system. This is because each point in the trajectory has one antecedent point so that the number of points in A is the same than in . It is also ergodic if the attractor cannot be decomposed in two distinct invariant sets. In practice, one can also assume ergodicity by assuming that the system is always on the same invariant subset (for example, because we observe one and only one trajectory as in the case of the climate). As stated in the introduction, the dimension Dp(ζ) is constant for almost all points when the measure is ergodic (Pesin, 1997; Ott, 2002; Pons et al., 2020).
The above discussion implies that, given a trajectory long enough, μ(B(R)) can be approximated as the number C(R) of points inside B(R) divided by the total number of points in the trajectory. It follows that the pointwise dimension Dp(ζ) can be interpreted as a characterization (see Eq. 5 below for a precise statement) of the growth rate of the number of points C(R) that one should find inside a ball B(R) centered around ζ (for infinitely small R).
If there are enough points around ζ, and if they span a smooth Dp(ζ)-dimensional surface, one can introduce the hyperspherical coordinates (r,θ) and the density of points σ(r,θ). In this case, the number of points C(R) inside B(R) is
with being the density integrated over angles. The number of points C(R) is proportional to if and only if Σ(r) is constant. If not, one has to consider the small R limit, where C can be expanded in a Taylor series. One can check whether the first nonzero term of this series is the one on the order of Dp(ζ):
where the notation δ=Dp(ζ) is used from now on. For example, for δ=2, we have
so that . This approximation amounts to considering Σ constant on the interval of integration [0, R] because the O(R3) term containing Σ′(0) is neglected.
After the estimation of C(R) for several values of R, and if it has the expected scaling C(R)∼Rδ, the dimension can be extracted using a fit on this scaling. In the context of the correlation dimension, C(R) is a local version of the correlation integral, and δ can be computed as (R1 and R2 have to be chosen).
Whatever technique we use to estimate δ, the following points have to be kept in mind:
-
The distances measured in phase space do not precisely match with r or R: in order for Eq. (5) to hold, R has to be measured along the surface of the attractor (more precisely, along the geodesics of the attractor, provided it can be approximated by a smooth manifold), but this is not possible when our representation of the attractor is a set of points. Instead, we measure distances in phase space, and, if the attractor is curved, there can be a mismatch with the distances measured along the surface of the attractor (see Fig. 1). Therefore, the number of points in B(R) might not scale exactly as Rδ. This could lead to a bias in the estimated dimension (Perinelli et al., 2023). Since the distance computed in phase space becomes closer to the one computed on the surface when R is small enough (i.e., smaller than some typical scale of the curvature given, for example, by the inverse of the curvature itself), one recovers C(R)∼Rδ in the limit R→0.
-
If we use too big of a value of R, the Rδ+1 term in Eq. (5) might not be small anymore. Said differently, Σ(r) in Eq. (4) is not sufficiently constant on [0, R] for C(R)∼Rδ to hold. Actually, if in this range, Σ(r) looks more like ∼ra for a≠0, C(R) will scale as Rδ+a. The value of the dimension we measure in this case does not have a clear geometric meaning but is an effective value , taking into account the change in Σ over [0, R].
In this case, the information contained in δeff is much more difficult to use. If one had a way to estimate a in Σ(r)∼ra, one could compute .
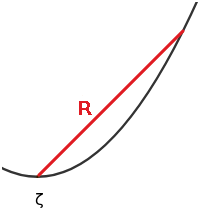
Figure 1Illustration of the fact that the distance computed in phase space might be different than the distance on the surface: the distance R computed in phase space is in red, while R should be measured along the surface of which we are trying to estimate the dimension (which is in black) in order to find the C(R)∼Rδ behavior.
2.1 Dimension and extreme value theory
Extreme value theory is a framework to study the occurrences of extreme events (see, for example, the textbooks Beirlant et al., 2004; Falk et al., 2010; Lucarini et al., 2016).
Two approaches can be followed to define extremes among the samples . The peak over threshold (POT) approach consists of fixing a threshold u, and the values Xi>u above this threshold are considered extremes. The threshold u has to be taken to be as high as possible to reach the correct definition of extremes. The block maxima (BM) approach consists of splitting the set of samples in chunks of size m, and the extremes are the highest values of each chunk (one extreme for each chunk). The size m has to go to infinity in order to correctly define the extremes.
The main theorem in the BM approach states that, under some conditions, there are essentially three asymptotic distribution for extremes that are regrouped under the generalized extreme value (GEV) law. In the POT approach, an equivalent theorem states that there are also three limiting distributions that are regrouped under the generalized Pareto distribution (GPD):
where the support of z is z≥0 for ξ≥0 and for ξ<0.
2.1.1 Theoretical extreme value law around ζ
The scaling C(R)∼Rδ induced by the definition of the pointwise dimension (Eq. 1) is the starting point in estimating the dimension in the EVT framework using the POT approach (Faranda et al., 2012). We reformulate here some of their results.
Consider the ball B(R) of radius R in the n-dimensional phase space. C(R)∼Rδ implies that the number of points between r and r+dr is
In order to have a probability density function (PDF) between 0 and R (i.e., in the B(R) ball), c is normalized to 1 (), so that
With such a normalization for c(r), it can be interpreted as follows: if we select a point randomly inside B(R), c(r)dr is the probability that its distance to ζ is between r and r+dr (for r<R).
The usual EVT framework for the dimension is formulated within the POT approach. The observable whose extreme values distribution is studied is often one of the following functions of r:
The parameter K can be freely chosen, and α and γ have to be positive. Given a point ζ in phase space, the points corresponding to extremes are those whose distances to ζ are smaller than R. The threshold of the POT approach is given by Ta=ga(R) (), where ga is the function that was chosen from the above three. Note that EVT usually defines extremes as high values of an observable, while, in terms of the distance r to ζ, extremes are defined as small values of r. Using these transformations and their inverses as well as Eq. (11), the PDFs describing the distributions of ga=ga(r) are computed to be
Note that one always assumes ga≥Ta because r≥R and the functions in Eq. (12) are decreasing for r>0. One can check whether each of the distributions in Eq. (13) correspond exactly to one of the signs of ξ (ξ=0, ξ>0 and ξ<0) of the GPD Eq. (9), with
Note that, starting from one of the three possible distributions in Eq. (13) and using the corresponding transformations from Eq. (12), one recovers Eq. (11). That is, the application of each one of the transformations in Eq. (12) and the deduction of δ using a parameter fit of the corresponding distribution in Eq. (13) are an alternative way to access the exponent δ of the scaling C(R)∼Rδ.
2.1.2 Maximum likelihood estimation of δ
The expression of the maximum likelihood (ML) estimator of the dimension is now derived using the above density functions. It leads, in fact, to the expression of a local version of the estimator of Takens (Takens, 1985).
To compute the dimension around a computation point ζ, consider all points inside the ball B(R) centered on ζ (the analogues), whose distances to ζ are ri (with i=1, …, N and ri<R). The corresponding g values are defined as . We know from the previous section that ga,i values should follow the distribution .
The (log-)likelihood functions are for each case:
Setting the derivative of ln L with respect to δ to 0 in each case gives the ML estimator:
These three estimators are numerically equal. Indeed, using , and , one gets
The estimated inverse dimensions are all equal to
which is minus the mean of in logarithmic scale or minus the logarithm of the geometric mean of the ratios . Since values are all the same, we use from now on the notation instead. This is precisely a local version of the expression of the estimator of the local dimension as given by Takens (1985).
This ML estimator is particularly interesting in this case since it is, even for a finite N, unbiased and efficient as an estimator (James, 2006).
These three different ML principles are really equivalent since the log-likelihood functions are all equal up to a term independent of δ (so that the derivatives of the log-likelihood functions are equal). Indeed, using the different but equal expressions of in terms of ga,i values, one derives the following:
As functions of δ, the three different log-likelihood functions are thus equal up to an additive term independent of δ. This is why values are all the same and why the confidence bounds based on the likelihood function do not depend on the chosen function ga(r) (see Sect. 2.1.3). In the following, we use only the function g1(r) unless explicitly stated.
In Pons et al. (2023), the authors also estimate the shape parameter (ξ) of the observed extreme value law of ga,i values. We do not do it since it is the choice of the function ga(r) which fixes the extreme value law to the expected extreme value law. If there is a deviation from this law, it is because the scaling C(R)∼Rδ is not satisfied in the first place (see Sect. 2.5 for possible reasons why C(R)∼Rδ does not hold).
2.1.3 Confidence intervals
Confidence bounds on the estimations of the dimension were already studied to some extent in Theiler (1990) but through the statistical error in the estimation of C(R). Since we do not rely on estimations of C(R) and use only a ML principle for , we present here the computation of the bounds of the confidence intervals of δ using the likelihood function.
The log-likelihood function in the first case () is
and ln L2 and ln L3, they are the same functions of δ up to an irrelevant term, as shown in Sect. 2.1.2. We thus derive the following:
where . Since the computation of confidence bounds using the likelihood involves only Δln L, the confidence bounds will be the same for all three cases.
Given N, one can have a nσ confidence interval by finding the values of δ for which (see left panel of Fig. 2; James, 2006)
On the other hand, if we fix some target confidence interval [δmin, δmax] around , we can look for the minimum value of N to use. The above equation turns into an inequality, of which there are two versions (for δmin and δmax). Taking into account the most restrictive one, one has
For example, if we want a 10 % interval (i.e., and ) with 95.5 % confidence (nσ=2), the required N is computed as
So N has to be bigger than 427 for us to be 95.5 % sure that the true dimension is at most 10 % below or 10 % higher than .
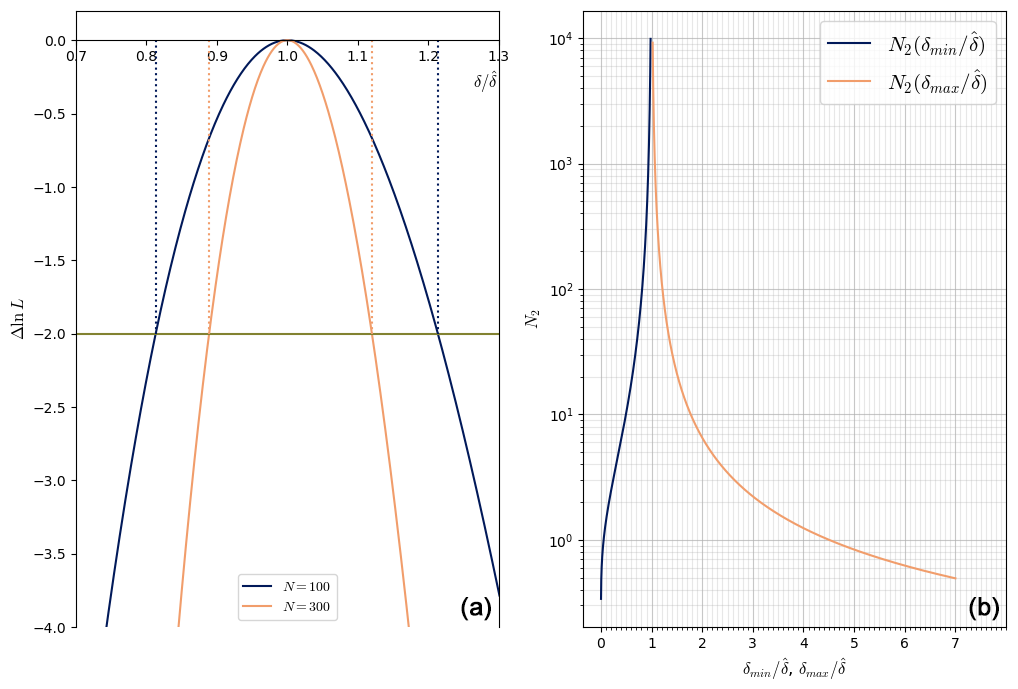
Figure 2(a) Plot of Δln L as a function of for N=100 and N=300. The horizontal green line corresponds to (nσ=2). The dotted lines show how to read and for the two different values of N. (b) Plot of N2 versus of and (nσ=2, 95.5 % confidence).
The right panel of Fig. 2 shows a plot of the functions and .
One can also invert the relationship to compute and in terms of N:
where W0 and W−1 are the Lambert function on the order of 0 and −1, respectively, and . Note that these relative bounds (i.e., the bounds for δ relatively to ) depend only on the number of observations, i.e., on the number of analogues, and not on the dimension itself.
These bounds should be taken with caution. They are computed under the assumption that the underlying distribution of points is indeed exponential and that all the samples are i.i.d., as was already pointed out in Theiler (1990). In the case of a dynamical system producing the dataset, this is only true in the asymptotic limit. Consider, for example, a system observed with a very high time resolution but in quite a short time. In this case, the system could have visited the ball B(R) only a few times (so that the system has not explored all directions around ζ yet), but one could still have N≥427. In such a case, the distribution of values of r around ζ has not converged yet, and we cannot really trust the confidence interval . It is, however, unlikely that the observed distribution of values of r looks like an exponential in that case. The NRMSE score introduced below helps to quantify how far the experimental distribution is from an exponential distribution.
2.2 NRMSE score
The ML method produces an estimate of the dimension even if the distribution of points is not at all an exponential, in which case the estimated dimension and its bounds are not correct. A systematic way to assess whether the fitted distribution is indeed exponential or not is therefore needed.
