the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 14 Jun 2023
| 14 Jun 2023
Toward a multivariate formulation of the parametric Kalman filter assimilation: application to a simplified chemical transport model
Antoine Perrot
Olivier Pannekoucke
Vincent Guidard
This contribution explores a new approach to forecasting multivariate covariances for atmospheric chemistry through the use of the parametric Kalman filter (PKF). In the PKF formalism, the error covariance matrix is modellized by a covariance model relying on parameters, for which the dynamics are then computed. The PKF has been previously formulated in univariate cases, and a multivariate extension for chemical transport models is explored here. This contribution focuses on the situation where the uncertainty is due to the chemistry but not due to the uncertainty of the weather. To do so, a simplified two-species chemical transport model over a 1D domain is introduced, based on the non-linear Lotka–Volterra equations, which allows us to propose a multivariate pseudo covariance model. Then, the multivariate PKF dynamics are formulated and their results are compared with a large ensemble Kalman filter (EnKF) in several numerical experiments. In these experiments, the PKF accurately reproduces the EnKF. Eventually, the PKF is formulated for a more complex chemical model composed of six chemical species (generic reaction set). Again, the PKF succeeds at reproducing the multivariate covariances diagnosed on the large ensemble.
- Article
(5411 KB) - Full-text XML
- BibTeX
- EndNote





Data assimilation aims to provide an estimation of the true state of a system. This estimation, called the analysis, is a compromise between the forecast of the state and the available observations. The optimal combination of the forecast and the observations relies on their respective error covariance matrices as given by the Kalman filter equations (Kalman, 1960). The accuracy of the analysis is directly related to the quality of these two matrices.
In atmospheric chemistry applications, the system to study is the concentration of multiple chemical species in the atmosphere. In most cases, chemical transport models (CTMs) are used to forecast the concentrations, such as the operational Model Of atmospheric Chemistry At larGE scale (MOCAGE) used in Météo-France (Josse et al., 2004). CTMs make predictions based on the transport by the wind (the fields are provided by numerical weather prediction (NWP) models) and the chemical interactions of the species (Hauglustaine et al., 1998) and take into account multiple other important processes, e.g. the diffusion, the emissions, the deposition, or the interaction with clouds. However, in CTMs, chemistry does not influence the meteorology, which is of course a crude approximation of the true atmosphere. The advantage of a CTM is that it allows air quality prediction at a low numerical cost and is used in several operational centres. For instance, the Copernicus Atmosphere Monitoring Service (CAMS) regional air quality production (https://atmosphere.copernicus.eu/cams-european-air-quality-ensemble-forecasts-welcomes-two-new-state-art-models, associated with CAMS2.40 at https://confluence.ecmwf.int/display/CKB/CAMS+Regional%3A+European+air+quality+analysis+and+forecast+data+documentation; see here for a scientific description – last access to web references: 15 March 2023), which forecasts daily a multi-model ensemble of 11 members that covers the following 4 d, is performed from the integration of 11 models, of which 10 are CTMs. Note that each member of the ensemble relies on its own data assimilation system for providing its surface analysis, while all the models process the same set of surface observations, and all the model forecasts are based on the same meteorological forcings from European Centre for Medium-Range Weather Forecasts (ECMWF) high-resolution weather forecasts. In particular, members of the CAMS multi-model ensemble are not used within an EnKF to provide its own assimilation system.
In this context, the forecast-error covariance matrix contains the correlations of the forecast errors within and between the chemical species. In multivariate covariance modelling applied in meteorology, these correlations are respectively denoted as auto-correlations and cross-correlations (Derber and Bouttier, 1999). Accurately describing the auto-correlation and cross-correlation is a key component in improving the overall quality of the analysis. Indeed, strong correlations exist between different chemical species, and the analysis could benefit from them: an observation for a given species might also correct other concentrations and reduce their error amplitude at the same time. Note that, in operational applications, chemical species are often assimilated separately; for example, in CAMS 2.40, the univariate 3D variational data assimilation (3DVar) system of MOCAGE is used for the assimilation of ozone, nitrogen dioxide, sulfur dioxide, and fine particulate matter PM2.5 and PM10 (following a configuration similar to the one used for Monitoring Atmospheric Composition and Climate: Interim Implementation (MACII) detailed by Marécal et al., 2015). Note also that simplifications are often introduced to represent a flow dependency of the background term. For example, in several studies using MOCAGE, the 3DVar background error standard deviations are specified as a percentage of the first-guess field (El Amraoui et al., 2020; El Aabaribaoune et al., 2021; Peiro et al., 2018) – which is very different from the forecast-error variance in an ensemble Kalman filter (EnKF) that results from the ensemble estimation and the dynamics of the uncertainty along the previous analysis and forecast cycles.
However, the estimation and the modelling of multivariate covariances in air quality are complex topics (Emili et al., 2016). However, this is not specific to air quality, and two main approaches are found in data assimilation. The first one relies on balance operators and has been introduced in variational data assimilation. These balance operators establish a relation between the state variables and allow for the modelling of cross-covariances from the design of univariate covariances. Such operators exist in numerical weather prediction (Derber and Bouttier, 1999; Fisher, 2003) and for the ocean (Weaver et al., 2006), but as far as we know, no balance operators are used in atmospheric chemistry applications. The second approach relies on the ensemble method (Evensen, 2009), where an ensemble of forecasts is used to estimate the multivariate covariance matrix (Coman et al., 2012). The ensemble method offers a flow-dependent estimation of the error statistics and leads to a practical implementation of the Kalman filter, which is the EnKF (Evensen, 1994). The EnKF applies to a wide range of problems, from a simple Lorenz-63 model (Lorenz, 1963) to the numerical prediction of the atmosphere or the ocean. At the same time, this advantage may be seen as a limitation: the EnKF does not necessarily take advantage of the particular set of equations of a problem, e.g. the continuity of physical fields, which leads to simplification not available in the usual matrix formulation of the EnKF equations. Moreover, the ensemble method presents some drawbacks. For instance, since the estimation often relies on a small ensemble, the statistical estimations are polluted by a spurious sampling noise which requires the introduction of filtering (Berre et al., 2007) and localization (Houtekamer and Mitchell, 1998, 2001). In air quality, it may be preferable to set the ensemble estimation of the multivariate correlation to zero to avoid polluting the resulting analysis state (Tang et al., 2011; Gaubert et al., 2014), except at the globe's surface (Eben et al., 2005) or when the chemical species are strongly correlated (Miyazaki et al., 2012). Note that additional treatments can be required as inflation of the variance in order to represent effects of model errors (Anderson and Anderson, 1999; Whitaker and Hamill, 2003). As another drawback, the numerical computation of the EnKF is costly since it relies on the several time integrations of a numerical model, which are often computed in parallel at lower resolution.
Recently, a new approximation of the Kalman filter (KF) was introduced, the parametric Kalman filter (PKF), where the error covariance matrices are approximated by a covariance model fitted with a set of parameters, e.g. the grid-point variance and the local anisotropy (Pannekoucke et al., 2016). In the PKF, the dynamics of the parameters are described all along the forecast and analysis steps of the assimilation cycle (Pannekoucke, 2021a). This approach does not rely on ensembles, and the dynamics of the parameters are deduced from the partial differential equations that govern the physical system. Hence, the PKF opens the way to understanding the physics of uncertainties. However, the construction of the parameter dynamics is the most difficult part for the design of the PKF. When the parameters are the variance and the local error-correlation anisotropy, a systematic formalism for deducing the PKF's equations based on a Reynolds decomposition (or Reynolds averaging technique; see e.g. Lesieur, 2008, chap. 4) has been introduced, associated with a Python package, SymPKF (Pannekoucke and Arbogast, 2021; Pannekoucke, 2021b), and is based on the Python computer algebra system Sympy (Meurer et al., 2017). However, modelling the physics of uncertainties often comes with closure problems. To alleviate this issue, another numerical framework, PDE-Netgen, has been introduced to be able to close problems using a deep-learning approach (Pannekoucke and Fablet, 2020; Pannekoucke, 2020).
Applying the PKF approach for CTMs is attractive because the parametric dynamics are known for the transport equations (Cohn, 1993; Pannekoucke et al., 2018), and this leads to a better understanding of the forecast-error covariance dynamics, e.g. a better understanding of the model-error covariance due to the numerical integration (Pannekoucke et al., 2021) and the loss of variance which appears in the EnKF (Ménard et al., 2021). Moreover, an application of the PKF was recently proposed for the assimilation of Greenhouse Gases Observing Satellite (GOSAT) methane in the hemispheric Community Multiscale Air Quality (CMAQ) model (Voshtani et al., 2022a, b), showing the potential of the PKF in nearly operational applications where only the error variance evolved. Compared to specifying the background variance as a percentage of the first guess, as mentioned above for the MOCAGE assimilation, the PKF could provide a flow dependence more consistent with the KF theoretical framework but without the numerical cost of using an ensemble as with an EnKF.
While the PKF has been formulated for univariate statistics, a first attempt at multivariate statistics has been proposed based on the balance operator approach (Pannekoucke, 2021a). However, applying such a balance operator is a challenge for chemical reactions where no simple relation exists as the geostrophic balance in weather forecasting. Hence, the aim of this contribution is to explore how to extend the univariate PKF to a multivariate formulation adapted to CTMs. To do so, a multivariate covariance model adapted to air quality prediction is first proposed, and then it is validated by a twin experiment based on an EnKF using a large ensemble.
This contribution only focuses on the uncertainty dynamics due to the chemistry without accounting for the part of the uncertainty of the weather: for example, we do not take into account the uncertainty of the wind that transports the chemical species.
The paper is organized as follows. Section 2 recalls basic concepts in data assimilation with the formalism of the Kalman filter and its parametric approximation in univariate statistics. Then, in Sect. 3, a simplified two-species multivariate CTM is introduced for which a multivariate parametric assimilation is first proposed and then validated based on a comparison with an ensemble approach. A six-species chemical scheme is considered in Sect. 4 to evaluate the PKF multivariate forecast in a more complex context. The conclusions of the contribution are given in Sect. 5.
The PKF is a recent implementation of the Kalman filter where the covariance matrices are approximated by some covariance model. For the sake of consistency, this section first recaps the basics of the Kalman filter, and then it recalls the diagnosis of the covariance matrix in large-dimension and covariance models to introduce the formalism of the PKF in univariate statistics. The section ends with a numerical example of interest for air quality that illustrates the PKF.
2.1 Analysis and forecast step in the Kalman filter
Here we consider a system whose state is denoted by 𝒳 and governed by the evolution equation
Time integration from a time tq to a time tq+1 of the dynamics in Eq. (1) defines the propagator , which maps a state 𝒳(tq) to the prediction of Eq. (1), . In geophysics, 𝒳 stands for the multivariate fields that represent the state of the ocean, the atmosphere, or chemical species concentration for air quality. The dynamics ℳ are then given by a system of partial differential equations. After spatial discretization, ℳ becomes a system of ordinary differential equations, and 𝒳 is a vector of dimension n. Thereafter, 𝒳 can be seen either as a collection of continuous fields with dynamics given by Eq. (1) or a discrete vector of dynamics in the discretized version of Eq. (1).
Because of the spatio-temporal sparsity of observations, modelling, and chaotic amplification of initial error in forecast and measurement errors, the exact actual state at a time t=tq, , is unknown.
Data assimilation aims to provide the analysis state, , which is an estimation of performed from the observations and the forecast state. The analysis state is decomposed into , where is the analysis error, which is modelled as a random error of the zero mean and covariance matrix , with 𝔼 (or its shorthand ) the expectation operator and T the transpose operator. This analysis state can be obtained by combining the forecast state and the observations . Similarly to the analysis state, the forecast and the observations can be written as and , introducing the forecast (observation) error (), both modelled as random errors of zero-mean and covariance matrices and respectively. In the case when the dynamic of 𝒳t is assumed to be linear, replacing ℳ with its matrix version M in Eq. (1), and when the errors are Gaussian, uncorrelated in time, and errors between observations and forecast are independent, the KF's equations describe the evolution of the uncertainty over time (Kalman, 1960).
The process of estimating the analysis state from a forecast and some observations is called the analysis step. The forecast-error covariance matrix denoted by and the observation error covariance matrix Rq associated respectively with and are used to produce the optimal estimation (analysis) of and the associated analysis-error covariance matrix . The equations of this procedure are
where is the Kalman gain matrix, with Hq the linear observation operator that maps the state vector into the observation space, the analysis-error covariance matrix, and In the identity matrix in dimension n.
Next, the forecast step pushes the uncertainty forward in time. The analysis state is propagated using the linear dynamics M to obtain the forecast at time tq+1, leading to an estimation of the true state system 𝒳t(tq+1). The Gaussian error statistics for this forecast are given by the Kalman filter forecast steps
where Qq is the model-error covariance matrix. Thereafter, no model error is considered: i.e. Q is zero.
While the Kalman filter formalism is based on simple vector algebra equations, it is not easy to understand the statistical content of the error covariances, which would require representing each covariance function and exploring their temporal evolution. Fortunately, simple diagnosis can be introduced to summarize the statistical relationship between points in the geographic domain. In turn, these diagnostics can be used as parameters of covariance models, as detailed now.
2.2 Diagnosis and modelling of the covariance matrix in a large dimension
In data assimilation, two diagnoses for the error covariance matrices are often introduced: the variance field and the anisotropy of the correlation functions which correspond to the principal axes of the spatial correlation. These diagnoses are used for the description of the forecast-error covariance matrix.
The forecast-error variance field, Vf, is defined by Vf(x)=𝔼((εf(x))2), where x denotes the coordinate of a grid point. The variance field also corresponds to the diagonal of Pf. The field of variance characterizes the magnitude of the error at a given position.
When the forecast error is a differential random field, the anisotropy of the correlation is characterized by the so-called local forecast-error metric tensor gf(x) that appears in the Taylor expansion of the correlation function (Daley, 1991)
where stands for the Euclidean norm associated with a metric g and defined from . The local metric tensor gf(x) is a symmetric positive-definite matrix that prevents the correlation value from being larger than one. There is one local metric tensor at each grid location x. The metric tensor is related to the statistics of the random field εf according to the formula (Berre et al., 2007)
where is the forecast-error standard deviation and where xi denotes the coordinate functions associated with the coordinate system x.
In practice, the direction of the largest correlation anisotropy corresponds to the principal axis of the smallest eigenvalue for the metric tensor: the metric tensor is contravariant. It is thus useful to introduce the local aspect tensor (Purser et al., 2003), whose geometry goes as the correlation and is defined as the inverse of the metric tensor:
where the superscript “−1” denotes the matrix inverse. Note that, in a 1D domain, the square root of s is homogeneous to a length, leading to the so-called length scale , which is often introduced in diagnoses.
One of the motivations behind the diagnosis of the variance and the local anisotropy tensor is that they can be used as parameters of covariance models, the VLATcov models (Pannekoucke, 2021a). For instance, for the covariance model based on a diffusion equation (Weaver and Courtier, 2001), the anisotropy tensor has been used as a proxy for setting the heterogeneous diffusion tensor field of the covariance model based on a heterogeneous diffusion equation (Pannekoucke and Massart, 2008; Mirouze and Weaver, 2010). This covariance model is used in variation data assimilation to generate heterogeneous covariances where correlation functions vary between grid points. While there is no analytical expression for the covariance functions based on the diffusion operator, analytical heterogeneous VLATcov models exist, for instance the heterogeneous Gaussian-like covariance model
with denoting the matrix determinant (Paciorek and Schervish, 2006).
Heterogeneous covariance models are important because they provide a way to produce non-obvious correlation functions from a set of parameters. Hence, approximating a covariance matrix, as the forecast-error covariance at a given time, by a covariance model is reduced to the knowledge of a set of parameters. The parametric Kalman filter takes advantage of this kind of approximation to reproduce the Kalman filter dynamics as explained now.
2.3 Formalism of the parametric Kalman filter
A covariance model is first considered, P(𝒫), where 𝒫 denotes a set of parameters. For instance, when the PKF is designed from a VLATcov model, the set of parameters 𝒫 is given by the field of variance and of the local anisotropic tensors, i.e. or .
To describe the sequential evolution of error-covariance matrices along the assimilation cycles, we assume that the forecast-error covariance matrix at a time tq, , is approximated by the covariance model, , where denotes a set of parameters so that .
At an abstract level, the parametric Kalman filter consists of the following sequential steps (Pannekoucke, 2021a). The PKF analysis step, equivalent to Eq. (2), consists in determining the analysis state and the parameters from , , and the observations. In practice, this step consists in sequentially processing observations, similar to the one often encountered in EnKF (Houtekamer and Mitchell, 2001), which is a sequential assimilation of single observations based on Eq. (2a) for the mean accompanied by an update of the covariance parameters so that, at the end of the analysis step, approximates the analysis-error covariance of the Kalman filter Eq. (2b), i.e. . Note that this sequential assimilation of observations can be performed in parallel as for the EnKF, with the difference that the EnKF often assimilates a batch of observations in place of a single observation. Of course, for the PKF this step only relies on the update of the parameters, with no ensemble. For instance, when considering a VLATcov model P(V,s), the PKF analysis of a single observation at position xl, of value yo and observation-error variance Vo(xl), is written as (at time tq) (Pannekoucke, 2021a)
where the function is the correlation function between the observation location and each model grid point x, associated with the covariance matrix P(Vf,sf), is the field of the forecast-error standard deviation, and Eq. (8c) is the leading-order approximation of the anisotropy update (Pannekoucke, 2021a).