As in Datseris et al. (2023), we tried to use a Kolmogorov–Smirnov test, but it did not prove to be very efficient in assessing the quality of the exponential fit to the data. Following their suggestion, the normalized root mean squared error (NRMSE) is used instead between the fitted version of the exponential distribution and a uniform distribution. It is computed as follows:
-
The data are first binned in bins of equal size, and the empirical probability Pi associated with the bin i is computed as the fraction of observations lying in this bin (the number of bins is taken as the minimum between the Sturges's rule and the Freedman–Diaconis rule; see Scott, 2015, for information about those rules).
-
Ei values are defined as the fraction of events that would fall into each of the bins if the events followed an exponential law characterized by .
-
U is defined as the probability of falling into each bin using a uniform law over the range of observations (it does not depend on the bin because they are taken to all have the same width).
-
The NRMSE score is then computed as
The NRMSE score gives an indication of how much better the data are described by an exponential law than by a uniform law. For a good fit, we expect a small NRMSE score: in this case, the numerator (which is the error between the experimental distribution and the fitted exponential distribution) is much lower than the denominator (which is the error between the experimental distribution and the uniform distribution).
2.3 Interpretation of the estimated dimension
The interpretation of the dimension is more easily understandable in the third case with γ=1 and K=0: the observable is in this case . Since the values of δ obtained in each case are equal, the interpretation holds irrespectively of the function ga used.
Figure 3 shows two possible histograms for two random variables, both following the distribution (i.e., with K=0 and γ=1) but for two different values of δ. If the empirical distribution of radius ri values (normalized by R) looks like that of the orange histogram, the estimated value will be lower than if the empirical distribution is closer to the dark blue histogram. Mathematically, this is because the higher the value of δ, the steeper rδ−1 is. This means that the higher the dimension, the closer the analogues inside B(R) will be to the boundary of B(R). In the following, the estimated value of the dimension is sometimes artificially high because of that.
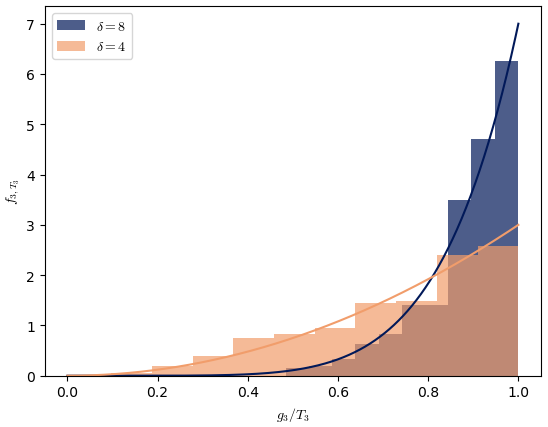
Figure 3Example of histograms of two random variables , whose PDFs for both are (i.e., with D=0 and γ=1) but for different values of δ. The horizontal axis is .
2.4 Measure a high dimension with a small N?
The computation in Sect. 2.1.3 indicates that with N≳400 (and if the NRMSE score is good), a 10 % accuracy is reached for the estimation of δ for all values of the dimension. This seems to be in contradiction with the argument of Eckmann and Ruelle (1992) (i.e., the number of points in B(R) should be an exponential of δ). In this section, we examine in detail how the scaling C(R)∼Rδ is consistent with the computation in Sect. 2.1.3.
We place ourselves again in the first case, using as observable. If we denote by xi the combination (also equal to ), the computation of Sect. 2.1.1 implies that xi values follow an exponential law, . In terms of this exponential distribution, δ−1 is interpreted as the scale (see Fig. 4). The ML estimator of the scale of an exponential is the mean of xi values, so we recover the expression from Sect. 2.1.2. From this point of view, a larger dimension just means a smaller scale for the exponential, which is why it is not much more difficult to measure.
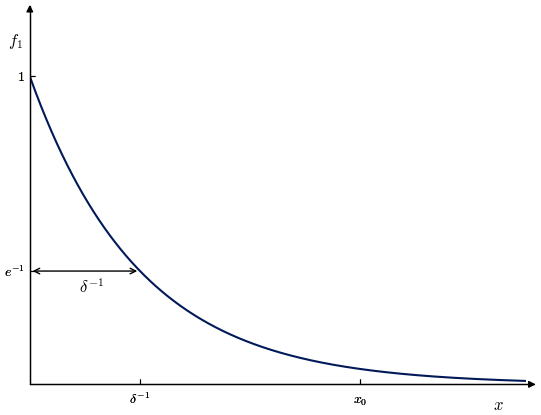
Let us write r0 for the smallest of ri values and for the biggest of xi values. One has obviously . If there are enough points to estimate δ−1, x0 must be quite far to the right of the plot in Fig. 4, so that a necessary condition is , or
This expresses that x0 has to be large with respect to the scale δ−1 of the exponential. Conversely, if s≫1, this means that the exponential has been sampled enough to get a high value for x (namely, x0).
One could think that the condition in Eq. (33) is actually easier to fulfill if the scale δ−1 is smaller (and the dimension bigger) because this leaves “more room” for x0. But this is not the case since a smaller scale means that the exponential has a higher peak near x=0, so it will be more difficult to have a sample x with a high value. This is consistent with the fact that the number N=C(R) of points inside B(R) (using the scaling C(R)∼Rδ and the fact that C(r0)=1 since r0 is the smallest of ri values) satisfies the following condition:
This equality shows that, for a fixed N, the ratio over which the scaling Eq. (3) holds quickly approaches 1 when δ increases. This is the price to pay to measure high dimensions with a reduced number of points, and this poses some difficulties when dealing with large systems (see Sect. 4).
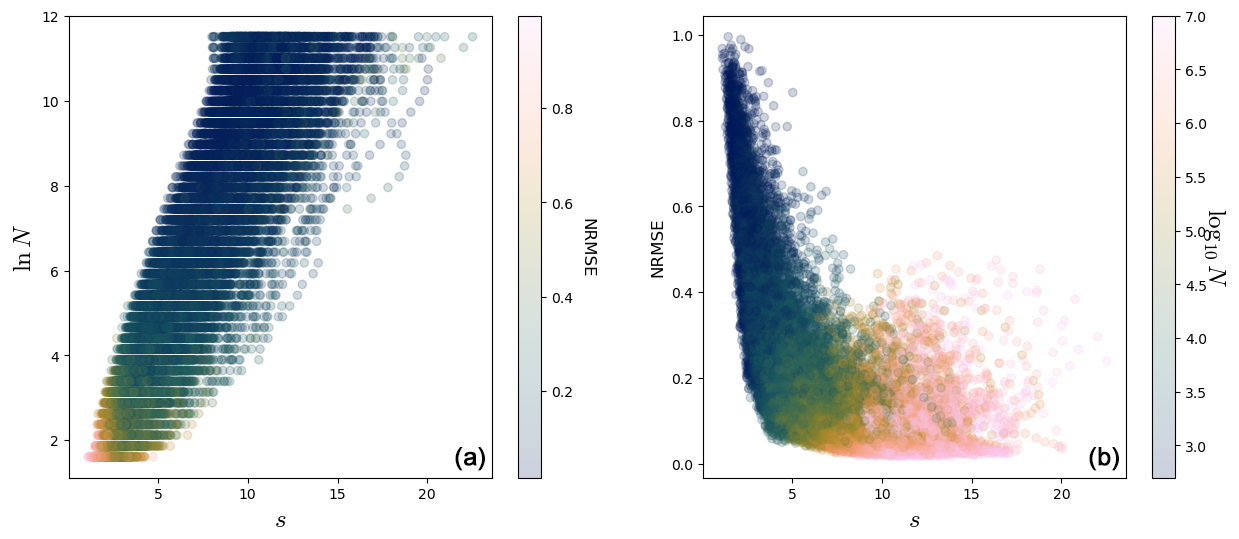
Figure 5For the Lorenz 63 system (see Appendix A) with ρ=28, 106 points. (a) Scatterplot of ln N against s. The color is the NRMSE of the fit. (b) Scatterplot of the NRMSE against s. The color is the base-10 logarithm of the number of points used in the exponential fit. There are 1000 points and 20 fits for each.
We address some remarks:
-
Using Eq. (34), one can see that s=x0δ should be just ln N and that the condition Eq. (33) is simply
In practice, the distributions are exactly exponential only in the limit R→0, so s and ln N are not exactly equal.
-
This equivalence between the estimation of different dimensions is because of the scaling transformation of the exponential distribution f1:
which makes the difficulty of measuring a high value of the dimension similar to the difficulty of measuring a small value. Again, in terms of an exponential distribution, the dimension is just the inverse of the scale of the exponential. The probability density functions and and adapted definitions of x in each case have similar scaling properties. These make it possible to absorb a redefinition of δ to redefinition of x if one uses or instead of .
-
If the EVT estimator for δ is able to produce a high value over some range, the estimation of the dimension through the correlation dimension can also do it. Indeed, in both cases, is obtained by somehow fitting the scaling C(R)∼Rδ. The limitation for the correlation dimension is the same as for the EVT dimension: when δ increases, the range over which this scaling can hold decreases.
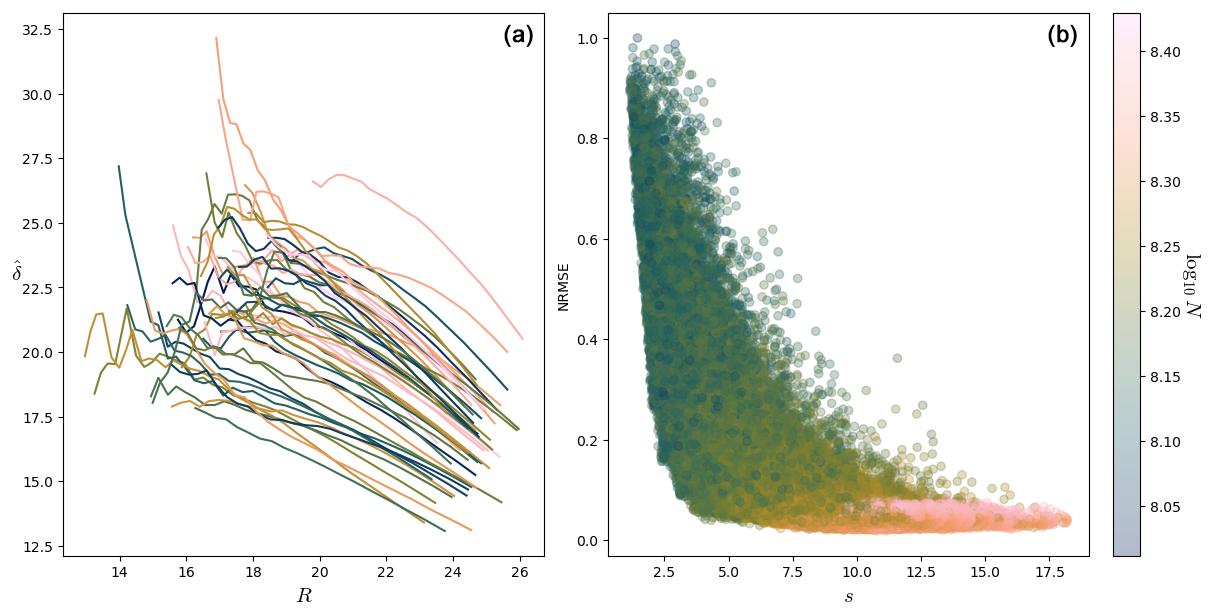
The left panel of Fig. 5 shows a scatterplot of ln N against s, with the color being the NRMSE score for dimensions in the Lorenz 63 system (see Appendix A about the Lorenz 63 system). Each point in both panels of Fig. 5 represents a fit. We computed the dimension for 1000 points for 20 different values of N, so there are 20 000 points in each scatterplot of this figure. A given computation point ζ in the phase space is therefore represented several times. One can see a rough agreement between ln N and s. Here and in the following, we compute s as .
The right panel of Fig. 5 shows a scatterplot between the NRMSE score and s for the Lorenz 63 system. The form of this plot is quite characteristic and is encountered several times in the rest of the paper. The NRMSE score clearly decreases as s increases: this part corresponds to fits increasingly better. When s>10, the NRMSE reaches a plateau. The NRMSE for some high values of s and N is not so good, that is, when the B(R) ball is too big and the distribution in it cannot be a power law (see Sect. 3.2). In practice, one finds that s bigger than 4–5 seems to give NRMSE scores below 0.4. Reliable fits can be selected by keeping, for example, only those for which s>5 and NRMSE < 0.4.
In summary, Sect. 2.1.3 shows that, for a given accuracy on δ relative to , all dimensions require the same number of points inside B(R). This might seem surprising because of the scaling C(R)∼Rδ but can actually be understood if we see δ−1 as the scale of the exponential distribution of g1 values. However, the range of values of R over which the dimension can be measured decreases with the dimension. This is why there is no contradiction with the original argument of Eckmann and Ruelle (1992), which supposed that R is fixed.
In the following analyses, we use scatterplots in the form of that of the right panel of Fig. 5. The rough agreement between s and ln N can be seen as a consistency check that the distributions of values of g1,i are indeed close to exponentials (and equivalently, that the distributions of ri are close to power laws).
2.5 Possible phenomena affecting the value of the dimension
The last few sections develop tools to quantify how good is a fit to the exponential law. However, even if the fit is good, different phenomena can affect for a given R.
If the NRMSE or s do not have good scores, the points in B(R) do not follow a Rδ law. The cause of this could be one of the following:
-
There are not enough points inside B(R) to properly recognize an exponential (and make out the difference with a uniform law, for example).
-
The points are not statistically independent, as in the example mentioned at the end of Sect. 2.1.3. This was already noted in Theiler (1990).
-
R is too big. To observe the C(R)∼Rδ law, one indeed needs to consider a flat neighborhood around ζ and, if R is too large, this law could be affected by the curvature (Perinelli et al., 2023) or by another geometric feature entering B(R). See Sect. 3.2 and Fig. 8 for an example of that.
On the other hand, if the NRMSE and s give good scores, this means that the number of points inside B(R) indeed follows a power law . This could have different causes, and a non-exhaustive list is as follows:
-
The estimated value of the dimension can indeed reflect the dimension of the surface supporting the neighboring points. This happens if the density of points is constant and the “surface” of the attractor is approximately flat.
-
If there is a clear structure of points in the phase space, with the density of points of this structure being higher enough than its surroundings, the estimated dimension will be that of this structure. This is because the intersection of such a structure with the ball B(R) will make the number of points scale as Rδ, where δ is the dimension of the structure. Such a situation is shown schematically in Fig. 6: in a plane, there is a straight line crossing B(R), and the density λ of points on that line is much higher than anywhere else in B(R). The number of points in B(R) will then essentially be the number of points on that line. A simple computation only taking into account the points of the line gives , and if a≪R (i.e., if ζ is close enough to the line), C(R)≈2λR. The scaling of C(R) around ζ becomes that of the line, even though ζ is not strictly on it.
The previous case and this one are cases where the estimated dimension is the dimension of some geometric structure in the phase space. This geometric dimension is only well defined for ranges of R where the geometry is homogeneous in this range: if the curvature changes or a different geometric feature enters B(R) for some value of R, one cannot give a geometric meaning to the dimension. It is only for the values of R for which there are clear objects that the dimension can be interpreted geometrically. In particular, one can approach the pointwise dimension in the limit R→0 only when R is below any other geometric scale. This is illustrated in the next sections.
Note that this kind of geometric dimension is conceptually equivalent to the one measured by local PCA techniques (such as in Little et al., 2017).
-
The fact is that C(R)∼Rδ supposes that the density of points is uniform in the range over which the estimation is done. If the density is increasing when getting away from ζ (i.e., for increasing r, Σ∼ra for a>0), the empirical histogram of the values of r will be inflated for values of r close to R. In that case, the estimated distribution will be closer to the dark blue curve than to the orange curve in Fig. 3, so the estimated dimension will be higher than the dimension of the surface supporting the points (the “geometric dimension”). In the same way, if the density of points decreases, the estimated dimension will be lower (see remarks in Sect. 2).
In practice, it is not likely that the density Σ will follow the same behavior (Σ∼ra) on a large range of values of r. The fit in this case is usually not so good, so the selection using the NRMSE and s (see Sect. 2.4) should discard some of them. One can also try to visually identify when this happens because the dimension fluctuates a lot.
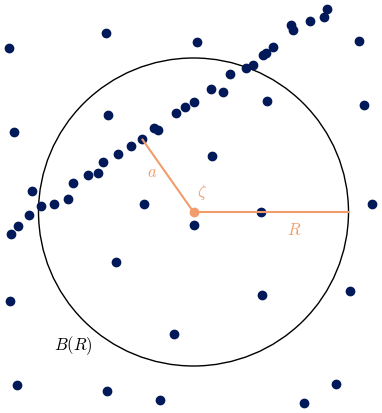
Figure 6Picture of a situation where almost all points on the attractor (in dark blue) lie in a line. If the density of points is constant and denoted as λ, the number of points inside B(R) is essentially . For a≪R, the estimated dimension will be 1.
Unfortunately, the tools we developed (the NRMSE and the quantity s) can produce good scores in all three above cases and do not allow us to make out the difference between each of these cases. One therefore has to keep in mind all possible phenomena affecting the estimation of the dimension and inspect the values of the dimension over some range of values of R in order to interpret properly the geometry of the system in this range.
In the following, as is usual when computing dimensions from time series, a Theiler window around each computation point ζ was applied (Theiler, 1986) in order to avoid having points too close in time inside the ball B(R).
To illustrate some aspects described in the previous sections, we compute the local dimension for small systems, allowing us to get some insight into what is captured by the estimated dimension.
The classical Lorenz 63 system for ρ=28 (Lorenz, 1963) is first considered. The relatively simple geometry allows us to illustrate some phenomena described in Sect. 2.5. We then present the results of the computation of the local dimension for the Lorenz 63 system with ρ=166.5, which is intermittent (Pomeau and Manneville, 1980; Sparrow, 1982). In the case of intermittent systems, a situation like the one displayed in Fig. 6 is often encountered, and the tools described in Sect. 2 can be used to detect structures in phase space.
3.1 How we choose the values of R
If we want to compute the dimension for different computation points ζ, it is difficult to choose relevant values of R for each of them if we do not know the system very well. Indeed, depending on the dimension and on the density of points, the values of R needed for B(R) to contain a sufficient number of points to estimate δ might be different for each computation point ζ.
An alternative approach is to compute the distance between the computation points and all other points of the trajectory and keep a given percentage q of points (i.e., consider to be extremes), common to all computation points. For each computation point ζ, R is then defined such that B(R) contains q % of the total number of points in the dataset (i.e., R is the qth percentile). For each computation point and for each percentage q for which we compute the dimension, there is thus one value of R. This has the advantage of adapting the range over which the dimension is computed accordingly to the computation point.
Of course, the percentile will not be exactly the same if one increases the length of the series. However, if the attractor has been reasonably sampled by Ntot points, additional points should spread in the phase space in the same proportions so that the percentiles computed with Ntot or should correspond. In other words, if the density of points is already close to the invariant measure of the attractor μ, the computed percentiles will not significantly change when the length of the trajectory is increased.
In the following sections, we use this method with chosen percentages evenly spaced on a logarithmic scale, typically with the maximum percentage being 10 % and the smallest percentage corresponding to five analogues. The dimension computed with 5 points will not give a precise value (see Sect. 2.1.3), but this allows us to ensure we have a dimension computed over a sufficiently large range of values of R. The values of the dimension with not enough points are filtered out through the computation of s and of the NRMSE score.
In Sect. 3.3, we also choose the values of the radius R rather than computing it as percentiles because it will be easier to illustrate the interpretation of the dimension in this case.
3.2 Lorenz 63 with ρ=28
We start with the usual Lorenz 63 system with ρ=28 (see Appendix A), and we consider two different trajectories: one with Ntot=104 points and the other one with Ntot=107 points. Figure 7 shows the repartition of the dimension on the attractor. The dimension is computed with q=10 % (Fig. 7a and b) and with q=1 % (Fig. 7c and d) for these two trajectories. For q=10 %, the two plots look the same, and the dimensions agree between the two datasets. This is because 10 % of 104 is already enough points to estimate the dimension, and adding more points to the dataset will not change the percentiles nor change the distribution of points on the attractor. Note that the points “on the border” of the attractor have higher dimensions since, from their point of view, the density of points is increasing. The estimated dimension for these points is actually an effective dimension reflecting this feature (see Sect. 2.5).
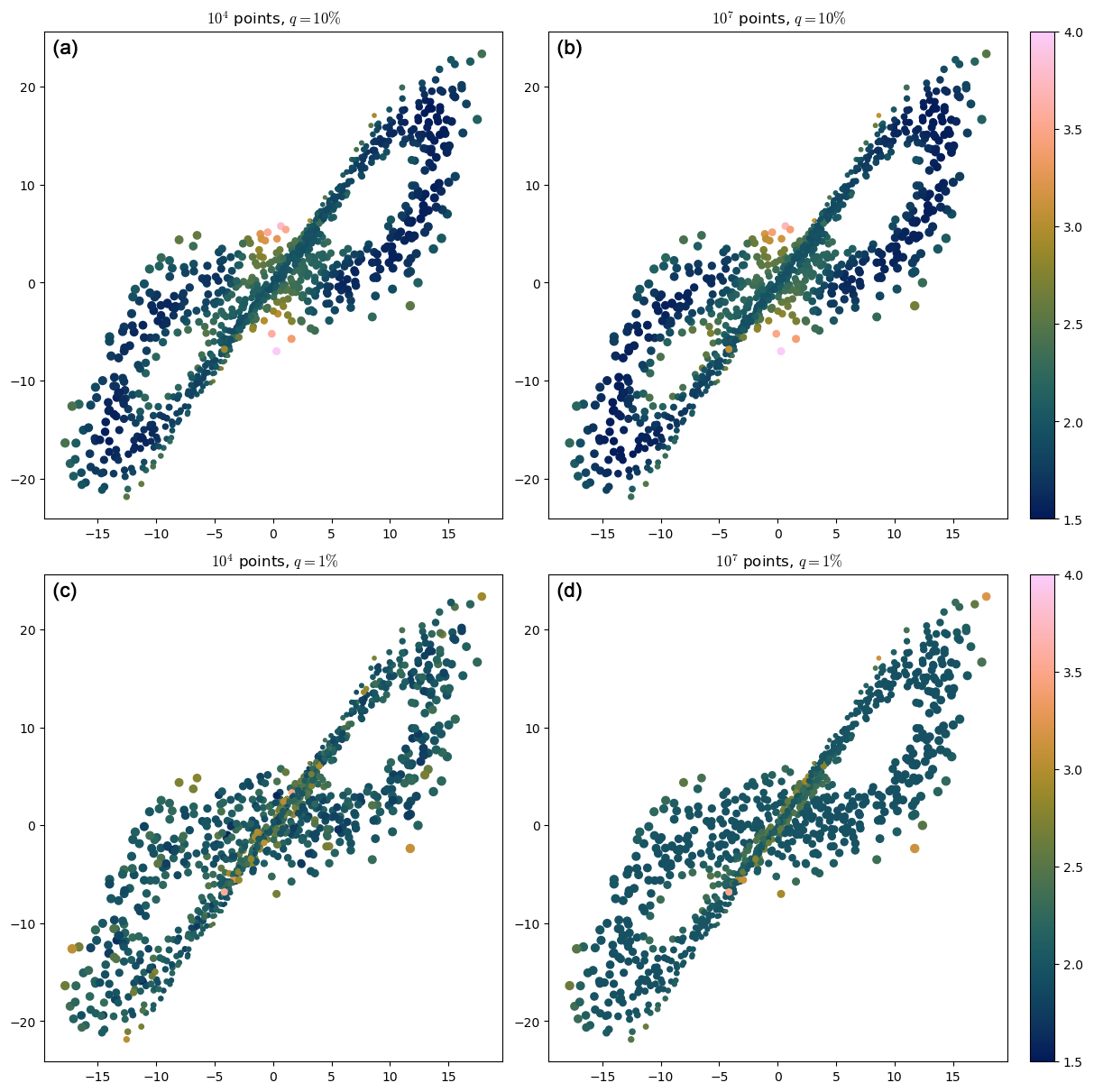
Figure 7The Lorenz 63 attractor, with the dimension represented in color, computed with 10 % (a, b) and 1 % (c, d) of the points in each case (only the 1000 points for which the dimension is computed are represented).
On the other hand, for q=1 %, there are not enough points in the Ntot=104 dataset (Fig. 7c) to have a proper estimation of the dimension, while the Ntot=107 dataset (Fig. 7d) still allows for a proper estimation of the dimension. The latter gives more homogeneous values of the dimension than are in the corresponding plot (Fig. 7b) with 10 % of the points. This is because the values of the percentiles are smaller, so the estimation is more local and the density less varying in the balls B(R).
It is also interesting to analyze the histograms of the dimension for the dataset with 107 points for q=1 % and q=10 % (Fig. 8a): a lot of points have a dimension close to 1.5 for q=10 %, but most points have a dimension close to 2 for q=1 %. This is because, in the q=10 % case, R is too large for some points: 2R is larger than the width of the wings of the attractor, so the C(R)∼R2 cannot hold. The two bottom scatterplots of Fig. 8 illustrate this. In the q=1 % case, R is smaller, and this never happens.
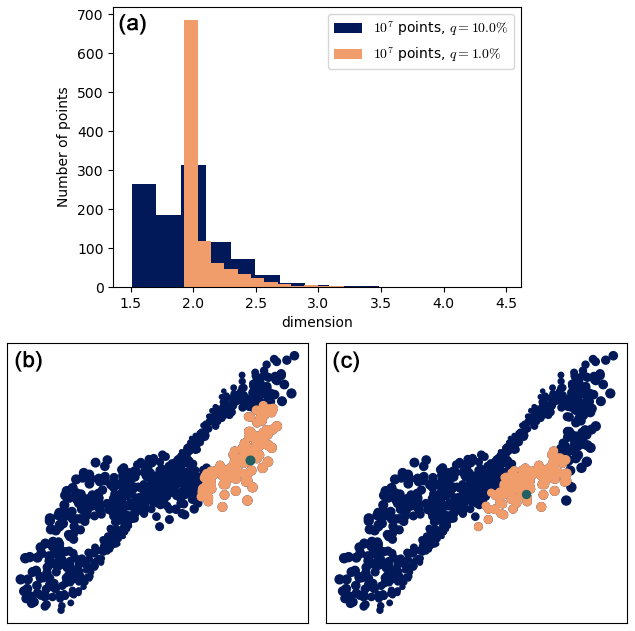
Figure 8(a) Histograms of the dimension for the dataset with 107 points for q=1 % and q=10 % (1000 values in each case). (b, c) Two illustrations showing that R can be too large for q=10 %. The computation point ζ is in green, and some of the points used to compute the dimension are in orange. The ball B(R) is bigger than the width of the wings, so the C(R)∼R2 characteristic of a surface cannot hold.