Then, the forecast step of the PKF, equivalent to Eq. (3), consists in finding the dynamics of the parameters in order to predict from , so that approximates the forecast-error covariance matrix of the Kalman filter, i.e. . The equation for the mean is Eq. (3a) of the KF.
2.4 PKF for the advection equation of the passive tracer
An illustration of the PKF is now proposed for a univariate advection problem, with a focus on the forecast step. This introduction of an intermediate problem aims to give the reader a good understanding of the PKF and its advantages and difficulties, which will be necessary to address the more complex problem encountered in a multivariate CTM.
For a 1D and periodic domain, of coordinate x, the conservative advection of a tracer, 𝒳(t,x), by a stationary heterogeneous wind field u(x) can be described by the partial differential dynamics
or equivalently by
The forecast step of the PKF is illustrated for the conservative dynamics, where the covariance matrices are approximated by a VLATcov model. The computation of the PKF dynamics can be performed using SymPKF (Pannekoucke and Arbogast, 2021) and reads as
where here 𝒳 stands for the mean state and where the forecast-error superscript “(⋅)f” has been removed for V and s for the sake of simplicity. Note that the PKF system in Eq. (10), which is decoupled, corresponds to the true uncertainty dynamics for the advection problem (Cohn, 1993; Pannekoucke et al., 2016, 2018). This is not true in general where closure issues can appear, e.g. for a diffusion equation: because of the second-order derivative, an unknown term appears in the dynamics of the metric and has to be closed (Pannekoucke et al., 2018).
In the following, a numerical test bed shows the ability of the PKF to predict the uncertainty dynamics compared to a reference ensemble estimation (EnKF).
The numerical experiment studies the time propagation of an uncertainty at time t=0, featuring a mean state 𝒳0 and an error covariance P0, to an arbitrary time T. Here, the initial error covariance is defined as the covariance , where P(V,s) is the VLATcov model based on the heterogeneous Gaussian-like model in Eq. (7) for a given (V0,s0).
To assess the PKF's ability to forecast the error statistics, we compare its results with diagnoses obtained from the forecast of a large ensemble, , of size Ne=6400, which implies a relative error of 1.25 %, according to the central limit theorem. At t=0, the ensemble is populated for each k as , where is the square root of the initial covariance matrix P0 and ζk is a Gaussian sample with zero mean and covariance matrix In, where n is the dimension of the vector 𝒳, i.e. . Then, each member is computed from the time integration of Eq. (9b) starting from . Note that, for the linear dynamics in Eq. (9a), the full computation of the KF covariance prediction could have been considered, but the ensemble approximation has been preferred since it introduces the methodology adapted to the non-linear setting explored for the multivariate situation in Sect. 3.
Hence, from the ensemble, the variance at a given time is then estimated from its unbiased estimator
with and where is the empirical mean. The metric tensor, defined from Eq. (5), is estimated by
where is the normalized error and is used to compute the estimation of the aspect tensor and of the length scale .
The numerical framework used to forecast both the ensemble and the PKF system is described now. The periodic domain is [0,D) with D=1000 km. It is regularly discretized with Nx=241 grid points, which corresponds to a mesh size Δx of size 4.15 km. The dynamics in Eqs. (9b) and (10) are discretized with a finite-difference method, where spatial derivatives are approximated using a centred scheme of order 2. The time integration is done using a fourth-order Runge–Kutta (RK4) scheme of time step Δt verifying the Courant–Friedrichs–Lewy condition (CFL) (Kalnay, 2002) , where Umax is the maximum wind speed magnitude of u.
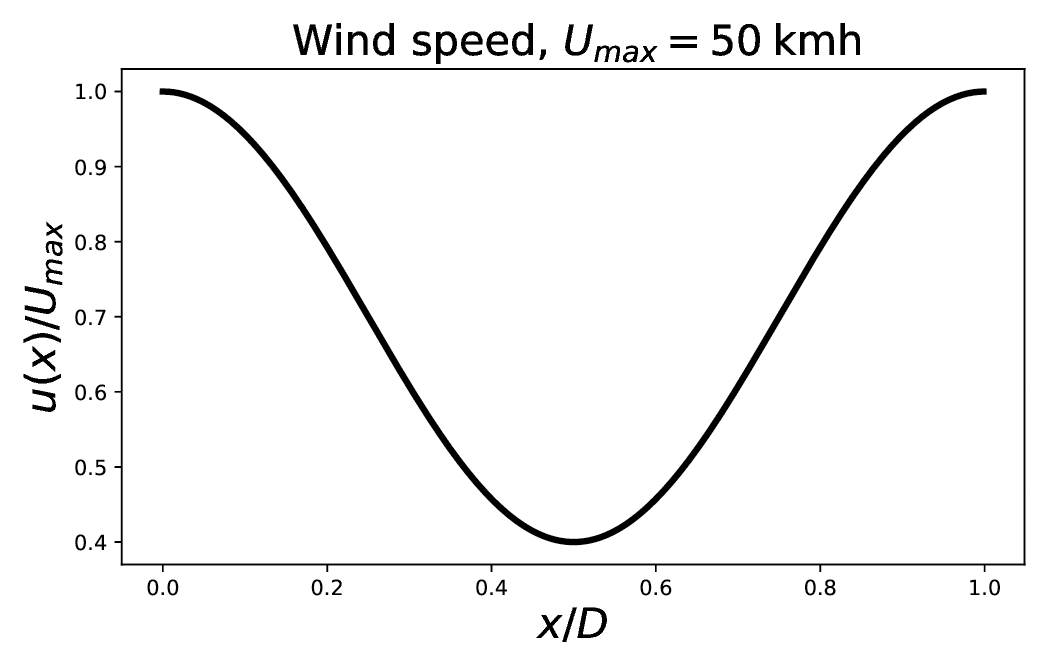
Figure 1Pre-defined heterogeneous and stationary wind field u(x) used for the transport simulations.
For this experiment, the mean state 𝒳, the variance field V, and the aspect-tensor field s are initialized homogeneously with values 𝒳0=1 and V0=(σ0)2, where σ0=0.1, and , where km. This initial setting also corresponds to the initial state of the PKF dynamics in Eq. (10). With regards to the domain chosen, this setting for the length scale is in agreement with practical estimations often encountered (Ménard et al., 2016). The wind field considered, shown in Fig. 1, is defined by and modellizes a wind of average intensity 35 km h−1 and of maximum speed km h−1. The characteristic time τadv is defined by h and approximately corresponds to the time of a revolution of the tracer around the periodic domain. The simulation time horizon T=tend is set to tend=3τadv.
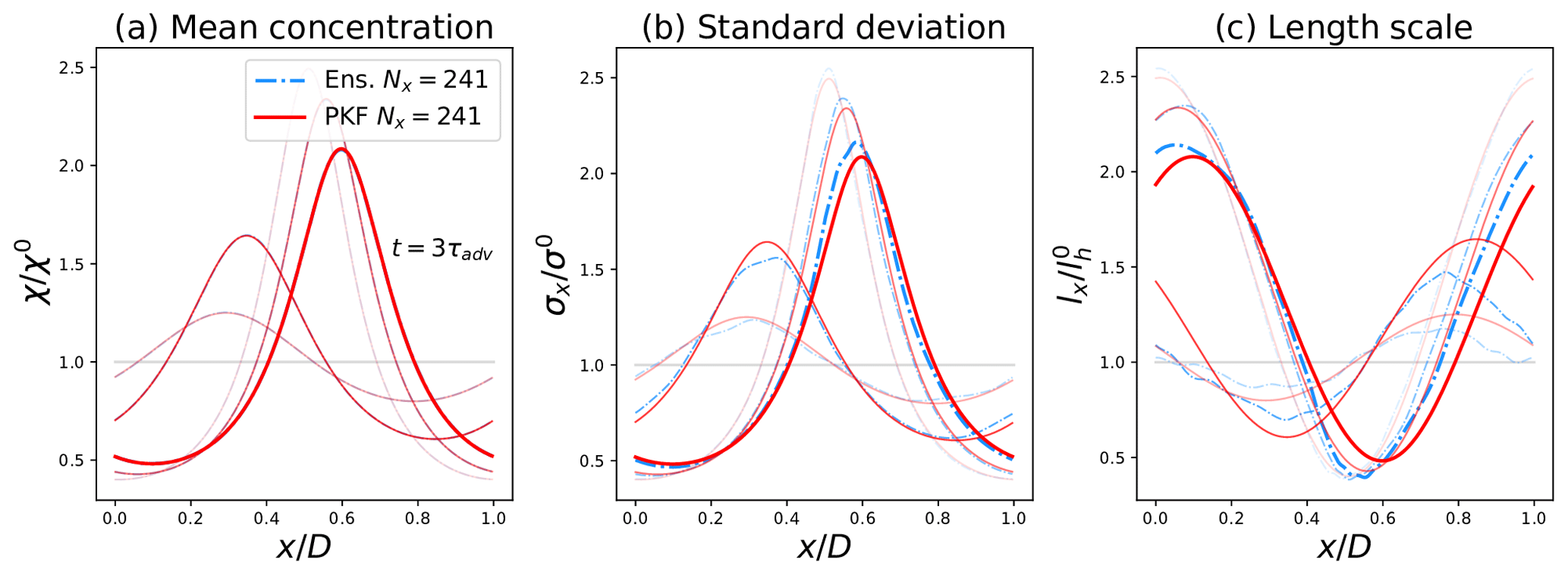
Figure 2Comparison of the (low-resolution) forecasts (Nx=241) of the mean state (a), the forecast-error standard deviation (b) and the forecast-error length scale (c), shown at times , computed from the PKF (red lines) and compared with the diagnoses of an ensemble of Ne=6400 forecasts (cyan dash-dotted lines). The more transparent the curve, the closer it is to t=0. The horizontal grey lines represent the initial conditions.
The dynamics of the uncertainty show in Fig. 2 that the tracer tends to concentrate in the deceleration zones (see Fig. 1 from x=0 to x=0.5) and to dilute in the acceleration zones (from x=0.5 to x=1.0) (Fig. 2a). This observation also applies to the standard-deviation field in Fig. 2b, as it is governed by the same dynamics as the tracer's concentration (it is straightforward to calculate the dynamics of σ using the dynamics of the variance in Eq. 10b). In Fig. 2c, the length scales (1D equivalent of the anisotropy) are subject to two processes: a pure transport term (left-hand side of Eq. 10c) and a production term related to the wind sheer (right-hand side of Eq. 10c). This production term is positive (negative) when the wind field is accelerating (decelerating), indicating an increase (decrease) in the length scales in the accelerating (decelerating) wind regions. In contrast to the concentrations and standard-deviation fields (governed by a conservative transport), the average value of the length scales varies in time; however, numerical experiments (not shown here) have shown that it oscillates around the initial value.
Regarding the performances of the two methods, the PKF forecast results for the error statistics are quite similar to the one diagnosed from the ensemble, i.e. the EnKF for this test bed. The forecasts of the concentrations in Fig. 2a are identical for both methods. Although the dynamics for the variance in Eq. (10b) and the anisotropy in Eq. (10c) are exact in the PKF system, a significant difference is observed between the forecasts of the two methods (Fig. 2b and c). This difference is due to errors in the EnKF rather than errors in the PKF. Note that the model error that affects the EnKF can be corrected by performing high-resolution simulations (Nx=723; see Appendix A for details). This highlights some of the limitations of the numerical validation of the PKF by an ensemble method in the presence of model error. This numerical experiment shows that the PKF is able to produce high-quality forecasts of the diagnoses of the forecast-error statistics, a result that is confirmed by looking at the forecast-error correlation functions (see Appendix B).
This example shows the motivation behind the PKF: it is able to predict the (main parameters of the) error covariance with a good skill and at a low numerical cost. This low numerical cost first concerns the computer memory: the information contained in a covariance matrix of size in the ensemble case is reduced by the covariance model in Eq. (7), which only needs a few parameters of sizes of order 𝒪(Nx) (with 𝒪 being the “Big O” notation, meaning “proportional to”). However, the low numerical cost also concerns the time taken to predict the uncertainty: the PKF only relies on the single time integration of Eq. (10), which represents the cost of 3 time integrations of the initial dynamics in Eq. (9b) compared to the 6400 time integrations required for the ensemble used here.
As another advantage, the PKF provides information about the physics of the uncertainty: when ensemble diagnosis only observes the time evolution of the statistics without any explications, the PKF provides a simplified proxy that details the origins of these statistical evolutions with only three equations, and thus the PKF improves our knowledge of uncertainty dynamics.
The exploration of the multivariate extension is now addressed. For multivariate problems, a modellization of the cross-correlation functions (or inter-species correlation functions) is needed. Moreover, it would be convenient to introduce a multivariate covariance model that extends the univariate VLATcov model, as the heterogeneous Gaussian model (Eq. 7), to take advantage of the PKF dynamics of univariate statistics.
Because multivariate modelling is a difficult topic, a multivariate covariance model is proposed in a simplified test bed in Sect. 3.1, where data-driven modelling is considered to determine a multivariate covariance model and its parameters. Next, the multivariate PKF is formulated, detailing the prediction and the analysis steps in Sect. 3.2. Finally, two numerical assimilation experiments are conducted in Sect. 3.3.
3.1 Development of a proxy multivariate covariance model
3.1.1 Introduction of the simplified chemical transport model
To explore a multivariate formulation of the PKF, a simplified chemical transport model is introduced that mimics the MOCAGE framework. This simplified CTM contains the essential features of what can be found in a more realistic CTM, i.e. advection, multiple chemical species, and non-linearities.
To do so, a 1D periodic domain of coordinate x is considered, where two non-linearly reactive chemical species, A(t,x) and B(t,x), are advected in a conservative way by a heterogeneous and stationary wind field u(x). The non-linear reaction is given by the Lotka–Volterra (LV) equations (see Appendix C), which leads to the coupled dynamics
where the transport is written following the univariate 1D example in Eq. (9b) and where the LV reaction appears as the last two terms on the right-hand side of each prognostic equation. The constants k1, k2, and k3 characterize the reaction rates: k1 corresponds to the rate at which A is produced, constant k2 represents the rate at which the chemical reactions between A and B produce 2B, and k3 describes the decay rate for species B. Note that, at a formal level, the state vector associated with Eq. (13) is then .
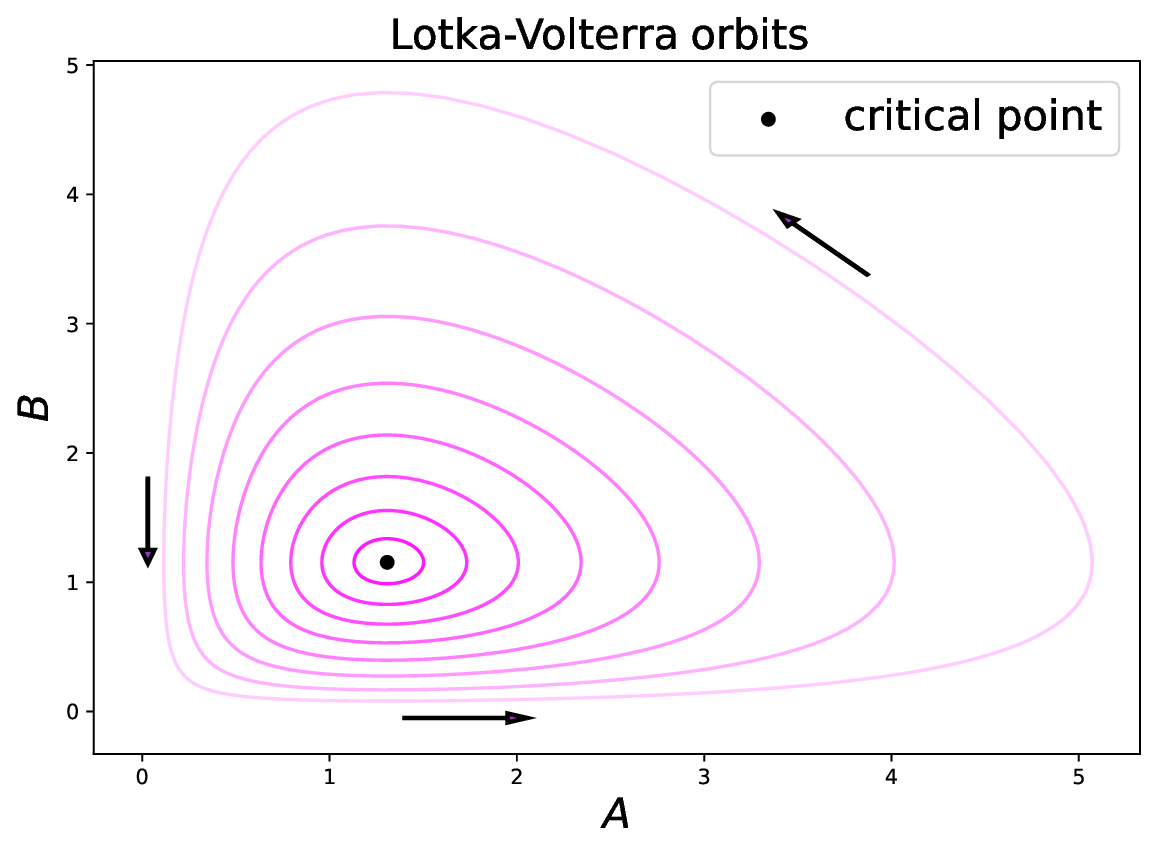
Figure 3Numerical simulations of the Lotka–Volterra dynamical system whose solutions are periodical orbits (purple curves with different transparencies), flowing anti-clockwise around the critical point (black dot).
Considered as a dynamical system of ordinary equations and represented in the phase space (A,B), the solutions of the Lotka–Volterra dynamics are periodical orbits flowing around the critical point of coordinates , as shown in Fig. 3. This is the kind of time evolution observed at each grid point when there is no wind (u=0).
In this multivariate framework, the error-covariance matrix P=𝔼(ε𝒳(ε𝒳)T) associated with the state , of error , reads as a block matrix
where PA and PB are the auto-covariance matrices of the errors, and PAB is the cross-covariance matrix, or the inter-species covariance matrix, of the errors. Note that, in general, PAB is not symmetric, i.e. . The two-point cross-covariance function between grid points of coordinates x and y is written as
where
is the cross-correlation function. The cross-correlation function is not symmetric in general, i.e. . In particular, if CAB denotes the associated cross-correlation matrix, then .
From a covariance-modelling point of view, and from the perspective of the PKF, the univariate covariances PA and PB could be approximated by a VLATcov model, e.g. P(VA,sA). Moreover, the single-point cross-covariance field defined as will appear in the dynamics of VA and VB because of the coupling due to LV equations and should be considered a natural parameter for a multivariate PKF. At this stage, the question is whether it is possible to approximate the two-point cross-covariance functions PAB(x,y) knowing the parameters , which are functions of x.
Since no multivariate modelling extending the VLATcov model is available, a numerical exploration of the dynamics of multivariate statistics is performed for the LV CTM so as to guess a proxy for the cross-covariance functions.
3.1.2 Ensemble of multivariate forecasts
Compared to the univariate experiment described in Sect. 2.4, without a multivariate covariance model, it is not possible to sample a multivariate ensemble. For this reason, the errors for the two chemical species are assumed to be decorrelated at the initial time t=0, so that the error-covariance matrix, P0, is the block diagonal
where is the univariate covariance associated with error in A (B). Following the ensemble generation of Sect. 2.4, the univariate covariance matrices are chosen as the two VLATcov matrices and . Then, an ensemble of Ne=6400 initial conditions is sampled, with, for each k, , where and are the block-diagonal matrix . This time, ζk is a sample of 𝒩(0,In) with n=2Nx. The domain is discretized into Nx=723 grid points.
For the simulation, the fields A0 and B0 are set to the constants A0=1.2 and B0=0.8. The univariate parameters are set to , , and with km. The reaction rates of LV are set to . The time integration follows the numerical setting used for the univariate simulation presented in Sect. 2.4 and leads to an ensemble of Ne=6400 multivariate forecasts.
While there is no cross-correlation at the initial condition, the coupling provided by the LV equations should introduce a non-zero cross-correlation between errors in A and B, and this can be diagnosed from the computation of the ensemble estimation of the two-point forecast-error cross-covariance function PAB(x,y) at time t, given by
with and , where and are the empirical means of the ensemble of forecasts (Ak) and (Bk), from which an estimation of the cross-correlation functions and matrix can be deduced.
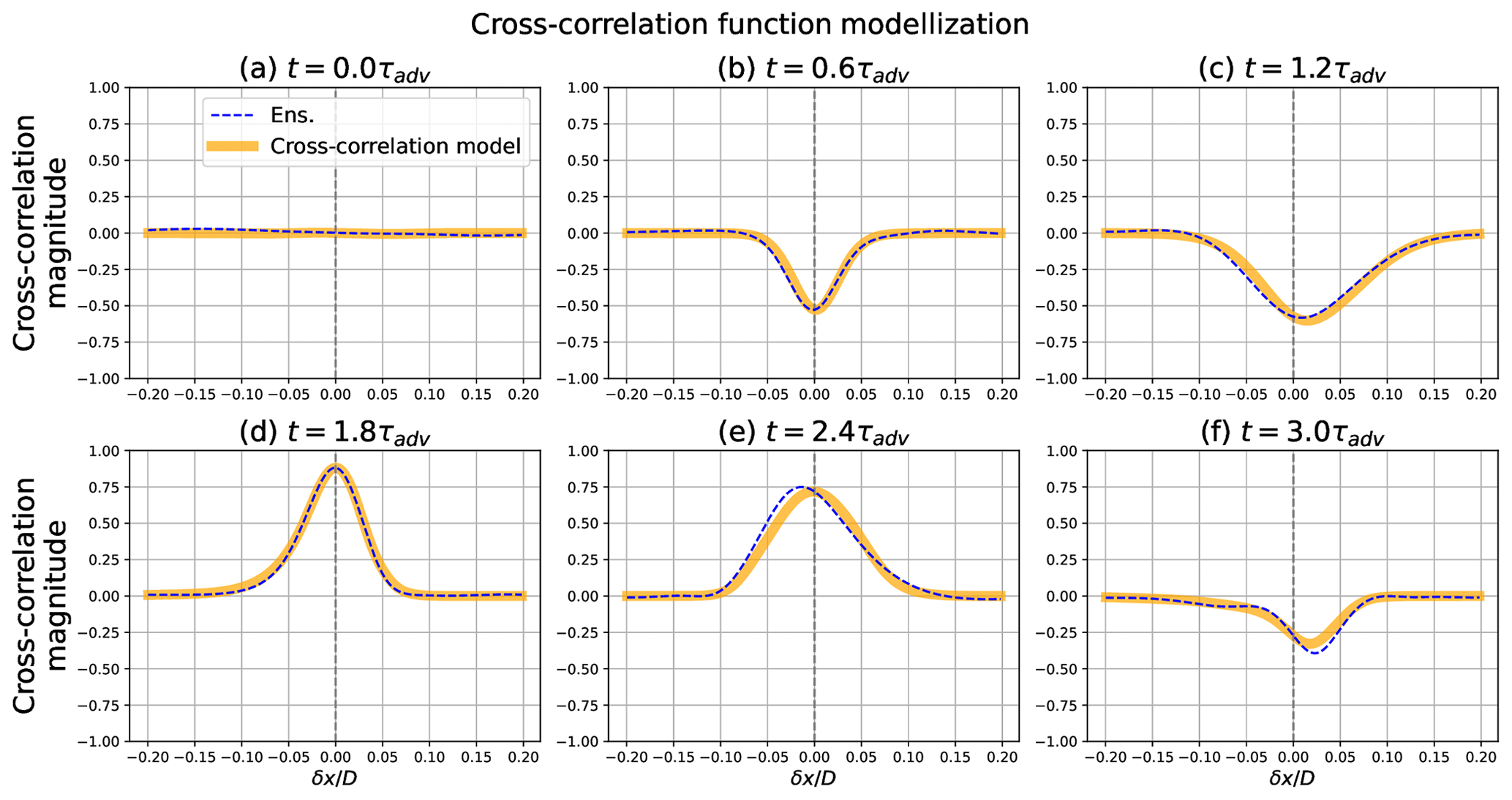
Figure 4Evaluation of the cross-correlation model (bold orange line) versus the ensemble estimation of the cross-correlation (blue dashed line) with respect to the location xl=0.5 and times .
Figure 4 shows the time evolution of the cross-correlation with respect to the grid point xl=0.5, i.e. the function . As has been specified, the cross-correlation is zero at t=0 (Fig. 4a). Then, as expected, the cross-correlation evolves along the time, presenting an anti-cross-correlation at t=0.6τadv (Fig. 4b) and then a positive one at t=1.8τadv (Fig. 4d). At t=2.4τadv (Fig. 4e), the cross-correlation appears clearly asymmetric while reaching its maximum value at a y strictly lower than xl.
3.1.3 Formulation of a proxy for the cross-correlation
Now, a proxy for the cross-correlation is introduced from the data set of multivariate forecasts.
After a trial-and-error process, and inspired by the VLATcov model in Eq. (7), the following expression,
as a function of the known parameters , has been proposed as a proxy for the cross-correlation ρAB, i.e. . It consists of an interpolation by the mean of the cross-correlation values at location x and y, multiplied by a Gaussian kernel, where the univariate aspect tensor has been substituted by the mean of the aspect tensors of all chemical species. The resulting proxy for the cross-correlation matrix is denoted by .
One of the main advantages of considering a simple analytic formula is that it can be extended to a problem with more chemical species and for a domain of a higher dimension.
Note that formulation Eq. (19) is symmetric (), while cross-correlations are not symmetric in general (), but this expression leverages all the parameters known at locations x and y. However, the function is not necessarily symmetric in δx, where, in general, .
To assess the skill of the proxy, Fig. 4 shows the functions (computed from Eq. 19 with the ensemble-estimated parameters ) compared with the ensemble-estimated cross-correlation . At a qualitative level, the functions rAB are in accordance with the cross-correlation ρAB of reference for all the panels. Note that, while rAB is symmetric, the functions can be asymmetric as they appear in Fig. 4c and f.
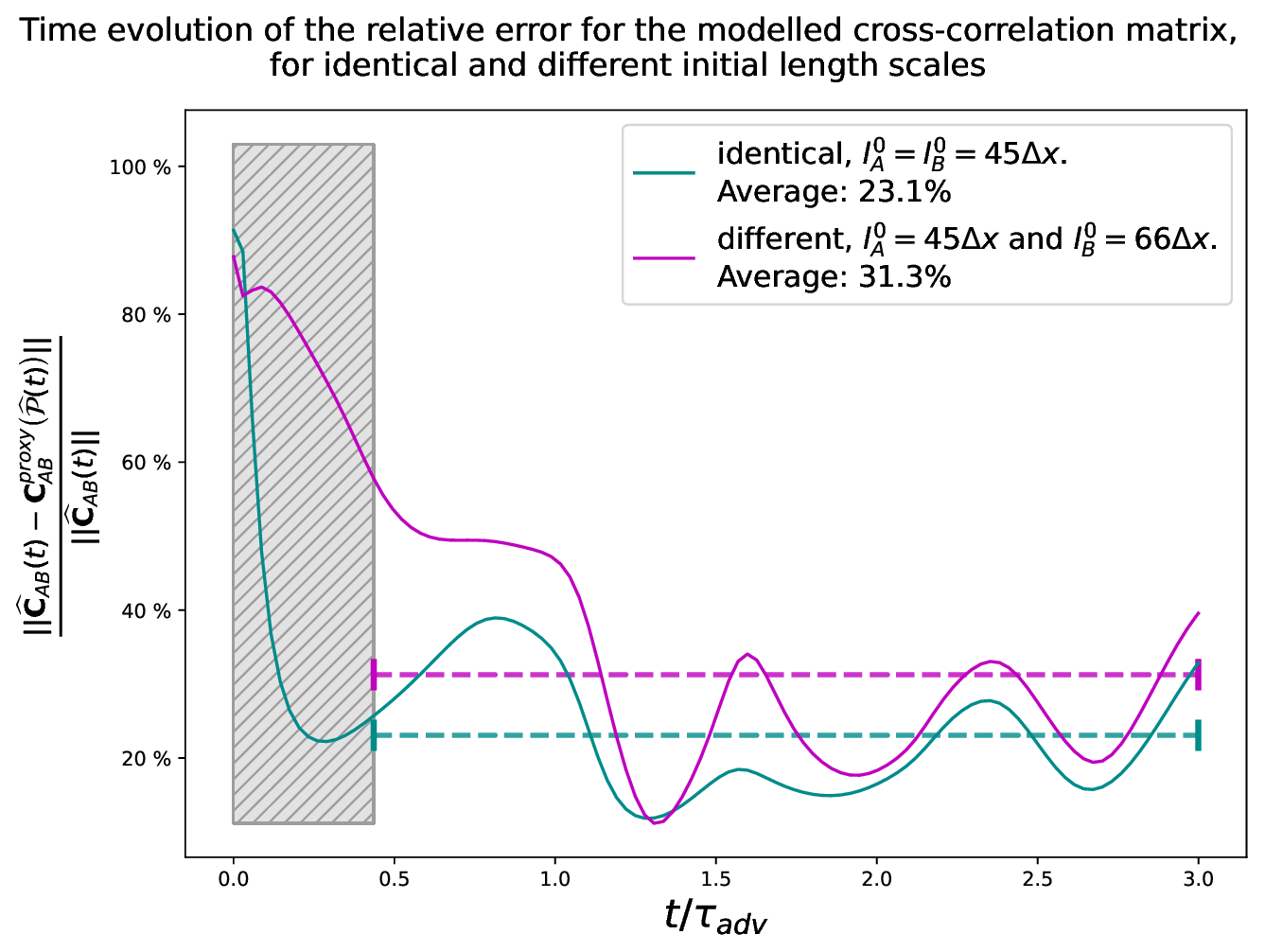
Figure 5Time evolutions of the relative errors between the empirical cross-correlation matrix (EnKF) and the proxy-generated cross-correlation matrix fitted with EnKF-diagnosed parameters for two different settings of the initial length scales: equal length scales with km (turquoise line) and different length scales with and km (mauve line). The results being dominated by sampling noise for t<0.45, they are not retained (grey hatching) for the computation of the temporal averages (dashed segments).
At a quantitative level, Fig. 5 shows the time evolution of the relative error , where is the Frobenius matrix norm where Tr is the trace operator, is the ensemble estimation of the cross-correlation matrix, and is the proxy for the cross-correlation matrix fitted with ensemble-estimated parameters . Two different experiments are shown depending on whether the initial length scales for A and B are equal, km (turquoise lines), or different, km, but km (purple lines).
As the two multivariate error fields are uncorrelated at the initial time, the true cross-correlation matrix CAB(t=0) is zero. However, the ensemble used in the estimation of being finite, this produces a spurious non-zero cross-correlation leading to a non-zero matrix and to a relative error larger than 80 %. Then, the first instants of the simulation are dominated by the sampling noise, and they are excluded for the analysis of the results (grey hatching). After t≃0.45, the experiments offer valid results and lead to temporal averages of 23.1 % when (turquoise dashed line) and 31.3 % when . Note that the effect of the sampling noise can lead to an overestimation of 8 % for this kind of experiment (Pannekoucke, 2021a).
According to our knowledge, no proxy of cross-correlations similar to Eq. (19) has been introduced up to now as a possible proxy of cross-correlations. As mentioned above, rAB does not share the same property of the cross-correlation (e.g. rAB is symmetric, while ρAB is not), and thus there is no guarantee that a multivariate covariance model based on the proxy rAB will lead to a true covariance matrix: such a multivariate covariance model is symmetric because rAB is symmetric but not necessarily positive definite, although it may not be essential for the PKF applications.
Despite the limitations of the proxy, a multivariate extension of the univariate VLATcov model is explored below, where the cross-correlation is approximated by the proxy in Eq. (19). This leads to a multivariate VLATcov model of parameters for fields , for which we can formulate a PKF.
3.2 Formulation and simplification of the parameter dynamics and analysis
3.2.1 PKF dynamics for the LV CTM
The computation of the PKF dynamics leverages the SymPKF package which, applied to the dynamics Eq. (13), provides the following system of coupled equations.
The overlines of the mean states and have been discarded for the sake of simplicity. The PKF is a second-order filter in which the variances of the fluctuations modify the time evolution of the mean states, e.g. by the term −k2VAB of Eq. (20a).
For the dynamics of the anisotropy in Eqs. (20f) and (20g), the contributions due to the transport (to the chemistry) are labelled () for identification.
Note that the dynamics induced by the transport process are exact, as mentioned in Sect. 2.4. In the PKF system in Eq. (20), the dynamics of the mean concentrations A and B, variances VA and VB, and cross-covariance VAB, Eqs. (20a) to (20e), are independent of the anisotropy field in Eqs. (20f) and (20g). The reciprocal is not true: the anisotropy field dynamics (Eqs. 20f–20g) are forced by the means, the variances, the cross-covariances, and their spatial heterogeneity. Equations (20a) and 20b also indicate an interaction between the cross-covariance and the mean concentrations.
The dynamics of the aspect tensors, Eqs. (20f) and (20g), are not closed: some terms are expressed as expectations of the normalized errors and . These open terms cannot be directly expressed using the available parameters, preventing the forecast of the error statistics.
3.2.2 Closure of the PKF dynamics
A closure is proposed for the LV CTM multivariate PKF dynamics. Note that the open terms of the PKF dynamics Eq. (20) can be related to spatial derivatives of the cross-correlation Eq. (16), e.g. or , leading to a closure of the PKF dynamics when the proxy rAB Eq. (19) is used in place of the true cross-correlation ρAB. However, numerical investigation of this closure did not lead to good results (not shown here).
From a detailed quantification of the impact of the chemistry alone (see Appendix D1) and of the relative contributions comparing the importance of the advection versus the chemistry (see Appendix D2), the result is that the advection contributes 80 % of the anisotropy dynamics, while 20 % are due to the chemistry. Since the advection mainly leads the dynamics of the anisotropy, this suggests that the contribution of the chemistry in Eqs. (20f) and (20g) be removed, which leads to a closure of the PKF dynamics in Eq. (20) as
3.2.3 Extension of the PKF analysis step for multivariate assimilations
For multivariate statistics, the update Eq. (8) presented in Sect. (2) has to be modified: it can be applied to update the univariate error statistics (mean concentrations, variances, aspect tensors) but does not indicate how to update the cross-covariance fields. To apply the formula Eq. (8) in multivariate contexts, xl must refer to the observation of a species Zl at the observation location, while x refers to any species at any location.