It is likely that, when decreasing q and increasing Ntot again in order to keep N=qNtot big enough, the dimension for all points will tend to a common value. This seems to be in agreement with the mentioned asymptotic results that the dimension of almost all points converges towards a unique value.
Indeed, as observed in Fig. 7, the dimension of the points on the wings seems to converge to some value close to 2, which is as expected for a surface. As q decreases and Ntot increases, the dimension of the points on the “border” of the attractor will behave as other points on the wings, and their dimension would converge to the same value close to 2.
The points close to the intersection of the wings have a dimension bigger than 2 as long as their balls B(R) include this intersection. However, when q is decreased, the balls B(R) might not enclose the intersection anymore. The neighborhoods of those points then look as that of any other points on the wings, so their dimensions will be close to 2. Only the points exactly at the intersection will always have a B(R), including this intersection, so their dimension will never approach 2.
The left plot of Fig. 9 displays the dimension estimate as a function of R. There is a range of values for which the is close to 2 for all points. The curves with a bump in the middle of the range of values of R correspond to points near the intersection of the wings.
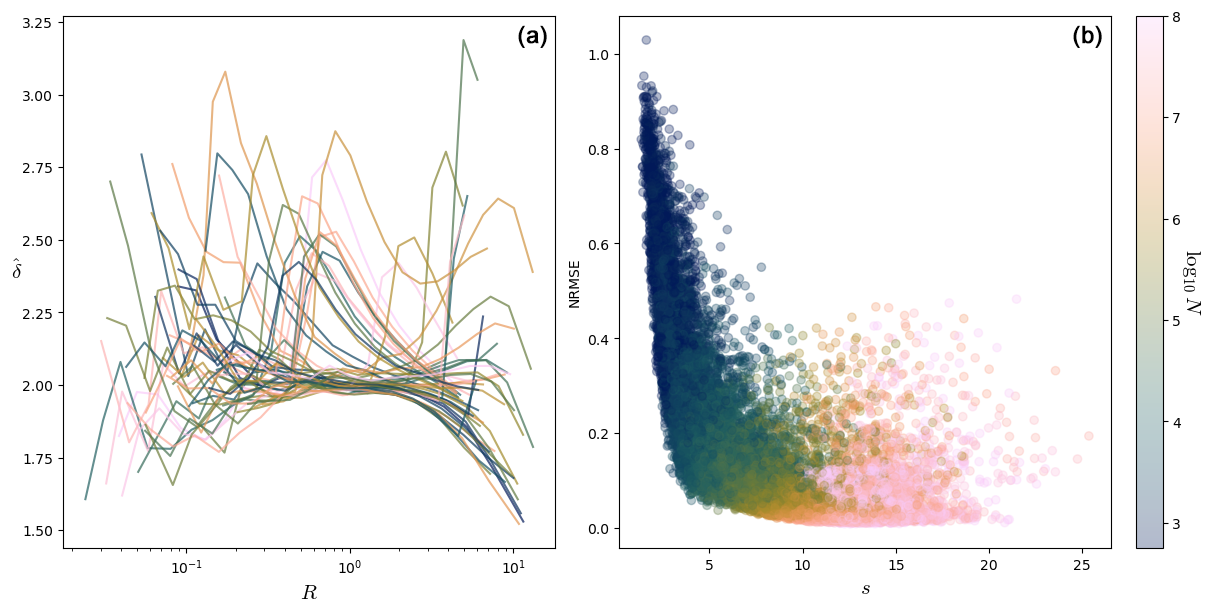
Figure 9(a) Plot of vs. R for 50 points of the Lorenz 63 system (ρ=28) with a trajectory of 107 points. Only fits with NRMSE < 0.4, s>5 are plotted. (b) Scatterplot of NRMSE vs. s for the same dataset but for all 1000 computation points. The color represents the logarithm of the number of points used in the dimension estimation.
As one can see in the right panel of Fig. 9, some points with a high value of s and a high number of points used in the estimation of δ, have a poor NRMSE score (i.e., up to 0.4, while most of the fits with s>10 have their NRMSE score below 0.2). Those correspond to situations shown in the bottom plots of Fig. 8, where the fit is not so good anymore.
3.3 Lorenz 63 with ρ=166.5
The results of the local dimension applied to the intermittent Lorenz 63 system with ρ=166.5 are now analyzed (see Appendix A for a short presentation of this system). The case of intermittent systems is interesting since those systems have a strongly inhomogeneous phase space, allowing us to illustrate how the dimension can have different values at different scales R. Intermittent systems are also of special interest since the primary goal is to use the local dimension of the rain data, which is known to be intermittent.
This system was integrated for ρ=166.5 to obtain 106 points on the attractor, and the dimension was computed for 1000 points. The plot of the dimension against R (computed as percentiles) is in the left panel of Fig. 10. One can see that, for the smallest values of R, the dimension is around 2, while it is closer to 1 for the highest values of R.
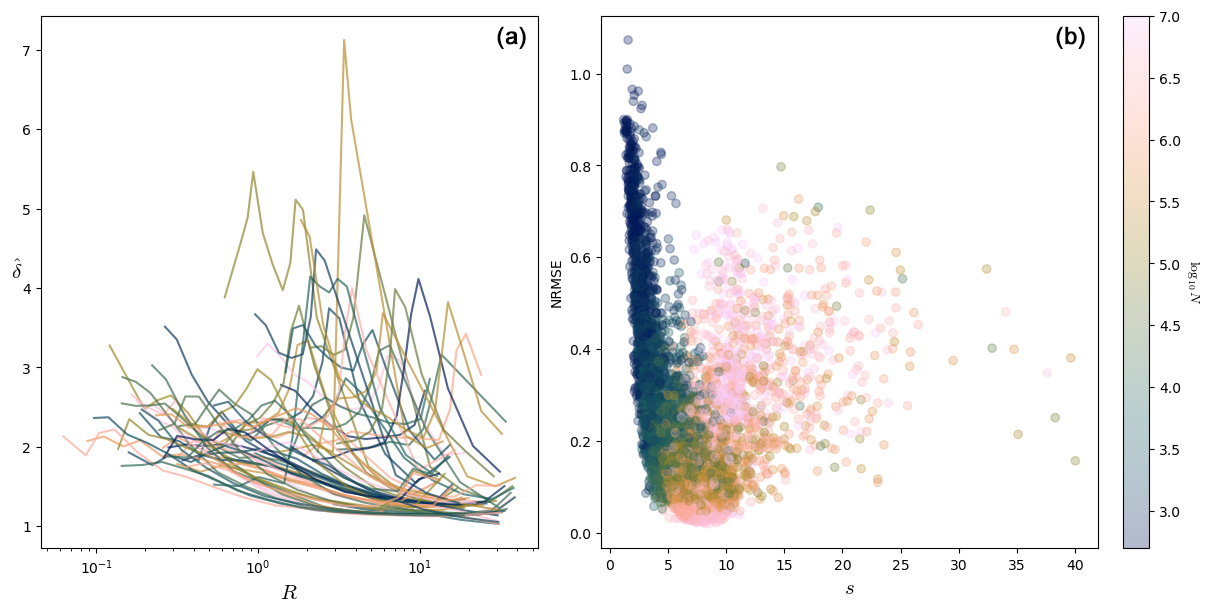
Figure 10(a) Estimated dimension against R for 100 points of the intermittent Lorenz 63 system (ρ=166.5, trajectory of 106 points). Only fits with NRMSE < 0.4 and s>5 are shown. (b) Scatterplot of NRMSE vs. s (all fits).
Actually, the remainder of the attractor before the bifurcation (see Fig. A1) defines a 1-dimensional structure in phase space. This structure is a closed loop and is made of the points in the laminar regime of this intermittent system. We expect that in the balls B(R) intersecting this closed loop enough, the scaling will be strongly influenced by this closed loop (as described in Sect. 2.5). A better insight into the behavior of the dimension with R than that given by the left panel of Fig. 10 can be gained by characterizing each point by its position with respect to this closed loop.
To do so, we select a part of the trajectory where it seems regular and almost periodic and integrate this part of the trajectory with a very small time step. We then take this as a representation of the laminar regime. Of course, this part of the trajectory is not strictly periodic, so choosing different parts of the trajectory will lead to slightly different representations. This representation allows us to define the “laminar distance” for any point ζ in the trajectory as the smallest of the distances between ζ and all points in the representation of the laminar regime. From a dynamical point of view, points with small laminar distances will be considered points in the laminar regime, while points with a significantly nonzero laminar distance can be considered chaotic points.
Figure 11 shows the dimension as a function of the laminar distance for that point. More specifically, six values of the radius R () are chosen, and the dimension for 1000 points is computed. Each panel corresponds to a specific radius R. In addition, the vertical red line marks where the laminar distance is equal to the radius R used in this plot.
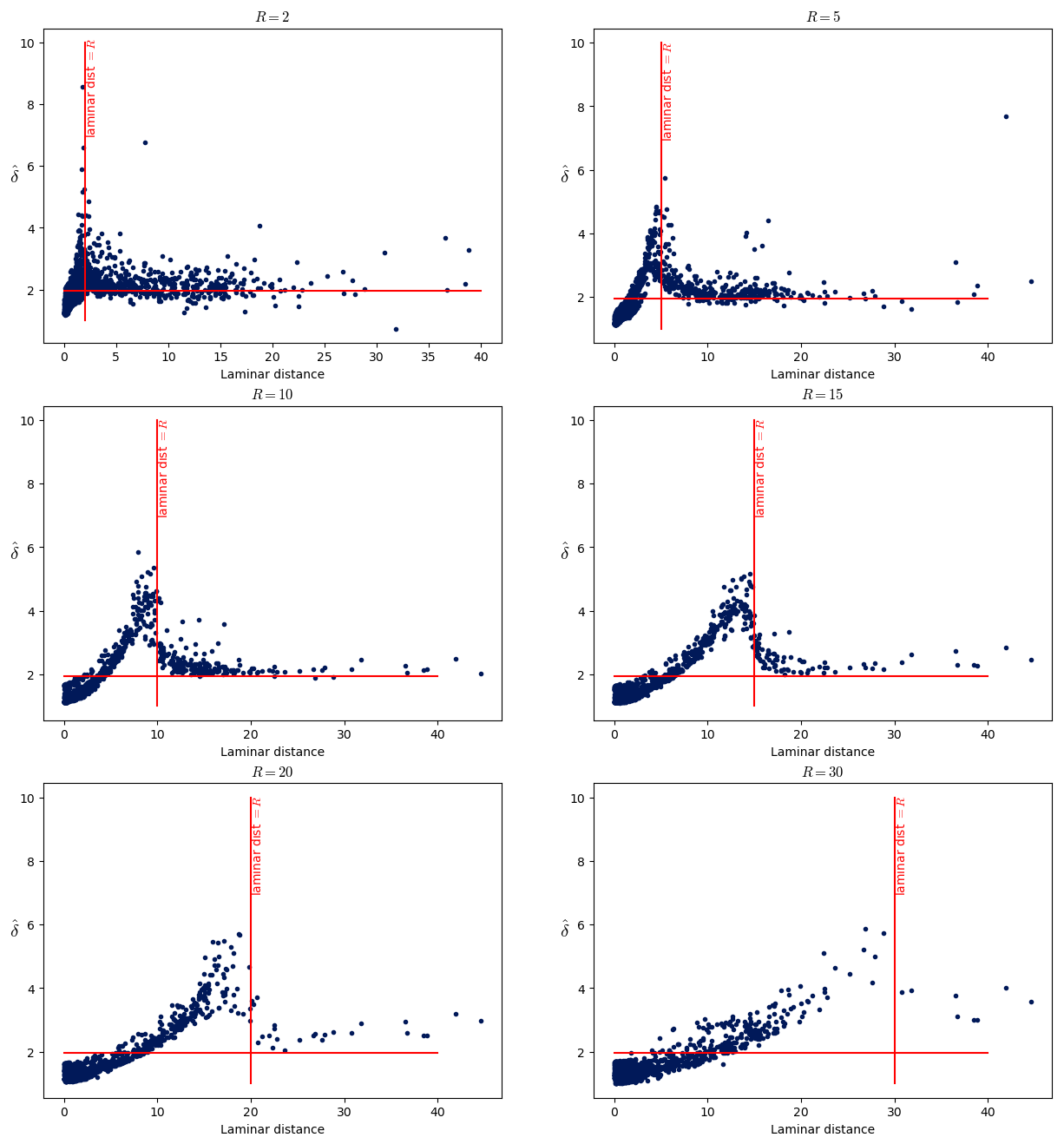
Figure 11Scatterplots of the local dimension in terms of the laminar distance. In a plot, all the dimensions have been computed with the same radius R (the value is above the plot). The horizontal red line marks the dimension value equal to 2, while the vertical red lines mark the value of the laminar distance which is equal to the radius R.
One can see from Fig. 11 that the dimension peaks for points whose laminar distance equals R. In other words, from the point of view of a given point, the following applies:
-
When R is smaller than the laminar distance, the dimension is around 2.
-
When R equals the laminar distance, the dimension has a peak.
-
When R is bigger than the laminar distance, the dimension decreases between 1 and 2.
The fact that there is a peak in the dimension when R equals the laminar distance can be understood by noting that it corresponds to the entrance of the laminar structure in the B(R) ball around the computation point ζ. There are suddenly a lot of points in the ball, near the boundary of the ball, so the distribution of points in B(R) resembles the dark blue curve more than the orange curve in Fig. 3.