For an observation at location xl of the chemical species Zl, the cross-covariance field between two species Z1 and Z2 updates as (see Appendix F)
where is the forecast cross-correlation function between Zl and Zi at location xl, defined by
Note that Eq. (22) also applies when one of the two chemical species Z1 or Z2 coincides with Zl. This leads to a new formulation of the PKFO1 algorithm (given by Algorithm F1 in Appendix F).
3.3 Numerical experiments: simple forecast and data assimilation over several cycles
In this section, two numerical experiments, labelled FCST and DA, are proposed to evaluate the multivariate formulation of the PKF for the LV CTM. Again, a large EnKF will be used as a reference to be compared with regarding the error statistics produced. The first experiment, FCST, focuses on the forecast step alone. Therefore, the PKF dynamics (Eq. 21) and the EnKF for equations (Eq. 13) are forecasted. Then, in DA, five complete data assimilation cycles are performed to test the PKF capacity to produce multivariate analysis. DA only differs from FCST by the assimilations of observations; otherwise, the configurations are identical. The next section details the set-up of the experiments.
3.3.1 Settings of the numerical experiments
In both experiments, the EnKF relies on 6400 members. The total time of the simulation is h (τadv is the characteristic time defined in Sect. 2.4). A high resolution with Nx=723 grid points is used. The settings of the wind field, chemical rates, initial concentrations, initial variances and cross-covariance, time scheme, and space grid are identical to those used in Sect. 3.1.2. The initial length-scale fields are homogeneously initialized at .
For the data assimilation experiment, a network of four sensors regularly spaced on the right-hand side of the domain is considered to generate observations of the chemical species A. Every h, observations are generated from an independent nature run and assimilated for both filters. The nature run is initialized with field concentrations A and B set respectively to 1.2+0.12ζA and 0.8+0.08ζB, where ζA and ζB are structured Gaussian random fields of zero mean, standard deviation 1, and length scale 45Δx (i.e. sampled from P(1,(45Δx)2) in Eq. 7). The synthetic observations are considered uncorrelated in space and time (i.e. at a given time, R is diagonal) and generated at the analysis time ta according to , where σobs=10 % is the observations' standard deviation, is a sample from the standard Gaussian distribution, and is the forecast of the nature run for location xl. The model error is neglected in this experiment (i.e. Q=0 in Eq. 3b). For the PKF, the observations are assimilated using the PKFO1 algorithm.
3.3.2 Results
The results for the FCST experiment are shown in Fig. 6. The figure presents the state vector (Fig. 6a and b) and five error statistics (Fig. 6c–g) for the EnKF and the PKF at and . The error statistics presented are, from Fig. 6c to g, the two standard deviations, the cross-correlation field, and the two length scales rather than the raw PKF parameters. A horizontal grey line in each panel is here to represent the initial setting of the corresponding quantity.
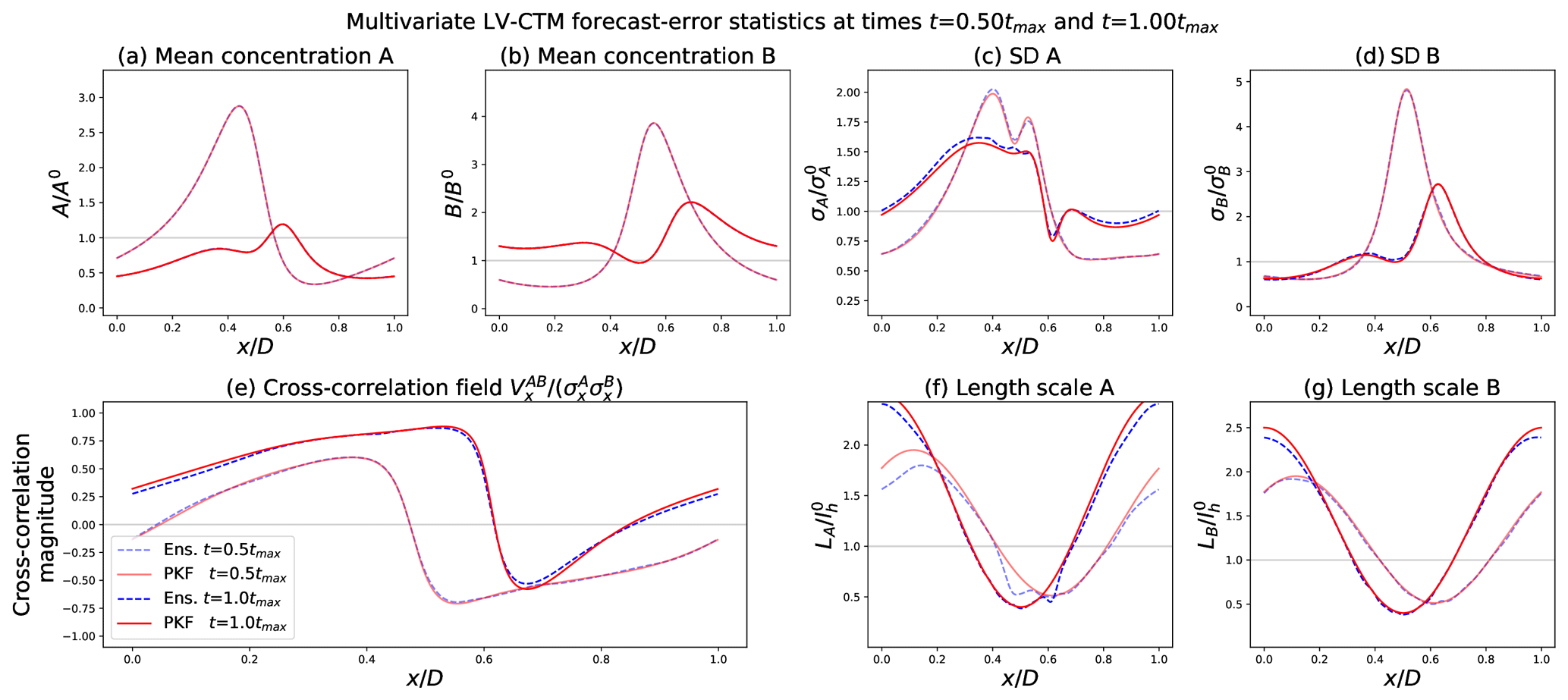
Figure 6Results of the forecast numerical experiment. PKF error statistics (solid red lines) and EnKF-diagnosed error statistics (dashed blue lines) at times . These times correspond approximately to t=23 h 45 min and t=47 h 40 min.
The forecasts of the means match perfectly for both methods (see Fig. 6a and b). Similarly to the univariate advection experiment (Sect. 2.4; see Fig. 2), an accumulation of the tracers is observed in the low-wind-speed region (centre of the domain). The standard deviations (Fig. 6c–d) observe a similar behaviour, although the effects of the chemistry appear more clearly: the curves show some quite localized deformations, especially for the standard deviation of A (compare Fig. 2b). The cross-correlation field in Fig. 6e, specific to the multivariate case, is predicted with great accuracy by the PKF dynamics. This indicates that, starting from decorrelated error fields for A and B, the chemistry dynamics have allowed non-zero cross-correlations to emerge by coupling the chemical species in a non-linear fashion. While less accurate than for the means, the filters coincide at estimating the standard deviation and for the cross-correlation fields. The forecasts of the length scales (Fig. 6f and g) show a general accordance between the two methods, even though a difference can be observed in A's case in Fig. 6f. This gap is due to the simplification of the anisotropy dynamics in the PKF formulation in Eq. (21), which does not permit such behaviours to be represented. The equation of the anisotropy dynamics of A in the original formulation of the PKF in Eq. (20f) suggests an explanation of the spikes presented on the EnKF curves in Fig. 6f which are absent for the PKF. The terms labelled TA,chem-3 and TA,chem-4 indicate a forcing of the spatial derivatives of the variance VA. Looking at Fig. 6c, it appears that the variance of A presents some strong spatial heterogeneity (x=0.45 for and x=0.60 for ), causing important magnitudes for ∂xVA and thus for TA,chem-3 and TA,chem-4. This produces a local deformation on A's length scales which is effectively observed for the same times and locations in Fig. 6f. However, these gaps between the EnKF and PKF curves are local and of a reasonable magnitude: overall, the PKF forecast for the anisotropy reproduces the EnKF results.
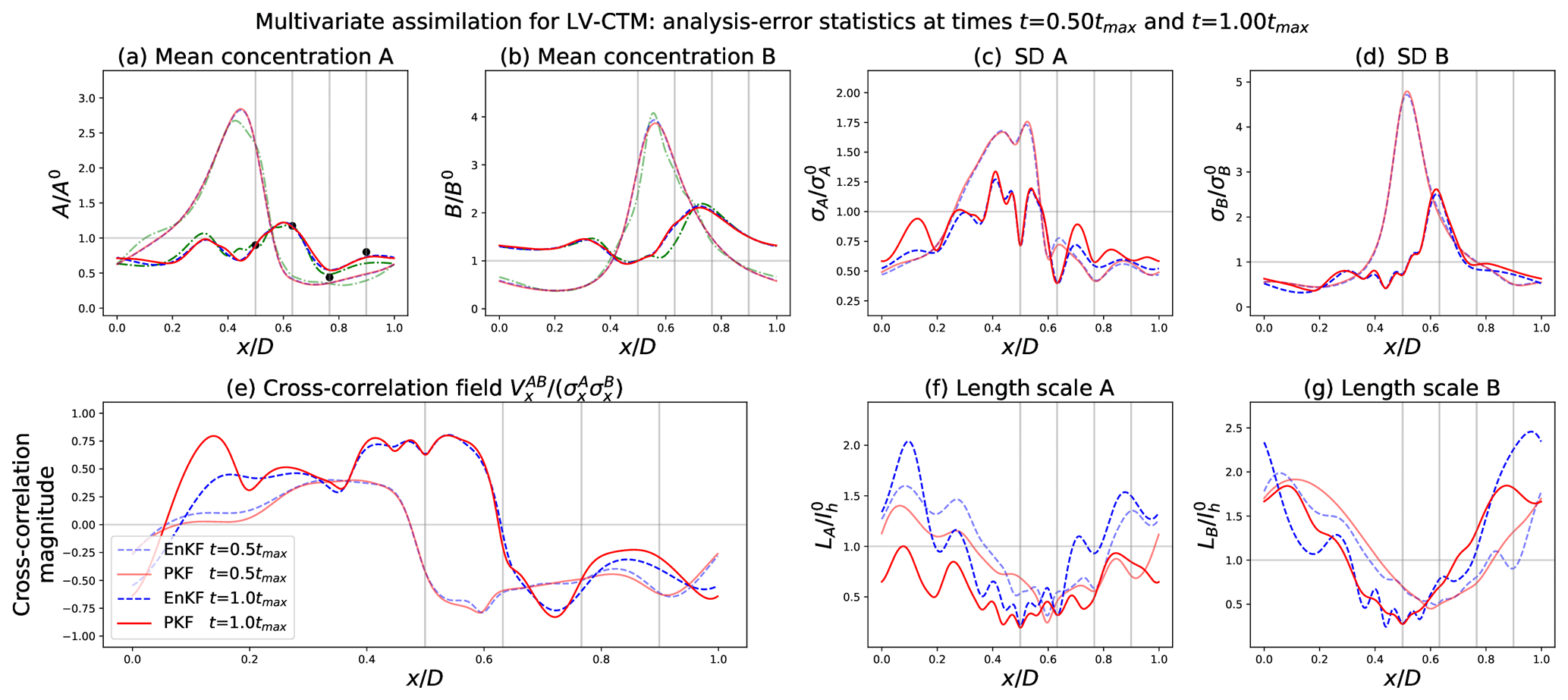
Figure 7Results of the data assimilation numerical experiment. Nature run (dash-dotted green lines, only in panels a and b), PKF error statistics (solid red lines), and EnKF-diagnosed error statistics (dashed blue lines) at times . These times correspond approximately to t=23 h 45 min and t=47 h 40 min. At time , two analysis steps have already been performed. At time , the fifth analysis step is being realized, and the generated observations are represented by black dots in panel (a). The vertical grey lines correspond to the sensor locations.
The outcome of the DA experiment in Fig. 7 is now shown, where five assimilation cycles are done over the period (one assimilation after each time integration, with ). The results are presented similarly to the FCST experiment, except that four vertical grey lines have been added to indicate the sensor locations. Also, time corresponds to a time for which synthetic observations for A are generated (see Fig. 7a).
For the DA experiment (Fig. 7), the resulting means in Fig. 7a and b are identical for the PKF and EnKF. This indicates similar forecasts and analyses for both methods during the five assimilation cycles. However, the corrections brought by the observations are not very significant given the neglected model error, the small amplitude of the forecast variance, and the observation error. This configuration implied that the generated observations are very close to the forecasted concentrations, and therefore the means are not significantly different than in the FCST experiment. The impact of the different analyses is more visible in the rest of the error statistics. For instance, the standard deviation of species A in Fig. 7c presents important downspikes which result from the uncertainty reduction during the analysis. This reduction in the uncertainty is also visible, with a reduced amplitude, in species B in Fig. 7d, for which we do not have observations. The ability to reduce the uncertainty of B and to correct its concentration when A is observed is the signature of the multivariate character of the analysis. The amplitude of the reduction in σB and correction of B is related to the strength of the cross-correlation at the moment of assimilation. The cross-correlation field in Fig. 7e is also impacted by the observation, but it is less obvious to say in which manner. Looking at Fig. 7f, an important gap between the PKF and EnKF for the length scales of A can be observed. It has two causes, the major one being the approximation in the anisotropy update formula in Eq. 8c. This simplified formula is less accurate than its second-order version in Eq. (10) from Pannekoucke (2021a) but offers more robustness during numerical simulations (see Fig. 13e from Pannekoucke, 2021a, and the discussion in their Sect. 4.4). The second reason is the reduction in the anisotropy dynamics to the transport process in the PKF formulation (compare Sect. 3.2). Compared to the FCST experiment, the assimilation of observations has had the effect of reducing the length scales.
In both of these experiments, the PKF has shown itself able to reproduce the results of a large ensemble Kalman filter. Again, these qualitative results of the PKF were obtained at a low numerical cost: the equivalent of 3 time integrations of Eq. (13) compared to 6400 for the EnKF.
It would be interesting to assess the robustness of the results, including whether the advection terms remain dominant under different conditions, such as weaker winds or accelerated chemistry, from a set of operational CTM predictions.
The simplified LV CTM has allowed for a multivariate PKF assimilation validated in numerical experiments. To explore the ability of the PKF to apply to a more complex chemical scheme, an intermediate chemical model is now introduced, the GRS (Azzi et al., 1992; Haussaire and Bocquet, 2016), which is then used to validate the PKF forecast.
4.1 Description of the GRS model
The GRS describes the dynamics of a reduced number of chemical species or pseudo species. Hence, six species are considered and interact as
where ROC, RP, and S(N)GN respectively mean reactive organic compound, radical pool, and stable (non-)gaseous nitrogen product. In this chemical model, additional processes such as photolysis rate variation, ground deposits, or atmospheric emissions of certain pollutants are represented.
The system of equations of the GRS CTM is written as
where, for a species Z, [Z](t,x) denotes the concentration field, and for , denotes the stationary emission field modulated by the smooth ocean–land mask shown in Fig. 8b and of maximum emission , whose value is given in Table 1 (right column). The ground deposition is represented by terms in λ, with a magnitude of 2 % d−1. Kinetic parameters and chemical reaction rates are set as follows: since Eqs. (25a) and (25c) depend on the solar radiation, k1 and k3 evolve in time to represent the diurnal cycle, while they are related by k1=0.152k3 (Fig. 8c); the other rates are constant and given in Table 1.
Table 1GRS settings.

In the k3 definition, the symbol ≡ corresponds to the modulo operator. Emission rates (ppbC d−1) for ROC or (ppb d−1) for NOx and the kinetic rates (ppb−1 min−1), except for k3 and k1 (min−1).
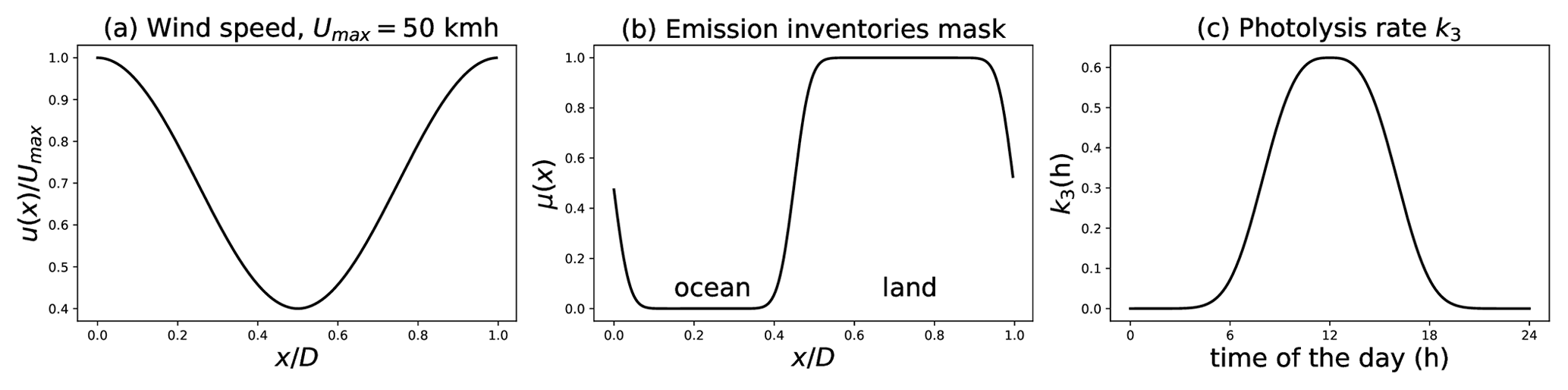
Figure 8Settings of the GRS CTM, with the pre-defined heterogeneous and stationary wind field (a) and emission inventory mask (b) and with the diurnal cycle of the photolysis rate k3 (min−1) (c) as they are used for the simulation.
4.2 The PKF for the GRS chemical transport model
In a new numerical experiment, the PKF forecasts will be compared with those of an EnKF (of size 1600). There is no observation assimilation in this simulation.
Given the complexity of the set of Eq. (25) and the increased number of species in comparison to the LV CTM in Eq. (13), the equations of the PKF dynamics for the GRS CTM are not presented in this article but can be found in additional material (https://github.com/opannekoucke/pkf-multivariate, last access: 9 June 2023). In this context, the PKF system describes the dynamics of 33 prognostic parameters: 6 mean fields, 6 univariate variance fields, 6 anisotropy fields, and 15 cross-covariance fields (corresponding to the number of pairs of chemical species). In terms of complexity, the PKF dynamics for the GRS CTM are similar to the simplified LV CTM: the transport part is the same, while the chemical part presents the same kinds of interactions between the chemical species. However, the stationary heterogeneous emissions, not present in the LV CTM, imply a forcing in the dynamics of the mean concentrations in the GRS CTM but without an effect on the uncertainty because the emissions are not stochastic here. Note that uncertainties in emission inventories can be introduced in a PKF formulation, e.g. as a source term in the variance dynamics, and are related to the specification of boundary conditions in a PKF (Sabathier et al., 2023). Similarly to the LV CTM, the dynamics of the anisotropy are closed by removing the terms due to the chemistry. Hence, later, the dynamics of anisotropy in the GRS CTM are only due to the transport.
4.3 Numerical experiment: forecast
For the settings of this numerical experiment, the resolution of the grid has been reduced to Nx=241 grid points and the time step to h to support the stiffness of the GRS equations. Some parameters remain unchanged: RK4 temporal scheme, finite differences to approximate spatial derivatives, choice of the wind field (Fig. 8a). The forecast starts at t0=00 h (midnight) and ends at h.
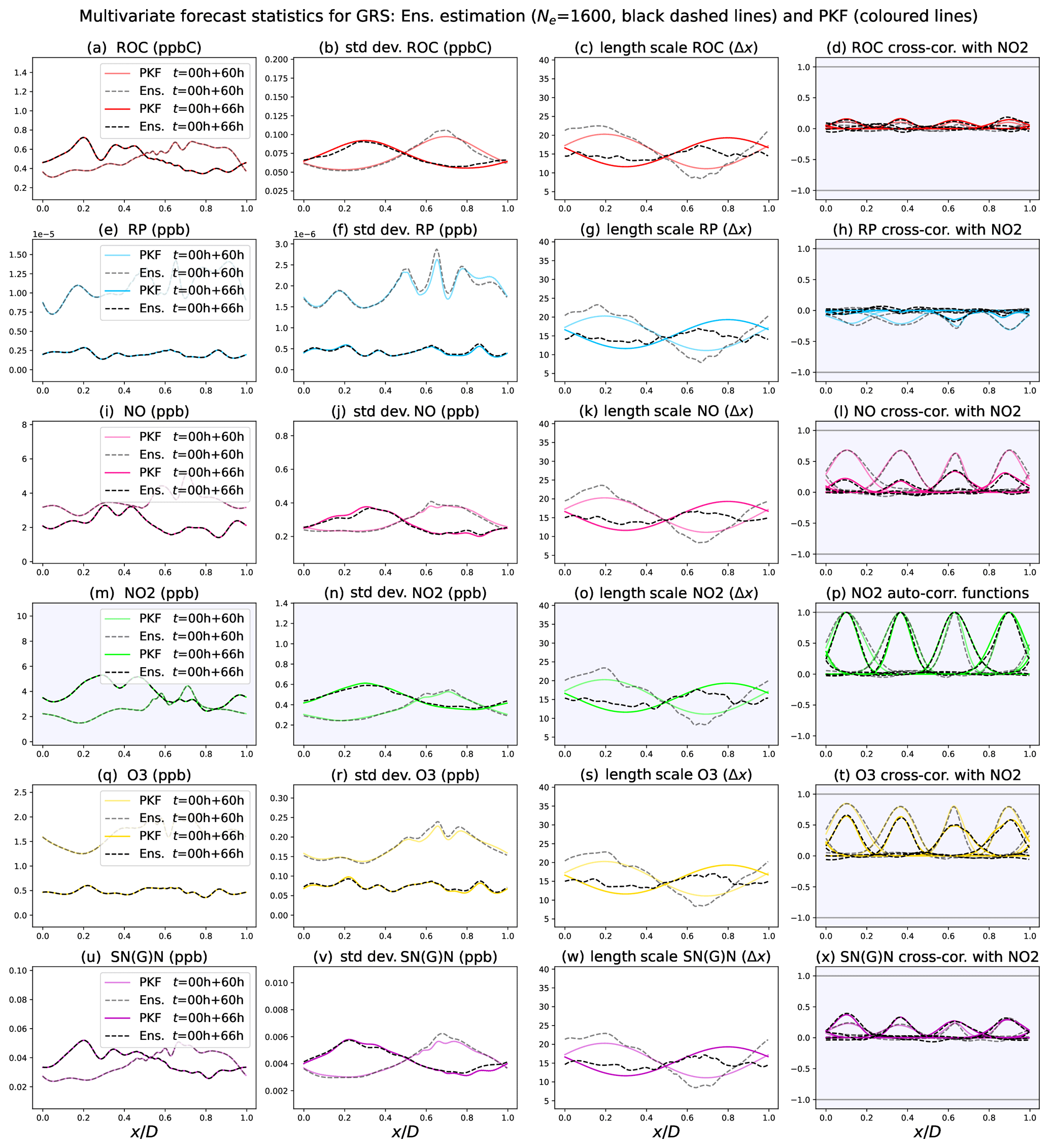
Figure 9Multivariate forecast statistics for the GRS CTM, PKF outputs (coloured lines), and ensemble estimations from Ne=1600 forecasts (black dashed lines) for times t=00 h + {60,66} h. As we consider a simulation that starts at midnight of day 0, t=00 h + 60 h (slight transparency on the curves) corresponds to midday of day 2 and t=00 h + 66 h (no transparency) to 18:00 of day 2. From left to right, the columns correspond to the forecasts of the mean concentration, the standard deviation, the length scales (normalized by Δx), and the correlation functions (auto and cross) with NO2 at locations for each of the six species (rows).
Realistic heterogeneous initial concentration fields are constructed as follows. First, starting from zero concentrations, a chemical equilibrium state is computed from a 4-week time integration of a 0D version of Eq. (25) where the transport has been switched off, while the concentrations are forced by their respective emissions . The resulting concentrations are denoted by . Then, 1D concentration fields are constructed, defined as constant and equal for each species to the final value of the 0D integration. The resulting homogeneous concentration fields are then independently perturbed to produce heterogeneous concentration fields, more realistic than the homogeneous concentrations: for any species Z of the six chemical species, the resulting 1D perturbed field , where with P, is a homogeneous Gaussian correlation version of Eq. (7) with variance 1 and constant length scale lh=12Δx, and ζ is a sample of Gaussian random vector . These perturbed 1D fields of concentrations correspond to the initial condition at t0=00 h of the GRS-CTM simulations.
The initial condition for the PKF is set as follows. The mean state is given by the six 1D fields [Z]0(x). The multivariate initial uncertainty is set as univariate (no cross-correlation) with a magnitude of for each of the six species, with univariate homogeneous Gaussian correlation of length scale 15Δx (60 km), and the length scales are identical for all the species.
For the validation, an ensemble of 1600 initial conditions has been populated, consistently from the PKF initial conditions, by adding univariate perturbations to the GRS-CTM initial condition. For each member k of the ensemble and each field Z that is to be perturbed, , where with P is a homogeneous version of Eq. (7) with variance 1 and constant length scale lh=15Δx and ζ is a sample of a Gaussian random vector .
Figure 9 shows the statistics produced by the PKF and EnKF experiments at two instants: t=00 h + 60 h and t=00 h + 66 h. These times correspond to 12:00 and 18:00 of day 2. Each row features the uncertainty for a species Z with respectively the mean, the standard deviation, the length scale, and a selection of four cross-correlation functions with NO2, ; this is the auto-correlation when Z is NO2 itself. The choice of NO2 for the cross-correlation is arbitrary, and other cross-correlations present the same behaviour (not shown).
Regarding the behaviour of the error statistics, the impact of the chemistry appears: the chemical reactions led to non-zero cross-correlations visible in the right column (except Fig. 9p, which corresponds to auto-correlations).
The impact of chemistry leads to non-zero cross-correlations between all pairs of species (Fig. 9, right column, except the auto-correlation in Fig. 9p). Also, the small-scale spatial variation, which was originally only present in the means, has been transferred to the standard-deviation fields, except for ROC. The effect of the transport is also present: it produces spatial heterogeneities in the means (left column), standard deviations (second column), and length scales (third column).
Compared to the EnKF, the PKF offers a high-quality forecast at a very low computational cost. The means (left column) are in perfect accordance in both methods. Slight differences can be observed regarding the standard-deviation fields (second column) but, as established in Sect. 2.4 (see Appendix A), the EnKF diagnoses are biased by the numerical model error that is significant when using the low-resolution grid (Nx=241 grid points in this simulation). The same argument applies to the length scales (third column), although they may also be governed by some underlying chemical dynamics similar to those described for Fig. 6f in Sect. 3.3.2). Since the PKF formulation considered here is closed by removing the contribution of the chemistry to the length-scale dynamics (following the simplification discussed in Sect. 3.2.2), the length-scale dynamics are the same for all the species. Moreover, starting from the same initial constant length-scale field lh, the length-scale fields predicted by the PKF are the same for all the species. Nevertheless, this does not prevent the PKF from estimating the auto-correlation and cross-correlation functions (right column). The last column presents an important result: the cross-correlation function estimations by the proxy are in great accordance with the EnKF. The proxy reproduces the variety of cross-correlation functions such as negative correlations, small amplitudes, and asymmetric structures. Despite differences in length-scale estimations, the proxy shows itself to be robust and delivers satisfying modelled cross-correlation functions (at a qualitative level). This has been observed for other cross-correlation functions (not shown here). This demonstrates the capacity of the PKF to forecast the cross-covariance fields.
Note that the specific behaviour of the ROC error variance can be understood from the PKF equations for the GRS CTM (not detailed here but available on the github repository; see https://github.com/opannekoucke/pkf-multivariate/blob/master/notebooks/annexe_notebooks/computing_grs_dynamics_with_sympkf.ipynb last access: 9 June 2023), where the dynamics of VROC, which read as
are only governed by decay (term in λ) and transport (terms in u) and are not coupled with any means – while a coupling with the means is present for other chemical species. Again, this illustrates the ability of the PKF to explain the physics of uncertainties.
This work explored a multivariate formulation of the PKF for atmospheric chemistry needs, when the PKF is formulated from the variance and the anisotropy tensor.
While a significant portion of the air quality uncertainty is due to meteorology (e.g. the uncertainty in the wind used for the transport), the present work focuses on the situation where the uncertainty in chemical variables is due solely to chemistry as it evolves during a given meteorological situation.
A simplified univariate chemical transport model was introduced in a 1D periodical domain with a heterogeneous wind field and conservative dynamics, illustrating the impact of the transport on the error statistics, and in particular the evolution of the variance and of the anisotropy (length scale) due to the wind heterogeneity. Compared with an estimation from a large ensemble of 6400 forecasts, the PKF has proven to be able to reproduce the variance and the anisotropy and also able to provide a proxy for the correlation functions. The PKF prediction has been obtained at a lower numerical cost compared with the cost of the ensemble. In addition, the PKF has been shown to be less sensitive to a dispersive model error encountered for this simulation that required computation of the ensemble at a high resolution to mitigate the effect of the dispersive term on the ensemble estimation. This simplified model proposed a proxy for multivariate covariance to approximate cross-covariances, which extends the univariate covariance model parameterized from variance and anisotropy, but the resulting multivariate covariance is symmetric with no guarantee of positiveness.
Then a simplified multivariate chemical transport model was introduced to tackle multivariate error statistics. Based on Lotka–Volterra (LV) dynamics, this test bed reproduces non-linear coupling between chemical species and the transport due to the wind, as it can be observed in a real chemical transport model. Then a multivariate PKF formulation was proposed, which made a closure issue related to the chemical part appear, but not to the transport, and concerns the dynamics of the anisotropy. A detailed analysis of the effect of the chemistry on the dynamics of the anisotropy led to an analytical solution of the multivariate evolution of the uncertainty in a 1D harmonic oscillator, which helps to understand the transfer of uncertainty from one species to another.
The PKF has permitted the understanding of the uncertainty dynamics: it offered equations that described the time evolutions of variances, cross-covariances, and anisotropies. The impacts of the advection and the chemistry have been clearly identified in the dynamics of the error statistics, allowing for a better comprehension of the overall problem. Since the relative contribution of the transport was larger than the one of the chemistry in the trend of the anisotropy, a closed form has been considered by removing the terms related to the chemistry in the dynamics of the anisotropy.
Despite this approximation, a validation test bed using an ensemble method showed that the PKF dynamics are able to predict the uncertainty dynamics for two chemical schemes based on LV. Moreover, a multivariate formulation of the PKF analysis step has been introduced, given by Algorithm F1, and several assimilation cycles have been conducted for the LV chemical scheme, showing that a multivariate PKF assimilation is possible, which is promising.
A final multivariate example, focused on the forecast step, was introduced to evaluate the potential of the multivariate PKF formulation to a larger system. In this case, the chemical scheme (GRS) describes the interaction of six species. Again, this example has shown the ability of the PKF to reproduce the EnKF error statistics.
To go further, it will be interesting to see whether the advection terms remain dominant under different conditions like weaker wind or accelerated chemistry from an ensemble of forecasts of operational CTMs, where isotropic and homogeneous correlations are often considered in variational data assimilation.
In addition, since we have focused on the uncertainty due to chemistry, it would be interesting to address the part of the uncertainty due to meteorology. For a CTM like MOCAGE, this could be done by considering an ensemble of weather forecasts with each member used as a forcing for a single CTM forecast. However, this solution would lead to multiple CTM forecasts, which would be expensive. Therefore, from the perspective of using a PKF (applied to a CTM), a less expensive solution would be to consider a single PKF forecast where the wind is uncertain (stochastic advection wind), with the wind uncertainty characterized by the variance and the anisotropy tensor estimated from the weather forecast ensemble. The challenge will be to find an appropriate closure for the unknown terms in the dynamics, including the cross-correlation between the wind error and chemical species, with the help of this contribution to multivariate statistics.
This work is a milestone in the development of a multivariate assimilation based on the PKF and applied to air quality and is an important step in extending the univariate PKF implementation to complex operational CTMs like the operational transport model MOCAGE at Météo-France. The work also highlights a drawback of the PKF: the cost of the current multivariate PKF formulation scales as the square of number of chemical species, which appears to be a limitation, at least if all the chemical species are considered in the multivariate uncertainty prediction. Hence, it would be interesting to test a PKF formulation on a reduced chemical scheme of interest for the data assimilation.
Moreover, while this contribution focused on air quality, it contributes to improving our understanding of multivariate statistics, e.g. with the analytical solution of the 1D harmonic oscillator. It would be interesting to extend this multivariate PKF formulation to other geophysical applications, e.g. numerical weather prediction, with particular attention paid to the extension of the multivariate cross-covariance proxy to the 2D or 3D domains. Compared with air quality where the chemical reactions are point-wise, geophysical equations make local interactions appear that have to be studied in view of the PKF approach, e.g. the geostrophic balance in the barotropic model.
The exploration of the uncertainty dynamics from numerical experiments, as made here to validate the PKF from an ensemble method, faces some limits. Figure 2 has shown a gap between the PKF and EnKF regarding the forecast of the error statistics (standard deviation in Fig. 2b and length scales in Fig. 2c). We now justify this observation, relating it to a model error.
As the problem is discretized for numerical simulations, the actual equation that is simulated is not exactly Eq. (9a) but rather an implicit modified equation induced by the use of finite differences for the spatial and temporal discretizations. Focusing on the spatial discretization, the modified equation is written as
which shows additional dispersive terms not present in the initial dynamics (Eq. 9a). Note that Eq. (A1) is not the full modified equation of the discretized model: in particular, it does not represent the effect of the RK4 time scheme, but the error associated with the fourth-order time scheme should be negligible compared with the spatial numerical error (second-order). Hence, Eq. (A1) should be close to the true modified equation, and the presence of additional processes may explain the significant differences observed in Fig. 2b and c: the dispersive term contributes to reducing the speed of the transport to a value lower than u, while the term implies a local exponential growing (damping) of 𝒳(t,x), where is negative (positive). This exponential evolution only contributes to the magnitude of the forecast error: i.e. it modifies the variance field, but it has no influence on the length scale (Pannekoucke et al., 2018). At the opposite end, the dispersive term influences both the variance and the length scale, as can be observed in Fig. 2c: the EnKF curves appear slightly late behind the PKF ones (the wind transports the curves toward the right), presenting a negative shift in the amplitude.