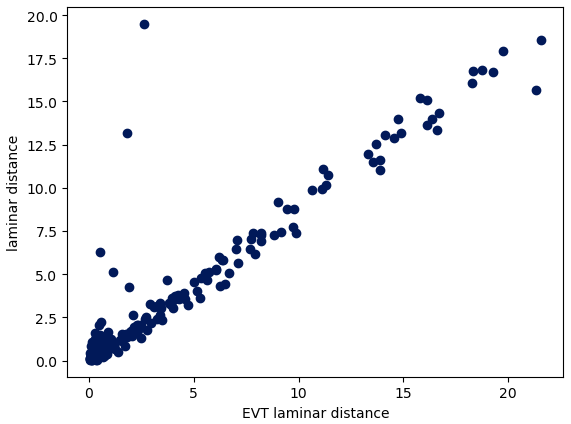
Figure 12Comparison of the EVT laminar distance with the laminar distance for the intermittent Lorenz 63 (ρ=166.5). The EVT laminar distance is computed as the distance for which the dimension is maximum (see text).
When R is bigger than the laminar distance, the situation becomes similar to the one in Fig. 6, and the dimension becomes closer to 1. The dimension is 1 only if R is sufficiently bigger than the laminar distance (i.e., R≫a in Fig. 6), which can happen only for points sufficiently close to the laminar regime. For other points, other parts of the loop forming the attractor in Fig. A1 would enter the B(R) ball and modify the scaling, or the curvature effects become too important. In those cases (when R is bigger, but not much bigger, than the laminar distance), the distribution of points in B(R) is not close to a power law, so the exponential fit is not appropriate.
When computing the dimension in the asymptotic limit R→0, the radius R should be below any other geometric scale around the computation point ζ. For the chaotic points, this geometric scale is, in this case, their laminar distance, while for laminar points, the geometric scale is the “width” of the laminar structure in phase space.
As a consistency check for that interpretation, we tried to estimate the laminar distance for each of the 1000 computation points as the value of the radius R for which the dimension is maximum. To achieve this, we used the values of the radius R computed as percentiles and the corresponding dimensions. In order to use only meaningful values of the dimension, for each computation point, we restricted the dimension to the range of values of R where NRMSE < 0.5 and s>4. We rejected all estimations where the maximum was found on one of the ends of this range because this points to the fact that the true peak of the dimension is maybe outside of the range of values of R we have for these points. Because of that, the laminar distance could be estimated for only one-fourth of the 1000 computation points. The scatterplot in Fig. 12 shows the comparison of the laminar distance with this estimation of the laminar distance using EVT (which we call the EVT laminar distance).
Note that the EVT laminar distance tends to be bigger than the laminar distance itself. This is because, if R is precisely equal to the laminar distance, there are not enough points in B(R) for to really be influenced. R has to be a little bigger than the laminar distance for to really increase, and the peak of is for values of R that are a little bigger than the laminar distance.
We carried out the same analysis on two other intermittent dynamical systems: the Lorenz 96 system with n=4 variables for F=11.87 and the Lorenz 96 system for n=12 variables for F=4.4. Figures similar to Fig. 11 for those two systems are displayed in Appendix B.
In this section, we present the results of the computation of the dimension for two large systems: the Lorenz 96 system with n=50 dimensions and the RADCLIM dataset (radar images of the precipitation field).
4.1 Lorenz 96, n=50
The Lorenz 96 system (see Appendix B for a brief description) with n=50 dimensions was integrated for 106 time units, with a time step of dt=0.1, for two values of the parameter: for F=4.9 and for F=6. Each of the two trajectories has 107 points. The radius R values were computed as percentiles, and the corresponding estimates of the dimension were computed in each case.
The results for F=6 are presented in Fig. B3. Our method suggests that there are no salient geometric structure in phase space for that parameter value. We focus now on the F=4.9 case.
The right plot of Fig. 13 shows as expected that the NRMSE score decreases when s increases. The left panel of Fig. 13 shows the estimated local dimension against the radius R of the ball for 100 points in this system. We selected the points for which the NRMSE is smaller than 0.4 and s>6.
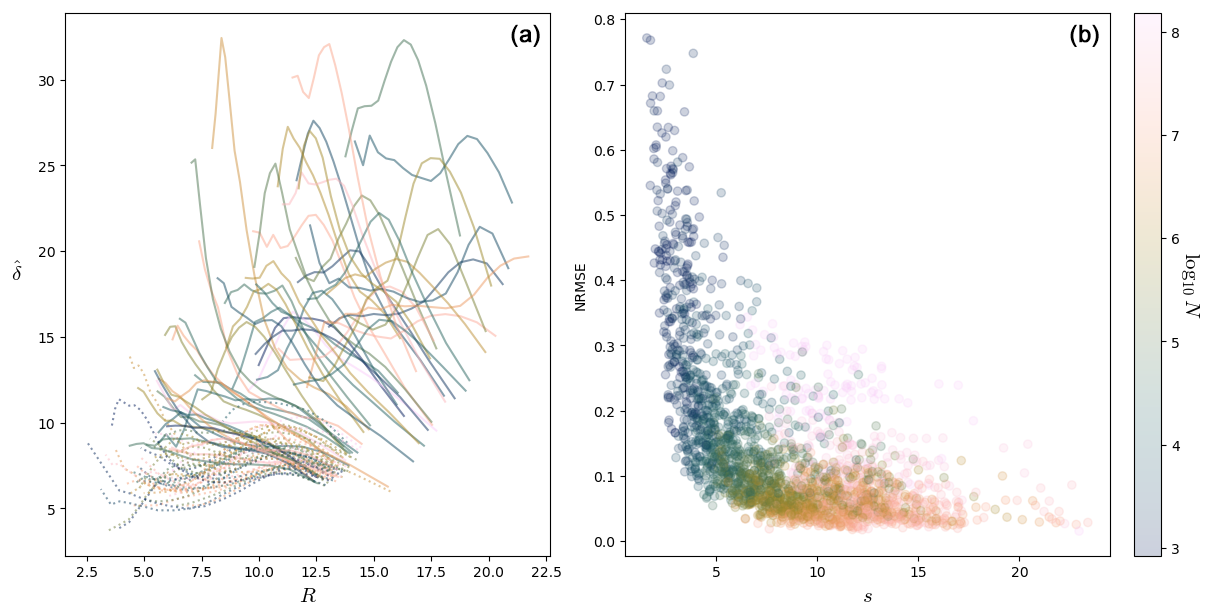
Figure 13(a) Plot of the dimension against the radius R for 100 computation points for Lorenz 96 with n=50 and F=4.9. Only fits for which NRMSE < 0.4 and s>6 are shown. The dotted lines detect a structure, and the corresponding points are part of that structure. (b) Scatterplot of the NRMSE vs. s for the Lorenz 96 system with n=50 and F=4.9, with log 10N in color.
One can see at the bottom of the plot a set of curves with a small maximum for radii between 8 and 12 and maximum dimension smaller than ∼12 (dotted curves). These points seem to detect a structure of points at a distance of 10–12 from them. If there was such a structure at that distance, we would see other curves with maxima for small values of R for the points which are part of this structure as for the intermittent Lorenz 63 in Sect. 3.3. Since there are no such curves because the dotted curves look quite regular and also because they correspond to a great proportion of all the curves, we can think that the points corresponding to these curves are part of the detected structure. In other words, the dotted curves correspond to points which are part of the structure that these curves detect. Geometrically, the points of these curves have a similar role to the laminar points of Sect. 3.3.
To understand how a structure can be detected by the curves of the points which are part of that structure, consider points uniformly distributed on a circle of radius . From the point of view of a point on the circle, the number of points at a distance < R grows as . This curve is the steepest when R approaches , so the fitted δ would have a peak for . This peak is analogous to the peak of the dotted curves in the left plot of Fig. 13.
The curves which are not in this set are much more diverse. They all start at a higher value of the radius, which is because the corresponding points are in less dense parts of the phase space. Typically, their starting value of is also higher, and this is because the density of points around those points typically increases. This leads to artificially high values of δ (see δeff of Sect. 2.5). Some of these curves have a bump: these could be because the structure described above enters their ball, and the radius for which this happens would then be the distance of the corresponding points to the structure (laminar distance of Sect. 3.3).
To further clarify this viewpoint, a trajectory of this system with 105 points was generated and the dimension is computed for all points. The 105 points were labeled as either laminar or chaotic, with the following steps:
-
restricting the curve for radii R>8;
-
looking for the maximum of this restricted curve;
-
if this maximum is not at the ends of this curve, and if the value of the dimension at the maximum is smaller than 12, labeling the point as laminar.
Points not labeled as laminar are labeled as chaotic. Note that the laminar/chaotic points are not necessarily laminar/chaotic in the context of chaotic intermittency in dynamical systems, but we use this terminology to distinguish between points with different dimension characteristics.
If the points we have labeled as laminar indeed form a geometric structure in phase space, the distance of chaotic points to this structure should correspond to a maximum of the dimension. Therefore, we proceed as in Sect. 3.3; for each chaotic point, we do the following:
-
We define the laminar distance as the minimum distance between the point and all the laminar points. (In other words, we use the set of points labeled as laminar as a representation of a laminar regime.)
-
We define the EVT laminar distance as the radius R, giving the maximum dimension.
If our above labeling of laminar and chaotic points is meaningful, the two distances should agree. As shown in the scatterplot of Fig. 14, there is a good agreement, and we take this as a consistency check of our interpretation of the curves in the left panel of Fig. 13.
Figure 14Scatterplots of the two ways to compute the distance to the laminar structure for chaotic points.
Note that, for 32.8 % of the chaotic points, no distance could be computed using the second method (for the same reason as in Sect. 3.3). Also, the fact that we find a structure in phase space, analogously to the laminar structures of the previous sections, points to the fact that the Lorenz 96 system, with n=50 dimensions for F=4.9 could be in an intermittent regime.
To summarize, we computed the dimension in this high-dimensional system and, as shown in the previous section, Sect. 3.3, the dimension highly depends on the radius R used to compute it, but this can be used to obtain some characterization of the geometry of the phase space: some points of the attractor are collected in a structure, much as the laminar points in Sect. 3.3. The distance from the other points to this structure can be estimated.
4.2 RADCLIM dataset
We now present the results of the computation of the dimension for the RADCLIM dataset (see Appendix C for a description). Before computing the dimension, the images were upscaled to 14 px × 14 px for two reasons. The first is that the whole dataset is then obviously easier to work with. The second is based on the hope that the upscaled images would define a reduced and less complex attractor within a reduced phase space.
The upscaling to 14×14 images was done by averaging the neighboring pixels, after the log transform of the rain rate. This is a way to take into account the multiplicative structure of the rain (Veneziano et al., 2006; Seed, 2003; Lovejoy and Schertzer, 2013) during the upscaling. As in Pulkkinen et al. (2019b), the zeros were transformed to −15 in logarithmic scale (dBR).
The geometry of the phase space defined by these images is quite particular. The value of each pixel is taken as an axis in phase space, which is therefore a 14 px × 14 px, i.e., 196-dimensional Euclidean space. Since the minimum value for all pixels is −15 dBR, the phase space is actually restricted to the orthant , …, 196. The point corresponds to images without any rain, which we call the dry event. There are 7150 such images (1.13 % of all 630 008 images). Even among images with rain, most of them are close to the dry event. The histogram in Fig. 15 shows the distribution of all distances to the dry events (including the dry events themselves).
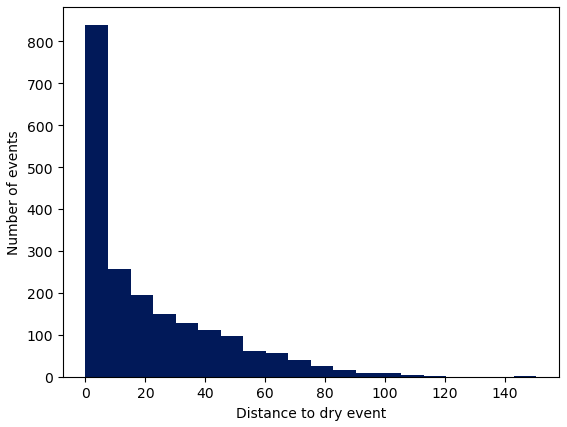
This histogram shows that the density of points in the phase space decreases very quickly when getting away from the dry event. As a comparison, if the density of points ρ was constant in the phase space, the number of points whose distance to the dry event is between r and r+dr would be . This means that the heights of the sticks in this histogram would grow as r195, which is radically different from what is observed. The relationship between distances and volumes in high-dimensional spaces can be quite different from our 3-dimensional intuition.
For 2000 computation points, the dimension was computed for 40 different values of R. As before, 40 percentages were fixed (exponentially spaced between % → 5 points and 10 % → 63 000 points), and the radius R values were chosen to correspond to the percentiles among all distances. Figure 16 shows the computed dimension as a function of the radius R for 100 points: the left plot has a logarithmic scale for R, and the right plot has a linear scale for R, allowing us to see the plot for small R values or for large R values more clearly. The color represents the base-10 logarithm of the averaged convective rain rate (see below).
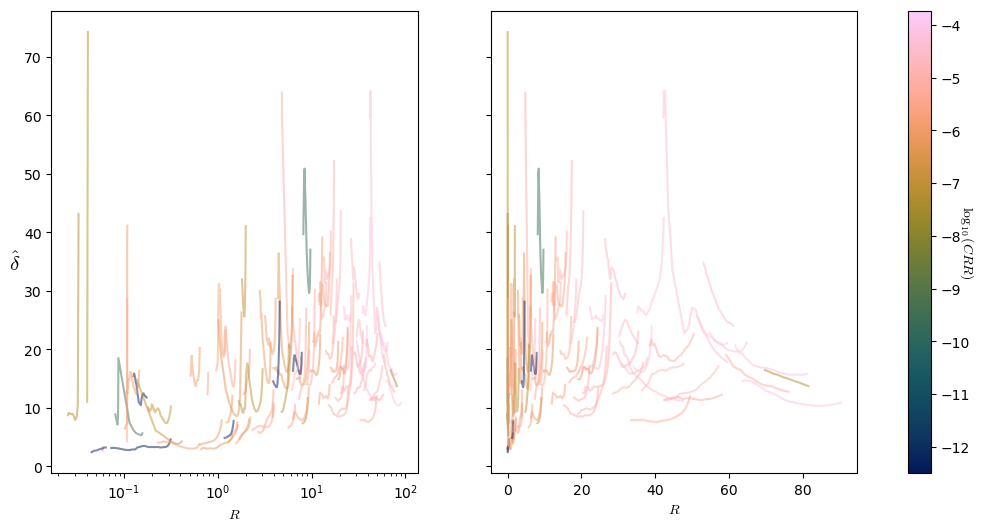
Figure 16Plot of the dimension against the radius (in dBR) for 100 points for the RADCLIM data (NRMSE < 0.4 and s>5). The color is the base-10 logarithm of the convective rain rate (CRR) in log mm s−1.
For some of the 2000 points, there is a bump in the dimension, which would point to the existence of some structure. We tried to apply the same procedure as in Sect. 3.3 to compute the distance to the laminar regime. The procedure allowed us to get a laminar distance for only 487 out of 2000 points (for the same reason as in Sect. 3.3: we discarded the estimation if the maximum dimension is on one of the ends of the range). It turns out that the laminar distance computed in this way is highly correlated to the distance to the dry event: see Fig. 17. As a consequence, the points labeled as laminar would simply be the dry events. The laminar distance as defined in this way does not really seem to contain any additional valuable information than the distance to dry events.
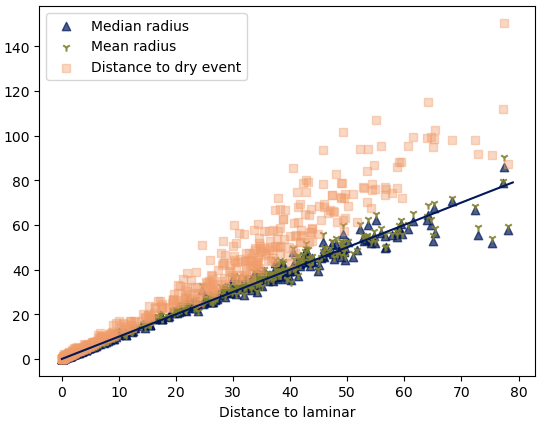
Figure 17Scatterplot of the laminar distance (in dBR) on the x axis, with the median radius, the mean radius and the distance to the dry event on the y axis (all in dBR).
In order to check if there is any valuable information in the set of values of R for any computation point, we looked for a way to aggregate the 40 values of R we have for each computation point and considered the mean and the median of R for all computation points. Note that these quantities obviously depend on the way the percentages to compute the dimension for were chosen. Because of that, one could think that these mean and median values would not be very informative. These values are, however, relatively stable: we ensured, for example, that they do not change much if we use the 10 smallest radii for each point instead of the 40 we have. This is because the extent of the range of values of radii we have for one computation point is small with respect to the actual values of the radii. This is also why the mean and the median do not differ much and why they give a measure of the relevant values of the radius for each point. Figure 17 shows that there is a correlation of these two quantities (mean and median radii) with the laminar distance and the dry distance. This shows that these four quantities (median radius, mean radius, laminar distance, dry distance) are essentially the same.
We see here the difficulty in working with high-dimensional systems, as discussed in Sect. 2.4. The particular geometry of this phase space worsens the situation even more because most of the points are collected near the dry event, as shown in the histogram in Fig. 15. Because of this, the dimension for all points can only be reliably computed on quite small ranges of values of R. For example, the points for which the curves are on the left of Fig. 16 often have an R value approximately within [30, 40] dBR. This is too small of a range of values of R to properly interpret the computed values of δ. The same happens for the points for which the curves are on the right of the figure: they often have an R∈[80, 100] dBR.
We used the convective available potential energy (CAPE), the convective rain rate (CRR) and the convective precipitation (CP) data from the ERA5 reanalysis to compare with the quantities computed in the phase space. For the region covered by the RADCLIM dataset, they come as 26 px × 41 px images with a 1 h resolution. We computed the mean of these images in order to have one value for each hour. For each of the 2000 computation points, we associated the closest (in time) available value of the CAPE, the CP and the CRR. As suggested by the color grading in Fig. 16, one can find a correlation between the mean radius, the dry distance or the laminar distance on the one hand and the CRR on the other hand: Fig. 18 shows the corresponding scatterplots for the 2000 images.
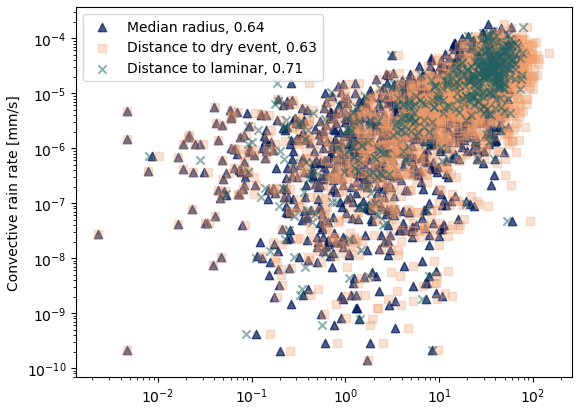
Figure 18Scatterplots of the mean radius, the dry distance and the laminar distance (x axis, all in dBR) with respect to mean convective rain rate (CRR) (y axis). The numbers in the legend are the correlation coefficients of the base-10 logarithm of each of these distances with log 10(CRR).
Results with the CP instead of the CRR are very similar, while the correlations with the CAPE also exist but are not as good.
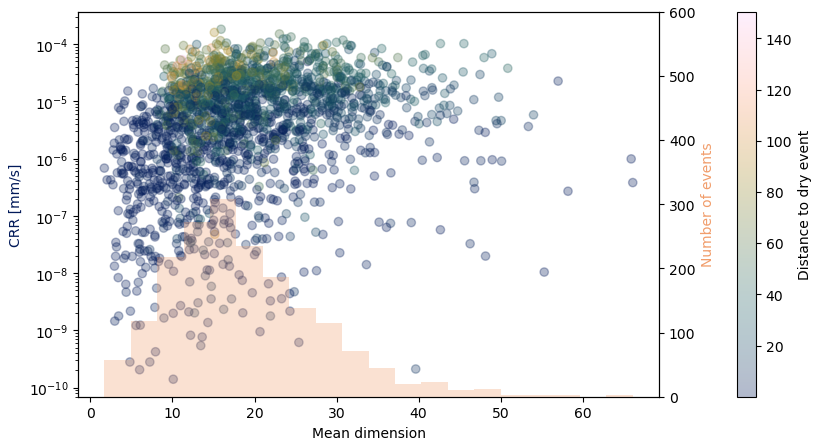
Figure 19Histogram of the repartition of the mean dimension for our 2000 computation points (in orange) and scatterplot of this mean dimension with the CRR (in color scale). The color is the distance to the dry event (in dBR).
The correlation of the CRR is the highest with the laminar distance, but this is because of the restriction to some points. The laminar distance could indeed be computed for only 487 points out of 2000, while the mean radius and the dry distance can be computed for all the points. If we restrict the computation of the correlation between the CRR and the mean radius to the points for which a laminar distance was computed, one gets a correlation of 0.70. The same happens for the correlation between the CRR and the dry distance.
We also checked if some information can be extracted from the mean value of the dimension: for each image, we computed the mean of the dimensions resulting from fits whose NRMSE score was below 0.4 and s above 5. Figure 19 shows the histogram of the repartition of this mean dimension for our 2000 computation points (in orange) and the scatterplot of this mean dimension with the CRR (in color grading from dark blue to orange). A complementary two-dimensional histogram of the mean dimension to the CRR is shown in Appendix C (Fig. C1).
A few things can be noted here:
-
The histogram has a nice peak around a mean dimension of 15–20.
-
The relationship with the CRR is not very clear except the fact that there is generally less variability in the CRR when the dimension is higher.
-
As expected, images that are farther away from the dry event have a higher CRR, but those images do not have the highest values of the mean dimension: their mean dimension is rather between 10 and 20.
-
When the mean dimension is below 10, the distance to the dry event is always relatively small. On the other hand, for big enough distances, the dimension is always above 10. This can also be seen from Fig. 16, taking into account that the distance to the dry event is almost the same as R.
To summarize, this analysis of the results of the computed dimension for the RADCLIM dataset shows that it is possible to reliably compute the dimension for some points and for some radius R values, but the results are quite difficult to interpret. This is essentially because of the limited number of data with respect to the number of dimensions at play. The estimated local dimensions range between 10 and 30, with a peak around 15–20. Not surprisingly, we observed a link between the convective rain rate and the distance to the dry event.
As emphasized in the introduction, results on the local dimension of attractors of dynamical systems predict that almost all points have the same dimension in the asymptotic limit of an infinite number of points and an infinitely small radius R. Because these limits are impossible to reach, we studied the behavior of the local dimension for finite R and showed that it allows us to detect geometrical structures in phase space of chaotic dynamical systems. The main visible feature of this detection is that the dimension has a peak for the value of R corresponding to the entrance of a geometric structure inside B(R).
When working with such tools, one always faces the question of whether the estimation of the dimension is reliable or not. This question is linked to that of the maximal dimension that one can estimate with a given number of points inside B(R). We systematically used the NRMSE score and the quantity s to tackle this problem. The development leading to the definition of s shed some light on the problem of the maximal measurable dimension using EVT techniques. This gives some falsifiability methods, which were lacking before, as was noticed in Datseris et al. (2023).
In short, the dimension is estimated as the exponent of the power law C(r)∼rδ over some range [0, R]. If the NRMSE score is good enough, a 10 % accuracy for δ relatively to is achieved with N≳400 points. However, a high exponent in the scaling C(r)∼rδ (i.e., a high dimension) will not be visible over a long interval [0, R] if there are not enough points. This is why high dimensions may be estimated, but only on limited ranges. There is no contradiction with the argument of Eckmann and Ruelle (1992): for a fixed range [0, R], the number of points needed to measure a dimension indeed grows exponentially with the dimension. The same applies for the correlation dimension: for a fixed number of points, higher dimensions can be measured if the range [0, R] decreases.
As shown, the dimension depends on the finite radius R of the ball B(R) used to compute the dimension. This implies that one cannot simply choose some small percentage (as 2 % or 5 %), compute R as the corresponding percentile and get a unique value for the dimension. In fact, different finite values of R may lead to very different values for the dimension.
To understand what is captured by the computed dimension at a given scale R, one has to compare R with the other local geometrical scales on the attractor. In this work, these scales were mainly set by some geometrical structures, but Perinelli et al. (2023) showed that the curvature could also set some scale, and the idea that the scale of the noise could play a role was raised by Little et al. (2017). We also identified that estimations of the dimension can be affected when the density of points is not constant. This often leads to an overestimation of the dimension. The value of the dimension for a given R can be affected by other phenomena as well, and it is important to recognize which ones are at play to correctly interpret the dimension.
For the RADCLIM dataset, one difficulty is that the number of points is rather limited so that, for each computation point, values of the dimension could only be computed in a very limited range of values of R. This was expected from the analysis of Sect. 2.4, and this makes the interpretation of the value of the dimension for this high-dimensional system difficult. Some interesting conclusions could, however, be gathered from the analysis, in particular that the range of dimension is between 10 and 30 with a peak at 15–20.
There exists other ways to compute the local dimension, such as the Lyapunov dimension (Kaplan and Yorke, 1979; see Ott, 2002, for a textbook review) and the dimension induced by the delay coordinate method (delay embedding dimension, Packard et al., 1980; see Abarbanel, 1996, for a textbook review). The dimensions estimated using the correlation dimension, which we argue is conceptually equivalent to the EVT dimension, and using the EVT dimension itself are compared to the Lyapunov dimension and to the delay embedding dimension in Datseris et al. (2023). Note also that, for these two latter definitions of the dimension, there is no equivalent to the scale R of the EVT dimension and the correlation dimension. Because of that, we do not expect a future comparison study (if any) to be able to recover the interpretation of the R dependence of the dimension proposed here for the Lyapunov dimension and the delay embedding dimension.
The Lorenz 63 system is defined by the following equations (Lorenz, 1963)
where σ, β and ρ are constant. Usual values are σ=10, and ρ=28. In this configuration, the system is known to be chaotic.
The same system for ρ=166.5 was also considered (σ and β being unchanged). This system is known to be intermittent, meaning that it follows regular and almost periodic patterns for some periods of time (so-called “laminar” phases), alternating with other periods where it seems to behave randomly (the “chaotic bursts”), see Ott (2002), Schuster and Just (2006) and Elaskar and Rio (2017) about intermittent dynamical systems. A trajectory is displayed in Fig. A1.