This can be understood as follows. Since Eq. (A1) is linear, it is the dynamics of the mean and of the errors in the numerical experiment. However, the typical scales of the mean and of the error are different: in this simulation, the spatial scale of the mean state is large, of order D, while the spatial scale of the errors is of order , where ; this implies that the magnitude of the negative phase shift due to the dispersive term is larger for the error than for the mean (see e.g. Korteweg–de Vries (KdV) Eq. 1.19 in Whitham, 1999, p. 9).
This justifies why the dispersion does not affect the prediction of the mean state – the estimation for the means coinciding for the two methods in Fig. 2a –, while it acts on the EnKF predictions of the variance and of the length scale, related to the error dynamics. In this simulation, the PKF in Eq. (10) is not influenced by the dispersion because the spatial scale of the variance and of the length-scale fields is large (order of D). This points out the sensitivity of the EnKF to numerical model error.
Since the magnitude of the dispersive term scales as 𝒪(Δx2), a simulation at high resolution could damp this term and would lead to attributing the gap observed in Fig. 2 to the model error.
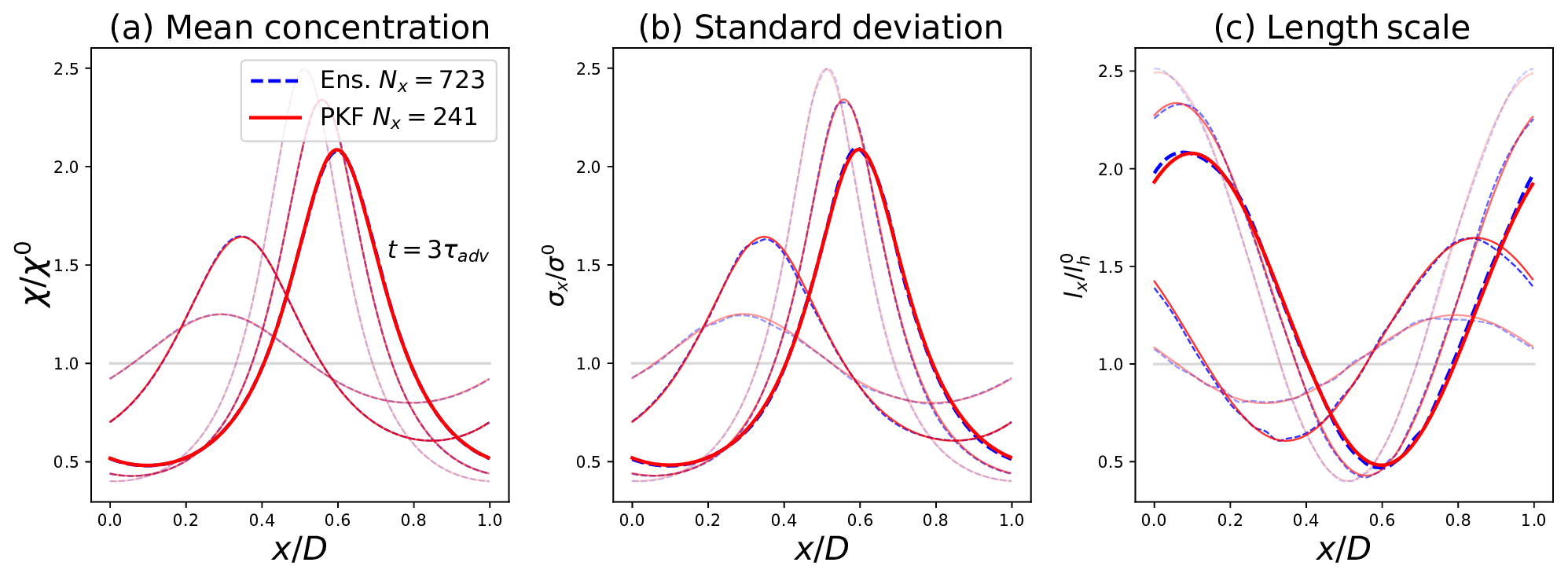
Figure A1Same experiment as Fig. 2 except that the EnKF forecast has been simulated using a higher grid definition (Nx=723) to reduce numerical model error.
This is demonstrated by comparing the PKF statistics to a high-resolution forecast of the EnKF with a grid of 3 times the original resolution, i.e. grid points. To be consistent with the initial low-resolution experiment, the initial length scale of the high resolution is set to km. The time step has been adapted in consequence to match the CFL condition. The results of this new simulation, in Fig. A1, show that predicting the ensemble at high resolution leads to the same variance (Fig. A1b) and length-scale (Fig. A1c) fields as the ones predicted by the PKF, while the latter is computed at low resolution. A PKF at high resolution has been computed (not shown here) and has been found to be equivalent to the PKF computed at low resolution, with a relative error at the end of the forecast window of lower than 0.2 % for the mean, 0.3 % for the standard deviation, and 0.05 % for the length scale, where the relative error of fields has been computed as , with the L2 functional norm defined for a function f as . This demonstrates the quality of the forecasted error statistics for the PKF, even at a low resolution. Figure B1 also shows the correlation functions computed from the high-resolution EnKF forecast. The correlation functions represented are in better accordance with the PKF-modelled correlation functions than for the low-resolution ensemble forecast: see e.g. Fig. B1d to f. This shows that the PKF is little subject to numerical model error as the error-statistic forecasts directly result from their time integration. Compared to previous studies that focused only on the comparison of variance and anisotropy error statistics, here we have shown the ability to reproduce complex heterogeneous correlation functions using the PKF formulation in the 1D domain.
Figure B1 compares the correlation functions at position xl=0.5, estimated from the ensemble for the EnKF and modelled from the predicted parameters for the PKF when using Eq. (7), at different times. At a qualitative level, the PKF is able to approximate the correlation functions, the latter being only known to within a sampling noise because of the ensemble estimation which is assumed to be low due to the ensemble size. In particular, the PKF is able to reproduce the large (small) spread of the symmetric correlations present in Fig. B1a (Fig. B1b). However, the PKF is also able to represent the anisotropy of the correlations, such as the one shown e.g. in Fig. B1e, where the correlation function at that time appears broader in its right-hand part (corresponding to x larger than xl) than in its left-hand part (corresponding to x smaller than xl).
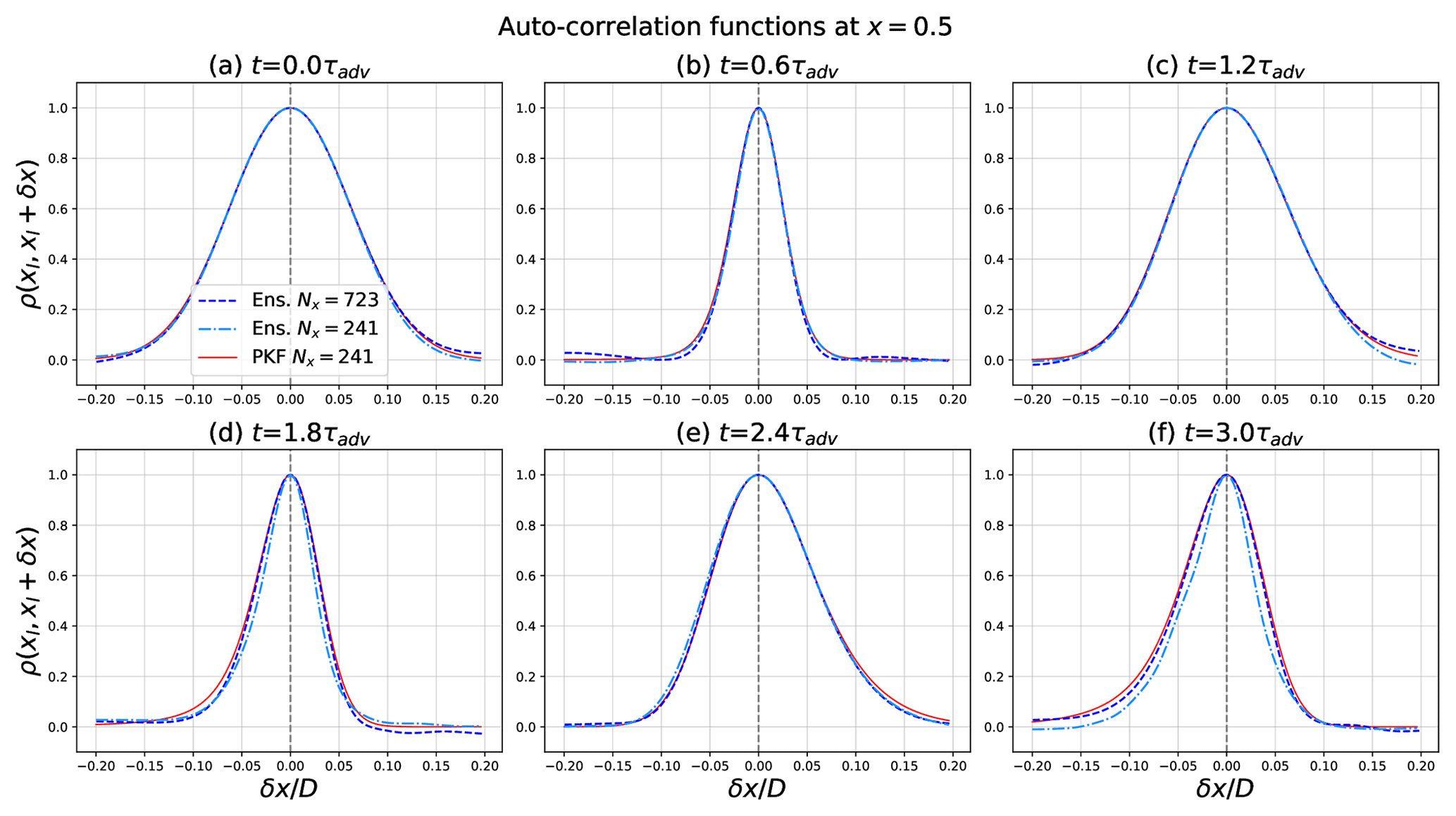
Figure B1Correlation functions at location xl=0.5 and times , computed with PKF correlation model fitted with a low-resolution (Nx=241) PKF forecast for error statistics (red lines) and diagnosed on the low-resolution (Nx=241) ensemble (cyan dash-dotted lines) and high-resolution (Nx=723) ensemble (blue dashed lines), of ensemble size Ne=6400.
We consider four chemical species , and Y governed by the chemical reactions
The kinetics of the reaction, deduced from the mass action law for reaction rates, are written as
where [⋅] denotes the concentration. When the concentrations of X and Y are constant, the system simplifies as
which is a Lotka–Volterra system.
This section contributes to evaluating the impact of chemistry on the dynamics of uncertainty with respect to the effect due to advection, leading to a closure for the PKF applied to the multivariate LV CTM.
D1 Impact of the chemistry alone on the dynamics of the anisotropies for homogeneous statistical initial conditions
Regarding the dynamics of the anisotropy fields presented in the prognostic equations (Eqs. 20f–20g), the part due to transport in is already well understood, as it comes down to the univariate case presented in Sect. 2.4. However, the role of the chemistry in is unclear at this time. The transport process is removed to focus on the dynamics of the anisotropy due to the chemistry.
In the PKF dynamics in Eq. (20), when there is no transport and when the variance fields are homogeneous at the initial condition, the homogeneity is preserved during the time evolution. Hence, the spatial derivatives of the variance and of the cross-variance fields are null, which leads to simplification of the dynamics of the anisotropy (Eqs. 20f–20g) as
To focus on the contribution of the chemistry to the dynamics of the anisotropies, an ensemble of Ne=1600 high-resolution forecasts is performed (Nx=723) with only the chemistry part. Hence, the transport terms are set to zero in Eq. (13). Two numerical experiments are conducted: first, the initial length scales are equal for both species, with km (results are shown in Fig. D1), and are then different with and km (results in Fig. D2). The initial conditions for the concentrations and the multivariate statistics are chosen to be homogeneous over the domain in both cases. Therefore, only the time series of the spatial average are shown for the variance, the cross-correlation, the length scale, and the open term , which is estimated from the ensemble by
where and .
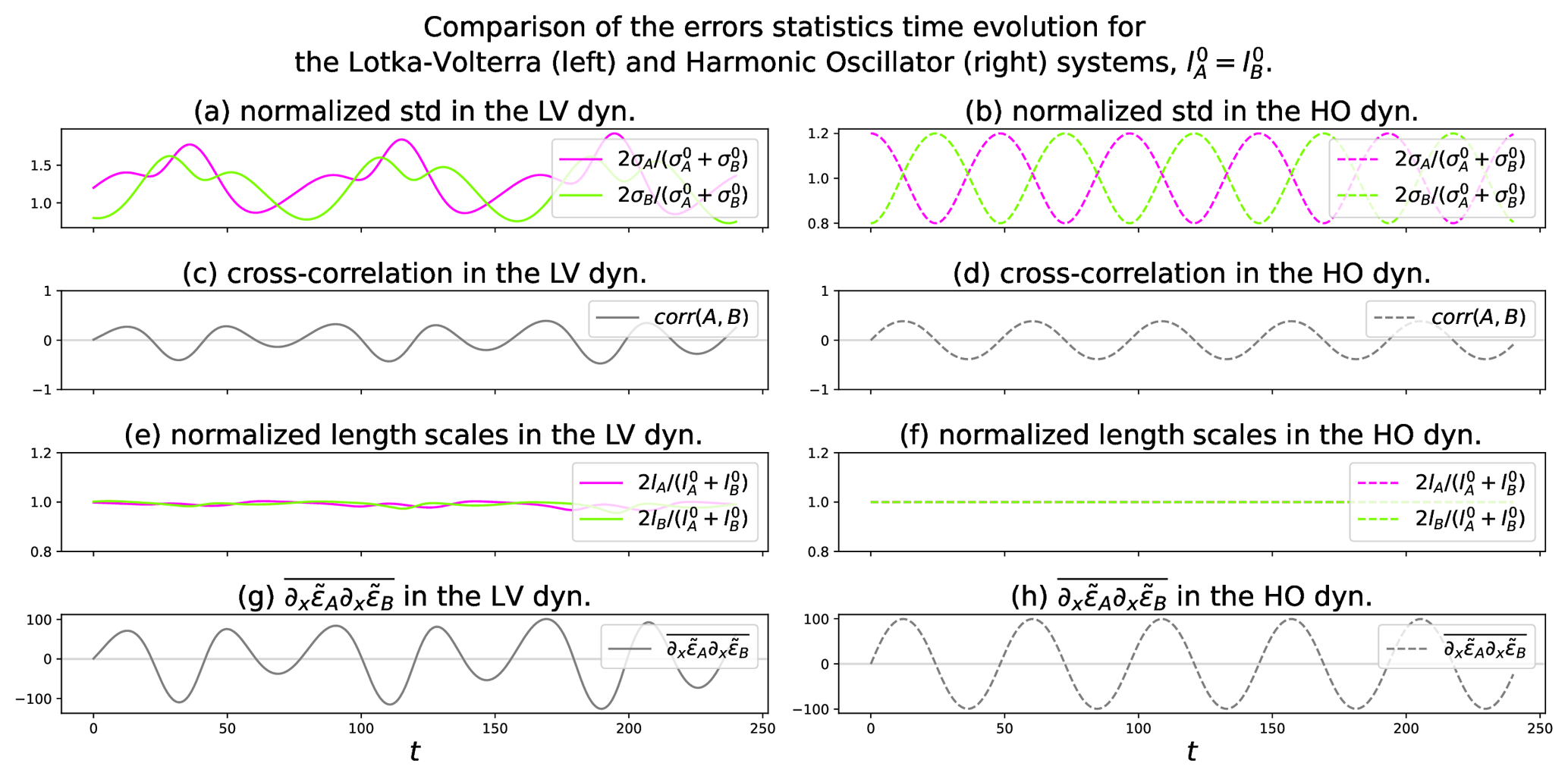
Figure D1Time series of the spatial average of the error statistics from the ensemble forecast with Ne=1600 for Lotka–Volterra (LV, left column) and harmonic oscillator analytical solutions (HO, right column). Equal initial length scales: .