As was first noted in Pomeau and Manneville (1980), this system undergoes a bifurcation at ρ≈166.07: the attractor is first periodic but disappears through a saddle-node bifurcation (Sparrow, 1982).
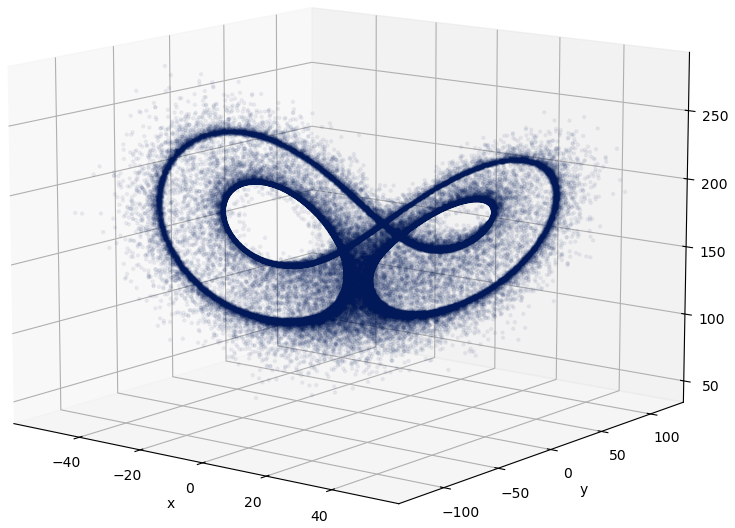
Figure A1Lorenz 63 attractor for ρ=166.5. The remainder of the attractor before the bifurcation is visible.
The Lorenz 96 system (Lorenz, 1996) is a dynamical system with n variables xi for i=1, …, n (n≥4). The evolution equations for xi values are
where index i is understood to be periodic: , x0=xn, and . The parameter F is a forcing constant.
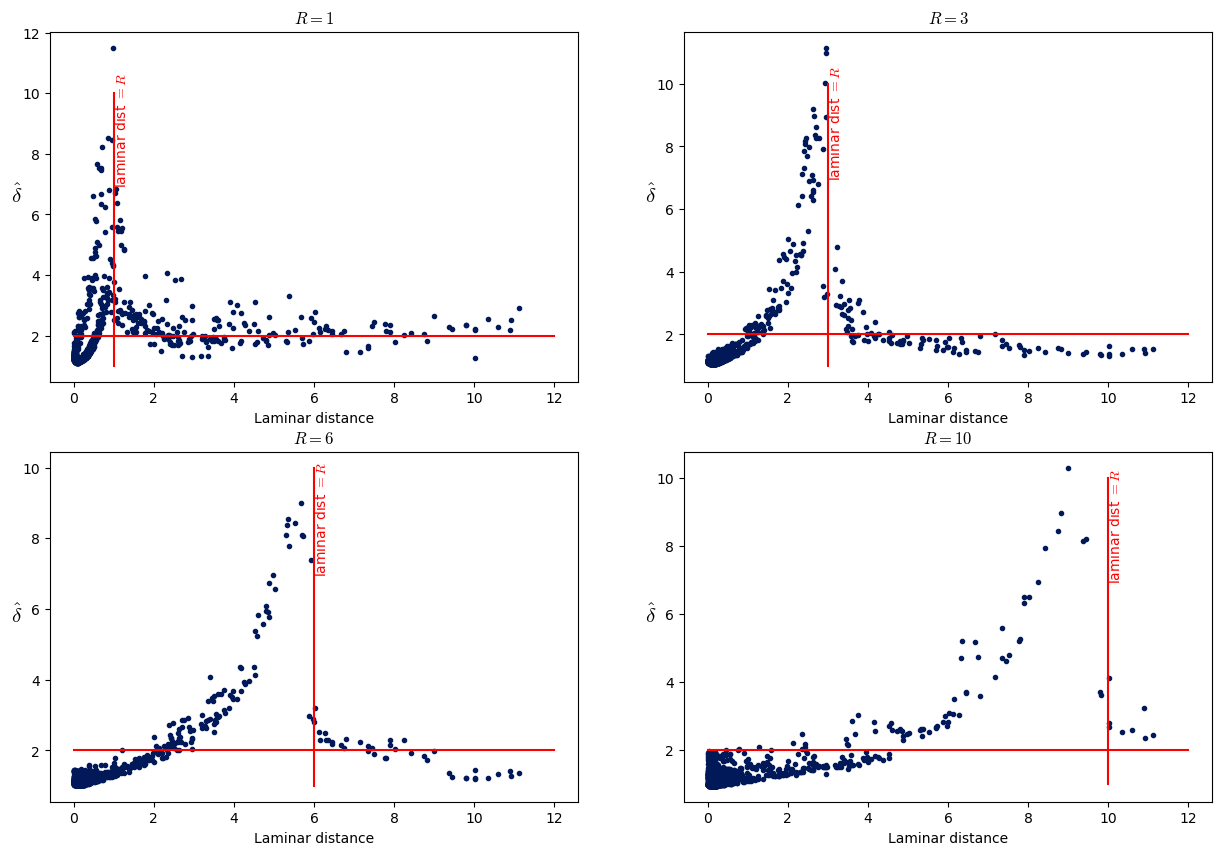
Figure B1Same as Fig. 11 but for the Lorenz 96 system with n=4 and F=11.87 (106 points in the trajectory). The vertical red lines mark the value of the laminar distance which is equal to the radius R, and the horizontal line marks the values 2 for .
This system for n=4 goes through a saddle-node bifurcation at F≈11.83 (Sterk and van Kekem, 2017; van Kekem and Sterk, 2018) and is intermittent for slightly higher values of F (see Appendix A for a brief introduction to intermittency). Figure B1 shows that the estimated value of δ is maximum when the laminar distance is equal to R, as in Fig. 11.
We also considered the Lorenz 96 system with n=12 for F=4.4. We found a bifurcation at F≈4.25 with an intermittent behavior after this value. The laminar regime for this system forms a higher-dimensional structure in the phase space and the trajectory in laminar phases is not almost periodic. One cannot proceed as we did for Lorenz 63 with ρ=166.5 to get a representation of the laminar regime. Instead, we used a trajectory for F=4.2 to represent the laminar regime. The problem with this approach is that the laminar regime after the bifurcation has moved and expanded in the phase space, with respect to the attractor at F=4.2. The peak of the dimension when the laminar distance is equal to R is still clearly visible in Fig. B2.
In complement to the analysis for the Lorenz 96 system with n=50 dimensions in Sect. 4, we computed the local dimension for the same system for F=6. We used a trajectory of 107 points. The left panel of Fig. B3 displays the dimension as a function of R for 50 computation points (restricted to NRMSE <0 .4 and s>6), while the right panel is the scatterplot of the NRMSE vs. s for all fits. The behavior of the dimension against R is the same for all points, and we conclude that our method suggests that there is no salient geometric structure in the phase space for that parameter value.
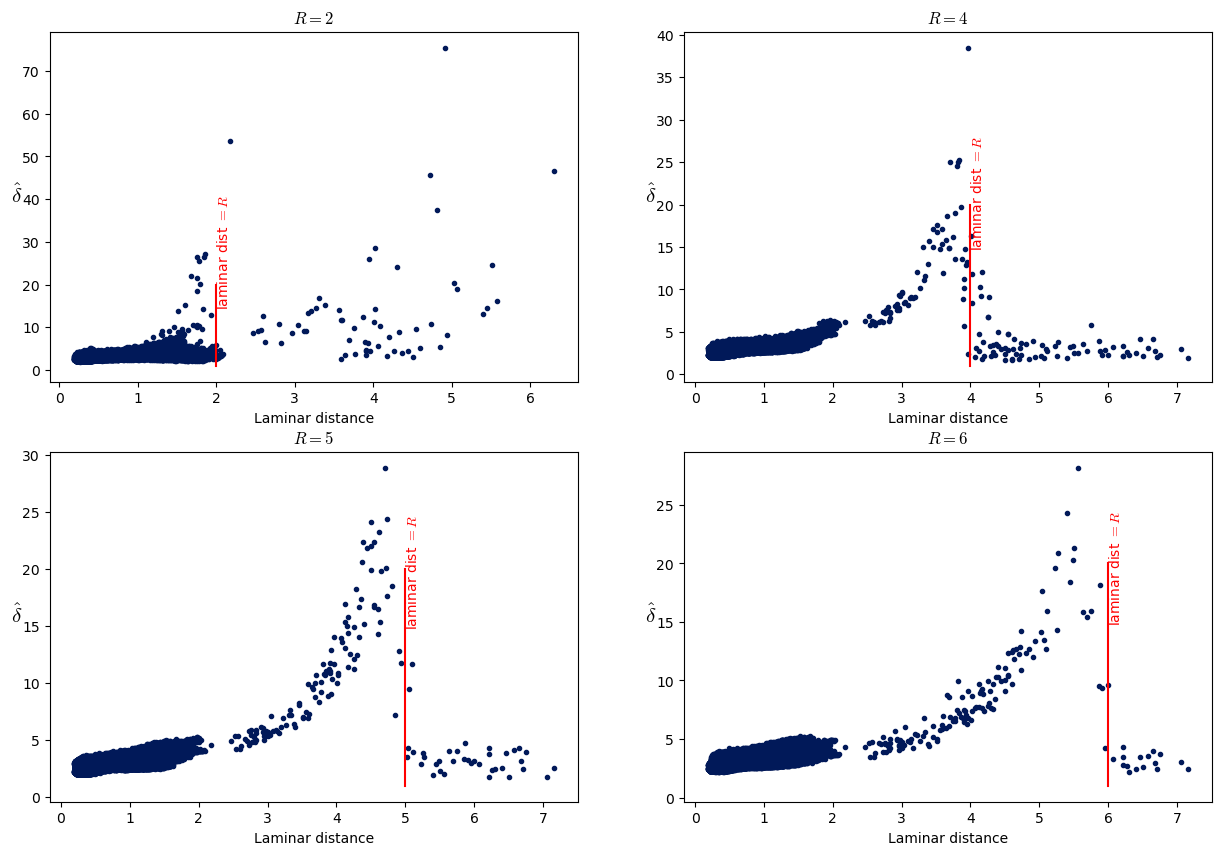
Figure B2Same as Fig. 11 but for the Lorenz 96 system with n=12 and F=4.4 (105 points in the trajectory). The vertical red lines mark the value of the laminar distance which is equal to the radius R.
The RADCLIM radar dataset (Goudenhoofdt and Delobbe, 2016; Journée et al., 2023) is a high-horizontal- and high-temporal-resolution quantitative precipitation estimation in Belgium and its surroundings. It is based on radar measurements, which are merged with rain gauge measures.
The time resolution is 5 min, and we used 6 years of the product. A few images are missing in the dataset, which has in total 630 008 radar images. The images are 700 px × 700 px, with each pixel representing a square of 1 km × 1 km.
As a complement to Fig. 19, Fig. C1 is a two-dimensional histogram of the mean dimension against the CRR. In total, 5000 computation points were used (instead of 2000 in Sect. 4.2) in order to have a more reliable histogram.
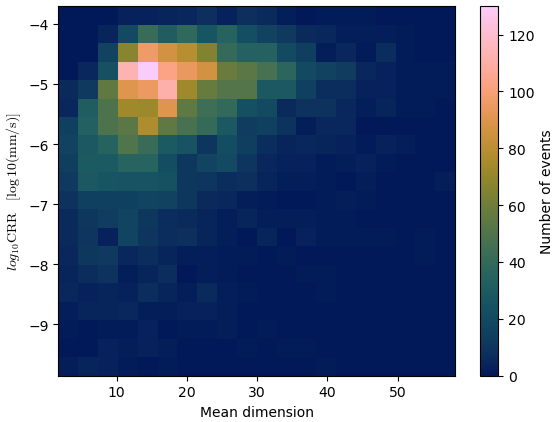
Figure C1Two-dimensional histogram of the repartition of the mean dimension for 5000 computation points with the associated CRR.
The code for computing the dimensions is available upon request to the authors.
The RADCLIM dataset is not available publicly but is accessible upon request from RMI Communication and Marketing service (marketing@meteo.be). For research purposes, these are free of charge.
MB and SV designed the work done. MB made the computations and wrote the text. SV helped with discussions about the results and the proofreading of the text.
At least one of the (co-)authors is a member of the editorial board of Nonlinear Processes in Geophysics. The peer-review process was guided by an independent editor, and the authors also have no other competing interests to declare.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The authors are grateful to Davide Faranda and Tommaso Alberti for discussions about the interpretation of the local dimension.
This research has been supported by the Belgian Federal Science Policy Office (grant no. B2/233/P2/PRECIP-PREDICT).
This paper was edited by Takemasa Miyoshi and reviewed by Jizhou Li and one anonymous referee.
Abarbanel, H. D. I.: Analysis of Observed Chaotic Data, Springer, New York, NY, 69–93, ISBN 978-1-4612-0763-4, https://doi.org/10.1007/978-1-4612-0763-4_5, 1996. a, b
Bac, J. and Zinovyev, A.: Local intrinsic dimensionality estimators based on concentration of measure, in: 2020 International Joint Conference on Neural Networks (IJCNN), 19–24 July 2020, Glasgow, UK, 1–8, https://doi.org/10.1109/IJCNN48605.2020.9207096, 2020. a
Beirlant, J., Goegebeur, Y., Segers, J., Teugels, J., De Waal, D., and Ferro, C.: Statistics of Extremes: Theory and Applications, in: Wiley Series in Probability and Statistics, Wiley, ISBN 9780471976479, https://doi.org/10.1002/0470012382, 2004. a
Berenguer, M., Sempere-Torres, D., and Pegram, G. G.: SBMcast – An ensemble nowcasting technique to assess the uncertainty in rainfall forecasts by Lagrangian extrapolation, J. Hydrol., 404, 226–240, https://doi.org/10.1016/j.jhydrol.2011.04.033, 2011. a
Bowler, N., Pierce, C., and Seed, A.: STEPS: A probabilistic precipitation forecasting scheme which merges an extrapolation nowcast with downscaled NWP, Q. J. Roy. Meteorol. Soc., 132, 2127–2155, https://doi.org/10.1256/qj.04.100, 2007. a, b
Caby, T.: Extreme value theory for dynamical systems, with applications in climate and neuroscience, Theses, Université de Toulon, Università degli studi dell' Insubria (Come, Italie), Facolta' scienze matematiche, fisiche e naturali, https://theses.hal.science/tel-02473235 (last access: 14 May 2025), 2019. a
Camastra, F. and Staiano, A.: Intrinsic dimension estimation: Advances and open problems, Inform. Sci., 328, 26–41, https://doi.org/10.1016/j.ins.2015.08.029, 2016. a, b, c
Datseris, G., Kottlarz, I., Braun, A. P., and Parlitz, U.: Estimating fractal dimensions: A comparative review and open source implementations, Chaos, 33, 102101, https://doi.org/10.1063/5.0160394, 2023. a, b, c, d, e, f
De Luca, P., Messori, G., Pons, F. M. E., and Faranda, D.: Dynamical systems theory sheds new light on compound climate extremes in Europe and Eastern North America, Q. J. Roy. Meteorol. Soc., 146, 1636–1650, https://doi.org/10.1002/qj.3757, 2020. a
Eckmann, J.-P. and Ruelle, D.: Fundamental limitations for estimating dimensions and Lyapunov exponents in dynamical systems, Physica D, 56, 185–187, https://doi.org/10.1016/0167-2789(92)90023-G, 1992. a, b, c, d, e
Elaskar, S. and Rio, E.: New Advances on Chaotic Intermittency and its Applications, Springer, ISBN 978-3-319-47837-1, https://doi.org/10.1007/978-3-319-47837-1, 2017. a
Erba, V., Gherardi, M., and Rotondo, P.: Intrinsic dimension estimation for locally undersampled data, Sci. Rep., 9, 17133, https://doi.org/10.1038/s41598-019-53549-9, 2019. a
Falk, M., Hüsler, J., and Reiss, R.: Laws of Small Numbers: Extremes and Rare Events, Springer, Basel, ISBN 9783034800099, 2010. a
Faranda, D., Lucarini, V., Turchetti, G., and Vaienti, S.: Extreme value theory for singular measures, Chaos, 22, 023135, https://doi.org/10.1063/1.4718935, 2012. a, b
Faranda, D., Messori, G., and Yiou, P.: Dynamical proxies of North Atlantic predictability and extremes, Sci. Rep., 7, 41278, https://doi.org/10.1038/srep41278, 2017. a, b
Faranda, D., Messori, G., and Vannitsem, S.: Attractor dimension of time-averaged climate observables: insights from a low-order ocean-atmosphere model, Tellus A, 71, 1554413, https://doi.org/10.1080/16000870.2018.1554413, 2019. a
Faranda, D., Bourdin, S., Ginesta, M., Krouma, M., Noyelle, R., Pons, F., Yiou, P., and Messori, G.: A climate-change attribution retrospective of some impactful weather extremes of 2021, Weather Clim. Dynam., 3, 1311–1340, https://doi.org/10.5194/wcd-3-1311-2022, 2022. a
Faranda, D., Pascale, S., and Bulut, B.: Persistent anticyclonic conditions and climate change exacerbated the exceptional 2022 European-Mediterranean drought, Environ. Res. Lett., 18, 034030, https://doi.org/10.1088/1748-9326/acbc37, 2023. a, b
Foresti, L., Puigdomènech Treserras, B., Nerini, D., Atencia, A., Gabella, M., Sideris, I. V., Germann, U., and Zawadzki, I.: A quest for precipitation attractors in weather radar archives, Nonlin. Processes Geophys., 31, 259–286, https://doi.org/10.5194/npg-31-259-2024, 2024. a
Germann, U. and Zawadzki, I.: Scale Dependence of the Predictability of Precipitation from Continental Radar Images. Part II: Probability Forecasts, J. Appl. Meteorol., 43, 74–89, https://doi.org/10.1175/1520-0450(2004)043<0074:SDOTPO>2.0.CO;2, 2004. a
Germann, U., Zawadzki, I., and Turner, B.: Predictability of Precipitation from Continental Radar Images. Part IV: Limits to Prediction, J. Atmos. Sci., 63, 2092–2108, https://doi.org/10.1175/JAS3735.1, 2006. a
Golay, J. and Kanevski, M. F.: A new estimator of intrinsic dimension based on the multipoint Morisita index, Pattern Recognit., 48, 4070–4081, 2014. a
Goudenhoofdt, E. and Delobbe, L.: Generation and Verification of Rainfall Estimates from 10-Yr Volumetric Weather Radar Measurements, J. Hydrometeorol., 17, 1223–1242, https://doi.org/10.1175/JHM-D-15-0166.1, 2016. a
Grassberger, P. and Procaccia, I.: Measuring the strangeness of strange attractors, Physica D, 9, 189–208, https://doi.org/10.1016/0167-2789(83)90298-1, 1983. a
James, F. E.: Statistical Methods in Experimental Physics, in: 2nd Edn., World Scientific, Singapore, ISBN 9812705279, 2006. a, b
Journée, M., Goudenhoofdt, E., Vannitsem, S., and Delobbe, L.: Quantitative rainfall analysis of the 2021 mid-July flood event in Belgium, Hydrol. Earth Syst. Sci., 27, 3169–3189, https://doi.org/10.5194/hess-27-3169-2023, 2023. a, b
Kantz, H. and Schreiber, T.: Nonlinear Time Series Analysis, in: 2nd Edn., Cambridge University Press, https://doi.org/10.1017/CBO9780511755798, 2003. a
Kaplan, J. L. and Yorke, J. A.: Chaotic behavior of multidimensional difference equations, in: Functional differential equations and approximations of fixed points. Lecture notes in mathematics Vol. 730, edited by: Peitgen, H. O. and Walter, H. O., Springer, Berlin, https://doi.org/10.1007/BFb0064319, 1979. a
Little, A. V., Maggioni, M., and Rosasco, L.: Multiscale geometric methods for data sets I: Multiscale SVD, noise and curvature, Appl. Comput. Harm. Anal., 43, 504–567, https://doi.org/10.1016/j.acha.2015.09.009, 2017. a, b, c
Lorenz, E. N.: Deterministic Nonperiodic Flow, J. Atmos. Sci., 20, 130–148, https://doi.org/10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2, 1963. a, b
Lorenz, E. N.: Predictability: A problem partly solved, in: vol. 1, Proc. Seminar on predictability, 4–8 September 1995, Reading, https://doi.org/10.1017/CBO9780511617652.004, 1996. a
Lovejoy, S. and Schertzer, D.: The Weather and Climate: Emergent Laws and Multifractal Cascades, Cambridge University Press, https://doi.org/10.1017/CBO9781139093811, 2013. a
Lucarini, V., Faranda, D., Moreira Freitas, A. C., Freitas, J. M., Mark, H., Tobias, K., Nicol, M., Todd, M., and Vaienti, S.: Extremes and Recurrence in Dynamical Systems, in: Pure and Applied Mathematics: A Wiley Series of Texts, Monographs and Tracts, Wiley, ISBN 978-1-118-63232-1, 2016. a
Ott, E.: Chaos in Dynamical Systems, in: 2nd Edn., Cambridge University Press, https://doi.org/10.1017/CBO9780511803260, 2002. a, b, c, d, e, f, g, h
Packard, N. H., Crutchfield, J. P., Farmer, J. D., and Shaw, R. S.: Geometry from a Time Series, Phys. Rev. Lett., 45, 712–716, https://doi.org/10.1103/PhysRevLett.45.712, 1980. a
Perinelli, A., Iuppa, R., and Ricci, L.: Estimating the correlation dimension of a fractal on a sphere, Chaos Solit. Fract., 173, 113632, https://doi.org/10.1016/j.chaos.2023.113632, 2023. a, b, c
Pesin, Y.: Dimension Theory in Dynamical Systems: Contemporary Views and Applications, Chicago Lectures in Mathematics, University of Chicago Press, ISBN 9780226662213, 1997. a, b
Pierce, C., Seed, A., Ballard, S., Simonin, D., and Li, Z.: Nowcasting, in: Doppler Radar Observations, chap. 4, edited by: Bech, J. and Chau, J. L., IntechOpen, Rijeka, https://doi.org/10.5772/39054, 2012. a
Pomeau, Y. and Manneville, P.: Intermittent transition to turbulence in dissipative dynamical systems, Commun. Math. Phys., 74, 189–197, https://doi.org/10.1007/BF01197757, 1980. a, b
Pons, F. M. E., Messori, G., Alvarez-Castro, M. C., and Faranda, D.: Sampling hyperspheres via extreme value theory: implications for measuring attractor dimensions, J. Stat. Phys., 179, 698–1717, https://doi.org/10.1007/s10955-020-02573-5, 2020. a, b, c, d, e
Pons, F. M. E., Messori, G., and Faranda, D.: Statistical performance of local attractor dimension estimators in non-Axiom A dynamical systems, Chaos, 33, 073143, https://doi.org/10.1063/5.0152370, 2023. a, b
Pulkkinen, S., Chandrasekar, V., and Harri, A.-M.: Stochastic Spectral Method for Radar-Based Probabilistic Precipitation Nowcasting, J. Atmos. Ocean. Tech., 36, 971–985, https://doi.org/10.1175/JTECH-D-18-0242.1, 2019a. a
Pulkkinen, S., Nerini, D., Pérez Hortal, A. A., Velasco-Forero, C., Seed, A., Germann, U., and Foresti, L.: Pysteps: an open-source Python library for probabilistic precipitation nowcasting (v1.0), Geosci. Model Dev., 12, 4185–4219, https://doi.org/10.5194/gmd-12-4185-2019, 2019b. a
Russell, D. A., Hanson, J. D., and Ott, E.: Dimension of Strange Attractors, Phys. Rev. Lett., 45, 1175–1178, https://doi.org/10.1103/PhysRevLett.45.1175, 1980. a
Schuster, H. and Just, W.: Deterministic Chaos: An Introduction, Wiley, ISBN 9783527606412, 2006. a
Scott, D.: Multivariate Density Estimation: Theory, Practice, and Visualization, in: Wiley Series in Probability and Statistics, Wiley, ISBN 9780471697558, 2015. a
Seed, A. W.: A Dynamic and Spatial Scaling Approach to Advection Forecasting, J. Appl. Meteorol., 42, 381–388, https://doi.org/10.1175/1520-0450(2003)042<0381:ADASSA>2.0.CO;2, 2003. a
Sparrow, C.: The Lorenz Equations: Bifurcations, Chaos, and Strange Attractors, in: Applied Mathematical Sciences, Springer, New York, ISBN 9781461257677, 1982. a, b, c
Sterk, A. and van Kekem, D.: Predictability of Extreme Waves in the Lorenz-96 Model Near Intermittency and Quasi-Periodicity, Complexity, 2017, 9419024, https://doi.org/10.1155/2017/9419024, 2017. a
Takens, F.: On the numerical determination of the dimension of an attractor, in: Dynamical Systems and Bifurcations, edited by: Braaksma, B. L. J., Broer, H. W., and Takens, F., Springer Berlin Heidelberg, Berlin, Heidelberg, 99–106, ISBN 978-3-540-39411-2, 1985. a, b, c
Theiler, J.: Spurious dimension from correlation algorithms applied to limited time-series data, Phys. Rev. A, 34, 2427–2432, https://doi.org/10.1103/PhysRevA.34.2427, 1986. a
Theiler, J.: Statistical precision of dimension estimators, Phys. Rev. A, 41, 3038–3051, https://doi.org/10.1103/PhysRevA.41.3038, 1990. a, b, c
van Kekem, D. L. and Sterk, A. E.: Travelling waves and their bifurcations in the Lorenz-96 model, Physica D, 367, 38–60, https://doi.org/10.1016/j.physd.2017.11.008, 2018. a
Veneziano, D., Langousis, A., and Furcolo, P.: Multifractality and rainfall extremes: A review, Water Resour. Res., 42, W06D15, https://doi.org/10.1029/2005WR004716, 2006. a
Zawadzki, I., Morneau, J., and Laprise, R.: Predictability of Precipitation Patterns: An Operational Approach, J. Appl. Meteorol. Climatol., 33, 1562–1571, https://doi.org/10.1175/1520-0450(1994)033<1562:POPPAO>2.0.CO;2, 1994. a
- Abstract
- Introduction
- Framework for the estimation of the dimension
- Application to small systems
- Application to large systems
- Summary and discussion
- Appendix A: Lorenz 63 system
- Appendix B: Lorenz 96 system
- Appendix C: RADCLIM dataset
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Framework for the estimation of the dimension
- Application to small systems
- Application to large systems
- Summary and discussion
- Appendix A: Lorenz 63 system
- Appendix B: Lorenz 96 system
- Appendix C: RADCLIM dataset
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References