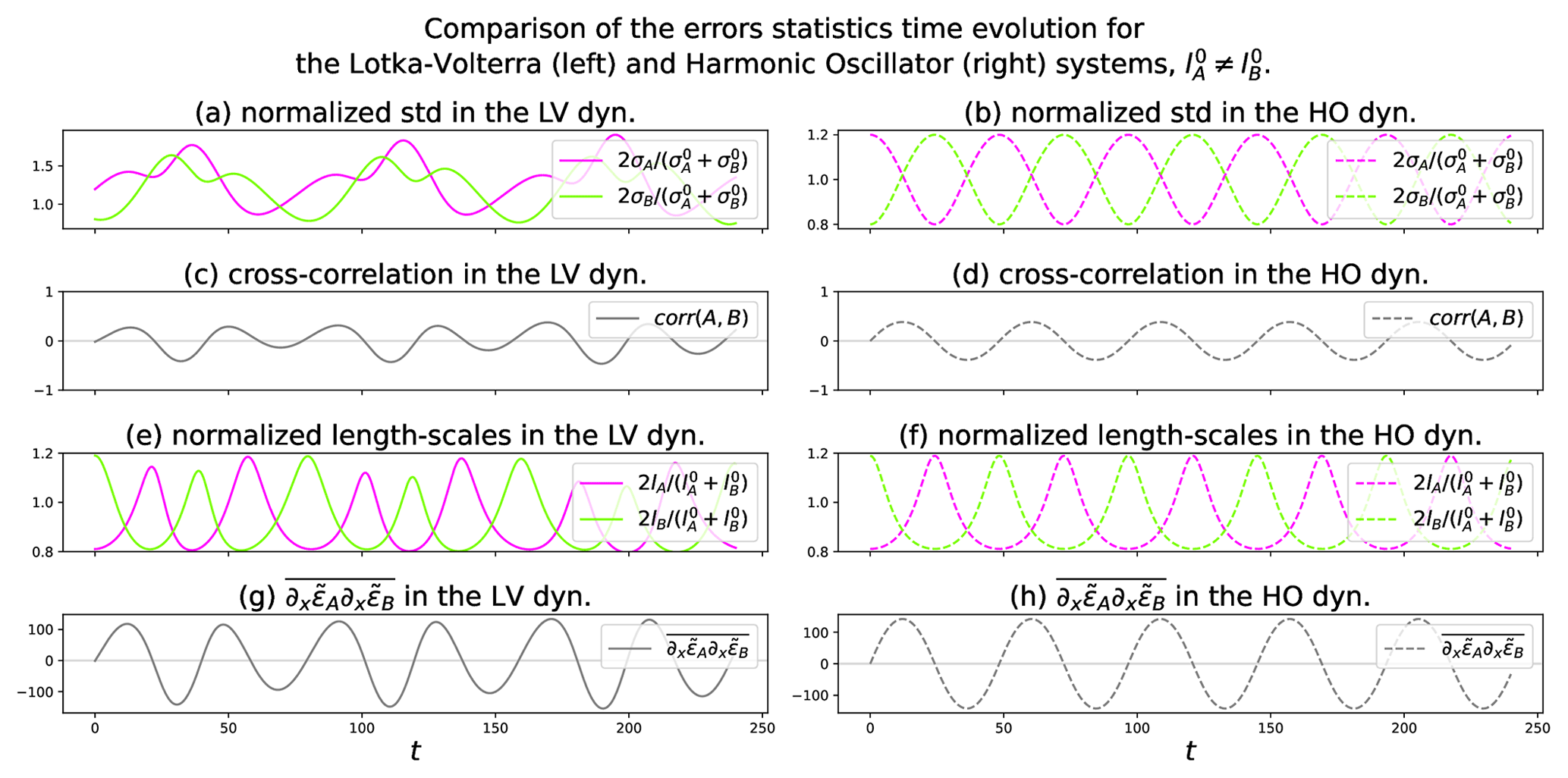
Figure D2Time series of the spatial average of the error statistics from the ensemble forecast with Ne=1600 for LV (left column) and HO analytical solutions (right column). Different initial length scales: and .
In the first experiment, Fig. D1, the magnitude of the error, given by the standard deviations in Fig. D1a, oscillates with a phase shift where the magnitude of the error in A advances the one of B. The cross-correlation in Fig. D1c and the unclosed term in Fig. D1g oscillate in a similar way. In this experiment, where the initial length scales are identical for A and B, there is no time evolution of the length scales, except the fluctuations that are due to the sampling noise (see Fig. D1e). The second experiment, Fig. D2, shows roughly the same picture, except that, this time, with initial length scales of different values, oscillations appear (Fig. D2e). Since, a priori, it is not easy to track the reason for the change in behaviour observed in the length-scale dynamics, an analytical investigation of the harmonic oscillator (HO),
is introduced, with k=k2. The comparison with HO is relevant since it is an example of analytical multivariate dynamics and also because it mimics the periodic oscillations of LV, explaining the numerical results. For HO, it is possible to calculate the time evolution of the statistics analytically (see Appendix E for details), which is written as
Numerical results computed for the HO are represented in Fig. D1 and Fig. D2 and show some of the behaviour encountered for the non-linear LV equations. For instance, the oscillations of the variance are visible. Moreover, the length scales oscillate depending on the initial condition: when the initial length scales are equal, there is no oscillation (see Fig. D1f) that appears from the analytical computation of sA and sB; in contrast, for different values of the initial length scales, oscillations appear (see Fig. D2f). These different behaviours of the anisotropy based on the initial settings of the length scales are explained by the analytical solutions of the error statistics for the harmonic oscillator. For instance, when plugging the identical initial condition for the length scales and the analytical solution of VA(t) (Eq. D4a) into the right-hand side of Eq. (D4d), it simplifies to . The same result applies for sB(t). This simplification no longer holds when , leading to non-constant length scales which are effectively observed.
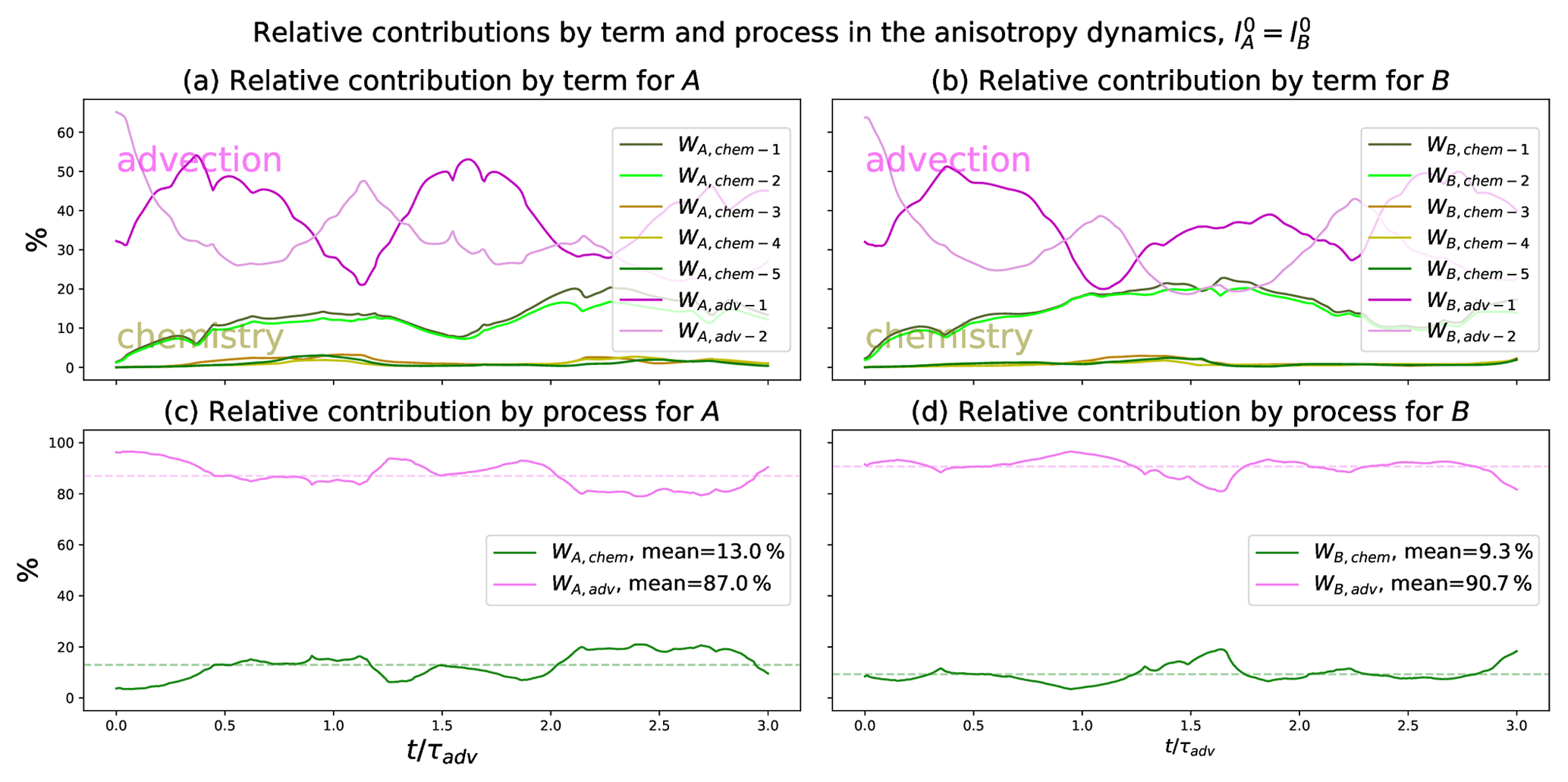
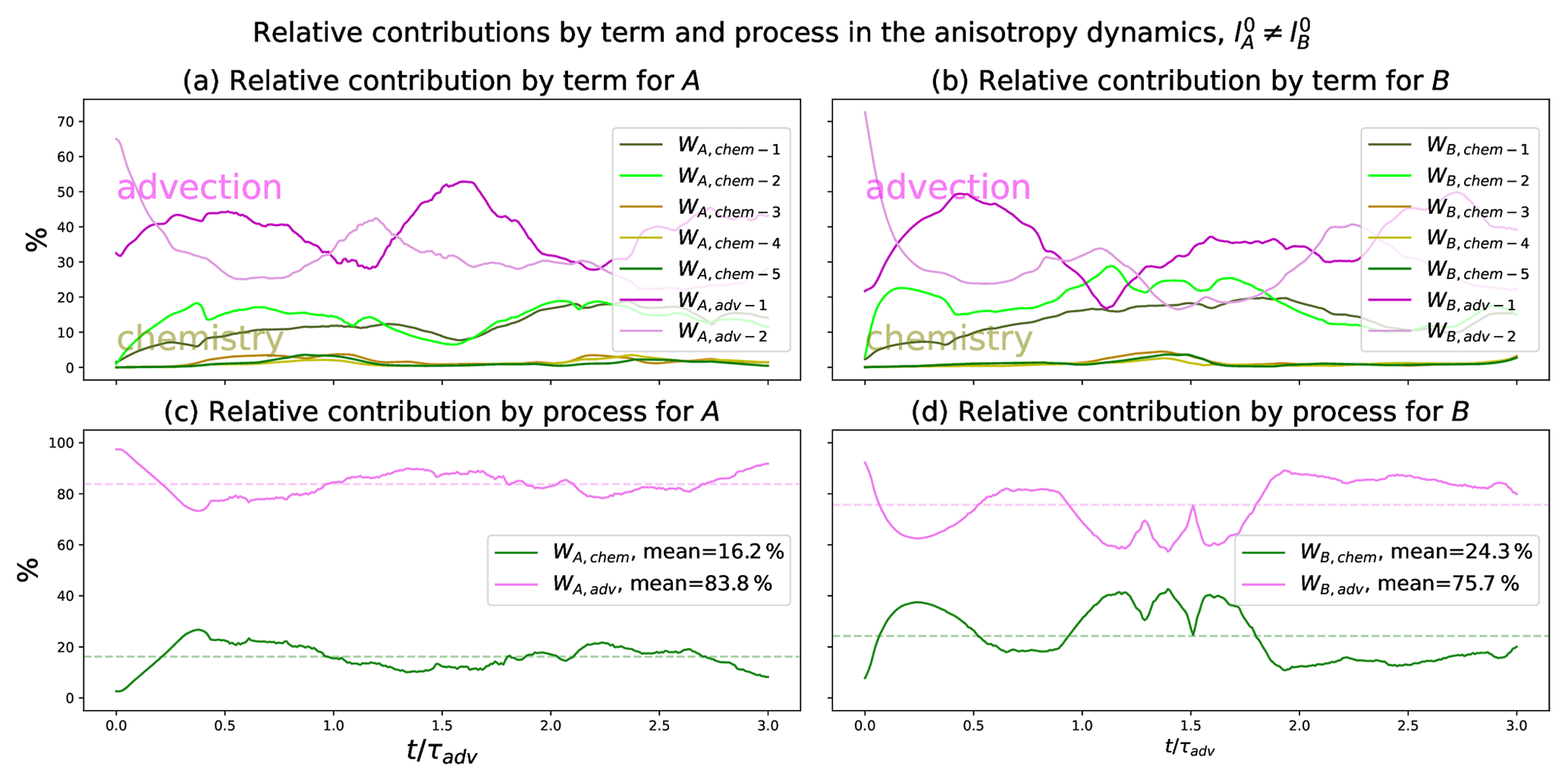
Note that, for equal initial length scales, the anisotropy appears to be stationary (see Fig. D1e), which suggests a closure for the open term : since the anisotropy is equal and constant, ; then, from the stationarity of the anisotropy, , the right-hand side of Eq. (D1) leads to the expression
This closure indicates that the term is proportional to the cross-correlation in this particular case. This is confirmed in Fig. D1, where in Fig. D1g appears to evolve as the cross-correlation in Fig. D1c. For this specific case, Eq. (D5) also applies for the error statistics of the harmonic oscillator: using and the time evolution of the cross-covariance VAB (Eq. D4c) allows us to solve for the open term in Eq. (D4f), obtaining the same expression as in Eq. (D5).
The time evolution of the HO error statistics makes an alternate transfer of the error statistics appear between the two components A and B, which qualitatively reproduces the evolution observed in the LV dynamics. The transfer of uncertainty from one component to the other is provided by the cross-covariance VAB when the error variance is different for each of the two species.
D2 Detailed contribution of each process to the dynamics of the anisotropy
The following section aims at identifying the dominant terms or processes in the dynamics of the anisotropy (Eqs. 20f and 20g).
Two different evaluations are performed. The first one evaluates the relative contribution WZ,j of the term TZ,j with respect to all other terms in the dynamics of the anisotropy of Z, which reads as
where is the L1 norm on the discretized domain [0,D). The second one evaluates the relative contribution of each physical processes in the dynamics of the anisotropy e.g. the relative contribution of the advection in the dynamics of the anisotropy of Z, WZ,adv, reads as
from which the relative contribution of the chemistry is written as . Note that the normalization is different between Eqs. (D6) and (D7).
The computation of these relative contributions will rely on ensemble of forecasts. They will be used to diagnose a posteriori the PKF parameters as well as the three open terms to then reconstruct all the terms in the anisotropy dynamics (Eqs. 20f–20g).
The quantifications of the relative contribution by term and by process will be performed for equal and different initial length scales for A and B, as they lead to different dynamics for the anisotropy. Thus, two ensembles are forecasted, with initial length scales set to in the first, and and in the second. A high-resolution grid is considered (Nx=723) to reduce numerical model error; the time step has been adapted in consequence to match the CFL. The other settings and the numerical configuration for this experiment are unchanged from previous ensemble forecast performed in Sect. 3.1.2.
The results of the relative contributions presented in Fig. D3 (Fig. D4) for the equal (different) length-scale configurations are now discussed. Regarding the relative contribution by process experiment, the comparison between Fig. D3c (Fig. D3d) and Fig. D4c (Fig. D4d) indicates that, when the initial length scales are different, , the chemistry has a more significant role (Wchem is about 21 %) compared to when the length scales are equal (Wchem is about 10 %) in the dynamics of the anisotropies. That difference was expected following the results obtained in Appendix D1. Now focusing on the relative contribution by term in Fig. D3a and b and Fig. D4a and b, it is noticeable that only the two terms and have a significant role in the dynamics. The rest of the chemistry-related terms' magnitudes are negligible. For equal initial length scales, as the chemistry-related part of the anisotropy dynamics can be neglected compared to the advection part (Fig. D3c, d) and as this part is mainly driven by and (Fig. D3a, b), this means an approximate compensation of the two terms. Eventually, this approximation simplifies to Eq. (D5), which is in accordance with the previous results of Appendix D1. However, this approximation becomes invalid in the heterogeneous case: the terms and no longer compensate each other as the gap between their corresponding curves increases in Fig. D4c and d. In some other numerical trials (not shown here), this approximation was used regardless of the length scales' initial configuration, and the remaining open terms were set to zero. These trials produced incoherent forecasts for the anisotropy, pointing out the incapacity of the approximation in capturing the true complexity of the unknown terms. Subsequently, this approximation is no longer retained.
The harmonic oscillator equations are written as
with and being functions of time and 1D space. As this problem is linear, the dynamic is identical for the errors:
Their analytical solution is given by
At the initial time, we consider the case where the errors are uncorrelated and where the variance and length-scale fields are homogeneous, i.e. , where the superscript ⋅0 is a shorthand for ascribing the fields an initial time.
From the analytical solution for the errors in Eq. (E3), we deduce solutions for the error statistics.
Following the same process, we deduce that and . We can now determine the dynamics of the metric tensor:
As we consider homogeneous fields, we have , simplifying the expression to
Then, at t=0, simplifies to and . The independence of and also implies that . Finally, we obtain
We can also deduce an analytical solution for the term , which reads, under assumption of homogeneity, as
Note that we could have derived analytical solutions in the case of heterogeneous initial fields, but for the sake of simplicity we chose to consider only the homogeneous case. However, obtaining the analytical solution when the initial error fields are correlated seems more difficult.
By introducing the true state and the error fields , and , the analysis Eq. (8a) becomes
which can be adapted to the multivariate case:
where Zl is the chemical species that is observed, Z1 can be any chemical species, and is the forecast cross-correlation function between Zl and Z1 at location xl. Writing the same equation for another chemical Z2,
and using the definition of the analysis-error covariance field leads to
Then, using the definition of the cross-correlation function , the independence between the forecast and observation errors , and the definitions of the observation error variance and forecast error , we obtain
The update of the variance in the multivariate situation leads to a new version of the PKFO1 as detailed in Algorithm F1.
Algorithm F1Sequential process building the analysis state and its error covariance matrix for the first-order PKF (PKFO1) with a pseudo-multivariate covariance model.
The code developed and used to generate the experiments is available at https://github.com/opannekoucke/pkf-multivariate (last access: 9 June 2023) and Zenodo (https://doi.org/10.5281/zenodo.7078574, Pannekoucke, 2023).
AP and OP explored the multivariate extension of the PKF and designed the experiments. A part of the work was co-supervised with VG during the master internship of AP.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We would like to thank Annika Vogel, the other two anonymous referees, and Zoltan Toth for their fruitful comments, which helped to improve the article. We thank Richard Ménard and Béatrice Josse for interesting discussions.
The Toulouse Paul Sabatier University and the SDU2E (Sciences de l'Univers, de l'Environnement et de l'Espace) doctoral school supported Antoine Perrot's thesis. This work was supported by French national programme LEFE/INSU grant “Multivariate Parametric Kalman Filter” (MPKF).
This paper was edited by Zoltan Toth and reviewed by Annika Vogel and two anonymous referees.
Anderson, J. L. and Anderson, S. L.: A Monte Carlo implementation of the nonlinear filtering problem to produce ensemble assimilations and forecasts, Mon. Weather Rev., 127, 2741–2758, 1999. a
Azzi, M., Johnson, G., and Cope, M.: An introduction to the generic reaction set photochemical smog mechanism, Proceedings of the International Conference of the Clean Air Society of Australia and New Zealand, 3, 451–462, 1992. a
Berre, L., Pannekoucke, O., Desroziers, G., Stefanescu, S., Chapnik, B., and Raynaud, L.: A variational assimilation ensemble and the spatial filtering of its error covariances: increase of sample size by local spatial averaging, in: ECMWF Workshop on Flow-dependent aspecyts of data assimilation, 11–13 June 2007, edited by: ECMWF, Reading, UK, 151–168, https://www.ecmwf.int/sites/default/files/elibrary/2007/8172-variational-assimilation-ensemble-and-spatial-filtering-its-error-covariances-increase-sample.pdf (last access: 9 June 2023), 2007. a, b
Cohn, S.: Dynamics of Short-Term Univariate Forecast Error Covariances, Mon. Weather Rev., 121, 3123–3149, https://doi.org/10.1175/1520-0493(1993)121<3123:DOSTUF>2.0.CO;2, 1993. a, b
Coman, A., Foret, G., Beekmann, M., Eremenko, M., Dufour, G., Gaubert, B., Ung, A., Schmechtig, C., Flaud, J.-M., and Bergametti, G.: Assimilation of IASI partial tropospheric columns with an Ensemble Kalman Filter over Europe, Atmos. Chem. Phys., 12, 2513–2532, https://doi.org/10.5194/acp-12-2513-2012, 2012. a
Daley: Atmospheric Data Analysis, Cambridge University Press, New York, 472 pp., ISBN-10 0521382157, 1991. a
Derber, J. and Bouttier, F.: A reformulation of the background error covariance in the ECMWF global data assimilation system, Tellus A, 51, 195–221, https://doi.org/10.3402/tellusa.v51i2.12316, 1999. a, b
Eben, K., Jurus, P., Resler, J., Belda, M., Pelikán, E., Krüger, B. C., and Keder, J.: An ensemble Kalman filter for short-term forecasting of tropospheric ozone concentrations, Q. J. Roy. Meteorol. Soc., 131, 3313–3322, 2005. a
El Aabaribaoune, M., Emili, E., and Guidard, V.: Estimation of the error covariance matrix for IASI radiances and its impact on the assimilation of ozone in a chemistry transport model, Atmos. Meas. Tech., 14, 2841–2856, https://doi.org/10.5194/amt-14-2841-2021, 2021. a
El Amraoui, L., Sič, B., Piacentini, A., Marécal, V., Frebourg, N., and Attié, J.-L.: Aerosol data assimilation in the MOCAGE chemical transport model during the TRAQA/ChArMEx campaign: lidar observations, Atmos. Meas. Tech., 13, 4645–4667, https://doi.org/10.5194/amt-13-4645-2020, 2020. a
Emili, E., Gürol, S., and Cariolle, D.: Accounting for model error in air quality forecasts: an application of 4DEnVar to the assimilation of atmospheric composition using QG-Chem 1.0, Geosci. Model Dev., 9, 3933–3959, https://doi.org/10.5194/gmd-9-3933-2016, 2016. a
Evensen, G.: Sequential data assimilation with a nonlinear quasi‐geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res., 99, 10143–10162, 1994. a
Evensen, G.: Data Assimilation: The Ensemble Kalman Filter, Springer-Verlag Berlin Heidelberg, https://doi.org/10.1007/978-3-642-03711-5, 2009. a
Fisher, M.: Background error covariance modelling, in: Proc. ECMWF Seminar on “Recent developments in data assimilation for atmosphere and ocean”, edited by ECMWF, Reading, UK, 45–63, https://www.ecmwf.int/sites/default/files/elibrary/2003/9404-background-error-covariance-modelling.pdf (last access: 9 June 2023), 2003. a
Gaubert, B., Coman, A., Foret, G., Meleux, F., Ung, A., Rouil, L., Ionescu, A., Candau, Y., and Beekmann, M.: Regional scale ozone data assimilation using an ensemble Kalman filter and the CHIMERE chemical transport model, Geosci. Model Dev., 7, 283–302, https://doi.org/10.5194/gmd-7-283-2014, 2014. a
Hauglustaine, D., Brasseur, G., Walters, S., Rasch, P., Müller, J.-F., Emmons, L., and Carroll, M.: MOZART: A global chemical transport model for ozone and related chemical tracers, J. Geophys. Res., 1032, 28291–28336, https://doi.org/10.1029/98JD02398, 1998. a
Haussaire, J.-M. and Bocquet, M.: A low-order coupled chemistry meteorology model for testing online and offline data assimilation schemes: L95-GRS (v1.0), Geosci. Model Dev., 9, 393–412, https://doi.org/10.5194/gmd-9-393-2016, 2016. a
Houtekamer, P. and Mitchell, H.: A sequential ensemble Kalman filter for atmospheric data assimilation, Mon. Weather Rev., 129, 123–137, https://doi.org/10.1175/1520-0493(2001)129<0123:ASEKFF>2.0.CO;2, 2001. a, b
Houtekamer, P. L. and Mitchell, H. L.: Data Assimilation Using an Ensemble Kalman Filter Technique, Mon. Weather Rev., 126, 796–811, https://doi.org/10.1175/1520-0493(1998)126<0796:dauaek>2.0.co;2, 1998. a
Josse, B., Simon, P., and Peuch, V.-H.: Radon global simulations with the multiscale chemistry and transport model MOCAGE, Tellus, 56, 339–356, 2004. a
Kalman, R. E.: A New Approach to Linear Filtering and Prediction Problems, Journal Basic Engineering, 82, 35–45, https://doi.org/10.1115/1.3662552, 1960. a, b
Kalnay, E.: Atmospheric modeling, data assimilation and predictability, Cambridge University Press, 364 pp., https://doi.org/10.1017/CBO9780511802270, 2002. a
Lesieur, M.: Turbulence in Fluids, Springer Netherlands, https://doi.org/10.1007/978-1-4020-6435-7, 2008. a
Lorenz, E. N.: Deterministic nonperiodic flow, J. Atmos. Sci., 20, 130–141, https://doi.org/10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2, 1963. a
Marécal, V., Peuch, V.-H., Andersson, C., Andersson, S., Arteta, J., Beekmann, M., Benedictow, A., Bergström, R., Bessagnet, B., Cansado, A., Chéroux, F., Colette, A., Coman, A., Curier, R. L., Denier van der Gon, H. A. C., Drouin, A., Elbern, H., Emili, E., Engelen, R. J., Eskes, H. J., Foret, G., Friese, E., Gauss, M., Giannaros, C., Guth, J., Joly, M., Jaumouillé, E., Josse, B., Kadygrov, N., Kaiser, J. W., Krajsek, K., Kuenen, J., Kumar, U., Liora, N., Lopez, E., Malherbe, L., Martinez, I., Melas, D., Meleux, F., Menut, L., Moinat, P., Morales, T., Parmentier, J., Piacentini, A., Plu, M., Poupkou, A., Queguiner, S., Robertson, L., Rouïl, L., Schaap, M., Segers, A., Sofiev, M., Tarasson, L., Thomas, M., Timmermans, R., Valdebenito, Á., van Velthoven, P., van Versendaal, R., Vira, J., and Ung, A.: A regional air quality forecasting system over Europe: the MACC-II daily ensemble production, Geosci. Model Dev., 8, 2777–2813, https://doi.org/10.5194/gmd-8-2777-2015, 2015. a
Ménard, R., Deshaies-Jacques, M., and Gasset, N.: A comparison of correlation-length estimation methods for the objective analysis of surface pollutants at Environment and Climate Change Canada, J. Air Waste Manage., 66, 874–895, https://doi.org/10.1080/10962247.2016.1177620, 2016. a
Ménard, R., Skachko, S., and Pannekoucke, O.: Numerical discretization causing error variance loss and the need for inflation, Q. J. Roy. Meteor. Soc., 47, 3498–3520, https://doi.org/10.1002/qj.4139, 2021. a
Meurer, A., Smith, C. P., Paprocki, M., Čertík, O., Kirpichev, S. B., Rocklin, M., Kumar, A., Ivanov, S., Moore, J. K., Singh, S., Rathnayake, T., Vig, S., Granger, B. E., Muller, R. P., Bonazzi, F., Gupta, H., Vats, S., Johansson, F., Pedregosa, F., Curry, M. J., Terrel, A. R., Roučka, Š., Saboo, A., Fernando, I., Kulal, S., Cimrman, R., and Scopatz, A.: SymPy: symbolic computing in Python, PeerJ Comput. Sci., 3, e103, https://doi.org/10.7717/peerj-cs.103, 2017. a
Mirouze, I. and Weaver, A. T.: Representation of correlation functions in variational assimilation using an implicit diffusion operator, Q. J. Roy. Meteor. Soc., 136, 1421–1443, https://doi.org/10.1002/qj.643, 2010. a
Miyazaki, K., Eskes, H. J., Sudo, K., Takigawa, M., van Weele, M., and Boersma, K. F.: Simultaneous assimilation of satellite NO2, O3, CO, and HNO3 data for the analysis of tropospheric chemical composition and emissions, Atmos. Chem. Phys., 12, 9545–9579, https://doi.org/10.5194/acp-12-9545-2012, 2012. a
Paciorek, C. and Schervish, M.: Spatial Modelling Using a New Class of Nonstationary Covariance Functions, Environmetrics, 17, 483–506, https://doi.org/10.1002/env.785, 2006. a
Pannekoucke, O.: opannekoucke/pdenetgen: pde-netgen-GMD (1.0.1), Zenodo [code], https://doi.org/10.5281/zenodo.3891101, 2020. a
Pannekoucke, O.: An anisotropic formulation of the parametric Kalman filter assimilation, Tellus A, 73, 1–27, https://doi.org/10.1080/16000870.2021.1926660, 2021a. a, b, c, d, e, f, g, h, i
Pannekoucke, O.: SymPKF: a symbolic and computational toolbox for the design of parametric Kalman filter dynamics (v1.0.1), Zenodo [code], https://doi.org/10.5281/zenodo.4625289, 2021b. a
Pannekoucke, O.: Toward a multivariate formulation of the PKF assimilation (v1.0), Zenodo [code], https://doi.org/10.5281/zenodo.7078574, 2023. a
Pannekoucke, O. and Arbogast, P.: SymPKF (v1.0): a symbolic and computational toolbox for the design of parametric Kalman filter dynamics, Geosci. Model Dev., 14, 5957–5976, https://doi.org/10.5194/gmd-14-5957-2021, 2021. a, b
Pannekoucke, O. and Fablet, R.: PDE-NetGen 1.0: from symbolic partial differential equation (PDE) representations of physical processes to trainable neural network representations, Geosci. Model Dev., 13, 3373–3382, https://doi.org/10.5194/gmd-13-3373-2020, 2020. a
Pannekoucke, O. and Massart, S.: Estimation of the local diffusion tensor and normalization for heterogeneous correlation modelling using a diffusion equation, Q. J. Roy. Meteor. Soc., 134, 1425–1438, https://doi.org/10.1002/qj.288, 2008. a
Pannekoucke, O., Ricci, S., Barthelemy, S., Ménard, R., and Thual, O.: Parametric Kalman filter for chemical transport models, Tellus A, 68, 31547, https://doi.org/10.3402/tellusa.v68.31547, 2016. a, b
Pannekoucke, O., Bocquet, M., and Ménard, R.: Parametric covariance dynamics for the nonlinear diffusive Burgers equation, Nonlin. Processes Geophys., 25, 481–495, https://doi.org/10.5194/npg-25-481-2018, 2018. a, b, c, d
Pannekoucke, O., Ménard, R., El Aabaribaoune, M., and Plu, M.: A methodology to obtain model-error covariances due to the discretization scheme from the parametric Kalman filter perspective, Nonlin. Processes Geophys., 28, 1–22, https://doi.org/10.5194/npg-28-1-2021, 2021. a
Peiro, H., Emili, E., Cariolle, D., Barret, B., and Le Flochmoën, E.: Multi-year assimilation of IASI and MLS ozone retrievals: variability of tropospheric ozone over the tropics in response to ENSO, Atmos. Chem. Phys., 18, 6939–6958, https://doi.org/10.5194/acp-18-6939-2018, 2018. a
Purser, R., Wu, W.-S., D.Parrish, and Roberts, N.: Numerical aspects of the application of recursive filters to variational statistical analysis. Part II: Spatially inhomogeneous and anisotropic general covariances, Mon. Weather Rev., 131, 1536–1548, https://doi.org/10.1175//2543.1, 2003. a
Sabathier, M., Pannekoucke, O., and Maget, V.: Boundary Conditions for the Parametric Kalman Filter forecast, J. Adv. Model. Earth. Sy., in review, 2023. a
Tang, X., Zhu, J., Wang, Z. F., and Gbaguidi, A.: Improvement of ozone forecast over Beijing based on ensemble Kalman filter with simultaneous adjustment of initial conditions and emissions, Atmos. Chem. Phys., 11, 12901–12916, https://doi.org/10.5194/acp-11-12901-2011, 2011. a
Voshtani, S., Ménard, R., Walker, T. W., and Hakami, A.: Assimilation of GOSAT Methane in the Hemispheric CMAQ; Part I: Design of the Assimilation System, Remote Sensing, 14, 371, https://doi.org/10.3390/rs14020371, 2022a. a
Voshtani, S., Ménard, R., Walker, T. W., and Hakami, A.: Assimilation of GOSAT Methane in the Hemispheric CMAQ; Part II: Results Using Optimal Error Statistics, Remote Sensing, 14, 375, https://doi.org/10.3390/rs14020375, 2022b. a
Weaver, A. and Courtier, P.: Correlation modelling on the sphere using a generalized diffusion equation (Tech. Memo. ECMWF, num. 306), Q. J. Roy. Meteor. Soc., 127, 1815–1846, https://doi.org/10.1002/qj.49712757518, 2001. a
Weaver, A., Deltel, C., Machu, E., Ricci, S., and Daget, N.: A multivariate balance operator for variational ocean data assimilation, Q. J. Roy. Meteor. Soc., 131, 3605–3625, https://doi.org/10.1256/qj.05.119, 2006. a
Whitaker, J. and Hamill, M.: Ensemble Data Assimilation without Perturbed Observations, Mon. Weather Rev., 130, https://doi.org/10.1175/1520-0493(2002)130<1913:EDAWPO>2.0.CO;2, 2003. a
Whitham, G. B.: Linear and nonlinear waves, Wiley, 638 pp., https://doi.org/10.1002/9781118032954, 1999. a
- Abstract
- Introduction
- Background on the parametric Kalman filter
- Toward a multivariate formulation of the PKF
- A more realistic chemical model: the generic reaction set (GRS) model
- Summary and conclusions
- Appendix A: Limits of the numerical validation of the PKF in the presence of model error
- Appendix B: Validation of correlation functions in univariate situations
- Appendix C: Lotka–Volterra chemical model
- Appendix D: Contribution of the chemistry to the uncertainty dynamics in the LV CTM
- Appendix E: Dynamics of the error statistics for the harmonic oscillator
- Appendix F: Cross-covariance analysis formula demonstration
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Background on the parametric Kalman filter
- Toward a multivariate formulation of the PKF
- A more realistic chemical model: the generic reaction set (GRS) model
- Summary and conclusions
- Appendix A: Limits of the numerical validation of the PKF in the presence of model error
- Appendix B: Validation of correlation functions in univariate situations
- Appendix C: Lotka–Volterra chemical model
- Appendix D: Contribution of the chemistry to the uncertainty dynamics in the LV CTM
- Appendix E: Dynamics of the error statistics for the harmonic oscillator
- Appendix F: Cross-covariance analysis formula demonstration
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References